1、Pytorch介绍
PyTorch 是由 Facebook AI Research (FAIR) 团队开发并维护的一款开源深度学习框架,于 2016 年首次发布。它因其直观的设计、卓越的灵活性以及强大的动态计算图功能,迅速在学术界和工业界获得了广泛认可,成为当前深度学习研究和开发的主流工具之一。
1.1、核心理念
PyTorch 最显著的特点是其 “Pythonic” 的设计哲学和 动态计算图 (Dynamic Computational Graph) 机制。
-
Pythonic 设计: PyTorch 深度融入 Python 生态系统,其 API 设计自然、简洁,非常符合 Python 程序员的思维习惯。你可以像操作普通的 Python 对象(如 NumPy 数组)一样操作张量(Tensor),使用标准的 Python 控制流(如
if,for,while)来构建模型结构。这种无缝集成极大地降低了学习门槛,让开发者能够专注于模型设计和算法本身,而非框架的复杂性。 -
动态计算图 (Define-by-Run): 这是 PyTorch 区别于早期静态图框架(如 TensorFlow 1.x)的关键。计算图在代码运行时动态构建。每一步张量操作都会实时扩展计算图,并立即执行。这种机制带来了革命性的优势:
-
直观的调试: 由于图是动态生成的,你可以像调试普通 Python 程序一样,使用
print语句、IDE 的断点调试器逐行检查张量的值和模型的行为,极大简化了复杂模型和训练过程的调试。 -
无与伦比的灵活性: 动态图允许模型结构在运行时根据数据或条件动态改变(如 RNN 中可变长度序列处理、树状结构网络、条件计算)。这种灵活性对于前沿研究(如元学习、神经架构搜索)和构建复杂模型至关重要。
-
更易理解的代码: 模型定义和训练循环的代码流程清晰、线性,更易于阅读和理解。
-
1.2、核心组件与功能
PyTorch 提供了一套完整的工具链来支持深度学习工作流:
-
强大的张量库:
torch.Tensor是其核心数据结构,支持高效的 CPU 和 GPU 加速计算。它提供了丰富的数学运算(线性代数、随机数生成等),并高度兼容 NumPy(通过.numpy()和torch.from_numpy()轻松转换)。 -
自动微分引擎 (Autograd):
torch.autograd模块是 PyTorch 的基石。它通过在动态计算图上自动追踪张量操作,实现反向传播时梯度的自动计算。只需在张量上设置.requires_grad=True,框架就会记录所有相关操作,并在调用.backward()时自动计算梯度。这极大地简化了梯度计算,让开发者无需手动推导和实现复杂的反向传播。 -
神经网络模块 (torch.nn): 该模块提供了构建神经网络所需的所有基础构件:
-
层 (Layers): 预定义了各种层(如 Linear, Conv2d, RNN, LSTM, Transformer, Dropout, BatchNorm 等)。
-
损失函数 (Loss Functions): 如 MSE, CrossEntropyLoss 等。
-
优化器 (Optimizers): 如 SGD, Adam, RMSprop 等,用于更新模型参数以最小化损失。
-
容器 (Containers):
nn.Module是构建所有模型的基类。通过继承它并定义forward方法,可以轻松组合各种层来创建复杂的网络结构。nn.Module还自动管理参数、设备移动(CPU/GPU)、序列化等。
-
-
数据加载与处理 (torch.utils.data):
-
Dataset 类: 定义如何访问单个样本。
-
DataLoader: 负责高效地批量加载数据、打乱顺序、多进程预读取等,是训练循环中数据供给的核心。
-
Transforms: 提供丰富的图像和数据处理工具(如裁剪、旋转、归一化),用于数据增强和预处理。
-
-
GPU 加速: PyTorch 天然支持 CUDA。只需将张量或模型移动到 GPU 设备(
.to(‘cuda’)),即可利用 NVIDIA GPU 强大的并行计算能力,显著加速模型训练和推理。 -
分布式训练:
torch.distributed模块提供了强大的工具(如 DistributedDataParallel - DDP),支持在多 GPU、多节点集群上进行高效的数据并行和模型并行训练,极大缩短大型模型的训练时间。 -
TorchScript 和 TorchDynamo (PyTorch 2.x): 为了满足生产环境对性能、部署和脱离 Python 环境运行的需求,PyTorch 提供了:
-
TorchScript: 一种将 PyTorch 模型(代码)转换为可优化、可序列化的中间表示的方法,可以在 C++ 等环境中高效运行。
-
TorchDynamo (PyTorch 2.0+): 一个创新的即时(JIT)编译器框架,结合了
torch.compile()API,能够在不显著改变用户代码的情况下,自动加速模型训练和推理,性能提升显著。
-
-
丰富的生态系统:
-
领域库:
TorchVision(CV),TorchText(NLP),TorchAudio(音频) 提供了各自领域常用的数据集、模型架构和转换工具。 -
Hugging Face Transformers: PyTorch 是该流行库的首选后端,提供了大量预训练的语言模型(如 BERT, GPT)。
-
PyTorch Lightning: 一个轻量级封装库,将研究代码与工程代码解耦,简化了训练流程(如多 GPU、混合精度训练、日志记录),加速研究向生产的转化。
-
ONNX 支持: 方便模型导出到其他支持 ONNX 格式的推理引擎部署。
-
部署工具: TorchServe, LibTorch (C++ API) 等支持模型在各种环境下的部署。
-
1.3、适用场景与优势总结
-
研究与原型开发: 动态图的灵活性和易调试性使其成为学术研究和快速实验新想法的理想平台。大量前沿论文的官方实现都基于 PyTorch。
-
教学与学习: Pythonic 的设计和直观的调试使其成为学习深度学习的绝佳工具。
-
计算机视觉 (CV): 在图像分类、目标检测、分割等任务中占据主导地位。
-
自然语言处理 (NLP): 是 Transformer 等现代 NLP 模型实现和预训练模型库(如 Hugging Face)的主要支撑。
-
强化学习、生成模型等: 其灵活性同样适用于这些新兴且结构多变的领域。
-
生产部署: 随着 TorchScript、TorchDynamo (
torch.compile()) 以及部署工具链的成熟,PyTorch 在生产环境中的应用也日益广泛。
1.4、优势总结
-
易用性与灵活性: Pythonic 设计 + 动态图,开发调试效率高。
-
强大的社区与生态: 拥有庞大且活跃的开发者社区,丰富的库、模型、教程和资源。
-
卓越的研究支持: 是学术界的宠儿,最新研究成果往往首选 PyTorch 实现。
-
成熟的工业应用: 从研究到生产的路径日益顺畅,被众多科技巨头采用。
-
持续创新: 开发团队(Meta 和开源社区)积极推动,不断引入新特性(如 PyTorch 2.x 的编译加速)。
2、安装Pytorch
2.1、通过官网安装
ubuntu系统安装cuda驱动、cudatoolkit、cuDNN教程见:
1、安装cuda驱动,cuda toolkit和cuDNN-CSDN博客
查看cuda版本:
(llm) wangqiang@wangqiang:~$ nvcc -V nvcc: NVIDIA (R) Cuda compiler driver Copyright (c) 2005-2025 NVIDIA Corporation Built on Wed_Jan_15_19:20:09_PST_2025 Cuda compilation tools, release 12.8, V12.8.61 Build cuda_12.8.r12.8/compiler.35404655_0
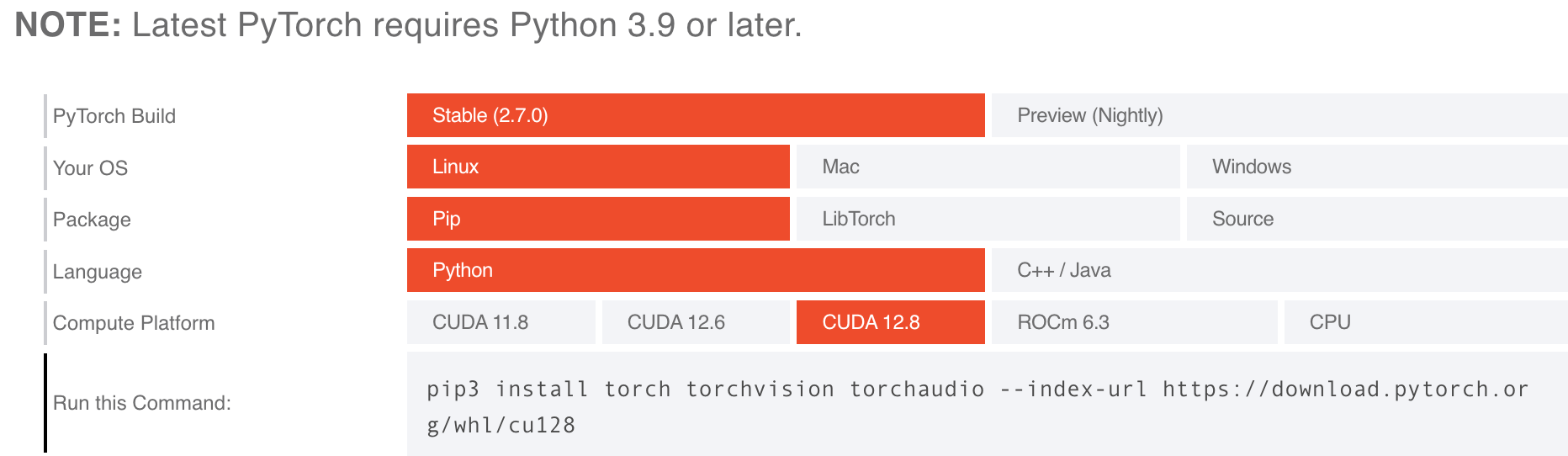
最新的pytorch只支持pip安装,去官网Get Started查看PyTorch的安装需求和安装命令。
ubuntu系统安装pytorch 12.8:
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu128
查看安装的pytorch版本:
方式1:
import torch print(torch.__version__)方式2:
终端中运行:
(llm) wangqiang@wangqiang:~$ pip show torch Name: torch Version: 2.7.0+cu128 Summary: Tensors and Dynamic neural networks in Python with strong GPU acceleration Home-page: https://pytorch.org/ Author: PyTorch Team Author-email: packages@pytorch.org License: BSD-3-Clause Location: /home/wangqiang/anaconda3/envs/llm/lib/python3.12/site-packages Requires: filelock, fsspec, jinja2, networkx, nvidia-cublas-cu12, nvidia-cuda-cupti-cu12, nvidia-cuda-nvrtc-cu12, nvidia-cuda-runtime-cu12, nvidia-cudnn-cu12, nvidia-cufft-cu12, nvidia-cufile-cu12, nvidia-curand-cu12, nvidia-cusolver-cu12, nvidia-cusparse-cu12, nvidia-cusparselt-cu12, nvidia-nccl-cu12, nvidia-nvjitlink-cu12, nvidia-nvtx-cu12, setuptools, sympy, triton, typing-extensions Required-by: torchaudio, torchvision
卸载pytorch
sudo pip uninstall torch torchvision torchaudio# 删除缓存和配置文件: rm -rf ~/.cache/torch rm -rf ~/.local/bin/torch_shm_manager
2.2、从源码安装
如果需要从源代码安装PyTorch,或者想要尝试最新的开发版本,可以使用以下命令:
git clone --recursive https://github.com/pytorch/pytorch
cd pytorch
python setup.py install2.3、通过pip安装
pip install torch torchvision torchaudio- 默认安装的是 CPU 版本(不包含 GPU 支持),除非在系统环境已经明确配置了 CUDA 并且 PyPI 源中存在对应的 GPU 版本。
- 安装的版本是 PyPI 上的最新稳定版(可能不是与电脑硬件或Python 版本完全兼容的版本)。
3、Pytorch参考链接
PyTorch 官网 :https://pytorch.org/
PyTorch 官方入门教程:Get Started
PyTorch 官方文档:PyTorch documentation — PyTorch 2.7 documentation
PyTorch 源代码:https://github.com/pytorch/pytorch
PyTorch 官方英文教程:Welcome to PyTorch Tutorials — PyTorch Tutorials 2.7.0+cu126 documentation
PyTorch 官方中文文档:主页 - PyTorch中文文档
RUNOOB PyTorch教程:PyTorch 教程 | 菜鸟教程
)







![[AI算法] LLM中的gradient checkpoint机制](http://pic.xiahunao.cn/[AI算法] LLM中的gradient checkpoint机制)







(ABC))


