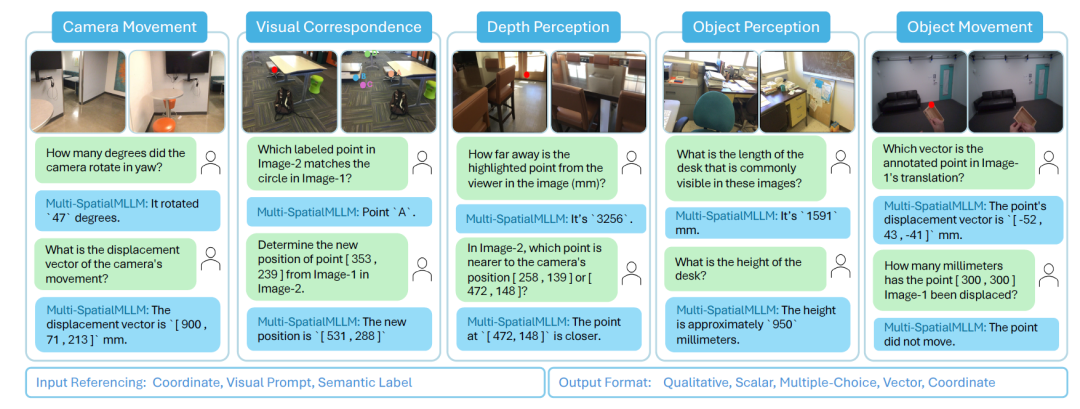

<------最重要的是订阅“鲁班模锤”------>
当我们看到一张照片时,大脑会自动分析其中的空间关系——哪个物体在前,哪个在后,左边是什么,右边是什么。但对于当今最先进的AI系统来说,这种看似简单的空间理解却是一个巨大的挑战。Meta FAIR和香港中文大学的研究团队最近发布的Multi-SpatialMLLM项目,正在试图解决这个根本性问题。
现有的多模态大语言模型虽然在图像识别和文本理解方面表现出色,但在空间推理上却存在严重缺陷。这些模型往往连最基本的左右区分都会出错,更不用说理解复杂的3D空间关系了。造成这种现象的根本原因在于,绝大多数AI训练都基于单张图像,就像让一个人只通过一扇窗户观察整个世界一样,视野必然受限。
随着AI在机器人技术、自动驾驶、增强现实等领域的应用需求日益增长,空间理解能力的缺失成为了制约其发展的关键瓶颈。机器人需要准确理解环境中物体的位置关系才能有效执行任务,自动驾驶系统必须精确判断道路、车辆和行人的空间分布才能安全行驶。

空间理解的技术突破
Multi-SpatialMLLM的核心创新在于将AI的视觉理解从单张图像扩展到多张图像的协同分析。这种方法模仿了人类的视觉系统——我们通过双眼产生立体视觉,通过头部和身体的移动获得不同视角,然后大脑整合这些信息形成完整的空间认知。
-
深度感知(Depth Perception):理解物体离镜头的远近;
-
视觉对应(Visual Correspondence):识别同一物体在不同图像中的位置对应;
-
动态感知(Dynamic Perception):推断相机或物体的运动方向和幅度。
研究团队设计了一个包含三个核心组件的框架:深度感知、视觉对应和动态感知。深度感知让AI能够判断物体距离的远近,视觉对应使AI能在不同视角间建立像素点的对应关系,动态感知则赋予AI捕捉相机和物体运动信息的能力。这三个组件的协同工作,使AI首次具备了真正的多帧空间理解能力。

