资料来源:火山引擎-开发者社区
DiT 模型与推理挑战
近年来,扩散模型(Diffusion Models)在生成式人工智能领域取得了突破性进展,尤其是在图像和视频生成方面表现卓越。基于 Transformer 的扩散模型(DiT, Diffusion Transformer)因其强大的建模能力和高质量输出,成为学术界和工业界的研究热点。DiT 模型通过逐步去噪的过程,从随机噪声生成逼真的图像或视频帧,结合 Transformer 架构的全局建模能力,能够捕捉复杂的语义特征和视觉细节,广泛应用于文本到图像、文本到视频、视频编辑等场景。
然而,DiT 模型在推理过程中面临诸多挑战,主要体现在计算效率、显存占用、模型架构复杂性及多模态融合等方面。这些痛点限制了 DiT 模型在实际场景中的部署和应用,尤其是在对实时性和资源效率有要求的生成任务中。
计算量大
- 序列长度激增:当 DiT 模型在处理高分辨率图像或长视频时,输入序列的长度会显著增长,导致自注意力(Self-Attention)机制的计算量呈平方级膨胀。
- 扩散步骤多:扩散模型需要多步迭代去噪(比如50步),每一步都需要执行完整的前向计算,累积的计算开销巨大。
模型多样
- 架构多样性:不同 DiT 模型的算子设计和连接方式上差异显著,例如注意力机制、卷积层或归一化层的组合方式各异,这增加了并行策略适配的复杂性。此外,不同阶段的算子对硬件设备的计算和显存特性要求不同,存在极大差异,导致同构推理性价比低下。例如,DiT 核心的 Transformer 模块属于计算密集型,高度依赖算力;而VAE(变分自编码器,Variational Auto-Encoder)则对显存容量和访存带宽要求极高。
