前言
手语视频流的识别有两种大的分类,一种是直接将视频输入进网络,一种是识别了关键点之后再进入网络。所以这篇文章我就要来讲讲如何用mediapipe对手语视频进行关键点标注。
代码
需要直接使用代码的,我就放这里了。环境自己配置一下吧,不太记得了。
基础代码
这部分实现了主要功能,后续在此基础上进行修改
import os
import cv2
import numpy as np
import mediapipe as mp
from concurrent.futures import ThreadPoolExecutor# 关键点过滤设置
filtered_hand = list(range(21))
filtered_pose = [11, 12, 13, 14, 15, 16] # 只保留躯干和手臂关键点
HAND_NUM = len(filtered_hand)
POSE_NUM = len(filtered_pose)# 初始化MediaPipe模型(增加检测参数)
mp_hands = mp.solutions.hands
mp_pose = mp.solutions.posehands = mp_hands.Hands(static_image_mode=False,max_num_hands=2,min_detection_confidence=0.1,#太高的话,没识别到就不识别,比较低能识别的比较全(没有干扰的情况下低比较好)min_tracking_confidence=0.1#太高,没追踪到也会放弃,比较低的连续性会比较好
)pose = mp_pose.Pose(static_image_mode=False,model_complexity=1,min_detection_confidence=0.7,min_tracking_confidence=0.5
)def get_frame_landmarks(frame):"""获取单帧关键点(修复线程安全问题)"""all_landmarks = np.full((HAND_NUM * 2 + POSE_NUM, 3), np.nan) # 初始化为NaN# 改为顺序执行确保数据可靠性# 手部关键点results_hands = hands.process(frame)if results_hands.multi_hand_landmarks:for i, hand_landmarks in enumerate(results_hands.multi_hand_landmarks[:2]): # 最多两只手hand_type = results_hands.multi_handedness[i].classification[0].indexpoints = np.array([(lm.x, lm.y, lm.z) for lm in hand_landmarks.landmark])if hand_type == 0: # 右手all_landmarks[:HAND_NUM] = pointselse: # 左手all_landmarks[HAND_NUM:HAND_NUM * 2] = points# 身体关键点results_pose = pose.process(frame)if results_pose.pose_landmarks:pose_points = np.array([(lm.x, lm.y, lm.z) for lm in results_pose.pose_landmarks.landmark])all_landmarks[HAND_NUM * 2:HAND_NUM * 2 + POSE_NUM] = pose_points[filtered_pose]return all_landmarksdef get_video_landmarks(video_path, start_frame=1, end_frame=-1):"""获取视频关键点(添加调试信息)"""cap = cv2.VideoCapture(video_path)if not cap.isOpened():print(f"无法打开视频文件: {video_path}")return np.empty((0, HAND_NUM * 2 + POSE_NUM, 3))total_frames = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))if end_frame < 0 or end_frame > total_frames:end_frame = total_framesvalid_frames = []frame_index = 0while cap.isOpened():ret, frame = cap.read()if not ret or frame_index > end_frame:breakif frame_index >= start_frame:frame_rgb = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)landmarks = get_frame_landmarks(frame_rgb)# 检查是否检测到有效关键点if not np.all(np.isnan(landmarks)):valid_frames.append(landmarks)else:print(f"第 {frame_index} 帧未检测到关键点")frame_index += 1cap.release()if not valid_frames:print("警告:未检测到任何关键点")return np.empty((0, HAND_NUM * 2 + POSE_NUM, 3))return np.stack(valid_frames)def draw_landmarks(video_path, output_path, landmarks):"""绘制关键点到视频"""cap = cv2.VideoCapture(video_path)if not cap.isOpened():print(f"无法打开视频文件: {video_path}")returnfps = int(cap.get(cv2.CAP_PROP_FPS))width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))fourcc = cv2.VideoWriter_fourcc(*'mp4v')out = cv2.VideoWriter(output_path, fourcc, fps, (width, height))landmark_index = 0while cap.isOpened():ret, frame = cap.read()if not ret:breakif landmark_index < len(landmarks):# 绘制关键点for i, (x, y, _) in enumerate(landmarks[landmark_index]):if not np.isnan(x) and not np.isnan(y):px, py = int(x * width), int(y * height)# 右手绿色,左手红色,身体蓝色color = (0, 255, 0) if i < HAND_NUM else \(0, 0, 255) if i < HAND_NUM * 2 else \(255, 0, 0)cv2.circle(frame, (px, py), 4, color, -1)landmark_index += 1out.write(frame)cap.release()out.release()# 处理所有视频
video_root = "./doc/补充版/正式数据集/"
output_root = "./doc/save/"if not os.path.exists(output_root):os.makedirs(output_root)for video_name in os.listdir(video_root):if not video_name.endswith(('.mp4', '.avi', '.mov')):continuevideo_path = os.path.join(video_root, video_name)print(f"\n处理视频: {video_name}")# 获取关键点landmarks = get_video_landmarks(video_path)print(f"获取到 {len(landmarks)} 帧关键点")# 保存npy文件base_name = os.path.splitext(video_name)[0]np.save(os.path.join(output_root,"npy", f"{base_name}.npy"), landmarks)# 生成带关键点的视频output_video = os.path.join(output_root, "MP4",f"{base_name}_landmarks.mp4")draw_landmarks(video_path, output_video, landmarks)
print("全部处理完成!")
