目录
- 理解"文件"
- 狭义理解
- 广义理解
- 文件操作的归类认知
- 系统角度
- 文件类别
- 回顾C文件接口
- 打开文件
- 写文件
- 读文件
- 稍作修改,实现简单cat命令
- 输出信息到显示器,你有哪些方法
- stdin & stdout & stderr
- 打开文件的方式
- 系统⽂件I/O
- ⼀种传递标志位的方法
- 系统调用
- 理解文本写入和二进制写入
- FILE介绍
- open函数返回值
- 文件描述符fd
- ⽂件描述符的分配规则
- 重定向
- 使用 dup2 系统调用
- 为什么会有标准错误和标准输错呢?还指向同一个显示器(文件)?
- 理解“⼀切皆文件”
- 缓冲区
- 什么是缓冲区
- 为什么要引入缓冲区机制
- FILE
- 缓冲类型
理解"文件"
狭义理解
• ⽂件在磁盘⾥
• 磁盘是永久性存储介质,因此⽂件在磁盘上的存储是永久性的
• 磁盘是外设(即是输出设备也是输⼊设备)
• 磁盘上的⽂件 本质是对⽂件的所有操作,都是对外设的输⼊和输出简称 IO
广义理解
Linux 下⼀切皆⽂件(键盘、显⽰器、⽹卡、磁盘…… 这些都是抽象化的过程)
文件操作的归类认知
• 对于 0KB 的空⽂件是占⽤磁盘空间的
• ⽂件是⽂件属性(元数据)和⽂件内容的集合(⽂件 = 属性(元数据)+ 内容)
• 所有的⽂件操作本质是⽂件内容操作和⽂件属性操作
系统角度
• 对⽂件的操作本质是进程对⽂件的操作
• 磁盘的管理者是操作系统
• ⽂件的读写本质不是通过 C 语⾔ / C++ 的库函数来操作的(这些库函数只是为⽤⼾提供⽅便),⽽是通过⽂件相关的系统调⽤接⼝来实现的.

文件类别
"内存级(被打开)"文件
磁盘级文件
回顾C文件接口
打开文件
打开的log.txt⽂件在哪个路径下?
在程序的当前路径下,那系统怎么知道程序的当前路径在哪⾥呢?(会把当前路径和文件名进行拼接,来创建文件)
可以使⽤ ls /proc/[进程id] -l 命令查看当前正在运⾏进程的信息:

打开⽂件,本质是进程打开,所以,进程知道⾃⼰在哪⾥,即便⽂件不带路径,进程也知道。由此OS就能知道要创建的⽂件放在哪⾥。
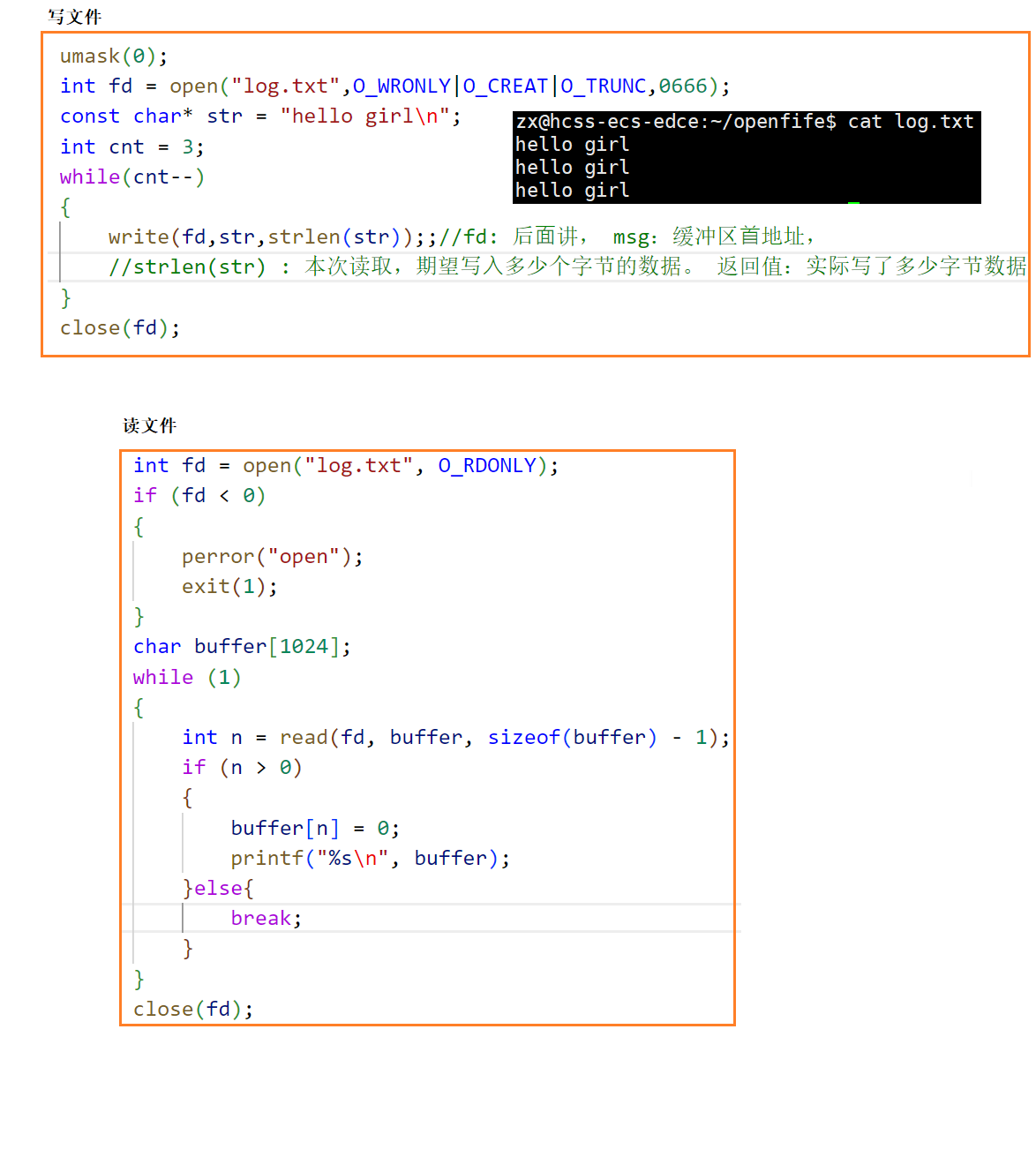
写文件


读文件

稍作修改,实现简单cat命令
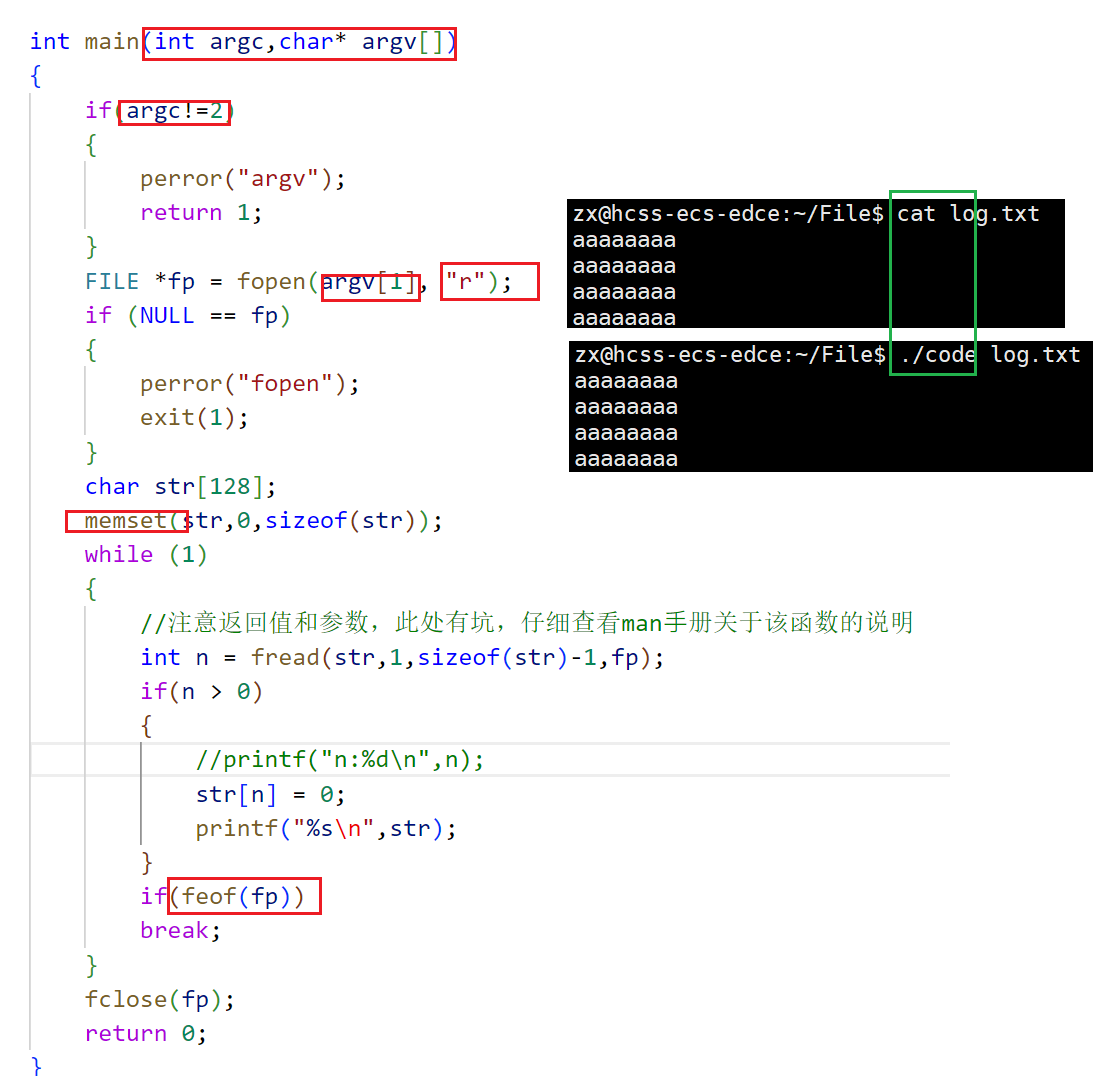
输出信息到显示器,你有哪些方法
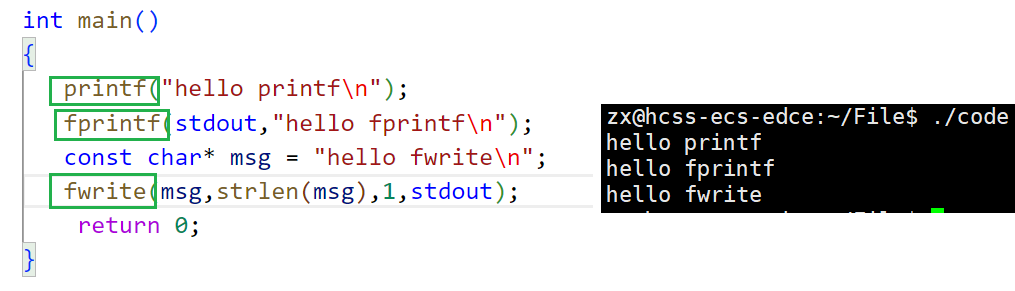
stdin & stdout & stderr
- C默认会打开三个输⼊输出流,分别是
stdin,stdout,stderr- 仔细观察发现,这三个流的类型都是FILE*, fopen返回值类型,文件指针
#include <stdio.h>
extern FILE *stdin;//标准输入 -- 键盘文件
extern FILE *stdin;//标准输出 -- 显示器文件
extern FILE *stderr;//标准错误 -- 显示器文件
程序启动时,默认会打开这三个文件(编译器做的),为什么呢?
因为我们的程序是做数据处理的,打开stdin,stdin是为了给程序提供默认的数据源和数据结果。这三个默认打开的文件,自己是可以手动关掉的。
打开文件的方式

如上,是我们之前学的⽂件相关操作。还有 fseek,ftell,rewind的函数
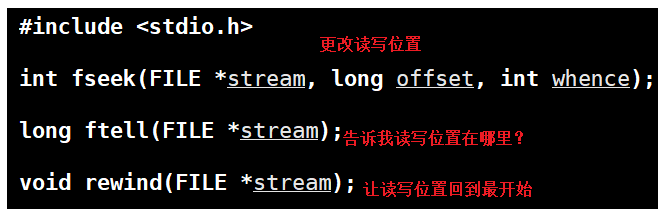
细节注意:不要把\0写入文件,它是C语言的规定,和文件没有关系,有时候会出现乱码。
系统⽂件I/O
打开⽂件的⽅式不仅仅是fopen,ifstream等流式,语⾔层的⽅案,其实系统才是打开⽂件最底层的⽅案。不过,在学习系统⽂件IO之前,先要了解下如何给函数传递标志位,该⽅法在系统⽂件IO接⼝中会使⽤到。
⼀种传递标志位的方法
#include <stdio.h>
