文章目录
- 前言
- 一、Polyphase 多项分解
- 1.定义
- 2.拆分公式
- 3.推导过程
- 1)按模 M M M拆分求和项
- 2)提取因子
- 4.总结
- 二、Noble恒等式
- 1. 定义
- 2.Noble恒等式表达方式
- 1)抽取系统的 Noble 恒等式
- 2)插值系统的 Noble 恒等式
- 2.Nodble恒等式推导
- 1)符号定义
- 2)先滤波后抽取
- 3)先抽取后滤波
- 4)比较左右两式
- 3.稀疏滤波器 H ( z M ) H(z^M) H(zM)
- 4.计算量对比
- 三、高效多相抽取器
- 1.Polyphase和Noble的关系
- 2.设计一个抽取因子为 M M M的系统
- 1)常规系统结构
- 2)使用polyphase分解
- 3)使用Noble恒等式
- 4)Polyphase + Noble
- 5)整体的系统结构
- 四、实现高效QMF滤波器组
- 1. 设计目标
- 2.设计思路
- 3.实现代码
- 4.输出结果
- 总结
前言
在上一篇文章中,深入介绍了QMF滤波器组的原理,并且基于原理也同样给出了实现方式,它可以用于频带分割和完美重构。而本篇文章将会介绍一种高效多相抽取器的设计,它可以大大减少下采样、上采样、滤波器组等中的计算量,同样可以改进QMF滤波器组的设计。
本篇文章将先介绍Polyphase 多项分解和Noble恒等式的定义和原理,其中得到Polyphase 分解 + Noble 恒等式 = 高效多相抽取器设计。并以QMF滤波器为例,最终实现更为高效的频带分割。
|版本声明:山河君,未经博主允许,禁止转载
一、Polyphase 多项分解
1.定义
Polyphase 多项分解(Polyphase Decomposition)是数字信号处理中一种对滤波器进行重构或分解的方法,广泛应用于下采样、上采样、滤波器组(filter bank)等。
简单来说,它可以将一个FIR滤波器的冲激响应(或系统函数)按照某种方式拆分为若干子滤波器(称为 polyphase 分量),以便于在多速率处理(如抽取/内插)中实现更高效的计算。
2.拆分公式
对于长度为 N N N的FIR滤波器,它的Z变换为:
H ( z ) = ∑ n = 0 N − 1 h [ n ] z − n H(z)=\sum_{n=0}^{N-1}h[n]z^{-n} H(z)=n=0∑N−1h[n]z−n
将其分解为 M M M个polyphase分量为:
H ( z ) = ∑ k = 0 M − 1 z − k E k ( z M ) H(z)=\sum_{k=0}^{M-1}z^{-k}E_k(z^M) H(z)=k=0∑M−1z−kEk(zM)
其中
- E k ( z ) = ∑ n = 0 ∞ h [ n M + k ] z − n E_k(z) = \sum_{n=0}^{\infty}h[nM+k]z^{-n} Ek(z)=∑n=0∞h[nM+k]z−n
- E k ( z M ) E_k(z^M) Ek(zM):是第 k k k个多项式,取 M M M个系数中的第 k k k个
例如我们将一个FIR滤波器分解为M个polyphose分量,那么系统的结构应该是:
x[n]↓
+---多相分解---+
| |
| x_0[n] --> E_0(z^M) --+
| x_1[n] --> E_1(z^M) --+--> 叠加后输出 y[n]
| ... |
| x_{M-1}[n] --> E_{M-1}(z^M) --+3.推导过程
1)按模 M M M拆分求和项
将索引 n n n拆成两部分:
n = M m + k , 0 ≤ k < M , m = 0 , 1 , … n=Mm+k, \quad 0≤k<M,m=0,1,… n=Mm+k,0≤k<M,m=0,1,…
也就是说,我们把 h [ n ] h[n] h[n]分组,每组第 k k k个对应:
- k = 0 : h [ 0 ] , h [ M ] , h [ 2 M ] , . . . . k=0:h[0], h[M], h[2M],.... k=0:h[0],h[M],h[2M],....
- k = 1 : h [ 1 ] , h [ M + 1 ] , h [ 2 M + 1 ] , . . . . k=1:h[1], h[M+1], h[2M+1],.... k=1:h[1],h[M+1],h[2M+1],....
- . . . . .... ....
