之前我们讨论了如何实现 Transformer 的核心多头注意力机制,那么这期我们来完整地实现整个 Transformer 的编码器和解码器。
Transformer 架构最初由 Vaswani 等人在 2017 年的论文《Attention Is All You Need》中提出,专为序列到序列(seq2seq)的机器翻译任务设计。其核心创新在于完全摒弃了传统的循环神经网络(RNN)和卷积神经网络(CNN)结构,仅依赖自注意力机制来捕捉输入和输出序列之间的长距离依赖关系。原始 Transformer 采用了编码器 - 解码器(Encoder - Decoder)架构,这种架构在后续的自然语言处理研究中被广泛应用和扩展。
编码器的作用是将源语言中的句子作为输入,并生成基于注意力的表示。这种表示能够有效地捕捉输入序列中各个元素之间的关系。经过后续的发展,研究者们发现可以根据具体任务的需求,对 Transformer 架构进行简化和调整,从而出现了仅编码器(Encoder - only)和仅解码器(Decoder - only)的 Transformer 模型。例如,BERT(Bidirectional Encoder Representations from Transformers)是仅编码器架构的典型代表,主要用于语言理解任务;而 GPT(Generative Pre - trained Transformer)则是仅解码器架构的代表,主要用于文本生成任务。
我们在这里先手动实现一个编码器块(encoder block)。
在神经网络中,"块"(Block)和 "层"(Layer)都是常用的概念。"层"(Layer)是神经网络的基本计算单元,如全连接层、卷积层、注意力层等,它们执行特定的数学运算,对输入数据进行变换。而 "块"(Block)通常指模块化设计的子网络结构,由多个层(Layer)或操作组合而成,用于实现特定的功能。块的核心思想是复用性和可扩展性 —— 通过重复堆叠相同的块来构建复杂的模型,同时简化代码和优化过程。这种设计模式使得网络结构更加清晰,便于理解和维护,同时也提高了模型的灵活性和可扩展性。通过将多个编码器块和 / 或解码器块按照特定的方式组合起来,就可以构建出完整的 Transformer 模型,以适应不同的自然语言处理任务。
class EncoderBlock(nn.Module):def __init__(self, input_dim, num_heads, dim_feedforward, dropout=0.0):"""EncoderBlock.Args:input_dim: Dimensionality of the inputnum_heads: Number of heads to use in the attention blockdim_feedforward: Dimensionality of the hidden layer in the MLPdropout: Dropout probability to use in the dropout layers"""super().__init__()# Attention layerself.self_attn = MultiheadAttention(input_dim, input_dim, num_heads)# Two-layer MLPself.linear_net = nn.Sequential(nn.Linear(input_dim, dim_feedforward),nn.Dropout(dropout),nn.ReLU(inplace=True),nn.Linear(dim_feedforward, input_dim),)# Layers to apply in between the main layersself.norm1 = nn.LayerNorm(input_dim)self.norm2 = nn.LayerNorm(input_dim)self.dropout = nn.Dropout(dropout)def forward(self, x, mask=None):# Attention partattn_out = self.self_attn(x, mask=mask)x = x + self.dropout(attn_out)x = self.norm1(x)# MLP partlinear_out = self.linear_net(x)x = x + self.dropout(linear_out)x = self.norm2(x)return x首先依旧是实现一个编码器块的类并初始化,在上期中我们编写了一个多头注意力的类MultiheadAttention,用来实现多头注意力机制。这里我们使用
self.self_attn = MultiheadAttention(input_dim, input_dim, num_heads)来创建该类的一个实例,并将其赋值给self.self_attn以成为当前类的一个属性。
然后我们定义一个前馈神经网络(指数据单向流动),使用两层的MLP,分别包含两个线性层、drop out层以及激活函数ReLU。(这些是神经网络常用结构,简单来说drop out层防止过拟合,激活函数增加非线性)。
再定义一下每层的归一化(nn.LayerNorm(input_dim)),以稳定训练过程
最后把上面定义好的内容串起来,实现编码块的前向传播部分:
1、首先使用多头注意力对输入x计算
2、实现残差连接和drop out(可以解决梯度消失、爆炸的问题,稳定训练),然后进行第一次层归一化
3、经过我们上面定义的线性层,然后再次残差连接
4、第二次层归一化,并得到最终输出
然后我们基于上面的编码器块来实现完整的transformer编码器(可以理解为上面添了一块砖,下面是我们用砖堆叠形成需要的房子)
class TransformerEncoder(nn.Module):def __init__(self, num_layers, **block_args):super().__init__()self.layers = nn.ModuleList([EncoderBlock(**block_args) for _ in range(num_layers)])def forward(self, x, mask=None):for layer in self.layers:x = layer(x, mask=mask)return x上述代码中的关键代码
