python实现word 自动化
- 重复性文档制作,手动填充模板,效率低下还易错
- 1.python-docx入门:Word文档的“瑞士军刀”!
- 1.1 安装与基础概念:文档、段落、运行、表格
- 1.2 打开/创建Word文档:Python与Word的初次接触
- 1.3 读写文本内容:让Python填写Word
- 2.Python批量生成个性化Word文档
- 2.1 设计Word模板:word自动化开始
- 2.2 读取数据与智能填充:数据
- 3.Python实现批量替换、格式调整!
- 3.1 批量替换内容:告别Ctrl+H,一键修改文档
- 3.2 字体、颜色、大小与对齐:自动化专业排版
- 4.Word文档工厂
- 5.Word自动化,开启智能文档管理新时代!
重复性文档制作,手动填充模板,效率低下还易错
在职场中,Word文档是公认的“好伙伴”,但你有没有被它“折磨”过?
批量生成合同: 每月几十份合同,内容大同小异,却要手动修改日期、客户名、金额,重复劳动让人抓狂。
制作报告: 不同的季度报告,框架一样,数据更新,但排版、图表插入每次都要从头来过。
发放证书/通知: 几百份个性化证书,只改个姓名、编号,却要手动复制粘贴几百次,效率低下还易错!
这些重复、低效的文档制作和排版耗时问题,严重拖慢了你的办公自动化进程。

今天,我将带你进入Python操作Word的奇妙世界!我们将手把手教你如何利用python-docx库,轻松实现:
Word文档批量生成: 数据驱动,自动生成海量个性化文档。
智能模板填充: 告别手动复制粘贴,精准填充文本、图片。
内容修改与排版优化: 批量替换文本、调整格式,让文档瞬间专业!
1.python-docx入门:Word文档的“瑞士军刀”!
要实现Python操作Word,我们离不开强大的python-docx库。它是Python中专门用于创建、修改和读取.docx格式Word文档的库。
作用: python-docx将Word文档视为一个包含“文档”、“段落”、等元素的层次结构。通过操作这些元素,你可以精确控制文档的每一个部分。
安装python-docx:
pip install python-docx
1.1 安装与基础概念:文档、段落、运行、表格
我们先了解python-docx中的几个核心概念:
Document (文档): 整个Word文件,是最高层级的对象。
Paragraph (段落): Word文档中的一个文本块,由一个或多个“运行”组成。
Run (运行): 段落中具有相同样式(如字体、颜色、加粗)的连续文本。通常,一个段落内部的样式变化会导致新的“运行”的生成。
Table (表格): Word文档中的表格对象,可以访问行、列和单元格。
1.2 打开/创建Word文档:Python与Word的初次接触
场景: 你想用Python创建一个新的Word文档,或者打开一个已有的文档进行修改。
方案: python-docx提供了简单的方法来创建空文档或加载现有文档。
代码:
from docx import Document # 导入Document类
import osdef create_or_open_word_doc(file_path, mode="new"):"""创建或打开Word文档。这是Python操作Word的基础。:param file_path: Word文档路径:param mode: "new" (创建新文档) 或 "open" (打开现有文档):return: Document对象"""os.makedirs(os.path.dirname(file_path), exist_ok=True) # 确保目录存在doc = Nonetry:if mode == "new":doc = Document() # 创建一个空文档print(f"✅ 成功创建新Word文档对象。")