- k = M − 1 : h [ M − 1 ] , h [ 2 M − 1 ] , h [ 3 M − 1 ] , . . . . k=M-1:h[M-1], h[2M-1], h[3M-1],.... k=M−1:h[M−1],h[2M−1],h[3M−1],....
那么原始滤波器就变为:
H ( z ) = ∑ n = 0 N − 1 h [ n ] z − n = ∑ k = 0 M − 1 ∑ m = 0 ∞ h [ M m + k ] z − ( M m + k ) H(z)=\sum_{n=0}^{N-1}h[n]z^{-n}=\sum_{k=0}^{M-1}\sum_{m=0}^{\infty}h[Mm+k]z^{-(Mm+k)} H(z)=n=0∑N−1h[n]z−n=k=0∑M−1m=0∑∞h[Mm+k]z−(Mm+k)
注意:当 M m + k ≥ N Mm+k\geq N Mm+k≥N时, h [ M m + k ] = 0 h[Mm+k] = 0 h[Mm+k]=0,所以无穷求和也成立,实际上这个求和是形式上是无穷级数,但实际只有有限项非零,其实应该为 ∑ m = 0 N − k − 1 M h [ M m + k ] z − ( M m + k ) \sum_{m=0}^{\frac{N-k-1}{M}}h[Mm+k]z^{-(Mm+k)} ∑m=0MN−k−1h[Mm+k]z−(Mm+k)
2)提取因子
现在将 z − ( M m + k ) = z − k z − M m z^{-(Mm+k)}= z^{-k}z^{-Mm} z−(Mm+k)=z−kz−Mm拆分出来:
H ( z ) = ∑ k = 0 M − 1 z − k ∑ m = 0 ∞ h [ M m + k ] z − M m H(z)=\sum_{k=0}^{M-1}z^{-k}\sum_{m=0}^{\infty}h[Mm+k]z^{-Mm} H(z)=k=0∑M−1z−km=0∑∞h[Mm+k]z−Mm
内层和是关于 m m m的,是子滤波器的表达式。我们定义:
E k ( z ) = ∑ m = 0 ∞ h [ M m + k ] z − m ⇒ E k ( z M ) = ∑ m = 0 ∞ h [ M m + k ] z − m M E_k(z)=\sum_{m=0}^{\infty}h[Mm+k]z^{-m} \Rightarrow E_k(z^M)=\sum_{m=0}^{\infty}h[Mm+k]z^{-mM} Ek(z)=m=0∑∞h[Mm+k]z−m⇒Ek(zM)=m=0∑∞h[Mm+k]z−mM
最终得到:
H ( z ) = ∑ k = 0 M − 1 z − k E k ( z M ) H(z)=\sum_{k=0}^{M-1}z^{-k}E_k(z^M) H(z)=k=0∑M−1z−kEk(zM)
4.总结
截止到当前内容,可以看到:
- 多相分解本质上是滤波器的数学重构,不改变滤波器的频率响应和功能
- 只用 polyphase 分解结构组合出的滤波器,结果与原始 FIR 滤波器一样
- 此时并没有节省计算,甚至由于多设计在实现时更复杂
那么本篇文章在一开始说多项分解是期望计算量可以大大减少,而这里并没有减少计算量,这其实在一开始的定义中就已经说了,是配合抽取或插值时才使用 polyphase,这里就需要结合下面的内容——Noble恒等式。