#define ONE 0001 //0000 0001
#define TWO 0002 //0000 0010
#define THREE 0004 //0000 0100void func(int flags) {if (flags & ONE) printf("flags has ONE! ");if (flags & TWO) printf("flags has TWO! ");if (flags & THREE) printf("flags has THREE! ");printf("\n");
}int main() {func(ONE);func(THREE);func(ONE | TWO);func(ONE | THREE | TWO);return 0;
}
以位图的形式传递。
操作⽂件,除了上⼩节的C接⼝(当然,C++也有接⼝,其他语⾔也有),我们还可以采⽤系统接⼝来进⾏⽂件访问, 先来直接以系统代码的形式,实现和上⾯⼀模⼀样的代码:
系统调用
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>int open(const char *pathname, int flags);//打开已经创建的文件
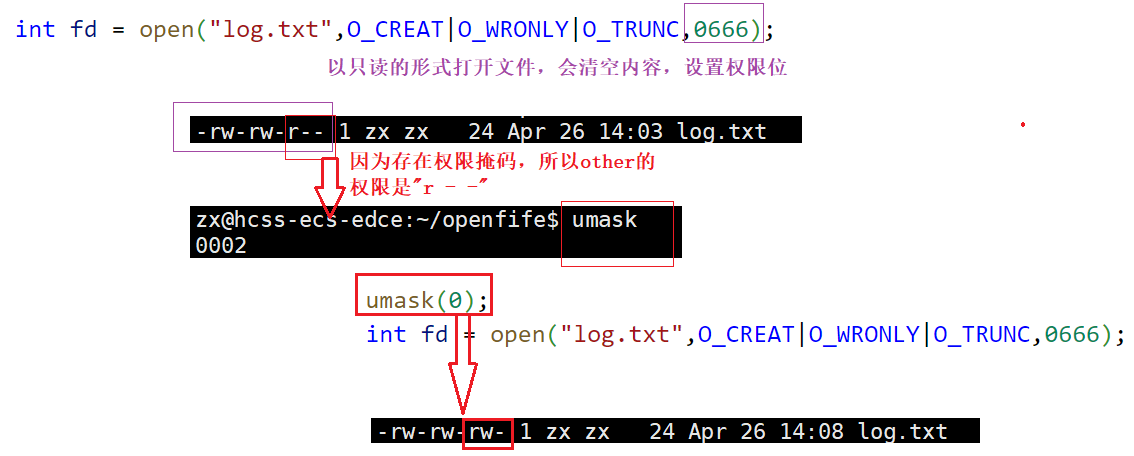
int open(const char *pathname, int flags, mode_t mode);//打开未创建的文件flags(这里挑选几个常用的标记位)
O_CREAT:不存在就创建
O_RDNOIY:只读
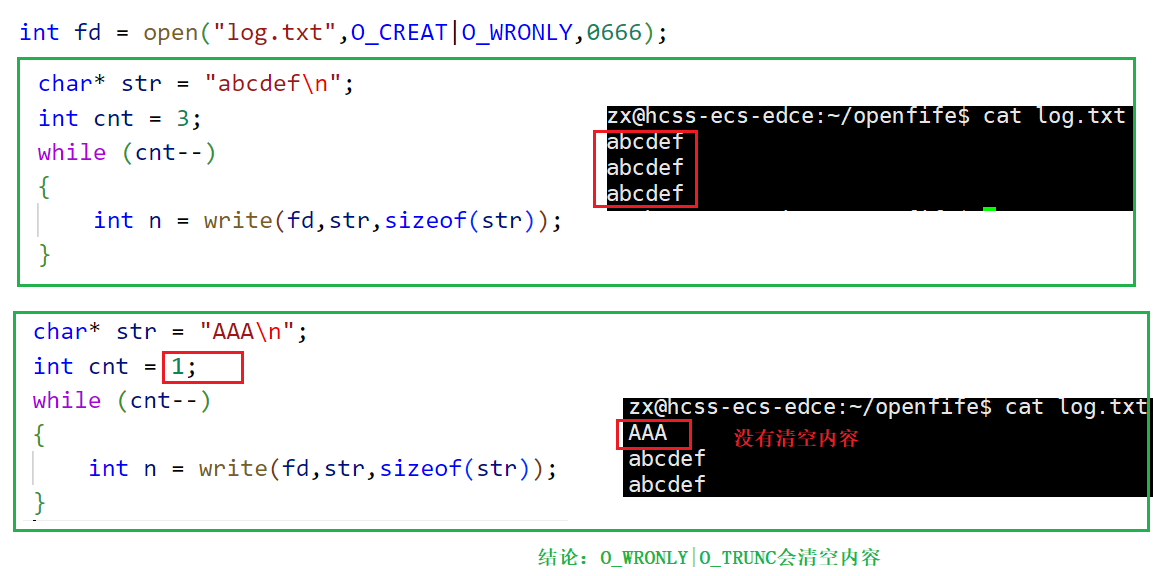
O_WRNOLY:只写(不会清空内容)
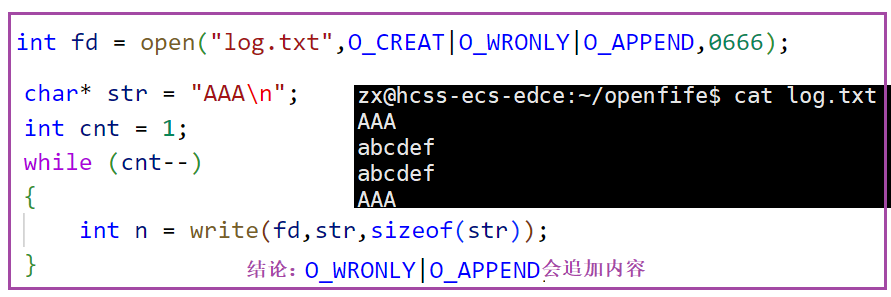
O_APPEND:追加
O_TRUNC:清除

#include <unistd.h>int close(int fd);//fd是open函数的返回值
