文章目录
- InstructBLIP:迈向通用视觉语言模型的指令微调研究总结
- 一、研究背景与目标
- 二、核心方法
- 数据构建与划分
- 模型架构
- 训练策略
- 三、实验结果
- 零样本性能
- 消融实验
- 下游任务微调
- 定性分析
- 可视化结果展示
- 四、结论与贡献
InstructBLIP:迈向通用视觉语言模型的指令微调研究总结
论文题目:InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning
论文链接:https://arxiv.org/pdf/2305.06500
一、研究背景与目标
-
挑战
视觉-语言任务因视觉输入的多样性和任务复杂性,难以通过单一模型实现通用化。现有方法中,多任务学习缺乏指令引导导致泛化能力弱,基于图像描述数据训练的视觉组件难以支撑复杂任务。 -
目标
提出 InstructBLIP 框架,通过视觉-语言指令微调,使模型能通过统一自然语言接口解决多种视觉-语言任务,实现零样本泛化和下游任务微调的最优性能。
二、核心方法
数据构建与划分
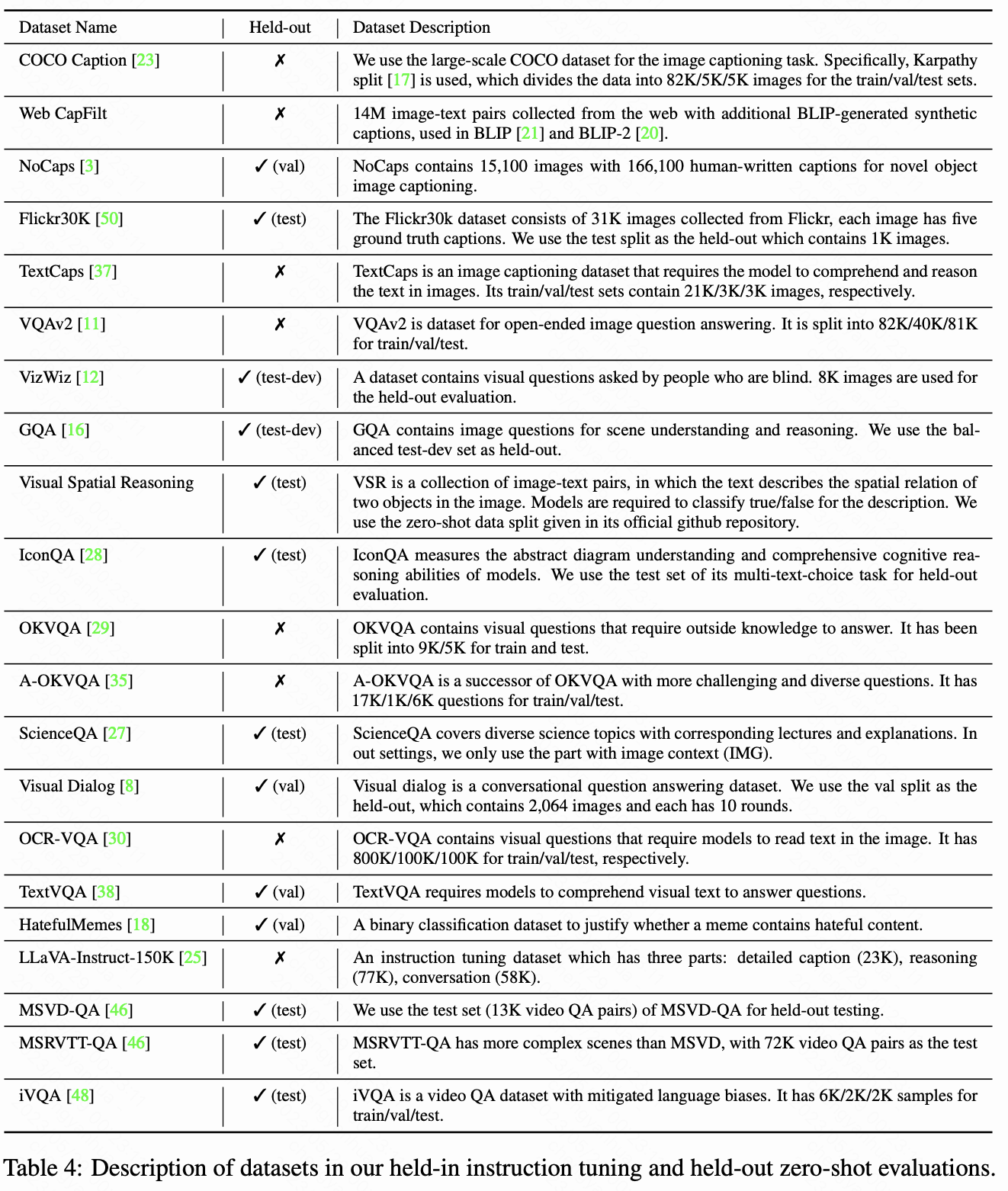
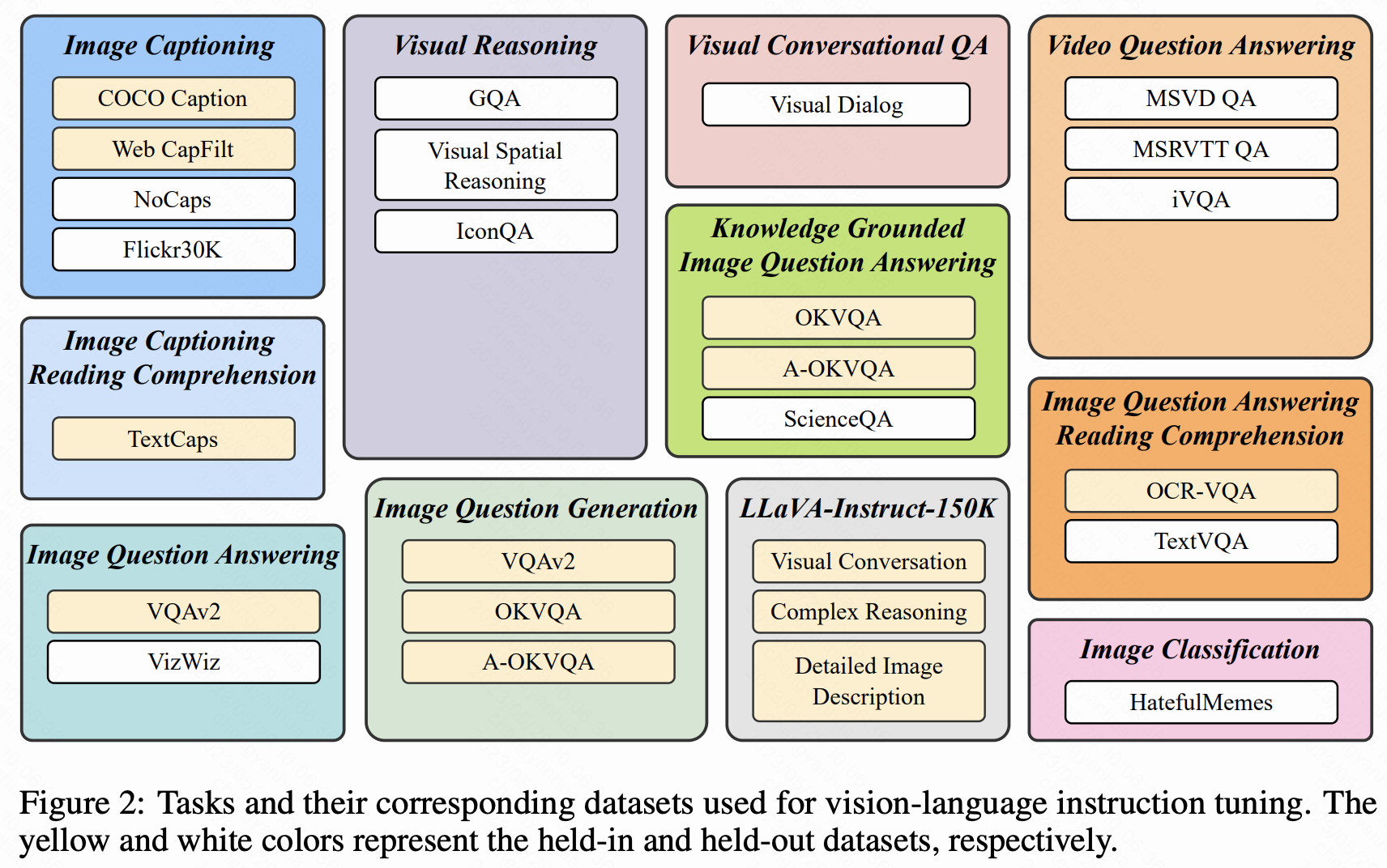
- 收集 26 个公开数据集,转化为指令微调格式,涵盖 11 类任务(如图像 captioning、视觉推理、视频问答等)。
- 划分 13 个数据集为训练集(held-in),13 个为零样本评估集(held-out),并保留 4 类任务(如视频 QA、视觉对话)用于任务级零样本测试。
指令数据:

模型架构
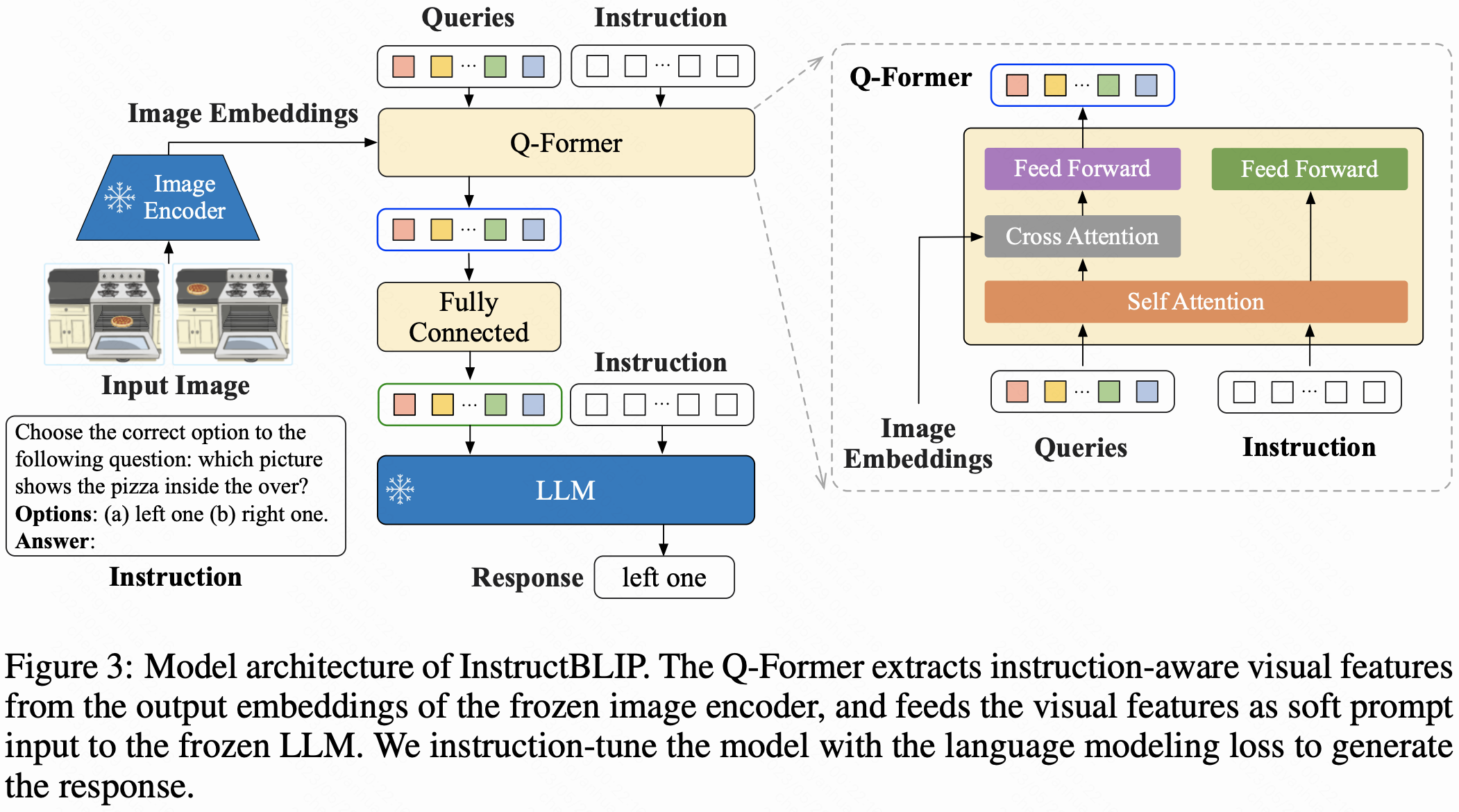
- 基于 BLIP-2 的模块化设计,包含冻结的图像编码器、LLM(如 FlanT5、Vicuna)和可微调的 Query Transformer(Q-Former)。
- 创新点:引入指令感知的视觉特征提取,将文本指令输入 Q-Former,使其提取与指令相关的视觉特征,增强任务适配性。
训练策略