实时性需求
- 视频生成的实时性瓶颈:基于DiT的视频生成模型(如 Sora)需要保证多帧间的连贯性,这就要求处理时空一致性。然而,这一需求使得单卡推理在面对高质量视频时,无法满足实时生成的要求。推理过程中的延迟,使得高清视频的生成体验较差,用户往往需要忍受长时间的等待,影响了使用体验。
火山引擎 veFuser 推理框架解决方案
为应对 DiT 模型推理的挑战,字节跳动依托自身强大的技术研发实力,精心构建了基于扩散模型的图像与视频生成推理服务框架 VeFuser,旨在提供低延迟、低成本的高质量图片与视频生成体验。
图片生成:低端硬件上的高效推理
veFuser 针对硬件资源的优化极为出色,即使在配备 24GB 显存的低端 GPU 上,也能高效运行当前主流的图像生成模型,如 FLUX.1-dev(12B) 和 HiDream-I1-Full(17B)。与开源实现相比,veFuser 将推理时间缩减了 83%,极大提升了生成效率。在 FLUX.1-dev 模型上,出图时间只需 3 秒;在 HiDream-I1-Full 模型上,出图时间只需 13 秒。这一性能突破不仅显著提升了用户体验,还通过降低对高端硬件的依赖,减少了部署和运营成本,提供了更具性价比的生成式 AI 解决方案。
视频生成:实时体验的先锋
在视频生成任务中,veFuser 展现了无与伦比的实时性能。针对某 14B 开源视频生成模型,veFuser 在 32 卡集群上可实现 16 秒延迟生成 5 秒 480p 视频的极致体验。若扩展至百卡集群,veFuser 甚至能实现 5 秒生成 5 秒视频的实时生成效果,接近实时渲染的行业前沿水准。这种低延迟特性为短视频、直播、虚拟现实等高实时性场景提供了强大支持。