二、Noble恒等式
1. 定义
假如现在有一个系统,在进行滤波后,需要进行抽取或者插值,那么使用Noble恒等式可以把滤波器移到抽取或插值前(或后),从而减少不必要的计算,以避免对冗余样本进行滤波可显著提高效率。
2.Noble恒等式表达方式
1)抽取系统的 Noble 恒等式
如果一个系统包含一个滤波器 H ( z ) H(z) H(z),后面跟着一个抽取器 ↓ M \downarrow M ↓M,那么根据Noble恒等式存在以下关系:
H ( z ) ⋅ ↓ M = ↓ M ⋅ H ( z M ) H(z) \cdot \downarrow M = \downarrow M \cdot H(z^M) H(z)⋅↓M=↓M⋅H(zM)
其表明了:将滤波器 H ( z ) H(z) H(z)放在抽取器 ↓ M \downarrow M ↓M之前,等价于先抽取再使用滤波器 H ( z M ) H(z^M) H(zM),其中 H ( z M ) H(z^M) H(zM)表示将滤波器频率压缩(频谱展开)。
2)插值系统的 Noble 恒等式
如果一个系统包含一个插值器 ↑ L \uparrow L ↑L,后面跟着一个滤波器 H ( z ) H(z) H(z),那么根据Noble恒等式存在以下关系:
↑ L ⋅ H ( z ) = H ( z L ) ⋅ ↑ L \uparrow L \cdot H(z) = H(z^L) \cdot \uparrow L ↑L⋅H(z)=H(zL)⋅↑L
其表明了:在插值器后进行滤波,等价于先使用变换后的滤波器 H ( z L ) H(z^L) H(zL)再进行插值)。
2.Nodble恒等式推导
值得注意的是:我们知道抽取等同于下采样,而下采样时需要考虑混叠现象的发生,Noble 恒等式之所以成立,前提是滤波器 h [ n ] h[n] h[n]是设计合理的,也就是说它已经足够抑制抽取过程可能产生的混叠(aliasing)。
1)符号定义
以FIR滤波器+抽取为例,从上文可知,先滤波再抽取等于先抽取再滤波,即:
( x [ n ] ∗ h [ n ] ) ↓ M = ( x [ n ] ↓ M ) ∗ h [ n M ] (x[n]*h[n]) \downarrow M=(x[n] \downarrow M)*h[nM] (x[n]∗h[n])↓M=(x[n]↓M)∗h[nM]
其中定义:
- x [ n ] x[n] x[n]: 原始输入信号
- h [ n ] h[n] h[n]: FIR 滤波器的冲激响应
- y [ n ] = x [ n ] ∗ h [ n ] y[n] = x[n]*h[n] y[n]=x[n]∗h[n]: 卷积结果
- x e [ n ] = x [ n M ] x_e[n]=x[nM] xe[n]=x[nM]: 抽取后的输入信号
- h e [ n ] = h [ n M ] h_e[n]=h[nM] he[n]=h[nM]: 稀疏化后的滤波器
- y e [ n ] = y [ n M ] y_e[n]=y[nM] ye[n]=y[nM]: 抽取后结果
2)先滤波后抽取
- 对于FIR滤波为:
y [ n ] = x [ n ] ∗ h [ n ] = ∑ k = − ∞ ∞ x [ k ] h [ n − k ] y[n]=x[n]*h[n]=\sum_{k=-\infty}^{\infty}x[k]h[n-k] y[n]=x[n]∗h[n]=k=−∞∑∞x[k]h[n−k] - 再进行抽取即:
y e [ n ] = y [ n M ] = ∑ k = − ∞ ∞ x [ k ] h [ n M − k ] y_e[n]=y[nM]=\sum_{k=-\infty}^{\infty}x[k]h[nM-k] ye[n]=y[nM]=k=−∞∑∞x[k]h[nM−k]
注意:这里是对输出也就是 y [ n ] y[n] y[n]进行抽样 M M M,所以系统输入 x [ n ] x[n] x[n]不变,而FIR滤波器冲激响应应该只对于 n M − k nM-k nM−k处存在响应。
3)先抽取后滤波
- 对于 x [ n ] x[n] x[n]抽取: x e [ n ] = x [ n M ] x_e[n]=x[nM] xe[n]=x[nM]
- 对于稀疏滤波器响应: h e [ n ] = h [ n M ] h_e[n]=h[nM] he[n]=h[nM]
- 带入系统响应
y 1 [ n ] = ∑ k = − ∞ ∞ x e [ k ] h e [ n − k ] = ∑ k = − ∞ ∞ x [ k M ] h [ ( n − k ) M ] y_1[n]=\sum_{k=-\infty}^{\infty}x_e[k]h_e[n-k]=\sum_{k=-\infty}^{\infty}x[kM]h[(n-k)M] y1[n]=k=−∞∑∞xe[k]he[n−k]=k=−∞∑∞x[kM]h[(n−k)M]
4)比较左右两式
令 m = k M m=kM m=kM,即上式:
y 1 [ n ] = ∑ k = − ∞ ∞ x [ k M ] h [ ( n − k ) M ] = ∑ m = − ∞ ∞ x [ m ] h [ ( n M − m ) ] y_1[n]=\sum_{k=-\infty}^{\infty}x[kM]h[(n-k)M]=\sum_{m=-\infty}^{\infty}x[m]h[(nM-m)] y1[n]=k=−∞∑∞x[kM]h[(n−k)M]=m=−∞∑∞x[m]h[(nM−m)]
而 x [ k M ] x[kM] x[kM]只在 k = m k=m k=m是 M M M的整数倍处非零,所以 y 1 [ n ] = y e [ n ] y_1[n]=y_e[n] y1[n]=ye[n]左右两边等式相同。
3.稀疏滤波器 H ( z M ) H(z^M) H(zM)
从上式中,对于
y 1 [ n ] = ∑ m = − ∞ ∞ x [ m ] h [ ( n M − m ) ] y_1[n]=\sum_{m=-\infty}^{\infty}x[m]h[(nM-m)] y1[n]=m=−∞∑∞x[m]h[(nM−m)]
只在 M M M的整数倍处非零,将原信号拉伸 M M M倍,中间插入 M − 1 M-1 M−1个0。也就是说在系统的冲击响应变成了如下形式:
[ h [ 0 ] , 0 , . .0 , h [ M − 1 ] , 0 , . . , 0 , n ( M − 1 ) ] [h[0],0,..0,h[M-1],0,..,0,n(M-1)] [h[0],0,..0,h[M−1],0,..,0,n(M−1)]
根据语音信号处理二十八——采样率转换文章中上采样的过程,这实际上就是插值0的处理,那么对于原滤波器:
H ( z ) = ∑ n h [ n ] z − n ⟹ H ( z M ) = ∑ n h [ n ] z − M n H(z)=\sum_nh[n]z^{-n} \Longrightarrow H(z^M)=\sum_nh[n]z^{-Mn} H(z)=n∑h[n]z−n⟹H(zM)=n∑h[n]z−Mn
对于系统的冲击响应为:
h [ n ] ⟹ h ′ [ n ] = { h [ n / M ] , n ≡ 0 ( m o d M ) 0 , o t h e r w i s e h[n] \Longrightarrow h'[n]=\begin{cases} h[n/M], \quad n \equiv 0(\mod M) \\ 0, \quad otherwise \\ \end {cases} h[n]⟹h′[n]={h[n/M],n≡0(modM)0,otherwise
也就是Noble的滤波器从 H ( z ) H(z) H(z)变为了 H ( z M ) H(z^M) H(zM)
4.计算量对比
| 步骤 | 先滤后抽 | 先抽后滤(用 Noble 恒等式) |
|---|---|---|
| 处理采样率 | 原始速率 | 降低后的速率(低 M 倍) |
| 滤波器计算次数 | 所有输入都要处理 | 只有每 M 个输入处理一次 |
| 运算量 | 高 | 低 |
| 滤波器形态 | 原始 H ( z ) H(z) H(z) | H ( z M ) H(z^M) H(zM):频率压缩,稀疏系数 |
三、高效多相抽取器
此时了解了polyphase多项分解和noble恒等式,那么现在就可以构造一个高效多项抽取器。
1.Polyphase和Noble的关系
- Polyphase中的 E k ( z M ) E_k(z^M) Ek(zM):
回到上文中Polyphase对于长度为 N N N的FIR滤波器的分解:
H ( z ) = ∑ k = 0 M − 1 z − k E k ( z M ) H(z)= \sum_{k=0}^{M-1}z^{-k}E_k(z^M) H(z)=k=0∑M−1z−kEk(zM)
而 E k ( z ) = ∑ n = 0 ∞ h [ n M + k ] z − n E_k(z) = \sum_{n=0}^{\infty}h[nM+k]z^{-n} Ek(z)=∑n=0∞h[nM+k]z−n,得到 E k ( z M ) E_k(z^M) Ek(zM)为:
E k ( z M ) = ∑ n = 0 ∞ h [ n M + k ] z − n M E_k(z^M)=\sum_{n=0}^{\infty}h[nM+k]z^{-nM} Ek(zM)=n=0∑∞h[nM+k]z−nM
根据语音信号处理二十八——采样率转换文章中上采样的过程,这个Polyphase分量的子滤波器同样是一个稀疏滤波器 - Noble中的 H ( z M ) H(z^M) H(zM):
根据上文描述,它一样是一个稀疏滤波器
