#include<stdio.h>
#include<unistd.h>int main()
{printf("XXXXXXX");sleep(3);return 0;
}为什么以下代码是先显示"XXXXXXX",屏幕才显示"XXXXXXX"sleep三秒。
#include<stdio.h>
#include<unistd.h>int main()
{printf("XXXXXXX\n");sleep(3);return 0;
}1.什么是缓冲区
举个例子:
假设有两个人,张三和李四。他们两个是网友,有一天呢李四过生日,张三就准备把自己给他准备的礼物给爱他,但是张三和李四距离太远,以前呢张三骑着自己的小单车就出发了,经过两个月的长途跋涉终于送给了李四。张三两个月没上班,一想,亏死了。
后来,有了菜鸟驿站,张三需要给李四礼物就不用骑单车了,张三只需要把快递交给楼下的菜鸟驿站,至于菜鸟驿站什么时候发,快递什么时候到都不需要张三管,张三就可以继续上班了,快递到了先是放在李四楼下的菜鸟驿站,至于李四什么时候在家,菜鸟驿站再送。

至此,我们其实就可以大概猜得出,菜鸟驿站其实就是缓冲区的意思,而张三就是程序员,李四就是硬件。张三家楼下的菜鸟驿站就是C语言FILE结构体里面的一个长数组,他就是C语言下的缓冲区,我们的printf实际上就是先把数据写到它里面去。(下面会详细说FILE)
struct _IO_FILE {// ...其他字段...char* _IO_buf_base; // 缓冲区起始位置char* _IO_buf_end; // 缓冲区结束位置// ...其他字段...
};李四楼下的缓冲区就是内核里面的缓冲区,在struct file里,struct file里不止有文件的属性和内容信息,还有缓冲区。
struct file {// ...const struct file_operations *f_op; // 文件操作函数指针struct address_space *f_mapping; // 指向address_space结构// ...
};其中,f_mapping字段指向一个struct address_space,这是文件与页缓存之间的桥梁。
2 .为什么要引⼊缓冲区机制
3.缓冲类型
缓冲区:这种缓冲⽅式要求填满整个缓冲区后才进⾏I/O系统调⽤操作。对于磁盘⽂件的操作通常使⽤全缓冲的⽅式访问。⾏缓冲区:在⾏缓冲情况下,当在输⼊和输出中遇到换⾏符时,标准I/O库函数将会执⾏系统调⽤操作。当所操作的流涉及⼀个终端时(例如标准输⼊和标准输出),使⽤⾏缓冲⽅式。因为标准I/O库每⾏的缓冲区⻓度是固定的,所以只要填满了缓冲区,即使还没有遇到换⾏符,也会执⾏I/O系统调⽤操作,默认⾏缓冲区的⼤⼩为1024。⽆缓冲区:⽆缓冲区是指标准I/O库不对字符进⾏缓存,直接调⽤系统调⽤。标准出错流stderr通常是不带缓冲区的,这使得出错信息能够尽快地显⽰出来。
1. 缓冲区满时;2. 执⾏flush语句;
include <stdio.h>
#include <string.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
int main() {close(1);int fd = open("log.txt", O_WRONLY | O_CREAT | O_TRUNC, 0666);if (fd < 0) {perror("open");return 0;}printf("hello world: %d\n", fd);close(fd);return 0;
}这里相当于把stdout用log.txt替换
[ljh@VM-8-12-centos buffer]$ ./myfile
[ljh@VM-8-12-centos buffer]$ ls
log.txt makefile myfile myfile.c
[ljh@VM-8-12-centos buffer]$ cat log.txt
[ljh@VM-8-12-centos buffer]$当调用printf()时,数据被写入stdout对应的FILE结构体管理的缓冲区,这个缓冲区完全在用户空间,由 C 标准库 (libc) 维护默认情况下,重定向到文件的流是全缓冲的,缓冲区大小通常为 4KB 或 8KB。
只有当 C 库缓冲区刷新时 (通过fflush()或缓冲区满),才会调用write()系统调用,write()将数据从用户空间复制到内核空间的页缓存 (Page Cache),页缓存由内核管理,位于物理内存中
include <stdio.h>
#include <string.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
int main() {close(1);int fd = open("log.txt", O_WRONLY | O_CREAT | O_TRUNC, 0666);if (fd < 0) {perror("open");return 0;}printf("hello world: %d\n", fd);fflush(stdout);close(fd);return 0;