veFuser 核心优势
降低计算复杂度与延迟
- 高性能算子:针对 Attention 算子进行了高度优化,实现细粒度的通信计算重叠。在 D、A、L、H 不同架构的 GPU 上,针对扩散模型常用的算子进行了深度调优,对计算密集算子进行无损的量化和稀疏化。
- 稀疏 Attention:打破传统自注意力机制对序列中所有元素进行全局计算的模式。在处理高分辨率图像或长视频的长输入序列时,它基于对数据特征的深入分析,运用特定的算法筛选出与当前计算任务最相关的关键信息。
攻克模型架构异构性难题
- 分布式架构:扩散模型的工作流往往包含多个独立的角色(如 Text Encoder、VAE 、LLM 等),各个阶段对显存、计算、带宽等不同资源的瓶颈不同。针对这一特点,我们为不同角色选择最适合的并行方法和资源配置,并将工作流看成一张 DAG。将耦合的一个工作流中的不同角色(如Encoder、VAE、DiT等),拆分为独立的微服务,并通过统一调度异步执行没有依赖的角色,比如 image encoder 和 text encoder。
- 异构部署:同时结合各个阶段对显存、计算、带宽等不同资源瓶颈,利用异构硬件的不同特性,优化部署成本。
- 灵活可扩展:支持自定义 pipeline 和服务组件,支持不同类型的模型推理的低成本接入。
突破实时性与扩展性限制
- 内存优化:veFuser 根据模型结构优化中间结果内存排布,消除算子激增导致的临时内存开销。在仅 24GB 显存的 GPU 上,veFuser 可流畅运行 720p 视频生成任务。