总结:Polyphase多项分解中,各个子Polyphase分量滤波器已经变成了稀疏滤波器,即Noble恒等式中可以直接在Polyphase多项分解中直接使用。
2.设计一个抽取因子为 M M M的系统
1)常规系统结构
x(n) ──► H(z) ──► ↓M ──► y(n)
即:输入信号先通过滤波器 H ( z ) H(z) H(z),再进行抽取,如果使用常规办法:
- 对每一个输入样本 x [ n ] x[n] x[n] 都应用完整的滤波器 H ( z ) H(z) H(z)
- 然后只保留每隔 M M M个样本一个,丢弃其他
那么会存在以下缺点:
- 大部分滤波器输出最终被丢弃了
- 运算量大
因此我们需要设计一个高效多相抽取器来解决运算量问题
| 项目 | 内容 |
|---|---|
| 原始结构 | x ( n ) → H ( z ) → ↓ M x(n) \rightarrow H(z) \rightarrow \downarrow M x(n)→H(z)→↓M |
| 问题 | 计算量大,大部分结果被丢弃 |
| 解决步骤 | 1)Polyphase 分解 2)应用 Noble 恒等式 |
| 得到的结构 | 只计算必要的滤波器输出,每 M M M 个输入产生一次输出,高效节省计算量 |
2)使用polyphase分解
根据上文中,先将 H ( z ) H(z) H(z)分解为 M M M个
H ( z ) = ∑ k = 0 M − 1 z − k E k ( z M ) H(z)=\sum_{k=0}^{M-1}z^{-k}E_k(z^M) H(z)=k=0∑M−1z−kEk(zM)
3)使用Noble恒等式
根据上文,将抽取位置放到滤波之前,滤波器变为 H ( z N ) H(z^N) H(zN)
H ( z ) ⋅ ↓ M = ↓ M ⋅ H ( z M ) H(z) \cdot \downarrow M = \downarrow M \cdot H(z^M) H(z)⋅↓M=↓M⋅H(zM)
即:
x(n) ──► H(z^M) ──► ↓M ──► y(n)
4)Polyphase + Noble
将Noble恒等式滤波器带入,即最后系统结构变为
H ( z M ) = ∑ k = 0 M − 1 z − k M E k ( z M 2 ) H(z^M)=\sum_{k=0}^{M-1}z^{-kM}E_k(z^{M^2}) H(zM)=k=0∑M−1z−kMEk(zM2)
对于这个式子,整个系统结构如同下图:
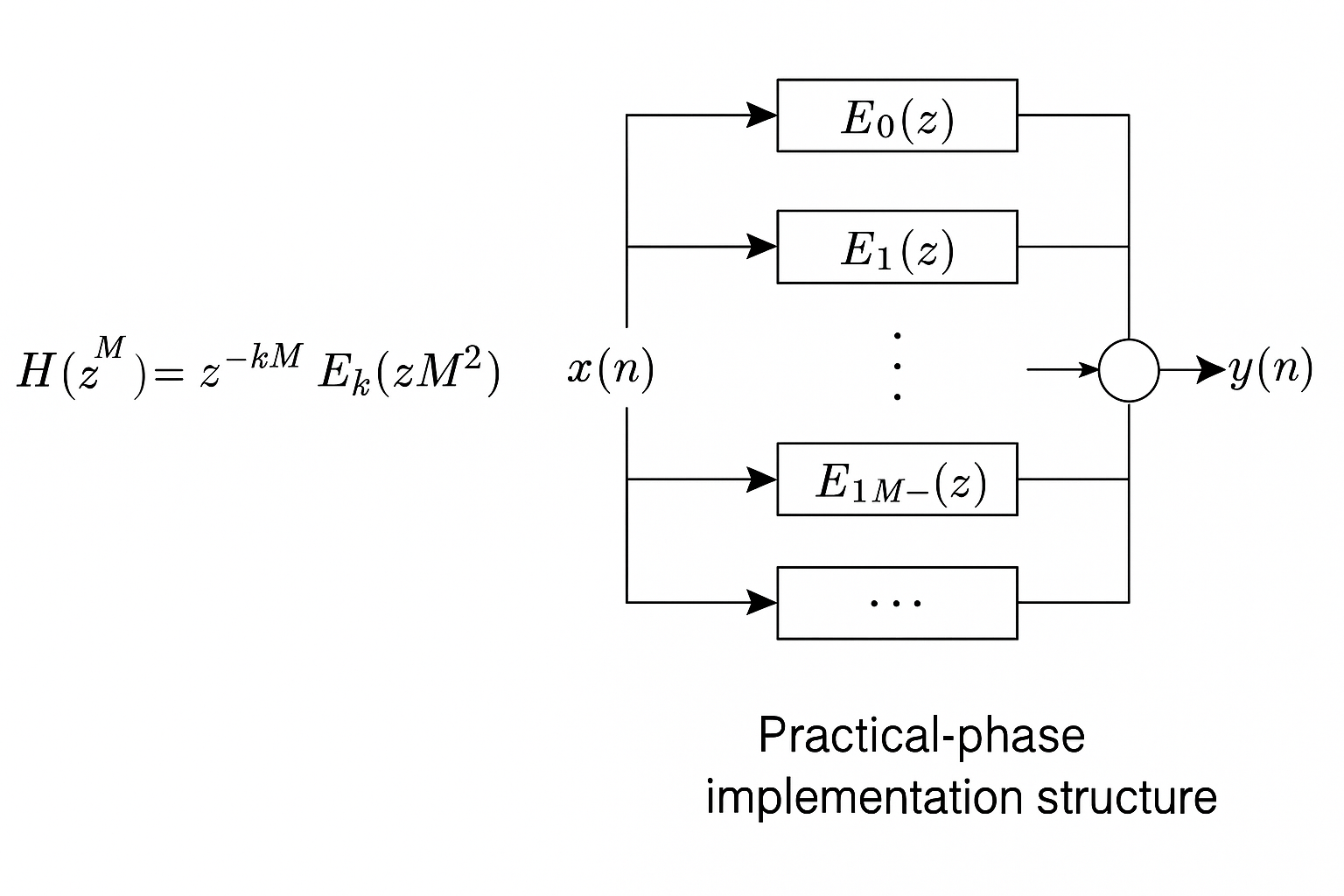
5)整体的系统结构
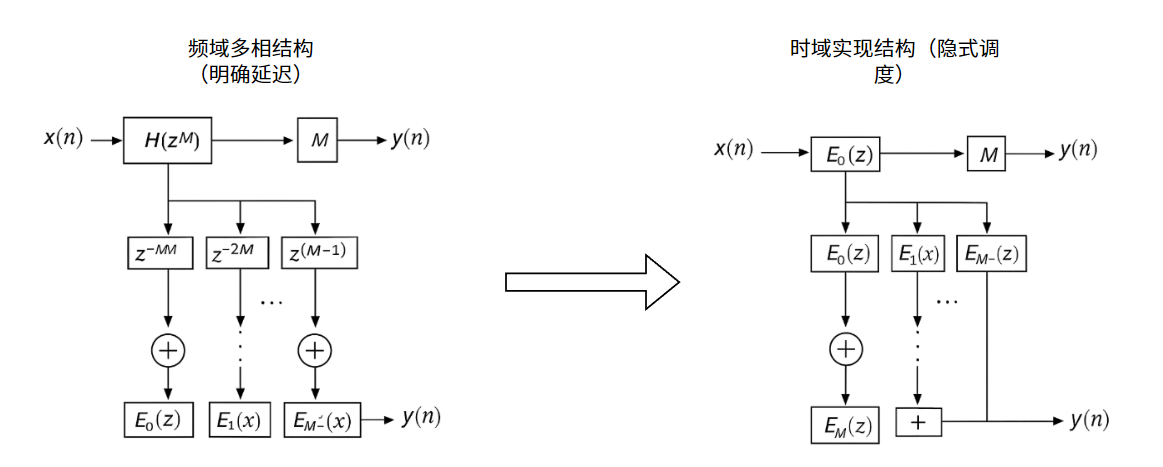
- 根据上文中Polyphase和Noble的关系,实际上每个子Polyphase分量已经是稀疏滤波器,所以对于 E k ( z M 2 ) E_k(z^{M^2}) Ek(zM2)只是用于表达,实际上应用的还是 E k ( z M ) E_k(z^M) Ek(zM)
- 虽然频域表达上有 z − k M z^{-kM} z−kM,是第k个polyphase 分量相对于整体滤波器输出的时间偏移,但是它只是推导过程中出现的一个中间形式。在时域结构中,这个延迟已经隐含在多通道输入顺序和采样调度中,不需要手动加 delay block。