self.layers = nn.ModuleList([EncoderBlock(**block_args) for _ in range(num_layers)])顾名思义就是是通过for循环重复创建神经网络的层,层数为指定的num_layers的值,这里的block_args是在实例化TransformerEncoder时收集额外参数打包成字典,然后在创建EncoderBlock时解包并作为参数传入。
然后再来实现一个前面讲解过的位置编码
class PositionalEncoding(nn.Module):def __init__(self, d_model, max_len=5000):"""Positional Encoding.Args:d_model: Hidden dimensionality of the input.max_len: Maximum length of a sequence to expect."""super().__init__()# Create matrix of [SeqLen, HiddenDim] representing the positional encoding for max_len inputspe = torch.zeros(max_len, d_model)position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))pe[:, 0::2] = torch.sin(position * div_term)pe[:, 1::2] = torch.cos(position * div_term)pe = pe.unsqueeze(0)# register_buffer => Tensor which is not a parameter, but should be part of the modules state.# Used for tensors that need to be on the same device as the module.# persistent=False tells PyTorch to not add the buffer to the state dict (e.g. when we save the model)self.register_buffer("pe", pe, persistent=False)def forward(self, x):x = x + self.pe[:, : x.size(1)]return x接下来,我们再来实现一个优化器(optimizer)和学习率调度器(lr scheduler),这些可以说是神经网络必备的组件,并且和其他超参数一样大多是工程实践的结果,相信大家多多少少叶听过,在此就不再赘述了,感兴趣的同学可以自行查阅我之前的博客,里面提及了不同optimizer和lr scheduler之间的优劣。
class CosineWarmupScheduler(optim.lr_scheduler._LRScheduler):def __init__(self, optimizer, warmup, max_iters):self.warmup = warmupself.max_num_iters = max_iterssuper().__init__(optimizer)def get_lr(self):lr_factor = self.get_lr_factor(epoch=self.last_epoch)return [base_lr * lr_factor for base_lr in self.base_lrs]def get_lr_factor(self, epoch):lr_factor = 0.5 * (1 + np.cos(np.pi * epoch / self.max_num_iters))if epoch <= self.warmup:lr_factor *= epoch * 1.0 / self.warmupreturn lr_factor到此,我们造车所需的全部零件就都设计好了,接下来我们使用pytorch_lighting框架把这些零件全部组装起来,让车真正开始上路。
这里我提一嘴,PyTorch Lightning(PL)是基于 PyTorch 的开源深度学习框架,旨在简化复杂模型的训练流程,同时保留 PyTorch 的灵活性与原生功能。其核心价值是PL 通过模块化设计和自动化机制,将深度学习开发流程标准化为以下核心组件:
- 模型定义:仅需关注神经网络结构(如 Transformer 的编码器 - 解码器)和损失函数,无需重复编写训练循环代码。
- 训练逻辑:自动管理训练、验证、测试阶段的流程,支持分布式训练、混合精度计算等高级功能。
- 日志与回调:内置对 TensorBoard、W&B 等日志工具的支持,可自动记录指标、保存检查点。

与 PyTorch 的关系
- 非侵入性:PL 不改变 PyTorch 的底层逻辑,模型仍以原生 PyTorch 张量(Tensor)和模块(Module)为基础。
- 流程抽象:将数据加载、优化器设置、反向传播等重复性代码封装为框架逻辑,开发者仅需实现核心业务逻辑(如多头注意力机制、位置编码)。
典型应用场景
在构建 Transformer 等复杂模型时,PL 可大幅减少样板代码。例如:
- 定义模型时,只需编写编码器和解码器的前向传播逻辑;
- 训练时,PL 自动处理批次迭代、梯度更新、验证集评估等流程;
- 支持快速扩展功能(如模型量化、onnx 导出),无需修改核心代码。
PL 如何简化 Transformer 实现呢? 首先训练流程抽象,就是PL 的 Trainer 自动管理 epoch 循环、梯度更新、设备同步等底层逻辑。然后对超参数管理,通过 self.hparams 统一访问参数,支持命令行或配置文件动态调整(如 Hydra)。当然代码复用性也是必不可少的,自定义模块(如 PositionalEncoding)与 PL 组件解耦,便于单独测试或替换。以下是对代码结构与逻辑的详细解析,以技术视角逐层拆解实现细节:
1. 整体架构:基于 PyTorch Lightning 的模块化设计
TransformerPredictor 类继承自 pl.LightningModule,核心目标是构建一个基于 Transformer 的序列预测模型。其核心优势在于:
训练流程自动化:通过 PL 的 Trainer 类自动管理多 epoch 训练,无需手动编写循环。
超参数集成:通过 self.save_hyperparameters() 自动管理超参数,支持与 Hydra 等工具集成,实现配置文件驱动的参数管理。
2. 初始化与超参数
def __init__(self,input_dim,model_dim,num_classes,num_heads,num_layers,lr,warmup,max_iters,dropout=0.0,input_dropout=0.0,
):super().__init__()self.save_hyperparameters() # 自动保存超参数到self.hparamsself._create_model()关键参数:
input_dim:输入特征维度(如文本嵌入维度)。
model_dim:Transformer 内部特征维度(需与多头注意力头数匹配,即 model_dim % num_heads == 0)。
num_layers:Transformer 编码器层数,每层包含多头注意力和前馈网络。
warmup/max_iters:学习率调度器参数,控制训练初期的学习率升温与余弦衰减。
3. 模型构建:从输入到输出的流水线
3.1 输入预处理模块
self.input_net = nn.Sequential(nn.Dropout(self.hparams.input_dropout), nn.Linear(self.hparams.input_dim, self.hparams.model_dim)
)
功能:将输入特征(如词嵌入)从 input_dim 投影到 model_dim,并添加 Dropout 抑制过拟合。
3.2 位置编码模块
self.positional_encoding = PositionalEncoding(d_model=self.hparams.model_dim)
作用:为序列添加位置信息(因 Transformer 无循环结构,需显式编码顺序)。
实现:通过正弦 / 余弦函数生成固定位置编码,与输入特征相加后输入编码器。
3.3 Transformer 编码器模块
self.transformer = TransformerEncoder(num_layers=self.hparams.num_layers,input_dim=self.hparams.model_dim,dim_feedforward=2 * self.hparams.model_dim,num_heads=self.hparams.num_heads,dropout=self.hparams.dropout,
)
核心组件:多层 EncoderBlock:每层包含 多头注意力层 和 前馈神经网络,通过残差连接与层归一化(LayerNorm)稳定训练。
多头注意力:将输入拆分为多个头(num_heads),每个头独立计算注意力,捕捉不同语义特征(如语法、上下文),最终拼接输出。
前馈网络:对注意力输出进行非线性变换,增强特征表达能力。
3.4 输出分类模块
self.output_net = nn.Sequential(nn.Linear(model_dim, model_dim),nn.LayerNorm(model_dim),nn.ReLU(),nn.Dropout(dropout),nn.Linear(model_dim, num_classes),
)
功能:将 Transformer 输出的特征(model_dim)投影到任务目标维度(num_classes),用于序列标注或分类。
结构:通过两层线性变换 + 非线性激活,引入层归一化和 Dropout 提升泛化能力。
4. 前向传播:数据流动的核心逻辑
def forward(self, x, mask=None, add_positional_encoding=True):x = self.input_net(x) # 输入投影if add_positional_encoding:x = self.positional_encoding(x) # 添加位置编码x = self.transformer(x, mask=mask) # Transformer编码x = self.output_net(x) # 输出分类return x输入形状:x 为 [Batch, SeqLen, input_dim],经投影后变为 [Batch, SeqLen, model_dim]。
位置编码:通过 add_positional_encoding 参数控制是否启用(适用于无需位置信息的特殊任务)。
掩码机制:mask 用于屏蔽无效位置(如填充符),避免注意力计算时引入噪声。
5. 训练相关组件:优化器与调度器
5.1 优化器配置
def configure_optimizers(self):optimizer = optim.Adam(self.parameters(), lr=self.hparams.lr)self.lr_scheduler = CosineWarmupScheduler(optimizer, warmup=self.hparams.warmup, max_iters=self.hparams.max_iters)return optimizer优化器:使用 Adam 优化器,参数包含模型所有可学习权重(如线性层、位置编码中的可学习参数)。
学习率调度器:Warmup 阶段:训练初期逐步提升学习率,避免模型在随机初始化阶段过拟合。Cosine 衰减阶段:学习率随迭代次数呈余弦曲线下降,促进模型收敛到更优解。
5.2 分步执行逻辑
def optimizer_step(self, *args, **kwargs):super().optimizer_step(*args, **kwargs)self.lr_scheduler.step() # 每步迭代更新学习率