使用比较简单,修改video_root为视频目录路径,output_root为结果输出目录路径就可以正常使用了!
前置处理
# 关键点过滤设置
filtered_hand = list(range(21))
filtered_pose = [11, 12, 13, 14, 15, 16] # 只保留躯干和手臂关键点
HAND_NUM = len(filtered_hand)
POSE_NUM = len(filtered_pose)
)
这里需要选取你需要的关键点,手部正常来说每个手21个,姿态和脸部的关键点也可以自己选择保留什么,网上可以查到每个点对应数字。
# 初始化MediaPipe模型(增加检测参数)
mp_hands = mp.solutions.hands
mp_pose = mp.solutions.posehands = mp_hands.Hands(static_image_mode=False,max_num_hands=2,min_detection_confidence=0.1,#太高的话,没识别到就不识别,比较低能识别的比较全(没有干扰的情况下低比较好)min_tracking_confidence=0.1#太高,没追踪到也会放弃,比较低的连续性会比较好
)pose = mp_pose.Pose(static_image_mode=False,model_complexity=1,min_detection_confidence=0.7,min_tracking_confidence=0.5
参数调整,对于手部和姿态都可以进行单独的参数调整,static_image_mode是是否是图片,False代表不是,我这里是视频,如果是视频的话,后面就还有一个min_tracking_confidence追踪阈值,而图片不具有时间连续性,所以用不到这个参数。max_num_hands是最大会识别到有几个手,后面两个参数我也写了怎么调。姿态参数基本同理,有一些区别可以自己查一下。
函数讲解
def get_frame_landmarks(frame):"""获取单帧关键点(修复线程安全问题)"""all_landmarks = np.full((HAND_NUM * 2 + POSE_NUM, 3), np.nan) # 初始化为NaN# 改为顺序执行确保数据可靠性# 手部关键点results_hands = hands.process(frame)if results_hands.multi_hand_landmarks:for i, hand_landmarks in enumerate(results_hands.multi_hand_landmarks[:2]): # 最多两只手hand_type = results_hands.multi_handedness[i].classification[0].indexpoints = np.array([(lm.x, lm.y, lm.z) for lm in hand_landmarks.landmark])if hand_type == 0: # 右手all_landmarks[:HAND_NUM] = pointselse: # 左手all_landmarks[HAND_NUM:HAND_NUM * 2] = points# 身体关键点results_pose = pose.process(frame)if results_pose.pose_landmarks:pose_points = np.array([(lm.x, lm.y, lm.z) for lm in results_pose.pose_landmarks.landmark])all_landmarks[HAND_NUM * 2:HAND_NUM * 2 + POSE_NUM] = pose_points[filtered_pose]return all_landmarks
对于单帧进行处理,先对所有关键点留np的位置,全部填充NaN,再分别对手部关键点和肢体关键点进行识别,将识别的点填入原先的数组里面,得到最后要返回的关键点数组。
def get_video_landmarks(video_path, start_frame=1, end_frame=-1):"""获取视频关键点(添加调试信息)"""cap = cv2.VideoCapture(video_path)if not cap.isOpened():print(f"无法打开视频文件: {video_path}")return np.empty((0, HAND_NUM * 2 + POSE_NUM, 3))total_frames = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))if end_frame < 0 or end_frame > total_frames:end_frame = total_framesvalid_frames = []frame_index = 0while cap.isOpened():ret, frame = cap.read()if not ret or frame_index > end_frame:breakif frame_index >= start_frame:frame_rgb = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)landmarks = get_frame_landmarks(frame_rgb)# 检查是否检测到有效关键点if not np.all(np.isnan(landmarks)):valid_frames.append(landmarks)else:print(f"第 {frame_index} 帧未检测到关键点")frame_index += 1cap.release()if not valid_frames:print("警告:未检测到任何关键点")return np.empty((0, HAND_NUM * 2 + POSE_NUM, 3))return np.stack(valid_frames)处理视频帧的关键点识别,读取视频的每一帧,分别做通道BGR转RGB和调用单帧处理函数对其进行处理,将每一帧的结果堆叠起来返回。
def draw_landmarks(video_path, output_path, landmarks):"""绘制关键点到视频"""cap = cv2.VideoCapture(video_path)if not cap.isOpened():print(f"无法打开视频文件: {video_path}")returnfps = int(cap.get(cv2.CAP_PROP_FPS))width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))fourcc = cv2.VideoWriter_fourcc(*'mp4v')out = cv2.VideoWriter(output_path, fourcc, fps, (width, height))landmark_index = 0while cap.isOpened():ret, frame = cap.read()if not ret:breakif landmark_index < len(landmarks):# 绘制关键点for i, (x, y, _) in enumerate(landmarks[landmark_index]):if not np.isnan(x) and not np.isnan(y):px, py = int(x * width), int(y * height)# 右手绿色,左手红色,身体蓝色color = (0, 255, 0) if i < HAND_NUM else \(0, 0, 255) if i < HAND_NUM * 2 else \(255, 0, 0)cv2.circle(frame, (px, py), 4, color, -1)landmark_index += 1out.write(frame)cap.release()out.release()绘制结果关键点函数,将视频路径和输出路径以及识别的关键点数组传入,读取视频,对每一帧的图片每一个关键点进行绘制,画圈圈,然后将帧写入保存。