#include <unistd.h>
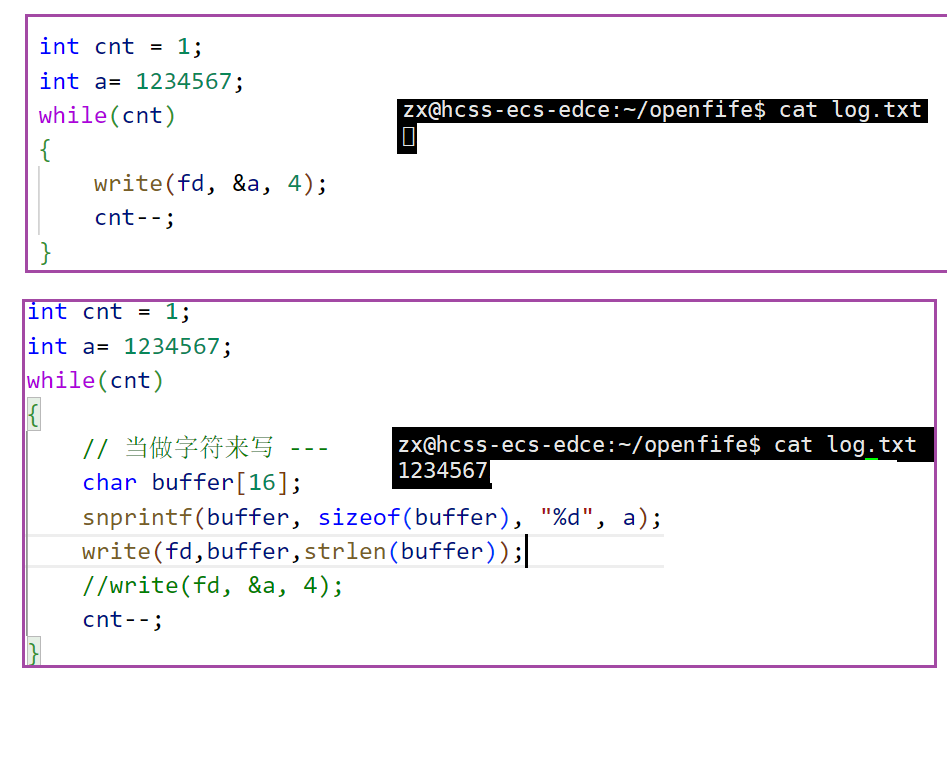
ssize_t write(int fd, const void *buf, size_t count);//返回值是写入的字节数理解文本写入和二进制写入
文本写入:将数据以文本形式存储,通常是以人类可读的字符形式(如ASCII或UTF-8编码)写入文件。例如,普通的文本文件(如.txt文件)就是以文本方式存储的。数据以字符编码的形式存储。例如,字符’A’在ASCII编码中对应十进制的65,存储时会以01000001的形式写入文件。
二进制写入:将数据以二进制形式存储,即直接将数据的二进制表示写入文件。这种方式通常用于存储程序的可执行文件、库文件、图像文件等,这些文件的内容对人类来说是不可直接阅读的,但计算机可以直接解析和处理。数据以原始的二进制形式存储,不经过字符编码转换。例如,一个整数65在内存中以二进制形式存储为01000001,直接将这个二进制形式写入文件。
总结:文本写入和二进制写入都是语言层面的概念,系统只认二进制,格式化输出时,只是把二进制转成你想要的格式,你想要输出什么格式,需要你自己转。
#include <unistd.h>
ssize_t read(int fd, void *buf, size_t count);//返回值是读到的字节数

FILE介绍
FILE:是C语言标准库中定义的一个结构体类型(struct),用来表示一个“文件流”,结构体里面封装了文件描述符fd,在操作系统的接口中,只认文件操作符fd。
open函数返回值
在认识返回值之前,先来认识⼀下两个概念: 系统调⽤ 和 库函数
• 上⾯的 fopen fclose fread fwrite 都是C标准库当中的函数,我们称之为库函数(libc)。
• ⽽ open close read write lseek 都属于系统提供的接⼝,称之为系统调⽤接⼝