elif mode == "open":if not os.path.exists(file_path):print(f"❌ 文件不存在,无法打开:{file_path}")return Nonedoc = Document(file_path) # 打开现有文档print(f"✅ 成功打开Word文档:{file_path}")# 打印文档中的段落数量print(f" 文档包含 {len(doc.paragraphs)} 个段落。")else:print("⚠️ 无效的模式。")return Nonereturn docexcept Exception as e:print(f"❌ 处理Word文档失败:{e}")return Noneif __name__ == "__main__":new_doc_path = os.path.expanduser("~/Desktop/new_empty_doc.docx")existing_doc_path = os.path.expanduser("~/Desktop/existing_sample_doc.docx")# 创建一个示例现有文档用于测试if not os.path.exists(existing_doc_path):doc = Document()doc.add_paragraph("这是一个用于测试的现有文档。")doc.save(existing_doc_path)# 示例1:创建新文档new_doc = create_or_open_word_doc(new_doc_path, mode="new")if new_doc:new_doc.add_paragraph("这是Python创建的第一个段落。")new_doc.save(new_doc_path)print(f"新文档已保存到:{new_doc_path}")# 示例2:打开现有文档opened_doc = create_or_open_word_doc(existing_doc_path, mode="open")if opened_doc:# 可以对 opened_doc 进行后续操作pass
步骤:
准备环境: pip install python-docx。
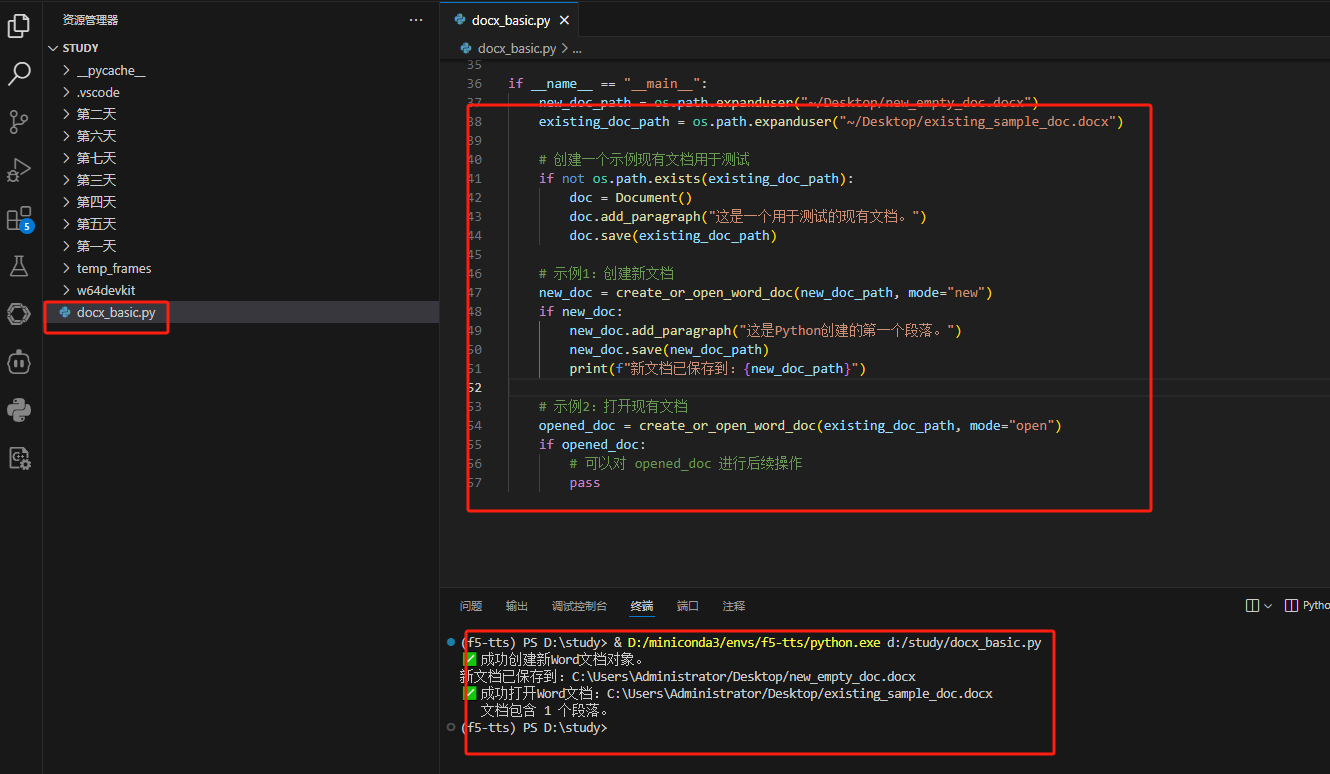
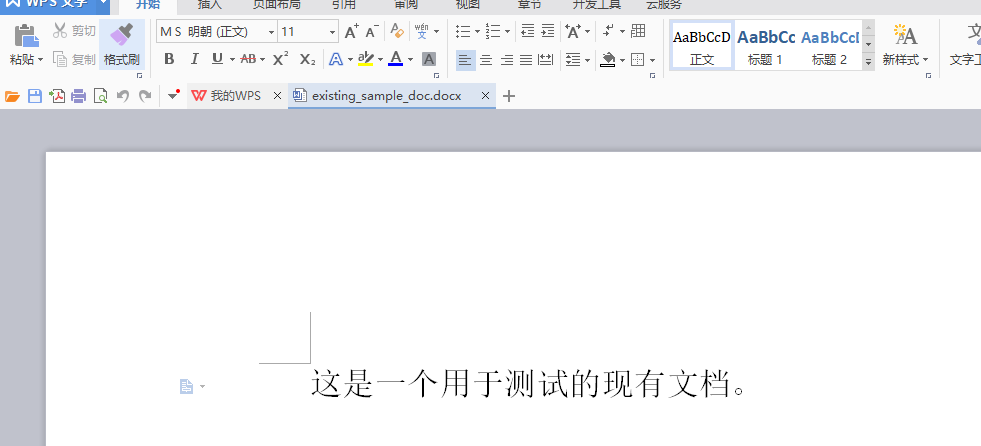
修改代码路径: 复制上方代码到VS Code,保存为docx_basic.py。修改 new_doc_path 和 existing_doc_path。
运行: 运行 python docx_basic.py。
效果展示:
1.3 读写文本内容:让Python填写Word
场景: 你需要从Word文档中提取文本内容进行分析,或者向Word文档中插入新的文字、段落。
方案: python-docx能让你像操作字符串一样,方便地读写Word文档中的文本内容,实现文档批量修改。
代码:
from docx import Document
from docx.shared import Inches # 用于设置图片大小
import osdef read_write_text_to_word(file_path):"""读取和写入Word文档中的文本内容。这是Word自动化和文档管理的基础。:param file_path: Word文档路径"""os.makedirs(os.path.dirname(file_path), exist_ok=True)try:# 创建一个新文档用于演示doc = Document()doc.add_heading('Python自动化文档示例', level=1) # 添加一级标题# 写入段落doc.add_paragraph('这是第一段内容。')