进阶版log代码
该版本在原有基础上将简单点连接,新加上了线连接,效果如下:
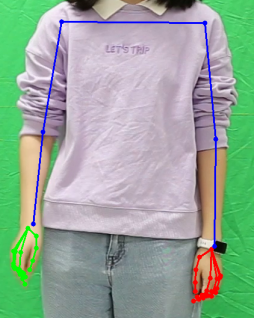
同时添加了log,对于结果的视频流进行分析处理,当当前帧缺失了一只手的点,那么就认为该帧出现掉帧,统计掉帧的帧数和将掉帧的前2帧外加后3帧保存为图片记录下来。
import os
import cv2
import numpy as np
import mediapipe as mp
from concurrent.futures import ThreadPoolExecutor# 关键点过滤设置
filtered_hand = list(range(21))
filtered_pose = [11, 12, 13, 14, 15, 16] # 只保留躯干和手臂关键点
HAND_NUM = len(filtered_hand)
POSE_NUM = len(filtered_pose)# 初始化MediaPipe模型(增加检测参数)
mp_hands = mp.solutions.hands
mp_pose = mp.solutions.posehands = mp_hands.Hands(static_image_mode=False,max_num_hands=2,min_detection_confidence=0.1,#太高的话,没识别到就不识别,比较低能识别的比较全(没有干扰的情况下低比较好)min_tracking_confidence=0.1#太高,没追踪到也会放弃,比较低的连续性会比较好
)pose = mp_pose.Pose(static_image_mode=False,model_complexity=1,min_detection_confidence=0.7,min_tracking_confidence=0.5
)def get_frame_landmarks(frame):"""获取单帧关键点(修复线程安全问题)"""all_landmarks = np.full((HAND_NUM * 2 + POSE_NUM, 3), np.nan) # 初始化为NaN# 改为顺序执行确保数据可靠性# 手部关键点results_hands = hands.process(frame)if results_hands.multi_hand_landmarks:for i, hand_landmarks in enumerate(results_hands.multi_hand_landmarks[:2]): # 最多两只手hand_type = results_hands.multi_handedness[i].classification[0].indexpoints = np.array([(lm.x, lm.y, lm.z) for lm in hand_landmarks.landmark])if hand_type == 0: # 右手all_landmarks[:HAND_NUM] = pointselse: # 左手all_landmarks[HAND_NUM:HAND_NUM * 2] = points# 身体关键点results_pose = pose.process(frame)if results_pose.pose_landmarks:pose_points = np.array([(lm.x, lm.y, lm.z) for lm in results_pose.pose_landmarks.landmark])all_landmarks[HAND_NUM * 2:HAND_NUM * 2 + POSE_NUM] = pose_points[filtered_pose]return all_landmarksdef get_video_landmarks(video_path, start_frame=1, end_frame=-1):"""获取视频关键点(严格版帧对齐+掉帧统计)"""output_dir = "./doc/save_log/log"os.makedirs(output_dir, exist_ok=True) # 确保输出目录存在video_name=video_path.split("/")[4].split(".")[0]output_root=os.path.join(output_dir,video_name)os.makedirs(output_root, exist_ok=True)log_file_path = os.path.join(output_root, f"{video_name}.txt")with open(log_file_path, 'w') as log_file:cap = cv2.VideoCapture(video_path)if not cap.isOpened():print(f"无法打开视频文件: {video_path}", file=log_file)return np.empty((0, HAND_NUM * 2 + POSE_NUM, 3))total_frames = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))if end_frame < 0 or end_frame > total_frames:end_frame = total_frames# 预分配全NaN数组确保严格帧对齐results = np.full((end_frame - start_frame + 1, HAND_NUM * 2 + POSE_NUM, 3), np.nan)missing_frames = []frame_index = 0results_index = 0 # 结果数组的索引frame_buffer = [] # 用于保存帧图像width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))while cap.isOpened():ret, frame = cap.read()if not ret or frame_index > end_frame:breakif start_frame <= frame_index <= end_frame:frame_rgb = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)landmarks = get_frame_landmarks(frame_rgb)# 保存帧图像到缓冲区only_draw_landmarks(frame, landmarks, width, height)frame_buffer.append((frame_index, frame.copy()))# 检查关键点数量是否正确if landmarks.shape[0] == HAND_NUM * 2 + POSE_NUM:valid_points = np.sum(~np.isnan(landmarks[:, :2]))results[results_index] = landmarksif valid_points != 2 * (HAND_NUM * 2 + POSE_NUM):# 保存前后5帧save_range = range(max(frame_index - 2, start_frame), min(frame_index + 3, end_frame) + 1)for save_idx in save_range:save_path = os.path.join(output_root, f"frame_{save_idx:04d}_near_nan.png")# 