目录
前言:
一、分页式存储管理
二、二级页表的地址转化
三、缺页中断
总结
前言:
我们上篇文章简单介绍了线程的一些知识点,但是还有很多坑没有给大家填上,包括页表部分我们还没为大家说明。
本篇文章我将会继续为大家讲解线程的有关内容,希望对大家有所帮助。
一、分页式存储管理
我们今天先继续谈论关于分页式存储的话题。
首先就是帮助大家深入的了解页表。
我们之前在学习进程PCB的时候就已经接触到了页表,在上文我们也曾提到过:在分页式存储管理中,虚拟地址空间被划分为固定大小的页(Page)(通常为4KB),而物理内存则被划分为相同大小的页框(Page Frame)。操作系统通过页表(Page Table)建立虚拟页到物理页框的映射关系,使得进程可以透明地访问物理内存。
我们的每一个进程都有自己的页表结构,这是大家之前就知道的。但是这个页表结构具体是什么样的呢?
我们之前只说了页表负责存储虚拟地址空间到物理地址的映射关系,但是页表具体怎么存储的呢?
在32位系统中,虚拟空间的最大空间是4GB,这是每一个用户程序都拥有的虚拟内存空间。既然需要让4GB的虚拟内存全部可用,那么页表中就需要能够表示所4GB空间的表项数量,也就是4GB/4KB=1048576个表项,如下图所示:
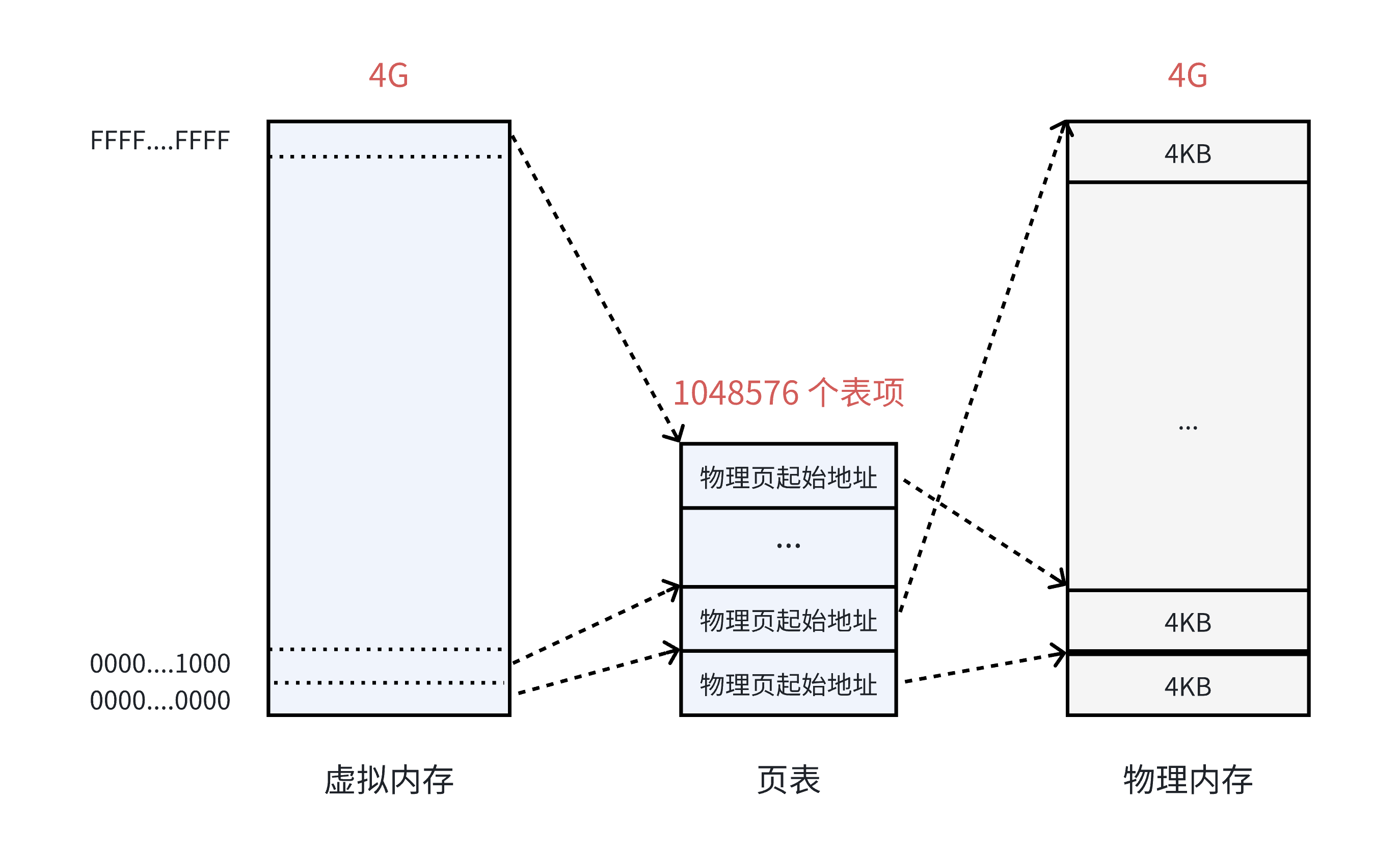
-