所以整体的系统结构和上文中公式表述的结构区别如同下图:
四、实现高效QMF滤波器组
1. 设计目标
使用Noble+polyphase多项分解实现一个QMF滤波器组,给出matlab代码,要求:
- 16k采样率的信号,使用一个2kHz和6kHz的正弦信号
- 对于原始序列进行频带分割和重组
- 镜像滤波器使用FIR滤波器设计,同时使用汉明窗
输出:
4. 画出原始序列的频谱
5. 画出分割后的低频和高频频谱
6. 画出重组后的频谱
7. 画出原始的时域图和重组后的时域图
2.设计思路
在上一篇文章中,语音信号处理二十九——QMF滤波器设计原理与实现已经介绍了QMF滤波器组中镜像滤波器的设计原理,这里不再赘述,整体的思路如下:
| 步骤 | 描述 |
|---|---|
| 1 | 设计线性相位原型滤波器 H 0 ( z ) H_0(z) H0(z) |
| 2 | 构造 H 1 ( z ) = H 0 ( − z ) H_1(z) = H_0(-z) H1(z)=H0(−z) |
| 3 | 构造合成滤波器 G 0 ( z ) = H 0 ( z ) , G 1 ( z ) = − H 0 ( − z ) G_0(z) = H_0(z), G_1(z) = -H_0(-z) G0(z)=H0(z),G1(z)=−H0(−z) |
| 4 | 对所有滤波器进行 polyphase 分解 |
| 5 | 应用 Noble 恒等式将抽/插采样前移/后移,提高效率 |
| 6 | 构建完整的滤波器组结构,实现高效 PR 系统 |
3.实现代码
clc; clear; close all;
fs = 16000;
t = 0:1/fs:0.05;
x = sin(2*pi*2000*t) + sin(2*pi*6000*t); % 输入信号%% 设计 QMF 滤波器组
M = 64; % 滤波器长度
h0 = fir1(M-1, 0.5, hamming(M)); % 低通滤波器
h1 = h0 .* ((-1).^(0:M-1)); % 高通镜像滤波器% 多项分解:偶数项、奇数项
h0_even = h0(1:2:end); % E0
h0_odd = h0(2:2:end); % E1
h1_even = h1(1:2:end); % E0'
h1_odd = h1(2:2:end); % E1'% 将信号分为偶数采样、奇数采样(Noble 恒等式:下采样前移)
x_even = x(1:2:end); % 下采样偶数点
x_odd = x(2:2:end); % 下采样奇数点% 对下采样信号分别使用 polyphase 分支滤波器
% 偶数采样信号滤波
y0_even = filter(h0_even, 1, x_even);
y0_odd = filter(h0_odd, 1, x_odd);y1_even = filter(h1_even, 1, x_even);
y1_odd = filter(h1_odd, 1, x_odd);% 由于x_even和x_odd长度可能不同,取最小长度裁剪
min_len = min([length(y0_even), length(y0_odd), length(y1_even), length(y1_odd)]);y0 = y0_even(1:min_len) + y0_odd(1:min_len);