doc.add_paragraph('这是第二段,')doc.paragraphs[1].add_run('包含加粗文本。').bold = True # 给第二个段落添加加粗文本# 写入列表doc.add_paragraph('这是一个列表:')doc.add_paragraph('项目1', style='List Bullet') # 添加项目符号列表doc.add_paragraph('项目2', style='List Bullet')# 写入表格table = doc.add_table(rows=1, cols=3)table.style = 'Table Grid' # 设置表格样式hdr_cells = table.rows[0].cellshdr_cells[0].text = '姓名'hdr_cells[1].text = '年龄'hdr_cells[2].text = '城市'data = [('Alice', 30, 'New York'),('Bob', 25, 'Los Angeles')]for name, age, city in data:row_cells = table.add_row().cellsrow_cells[0].text = namerow_cells[1].text = str(age)row_cells[2].text = city# 插入图片 (需要准备一张图片文件)# test_image_path = os.path.expanduser("~/Desktop/sample_image.png")# if os.path.exists(test_image_path):# doc.add_picture(test_image_path, width=Inches(1.25)) # 插入图片并设置宽度# print(f" ✅ 图片 '{os.path.basename(test_image_path)}' 已插入。")doc.save(file_path)print(f"✅ Word文档内容已成功写入并保存到:'{file_path}'")# --- 读取文档内容 ---print(f"\n🚀 正在读取文档:'{os.path.basename(file_path)}' 中的文本内容...")loaded_doc = Document(file_path)full_text = []for para in loaded_doc.paragraphs:full_text.append(para.text)print(" --- 文档内容概览 ---")print("\n".join(full_text[:5])) # 打印前5个段落print("✨ 文档内容读取完成!")except Exception as e:print(f"❌ 读写Word文档失败:{e}")if __name__ == "__main__":output_word_path = os.path.expanduser("~/Desktop/automated_report_content.docx")read_write_text_to_word(output_word_path)
步骤:
准备环境: pip install python-docx。
修改代码路径: 复制上方代码到VS Code,保存为docx_read_write.py。修改 output_word_path。
运行: 运行 python docx_read_write.py。
效果展示:
2.Python批量生成个性化Word文档
这是Word自动化最核心的应用之一!批量生成文档如合同、报告、证书等,通过模板填充实现个性化,彻底告别手动复制粘贴!