- 高效并行框架:集成多种并行框架,包括混合流水线并行(PipeFusion)、序列并行(USP 并行)和 CFG 并行,显著提升多卡扩展性。
- 通信效率提升:通过 veTurbo rpc (支持在 vpc 上实现虚拟 RDMA 传输通信协议)实现多角色的通信,同时针对 tensor 数据优化传输性能。
多 Lora 动态切换
Lora(Low Rank Adaptation)是内容生成任务中一个常用的插件能力,能够很好地控制生成内容的风格模式。然而,频繁地切换Lora往往会带来较高的开销。因此,veFuser 针对这一通用能力,实现了多 LoRA 动态切换功能,基于用户请求实现近乎无感的风格切换体验。
精度无损
通过严格的 GSB(Good - Same - Bad) 评测,veFuser 确保速度提升不会牺牲输出质量。无论是图像还是视频生成,veFuser 始终保持与传统框架相当或更优的生成效果,实现速度与品质的完美平衡。
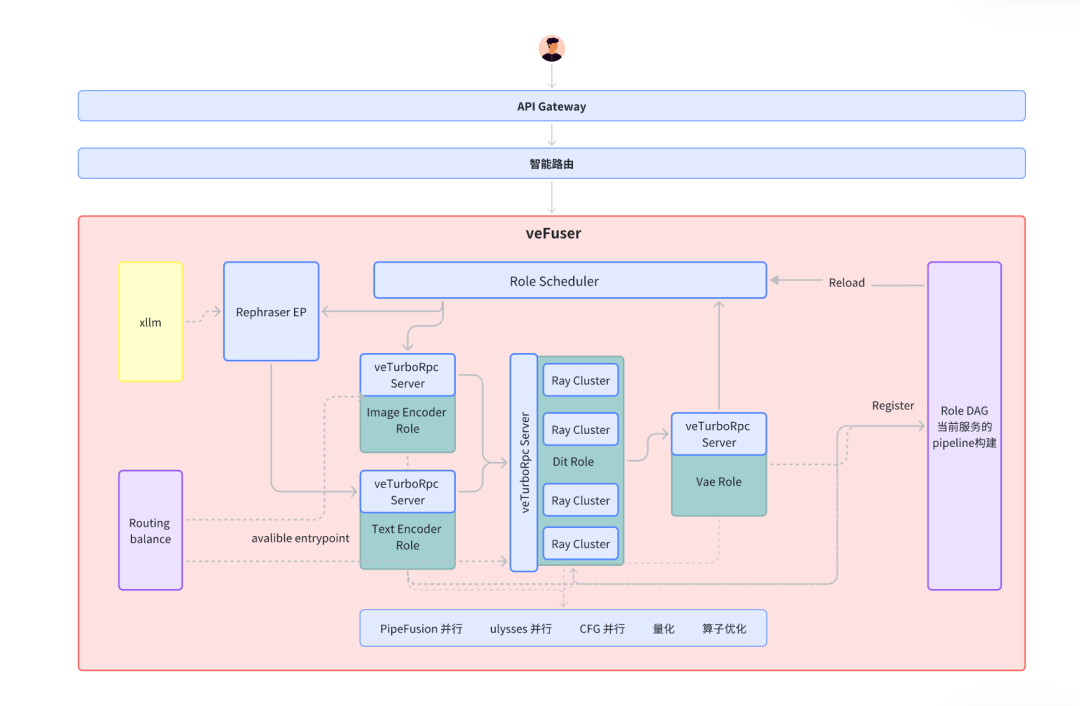
图1 veFuser 产品架构
veFuser 性能优势
某 14B 开源模型 视频生成任务-单机性能(Dit 单机 8 卡)
D卡
I2V (Image to Video,图生视频)性能相较于业内 SOTA 水平延时降低 50% 左右,480P 每 infer-steps 平均 1.8 秒,720P 每infer-steps 平均 5 秒。
T2V (Text to Video,文生视频)性能相较于业内 SOTA 水平延时降低 60% 左右,480P 每 infer-steps 平均 1.5 秒,720P 每 infer-steps 平均 4 秒。
