前言
过去一周,我司「七月在线」长沙分部的具身团队在机械臂和人形上并行发力
- 关于机械臂
一方面,在IL和VLA的路线下,先后采集了抓杯子、桌面收纳、插入耳机孔的数据,然后云端训-本地5090推理
二方面,在RL的路线下,通过复现UC伯克利的HIL-SERL先后在仿真、真机上抓方块 - 关于人形
一者,对于manipulation,本周暂先实现了通过VR遥操宇树G1采集数据
二者,对于locomotion,我司长沙具身团队的其中一个小组准备复现基于PBHC的KungfuBot
故为了和团队更好的复现之,我在解读完该论文之后,准备把其源码也好好解析下
而根据此文《KungfuBot——基于物理约束和自适应运动追踪的人形全身控制PBHC,用于学习打拳或跳舞(即RL下的动作模仿和运控)》可知,KungfuBot中的RL模块是基于ASAP实现的
故为了更好的复现KungfuBot,本文先来解读下ASAP目前已经对外开源的代码
根据ASAP的GitHub代码仓库可知,ASAP专注于学习敏捷的人形机器人全身技能,构建在HumanoidVerse多模拟器框架之上,其
- 支持多种物理模拟器:IsaacGym、IsaacSim、Genesis
- 实现人形机器人的运动追踪和全身控制
- 提供从仿真到现实的转移能力
- 模块化设计,支持算法、环境、模拟器的分离
┌─────────────────────────────────────────────────┐
│ 配置系统 (config/) │
│ base.yaml → algo/ → env/ → robot/ → rewards/ │
└─────────────┬───────────────────────────────────┘│ Hydra instantiate()▼
┌─────────────────────────────────────────────────┐
│ 环境层 (envs/) │
│ BaseTask ← locomotion/motion_tracking │
└─────────────┬───────────────────────────────────┘│ composition▼
┌─────────────────────────────────────────────────┐
│ 模拟器层 (simulator/) │
│ BaseSimulator ← IsaacGym/IsaacSim/Genesis │
└─────────────┬───────────────────────────────────┘│ used by▼
┌─────────────────────────────────────────────────┐
│ 算法层 (agents/) │
│ BaseAlgo ← PPO/DAGGER/DeltaA/ForceControl │
└─────────────────────────────────────────────────┘运行时调用顺序如下
1. train_agent.py::main()
2. ├── config加载 (Hydra)
3. ├── 模拟器选择 (IsaacGym/IsaacSim/Genesis)
4. ├── env实例化 (BaseTask子类)
5. │ ├── simulator实例化 (BaseSimulator子类)
6. │ ├── robot配置加载
7. │ └── terrain/obs/rewards设置
8. ├── algo实例化 (BaseAlgo子类)
9. │ ├── actor/critic网络创建
10. │ └── 数据缓冲区初始化
11. └── algo.learn() 训练循环第一部分 算法模块 agents/
包含
- train_agent.py: 训练智能体的主入口
train_agent.py: ├── hydra → 配置加载 ├── utils.config_utils → 配置预处理 ├── BaseTask → 环境创建 ├── BaseAlgo → 算法创建 └── wandb → 日志记录 - eval_agent.py: 评估智能体的主入口
提供实时键盘控制接口
支持力控制调试功能
可视化评估结果
agents模块的完整目录如下
agents/
├── base_algo/ # 算法基类定义
│ └── base_algo.py # BaseAlgo抽象基类
├── modules/ # 神经网络核心组件
│ ├── ppo_modules.py # PPO Actor/Critic网络
│ ├── modules.py # 通用神经网络模块
│ ├── encoder_modules.py # 编码器模块
│ ├── world_models.py # 世界模型实现
│ └── data_utils.py # 数据存储和GAE计算
├── callbacks/ # 实时分析和可视化系统
│ ├── base_callback.py # 回调基类
│ ├── analysis_plot_*.py # 各类分析绘图回调
│ └── analysis_plot_template.html # 实时可视化模板
├── ppo/ # 标准PPO算法
├── dagger/ # 模仿学习算法
├── decouple/ # 解耦合控制算法
├── delta_a/ # ASAP核心创新:增量学习
├── delta_dynamics/ # Delta动力学模型
├── force_control/ # 力感知控制算法
├── mppi/ # 模型预测路径积分控制
└── ppo_locomanip.py # 运动操作专用PPO1.1 模块组件agents/modules/
1.1.1 ppo_modules.py: PPO算法的Actor-Critic网络
1.1.2 modules.py: 通用神经网络模块
1.1.3 encoder_modules.py: 编码器模块
1.1.4 world_models.py: 世界模型实现
1.1.5 data_utils.py: 数据处理工具,包含经验回放缓冲区
// 待更
1.2 回调系统 agents/callbacks/
**分析和可视化:**
- **analysis_plot_*.py**: 各种分析图表生成