作用: 预先设计好包含“占位符”的Word模板文件,Python脚本读取外部数据(如Excel),然后用真实数据替换模板中的占位符,生成新的文档。
2.1 设计Word模板:word自动化开始
场景: 你有100份需要发给不同客户的合同,其中只有“客户名称”、“合同金额”、“日期”等少数信息不同。
方案: 在Word中创建带有特殊标记(如{{客户名称}})的文本,作为Python识别和替换的占位符。
模板:
这是一份重要的合同
合同编号:{{合同编号}}
甲方:{{甲方名称}}
乙方:{{乙方名称}}
签订日期:{{签订日期}}
合同金额:人民币 {{合同金额}} 元整
… (其他合同条款) …
请双方签字确认。
2.2 读取数据与智能填充:数据
场景: 你有100个客户的合同数据存在Excel里,需要自动生成100份定制化的合同。
方案: Python脚本(通常结合Pandas读取Excel)能读取这些数据,然后遍历数据,逐个生成个性化文档。
代码:
pip install xlrd
from docx import Document
import pandas as pd
import osdef generate_docs_from_template(template_path, data_excel_path, output_folder):"""根据Word模板和Excel数据,批量生成个性化Word文档。这是Python批量生成文档和模板填充的核心功能。:param template_path: Word模板文件路径 (含占位符,如{{姓名}}):param data_excel_path: 包含数据的Excel文件路径:param output_folder: 生成文档的输出文件夹"""if not os.path.exists(template_path): return print(f"❌ 模板文件不存在:{template_path}")if not os.path.exists(data_excel_path): return print(f"❌ 数据文件不存在:{data_excel_path}")os.makedirs(output_folder, exist_ok=True)try:df = pd.read_excel(data_excel_path) # 读取Excel数据print(f"🚀 正在根据模板 '{os.path.basename(template_path)}' 和数据 '{os.path.basename(data_excel_path)}' 批量生成文档...")generated_count = 0for index, row in df.iterrows(): # 遍历Excel的每一行数据doc = Document(template_path) # 每次循环重新加载模板,确保是干净的模板# 遍历文档中的所有段落,替换占位符for paragraph in doc.paragraphs:for key, value in row.items(): # 遍历当前行的数据(列名:值)placeholder = f"{{{{{key}}}}}" # 构建占位符字符串,如 {{姓名}}if placeholder in paragraph.text:paragraph.text = paragraph.text.replace(placeholder, str(value))# 遍历表格中的单元格,替换占位符(如果模板中包含表格)for table in doc.tables:for row_table in table.rows:for cell in row_table.cells:for key, value in row.items():placeholder = f"{{{{{key}}}}}"if placeholder in cell.text:cell.text = cell.text.replace(placeholder, str(value))# 构建输出文件名 (例如:合同_客户名称.docx)output_filename = f"合同_{row['乙方名称']}_{row['签订日期']}.docx" # 假设Excel有“乙方名称”和“签订日期”列output_full_path = os.path.join(output_folder, output_filename)doc.save(output_full_path)print(f" ✅ 已生成:'{output_filename}'")generated_count += 1print(f"✨ 批量文档生成完成!共生成 {generated_count} 份文档。")except Exception as e:print(f"❌ 批量生成文档失败:{e}")if __name__ == "__main__":template_doc = os.path.expanduser("~/Desktop/contract_template.docx")data_excel = os.path.expanduser("~/Desktop/contract_data.xlsx")output_docs_folder = os.path.expanduser("~/Desktop/生成的合同")# 确保模板文件存在if not os.path.exists(template_doc):# 简单创建模拟模板 (用户需手动创建带有占位符的docx)doc = Document(); doc.add_paragraph("合同编号:{{合同编号}}"); doc.add_paragraph("甲方:{{甲方名称}}"); doc.save(template_doc)print(f"临时模板文件 '{os.path.basename(template_doc)}' 已创建。请手动在其中添加占位符。")# 确保数据Excel存在if not os.path.exists(data_excel):pd.DataFrame({'合同编号': ['C001', 'C002'], '甲方名称': ['A公司', 'B公司'], '乙方名称': ['张三', '李四'], '签订日期': ['2025-01-01', '2025-02-01'], '合同金额': [10000, 15000]}).to_excel(data_excel, index=False)print(f"临时数据文件 '{os.path.basename(data_excel)}' 已创建。")generate_docs_from_template(template_doc, data_excel, output_docs_folder)
步骤:
准备模板: 创建一个contract_template.docx文件,按照示例添加{{占位符}}。
准备数据: 创建一个contract_data.xlsx文件,包含与占位符对应的列数据。
修改代码路径: 修改 template_doc、data_excel、output_docs_folder。
运行: 运行 python generate_docs.py。
效果:
 ## 2.3 图片与图表的自动插入:让文档图文并茂
## 2.3 图片与图表的自动插入:让文档图文并茂
场景: 你的报告需要插入多张图片或由Python生成的图表,手动调整大小和位置非常耗时。
方案: python-docx支持图片和图表的自动插入,并能控制其大小,让你的报告瞬间变得图文并茂、专业美观!