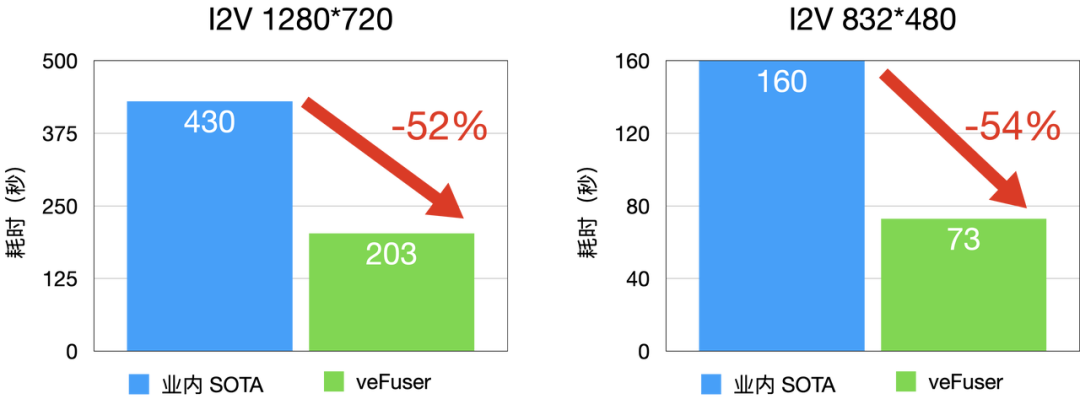
图2 I2V 延时分布(D卡)
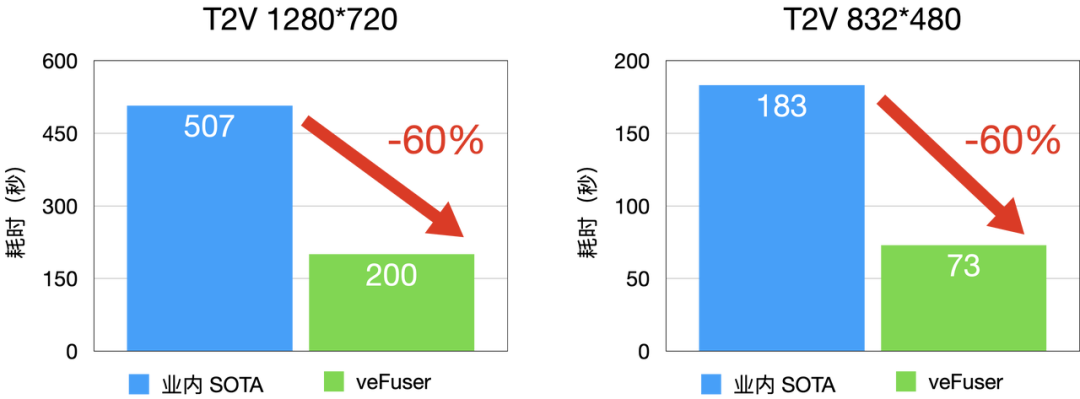
图3 T2V 延时分布(D卡)
A800
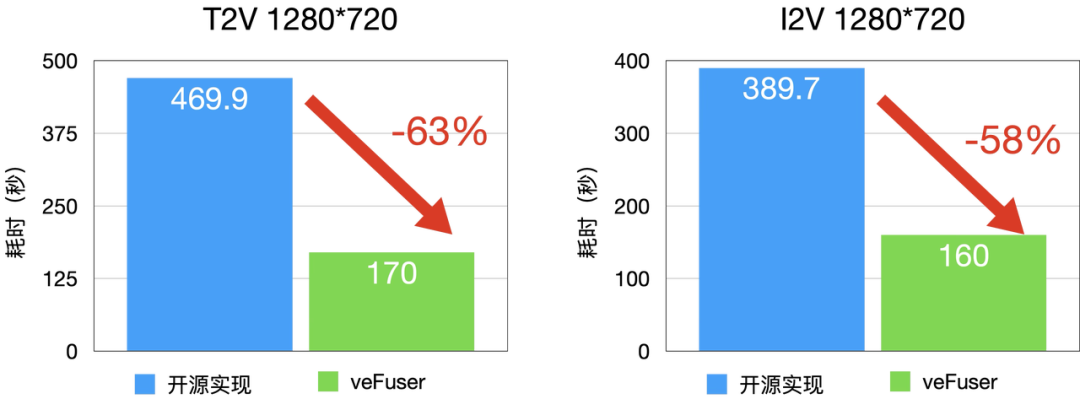
图4 I2V 和 T2V 延时分布(A800)
H20
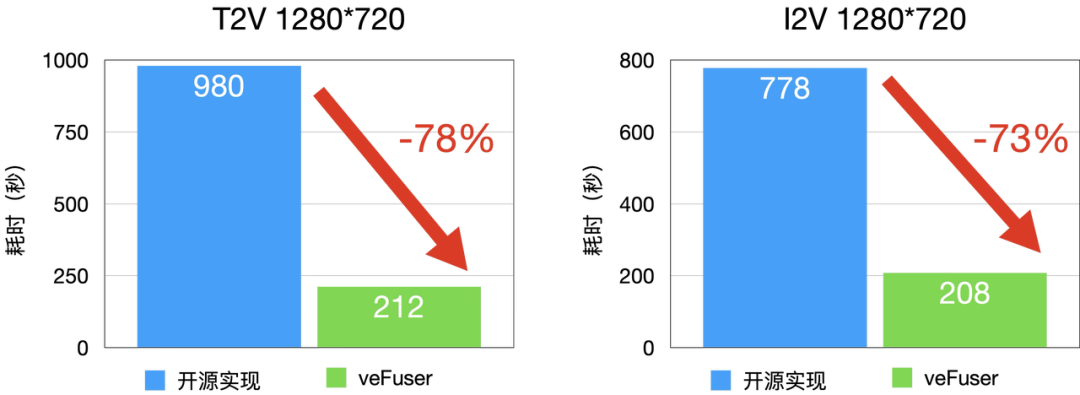
图5 I2V 和 T2V 延时分布(H20)
L20
- veFuser 详细延时分布:
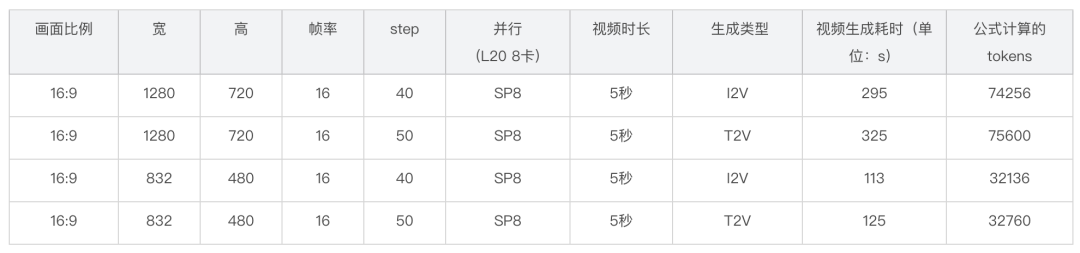
某 14B 开源模型 视频生成任务-多机扩展性能
多机延迟 - D 卡
借助 veFuser 对 CFG 并行的支持,即便 D 卡不具备 RDMA 网络,也能够达成近乎 TCO 无损的 16 卡并行效果,为计算任务提供高效且稳定的运行环境。
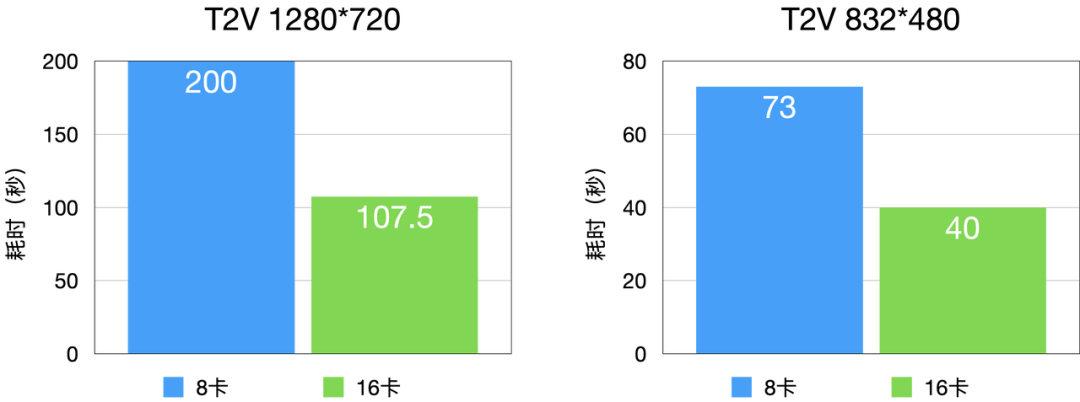
图6 T2V 延时分布(D卡)
多机延迟 - A100
- 与 D 卡相比,A100 具有 RDMA,这一优势使得计算集群的并行规模能够从 16 卡进一步拓展至 32 卡,显著提升了大规模并行计算的性能与效率。
- 通过多机部署,可以实现极低的延迟,比如 480P-5秒-T2V 在 A100 上最低耗时可以到 16 秒(32卡并行),vefuser 在 RDMA 互联硬件上具有非常好的扩展性。