- **base_callback.py**: 回调基类
- 支持力估计、运动分析、开环跟踪等多种分析
1.3 模仿学习:DAgger 算法实现(dagger.py)
本文件实现了 DAgger(Dataset Aggregation)模仿学习算法,是 ASAP 框架中用于“模仿学习/专家演示学习”的核心类。它让智能体在自己的策略下探索环境,并在这些状态下查询专家动作,逐步聚合数据,提升策略泛化能力
整个算法的流程为
- 初始化:加载学生和专家网络,准备数据存储
- 训练循环:
用学生策略探索环境,记录每一步的状态和专家动作
用专家动作作为标签,训练学生策略模仿专家
记录和可视化训练过程 - 评估:支持回调式评估和推理
DAgger(BaseAlgo)
- 继承自 BaseAlgo,拥有统一的 setup、learn、evaluate_policy 等接口
- 关键成员变量包括:
- self.actor:待训练的策略网络
- self.gt_actor:专家(教师)策略网络
- self.optimizer:优化器
- self.storage:数据存储(经验回放)
- self.writer:Tensorboard 日志
- self.eval_callbacks:评估回调
- self.episode_env_tensors:环境统计
1.3.1 setup:模仿学习中"学生-教师"双网络架构的实现
该方法主要
- 网络初始化:创建学生网络(需要训练的actor)和教师网络(提供专家示范的gt_actor)
- 优化器设置:为学生网络配置Adam优化器
- 存储初始化:设置用于存储轨迹数据的RolloutStorage,注册各种数据类型的存储键
- 统计跟踪:初始化用于跟踪训练过程中各种统计信息的变量和缓冲区
即初始化 RolloutStorage,注册观测、动作、专家动作等数据字段
具体而言
- 方法开始时通过日志记录初始化过程,然后创建两个关键的神经网络组件
第一个是学习者网络 (`self.actor`),它是需要被训练的策略网络,使用当前配置中的网络架构参数进行初始化
第二个是专家网络 (`self.gt_actor`),它代表"ground truth"或教师策略,不仅使用专门的网络配置,还通过 `teacher_actor_network_load_dict` 加载预训练的权重def setup(self):logger.info("Setting up Dagger") # 记录开始设置DAgger算法的日志信息# 从配置中提取演员网络的配置字典actor_network_dict = dict(actor=self.config.network_dict['actor'])
最终,分别创建学生actor、教师gt_actor# 从配置中提取教师演员网络的配置字典teacher_actor_network_dict = dict(actor=self.config.network_dict['teacher_actor'])# 从配置中提取教师演员网络的加载配置字典teacher_actor_network_load_dict = dict(actor=self.config.network_load_dict['teacher_actor'])
这种设计使得专家网络能够在训练过程中为学习者提供高质量的示范动作# 创建学生演员网络(PPO演员,固定标准差)self.actor = PPOActorFixSigma(self.algo_obs_dim_dict, actor_network_dict, {}, self.num_act)# 创建教师演员网络(ground truth演员,用于提供专家示范)self.gt_actor = PPOActorFixSigma(self.algo_obs_dim_dict, teacher_actor_network_dict, teacher_actor_network_load_dict, self.num_act) - 网络初始化完成后,代码将两个网络都移动到指定的计算设备上,确保训练过程中的计算效率
# 将学生演员网络移动到指定设备(CPU或GPU)self.actor.to(self.device)# 将教师演员网络移动到指定设备(CPU或GPU)self.gt_actor.to(self.device) - 接下来,为学习者网络创建 Adam 优化器,这是训练过程中唯一需要更新参数的网络,而专家网络的参数保持固定
# 创建Adam优化器来训练学生演员网络self.optimizer = optim.Adam(self.actor.parameters(), lr=self.learning_rate)logger.info(f"Setting up Storage") # 记录开始设置存储的日志信息 - 然后,方法初始化了一个专门的存储系统 `RolloutStorage`,用于管理训练数据的收集和批处理
存储系统的设计特别体现了 DAgger 算法的数据需求
首先,它为所有观测变量分配存储空间
然后注册两套完整的动作相关数据:# 创建回合存储对象,用于存储轨迹数据self.storage = RolloutStorage(self.env.num_envs, self.num_steps_per_env)## Register obs keys # 注册观测键# 遍历算法观测维度字典,为每个观测类型注册存储键for obs_key, obs_dim in self.algo_obs_dim_dict.items():self.storage.register_key(obs_key, shape=(obs_dim,), dtype=torch.float)
一套用于学习者的动作、动作概率、动作均值和方差