将原1M个条目的单级页表拆分为 1024个小页表(每个小页表存储1024个条目,占4KB)。
-
新增一个页目录(Page Directory),包含1024个条目,每个条目指向一个小页表。
-
总容量不变:1024小页表×1024条目/页表=1M1024小页表×1024条目/页表=1M条目,仍可覆盖4GB空间。
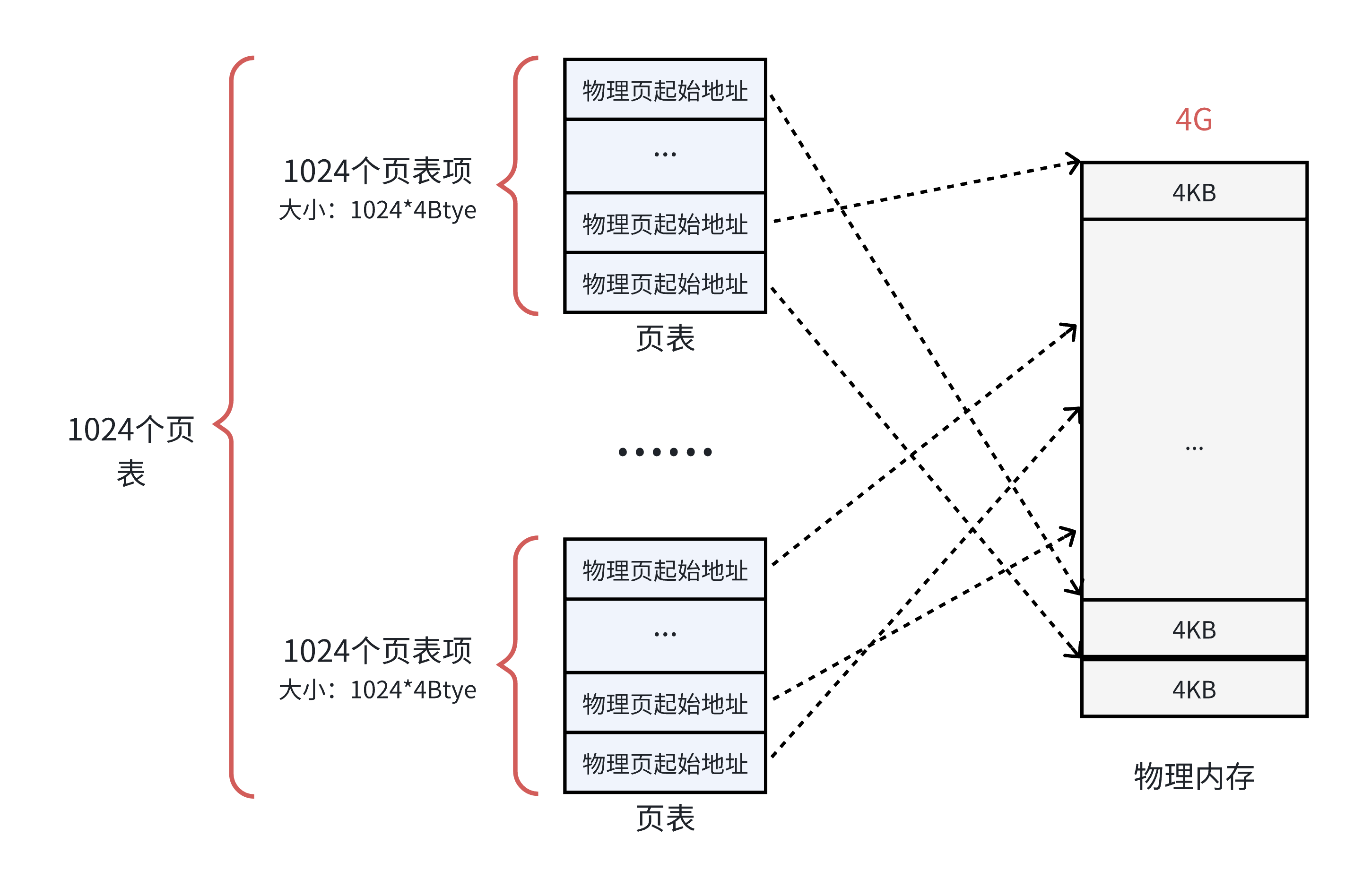
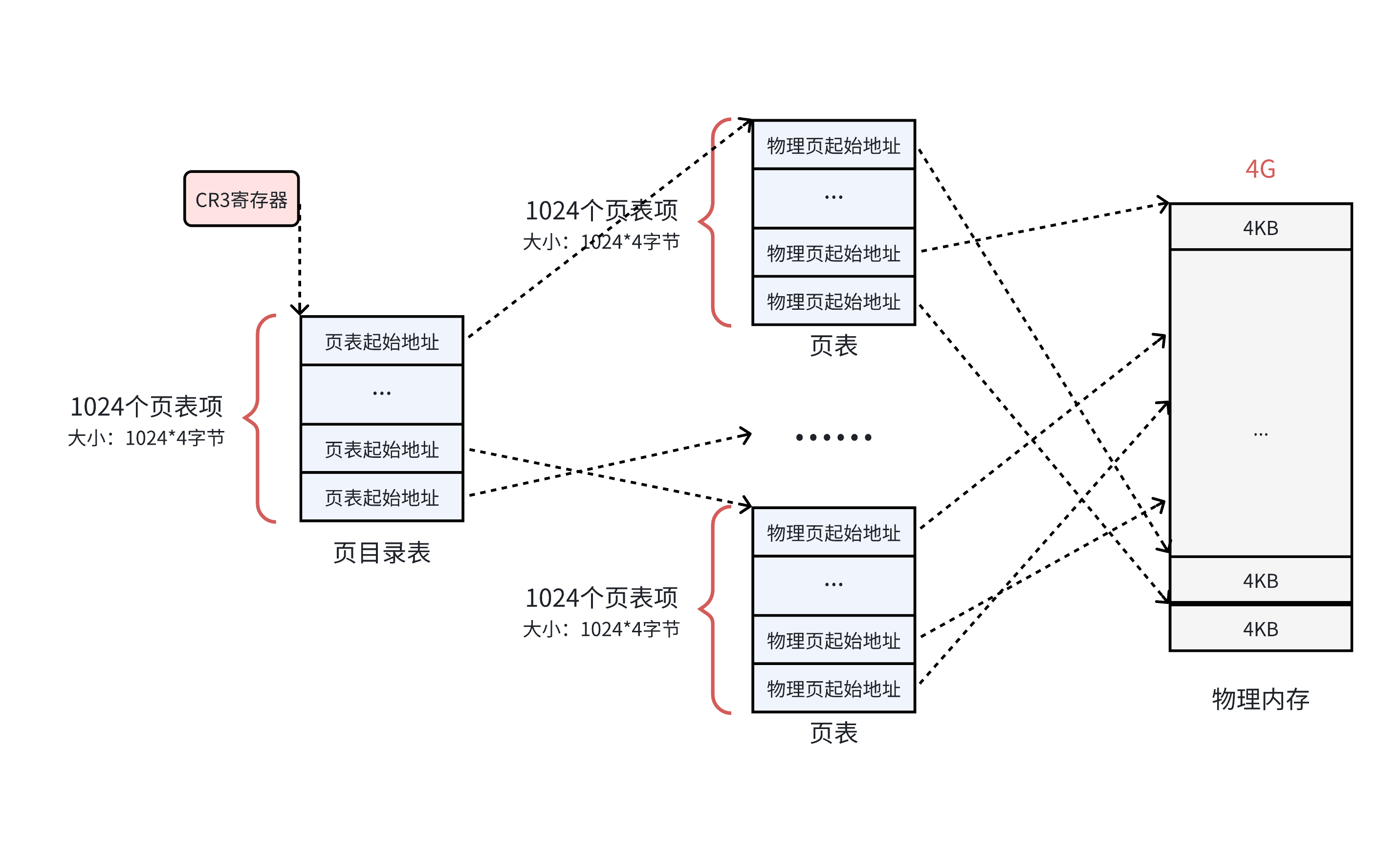
页目录表就是用来负责管理小页表的结构。所有小页表的物理地址被页目录表项指向,而页目录的物理地址被CR3寄存器指向,这个寄存器中,保存了当前正在执行任务的页目录地址。