- 以 A800 T2V 为例子进行说明,Dit 部分进行并行扩展:
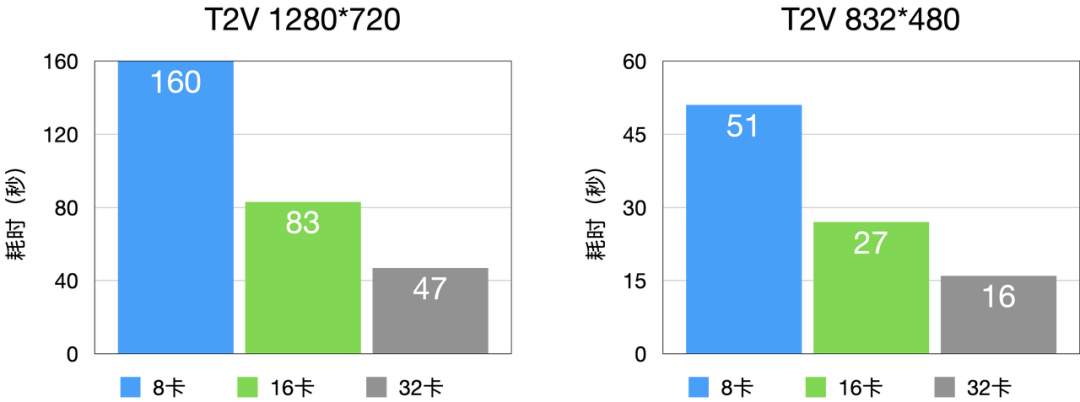
图7 T2V 延时分布(A100)
多机扩展加速比
如图8所示,从 8 卡到 32 卡可以实现近乎线性的加速比,在极大减少延迟的前提下,TCO 基本不变。
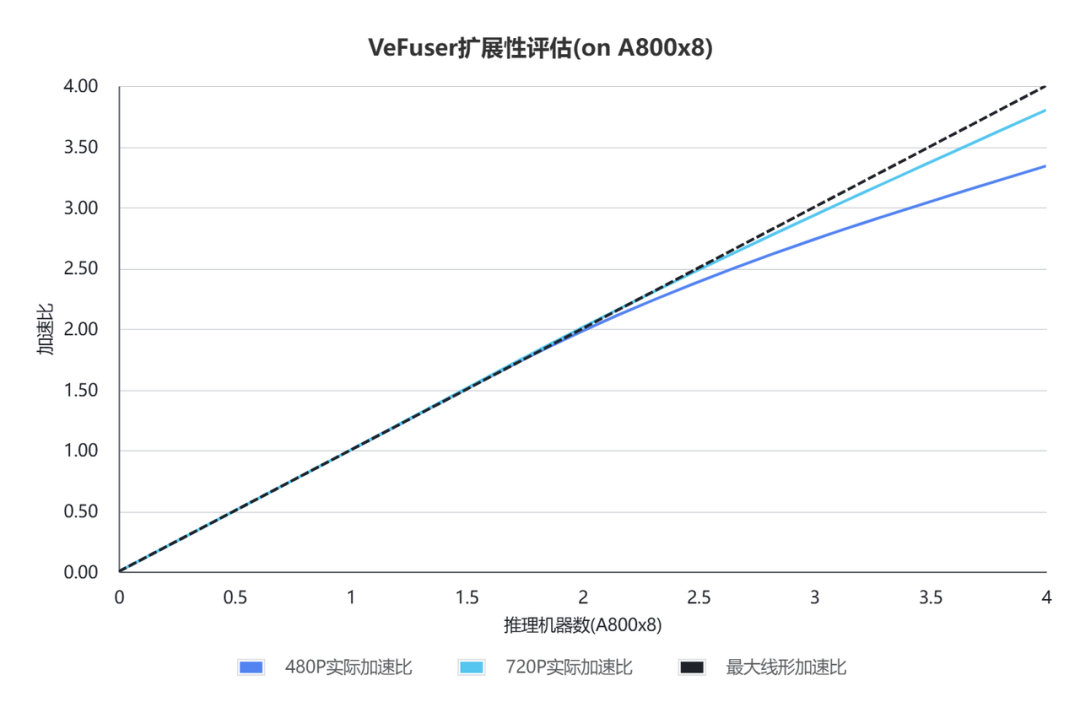
图8 VeFuser 扩展性评估(on A800x8)
按照当前的理论拓展性,当推理卡数增加到 128 张 A800 后,实际生图速度(蓝线)与实时生图所需速度(黑线)重合,如图9所示。表示在这个设置下,理论上可以实现视频生成时间小于等于视频的时间,达到实时生视频的效果。
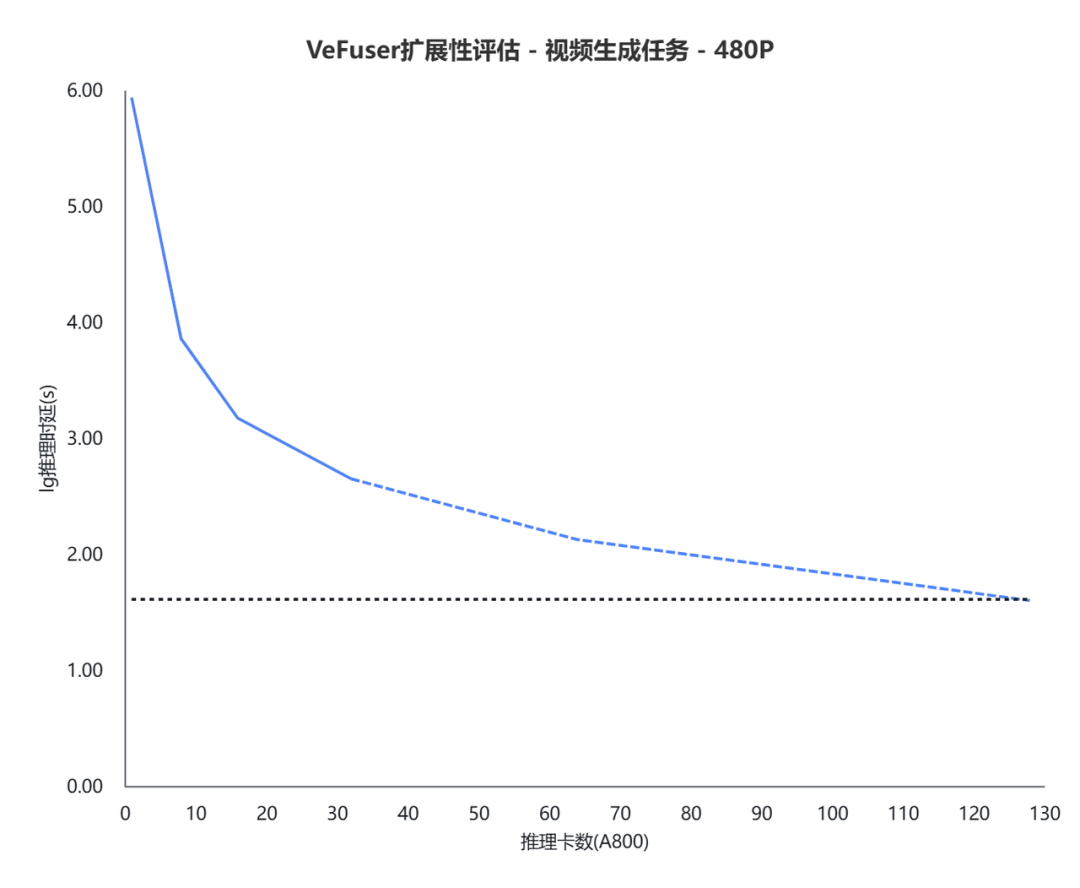
图9 VeFuser 扩展性评估 - 视频生成任务 - 480P(on A800)
FLUX.1 & HiDream 文生图任务-单机性能
- 对于 FLUX.1-dev 模型:
- 在 D 卡上性能相较于开源实现单卡延时降低 83% 左右,1024px 下生成单图的时间仅需 2.87s。
- 在 L20 上性能相较于开源实现单卡延时降低 76% 左右,1024px 下生成单图的时间仅需 6.22s。
- 对于 HiDream-I1-Full 模型:
- 在 D 卡上性能相较于开源实现单卡延时降低 54% 左右,四卡延时降低 83% 左右,1024px 下生成单图的时间仅 12.49s。
