一、引言
在大数据时代,数据成为了驱动决策、洞察趋势的核心资源。出于对数据分析的浓厚兴趣,以及希望能更高效获取网络信息的目的,我踏上了网络爬虫的学习之旅。通过这段时间的学习,我不仅掌握了从网页中提取数据的技术,还深刻体会到网络爬虫在市场调研、学术研究、信息监测等领域的巨大价值,这对我的职业发展和个人能力提升有着深远的意义。

二、基础知识学习
2.1 网络基础概念
学习网络爬虫,HTTP 协议是绕不开的基石。我通过查阅 RFC 文档和各类技术博客,深入理解了 GET、POST 等请求方法的差异,以及 200、404、500 等响应状态码背后的含义。例如,在使用 requests 库发送请求时,requests.get(url)对应 HTTP 的 GET 请求,而requests.post(url, data=data)则用于 POST 请求 。URL 作为网页的 “地址”,其协议、域名、路径、参数等组成部分的解析,让我明白如何精准定位目标资源。相关代码示例可参考requests 官方文档示例。
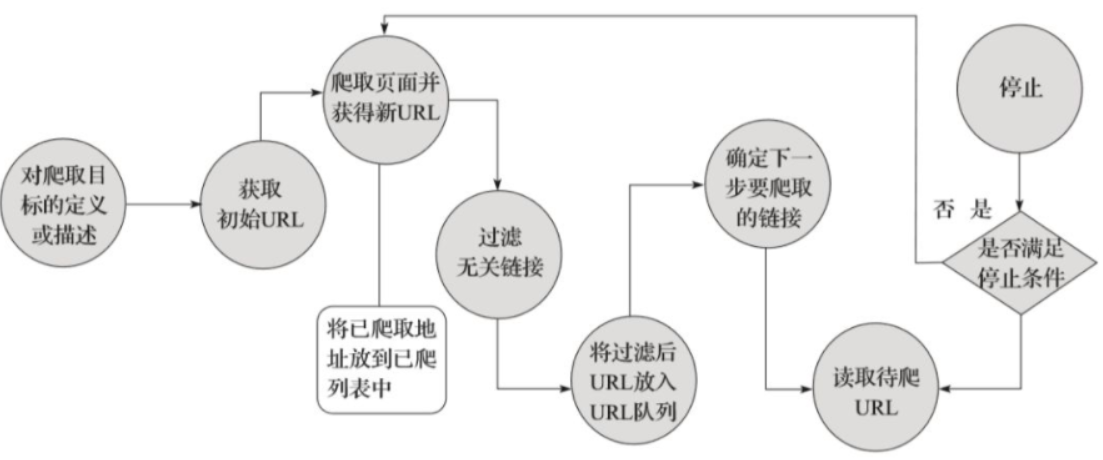
2.2 网页结构与解析
HTML 作为网页的骨架,其标签构成的树状结构是数据提取的关键。我通过实际分析各类网页源码,熟悉了<div>、<p>、<span>等常用标签的作用。在解析网页时,CSS 选择器和 XPATH 表达式成为了我的得力工具。CSS 选择器语法简洁,适合快速定位元素,如div.container p可选中 class 为container的<div>标签下的所有<p>标签;XPATH 表达式则更强大灵活,能通过路径精准匹配,如//div[@class='article']/p可获取 class 为article的<div>下的所有<p>标签。Python 的BeautifulSoup库对 CSS 选择器支持良好,示例代码可见BeautifulSoup 官方教程 ;而lxml库在处理 XPATH 表达式上表现出色,代码示例参考lxml 官方文档。
2.3 编程语言基础
Python 以其简洁的语法和丰富的库,成为爬虫开发的首选语言。在学习过程中,我巩固了数据类型(列表、字典等)、控制流(if - else、for 循环)等基础知识,并将其灵活运用到爬虫逻辑中。requests库用于发送网络请求,BeautifulSoup和lxml用于解析网页,Scrapy是强大的爬虫框架,Selenium则能驱动浏览器处理动态页面。如使用requests和BeautifulSoup获取网页标题的简单代码:
import requests
from bs4 import BeautifulSoupurl = "https://example.com"
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
print(soup.title.text)三、工具与框架实践
3.1 爬虫工具的使用
浏览器开发者工具是调试爬虫的利器。通过 Chrome DevTools 的 “Network” 面板,我能清晰看到网络请求的发起、响应过程,分析请求头、响应体,定位数据加载接口。Fiddler 抓包工具则能拦截、修改请求和响应数据,帮助我理解网络通信细节。在处理复杂网页请求时,利用 Fiddler 设置断点,修改 User - Agent 等头部信息,解决了部分网站的访问限制。关于 Fiddler 的使用教程可参考Fiddler 官方文档。
3.2 爬虫框架应用
Scrapy 框架以其高效的架构和完善的功能,极大提升了爬虫开发效率。从创建项目、定义 Item、编写 Spider,到设置 Pipeline 进行数据处理,每个环节都有清晰的流程。例如,在一个抓取新闻网站的项目中,通过定义NewsItem类来结构化数据,在NewsSpider中编写解析逻辑,使用Pipeline对数据进行清洗和存储。分布式爬虫框架 Scrapy - Redis 则让爬虫能够在多台机器上协同工作,适合大规模数据抓取场景。Scrapy 项目示例代码可在Scrapy 官方 GitHub 仓库查看,Scrapy - Redis 的使用示例参考Scrapy - Redis GitHub 仓库。
