提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 前言
- 工程创建
- 创建ck-oj
- 创建oj-modules
- 创建具体微服务oj-system
- 推送码云
- 管理员登录逻辑分析
- docker安装mysql
- docker客户端docker desktop安装
- 安装mysql
- mysql-plus和数据库连接池介绍
- 数据库连接池
- 为什么采⽤HikariCP
- 集成mybatis-plus和数据库连接池
- 管理员登录-表结构设计
- 实体类
- 雪花算法
- 为什么不使⽤⾃增id
- 如何处理⾃增id问题:
- 为什么不使⽤uuid作为主键
- 实体类代码优化
- lombok
- BaseEntity
- 接口文档
- 内容
- ⾃定义状态码和统一数据返回
- 接口文档定义
- Swagger
- 介绍
- 引入
- Swagger注解使用
- 访问接口文档
- 测试功能
- 总结
前言
工程创建
先开发B端在开发C端
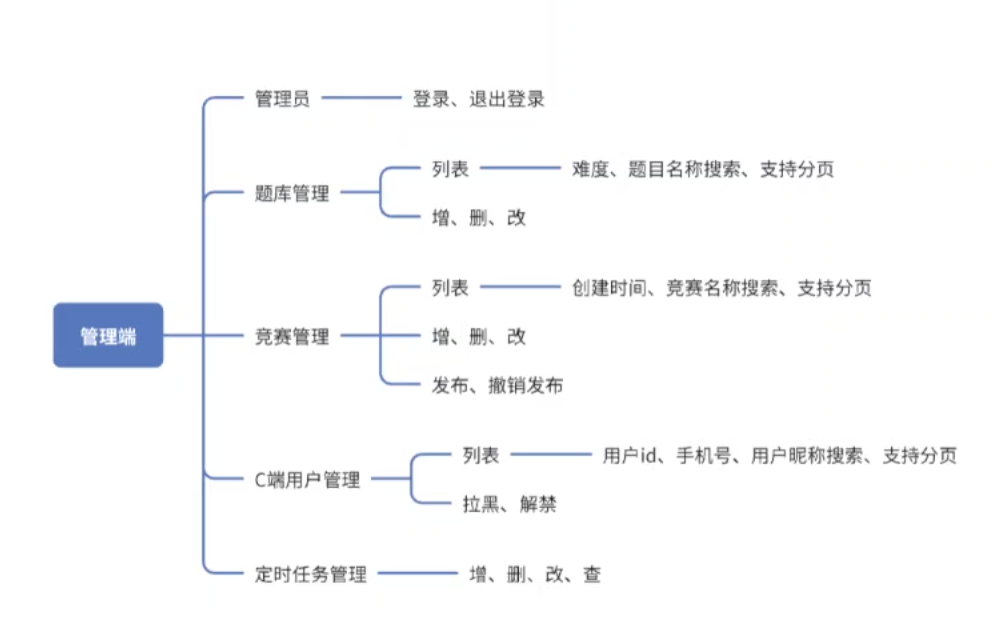
在做后端,在做前端
先做登录

按照这个层级结构进行创建
创建ck-oj

创建最外层ck-oj,然后删掉src,因为这个不写代码
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0
http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>3.0.1</version><relativePath/> <!-- lookup parent from repository --></parent><groupId>com.ck</groupId><artifactId>ck-oj</artifactId><version>1.0-SNAPSHOT</version><properties><maven.compiler.source>17</maven.compiler.source><maven.compiler.target>17</maven.compiler.target><spring-boot.version>3.0.1</spring-boot.version><spring-cloud-alibaba.version>2022.0.0.0-RC2</spring-cloud-alibaba.version><spring-cloud.version>2022.0.0</spring-cloud.version></properties><dependencies><!-- bootstrap 启动器 --><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-bootstrap</artifactId></dependency></dependencies><dependencyManagement><dependencies><!-- SpringCloud Alibaba 微服务 --><dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-alibaba-dependencies</artifactId><version>${spring-cloud-alibaba.version}</version><type>pom</type><scope>import</scope></dependency><!-- SpringCloud 微服务 --><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-dependencies</artifactId><version>${spring-cloud.version}</version><type>pom</type><scope>import</scope></dependency><!-- SpringBoot 依赖配置 --><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-dependencies</artifactId><version>${spring-boot.version}</version><type>pom</type><scope>import</scope></dependency></dependencies></dependencyManagement>
</project>
更改依赖
创建oj-modules