• 回忆⼀下我们讲操作系统概念时,画的⼀张图:
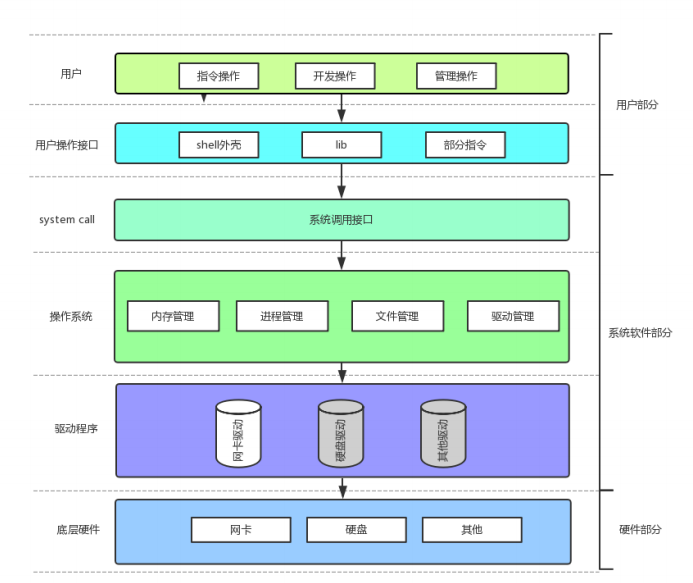
系统调⽤接⼝和库函数的关系,⼀⽬了然。
所以,可以认为, f# 系列的函数,都是对系统调⽤的封装,⽅便⼆次开发。
文件描述符fd
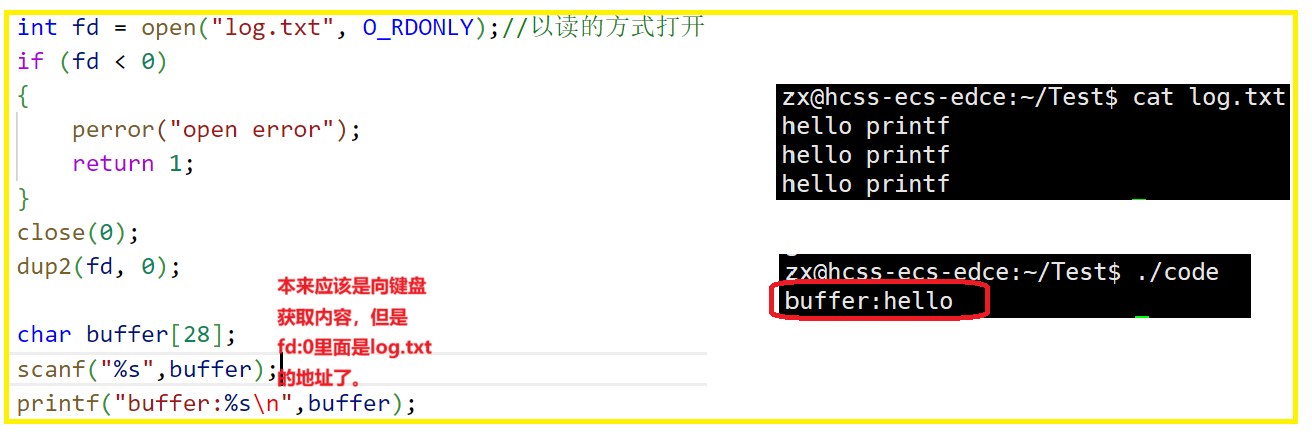
通过对open函数的学习,我们知道了⽂件描述符就是⼀个⼩整数
- Linux进程默认情况下会有3个缺省打开的⽂件描述符,分别是标准输⼊0, 标准输出1, 标准错
误2.- 0,1,2对应的物理设备⼀般是:键盘,显⽰器,显⽰器
所以输⼊输出还可以采⽤如下⽅式:

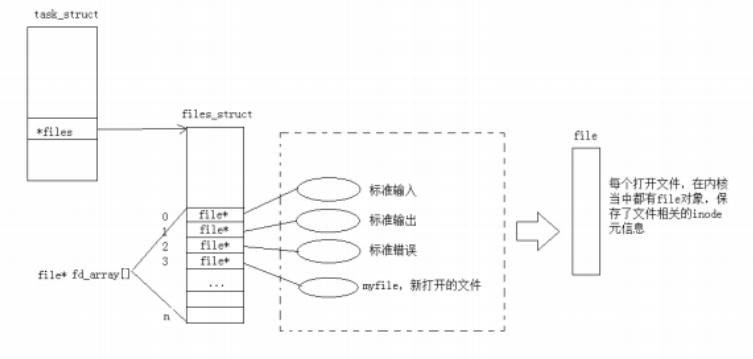
进程执⾏open系统调⽤,所以必须让进程和⽂件关联起来。每个进程都有⼀个指针*files, 指向⼀张表files_struct,该表最重要的部分就是包含⼀个指针数组,每个元素都是⼀个指向打开⽂件的指针!所以,本质上,⽂件描述符就是该数组的下标。所以,只要拿着⽂件描述符,就可以找到对应的⽂件。
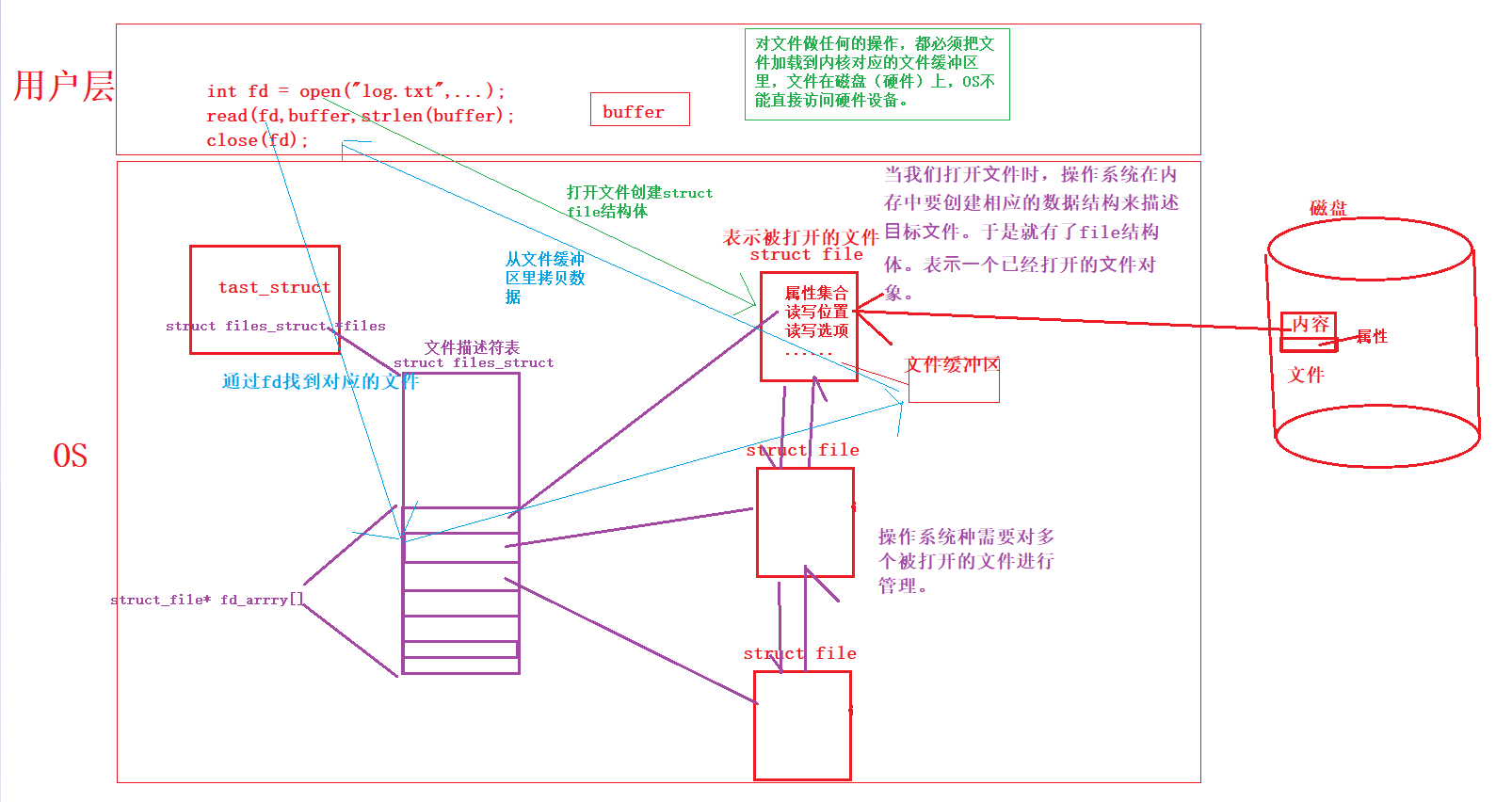
⽂件描述符的分配规则
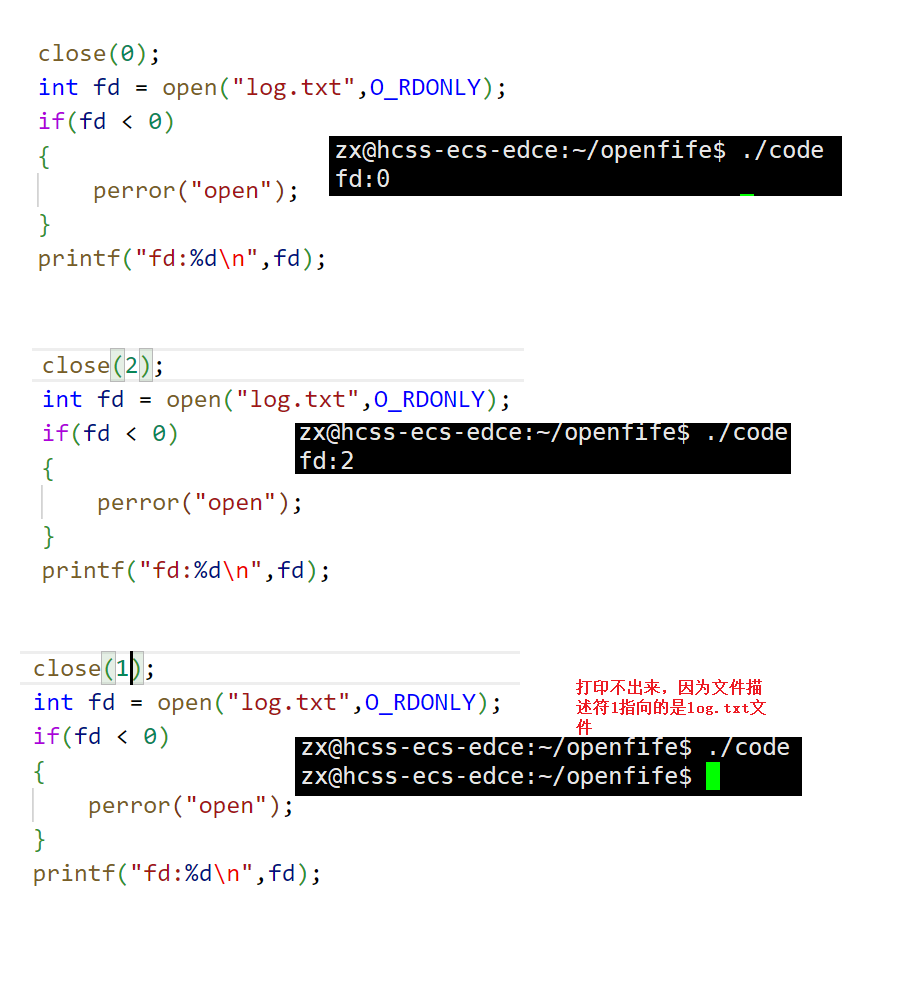
可⻅,⽂件描述符的分配规则:在files_struct数组当中,找到当前没有被使用的最小的⼀个下标,作为新的⽂件描述符。
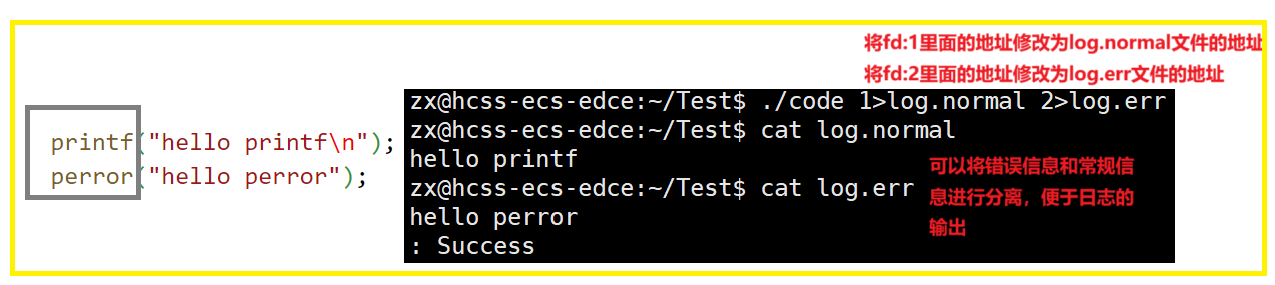
重定向

那重定向的本质是什么呢?更改文件描述符表
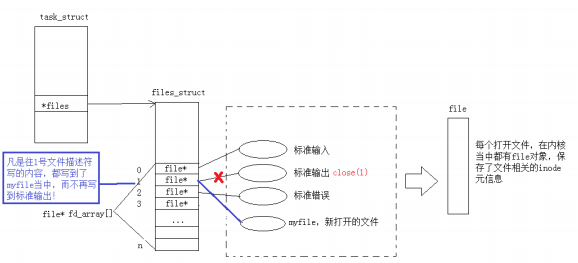
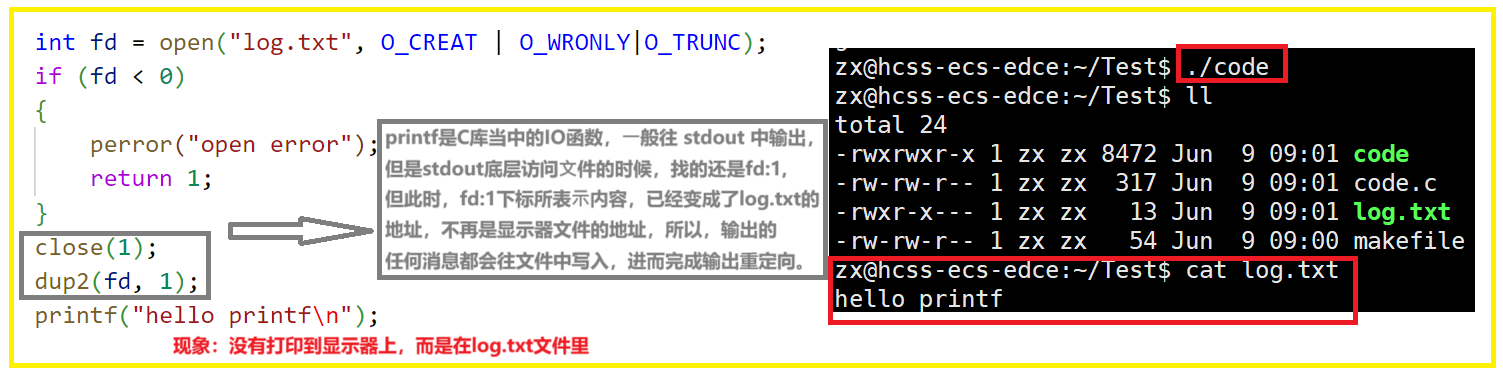
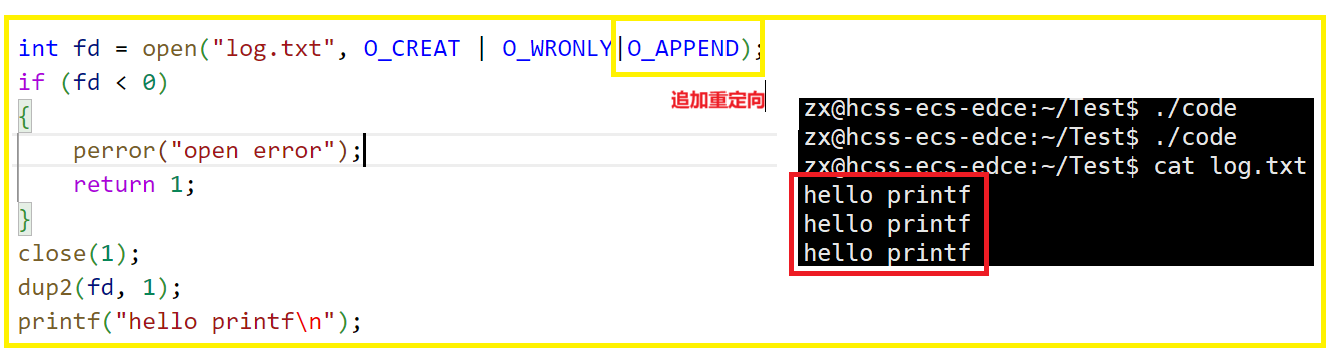
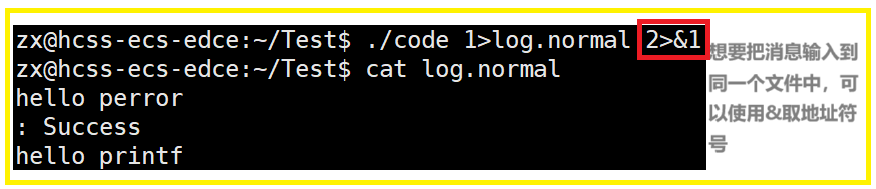