关键点:PL 默认学习率调度器按 epoch 更新,此处强制按迭代更新(step() 在 optimizer_step 中调用),适配复杂训练场景。
我们简单梳理一下上述代码的结构,里面调用了三个我们之前创建的类,分别是:
PositionalEncoding :位置编码类
TransformerEncoder :Transformer编码器类
CosineWarmupScheduler :学习率调度器类
而Transformer编码器类是靠循环创建我们定义好的编码器块类(EncoderBlock)实现的。
EncoderBlock类则通过调用我们先前写好的多头注意力机制计算以及设计网络连接方式来实现的。
而对多头注意力机制的核心计算方式的实现就又回到了我们一开始中的函数把QKV按照不同的方式做点积。
也就是说我们之前设计的所有结构就都汇总到了最后这段代码里,并通过PyTorch Lightning实现了训练流程的自动化。
上面的代码就是我们造好的transformer车辆的完整形态,下一期我们将尝试驾驶这辆车开在我们的数据公路上。
Transformer模型测试
在本节内容中,我们将对之前实现的 Transformer 模型进行测试,以验证其性能。我们创建了一个简单的数据集,其中输入是介于 0 和 M 之间的数字序列 N,任务是将输入序列反转,即输出为 x [::-1]。选择这个任务是因为它需要模型捕捉长期依赖关系,而这正是 Transformer 架构的优势所在。相比之下,传统的循环神经网络(RNN)在处理此类任务时可能会遇到困难,因为它们在处理长序列时会面临梯度消失或爆炸的问题。通过这个简单的任务,我们可以直观地比较 Transformer 与传统模型的性能差异。接下来,我们将使用 PyTorch Lightning 搭建的训练流程在这个数据集上进行实验,观察 Transformer 模型的表现。
class ReverseDataset(data.Dataset):def __init__(self, num_categories, seq_len, size):super().__init__()self.num_categories = num_categoriesself.seq_len = seq_lenself.size = sizeself.data = torch.randint(self.num_categories, size=(self.size, self.seq_len))def __len__(self):return self.sizedef __getitem__(self, idx):inp_data = self.data[idx]labels = torch.flip(inp_data, dims=(0,))return inp_data, labels接下来,我们创建任意数量的介于 0 到 num_categories-1,代码中的示例是10, 之间的随机数字序列。标签只是将张量沿序列维度翻转。我们可以在下面创建相应的数据加载器。
dataset = partial(ReverseDataset, 10, 16)
train_loader = data.DataLoader(dataset(50000), batch_size=128, shuffle=True, drop_last=True, pin_memory=True)
val_loader = data.DataLoader(dataset(1000), batch_size=128)
test_loader = data.DataLoader(dataset(10000), batch_size=128)我们需要使用 Python 的 functools.partial 对自定义数据集类 ReverseDataset 进行参数预绑定,核心目标是固定部分参数并保留灵活性。首先明确 ReverseDataset 的功能:生成由数字组成的序列样本,每个样本包含 16 个数字(范围 0-9),输出为该序列的逆序。例如输入 [1,2,3,4,5] 对应输出 [5,4,3,2,1],每个样本的数字范围和样本内数字数量(16 个)是固定的,而数据集的样本总数(如训练集 50000 条)通过 size 参数动态指定。
使用 functools.partial 时,先将 ReverseDataset 的参数 num_samples(样本内数字数量)固定为 16,digit_range(数字范围)固定为 (0,10)(即 0-9),这两个参数对所有数据集实例是统一的。剩下的 size 参数(数据集样本总数)不预先绑定,而是留给不同数据集(如训练集、验证集)自行指定。例如创建训练集时,通过partial(ReverseDataset, num_samples=16, digit_range=(0,10))(size=50000)生成 50000 条样本,每个样本是 16 个 0-9 的数字,输出为逆序序列。这种方式通过参数预绑定减少重复设置,同时保留 size 的灵活性,使数据集构建更简洁且符合任务需求。
inp_data, labels = train_loader.dataset[0]
print("Input data:", inp_data)
print("Labels: ", labels)
导入所有必要的库
import math
import os
import urllib.request
from functools import partial
from urllib.error import HTTPError
# Plotting
import matplotlib
import matplotlib.pyplot as plt
import matplotlib_inline.backend_inline
import numpy as np
# PyTorch Lightning
import pytorch_lightning as pl
import seaborn as sns