代码:
from docx import Document
from docx.shared import Inches # 用于设置图片大小
import os
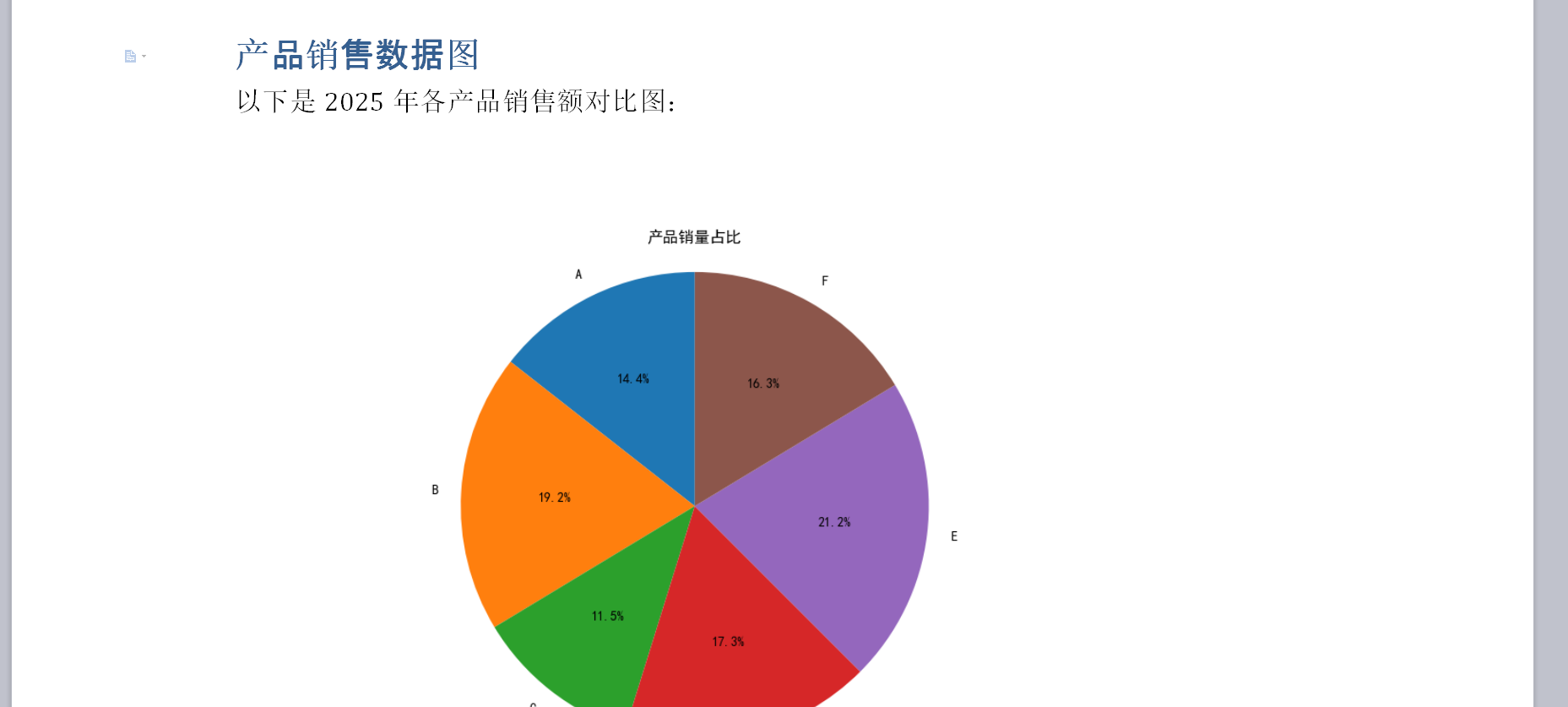
import matplotlib.pyplot as plt # 用于生成图表图片def insert_image_to_word_doc(file_path, image_path, width_inches=4):"""向Word文档中插入图片。:param file_path: Word文档路径:param image_path: 要插入的图片路径:param width_inches: 图片在文档中的宽度(英寸)"""if not os.path.exists(image_path): return print(f"❌ 图片文件不存在:{image_path}")os.makedirs(os.path.dirname(file_path), exist_ok=True)try:# 创建或打开文档doc = Document() # 创建新文档,或者 load_document(file_path)doc.add_heading('产品销售数据图', level=1)doc.add_paragraph('以下是2023年各产品销售额对比图:')# **核心操作:插入图片**doc.add_picture(image_path, width=Inches(width_inches)) # 插入图片并设置宽度doc.add_paragraph('数据分析结论:...')doc.save(file_path)print(f"✅ 图片 '{os.path.basename(image_path)}' 已成功插入到Word文档:'{file_path}'")except Exception as e:print(f"❌ 插入图片到Word文档失败:{e}")if __name__ == "__main__":output_word_path = os.path.expanduser("~/Desktop/report_with_image.docx")# 