从缓冲区查找帧for buf_idx, buf_frame in frame_buffer:if buf_idx == save_idx:cv2.imwrite(save_path, buf_frame)missing_frames.append(frame_index)print(f"掉帧警告 - 第 {frame_index} 帧: 有效点不足 ({valid_points}/{2 * landmarks.shape[0]})",file=log_file)else:missing_frames.append(frame_index)print(f"掉帧警告 - 第 {frame_index} 帧: 关键点数量异常 ({landmarks.shape[0]} != {HAND_NUM * 2 + POSE_NUM})",file=log_file)results_index += 1frame_index += 1cap.release()# 统计报告total_processed = end_frame - start_frame + 1print("\n关键点检测统计报告:", file=log_file)print(f"处理帧范围: {start_frame}-{end_frame} (共 {total_processed} 帧)", file=log_file)print(f"成功帧数: {total_processed - len(missing_frames)}", file=log_file)print(f"掉帧数: {len(missing_frames)}", file=log_file)if missing_frames:print("掉帧位置: " + ", ".join(map(str, missing_frames)), file=log_file)print(f"掉帧率: {len(missing_frames) / total_processed:.1%}", file=log_file)return resultsdef only_draw_landmarks(frame, landmarks, width, height):"""绘制关键点和连线到帧"""# 定义连接线HAND_CONNECTIONS = [ # 21个手部关键点连线 (MediaPipe手部模型)(0, 1), (1, 2), (2, 3), (3, 4), # 拇指(0, 5), (5, 6), (6, 7), (7, 8), # 食指(0, 9), (9, 10), (10, 11), (11, 12), # 中指(0, 13), (13, 14), (14, 15), (15, 16), # 无名指(0, 17), (17, 18), (18, 19), (19, 20) # 小指]# 躯干和手臂连线 (11-16对应: 肩膀、手肘、手腕)POSE_CONNECTIONS = [(11, 12), # 左右肩连线(11, 13), (13, 15), # 左臂(12, 14), (14, 16) # 右臂]# 绘制关键点for i, (x, y, _) in enumerate(landmarks):if not np.isnan(x) and not np.isnan(y):px, py = int(x * width), int(y * height)# 右手绿色(0-20),左手红色(21-41),身体蓝色(42+)color = (0, 255, 0) if i < HAND_NUM else \(0, 0, 255) if i < HAND_NUM * 2 else \(255, 0, 0)cv2.circle(frame, (px, py), 4, color, -1)# 绘制连线 - 右手 (前21个点)for connection in HAND_CONNECTIONS:start_idx, end_idx = connectionif start_idx < len(landmarks) and end_idx < len(landmarks):x1, y1, _ = landmarks[start_idx]x2, y2, _ = landmarks[end_idx]if not np.isnan(x1) and not np.isnan(y1) and not np.isnan(x2) and not np.isnan(y2):pt1 = (int(x1 * width), int(y1 * height))pt2 = (int(x2 * width), int(y2 * height))cv2.line(frame, pt1, pt2, (0, 255, 0), 2)# 绘制连线 - 左手 (21-41)for connection in HAND_CONNECTIONS:start_idx, end_idx = connectionstart_idx += HAND_NUMend_idx += HAND_NUMif start_idx < len(landmarks) and end_idx < len(landmarks):x1, y1, _ = landmarks[start_idx]x2, y2, _ = landmarks[end_idx]if not np.isnan(x1) and not np.isnan(y1) and not np.isnan(x2) and not np.isnan(y2):pt1 = (int(x1 * width), int(y1 * height))pt2 = (int(x2 * width), int(y2 * height))cv2.line(frame, pt1, pt2, (0, 0, 255), 2)# 绘制连线 - 身体 (只绘制filtered_pose中的点)for connection in POSE_CONNECTIONS:start_idx, end_idx = connection# 转换为实际索引 (假设身体关键点从2*HAND_NUM开始)start_idx = 2 * HAND_NUM + filtered_pose.index(start_idx) if start_idx in filtered_pose else -1end_idx = 2 * HAND_NUM + filtered_pose.index(end_idx) if end_idx in filtered_pose else -1if start_idx != -1 and end_idx != -1 and start_idx < len(landmarks) and end_idx < len(landmarks):x1, y1, _ = landmarks[start_idx]x2, y2, _ = landmarks[end_idx]if not np.isnan(x1) and not np.isnan(y1) and not np.isnan(x2) and not np.isnan(y2):pt1 = (int(x1 * width), int(y1 * height))pt2 = (int(x2 * width), int(y2 * height))cv2.line(frame, pt1, pt2, (255, 0, 0), 2)