# 注册学生演员的动作存储键self.storage.register_key('actions', shape=(self.num_act,), dtype=torch.float)# 注册学生演员的动作对数概率存储键self.storage.register_key('actions_log_prob', shape=(1,), dtype=torch.float)# 注册学生演员的动作均值存储键self.storage.register_key('action_mean', shape=(self.num_act,), dtype=torch.float)# 注册学生演员的动作标准差存储键self.storage.register_key('action_sigma', shape=(self.num_act,), dtype=torch.float)
这种并行存储机制使得算法能够在每个时间步同时记录学习者的行为和专家在相同状态下的示范行为,为后续的监督学习提供配对的训练数据# 注册教师演员的动作存储键(ground truth actions)self.storage.register_key('gt_actions', shape=(self.num_act,), dtype=torch.float)# 注册教师演员的动作对数概率存储键self.storage.register_key('gt_actions_log_prob', shape=(1,), dtype=torch.float)# 注册教师演员的动作均值存储键self.storage.register_key('gt_action_mean', shape=(self.num_act,), dtype=torch.float)# 注册教师演员的动作标准差存储键self.storage.register_key('gt_action_sigma', shape=(self.num_act,), dtype=torch.float) - 最后,方法初始化了训练过程中的统计和监控组件
这包括用于记录回合信息的列表,以及使用双端队列实现的滑动窗口统计,可以跟踪最近100个回合的奖励和长度
同时,为每个并行环境分配了当前奖励总和和回合长度的张量,支持多环境并行训练的实时统计# 初始化回合信息列表,用于存储每个回合的统计信息self.ep_infos = []# 创建奖励缓冲区,最多存储100个回合的奖励(用于计算平均奖励)self.rewbuffer = deque(maxlen=100)# 创建长度缓冲区,最多存储100个回合的长度(用于计算平均长度)self.lenbuffer = deque(maxlen=100)# 初始化当前奖励累计张量,为每个环境跟踪当前回合的奖励总和self.cur_reward_sum = torch.zeros(self.env.num_envs, dtype=torch.float, device=self.device)# 初始化当前回合长度张量,为每个环境跟踪当前回合的步数self.cur_episode_length = torch.zeros(self.env.num_envs, dtype=torch.float, device=self.device)
1.3.2 learn:训练主循环,分为数据采集和训练两个阶段
每次迭代:
- _rollout_step:用当前策略与环境交互,收集状态、动作、专家动作等数据
- _training_step:用行为克隆损失(BC Loss)训练 actor,使其输出尽量接近专家动作
- 日志记录与模型保存
具体而言
- 首先,如果设置了 `init_at_random_ep_len`,会将环境的 episode 长度缓冲区随机初始化,以增加训练多样性
接着,环境被重置,获得初始观测,并将所有观测张量移动到指定设备(如 GPU),确保后续计算高效def learn(self):# 如果需要在随机的episode长度初始化,则对环境的episode长度缓冲区进行随机赋值if self.init_at_random_ep_len:self.env.episode_length_buf = torch.randint_like(self.env.episode_length_buf, high=int(self.env.max_episode_length))# 重置所有环境,获取初始观测obs_dict = self.env.reset_all()# 将所有观测数据转移到指定设备(如GPU或CPU)for obs_key in obs_dict.keys():obs_dict[obs_key] = obs_dict[obs_key].to(self.device) - 随后,模型被切换到训练模式
主循环根据 `num_learning_iterations` 控制迭代次数,每次迭代都记录起始时间# 设置模型为训练模式self._train_mode()
每一轮,首先通过 `_rollout_step` 与环境交互,采集一批新数据,并返回最新的观测# 获取本次学习的迭代次数num_learning_iterations = self.num_learning_iterations# 计算总的迭代次数tot_iter = self.current_learning_iteration + num_learning_iterations# 遍历每一次学习迭代# for it in track(range(self.current_learning_iteration, tot_iter), description="Learning Iterations"):for it in range(self.current_learning_iteration, tot_iter):# 记录本次迭代的起始时间self.start_time = time.time()
然后调用 `_training_step`,对采集到的数据进行行为克隆(BC)训练,得到平均损失# 进行一次rollout,返回新的观测(必须更新,否则一直用初始观测)obs_dict = self._rollout_step(obs_dict)
完成训练后,记录本轮训练所用时间# 执行一次训练步骤,返回平均BC损失mean_bc_loss = self._training_step()# 记录本次迭代的结束时间self.stop_time = time.time()# 计算本次学习所用时间self.learn_time = self.stop_time - self.start_time - 每轮结束后,会整理日志信息(如当前迭代数、采集和训练时间、平均损失、奖励等)
并调用 `_post_epoch_logging` 进行可视化和记录
