前言
当下遇到这样一个场景,由于订单数据量达到千万级别,采用分库分表进行优化,根据订单的热查条件:order_no订单编号进行分表,但是这样带来一个问题,用户查询自己的订单怎么查?由于分片键使用的order_no , 每次需要携带条件order_no才可以路由到对应的表,然而站在用户的查询角度只会携带user_id进行查询。文本将介绍如何采用:基因法+自定义多key分片 方案解决这个问题
一.前置知识
这里稍微普及一下什么是分库分表,分库分表分为垂直分 和 水平分 ,先说垂直方向概念如下
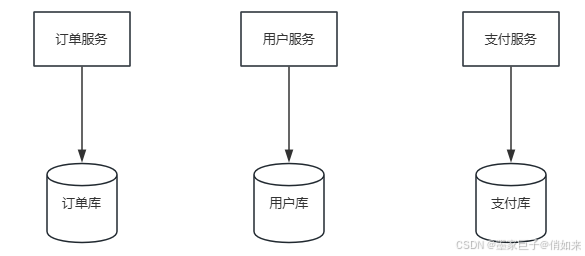
1.垂直分库
垂直分库 :通常按照业务维度把一个系统的数据库拆分成多个库,一般一个服务对应一个子库,比如有一电商系统可拆分为 : 订单服务 - 订单库 ,用户服务 - 用户库 ,支付服务 - 支付库 ,每个库中只包含自己业务领域类的相关表即可。
垂直分库的好处是:从数据库层面来说达到了数据隔离,职责分明的目的,同时把请求的压力分担到多个数据库中让数据库具备了更高的负载能力。这也是数据库性能提升的重要手段。
2.垂直分表
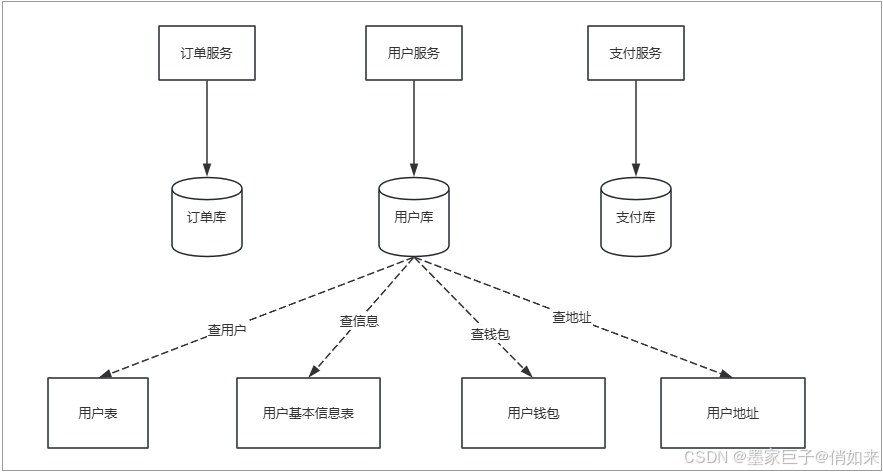
垂直分表是把大表按照字段(业务维度)拆分成多个小表,比如:一个用户表中包含了 用户认证相关的字段,用户基本信息,用户地址信息,用户钱包信息。很明显如果把用户相关的数据都塞到一张表那么这张表会特别庞大,难以维护,通常的做法是把这些表字段按照业务维度拆分如:用户基础表 ,用户认证表,用户钱包表,用户地址信息表。这些表是一对一的关系,可以使用相同的ID主键。
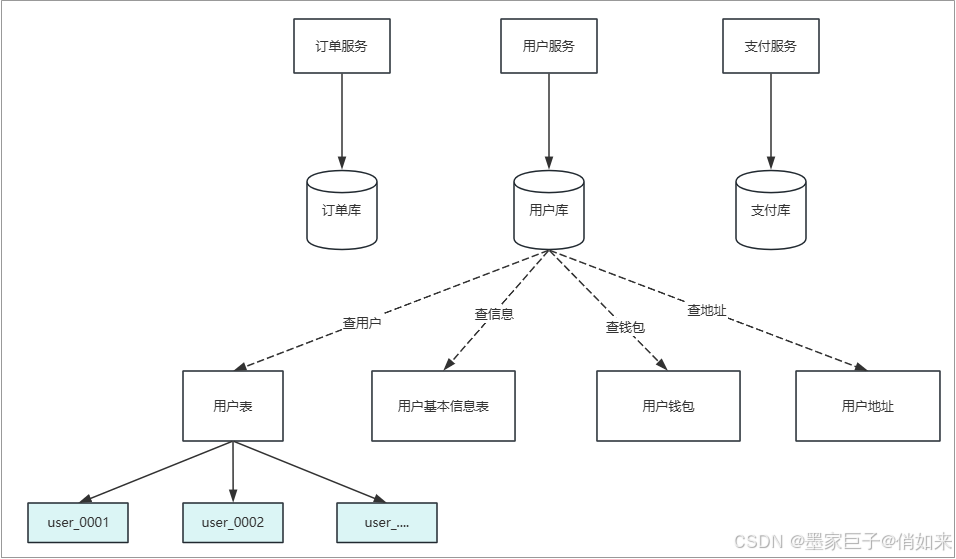
3.水平分表
垂直方向的拆分确实可以让单个库,或者单个表中的数据量变小,让请求分担到多个库或者多个表中,一定程度上是可以提升查询性能的,但是它解决不了大数据量的问题。
比如:一张表数据量一个亿,再怎么垂直拆分列每个表中的行始终是一个亿,我们知道对于Mysql这种关系型数据库而言它的性能瓶颈就是大表的磁盘IO,所以想要在大数据量的情况下查询不影响性能那么我们只能从水平上减少表的数据量 - 水平分表 ,
水平分表的方式有很多,常见的方案如下
- 按数据范围分:根据数据的某个范围(如时间、ID区间)划分,比如:订单表按 订单创建时间 分表:order_202301、order_202302。用户表按用户ID区间 分表:user_0_100w、user_100w_200w。这种分表适用于时间序列数据(如日志)
- Hash取模分表:对分片键(如用户ID)计算哈希值,再按哈希结果对表数量取模分片,如:用户表按 Hash(user_id ) % 4 分成 4 张表:user_0、user_1、user_2、user_3。这种分表不会有数据倾斜问题,但是扩容是一个麻烦事情(比如:4张表要扩充到5张表) ,不支持范围查询(如 BETWEEN 需跨多表查询)
- 一致性哈希:使用一致性哈希算法减少扩容时的数据迁移量,这种算法的优点是扩容时只需要迁移少量数据,缺点是实现稍微复杂。
- 复合分片 : 复合分片,组合多种分片策略(如先按范围再按哈希)比如:日志表先按 年月 分库,再按 user_id % 8 分表,兼顾查询效率和分布均匀性,但是复杂度高
- 按目录分片 :维护一个“路由表”记录分片键与物理表的映射关系,比如:订单表根据 order_id 查询路由表决定访问哪个分表,这种方式的问题是每次都要查询一下路由表,性能堪忧
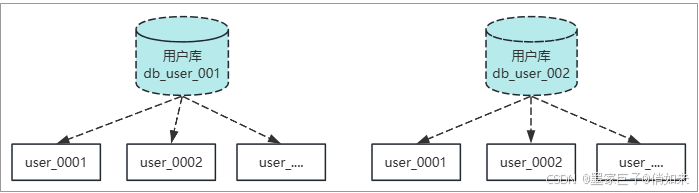
4.水平分库
水平分库主要解决单库表太多导致的数据库压力问题,比如数据量特别大导致分了10000个表全在一个数据库,那么该数据库的压力也会较大,那么可以把这些表分摊到多个库中,如下:
如果只是做分表那么我们需要1个分片键即可,如果要做分库分表那就需要2个分片键,一个用于数据库的分片,一个用于表的分片,比如:商品有 shop_id 店铺ID , order_no 订单编号,我们使用店铺ID分库,使用Order_no分表,那么就需要进行2次计算
- hash(shop_id) % 库的数量 来确定哪个库
- hash(order_no) % 表的数量 来确定哪个表
二.Sharding入门
如果不知道什么是ShardingJdbc的童鞋自己去官网上找补一下:https://shardingsphere.apache.org/document/5.2.1/cn/overview/