# PyTorch
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torch.utils.data as data
# Torchvision
import torchvision
from pytorch_lightning.callbacks import ModelCheckpoint
from torchvision import transformsfrom tqdm.notebook import tqdm
# Setting the seed
pl.seed_everything(42)新建保存模型的文件夹
DATASET_PATH = os.environ.get("PATH_DATASETS", "data/")
# Path to the folder where the pretrained models are saved
CHECKPOINT_PATH = os.environ.get("PATH_CHECKPOINT", "saved_models/Transformers/")
os.makedirs(CHECKPOINT_PATH, exist_ok=True)这里提供两种选项,我们如果想自己从头训练一个模型,则无需下面的代码(纯CPU训练1分钟左右)。如果想直接加载已经训练好的预训练模型,则添加以下代码下载。
# Github URL where saved models are stored for this tutorial
base_url = "fill in yours"
# Files to download
pretrained_files = ["ReverseTask.ckpt", "SetAnomalyTask.ckpt"]# Create checkpoint path if it doesn't exist yet
os.makedirs(CHECKPOINT_PATH, exist_ok=True)# For each file, check whether it already exists. If not, try downloading it.
for file_name in pretrained_files:file_path = os.path.join(CHECKPOINT_PATH, file_name)if "/" in file_name:os.makedirs(file_path.rsplit("/", 1)[0], exist_ok=True)if not os.path.isfile(file_path):file_url = base_url + file_nameprint(f"Downloading {file_url}...")try:urllib.request.urlretrieve(file_url, file_path)except HTTPError as e:print("Something went wrong. Please try to download the file manually,"" or contact the author with the full output including the following error:\n",e,)继承并重写一下transformer,因为我们的目标是基于 Transformer 架构实现序列反转任务,核心在于通过模型学习输入数字序列与反转后的目标序列之间的映射关系。由于序列中的每个数字代表独立的类别(如数字 1 和 3 是完全不同的类别,而非数值大小或数量的线性关系),因此采用 one-hot 编码对输入序列进行离散化处理至关重要。这是因为若直接使用数值编码(如整数嵌入),模型可能会错误捕捉数字间的线性关联(例如认为 3 比 1 “大” 或存在倍数关系),而实际上我们需要模型将每个数字视为独立的离散符号,仅关注其位置和类别信息。
在模型设计上,继承 PyTorch Lightning 的 LightningModule 类并重写 Transformer 结构,使其适配序列反转任务。核心修改在于通过_calculate_loss方法统一处理三种模式(训练、验证、测试)的损失计算与指标记录。具体而言,该方法接收模型输出、真实标签和模式标识,使用交叉熵损失函数计算损失(因 one-hot 编码的标签本质是多分类问题),并通过 PyTorch Lightning 内置的self.log方法自动记录各模式下的损失值及其他指标(如准确率)。这种设计确保了训练流程的标准化,同时利用框架特性实现指标的实时监控与日志管理。模型的输入层将 one-hot 编码的序列映射到高维嵌入空间,结合位置编码捕捉顺序信息(因 Transformer 本身不具备序列顺序感知能力)。编码器和解码器均采用多头注意力机制与前馈神经网络的组合,通过层归一化和残差连接提升训练稳定性。最终输出层通过线性变换将解码器输出映射回 one-hot 空间,生成反转后的序列预测。通过统一的损失计算模块,模型在不同训练阶段(训练 / 验证 / 测试)均可保持一致的指标计算逻辑,确保评估结果的可靠性与可比性,同时利用框架的日志系统简化实验跟踪流程。
class ReversePredictor(TransformerPredictor):def _calculate_loss(self, batch, mode="train"):# Fetch data and transform categories to one-hot vectorsinp_data, labels = batchinp_data = F.one_hot(inp_data, num_classes=self.hparams.num_classes).float()# Perform prediction and calculate loss and accuracypreds = self.forward(inp_data, add_positional_encoding=True)loss = F.cross_entropy(preds.view(-1, preds.size(-1)), labels.view(-1))acc = (preds.argmax(dim=-1) == labels).float().mean()# Loggingself.log(f"{mode}_loss", loss)self.log(f"{mode}_acc", acc)return loss, accdef training_step(self, batch, batch_idx):loss, _ = self._calculate_loss(batch, mode="train")return lossdef validation_step(self, batch, batch_idx):_ = self._calculate_loss(batch, mode="val")def test_step(self, batch, batch_idx):_ = self._calculate_loss(batch, mode="test")再组织一下训练环境,设备检测、模型检测等。