如果当前迭代数满足保存间隔条件,还会保存模型检查点
每轮结束后,episode 相关信息会被清空,为下次迭代做准备 - 循环结束后,更新当前的学习迭代计数,并再次保存最终模型
整体来看,该方法实现了 DAgger 算法的标准训练流程,包括数据采集、模型训练、日志记录和模型保存等关键步骤
1.3.3 _rollout_step
- 用 actor 采样动作与环境交互,同时用 gt_actor 计算同一状态下的专家动作
- 将观测、动作、专家动作等信息存入 storage
- 统计奖励、episode 长度等信息
1.3.4 _training_step
- 从 storage 生成小批量数据
- 计算行为克隆损失(BC Loss):均方误差,目标是让 actor 输出接近专家动作
- 反向传播并优化 actor 网络
1.3.5 日志与评估
- _post_epoch_logging:详细记录训练过程中的损失、奖励、性能等信息,支持 Tensorboard 和 Rich 控制台美化
- evaluate_policy:支持评估模式,结合回调机制灵活扩展评估逻辑
1.4 PPO:标准实现与运动操作专用PPO的实现
1.4.1 PPO的标准实现
这段代码实现了 PPO(Proximal Policy Optimization)强化学习算法的主类。它负责整个算法的生命周期管理,包括初始化、模型和优化器的构建、数据存储、训练循环、模型保存与加载、评估流程等
1.4.1.1 __init__
- 在 `__init__` 构造函数中,PPO 类会初始化环境、配置、日志记录器(用于 TensorBoard)、以及一些用于统计和追踪训练过程的变量。它还会初始化奖励和回合长度的缓冲区,用于后续的统计分析
- `_init_config` 方法会从配置对象中提取所有关键超参数,包括环境数量、观测和动作维度、学习率、损失系数、折扣因子等,确保算法的灵活性和可配置性
1.4.1.2 setup方法:调用 `_setup_models_and_optimizer` 和 `_setup_storage`
`setup` 方法会调用 `_setup_models_and_optimizer` 和 `_setup_storage`,分别初始化 actor/critic 网络及其优化器,以及 rollout 数据存储结构
- 模型采用 PPOActor 和 PPOCritic 两个神经网络,优化器使用 Adam
- 数据存储结构会注册所有需要追踪的张量,包括观测、动作、奖励、优势等
1.4.1.3 训练主循环在 `learn` 方法
简言之,训练主循环在 `learn` 方法中实现。每次迭代会先进行 rollout(与环境交互收集数据),然后进行训练步骤(mini-batch SGD),并记录训练过程中的各种统计信息。训练过程中会定期保存模型和优化器状态,便于断点恢复
具体而言
- 首先,如果配置了 `init_at_random_ep_len`,会将环境的 episode 长度缓冲区随机初始化,这有助于增加训练的多样性
def learn(self):# 如果需要在随机的episode长度初始化,则对环境的episode长度缓冲区进行随机赋值if self.init_at_random_ep_len:self.env.episode_length_buf = torch.randint_like(self.env.episode_length_buf, high=int(self.env.max_episode_length)) - 接着,环境会被重置,获得初始观测
并将所有观测张量移动到指定的设备(如 GPU 或 CPU),以确保后续计算的高效性# 重置所有环境,获取初始观测obs_dict = self.env.reset_all()# 将每个观测都转移到指定的设备上(如GPU或CPU)for obs_key in obs_dict.keys():obs_dict[obs_key] = obs_dict[obs_key].to(self.device) - 随后,模型被切换到训练模式(`self._train_mode()`),以启用如 dropout、BN 等训练相关的行为
主循环根据当前迭代次数和总训练迭代数进行# 设置模型为训练模式self._train_mode()
每次迭代包括以下步骤:# 获取本次学习的迭代次数num_learning_iterations = self.num_learning_iterations# 计算总的迭代次数(当前迭代数 + 本次要迭代的次数)tot_iter = self.current_learning_iteration + num_learning_iterations
1. 记录当前时间,便于后续统计训练耗时
2. 调用 `_rollout_step` 与环境交互,收集一批数据(观测、动作、奖励等),并返回最新的观测# 不使用track进度条,因为会和motion loading bar冲突# for it in track(range(self.current_learning_iteration, tot_iter), description="Learning Iterations"):for it in range(self.current_learning_iteration, tot_iter):# 记录本次迭代的起始时间self.start_time = time.time()
3. 调用 `_training_step`,对采集到的数据进行策略和价值网络的训练# 进行一次rollout,返回新的观测(必须更新,否则一直用初始观测)obs_dict = self._rollout_step(obs_dict)
4. 记录本次迭代的耗时,并将相关统计信息(如损失、采集时间、奖励等)打包到 `log_dict`,用于日志记录和可视化# 进行一次训练步骤,返回损失字典loss_dict = self._training_step()