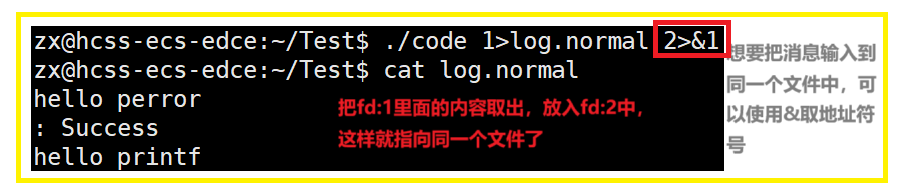
使用 dup2 系统调用
#include<unistd.h>
int dup2(int oldfd,int newfd);


为什么会有标准错误和标准输错呢?还指向同一个显示器(文件)?
这样可以通过重定向的能力,把常规消息和错误消息进行分离。
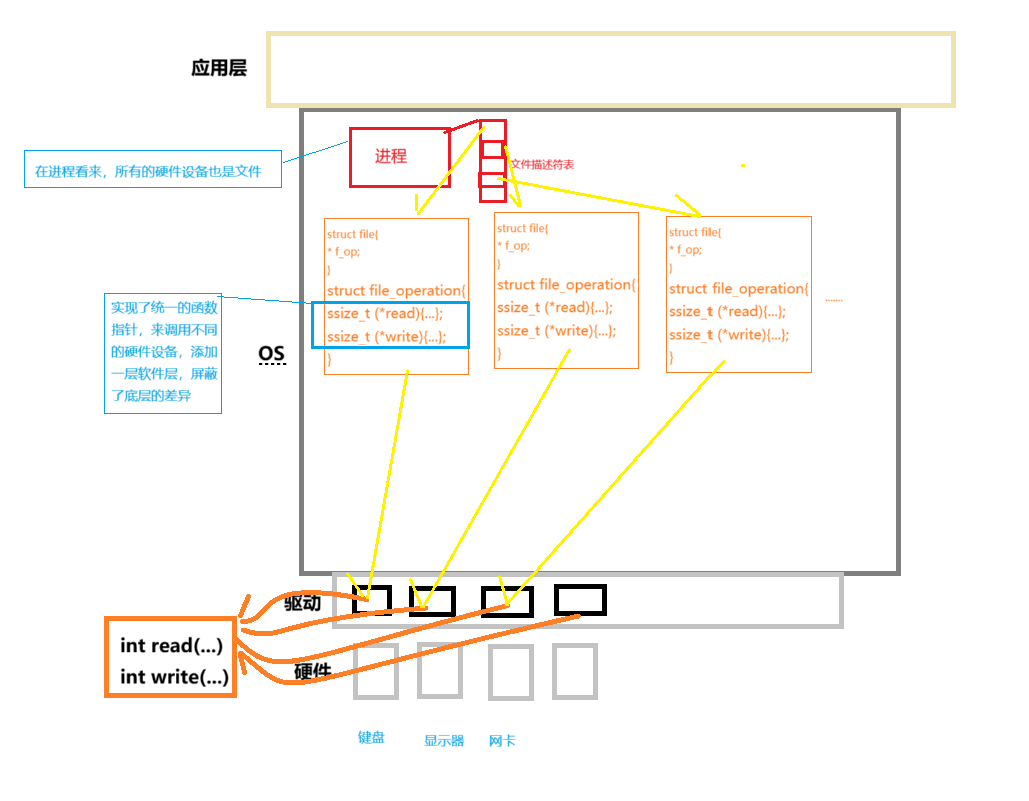
理解“⼀切皆文件”
- ⾸先,在windows中是⽂件的东西,它们在linux中也是⽂件;其次⼀些在windows中不是⽂件的东西,⽐如进程、磁盘、显⽰器、键盘这样硬件设备也被抽象成了⽂件,你可以使⽤访问⽂件的⽅法访问它们获得信息;甚⾄管道,也是⽂件;将来我们要学习⽹络编程中的socket(套接字)这样的东西,使⽤的接⼝跟⽂件接⼝也是⼀致的。
- 这样做最明显的好处是,开发者仅需要使⽤⼀套 API 和开发⼯具,即可调取 Linux 系统中绝⼤部分的资源。举个简单的例⼦,Linux 中⼏乎所有读(读⽂件,读系统状态,读PIPE)的操作都可以⽤read 函数来进⾏;⼏乎所有更改(更改⽂件,更改系统参数,写PIPE)的操作都可以⽤ write 函数来进⾏。
struct file {
...
struct inode *f_inode; /* cached value */
const struct file_operations *f_op;
...
atomic_long_t f_count; // 表⽰打开⽂件的引⽤计数,如果有多个⽂件指针指向
它,就会增加f_count的值。
unsigned int f_flags; // 表⽰打开⽂件的权限
fmode_t f_mode; // 设置对⽂件的访问模式,例如:只读,只写等。所有
的标志在头⽂件<fcntl.h> 中定义
loff_t f_pos; // 表⽰当前读写⽂件的位置
...