所以操作系统在加载用户程序时,不仅仅需要为程序内容来分配物理地址,还需要为用来保存程序的页目录和页表分配物理地址哦!!
二、二级页表的地址转化
事实上,20位可寻址1M个页框 × 4KB = 4GB,与32位地址空间上限一致。并且物理页框的基址必须是4KB的整数倍(即低12位全为0),因此存储物理地址时无需记录低12位,硬件会自动在拼接时补零。如0x123 → 物理页框基址 = 0x123000。
所以我们如果把二级页表的32位全部用来存储地址,会造成浪费。于是,我们的二级页表的32位的前20位才是存储的物理地址,而后面12位,存储的是页偏移。
什么意思呢?就是对我们32位的虚拟地址来说,我们可以把这32个数字划分为三段。
第一段1-10位,表示的是这个虚拟地址代表的页目录,2^10次方刚好就是1024个页目录项。
第二段11-20位,这个是在找到了页目录项的基础上,找到这个页目录项上面的页表项。
第三段21-32位,表示的是偏移量,我们最后结合这个偏移量找到物理地址:
以0000000000 1111111110 111111111111为例:
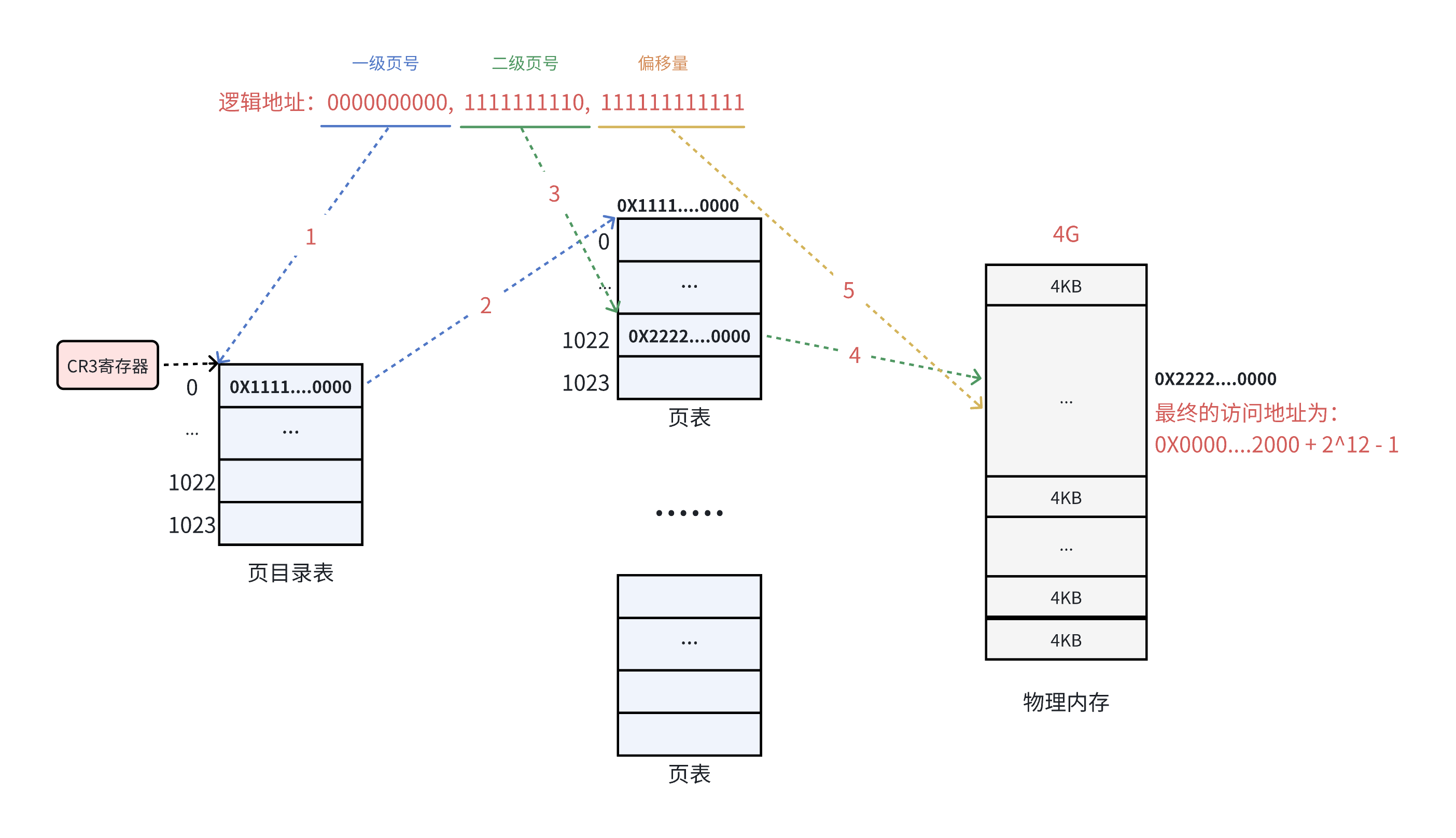
我们32位的物理地址也是差不多的理由,只不过是划分了两段。
第一段1-20位表示物理页框号,第二段21-32位表示标志位,包括读写权限这些。