5. 每隔 `save_interval` 次迭代保存一次模型和优化器状态,便于断点恢复# 记录本次迭代的结束时间self.stop_time = time.time()# 计算本次学习所用时间self.learn_time = self.stop_time - self.start_time# 日志信息字典,包含当前迭代、损失、采集和学习时间、奖励等log_dict = {'it': it,'loss_dict': loss_dict,'collection_time': self.collection_time,'learn_time': self.learn_time,'ep_infos': self.ep_infos,'rewbuffer': self.rewbuffer,'lenbuffer': self.lenbuffer,'num_learning_iterations': num_learning_iterations}# 执行日志记录self._post_epoch_logging(log_dict)
6. 清空本轮的 episode 信息缓存,为下轮训练做准备# 每隔save_interval步保存一次模型if it % self.save_interval == 0:self.save(os.path.join(self.log_dir, 'model_{}.pt'.format(it)))# 清空本轮收集的episode信息self.ep_infos.clear() - 循环结束后,更新当前的训练迭代计数,并再次保存一次模型,确保所有训练进度都被持久化
# 累加当前学习迭代次数self.current_learning_iteration += num_learning_iterations# 保存最终模型self.save(os.path.join(self.log_dir, 'model_{}.pt'.format(self.current_learning_iteration)))
1.4.1.4 rollout (采样和数据收集)的实现:_rollout_step与_actor_rollout_step
rollout 过程由 `_rollout_step` 实现——_rollout_step又会调用_actor_rollout_step,负责与环境交互、收集数据、处理奖励和终止信息,并将数据写入存储
具体而言,
- 它首先在 `torch.inference_mode()` 上下文中运行,这样可以避免梯度计算,提高推理效率。方法内部通过循环 `self.num_steps_per_env` 次,每次循环代表智能体在环境中的一步
def _rollout_step(self, obs_dict):# 在推理模式下,不计算梯度,提升效率with torch.inference_mode():# 遍历每个环境步数for i in range(self.num_steps_per_env):# 初始化策略状态字典policy_state_dict = {} - 在每一步中
首先通过 `_actor_rollout_step` 计算当前观测下的动作及相关策略信息
并通过 `_critic_eval_step` 评估当前状态的价值# 通过actor获取动作及相关策略信息,存入policy_state_dictpolicy_state_dict = self._actor_rollout_step(obs_dict, policy_state_dict)
所有与观测和策略相关的数据都会被存储到 `self.storage`,以便后续训练使用# 通过critic评估当前状态的价值values = self._critic_eval_step(obs_dict).detach()# 将价值信息加入策略状态字典policy_state_dict["values"] = values
随后,智能体根据动作与环境交互,获得新的观测、奖励、终止信号和额外信息# 将观测信息存入rollout存储for obs_key in obs_dict.keys():self.storage.update_key(obs_key, obs_dict[obs_key])# 将策略相关信息存入rollout存储for obs_ in policy_state_dict.keys():self.storage.update_key(obs_, policy_state_dict[obs_])
并将这些数据转移到设备上(如 GPU)# 获取当前动作actions = policy_state_dict["actions"]# 构造actor_state字典actor_state = {}actor_state["actions"] = actions# 与环境交互,获得新的观测、奖励、done标志和额外信息obs_dict, rewards, dones, infos = self.env.step(actor_state)# 将新的观测转移到指定设备for obs_key in obs_dict.keys():obs_dict[obs_key] = obs_dict[obs_key].to(self.device)# 奖励和done也转移到设备rewards, dones = rewards.to(self.device), dones.to(self.device) - 奖励会根据是否有超时(`time_outs`)进行修正,确保奖励的准确性
每一步的数据(奖励、终止信号等)都会被存储,并通过 `self._process_env_step` 处理智能体和价值网络的重置
若启用了日志记录,还会统计每个 episode 的奖励和长度,并在 episode 结束时重置相关统计量 - 循环结束后,方法会记录采集数据所用的时间,并调用 `_compute_returns` 计算每一步的回报(returns)和优势(advantages)
这些数据随后批量存储到 `self.storage`,为后续的策略优化做准备# 为训练准备数据,计算returns和advantagesreturns, advantages = self._compute_returns(last_obs_dict=obs_dict,policy_state_dict=dict(values=self.storage.query_key('values'), dones=self.storage.query_key('dones'), rewards=self.storage.query_key('rewards'))) - 最终,方法返回最新的观测字典