def draw_landmarks(video_path, output_path, landmarks):"""绘制关键点和连线到视频"""# 定义连接线HAND_CONNECTIONS = [ # 21个手部关键点连线 (MediaPipe手部模型)(0, 1), (1, 2), (2, 3), (3, 4), # 拇指(0, 5), (5, 6), (6, 7), (7, 8), # 食指(0, 9), (9, 10), (10, 11), (11, 12), # 中指(0, 13), (13, 14), (14, 15), (15, 16), # 无名指(0, 17), (17, 18), (18, 19), (19, 20) # 小指]# 躯干和手臂连线 (11-16对应: 肩膀、手肘、手腕)POSE_CONNECTIONS = [(11, 12), # 左右肩连线(11, 13), (13, 15), # 左臂(12, 14), (14, 16) # 右臂]cap = cv2.VideoCapture(video_path)if not cap.isOpened():print(f"无法打开视频文件: {video_path}")returnfps = int(cap.get(cv2.CAP_PROP_FPS))width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))fourcc = cv2.VideoWriter_fourcc(*'mp4v')out = cv2.VideoWriter(output_path, fourcc, fps, (width, height))landmark_index = 0while cap.isOpened():ret, frame = cap.read()if not ret:breakif landmark_index < len(landmarks):current_landmarks = landmarks[landmark_index]# 绘制关键点for i, (x, y, _) in enumerate(current_landmarks):if not np.isnan(x) and not np.isnan(y):px, py = int(x * width), int(y * height)# 右手绿色(0-20),左手红色(21-41),身体蓝色(42+)color = (0, 255, 0) if i < HAND_NUM else \(0, 0, 255) if i < HAND_NUM * 2 else \(255, 0, 0)cv2.circle(frame, (px, py), 4, color, -1)# 绘制连线 - 右手 (前21个点)for connection in HAND_CONNECTIONS:start_idx, end_idx = connectionif start_idx < len(current_landmarks) and end_idx < len(current_landmarks):x1, y1, _ = current_landmarks[start_idx]x2, y2, _ = current_landmarks[end_idx]if not np.isnan(x1) and not np.isnan(y1) and not np.isnan(x2) and not np.isnan(y2):pt1 = (int(x1 * width), int(y1 * height))pt2 = (int(x2 * width), int(y2 * height))cv2.line(frame, pt1, pt2, (0, 255, 0), 2)# 绘制连线 - 左手 (21-41)for connection in HAND_CONNECTIONS:start_idx, end_idx = connectionstart_idx += HAND_NUMend_idx += HAND_NUMif start_idx < len(current_landmarks) and end_idx < len(current_landmarks):x1, y1, _ = current_landmarks[start_idx]x2, y2, _ = current_landmarks[end_idx]if not np.isnan(x1) and not np.isnan(y1) and not np.isnan(x2) and not np.isnan(y2):pt1 = (int(x1 * width), int(y1 * height))pt2 = (int(x2 * width), int(y2 * height))cv2.line(frame, pt1, pt2, (0, 0, 255), 2)# 绘制连线 - 身体 (只绘制filtered_pose中的点)for connection in POSE_CONNECTIONS:start_idx, end_idx = connection# 转换为实际索引 (假设身体关键点从2*HAND_NUM开始)start_idx = 2 * HAND_NUM + filtered_pose.index(start_idx) if start_idx in filtered_pose else -1end_idx = 2 * HAND_NUM + filtered_pose.index(end_idx) if end_idx in filtered_pose else -1if start_idx != -1 and end_idx != -1 and start_idx < len(current_landmarks) and end_idx < len(current_landmarks):x1, y1, _ = current_landmarks[start_idx]x2, y2, _ = current_landmarks[end_idx]if not np.isnan(x1) and not np.isnan(y1) and not np.isnan(x2) and not np.isnan(y2):pt1 = (int(x1 * width), int(y1 * height))pt2 = (int(x2 * width), int(y2 * height))cv2.line(frame, pt1, pt2, (255, 0, 0), 2)landmark_index += 1out.write(frame)cap.release()out.release()# 处理所有视频
video_root = "./doc/补充版/正式数据集/"
output_root = "./doc/try_log/"if not os.path.exists(output_root):os.makedirs(output_root)for video_name in os.listdir(video_root):if not video_name.endswith(('.mp4', '.avi', '.mov')):continuevideo_path = os.path.join(video_root, video_name)print(f"\n处理视频: {video_name}")# 获取关键点landmarks = get_video_landmarks(video_path)print(f"获取到 {len(landmarks)} 帧关键点")if not os.path.exists(os.path.join(output_root,"npy")):os.makedirs(os.path.join(output_root,"npy"))# 保存npy文件base_name = os.path.splitext(video_name)[0]np.save(os.path.join(output_root,"npy", f"{base_name}.npy"), landmarks)if not os.path.exists(os.path.join(output_root,"MP4")):os.makedirs(os.path.join(output_root,"MP4"))# 生成带关键点的视频output_video = os.path.join(output_root, "MP4",f"{base_name}_landmarks.mp4")draw_landmarks(video_path, output_video, landmarks)
print("全部处理完成!")