1.数据库准备
本文主要的目的是演示如何实现 :基因法+自定义多key分片,来支持多字段查询,为了不增加难度就不做分库,只做分表。假设我们有一个订单库 db-order , 该库中有2个表,t_order ; t_order_item ; 假设我们规划的分表数量为 2 ,那么就有了: t_order_0000 、t_order_0001 、t_order_item_0000 、t_order_item_0001 ; 订单明细和订单表采用相同的分片策略,他们的表结构分别如下
CREATE TABLE `t_order_0000` (`id` bigint NOT NULL COMMENT 'ID',`order_no` varchar(255) DEFAULT NULL COMMENT '单号',`shop_id` bigint DEFAULT NULL COMMENT '店家ID',`amount` decimal(10,2) DEFAULT NULL COMMENT '金额',`user_id` bigint DEFAULT NULL COMMENT '用户ID',`status` int DEFAULT NULL COMMENT '状态',PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;CREATE TABLE `t_order_item_0000` (`id` bigint NOT NULL COMMENT 'ID',`user_id` bigint DEFAULT NULL COMMENT '用户ID',`amount` decimal(10,2) DEFAULT NULL COMMENT '金额',`order_id` bigint DEFAULT NULL COMMENT '订单ID',`order_no` varchar(255) DEFAULT NULL COMMENT '编号',PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
- 问:为什么是t_order_0000 ,你也可以使用 t_order_0, 主要考虑如果要分上千张表
那么我们怎么分表呢?先来玩个简单的,我们使用 order_no 作为分片键,采用Hash取模算法,比如:order_no = A11111 , 那么计算Hash值: Hash(order_no) = 1907705760 , 那么 1907705760 % 2(表的数量) = 0 , 那么该条数据应该插入 t_order_0000 表。下面我们来看如何用程序实现
2.项目搭建整合Sharding
参考:https://shardingsphere.apache.org/document/5.2.1/cn/quick-start/shardingsphere-jdbc-quick-start/
本篇文章我们采用Sharding-Jdbc来做分表,首先需要搭建一个SpringBoot项目,然后去整合Sharding-jdbc,以及数据库驱动等,Sharding官方版本更新到5.5.0,但是阿里云仓库中最高版本是5.2.1,所以我这里采用的是5.2.1 , pom.xml文件如下
<parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>3.3.12</version><relativePath/>
</parent><dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><!-- Mybatis --><dependency><groupId>org.mybatis.spring.boot</groupId><artifactId>mybatis-spring-boot-starter</artifactId><version>3.0.3</version></dependency><!-- Mybatis Plus --><dependency><groupId>com.baomidou</groupId><artifactId>mybatis-plus-spring-boot3-starter</artifactId><version>3.5.5</version></dependency><!-- MySQL JDBC 驱动 --><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>8.0.27</version></dependency><!