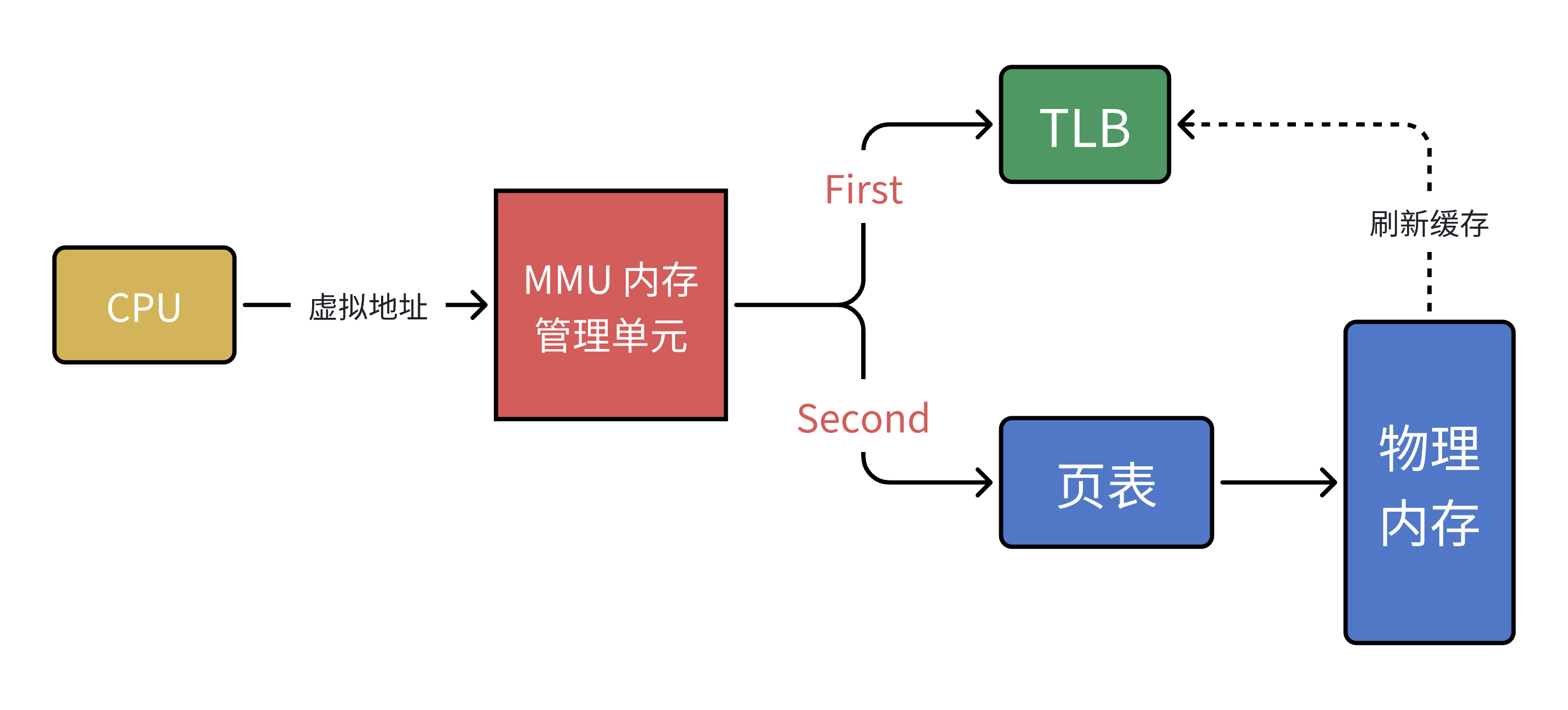
在CPU内部,有一个叫做MMU的硬件电路。以上其实就是MMU的工作流程,他的速度很快,主要工作还是进行内存管理,地址转化只是他承接的任务之一。
然而还有一个问题,MMU要先进行两次页表查询确定物理地址,在确定了权限等问题之后,MMU再将这个物理地址发送给总线,内存收到之后开始读取对应的地址的数据并返回。那么当页表变为N级的时候,就变成了N次检索加1次读写。可见,页表的级数越多,他所花费的步骤越多,那么对于CPU来说,等待的时间也就越长。
(总线是计算机系统中用于在各部件之间传输数据、地址和控制信号的 公共通信通道。它相当于计算机的“神经系统”,负责连接CPU、内存、I/O设备等组件,确保它们能高效协同工作)