}#include <stdio.h>
#include <string.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
int main() {close(2);int fd = open("log.txt", O_WRONLY | O_CREAT | O_TRUNC, 0666);if (fd < 0) {perror("open");return 0;}perror("hello world");close(fd);return 0;
}4.FILE
上面我们提到了FILE,这里我们详细来聊聊。
4.1 FILE结构体的本质与作用
FILE是 C 标准库中定义的结构体类型,用于封装文件操作的相关信息,是用户空间与系统调用之间的桥梁。它本质上是对文件描述符(fd)的一层封装,同时管理 I/O 缓冲区,以提升 I/O 操作效率。
4.2 FILE结构体的核心字段
在 GNU C 库(glibc)中,FILE结构体的关键字段如下:
struct _IO_FILE {int _fileno; // 封装的文件描述符(fd)char* _IO_buf_base; // 缓冲区起始地址char* _IO_buf_end; // 缓冲区结束地址char* _IO_read_ptr; // 读缓冲区当前位置char* _IO_write_ptr; // 写缓冲区当前位置int _flags; // 文件状态标志(如读写模式、是否关闭等)const struct _IO_jump_t* _vtable; // 函数指针表,指向I/O操作函数// 其他字段(省略)
};-
_fileno:
直接关联系统调用的文件描述符,是FILE与内核交互的桥梁。例如,printf最终会通过_fileno对应的 fd 调用write系统调用。 -
缓冲区相关指针:
_IO_buf_base和_IO_buf_end:标记缓冲区的物理范围。_IO_read_ptr和_IO_write_ptr:记录当前读写位置,用于控制数据在缓冲区中的流动。
-
_vtable:
指向函数表,包含一系列 I/O 操作的实现(如读、写、刷新缓冲区等),体现了面向对象的设计思想。
4.3 FILE与系统调用的关系
用户空间视角:通过FILE*指针调用printf、fscanf等库函数,数据先存入FILE的缓冲区。
内核空间视角:当缓冲区刷新时(如调用fflush、缓冲区满或程序结束),库函数通过_fileno调用write、read等系统调用,将数据传入内核缓冲区(页缓存)
4.4 为什么需要FILE结构体?
- 跨平台兼容性:封装不同系统的文件操作细节(如 Windows 和 Linux 的文件描述符机制差异)。
- 缓冲区优化:通过用户空间缓冲区减少系统调用次数,提升 I/O 效率。
- 高层抽象:提供更易用的接口(如
printf的格式化输出),隐藏底层系统调用的复杂性
FILE结构体是 C 语言 I/O 体系的核心,它通过封装文件描述符和管理用户空间缓冲区,在高效性和易用性之间取得平衡。理解FILE的内部结构,有助于深入掌握 C 语言 I/O 操作的本质,以及缓冲区刷新、重定向等关键机制。
5.一个关键问题
为了让我们更好的理解上面的内容,我们来看以下代码:
#include <stdio.h>
#include <string.h>
#include <unistd.h>
int main()
{const char *msg0="hello printf\n";const char *msg1="hello fwrite\n";const char *msg2="hello write\n";printf("%s", msg0);fwrite(msg1, strlen(msg1), 1, stdout);write(1, msg2, strlen(msg2));fork();return 0;
}这个代码看起来简单,却是检测是否理解缓冲区的关键!!!
问题:
为什么运行出结果:
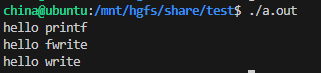
而重定向时:
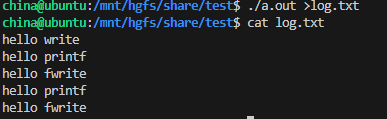
为什么结果不一样呢???
其实关键的原因就在于,显示器文件和该文本文件的缓冲区刷新方式不同。
显示器是行刷新,而文本是满刷新。
所以在显示器上,一行一行刷新,到子进程时缓冲区也没东西了。
在重定向时,开始数据进入缓冲区,但是一直没刷新,write是系统调用,直接输入到内核缓冲区了所以先打印,到了fork时,子进程继承了父进程缓冲区的东西,文件退出时,自动ffulsh,所以就得到了我们看见的现象。
- 一般 C 库函数写入文件时是全缓冲的,而写入显示器是行缓冲。
- printf fwrite 库函数 + 会自带缓冲区(进度条例子就可以说明),当发生重定向到普通文件时,数据的缓冲方式由行缓冲变成了全缓冲。