准备一张图片文件(例如通过matplotlib生成或普通图片)chart_image_path = os.path.expanduser("~/Desktop/sample_chart_for_word.png")# 简单创建模拟图表图片if not os.path.exists(chart_image_path):plt.figure(figsize=(6, 4)); plt.bar(['Jan','Feb'],[100,120]); plt.title('Monthly Sales'); plt.savefig(chart_image_path); plt.close()print(f"临时图表文件 '{os.path.basename(chart_image_path)}' 已创建。")insert_image_to_word_doc(output_word_path, chart_image_path, width_inches=5)
步骤:
准备环境: pip install python-docx matplotlib。
准备图片: 准备一张图片文件(如sample_chart_for_word.png),最好是图表图片。
修改代码路径: 修改 output_word_path 和 chart_image_path。
运行: 运行 python docx_insert_image.py。
效果展示:
3.Python实现批量替换、格式调整!
仅仅生成和填充还不够,Word自动化的真正威力在于对文档内容的灵活修改和自动化排版,彻底告别繁琐排版!
作用: python-docx允许你遍历文档的段落和运行(Run),查找并替换文本,以及直接修改文本的字体、颜色、大小、对齐方式。
3.1 批量替换内容:告别Ctrl+H,一键修改文档
场景: 公司名称变更,你需要修改几十份旧合同中的公司名称;或者一个报告中多次出现的某个关键词需要批量更新。手动Ctrl+H查找替换,效率低下且容易遗漏。
方案: Python脚本可以打开Word文档,遍历所有段落,并对其中的文本进行批量替换,效率远超手动操作!