函数讲解
def get_video_landmarks(video_path, start_frame=1, end_frame=-1):"""获取视频关键点(严格版帧对齐+掉帧统计)"""output_dir = "./doc/save_log/log"os.makedirs(output_dir, exist_ok=True) # 确保输出目录存在video_name=video_path.split("/")[4].split(".")[0]output_root=os.path.join(output_dir,video_name)os.makedirs(output_root, exist_ok=True)log_file_path = os.path.join(output_root, f"{video_name}.txt")with open(log_file_path, 'w') as log_file:cap = cv2.VideoCapture(video_path)if not cap.isOpened():print(f"无法打开视频文件: {video_path}", file=log_file)return np.empty((0, HAND_NUM * 2 + POSE_NUM, 3))total_frames = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))if end_frame < 0 or end_frame > total_frames:end_frame = total_frames# 预分配全NaN数组确保严格帧对齐results = np.full((end_frame - start_frame + 1, HAND_NUM * 2 + POSE_NUM, 3), np.nan)missing_frames = []frame_index = 0results_index = 0 # 结果数组的索引frame_buffer = [] # 用于保存帧图像width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))while cap.isOpened():ret, frame = cap.read()if not ret or frame_index > end_frame:breakif start_frame <= frame_index <= end_frame:frame_rgb = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)landmarks = get_frame_landmarks(frame_rgb)# 保存帧图像到缓冲区only_draw_landmarks(frame, landmarks, width, height)frame_buffer.append((frame_index, frame.copy()))# 检查关键点数量是否正确if landmarks.shape[0] == HAND_NUM * 2 + POSE_NUM:valid_points = np.sum(~np.isnan(landmarks[:, :2]))results[results_index] = landmarksif valid_points != 2 * (HAND_NUM * 2 + POSE_NUM):# 保存前后5帧save_range = range(max(frame_index - 2, start_frame), min(frame_index + 3, end_frame) + 1)for save_idx in save_range:save_path = os.path.join(output_root, f"frame_{save_idx:04d}_near_nan.png")# 从缓冲区查找帧for buf_idx, buf_frame in frame_buffer:if buf_idx == save_idx:cv2.imwrite(save_path, buf_frame)missing_frames.append(frame_index)print(f"掉帧警告 - 第 {frame_index} 帧: 有效点不足 ({valid_points}/{2 * landmarks.shape[0]})",file=log_file)else:missing_frames.append(frame_index)print(f"掉帧警告 - 第 {frame_index} 帧: 关键点数量异常 ({landmarks.shape[0]} != {HAND_NUM * 2 + POSE_NUM})",file=log_file)results_index += 1frame_index += 1cap.release()# 统计报告total_processed = end_frame - start_frame + 1print("\n关键点检测统计报告:", file=log_file)print(f"处理帧范围: {start_frame}-{end_frame} (共 {total_processed} 帧)", file=log_file)print(f"成功帧数: {total_processed - len(missing_frames)}", file=log_file)print(f"掉帧数: {len(missing_frames)}", file=log_file)if missing_frames:print("掉帧位置: " + ", ".join(map(str, missing_frames)), file=log_file)print(f"掉帧率: {len(missing_frames) / total_processed:.1%}", file=log_file)return results
稍稍讲一下这个修改比较大的部分吧,这部分添加了frame_buffer保存缓存帧,用于后续我提取我需要的记录帧,在保存之前添加了only_draw_landmarks函数,对于图片只进行关键点标注而不保存的功能,使得保存的图片能清楚看到问题出现在哪里。
if valid_points != 2 * (HAND_NUM * 2 + POSE_NUM):最关键的判断,有校点的判断,如果有nan的关键点就不是有校点,乘2是因为一个点要保留xy两个数值。当有效点不足时,进行log记录并且保存图片,最后还需要统计报告。
代码进阶版(卡尔曼滤波版)
class Kalman1D:def __init__(self):self.x = 0self.P = 1self.F = 1self.H = 1self.R = 0.01self.Q = 0.001self.initiated = Falsedef update(self, measurement):if not self.initiated:self.x = measurementself.initiated = True# Predictself.x = self.F * self.xself.P = self.F * self.P * self.F + self.Q# UpdateK = self.P * self.H / (self.H * self.P * self.H + self.R)self.x += K * (measurement - self.H * self.x)self.P = (1 - K * self.H) * self.Preturn self.xdef init_kalman_filters(num_points):return [[Kalman1D() for _ in range(3)] for _ in range(num_points)]def get_video_landmarks(video_path, start_frame=1, end_frame=-1):output_dir = "./doc/save_log/log"os.makedirs(output_dir, exist_ok=True)video_name = video_path.split("/")[-1].split(".")