# 返回最新的观测字典return obs_dict
1.4.1.5 GAE(广义优势估计):在 `_compute_returns` 方法中实现
优势和回报的计算采用 GAE(广义优势估计),在 `_compute_returns` 方法中实现,能够有效降低策略梯度的方差
- 首先,方法会用当前环境的最后一个观测(`last_obs_dict`)通过价值网络(critic)计算最后状态的价值 `last_values`
并将所有相关张量(values、dones、rewards、last_values)移动到指定设备(如 GPU)def _compute_returns(self, last_obs_dict, policy_state_dict):"""计算每一步的回报(returns)和优势(advantages),用于PPO训练使用广义优势估计(GAE)来降低策略梯度的方差。"""# 用critic网络评估最后一个观测的状态价值,并去除梯度last_values = self.critic.evaluate(last_obs_dict["critic_obs"]).detach()# 初始化优势为0advantage = 0# 从策略状态字典中获取values、dones和rewardsvalues = policy_state_dict['values']dones = policy_state_dict['dones']rewards = policy_state_dict['rewards']# 将所有张量转移到指定设备(如GPU)last_values = last_values.to(self.device)values = values.to(self.device)dones = dones.to(self.device)rewards = rewards.to(self.device) - 随后,初始化一个与 values 形状相同的 returns 张量,用于存储每一步的回报
# 初始化returns张量,形状与values相同returns = torch.zeros_like(values) - 为方便大家更好的理解,我直接引用此文《ChatGPT技术原理解析:从RL之PPO算法、RLHF到GPT4、instructGPT》的中的「3.3 针对「对话序列/奖励值序列/values/DSC优势函数/returns」的一个完整示例」内容 给大家解释说明下
首先,GAE的计算公式为
且如此文所说,考虑到有

故,实际计算的时候,为减少计算量,可以先计算A_7,再分别计算A_6、A_5、A_4、A_3、A_2、A_1
其次,再回顾一下TD误差的含义:δ_1 = r1 + γV_old(2) - V_old(1)
比如对于上式:实际获得的即时奖励 r1 加上折扣后的未来奖励预测 γV_old(2),再减去我们原先预测的当前时间步的奖励 V_old(1),这就是后者的预测与前者实际经验之间的差距
SO,核心计算在一个反向循环中完成(从最后一步到第一步)。对于每一步,方法会判断下一个状态是否为终止状态(`next_is_not_terminal`),并据此计算 TD 残差(delta)
优势(advantage)通过递归方式累加,结合了当前步的 TD 残差和未来步的优势,体现了 GAE 的思想# 获取步数num_steps = returns.shape[0]# 反向遍历每一步,计算GAE优势和回报for step in reversed(range(num_steps)):# 最后一步的next_values用last_values,其余用下一步的valuesif step == num_steps - 1:next_values = last_valueselse:next_values = values[step + 1]# 判断下一步是否为终止状态next_is_not_terminal = 1.0 - dones[step].float()# 计算TD残差delta = rewards[step] + next_is_not_terminal * self.gamma * next_values - values[step]
每一步的回报则等于当前优势加上当前状态的价值,即# 递归计算GAE优势advantage = delta + next_is_not_terminal * self.gamma * self.lam * advantage ,故有
,故有 # 当前步的回报等于优势加上当前价值returns[step] = advantage + values[step] - 最后,方法计算优势(returns - values)
并进行标准化处理(减去均值,除以标准差),以便后续训练时数值更稳定# 计算优势(returns - values),并进行标准化advantages = returns - valuesadvantages = (advantages - advantages.mean()) / (advantages.std() + 1e-8)# 返回回报和标准化后的优势 - 最终返回每一步的回报和标准化后的优势。这个过程确保了 PPO 算法在更新策略时能够利用高质量、低方差的优势估计
return returns, advantages
1.4.1.6 _training_step
训练步骤 `_training_step` 会从存储中生成 mini-batch,依次进行策略和价值网络的更新
1.4.1.7 _update_ppo
PPO 的核心损失计算在 `_update_ppo` 方法中实现,包括代理损失、价值损失和熵损失,并支持自适应 KL 散度调整学习率
1.4.1.8 其他
此外,类还实现了模型的保存与加载、评估流程(包括回调机制)、以及详细的日志记录和可视化
1.4.2 运动操作专用PPO
// 待更
1.5 ASAP的核心创新模块:增量学习与Delta动力学模型
1.5.1 机器人运控train_delta_a.py:基于PPO的扩展(支持双策略)
本文件定义了一个名为 `PPO DeltaA` 的类,是基于 PPO(Proximal Policy Optimization)算法的扩展,主要用于机器人运动控制任务,支持“双策略”机制:
- 主策略:当前正在训练的 PPO 策略