代码:
from docx import Document
import os
from docx.text.run import Run # 导入Run类,用于更细致的文本操作
from docx.enum.text import WD_ALIGN_PARAGRAPH # 可能会用到,为了样式操作
import shutil # 用于文件操作,如复制文件def _replace_text_in_run(run: Run, old_text: str, new_text: str):"""替换单个Run中的文本,并返回是否发生了替换。尽量保留原有Run的格式。"""if old_text not in run.text:return False# 替换Run的文本,并尝试保留格式# 这是一种简单粗暴的替换,可能会丢失复杂格式,但对大多数情况有效# 更高级的替换需要删除旧Run,创建新Run并逐个复制格式属性run.text = run.text.replace(old_text, new_text)return Truedef _replace_text_in_paragraph_robust(paragraph, replacements):"""鲁棒地替换段落中的文本,处理跨Run的情况。"""original_text = paragraph.text # 获取段落的完整文本found_and_replaced = Falsefor old_text, new_text in replacements.items():if old_text in original_text: # 如果段落的完整文本中包含要替换的字符串# 标记需要替换,即使现在不立即替换Runfound_and_replaced = True # 这是一个简化的处理策略:先删除所有旧的Run,再添加一个新Run来替换# 这种方法会丢失段落内部的格式(如粗体、斜体),但能保证替换的准确性# 如果需要保留格式,实现会非常复杂,涉及扫描和拆分Run# 简单策略:如果找到匹配,清空段落所有runs,然后写入新的文本# 这种方法会丢失原段落内所有格式,但最简单有效paragraph.clear() # 清空段落所有内容new_run = paragraph.add_run(original_text.replace(old_text, new_text))# TODO: 复制旧Run的格式到新Run,这里仅做示意,实际需要更复杂的逻辑# for r in original_runs:# new_run.bold = r.bold# new_run.italic = r.italic# new_run.font.size = r.font.size# ...等等所有格式属性print(f" ✅ 替换:'{old_text}' -> '{new_text}' 在段落中。")# 更新 original_text 以便处理同一段落内的多个替换original_text = original_text.replace(old_text, new_text)return found_and_replaceddef batch_replace_text_in_doc(file_path, replacements):"""批量替换Word文档中的文本内容。这是文档批量修改的核心功能,告别手动Ctrl+H。:param file_path: Word文档路径:param replacements: 替换字典,格式为 {旧文本: 新文本}"""if not os.path.exists(file_path): return print(f"❌ Word文件不存在:{file_path}")# 构建输出路径,避免覆盖原文件output_path = os.path.join(os.path.dirname(file_path), "modified_" + os.path.basename(file_path))temp_doc_path = os.path.join(os.path.dirname(file_path), "temp_" + os.path.basename(file_path))try:# 先将原始文档复制一份进行操作,避免直接修改源文件shutil.copyfile(file_path, temp_doc_path)doc = Document(temp_doc_path) # 打开临时文档进行修改print(f"🚀 正在批量替换 '{os.path.basename(file_path)}' 中的文本...")replaced_count = 0# 遍历文档中的所有段落for paragraph in doc.paragraphs:if _replace_text_in_paragraph_robust(paragraph, replacements):replaced_count += 1# 遍历表格中的单元格 (如果文档中包含表格)for table in doc.tables:for row in table.rows:for cell in row.cells:for paragraph_in_cell in cell.paragraphs: # 单元格内也可能有多个段落if _replace_text_in_paragraph_robust(paragraph_in_cell, replacements):replaced_count += 1doc.save(output_path)print(f"✨ 批量文本替换完成!共进行 {replaced_count} 处替换。修改后的文档已保存到:'{output_path}'")except Exception as e:print(f"❌ 批量文本替换失败:{e}")finally:# 清理临时文件if os.path.exists(temp_doc_path):os.remove(temp_doc_path)if __name__ == "__main__":# 准备一个包含要替换内容的Word文档test_doc_path = os.path.expanduser("D://study//company_report_v11.docx")# 简单创建模拟文档 (确保有多个包含关键字的段落和表格)if not os.path.exists(test_doc_path):doc = Document()doc.add_heading("年度运营报告 - 【繁星娱乐】", level=1)doc.add_paragraph("本报告由【繁星娱乐】撰写,版本为v1.0。")