} __attribute__((aligned(4))); /* lest something weird decides that 2 is OK */当打开⼀个⽂件时,操作系统为了管理所打开的⽂件,都会为这个⽂件创建⼀个file结构体。
值得关注的是 struct file 中的f_op指针指向了⼀个file_operations 结构体,这个结构体中的成员除了struct module* owner 其余都是函数指针。
file_operation 就是把系统调⽤和驱动程序关联起来的关键数据结构,这个结构的每⼀个成员都对应着⼀个系统调⽤。读取 file_operation 中相应的函数指针,接着把控制权转交给函数,从⽽完成了Linux设备驱动程序的⼯作。
struct file_operations {
struct module *owner;
//指向拥有该模块的指针;
loff_t (*llseek) (struct file *, loff_t, int);
//llseek ⽅法⽤作改变⽂件中的当前读/写位置, 并且新位置作为(正的)返回值.
ssize_t (*read) (struct file *, char __user *, size_t, loff_t *);
//⽤来从设备中获取数据. 在这个位置的⼀个空指针导致 read 系统调⽤以 -
EINVAL("Invalid argument") 失败. ⼀个⾮负返回值代表了成功读取的字节数( 返回值是⼀个
"signed size" 类型, 常常是⽬标平台本地的整数类型).
ssize_t (*write) (struct file *, const char __user *, size_t, loff_t *);
//发送数据给设备. 如果 NULL, -EINVAL 返回给调⽤ write 系统调⽤的程序. 如果⾮负, 返
回值代表成功写的字节数.
ssize_t (*aio_read) (struct kiocb *, const struct iovec *, unsigned long,
loff_t);
//初始化⼀个异步读 -- 可能在函数返回前不结束的读操作.
ssize_t (*aio_write) (struct kiocb *, const struct iovec *, unsigned long,
loff_t);
//初始化设备上的⼀个异步写.
int (*readdir) (struct file *, void *, filldir_t);
//对于设备⽂件这个成员应当为 NULL; 它⽤来读取⽬录, 并且仅对**⽂件系统**有⽤.
unsigned int (*poll) (struct file *, struct poll_table_struct *);
int (*ioctl) (struct inode *, struct file *, unsigned int, unsigned long);
long (*unlocked_ioctl) (struct file *, unsigned int, unsigned long);
long (*compat_ioctl) (struct file *, unsigned int, unsigned long);
int (*mmap) (struct file *, struct vm_area_struct *);//mmap ⽤来请求将设备内存映射到进程的地址空间. 如果这个⽅法是 NULL, mmap 系统调⽤返
回 -ENODEV.
int (*open) (struct inode *, struct file *);
//打开⼀个⽂件
int (*flush) (struct file *, fl_owner_t id);
//flush 操作在进程关闭它的设备⽂件描述符的拷⻉时调⽤;
int (*release) (struct inode *, struct file *);
//在⽂件结构被释放时引⽤这个操作. 如同 open, release 可以为 NULL.
int (*fsync) (struct file *, struct dentry *, int datasync);
//⽤⼾调⽤来刷新任何挂着的数据.
int (*aio_fsync) (struct kiocb *, int datasync);
int (*fasync) (int, struct file *, int);
int (*lock) (struct file *, int, struct file_lock *);
//lock ⽅法⽤来实现⽂件加锁; 加锁对常规⽂件是必不可少的特性, 但是设备驱动⼏乎从不实现
它.
ssize_t (*sendpage) (struct file *, struct page *, int, size_t, loff_t *,
int);
unsigned long (*get_unmapped_area)(struct file *, unsigned long, unsigned
long, unsigned long, unsigned long);
int (*check_flags)(int);
int (*flock) (struct file *, int, struct file_lock *);
ssize_t (*splice_write)(struct pipe_inode_info *, struct file *, loff_t *,
size_t, unsigned int);
ssize_t (*splice_read)(struct file *, loff_t *, struct pipe_inode_info *,
size_t, unsigned int);
int (*setlease)(struct file *, long, struct file_lock **);
};
缓冲区
什么是缓冲区
缓冲区是内存空间的⼀部分。也就是说,在内存空间中预留了⼀定的存储空间,这些存储空间⽤来缓冲输⼊或输出的数据,这部分预留的空间就叫做缓冲区。缓冲区根据其对应的是输⼊设备还是输出设备,分为输⼊缓冲区和输出缓冲区。
总结:缓冲区就是一段内存空间。
为什么要引入缓冲区机制