-- Druid 数据库连接池 --><dependency><groupId>com.alibaba</groupId><artifactId>druid</artifactId><version>1.2.20</version></dependency><!--shardingsphere--><dependency><groupId>org.apache.shardingsphere</groupId><artifactId>shardingsphere-jdbc-core-spring-boot-starter</artifactId><version>5.2.1</version></dependency><!-- shardingsphere和2.2不兼容,需要使用1.33,但是1.33和springboot 3.2.2 不兼容,所以自定义了 TagInspector和 UnTrustedTagInspector --><dependency><groupId>org.yaml</groupId><artifactId>snakeyaml</artifactId><version>1.33</version></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency>
</dependencies>这里引入了一个包 snakeyaml ,是因为 shardingsphere 引入了一个 2.2.版本snakeyaml , 启动会出现错误
启动出现的错误日志如下
Caused by: org.springframework.beans.BeanInstantiationException: Failed to instantiate [javax.sql.DataSource]: Factory method ‘shardingSphereDataSource’ threw exception with message: org.yaml.snakeyaml.representer.Representer: method ‘void ()’ not found
为了兼容我们采用1.33版本,但是1.33 和SpringBoot版本不兼容,会出现另外一个错误
Caused by: java.lang.ClassNotFoundException: org.yaml.snakeyaml.inspector.TagInspector
at java.base/jdk.internal.loader.BuiltinClassLoader.loadClass(BuiltinClassLoader.java:641)
at java.base/jdk.internal.loader.ClassLoaders$AppClassLoader.loadClass(ClassLoaders.java:188)
所以另外还需要做一个事情就是创建包org.yaml.snakeyaml.inspector把下面2个类拷贝进去
public interface TagInspector {boolean isGlobalTagAllowed(Tag tag);
}public final class UnTrustedTagInspector implements TagInspector {@Overridepublic boolean isGlobalTagAllowed(Tag tag) {return false;}
}
- TagInspector 是 SnakeYAML 库中的一个接口,它用于定义如何为 YAML 节点分配标签
接下来就是创建或生成 实体类 ,mapper,service那一套 ,这里不赘述了。
3.配置SpringBoot
接下来创建SpringBoot的启动类,和配置文件,我这里配置的比较简单,就开启了日志
mybatis-plus:configuration:map-underscore-to-camel-case: truelog-impl: org.apache.ibatis.logging.stdout.StdOutImpl # 打印SQL到控制台
logging:level:org.apache.shardingsphere: debugroot: info # 确保root日志级别不会覆盖
#spring:
# datasource:
# driver-class-name: com.mysql.cj.jdbc.Driver
# url: jdbc:mysql://localhost:3306/db-order?useUnicode=true&characterEncoding=UTF-8&serverTimezone=UTC
# username: root
# password: 123456
# type: com.alibaba.druid.pool.DruidDataSource
4.配置Sharding实现分表
参考文档:https://shardingsphere.apache.org/document/5.2.1/cn/user-manual/shardingsphere-jdbc/spring-boot-starter/rules/sharding/
参考官方案例进行配置调整,这里我创建了一个application.properties,使用yaml也是可以的没有任何区别,配置如下
# 模式-单机
spring.shardingsphere.mode.type=Standalone
# 类型JDBC
spring.shardingsphere.mode.repository.type=JDBC
# 打印SQL在控制台
spring.shardingsphere.props.sql-show=true
# 数据源的名字
spring.shardingsphere.datasource.names=db-order//=========配置数据源==============================================================
spring.shardingsphere.datasource.db-order.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.db-order.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.db-order.url=jdbc:mysql://localhost:3306/db-order?useUnicode=true&characterEncoding=UTF-8&serverTimezone=UTC
spring.shardingsphere.datasource.db-order.username=root
spring.shardingsphere.datasource.db-order.password=123456#=======配置 t_order 表的分表规则===============================================
# 节点配置 db-order.t_order_0000 ;db-order.t_order_001
spring.shardingsphere.rules.sharding.tables.t_order.actual-data-nodes=db-order.t_order_000$->{0..1}
# 分片的字段 order_no
spring.shardingsphere.rules.sharding.tables.t_order.table-strategy.standard.sharding-column=order_no
# 分片的算法名 hash_mod
spring.shardingsphere.rules.sharding.tables.t_order.table-strategy.standard.sharding-algorithm-name=hash_modspring.shardingsphere.rules.sharding.tables.t_order_item.actual-data-nodes=db-order.t_order_item_000$->{0..1}
spring.shardingsphere.rules.sharding.tables.t_order_item.table-strategy.standard.sharding-column=order_no
spring.shardingsphere.rules.sharding.tables.t_order_item.table-strategy.standard.sharding-algorithm-name=hash_mod# 配置分片的算法名 hash_mod 对应的算法 HASH_MOD(对应 : HashModShardingAlgorithm)