删除srcmul,更改pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><parent><groupId>com.ck</groupId><artifactId>ck-oj</artifactId><version>1.0-SNAPSHOT</version></parent><artifactId>oj-modules</artifactId><properties><maven.compiler.source>17</maven.compiler.source><maven.compiler.target>17</maven.compiler.target><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding></properties><dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency></dependencies></project>
创建具体微服务oj-system

然后是创建启动类
@SpringBootApplication
public class OjSystemApplication {public static void main(String[] args) {SpringApplication.run(OjSystemApplication.class, args);}
}
还有配置文件bootsrap.yml
这个是最先加载的配置文件
server:port: 9201spring:application:name: oj-system
其他同理


在服务这里可以对服务进行统一的启动和停止
推送码云


git config --global user.name ""
git config --global user.email ""
mkdir ck-oj //已经有了,不用执行
cd ck-oj
git init
touch README.md //防止仓库为空才创建的,我们的目录不为空,所以不用执行
git add README.md
git commit -m "first commit"
git remote add origin https://gitee.com/once-three-hearted-grass/ck-oj.git
git push -u origin "master"
这样就成功了
管理员登录逻辑分析
管理员用账号密码登录,C端使用手机号和验证码登录
不提供管理员注册功能,提供一个不带外开放的新增管理员接口


docker安装mysql
docker客户端docker desktop安装
安装官网

在这里下载
首页点击get docker
然后就是一直安装就可以了
安装wsl
等等
这个的原理就是在本地安装使用一个docker,和在本地使用镜像等等
打开 Docker Desktop,点击任务栏图标 → Settings(或右键菜单)。
选择 Docker Engine,在 JSON 配置中添加以下内容
修改镜像源
修改成这样就可以了```bash
{"builder": {"gc": {"defaultKeepStorage": "20GB","enabled": true}},"experimental": false,"registry-mirrors": ["https://registry.docker-cn.com","http://hub-mirror.c.163.com","https://docker.mirrors.ustc.edu.cn","https://dockerhub.azk8s.cn","https://mirror.ccs.tencentyun.com","https://registry.cn-hangzhou.aliyuncs.com","https://docker.mirrors.ustc.edu.cn","https://docker.1panel.live","https://atomhub.openatom.cn/","https://hub.uuuadc.top","https://docker.anyhub.us.kg","https://dockerhub.jobcher.com","https://dockerhub.icu","https://docker.ckyl.me","https://docker.awsl9527.cn"]
}
安装mysql
# 下载镜像到本地
docker pull mysql:5.7docker run -d --name oj-mysql -p 3306:3306 -e "TZ=Asia/Shanghai" -e "MYSQL_ROOT_PASSWORD=123456" mysql:5.7docker run启动一个容器
-d表示后台运行
–name指定名称
-p就是端口映射
-e是指定时区和root用户的密码
运行成功返回一个id
docker ps -a 显示全部容器
docker ps 显示正在运行的容器
docker rm 名称或者id
删除一个容器
docker exec -it 容器id bash
进入一个容器
mysql -u root -p123456
# 创建oj项⽬⽤⼾
CREATE USER 'ojtest'@'%' IDENTIFIED BY '123456';然后就是创建数据库
CREATE database if NOT EXISTS `ckoj_dev` ;然后就是为这个用户赋予这个数据库的权限
GRANT CREATE,DROP,SELECT, INSERT, UPDATE, DELETE ON ckoj_dev.* TO 'ojtest'@'%';
创建测试表,并插⼊测试数据
用新用户登录一下数据库
exit
mysql -u ojtest -p123456
show databases;
use ckoj_dev
创建一个表
CREATE TABLE `tb_test` (`test_id` bigint unsigned NOT NULL,`title` text NOT NULL,`content` text NOT NULL,PRIMARY KEY (`test_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
INSERT INTO tb_test values(1,'test','test');
select * from tb_test;
update tb_test set title = 'test_update' where test_id = 1;
delete from tb_test;
测试一下