- 读写⽂件时,如果不会开辟对⽂件操作的缓冲区,直接通过系统调⽤对磁盘进⾏操作(读、写等),那么每次对⽂件进⾏⼀次读写操作时,都需要使⽤读写系统调⽤来处理此操作,即需要执⾏⼀次系统调⽤,执⾏⼀次系统调⽤将涉及到CPU状态的切换,即从⽤⼾空间切换到内核空间,实现进程上下⽂的切换,这将损耗⼀定的CPU时间,频繁的磁盘访问对程序的执⾏效率造成很⼤的影响。
- 为了减少使⽤系统调⽤的次数,提⾼效率,我们就可以采⽤缓冲机制。⽐如我们从磁盘⾥取信息,可以在磁盘⽂件进⾏操作时,可以⼀次从⽂件中读出⼤量的数据到缓冲区中,以后对这部分的访问就不需要再使⽤系统调⽤了,等缓冲区的数据取完后再去磁盘中读取,这样就可以减少磁盘的读写次数,再加上计算机对缓冲区的操作⼤ 快于对磁盘的操作,故应⽤缓冲区可⼤ 提⾼计算机的运⾏速度。
- ⼜⽐如,我们使⽤打印机打印⽂档,由于打印机的打印速度相对较慢,我们先把⽂档输出到打印机相应的缓冲区,打印机再⾃⾏逐步打印,这时我们的CPU可以处理别的事情。可以看出,缓冲区就是⼀块内存区,它⽤在输⼊输出设备和CPU之间,⽤来缓存数据。它使得低速的输⼊输出设备和⾼速的CPU能够协调⼯作,避免低速的输⼊输出设备占⽤CPU,解放出CPU,使其能够⾼效率⼯作。
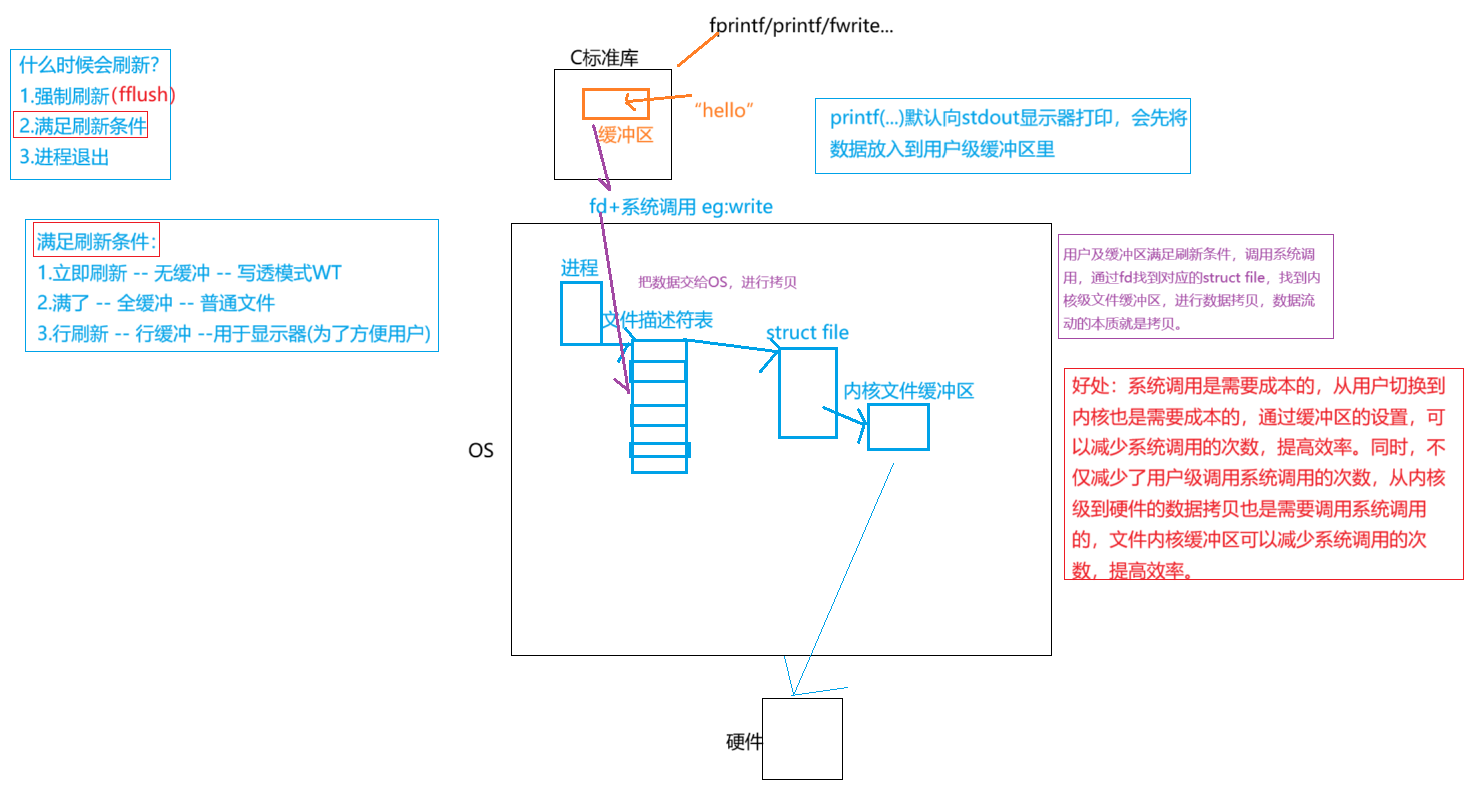
FILE
- 因为IO相关函数与系统调⽤接⼝对应,并且库函数封装系统调⽤,所以本质上,访问⽂件都是通过fd访问的。
- 所以C库当中的FILE结构体内部,必定封装了fd。
缓冲类型
标准I/O提供了3种类型的缓冲区。
- 全缓冲区:这种缓冲⽅式要求填满整个缓冲区后才进⾏I/O系统调⽤操作。对于磁盘⽂件的操作通常使⽤全缓冲的⽅式访问。
- ⾏缓冲区:在⾏缓冲情况下,当在输⼊和输出中遇到换⾏符时,标准I/O库函数将会执⾏系统调⽤操作。当所操作的流涉及⼀个终端时(例如标准输⼊和标准输出),使⽤⾏缓冲⽅式。因为标准I/O库每⾏的缓冲区⻓度是固定的,所以只要填满了缓冲区,即使还没有遇到换⾏符,也会执⾏I/O系统调⽤操作,默认⾏缓冲区的⼤⼩为1024。
- ⽆缓冲区:⽆缓冲区是指标准I/O库不对字符进⾏缓存,直接调⽤系统调⽤。标准出错流stderr通常是不带缓冲区的,这使得出错信息能够尽快地显示出来。

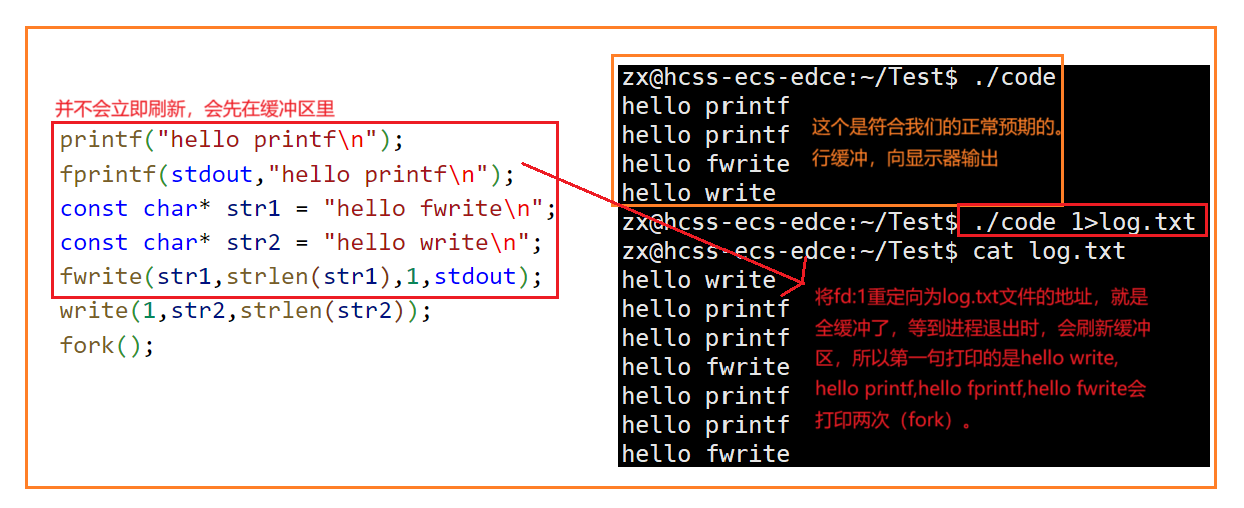
我们发现 printf ,fprintf和 fwrite (库函数)都输出了2次,⽽ write 只输出了⼀次(系统调⽤)。为什么呢?肯定和fork有关!
- ⼀般C库函数写⼊⽂件时是全缓冲的,⽽写⼊显示器是⾏缓冲。
- fprintf printf fwrite 库函数+会⾃带缓冲区,当发⽣重定向到普通⽂件时,数据的缓冲⽅式由⾏缓冲变成了全缓冲。
- ⽽我们放在缓冲区中的数据,就不会被⽴即刷新,甚⾄fork之后
- 但是进程退出之后,会统⼀刷新,写⼊⽂件当中。
- 但是fork的时候,⽗⼦数据会发⽣写时拷⻉,所以当你⽗进程准备刷新的时候,⼦进程也就有了同样的⼀份数据,随即产⽣两份数据。
- write 没有变化,说明没有所谓的缓冲。
typedef _IO_FILE FILE;
struct _IO_FILE {
int _flags; /* High-order word is _IO_MAGIC; rest is flags. */
#define _IO_file_flags _flags//缓冲区相关
/* The following pointers correspond to the C++ streambuf protocol. */
/* Note: Tk uses the _IO_read_ptr and _IO_read_end fields directly. */
char* _IO_read_ptr; /* Current read pointer *///这些就是缓冲区
char* _IO_read_end; /* End of get area. */
char* _IO_read_base; /* Start of putback+get area. */
char* _IO_write_base; /* Start of put area. */
char* _IO_write_ptr; /* Current put pointer. */
char* _IO_write_end; /* End of put area. */
char* _IO_buf_base; /* Start of reserve area. */
char* _IO_buf_end; /* End of reserve area. */
/* The following fields are used to support backing up and undo. */
char *_IO_save_base; /* Pointer to start of non-current get area. */
char *_IO_backup_base; /* Pointer to first valid character of backup area */
char *_IO_save_end; /* Pointer to end of non-current get area. */
struct _IO_marker *_markers;
struct _IO_FILE *_chain;//管理文件缓冲区的链表
int _fileno; //封装的⽂件描述符
#if 0
int _blksize;
#else
int _flags2;
#endif
_IO_off_t _old_offset; /* This used to be _offset but it's too small. */
#define __HAVE_COLUMN /* temporary */
/* 1+column number of pbase(); 0 is unknown. */
unsigned short _cur_column;
signed char _vtable_offset;
char _shortbuf[1];
/* char* _save_gptr; char* _save_egptr; */
_IO_lock_t *_lock;
#ifdef _IO_USE_OLD_IO_FILE
};





:整体架构)






:项目构建和时间戳、日志库)
: 模型压缩与优化)





)