doc.add_paragraph("请【繁星娱乐】的所有员工注意。")# 添加一个表格table = doc.add_table(rows=2, cols=2)table.cell(0, 0).text = "部门"table.cell(0, 1).text = "负责人"table.cell(1, 0).text = "销售部"table.cell(1, 1).text = "【繁星娱乐】代表"doc.save(test_doc_path)print(f"临时测试文档 '{os.path.basename(test_doc_path)}' 已创建。")replacements_dict = {"【繁星娱乐】": "【11111111】","v1.0": "v2.0"}batch_replace_text_in_doc(test_doc_path, replacements_dict)
步骤:
准备Word文档: 在桌面创建一个company_report_v1.docx,其中包含一些需要替换的文本。
修改代码路径和替换字典: 修改 test_doc_path 和 replacements_dict。运行: 运行 python docx_batch_replace.py。
效果展示:

3.2 字体、颜色、大小与对齐:自动化专业排版
场景: 你需要为报告中的某个标题加粗、设为红色,某个段落调整字体大小和对齐方式。手动逐个设置,耗时且难以保持一致性。
方案: python-docx可以精确控制文本的字体、大小、颜色、粗斜体,以及段落的对齐方式,实现文档排版自动化。
代码:
from docx import Document
from docx.shared import Pt, RGBColor # Pt用于磅数,RGBColor用于颜色
from docx.enum.text import WD_ALIGN_PARAGRAPH # 用于段落对齐
import osdef auto_format_word_doc(file_path):"""自动化设置Word文档的字体、颜色、大小与对齐方式。这是文档排版自动化和Python操作Word的高级功能。:param file_path: Word文档路径"""os.makedirs(os.path.dirname(file_path), exist_ok=True)try:# 创建新文档用于演示doc = Document()# 1. 添加标题并设置样式heading = doc.add_heading('Python自动化排版报告', level=1)# 访问标题的run,设置字体大小和加粗heading.runs[0].font.size = Pt(24) # 24磅heading.runs[0].font.bold = Trueheading.runs[0].font.color.rgb = RGBColor(0x42, 0x24, 0xE9) # 蓝色# 2. 添加段落并设置样式paragraph1 = doc.add_paragraph('这是一段重要的摘要内容。')paragraph1.runs[0].font.name = 'Arial' # 设置字体paragraph1.runs[0].font.size = Pt(12)paragraph1.alignment = WD_ALIGN_PARAGRAPH.JUSTIFY # 两端对齐paragraph2 = doc.add_paragraph('本段内容将居中显示,并设置为斜体。')paragraph2.alignment = WD_ALIGN_PARAGRAPH.CENTER # 居中对齐paragraph2.runs[0].font.italic = True # 斜体doc.save(file_path)print(f"✅ Word文档排版已成功设置并保存到:'{file_path}'")except Exception as e:print(f"❌ Word文档排版失败:{e}")if __name__ == "__main__":output_word_path = os.path.expanduser("~/Desktop/automated_formatted_doc.docx")auto_format_word_doc(output_word_path)
步骤:
准备环境: pip install python-docx。
修改代码路径: 修改 output_word_path。
运行: 运行 python docx_auto_format.py。
效果展示:

4.Word文档工厂
恭喜你!通过本篇文章,你已经掌握了Word文档自动化的各项核心魔法,亲手打造了一个能够批量生成、模板填充、内容修改的* Word文档工厂”
们深入学习了python-docx库,它堪称Word文档的**“瑞士军刀”**,实现了:
Word文档批量生成: 结合数据,一键生成海量个性化文档,告别重复性文档制作。
智能模板填充: 利用占位符,精准将数据填充到Word模板,杜绝手动填充模板的低效。
文档内容修改与排版优化: 批量替换文本,自动化设置字体、颜色、大小、对齐方式,彻底告别繁琐排版。
5.Word自动化,开启智能文档管理新时代!
通过本篇文章,你已经掌握了Word文档自动化的强大能力,为你的办公自动化之旅又增添了一个重量级技能!你学会了如何利用Python的python-docx库,高效地进行Word文档的创建、填充、修改与排版。
除了今天学到的Word自动化功能,你还希望Python能帮你实现哪些更复杂的文档处理需求?比如:自动提取Word文档中的特定信息?将Word文档内容智能生成摘要?在评论区分享你的需求和想法,你的建议可能会成为我们未来文章的灵感来源!
敬请期待! Word自动化系列至此告一段落。在下一篇文章中,我们将继续深入Python办公自动化的宝库,探索如何利用Python实现PDF文档自动化,包括PDF的合并、拆分、加水印、文本提取等,让你的文档管理更高效、更智能!同时,本系列所有代码都将持续更新并汇总在我的GitHub仓库中,敬请关注!未来,这个**“Python职场效率专家实战包”还将包含更多开箱即用、功能强大**的自动化工具。









)









)