- 参考策略:从 checkpoint 加载的、冻结参数的预训练策略(可用于对比、辅助、模仿等)
其主要依赖包括
- `torch`、`torch.nn`、`torch.optim`:PyTorch 深度学习框架
- humanoidverse 相关模块:自定义的环境、网络结构、工具等
- `hydra`、`omegaconf`:配置管理
- `loguru`、`rich`:日志和美观的终端输出
- 其他:`os`、`time`、`deque`、`statistics` 等标准库
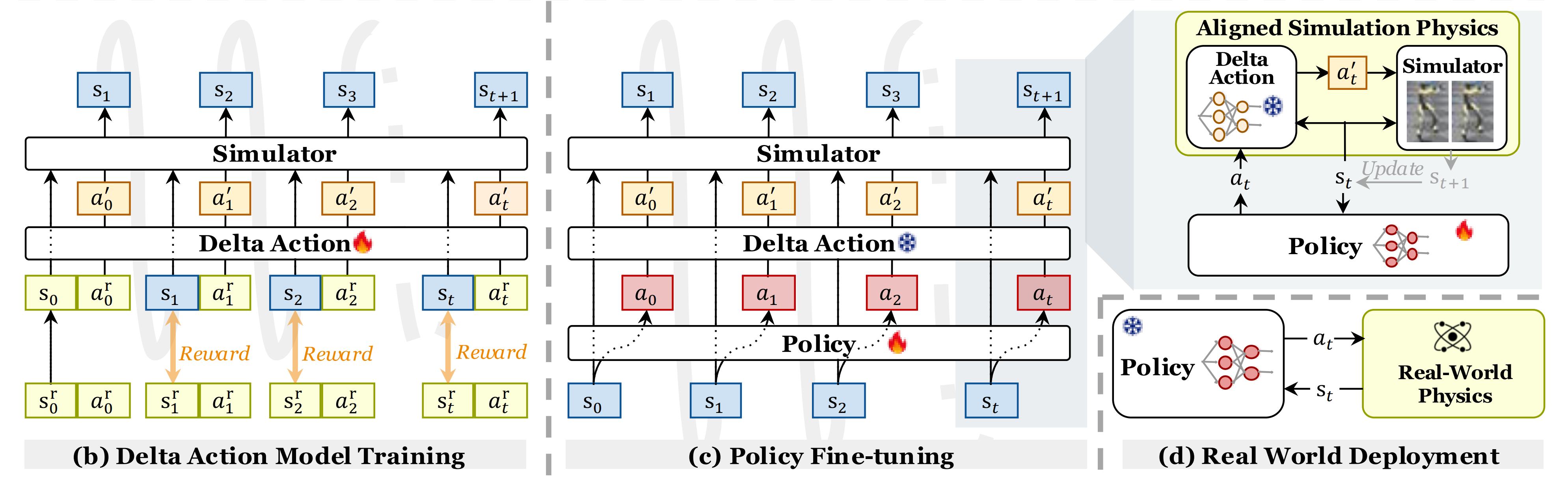
如此文《ASAP——让宇树G1后仰跳投且跳舞:仿真中重现现实轨迹,然后通过增量动作模型预测仿真与现实的差距,最终缩小差距以对齐》所说
- 工作流程如图2(b)所示
- PPO 用于训练增量动作策略
,学习修正后的
以匹配仿真与真实世界
1.5.1.1 初始化(`__init__`)
- -继承自 PPO 基类,初始化环境、配置、日志目录、设备等
如果配置中指定了 `policy_checkpoint`,则:
自动查找并加载 checkpoint 对应的 config.yaml 配置文件
合并 `eval_overrides` 配置(如果有) - 预处理配置
pre_process_config(policy_config) # 对配置进行预处理 - 使用 hydra 的 `instantiate` 动态实例化参考策略(`self.loaded_policy`),并调用其 `setup()` 方法
加载 checkpoint 权重到参考策略 - 设置参考策略为评估模式(冻结参数,不参与训练)
禁用参考策略所有参数的梯度(`param.requires_grad = False`)
获取参考策略的推理函数 `eval_policy`
1.5.1.2 rollout 步骤(`_rollout_step`):采集一段轨迹(rollout),供后续训练使用
这段 `_rollout_step` 方法负责在强化学习训练中收集一批(batch)环境交互数据。它的主要流程是在不计算梯度的情况下(`torch.inference_mode()`),循环执行 `num_steps_per_env` 次,每次代表环境中的一步
简言之,每步流程:
- 主策略推理,得到动作(actions)和值(values)
- 参考策略推理,得到 `actions_closed_loop`
- 将主策略和参考策略的动作都传入环境 `env.step(actor_state)`
- 收集环境返回的观测、奖励、done、info 等
- 更新存储器(RolloutStorage),包括奖励、done、values 等
- 统计回合奖励、长度等信息
- 采集完一段后,计算 returns 和 advantages,供 PPO 算法训练
具体而言,在每一步中
- 首先,主策略推理,得到动作(actions)和值(values)
通过 `_actor_rollout_step` 计算当前策略的动作,并通过 `_critic_eval_step` 计算当前状态的价值(value),这些信息被存储在 `policy_state_dict` 中def _rollout_step(self, obs_dict): # 采集一段rollout轨迹with torch.inference_mode(): # 关闭梯度计算,加速推理for i in range(self.num_steps_per_env): # 遍历每个环境步# 计算动作和值# 策略状态字典policy_state_dict = {} # 主策略推理policy_state_dict = self._actor_rollout_step(obs_dict, policy_state_dict) # 评估当前状态的价值values = self._critic_eval_step(obs_dict).detach() # 存储valuepolicy_state_dict["values"] = values - 随后,所有观测和策略相关的数据都会被存入 `self.storage`,用于后续训练
## 存储观测for obs_key in obs_dict.keys():# 存储每个观测self.storage.update_key(obs_key, obs_dict[obs_key]) for obs_ in policy_state_dict.keys():# 存储策略相关数据self.storage.update_key(obs_, policy_state_dict[obs_]) # 获取主策略动作actions = policy_state_dict["actions"] # 构造actor状态actor_state = {} # 主策略动作actor_state["actions"] = actions - 接下来,参考策略推理,得到 `actions_closed_loop`
方法还会用一个“参考策略”(`self.loaded_policy`,通常是预训练或专家策略)对 `closed_loop_actor_obs` 进行推理,得到 `actions_closed_loop`
并将其与主策略的动作一起组成 `actor_state`,用于环境的下一步模拟# 参考策略推理policy_output = self.loaded_policy.eval_policy(obs_dict['closed_loop_actor_obs']).detach()# 存储参考策略动作actor_state["actions_closed_loop"] = policy_output - 环境执行一步后,新的观测、奖励、终止标志和信息被返回。所有张量会被转移到正确的设备(如 GPU),奖励和终止信息也会被存储