spring.shardingsphere.rules.sharding.sharding-algorithms.hash_mod.type=HASH_MOD
# 分表的数量
spring.shardingsphere.rules.sharding.sharding-algorithms.hash_mod.props.sharding-count=2
- 配置数据源 : 这里只采用一个数据库演示,db-order 如果要配置分库根据官方配置
- sharding-algorithm-name=hash_mod :这个 hash_mod 是我自定义的名字,他和下面的
sharding-algorithms.hash_mod.type=HASH_MOD中的hash_mod对应HASH_MOD才是算法名 - sharding-algorithms.hash_mod.type=HASH_MOD : 指定 hash_mod 使用的内置的分片算法
HASH_MOD,对应的算法在:HashModShardingAlgorithm#doSharding方法中,他的算法就是采用分片键.hashCode() % 分片数量
5.测试分表
编写测试类,往数据库中插入订单数据,注意:分片键 order_no一定要给值,否则它无法分片
@Testpublic void addOrder2(){IntStream.range(1,10).forEach(i->{Order order = new Order();order.setShopId(RandomUtils.nextLong());order.setAmount(new BigDecimal(i));order.setUserId((long) RandomUtils.nextInt(100000));String orderNo = RandomUtils.nextInt(1000000000)+"";order.setOrderNo(orderNo);order.setStatus(0);orderMapper.insert(order);OrderItem item = new OrderItem();item.setOrderId(order.getId());item.setAmount(order.getAmount());item.setOrderNo(orderNo);item.setUserId(order.getUserId());orderItemMapper.insert(item);});}@Testpublic void get2(){//携带OrderNo,根据OrderNo分片Order order = orderMapper.selectOne(new LambdaQueryWrapper<Order>().eq(Order::getOrderNo,"50833359") //必须带上.eq(Order::getShopId,5233312790420396172L));System.out.println(order);}
从控制台的SQL中可以看到数据进入了哪个表

数据库效果如下:你可以自己去计算一下order_no的hash值 % 表数量计算一下对不对

注意:在查询的时候必须携带order_no才可以
三.基因法+自定义多key分片
上面我们完成了基本的分表实现,可以根据order_no实现分片入表和查询对应的表,现在某用户想要查询自己的订单?哦豁,凉了,因为用户查询自己的订单肯定是要根据user_id查询的,而不是根据order_no 。那么这个时候就要采用基因法 和 多key分片 了。
1.什么是基因法
名字听起来牛逼,确实原理非常简单,所谓的基因法就是把需要参与分片的键拼在一起作为组合分片键,比如:我们使用order_no 分片后想要使用user_id作为查询条件,那么我们可以把user_id的后n位直接拼到order_no的末尾作为order_no,比如:order_no = A1111 , user_id = 2222222 , 我们取后四位作为基因,那么新的order_no = A1111_2222(固定位数的情况下可以不用分隔符) 。
这样一来实际用作分片的的值是 2222 % 表数量 ,当使用order_no作为查询条件的时候可以满足查询 A1111_2222 % 表数量 ,当使用user_id作为查询条件的时候 2222222 % 表数量,是不是都可以满足查询呢?