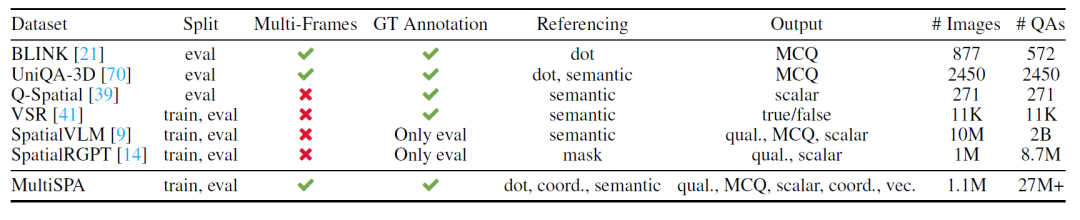
MultiSPA
为了训练AI系统,团队构建了MultiSPA数据集,这是一个包含超过2700万样本的大规模空间理解数据集。数据集的构建过程体现了研究团队的匠心独运。
-
数据来自真实世界的3D/4D图像集,不是合成或模拟数据;
-
自动采样图像对,确保画面有足够重叠与变化;
-
利用点云反投影技术建立像素级别的对应关系,实现空间和时间的精准对齐;
-
借助GPT-4o自动生成问题与答案模板,涵盖定性描述与定量坐标、向量等多种形式;
-
支持用像素点、语义标签、坐标等多种方式描述问题答案。
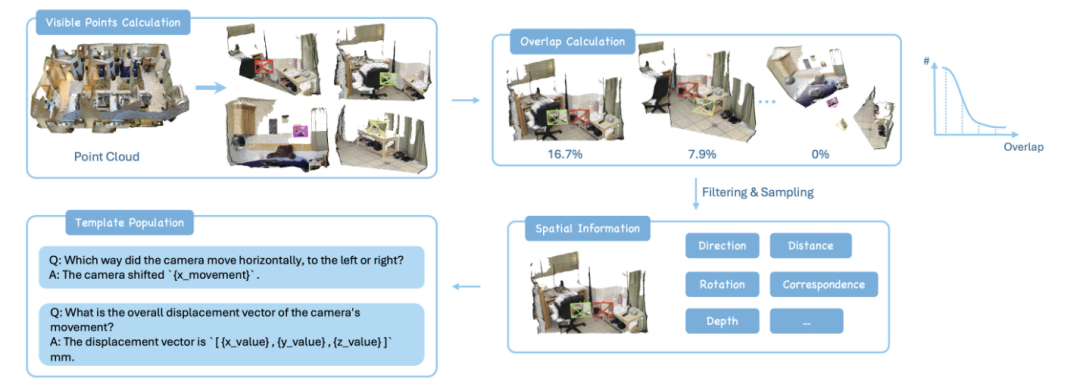
相机运动感知任务设计了从粗粒度到细粒度的九种不同难度级别,从简单的方向判断到复杂的位移向量预测。物体运动感知任务则要求AI跟踪特定物体在不同帧间的运动轨迹。最具挑战性的物体尺寸感知任务需要AI整合多张图像的信息来推断物体的真实尺寸。
数据生成过程充分利用了真实世界的3D场景数据,包括室内场景数据集ScanNet和动态场景数据集ADT、Panoptic Studio等。通过精密的3D-2D投影算法,研究团队确保生成的训练数据符合真实的几何约束。他们还设计了巧妙的图像对选择策略,选择重叠度在6%到35%之间的图像对进行训练,既保证了足够的空间关联性,又维持了视角的多样性。

精妙的技术架构
Multi-SpatialMLLM基于InternVL2-8B模型构建,这个选择经过了仔细考量。相比其他流行的多模态模型,InternVL2在遵从指令方面表现更为出色,为后续的空间理解训练奠定了良好基础。
训练策略采用了高效的LoRA(Low-Rank Adaptation)微调方法,只更新语言模型骨干网络的参数,而保持图像编码器和投影层冻结。这种设计既减少了训练成本,又避免了灾难性遗忘问题,确保模型在获得空间理解能力的同时保持原有的通用视觉理解能力。
数据格式遵循标准的多模态大语言模型训练范式,采用问答对的形式。为了处理多样化的输出格式,团队设计了统一的答案提取机制,支持从定性描述到精确坐标的各种回答类型。像素坐标的归一化处理解决了不同分辨率图像的兼容性问题,确保模型能够处理各种尺寸的输入图像。
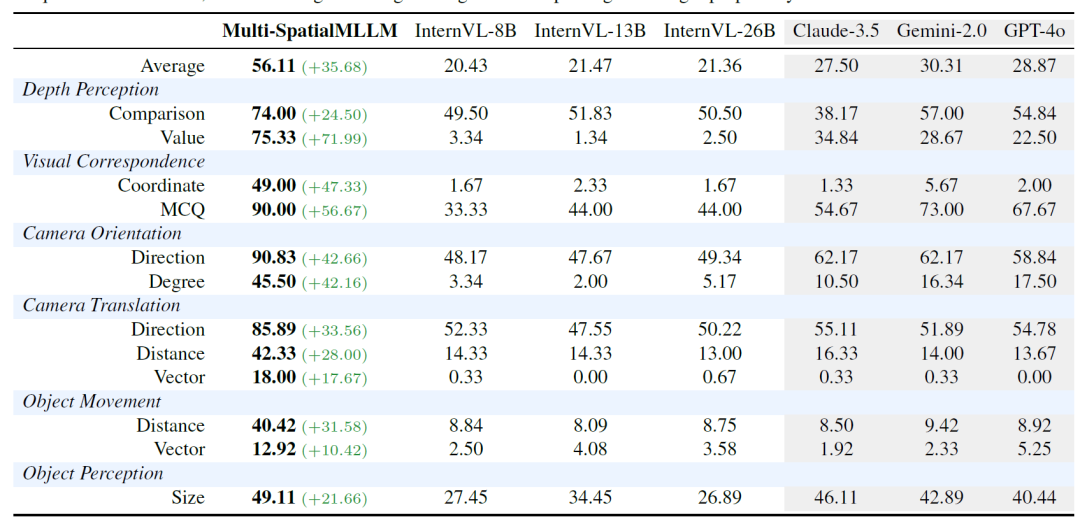
Multi-SpatialMLLM在MultiSPA基准测试中展现出了令人瞩目的性能提升。相比基础模型,该系统在所有空间理解任务上都实现了显著改进,平均准确率提升了36%。在相对简单的定性任务上,模型达到了80-90%的准确率,而基础模型仅能达到50%左右。
更为重要的是,在极具挑战性的相机运动向量预测任务上,Multi-SpatialMLLM达到了18%的准确率,而其他基线模型的表现几乎为零。这种定量的空间推理能力对于实际应用具有重要意义,为机器人导航、自动驾驶等应用提供了技术基础。
为了验证模型的泛化能力,研究团队在外部基准BLINK上进行了零样本评估。结果显示,Multi-SpatialMLLM在从未见过的数据上仍然保持了优异性能,平均准确率比基础模型提升26.4%,甚至超越了GPT-4o、Claude-3.5等大型商业模型。这表明模型学到的空间理解能力具有良好的可迁移性。
同时,在标准的视觉问答基准测试中,Multi-SpatialMLLM保持了与原始模型相当的性能,证明专业化训练并没有损害模型的通用能力。这种平衡对于实际部署至关重要,用户既需要专业的空间理解能力,也需要保持AI助手的全面性。