[0]output_root = os.path.join(output_dir, video_name)os.makedirs(output_root, exist_ok=True)log_file_path = os.path.join(output_root, f"{video_name}.txt")filters = init_kalman_filters(HAND_NUM * 2 + POSE_NUM)with open(log_file_path, 'w') as log_file:cap = cv2.VideoCapture(video_path)if not cap.isOpened():print(f"无法打开视频文件: {video_path}", file=log_file)return np.empty((0, HAND_NUM * 2 + POSE_NUM, 3))total_frames = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))if end_frame < 0 or end_frame > total_frames:end_frame = total_framesresults = np.full((end_frame - start_frame + 1, HAND_NUM * 2 + POSE_NUM, 3), np.nan)missing_frames = []frame_index = 0results_index = 0frame_buffer = []width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))while cap.isOpened():ret, frame = cap.read()if not ret or frame_index > end_frame:breakif start_frame <= frame_index <= end_frame:frame_rgb = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)landmarks = get_frame_landmarks(frame_rgb)# 应用卡尔曼滤波for i, (x, y, z) in enumerate(landmarks):for j, val in enumerate([x, y, z]):if not np.isnan(val):landmarks[i][j] = filters[i][j].update(val)only_draw_landmarks(frame, landmarks, width, height)frame_buffer.append((frame_index, frame.copy()))if landmarks.shape[0] == HAND_NUM * 2 + POSE_NUM:valid_points = np.sum(~np.isnan(landmarks[:, :2]))results[results_index] = landmarksif valid_points != 2 * (HAND_NUM * 2 + POSE_NUM):save_range = range(max(frame_index - 2, start_frame), min(frame_index + 3, end_frame) + 1)for save_idx in save_range:save_path = os.path.join(output_root, f"frame_{save_idx:04d}_near_nan.png")for buf_idx, buf_frame in frame_buffer:if buf_idx == save_idx:cv2.imwrite(save_path, buf_frame)missing_frames.append(frame_index)print(f"掉帧警告 - 第 {frame_index} 帧: 有效点不足 ({valid_points}/{2 * landmarks.shape[0]})", file=log_file)else:missing_frames.append(frame_index)print(f"掉帧警告 - 第 {frame_index} 帧: 关键点数量异常 ({landmarks.shape[0]} != {HAND_NUM * 2 + POSE_NUM})", file=log_file)results_index += 1frame_index += 1cap.release()total_processed = end_frame - start_frame + 1print("\n关键点检测统计报告:", file=log_file)print(f"处理帧范围: {start_frame}-{end_frame} (共 {total_processed} 帧)", file=log_file)print(f"成功帧数: {total_processed - len(missing_frames)}", file=log_file)print(f"掉帧数: {len(missing_frames)}", file=log_file)if missing_frames:print("掉帧位置: " + ", ".join(map(str, missing_frames)), file=log_file)print(f"掉帧率: {len(missing_frames) / total_processed:.1%}", file=log_file)return results其他部分同上就不赘诉和再次写了,当R=0.01时,会发现整体识别会跟不上视频,而R=0.00001时,又会发现几乎同没有卡尔曼差不多,在我的数据集上是这样的,其他数据集说不定有效果。
代码进阶版(速度卡尔曼滤波)
class Kalman1D_Velocity:def __init__(self):self.x = np.array([[0.], [0.]]) # 初始状态:[位置, 速度]self.P = np.eye(2) # 状态协方差self.F = np.array([[1., 1.],[0., 1.]]) # 状态转移self.H = np.array([[1., 0.]]) # 观测矩阵self.R = np.array([[0.01]]) # 观测噪声self.Q = np.array([[0.001, 0.],[0., 0.001]]) # 过程噪声self.initiated = Falsedef predict(self):self.x = np.dot(self.F, self.x)self.P = np.dot(self.F, np.dot(self.P, self.F.T)) + self.Qreturn self.x[0, 0]def update(self, measurement):if not self.initiated:self.x[0, 0] = measurementself.x[1, 0] = 0.0self.initiated = Truereturn measurement# Predictself.predict()# UpdateS = np.dot(self.H, np.dot(self.P, self.H.T)) + self.RK = np.dot(np.dot(self.P, self.H.T), np.linalg.inv(S))z = np.array([[measurement]])y = z - np.dot(self.H, self.x)self.x = self.x + np.dot(K, y)self.P = self.P - np.dot(K, np.dot(self.H, self.P))return self.x[0, 0]def update_or_predict(self, measurement):if np.isnan(measurement):return self.predict()else:return self.update(measurement)