2.Sharding-Jdbc配置
现在的配置文件调整如下
spring.shardingsphere.mode.type=Standalone
spring.shardingsphere.mode.repository.type=JDBC
spring.shardingsphere.props.sql-show=truespring.shardingsphere.datasource.names=db-order
# 数据源配置
spring.shardingsphere.datasource.db-order.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.db-order.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.db-order.url=jdbc:mysql://localhost:3306/db-order?useUnicode=true&characterEncoding=UTF-8&serverTimezone=UTC
spring.shardingsphere.datasource.db-order.username=root
spring.shardingsphere.datasource.db-order.password=123456# 表的节点 : db-order.t_order_0000 、db-order.t_order_0001
spring.shardingsphere.rules.sharding.tables.t_order.actual-data-nodes=db-order.t_order_000$->{0..1}
# 多个键分片主分片是 order_no
spring.shardingsphere.rules.sharding.tables.t_order.table-strategy.complex.sharding-columns=order_no,user_id
# 算法的名字定义为 order_sharding
spring.shardingsphere.rules.sharding.tables.t_order.table-strategy.complex.sharding-algorithm-name=order_shardingspring.shardingsphere.rules.sharding.tables.t_order_item.actual-data-nodes=db-order.t_order_item_000$->{0..1}
spring.shardingsphere.rules.sharding.tables.t_order_item.table-strategy.complex.sharding-columns=order_no,user_id
spring.shardingsphere.rules.sharding.tables.t_order_item.table-strategy.complex.sharding-algorithm-name=order_sharding# 自定义的分片算法 OrderShardingAlgorithm
spring.shardingsphere.rules.sharding.sharding-algorithms.order_sharding.type=CLASS_BASED
spring.shardingsphere.rules.sharding.sharding-algorithms.order_sharding.props.algorithmClassName=org.example.sharding.algorithm.OrderShardingAlgorithm
# 策略是复合分片
spring.shardingsphere.rules.sharding.sharding-algorithms.order_sharding.props.strategy=complex
# 表数量
spring.shardingsphere.rules.sharding.sharding-algorithms.order_sharding.props.tableCount=2
# 主分片键
spring.shardingsphere.rules.sharding.sharding-algorithms.order_sharding.props.mainColum=order_no
- table-strategy.complex.sharding-columns=order_no,user_id : 分表策略采用多个字段分片
- order_sharding.props.algorithmClassName=org.example.sharding.algorithm.OrderShardingAlgorithm :自定义的分片算法类
- order_sharding.props.strategy=complex :采用复合分片策略
- order_sharding.props.mainColum=order_no : 主分片策略
3.自定义算法
首先我们需要定义自己的算法类 OrderShardingAlgorithm ,去实现 ComplexKeysShardingAlgorithm (复合键)算法类。该类提供了 doSharding 分片算法,我们主要在该方法中处理分片键
/*** 订单分片策略算法类*/
@Slf4j
public class OrderShardingAlgorithm implements ComplexKeysShardingAlgorithm<String>{private Properties props;//主分片键private static final String PROP_MAIN_COLUM = "mainColum";//表数量private static final String PROP_TABLE_COUNT = "tableCount";@Overridepublic Properties getProps() {return props;}@Overridepublic void init(Properties props) {//初始化配置this.props = props;}@Overridepublic Collection<String> doSharding(Collection<String> availableTargetNames, ComplexKeysShardingValue<String> complexKeysShardingValue) {Collection<String> result = new HashSet<>();String mainColum = props.getProperty(PROP_MAIN_COLUM);// 获取分片键的值Collection<String> mainColumValues = complexKeysShardingValue.getColumnNameAndShardingValuesMap().get(mainColum);//表数量int tableCount = Integer.parseInt(props.getProperty(PROP_TABLE_COUNT));//包含主分键 - 根据主分键分片if (CollectionUtils.isNotEmpty(mainColumValues)) {for (String columValue : mainColumValues) {columValue = org.apache.commons.lang.StringUtils.right(columValue, 4);//计算分片int hashCode = columValue.hashCode();int index = (int) Math.abs((long) hashCode) % tableCount;//左边填充 000String shardingTarget = StringUtils.leftPad(String.valueOf(index), 4, "0");result.add(shardingTarget);}//获取表return getMatchedTables(result, availableTargetNames);}//不包含主分键 - 使用其他分片键complexKeysShardingValue.getColumnNameAndShardingValuesMap().remove(mainColum);Collection<String> otherColums = complexKeysShardingValue.getColumnNameAndShardingValuesMap().keySet();if (CollectionUtils.isNotEmpty(otherColums)) {for (String colum : otherColums) {//拿到值Collection<String> otherColumValues = complexKeysShardingValue.getColumnNameAndShardingValuesMap().get(colum);for (String columValue : otherColumValues) {columValue = org.apache.commons.lang.StringUtils.right(columValue, 4);//计算分片int hashCode = columValue.hashCode();int index = (int) Math.abs((long) hashCode) % tableCount;//左边填充 000String shardingTarget = StringUtils.leftPad(String.valueOf(index), 4, "0");result.add(shardingTarget);}}//获取表return getMatchedTables(result, availableTargetNames);}return null;}/*** 获取表* @param results :分片索引* @param availableTargetNames :可用的表* @return :分片后的表*/private Collection<String> getMatchedTables(Collection<String> results, Collection<String> availableTargetNames) {Collection<String> matchedTables = new HashSet<>();for (String result : results) {matchedTables.addAll(availableTargetNames.parallelStream().filter(each -> each.endsWith(result)).collect(Collectors.toSet()));}return matchedTables;}}
init :方法是初始化方法,可以拿到 Properties 也就是我们的sharding的配置内容 , doSharding 方法的入参有2个
- availableTargetNames:可用的表名,也就是所有的表明,
- complexKeysShardingValue:复合键分片的值,比如:order_no 或者 user_id 的值在这个里面
那么sharding方法中的逻辑也不是很复杂,首选我们需要判断业务方是传入的order_no(主分片键) 还是 user_id 。
- 通过 complexKeysShardingValue 我们可以拿到主分片键以及其值,然后
截取后四位取其hashCode % 表数量就可以拿到分片的表,然后再左边填充 000之后,从 availableTargetNames中匹配对应的表返回。 - 如果业务方传入的是 user_id ,那么主分片键就是空的,代码会走下面的循环,一样的道理去那分片键的值 % 表数量,填充000后去匹配对应的表返回。
4.编写测试
因为使用了基因算法,那么我们在插入订单的时候的订单号就必须要携带user_id了,原理也比较简单,就是把userId的后 4 位追加到订单号后面,改造如下
order.setUserId((long) RandomUtils.nextInt(100000));
//基因法:订单号 = 订单号_userId后四位
String orderNo = RandomUtils.nextInt(10000)+"";
orderNo = orderNo+"_"+StringUtils.right(String.valueOf(order.getUserId()),4);
order.setOrderNo(orderNo);
在查询的时候我们可以通过order_no查询,也可以通过user_id查询
@Testpublic void get2(){//携带OrderNo,根据OrderNo分片Order order = orderMapper.selectOne(new LambdaQueryWrapper<Order>().eq(Order::getOrderNo,"6389_1649"));order = orderMapper.selectOne(new LambdaQueryWrapper<Order>().eq(Order::getUserId,"11649"));System.out.println(order);}
两次查询的SQL日志如下:
Actual SQL: db-order ::: SELECT id,order_no,shop_id,amount,user_id,status FROM t_order_0000 WHERE (order_no = ?) ::: [6389_1649]
Actual SQL: db-order ::: SELECT id,order_no,shop_id,amount,user_id,status FROM t_order_0000 WHERE (user_id = ?) ::: [11649]
总结
文章就写到这里,本文我们介绍了如何在SpringBoot环境中去整合ShardingJDBC,然后讲解了2个案例,一个是通过Hash取模的方式进行分表,这种方式的局限性就是当查询条件中没有指定该字段的时候Shrding会选择连表从所有表中去查询数据,性能非常差,所以我们有介绍了采用:基因法+自定义多key分片键的方式来实现多字段查询。
其实分库分表的知识点是非常多的,比如:分表后的ID如何全局唯一,分表后的历史数据如何迁移,如果分表后数据又爆满了如何扩容,分库后的分布式事务如何处理…等等。期待我在后续的章节一一道来吧,你的三连是我最大的动力哦。
忠告:水平方向的拆分一定是最后的优化手段,因为水平拆分后会带来很多其他问题。

:基于 PyTorch 的手写体识别案例手册)

频率求解与仿真实践(2))

)
,Hadoop, Spark, Hive 的关系)



)