可扩展性与顿悟现象
研究团队通过系统性实验验证了Multi-SpatialMLLM的可扩展性。随着训练数据从50万样本增加到250万样本,26B参数模型在相机运动向量预测任务上的准确率从0.67%大幅提升至44%。这种线性的性能提升表明,更大规模的数据训练有望带来进一步的性能改进。

更有趣的是,研究发现了类似大语言模型的顿悟现象。在多选视觉对应任务中,只有26B参数的大型模型能够有效学习困难样本,而8B和13B的模型即使在困难样本上训练也无法获得提升。这种现象表明,某些高级的空间推理能力可能需要足够大的模型容量才能顿悟。
多任务学习的协同效应也得到了验证。当将相机运动任务与其他任务的数据混合训练时,模型在相机运动预测上的表现从9.3%提升到18%。类似地,物体运动预测任务在加入其他任务数据后,准确率从17.5%提升到22.04%。这种跨任务的正向迁移表明,不同类型的空间理解能力之间存在内在联系,多样化的训练任务能够相互促进。

真实世界应用验证
研究团队通过实际的机器人场景验证了Multi-SpatialMLLM的实用性。

在一个涉及机械臂堆叠积木的任务中,当被问及静态蓝色积木的移动情况时,GPT-4o和基础模型都给出了错误答案,而Multi-SpatialMLLM准确识别出积木并未移动。这种准确的空间感知能力对于机器人的安全操作至关重要。
Multi-SpatialMLLM的成功不仅仅是一个技术指标的提升,更代表了AI理解世界方式的根本性变革。Multi-SpatialMLLM通过多帧协同分析,实现了从"看图识物"到"立体思维"的跨越。这种技术突破的意义在于,它首次让AI具备了类似人类的空间认知能力。人类的视觉系统天然具备整合多视角信息的能力,这种能力是我们在3D世界中导航和操作的基础。
Multi-SpatialMLLM通过技术手段复现了这种能力,为AI在现实世界的广泛应用铺平了道路。在自动驾驶领域,这种多帧空间理解能力对于环境感知和路径规划具有重要价值。传统的自动驾驶系统主要依赖激光雷达等专用传感器获取3D信息,而Multi-SpatialMLLM展示了仅通过摄像头就能实现复杂空间理解的可能性,有望降低自动驾驶系统的成本和复杂度。
在增强现实和虚拟现实应用中,精确的空间理解能力是实现自然交互的关键。Multi-SpatialMLLM能够帮助AR系统更准确地在现实场景中放置虚拟物体,为VR系统提供更真实的空间感知。
医疗影像领域也是一个重要的应用方向。Multi-SpatialMLLM的多视角整合能力可以帮助医生从多个2D影像重建3D解剖结构,为手术规划和导航提供更精确的空间信息。

更多专栏请看:
-
LLM背后的基础模型
-
如何优雅的谈论大模型
-
体系化的通识大模型




)













)