def init_kalman_filters(num_points):return [[Kalman1D_Velocity() for _ in range(3)] for _ in range(num_points)]def get_video_landmarks(video_path, start_frame=1, end_frame=-1):output_dir = "./doc/save_log/log"os.makedirs(output_dir, exist_ok=True)video_name = video_path.split("/")[-1].split(".")[0]output_root = os.path.join(output_dir, video_name)os.makedirs(output_root, exist_ok=True)log_file_path = os.path.join(output_root, f"{video_name}.txt")filters = init_kalman_filters(HAND_NUM * 2 + POSE_NUM)with open(log_file_path, 'w') as log_file:cap = cv2.VideoCapture(video_path)if not cap.isOpened():print(f"无法打开视频文件: {video_path}", file=log_file)return np.empty((0, HAND_NUM * 2 + POSE_NUM, 3))total_frames = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))if end_frame < 0 or end_frame > total_frames:end_frame = total_framesresults = np.full((end_frame - start_frame + 1, HAND_NUM * 2 + POSE_NUM, 3), np.nan)missing_frames = []frame_index = 0results_index = 0frame_buffer = []width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))while cap.isOpened():ret, frame = cap.read()if not ret or frame_index > end_frame:breakif start_frame <= frame_index <= end_frame:frame_rgb = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)landmarks = get_frame_landmarks(frame_rgb)# 应用卡尔曼滤波for i, (x, y, z) in enumerate(landmarks):for j, val in enumerate([x, y, z]):landmarks[i][j] = filters[i][j].update_or_predict(val)only_draw_landmarks(frame, landmarks, width, height)frame_buffer.append((frame_index, frame.copy()))if landmarks.shape[0] == HAND_NUM * 2 + POSE_NUM:valid_points = np.sum(~np.isnan(landmarks[:, :2]))results[results_index] = landmarksif valid_points != 2 * (HAND_NUM * 2 + POSE_NUM):save_range = range(max(frame_index - 2, start_frame), min(frame_index + 3, end_frame) + 1)for save_idx in save_range:save_path = os.path.join(output_root, f"frame_{save_idx:04d}_near_nan.png")for buf_idx, buf_frame in frame_buffer:if buf_idx == save_idx:cv2.imwrite(save_path, buf_frame)missing_frames.append(frame_index)print(f"掉帧警告 - 第 {frame_index} 帧: 有效点不足 ({valid_points}/{2 * landmarks.shape[0]})", file=log_file)else:missing_frames.append(frame_index)print(f"掉帧警告 - 第 {frame_index} 帧: 关键点数量异常 ({landmarks.shape[0]} != {HAND_NUM * 2 + POSE_NUM})", file=log_file)results_index += 1frame_index += 1cap.release()total_processed = end_frame - start_frame + 1print("\n关键点检测统计报告:", file=log_file)print(f"处理帧范围: {start_frame}-{end_frame} (共 {total_processed} 帧)", file=log_file)print(f"成功帧数: {total_processed - len(missing_frames)}", file=log_file)print(f"掉帧数: {len(missing_frames)}", file=log_file)if missing_frames:print("掉帧位置: " + ", ".join(map(str, missing_frames)), file=log_file)print(f"掉帧率: {len(missing_frames) / total_processed:.1%}", file=log_file)return results
这个版本不会出现慢太多的情况,但是会出现有点飘的感觉,有时候会比没有的效果好一点。
总结
基础版:整个路线还是比较清晰的,由于我使用的数据视频背景比较简单,不太会出现误识别,所以我的参数调的很低,但是不知道为什么还是会出现掉帧的情况,需要后续研究一下。
进阶版:用了log记录之后才发现,掉帧和误识别还是有点严重的,一帧一帧会发现很多,采用了卡尔曼和速度卡尔曼似乎都不能很好的处理。





、LangChain框架、MCP协议和RAG技术研发)



)