y1 = y1_even(1:min_len) + y1_odd(1:min_len);%% 合成滤波器组(多项 + 上采样 + Noble)
% 合成滤波器多项
g0_even = h0_even; g0_odd = h0_odd;
g1_even = h1_even; g1_odd = h1_odd;v0_even = filter(g0_even, 1, y0);
v0_odd = filter(g0_odd, 1, y0);
v1_even = filter(g1_even, 1, y1);
v1_odd = filter(g1_odd, 1, y1);min_len2 = min([length(v0_even), length(v0_odd), length(v1_even), length(v1_odd)]);xr = zeros(1, 2*min_len2);
xr(1:2:end) = v0_even(1:min_len2) + v1_even(1:min_len2);
xr(2:2:end) = v0_odd(1:min_len2) + v1_odd(1:min_len2);%% 频谱可视化
NFFT = 1024;
f = fs*(0:NFFT/2-1)/NFFT;
X = fft(x, NFFT);figure;
subplot(2,3,1); plot(t, x); title('原始信号(时域)');
subplot(2,3,2); plot(f, abs(X(1:NFFT/2))); title('原始信号频谱');% 画低频子带频谱\高频子带频谱
fs_sub = fs / 2; % 子带采样率 8kHz
f_sub = fs_sub*(0:NFFT/2-1)/NFFT;Y0 = fft(y0, NFFT);
Y1 = fft(y1, NFFT);subplot(2,3,3);
plot(f_sub, abs(Y0(1:NFFT/2)));
title('低频子带频谱');
xlabel('频率 (Hz)');
subplot(2,3,4);
plot(f_sub, abs(Y1(1:NFFT/2)));
title('高频子带频谱');
xlabel('频率 (Hz)');t_rec = (0:length(xr)-1) / fs;
X_rec = fft(x, NFFT);
subplot(2,3,5); plot(t_rec, xr); title('重构信号(时域)');
subplot(2,3,6); plot(f, abs(X_rec(1:NFFT/2))); title('重构信号频谱');4.输出结果
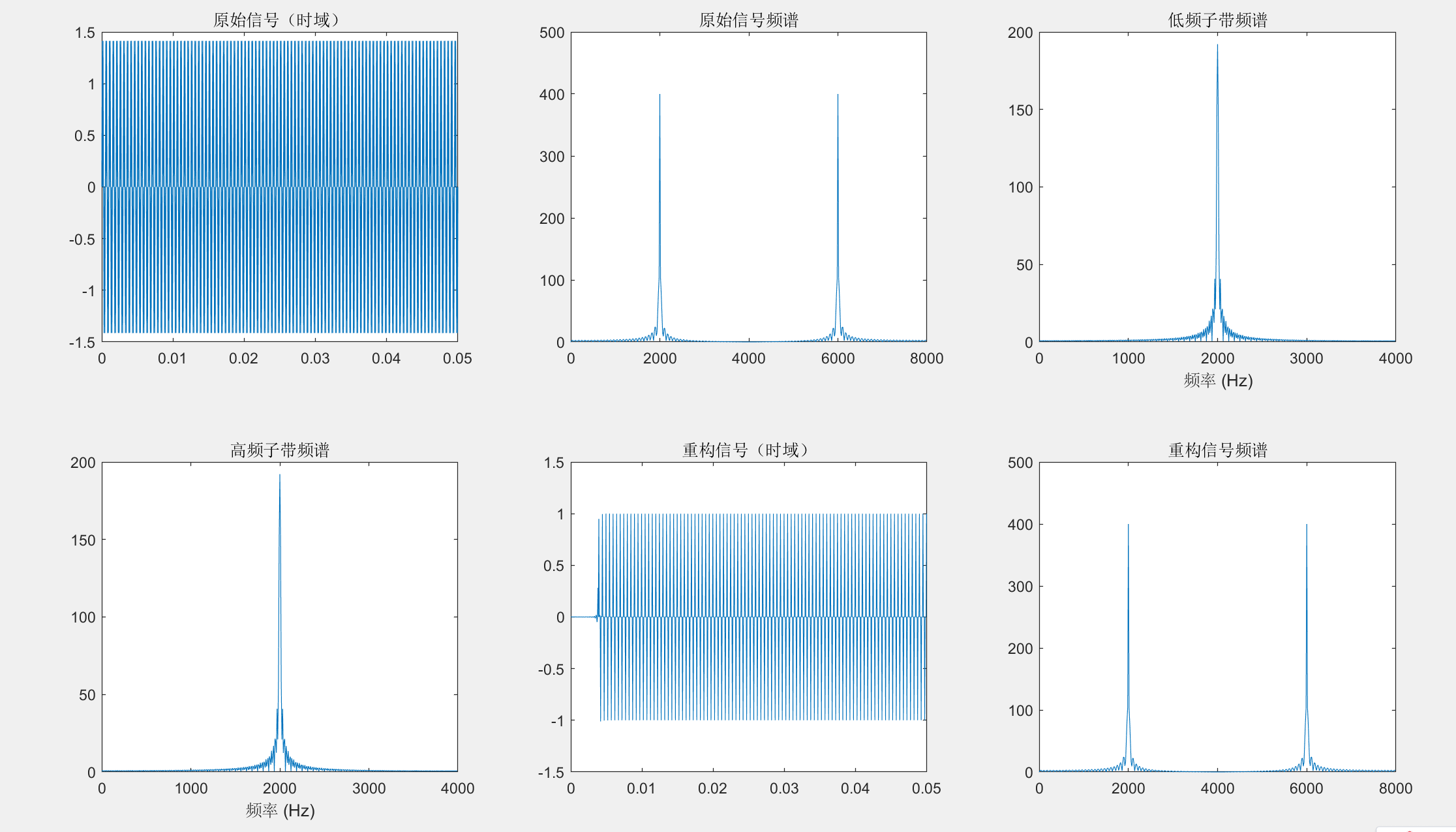
总结
高效多相抽取器是一种能够在进行抽取处理时,将滤波操作和下采样合并,显著降低计算量的滤波器结构。
对于polyphase多项分解和Noble恒等式存在具体的数学推导应该很容易理解,主要是对于高效多项抽取器中两者的组合,那里对于相位延迟和稀疏滤波器的地方容易放人混淆。
反正收藏也不会看,不如点个赞吧


 与虚拟机的爱恨情仇)
















)