若未检测到模型则自动重新训练,若已有模型存在则自动加载
def train_reverse(**kwargs):# Create a PyTorch Lightning trainer with the generation callbackroot_dir = os.path.join(CHECKPOINT_PATH, "ReverseTask")os.makedirs(root_dir, exist_ok=True)trainer = pl.Trainer(default_root_dir=root_dir,callbacks=[ModelCheckpoint(save_weights_only=True, mode="max", monitor="val_acc")],accelerator="auto",devices=1,max_epochs=10,gradient_clip_val=5,)trainer.logger._default_hp_metric = None # Optional logging argument that we don't need# Check whether pretrained model exists. If yes, load it and skip trainingpretrained_filename = os.path.join(CHECKPOINT_PATH, "ReverseTask.ckpt")if os.path.isfile(pretrained_filename):print("Found pretrained model, loading...")model = ReversePredictor.load_from_checkpoint(pretrained_filename)else:model = ReversePredictor(max_iters=trainer.max_epochs * len(train_loader), **kwargs)trainer.fit(model, train_loader, val_loader)# Test best model on validation and test setval_result = trainer.test(model, dataloaders=val_loader, verbose=False)test_result = trainer.test(model, dataloaders=test_loader, verbose=False)result = {"test_acc": test_result[0]["test_acc"], "val_acc": val_result[0]["test_acc"]}model = model.to(device)return model, result开始训练模型(给定超参数)
reverse_model, reverse_result = train_reverse(input_dim=train_loader.dataset.num_categories,model_dim=32,num_heads=1,num_classes=train_loader.dataset.num_categories,num_layers=1,dropout=0.0,lr=5e-4,warmup=50,
)开始训练-训练完成,我们再来看看其准确度
print("Val accuracy: %4.2f%%" % (100.0 * reverse_result["val_acc"]))
print("Test accuracy: %4.2f%%" % (100.0 * reverse_result["test_acc"]))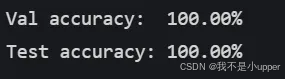
可以看出输出的结果非常完美
在本系列对 Transformer 的探索中,我们完整拆解了其核心构成。多头注意力机制作为 Transformer 的基石,通过查询向量、键向量与值向量的缩放点积运算,实现了对输入序列元素间相关性的精准捕捉。具体而言,该机制将输入特征分别投影为多个子查询、子键和子值,通过并行计算不同头的注意力分布,使模型能够从多个独立视角提取序列的语义、结构等特征,最终将各头结果拼接融合,显著增强了特征表达的丰富性。
Transformer 架构以多头注意力层为核心,通过叠加类似 ResNet 的残差连接与层归一化模块,构建起深度网络以建模复杂模式。这一架构的强大之处不仅在于其对自然语言处理任务的革新,更体现在跨领域的泛化能力 —— 从文本翻译、图像生成到音频处理等序列或非序列任务,均能通过适配输入形式发挥作用。值得关注的是,Transformer 本身对输入序列的排列顺序不敏感(置换等变性),这一特性使其能灵活处理无序数据,但也需通过位置编码显式引入序列顺序信息,以弥补对时序关系建模的缺失。
在工程实现中,除了理解架构原理,还需关注训练细节。例如学习率预热策略,可通过在初始迭代阶段逐步提升学习率,避免因参数随机初始化导致的梯度波动,确保模型稳定收敛。通过本系列的实践,我们不仅复现了 Transformer 的核心思想,更深入理解了其适应多样化数据与任务的内在逻辑。






!)



微服务(垂直AP/分布式缓存/装饰器Pattern))
)






)