这个就是数据库管理工具
mysql-plus和数据库连接池介绍
数据库连接池
借助mybatis-plus操作数据库虽然给我们提供了很⼤的便捷,但是这样⽅式操作数据库还是会存在⼀些问题:
• 频繁的创建连接和销毁连接:包括TCP层的握⼿和MySQL协议握⼿,这会消耗⼤量时间。
• 连接数不受控制:在业务流量⾼峰期,⼤量应⽤服务器可能同时请求数据库连接,⽽数据库能够承载的连接数有限,这可能导致数据库性能降低。
• 连接管理困难:开发者需要⾃⾏管理数据库连接的创建、使⽤和关闭,这增加了开发的复杂性和出错的可能性。
数据库连接池就是⽤来解决我们上⾯提到的这些问题,通过数据库连接池我们可以:
• 提供统⼀的管理:数据库连接池提供对数据库连接创建等操作的统⼀管理。
• 提⾼系统性能 :由于创建和销毁数据库连接需要消耗时间和系统资源,如果每次需要进⾏数据库操作时都进⾏创建和销毁连接,会极⼤地影响系统性能。⽽使⽤连接池,可以复⽤已经创建好的连接,⼤⼤提⾼了系统的性能。
• 提⾼资源利⽤率 :连接池通过复⽤已有连接,避免了频繁创建和销毁连接带来的资源浪费,提⾼了系统资源的利⽤率。
• 提⾼系统稳定性 :数据库连接池可以有效地控制系统中并发访问数据库的连接数量,避免因并发连接数过多⽽导致数据库崩溃。同时,连接池还会定时检查连接的有效性,⾃动替换掉⽆效连接,保证了系统的稳定性。

要设置的为初始连接数3,最大连接数4,空闲时间10,超时时间10
事先创建好3个mybatis与数据库的连接,如果a,b,c三个请求直接过来就可以链接了
第四个d请求来的话,如果前面处理完了,就可以接着使用,如果前面的还没有处理完,那么就创建一个新的连接,为第四个
当e来的时候,没有空余的链接的话,又因为最大链接为4,所以就会等待,等待10s,这个10s就是超时时间,超时的话,那么就请求失败了
如果10s中之类,也就是空闲时间之类,没有人使用第四个链接的话
那么第四个链接就会关闭掉了
常⻅的数据库连接池:
C3P0、Druid、HikariCP
为什么采⽤HikariCP
⾼性能:HikariCP是⼀个⾼性能的数据库连接池,它提供了快速、低延迟的连接获取和释放机制。在Spring Boot项⽬中,这可以显著提⾼应⽤程序的响应速度和吞吐量,特别是在⾼并发场景下表现尤为出⾊。
资源优化:HikariCP对资源的使⽤进⾏了精细的管理和优化。它采⽤了⼀种内存效率极⾼的数据结构
来存储和管理连接,减少了内存占⽤和垃圾回收的压⼒。此外,HikariCP还通过减少不必要的线程和锁竞争,进⼀步降低了系统资源消耗。
配置灵活:HikariCP提供了丰富的配置选项,允许开发者根据项⽬的具体需求进⾏微调。通过调整连接池⼤⼩、超时时间、连接⽣命周期等参数,可以优化连接池的性能和稳定性。
与Spring Boot集成良好:Spring Boot对HikariCP提供了良好的⽀持,可以轻松地在项⽬中集成和使⽤。Spring Boot的⾃动配置功能可以⾃动配置HikariCP的连接池参数,简化了配置过程。
默认都使用的这个数据库连接池
集成mybatis-plus和数据库连接池
先引入mybatis-plus的依赖
看官网
<dependency><groupId>com.baomidou</groupId><artifactId>mybatis-plus-spring-boot3-starter</artifactId><version>3.5.12</version>
</dependency>
我们在oj-system进行测试
但是这样不利于我们做版本管理,我们可以在ck-oj这里做好版本管理
<properties><maven.compiler.source>17</maven.compiler.source><maven.compiler.target>17</maven.compiler.target><spring-boot.version>3.0.1</spring-boot.version><spring-cloud-alibaba.version>2022.0.0.0-RC2</spring-cloud-alibaba.version><spring-cloud.version>2022.0.0</spring-cloud.version><mybatis-plus.version>3.5.12</mybatis-plus.version></properties>
<dependency><groupId>com.baomidou</groupId><artifactId>mybatis-plus-spring-boot3-starter</artifactId><version>${mybatis-plus.version}</version></dependency>
然后就可以这样引入了
除了引入mabatis,如果要操作数据库的话,还要引入mysql的驱动
<dependency><groupId>com.mysql</groupId><artifactId>mysql-connector-j</artifactId></dependency>
这个不用指定版本号
因为在ck-oj里面对版本号做了指定的
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-dependencies</artifactId><version>${spring-boot.version}</version><type>pom</type><scope>import</scope></dependency>
左键spring-boot-dependencies就可以看到mysql驱动的版本号了
@TableName("tb_test")
public class TestDomain {private Integer testId;private String title;private String content;
}
记得还要get和set方法
@SpringBootApplication
@MapperScan("com.ck.system.**.mapper")
public class OjSystemApplication {public static void main(String[] args) {SpringApplication.run(OjSystemApplication.class, args);}
}
@MapperScan(“com.ck.system.**.mapper”)启动类上的这个就可以把mapper包下面的接口都注入到spring中
spring:application:name: oj-systemdatasource:url: jdbc:mysql://localhost:3306/ckoj_dev?useUnicode=true&characterEncoding=utf8&useSSL=true&serverTimezone=GMT%2B8username: ojtestpassword: 123456hikari:minimum-idle: 5 # 最⼩空闲连接数maximum-pool-size: 20 # 最⼤连接数idle-timeout: 30000 # 空闲连接存活时间(毫秒)connection-timeout: 30000 # 连接超时时间(毫秒)
hikari是springboot自带的,就算不配置,也会有默认的配置的,但还是配置一下吧
@Service
public class TestServiceImpl implements TestService{@Autowiredprivate TestMapper testMapper;@Overridepublic List<?> list() {return testMapper.selectList(new LambdaQueryWrapper<>());}
}