- 而我们放在缓冲区中的数据,就不会被立即刷新,甚至 fork 之后
- 但是进程退出之后,会统一刷新,写入文件当中。
- 但是 fork 的时候,父子数据会发生写时拷贝,所以当你父进程准备刷新的时候,子进程也就有了同样的一份数据,随即产生两份数据。
- write 没有变化,说明没有所谓的缓冲区。
6.简单设计一下libc库
#pragma once#define SIZE 1024#define FLUSH_NONE 0
#define FLUSH_LINE 1
#define FLUSH_FULL 2struct IO_FILE
{int flag; // 刷新方式int fileno; // 文件描述符char outbuffer[SIZE];int cap;int size;// TODO
};typedef struct IO_FILE mFILE;mFILE *mfopen(const char *filename, const char *mode);
int mwrite(const void *ptr, int num, mFILE *stream);
void mfflush(mFILE *stream);
void mfclose(mFILE *stream);my_stdio.c
#include "my_stdio.h"
#include <string.h>
#include <stdlib.h>
#include <sys/stat.h>
#include <sys/types.h>
#include <fcntl.h>
#include <unistd.h>mFILE *mfopen(const char *filename, const char *mode)
{int fd = -1;if(strcmp(mode, "r") == 0){fd = open(filename, O_RDONLY);}else if(strcmp(mode, "w")== 0){fd = open(filename, O_CREAT|O_WRONLY|O_TRUNC, 0666);}else if(strcmp(mode, "a") == 0){fd = open(filename, O_CREAT|O_WRONLY|O_APPEND, 0666);}if(fd < 0) return NULL;mFILE *mf = (mFILE*)malloc(sizeof(mFILE));if(!mf){close(fd);return NULL;}mf->fileno = fd;mf->flag = FLUSH_LINE;mf->size = 0;mf->cap = SIZE;return mf;
}void mfflush(mFILE *stream)
{if(stream->size > 0){// 写到内核文件的文件缓冲区中write(stream->fileno, stream->outbuffer, stream->size);// 刷新到外设fsync(stream->fileno);stream->size = 0;}
}int mfwrite(const void *ptr, int num, mFILE *stream)
{// 1. 拷贝memcpy(stream->outbuffer + stream->size, ptr, num);stream->size += num;// 2. 检测是否要刷新if(stream->flag == FLUSH_LINE && stream->size > 0 && stream->outbuffer[stream->size - 1] == '\n'){mfflush(stream);}return num;
}void mfclose(mFILE *stream)
{if(stream->size > 0){mfflush(stream);}close(stream->fileno);
}main.c
#include "my_stdio.h"
#include <stdio.h>
#include <string.h>
#include <unistd.h>int main()
{mFILE *fp = mfopen("./log.txt", "a");if(fp == NULL){return 1;}int cnt = 10;while(cnt){printf("write %d\n", cnt);char buffer[64];snprintf(buffer, sizeof(buffer),"hello message, number is : %d", cnt);cnt--;mfwrite(buffer, strlen(buffer), fp);mfflush(fp);sleep(1);}mfclose(fp);
}







![谷粒商城-分布式微服务 -集群部署篇[一]](http://pic.xiahunao.cn/谷粒商城-分布式微服务 -集群部署篇[一])



)

)


 与虚拟机的爱恨情仇)