- 在 L20 上性能相较于开源实现单卡延时降低 57% 左右,四卡延时降低 86% 左右,1024px 下生成单图的时间仅 13.17s。
D卡
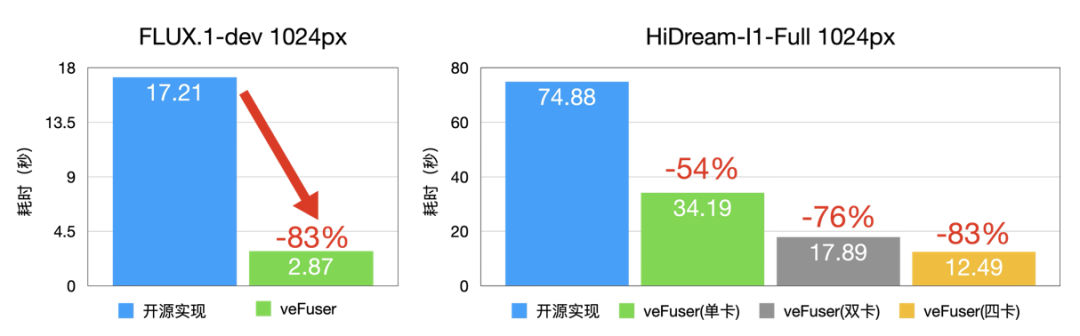
图10 模型生图速度(D卡)
L20
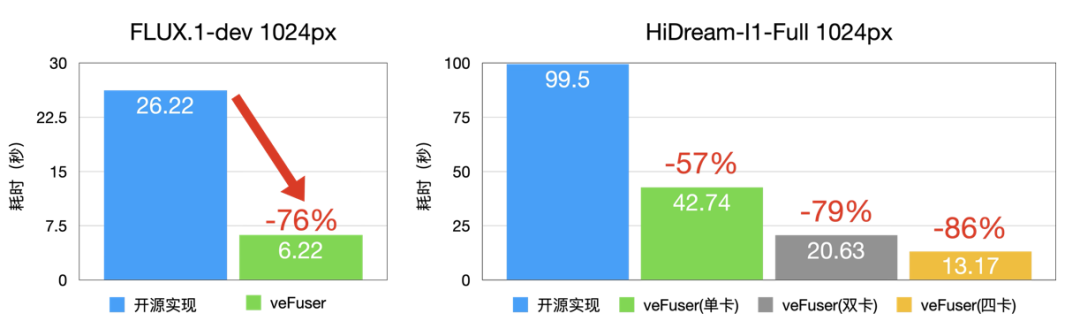
图11 模型生图速度(L20)
veFuser 生成效果:速度与质量兼得
火山引擎 veFuser 推理框架在加速 DiT 模型推理的同时,始终以高质量生成效果为核心目标,为用户提供高效且高质量的图像和视频生成体验。以下分别展示了使用开源模型原版与通过 veFuser 生成的视频和图像示例,在生成速度更快的情况下,veFuser 所生成的效果与原版一致。
- Prompt:在客厅里,一只毛茸茸的、眼睛明亮的小狗正在追逐一个玩具

图12 开源实现生成视频 VS veFuser生成视频
- Prompt: A steaming plate of fettuccine Alfredo

图13 开源实现生成图片 VS veFuser生成图片
总结与展望:veFuser 的持续创新与生态拓展
随着生成式人工智能领域的高速发展,新模型,新架构层出不穷。更多元的模型选择,更丰富的社区插件生态也共同推动了整个行业的蓬勃发展。在未来,veFuser 仍会持续迭代,在通用性,易用性,高效性等各个方面持续提升。
灵活兼容,快速迭代:持续适配新模型
针对未来 DiT 系列模型的多样化创新,veFuser 将持续构造更加通用化的模型服务框架以及模型推理框架,抽象模型结构,实现对各种不同模型结构的“即插即用”支持,避免过多重复的开发成本。