管理员登录-表结构设计
## datetime可以显示 年月日时分秒
create table tb_sys_user(user_id bigint unsigned not null comment '用户id',user_account varchar(20) not null comment '账号',password varchar(20) not null comment '密码',create_by bigint unsigned not null comment '创建人',update_by bigint unsigned comment '修改人',create_time datetime not null comment '创造时间',update_time datetime comment '修改时间',primary key(`user_id`),unique key `idx_user_account` (`user_account`)
)
unique key是唯一索引
实体类
bitint对应Long
datetime 对应LocalDateTime
@TableName("tb_sys_user")
public class SysUser {private Long userId;private String userAccount;private String password;private Long createBy;private Long updateBy;private LocalDateTime createTime;private LocalDateTime updateTime;
}
记得还要有get和set方法
雪花算法
主键我们不再使用自动增长的id
为什么不使⽤⾃增id
• 数据迁移和备份:如果你需要将数据从⼀个数据库迁移到另⼀个数据库,或者备份和恢复数据,⾃增主键可能会导致问题。例如,如果你在新数据库中已经存在与旧数据库相同的⾃增 ID,那么插⼊操作可能会失败。
• 删除和插⼊操作:如果表中存在⼤量删除和插⼊操作,⾃增主键可能会导致 ID 值的不连续。这可能会浪费存储空间,并可能导致某些应⽤程序或系统逻辑出现问题。
• 性能问题:在⾼并发的写⼊操作中,⾃增主键可能会导致性能瓶颈。因为每次插⼊新记录时,数据库都需要找到下⼀个可⽤的⾃增 ID。这可能会增加写操作的延迟。
• 可预测性:⾃增主键的值是可预测的,因为它们总是按照递增的顺序⽣成。这可能会带来安全⻛险,例如,攻击者可能会尝试预测未来的 ID 值来插⼊恶意数据。
• 分布式环境问题:在分布式数据库系统中,⾃增主键可能会带来挑战。如何保证各个节点⽣成的⾃增id是唯⼀的,这将需要额外的机制来协调各个节点。
如何处理⾃增id问题:
使⽤uuid或者雪花算法⽣成的主键。
• uuid:UUID(Universally Unique Identifier,通⽤唯⼀识别码)是⼀种软件建构的标准,⽤于在分布式计算环境中为元素提供唯⼀的辨识信息。UUID共占128位,分为五段,它具有唯⼀性、全局性、不变性等特点。
• 雪花算法:雪花算法(Snowflake)是⼀种分布式唯⼀ID⽣成算法,⽤于⽣成全局唯⼀的ID。它的设计⽬标是在分布式系统中⽣成ID,保证ID的唯⼀性、有序性和趋势递增。雪花算法的核⼼思想是将⼀个64位的ID分成多个部分,分别表⽰不同的信息。