所以多级页表是一个双刃剑,在减少连续存储要求且减少存储空间的同时降低了查询效率(以时间换取空间)
三、缺页中断
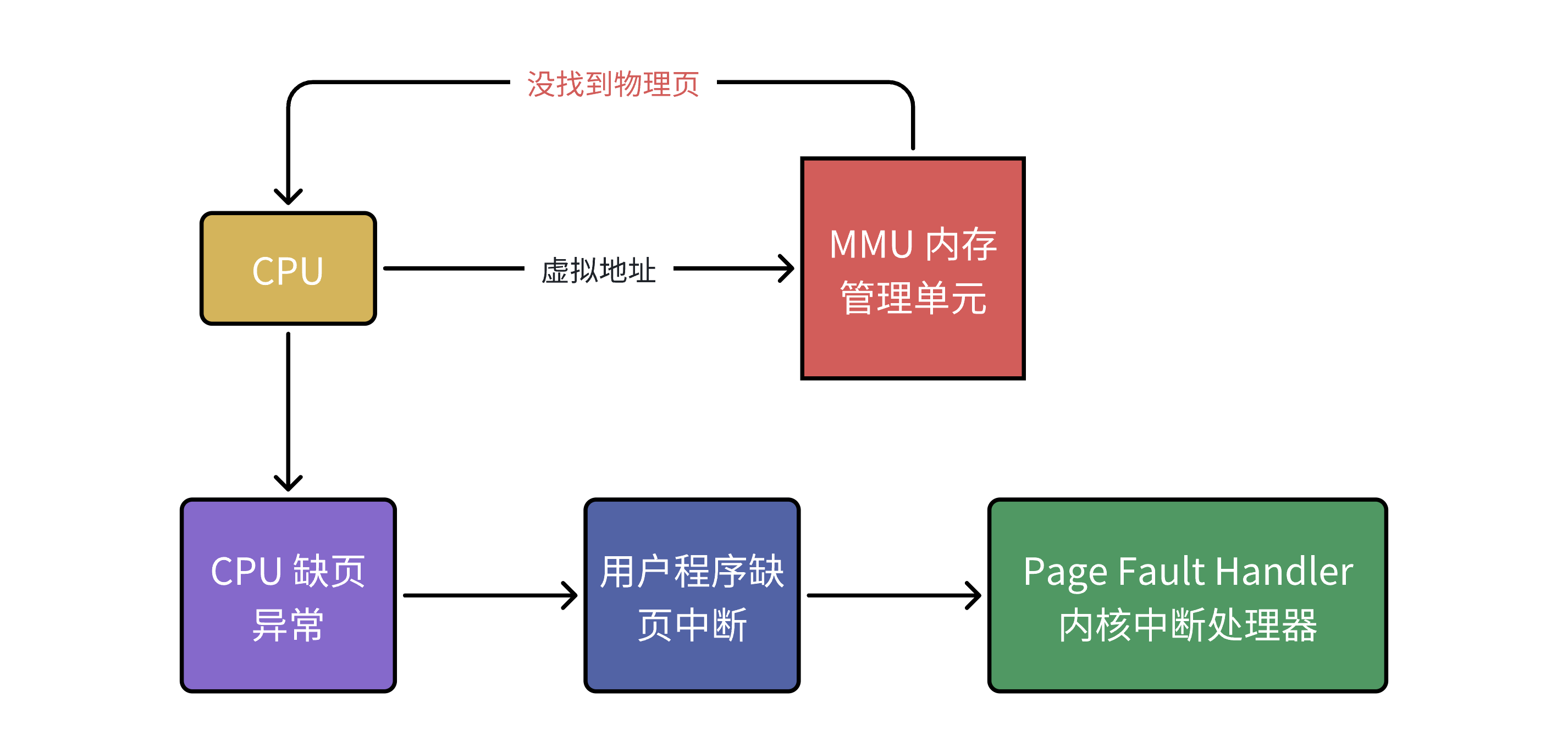
操作系统采用了按需分配的惰性策略,进程的虚拟地址空间虽然理论上覆盖整个范围(如32位系统的4GB),但实际仅对当前使用的区域初始化页表映射。(因为我们之前说过进程运行只需要几张物理页就行),如果我们把映射关系全部初始化,会浪费大量内存存储未使用的页表项。所以,当我们CPU给MMU的虚拟地址,在TLB与页表都没找到对应的物理页,该怎么办呢?