生态开放,功能拓展:支持更加丰富的插件生态
除了目前的 LoRA 支持外,veFuser 将结合社区需求,持续支持各类文生图/文生视频插件生态,允许用户自定义各种不同的插件模式,以实现生成效果的精准控制。
更极致的性能实现:推理速度,显存开销全面突破
通过低精度量化/模型蒸馏等方式,进一步减少推理过程的显存开销。同时充分结合不同算力卡型的硬件架构,定制化实现更高性能的推理算子,以实现更加极致的推理速度。
快速使用 veFuser
针对不同类型用户对视频生成的使用需求,火山引擎提供了两种便捷的接入方式:火山引擎机器学习平台(veMLP)和 火山方舟,分别适用于具备模型训练能力的专业用户和追求开箱即用体验的开发者。
veMLP:灵活定制,高效部署
体验链接:机器学习平台-火山引擎
对于有定制化训练和推理需求的用户,可以在 veMLP 上免费使用 veFuser。用户可以在平台中选择快速入门镜像,结合主流的开源模型进行快速部署,也可以将自己训练好的模型与推理框架集成,通过 veFuser 实现高效推理。
火山方舟:开箱即用,轻松生成高质量视频
体验链接:账号登录-火山引擎
如果用户更倾向于开箱即用的体验,火山方舟提供了基于 veFuser 推理加速的视频生成开源模型以及字节跳动自主研发的 Seedance 模型,可以直接登录方舟平台在模型广场中体验。同时,Seedance 模型还支持 API 接口调用,便于快速集成到业务系统中,适合短视频生成、内容创作、营销工具等场景的快速接入和规模化应用。
求解DF1-DF14,提供完整MATLAB代码)




)




)




的用法)

-Hive数据分析2)