- 平衡采样:按数据集大小的平方根比例采样,避免小数据集过拟合、大数据集欠拟合,并手动调整特定数据集权重(如降低 A-OKVQA、提高 OKVQA 权重)。
pd=Sd∑i=1DSip_d = \frac{\sqrt{S_d}}{\sum_{i=1}^{D} \sqrt{S_i}} pd=∑i=1DSiSd - 微调仅更新 Q-Former,冻结图像编码器和 LLM,减少训练参数,提升效率。
三、实验结果
零样本性能
- 在 13 个 held-out 数据集上全面超越 BLIP-2 和 Flamingo,例如 InstructBLIP FlanT5 XL 相对 BLIP-2 平均提升 15.0%,4B 参数模型性能超过 80B 参数的 Flamingo,平均提升 24.8%。
- 在未训练过的任务(如视频 QA)上表现优异,MSRVTT-QA 相对最优结果提升 47.1%。
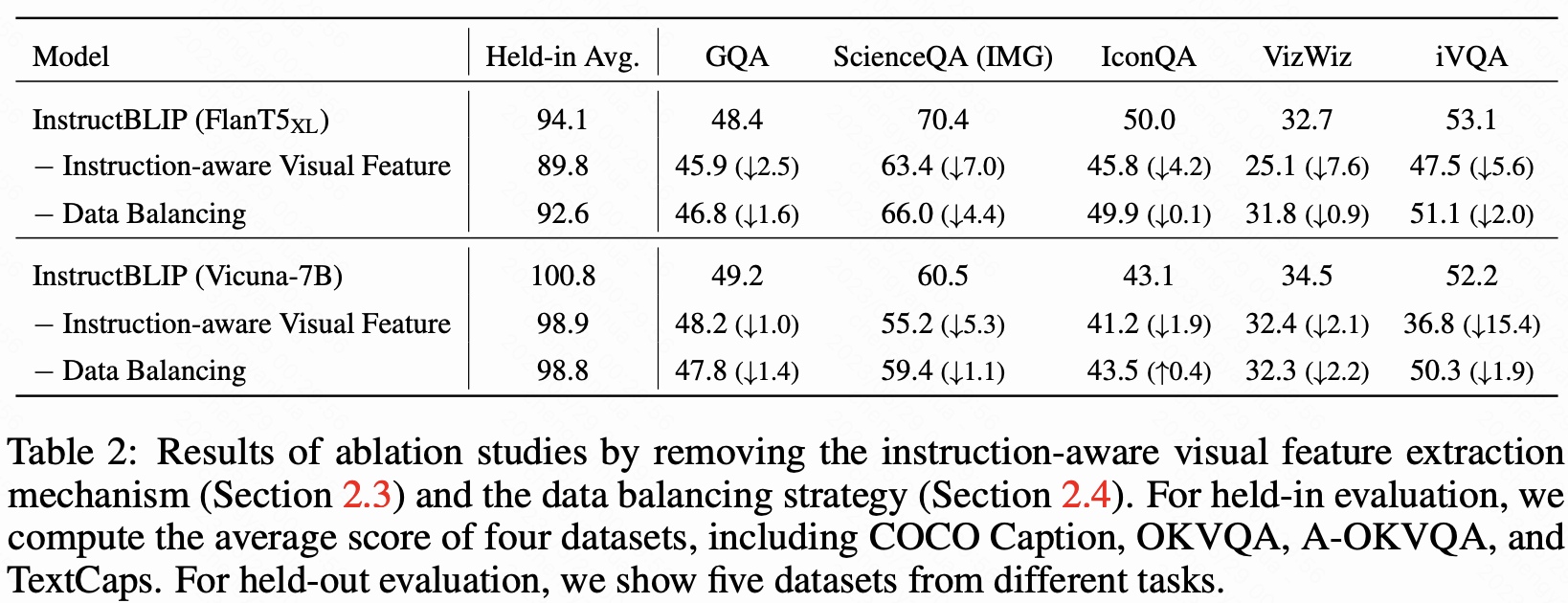
消融实验
- 移除指令感知特征提取后,空间 / 时间推理任务(如 ScienceQA、iVQA)性能显著下降(最多降低 7.6%)。
- 移除平衡采样导致训练不稳定,整体性能下降。
下游任务微调
- 作为初始化模型,在 ScienceQA(图像上下文)、OCR-VQA 等任务上刷新 SOTA,例如 ScienceQA 准确率达 90.7%。
- 冻结视觉编码器,训练参数从 1.2B 减至 188M,大幅提升微调效率。
定性分析
- 展现复杂视觉推理(如从场景推断灾害类型)、知识关联(如识别名画并介绍)、多轮对话等能力,响应更贴合指令意图,细节更准确。
可视化结果展示

四、结论与贡献
-
核心贡献:
- 系统研究视觉-语言指令微调,验证其对零样本泛化的有效性。
- 提出指令感知特征提取和平衡采样策略,提升模型适应性和训练稳定性。
- 开源基于 FlanT5 和 Vicuna 的 InstructBLIP 模型,为通用多模态 AI 研究提供基础。
-
优势:兼顾零样本泛化能力和下游任务微调效率,在多样化视觉-语言任务中表现出通用性和优越性。




——3DRPG游戏(2))

)






(上))