3.3 模拟登录与 Cookie 处理
许多网站需要登录后才能访问数据,模拟登录成为爬虫开发的重要技能。常见的模拟登录方式包括表单提交和验证码识别。对于简单的表单登录,通过分析登录请求的参数,使用requests库构造 POST 请求提交用户名和密码;遇到验证码时,可采用打码平台或机器学习模型进行识别。Cookie 在保持会话状态中起着关键作用,获取并保存 Cookie 后,后续请求带上 Cookie 即可模拟已登录状态。模拟登录示例代码可参考GitHub 模拟登录示例。
四、实战项目经验
4.1 简单网页数据抓取
在抓取静态网页数据时,我选择了一些新闻网站和博客作为目标。以抓取某博客文章列表为例,首先使用requests获取网页内容,再通过BeautifulSoup解析出文章标题、作者、发布时间等信息。在这个过程中,我遇到了网页编码问题,通过指定response.encoding = 'utf - 8'解决了乱码问题。完整项目代码可在GitHub 静态网页爬虫项目查看。
4.2 动态网页爬虫
对于大量使用 JavaScript 渲染的动态网页,Selenium+WebDriver 是绝佳解决方案。在抓取某电商平台商品信息时,使用 ChromeDriver 驱动浏览器,通过定位元素、模拟滚动等操作,获取到了通过 AJAX 加载的商品详情。示例代码如下:
from selenium import webdriver
from selenium.webdriver.common.by import Bydriver = webdriver.Chrome()
driver.get("https://example.com")
# 定位元素
product_name = driver.find_element(By.CSS_SELECTOR, '.product - name').text
print(product_name)
driver.quit()4.3 反爬虫机制应对
在爬虫实践中,我遭遇了多种反爬虫策略。面对 IP 封禁,我搭建了 IP 代理池,通过随机切换代理 IP 突破限制;对于 User - Agent 检测,构建 User - Agent 池,每次请求随机设置请求头中的 User - Agent;在验证码识别方面,尝试了 Tesseract OCR 和第三方打码平台。反爬虫应对代码示例可在GitHub 反爬虫策略项目查看。
五、学习过程中的问题与解决
5.1 遇到的技术难题
网络请求失败是常见问题,可能是网络不稳定、目标网站拒绝访问等原因。通过检查请求头、响应状态码,使用代理 IP 等方式逐步排查解决。复杂网页结构解析时,嵌套层级深、元素属性不唯一等问题增加了解析难度,通过结合 CSS 选择器和 XPATH 表达式,以及观察网页规律来定位元素。
5.2 非技术问题
学习过程中,面对复杂的技术难点,焦虑情绪时常出现。我通过制定学习计划,将大目标拆解为小任务,逐步攻克难点,同时与技术社区的同行交流,分享经验,调整学习心态。在学习进度与深度的平衡上,初期以快速入门掌握基础为主,后期针对感兴趣的方向深入研究。
六、总结与展望
6.1 学习网络爬虫的收获与成长
通过这段时间的学习,我从对网络爬虫一无所知,到能够独立开发功能完善的爬虫程序,技术能力得到了显著提升。同时,培养了问题解决能力和逻辑思维,也明白了数据合规使用的重要性。
6.2 网络爬虫技术的未来发展趋势
随着人工智能技术的发展,智能爬虫将更加普及,能够自动识别网页结构、处理复杂反爬虫机制。此外,对数据隐私和安全的重视,也将促使爬虫技术向更合规、更可控的方向发展。
6.3 个人后续学习计划与目标
未来,我计划深入学习机器学习在爬虫中的应用,如自动识别验证码、智能解析网页。同时,研究更多分布式爬虫技术,提升大规模数据抓取能力。并且,持续关注行业动态和法律法规,确保爬虫技术的合法合规使用。

)





)




)





:FBI树)