若出现超时(`time_outs`),奖励会做相应调整# 与环境交互,获得新观测、奖励、done等obs_dict, rewards, dones, infos = self.env.step(actor_state) for obs_key in obs_dict.keys():# 移动到指定设备obs_dict[obs_key] = obs_dict[obs_key].to(self.device) # 奖励和done也移动到设备rewards, dones = rewards.to(self.device), dones.to(self.device) # 记录环境统计信息self.episode_env_tensors.add(infos["to_log"]) # 奖励扩展维度rewards_stored = rewards.clone().unsqueeze(1)
每一步还会调用 `_process_env_step` 进行额外处理# 如果有超时信息if 'time_outs' in infos: # 修正奖励rewards_stored += self.gamma * policy_state_dict['values'] * infos['time_outs'].unsqueeze(1).to(self.device) # 检查奖励维度assert len(rewards_stored.shape) == 2 self.storage.update_key('rewards', rewards_stored) # 存储奖励self.storage.update_key('dones', dones.unsqueeze(1)) # 存储doneself.storage.increment_step() # 存储步数+1self._process_env_step(rewards, dones, infos) # 处理环境步 - 如果设置了日志目录,还会记录每个 episode 的奖励和长度,便于后续统计和分析
- 循环结束后,方法会统计采集数据所用的时间,并调用 `_compute_returns` 计算每一步的回报(returns)和优势(advantages)
这些数据会批量更新到存储中,为后续的策略优化做准备# 计算回报和优势returns, advantages = self._compute_returns(last_obs_dict=obs_dict,policy_state_dict=dict(values=self.storage.query_key('values'), dones=self.storage.query_key('dones'), rewards=self.storage.query_key('rewards')))self.storage.batch_update_data('returns', returns) # 存储回报self.storage.batch_update_data('advantages', advantages) # 存储优势 - 最后返回最新的观测字典
return obs_dict # 返回最新观测
整个过程实现了数据采集、存储和预处理的自动化,是 PPO 及其变体算法训练流程的核心部分。
1.5.1.3 评估前处理(`_pre_eval_env_step`)
简言之
- 用于评估阶段,每步都让主策略和参考策略分别推理动作
- 更新 `actor_state`,包含主策略动作和参考策略动作
- 支持回调机制(`eval_callbacks`),可扩展评估逻辑
1.5.2 Delta动力学模型
// 待更
1.6 控制算法:解耦合控制、力感知控制、模型预测路径积分控制
// 待更
第二部分 环境模块 envs/
BaseTask (envs/base_task/base_task.py):
├── BaseSimulator → 物理模拟器接口
├── terrain → 地形生成
├── robot配置 → 机器人参数
├── obs配置 → 观察空间定义
└── rewards配置 → 奖励函数设计具体任务继承关系:
BaseTask
├── LocomotionTask (locomotion/)
├── MotionTrackingTask (motion_tracking/)
└── LeggedBaseTask (legged_base_task/)**基础任务架构:**
- **BaseTask**: 所有RL任务的基类,处理模拟器初始化、环境设置、观察空间定义
- **base_task/**: 包含基础任务实现和配置
**专门任务类型:**
- **locomotion/**: 运动控制任务,实现机器人行走、跑步等基础运动
- **motion_tracking/**: 运动追踪任务,实现对人类动作的模仿和跟踪
- **legged_base_task/**: 腿式机器人基础任务
- **env_utils/**: 环境工具函数,包含地形生成、物理参数设置等
第三部分 模拟器模块 simulator/
支持多种物理引擎:
- **IsaacGym**: NVIDIA的GPU加速物理模拟器
- **IsaacSim**: 基于Omniverse的仿真平台
- **Genesis**: 新兴的高性能物理模拟器
- **base_simulator/**: 模拟器基类,提供统一接口
第四部分 配置系统 config/
采用Hydra配置管理,结构化组织:
- **base.yaml/base_eval.yaml**: 基础配置
- **algo/**: 算法特定配置
- **env/**: 环境配置
- **robot/**: 机器人配置 (如G1机器人的29自由度配置)
- **rewards/**: 奖励函数配置
- **obs/**: 观察空间配置
- **terrain/**: 地形配置
第五部分 工具模块 utils/
**通用工具:**
- **common.py**: 通用函数
- **math.py**: 数学工具函数
- **torch_utils.py**: PyTorch相关工具
- **config_utils.py**: 配置处理工具
- **motion_lib/**: 动作库,存储和处理人类动作数据
第六部分 数据模块data/
- **motions/**: 存储人类动作数据
- **robots/**: 机器人模型文件和配置
第七部分 Isaac工具isaac_utils/
专门为Isaac模拟器提供的数学和旋转工具:
- **maths.py**: 数学计算函数
- **rotations.py**: 旋转变换工具
// 待更















)