这个时候,就想到我们之前说过的延时分配机制,这个我们在讲进程的写实拷贝与动态内存管理申请空间时也提到过一点。比如在动态内存分配(malloc)时,操作系统并不会立即分配实际的物理页,而是等到程序首次访问这块内存时才通过缺页中断来真正分配;又如在 fork() 创建子进程时,父子进程共享相同的物理页,只有当某个进程尝试写入时,才会触发缺页中断并执行真正的页面复制。
写实拷贝真实是怎么做到的呢?原因是什么呢?
就是因为映射关系在页表上并未全部给你加载到内存上(虽然所有的映射关系早就初始化了),当程序首次访问未分配的堆内存、文件映射区域或换出到磁盘的页面时, MMU 在页表项中发现"存在位"(Present Bit)为0时,表明该虚拟页要么尚未关联物理页,要么对应的数据还未加载到内存中(可能被换出到交换空间)。这时,作为 CPU 一部分的 MMU 就会触发一个特殊的软中断,将控制权交给操作系统的缺页处理程序。内核会根据不同的缺页原因采取相应措施:对于未分配的页面会分配新的物理页;对于被换出的页面会从磁盘换回;对于权限不足的访问则会抛出段错误。处理完成后,操作系统会更新页表映射,并让 CPU 重新执行引发缺页的指令。
这个中断,就叫做缺页中断(缺页异常)。
正是通过缺页中断这个桥梁,现代操作系统才能如此优雅地实现虚拟内存管理,让每个进程都"错觉"自己独占了整个地址空间,而实际上物理内存资源在被所有进程高效共享。
总结
计算机系统的内存管理是一个环环相扣的精妙体系。当进程运行时,它看到的是一个连续的虚拟地址空间(32位系统为4GB),这个设计抽象了物理内存的碎片化问题。但虚拟地址必须转换为真实的物理地址才能访问内存,这个转换过程通过页表(Page Table)实现,而页表本身也存储在物理内存中。
而我们为了高效管理这个转换过程,采用多级页表结构(如x86的两级页表)。第一级是页目录,存储1024个页目录项(PDE),每个PDE指向一个页表;第二级页表存储1024个页表项,每个PTE最终指向4KB的物理页框。这种层级结构通过虚拟地址的10-10-12分拆实现:高10位定位页目录项,中间10位定位页表项,低12位作为页内偏移。
地址转换时,MMU首先查询TLB快表(缓存结构),若未命中则需遍历页表。为提升效率,操作系统采用按需分配策略:不会为整个4GB空间初始化页表,而是仅维护当前活跃区域的映射。当访问未映射的区域时,MMU发现页表项中"存在位"(Present Bit)为0,触发缺页异常。
缺页处理程序会根据不同情况采取行动:
-
若是首次访问的堆内存(如malloc分配),则分配物理页并建立映射
-
若是被换出的页面,则从交换空间换入
-
若是写时复制(COW)场景,则复制物理页并更新映射
这种机制与物理内存管理紧密耦合:操作系统通过伙伴系统管理物理页框分配,通过页缓存加速磁盘数据读取。
希望对大家有所帮助。
明天我们将重新讲回线程的知识点,这个知识点时讲到线程了顺带引出的,但也很重要!!!

















)

)