时间戳是精确到毫秒级的,是唯一的,机器表示又可以减少重复性,最后一个是一毫秒内生成id的序号
为什么不使⽤uuid作为主键
存储空间:UUID存储会占⽤更⼤的空间,这会增加数据库的存储需求,尤其是在⼤型数据库或⾼并发的系统中,这可能会成为性能瓶颈。
索引性能:由于UUID相对较⼤,使⽤UUID作为主键会导致索引变得更⼤,从⽽影响查询性能。特别是在执⾏范围查询或JOIN操作时,性能下降可能会更加明显。
可读性:UUID由⼀串字符组成,不易于⼈类阅读或记忆。这可能会影响到开发、运维和调试的便利性。
使用uuid的话,还必须为字符串类型的,因为uuid含有字母,但是雪花算法就没有字母,全是数字
@TableId(type = IdType.ASSIGN_ID)private Long testId;
ASSIGN_ID就是雪花算法的id
ASSIGN_UUID才是uuid
@GetMapping("/add")public String add() { return testService.add();}

这样就成功了
实体类代码优化
@TableId(type = IdType.ASSIGN_ID)private Long userId;
lombok
<dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId>
</dependency>
lombok因为都会用,所以直接放在ck-oj
@TableName("tb_sys_user")
@Data
public class SysUser {@TableId(type = IdType.ASSIGN_ID)private Long userId;private String userAccount;private String password;private Long createBy;private Long updateBy;private LocalDateTime createTime;private LocalDateTime updateTime;
}
BaseEntity
然后就是createBy这些字段可以提取出来为BaseEntity,供所有的基本类的使用
@TableName("tb_sys_user")
@Data
public class SysUser extends BaseEntity{@TableId(type = IdType.ASSIGN_ID)private Long userId;private String userAccount;private String password;
}
@Data
public class BaseEntity {private Long createBy;private Long updateBy;private LocalDateTime createTime;private LocalDateTime updateTime;
}
因为BaseEntity 会给所有的oj-modules使用
所以我们在建一个模块来放这些都要使用的东西
然后就是有些公共部分是所有模块都要使用的,比如BaseEntity
但是有些公共部分,比如redis,就可能只有部分模块要使用的,所以我们在oj-common里面再放一个模块oj-common-core来放所有模块都要使用的东西

然后oj-modules里面都会使用BaseEntity的,所以我们直接在oj-modules里面引入oj-common-core
<dependency><groupId>com.ck</groupId><artifactId>oj-common-core</artifactId><version>1.0-SNAPSHOT</version></dependency>
版本号统一在ck-oj里面管理
<oj-common-core.version>1.0-SNAPSHOT</oj-common-core.version>
<dependency><groupId>com.ck</groupId><artifactId>oj-common-core</artifactId><version>${oj-common-core.version}</version></dependency>
这样就行了
import com.ck.common.core.domain.BaseEntity;
接口文档
内容
• 接⼝概述:包括接⼝名称、接⼝功能、接⼝类别等。
• 接⼝地址:接⼝的唯⼀访问地址。
• 请求⽅法:定义接⼝的请求⽅式,如GET(查询)、POST(新增)、PUT(修改)、DELETE(删除)等。
• 请求参数:定义请求时需要传递的参数,包括路径参数(PathParameters)、查询参数(QueryParameters)、请求头(Headers)、请求体(Body)等。
• 响应数据:定义接⼝返回的数据格式,包括状态码(Status Code)、消息(Message)、数据体(Data)等。(注意:包含接⼝请求出现错误时,返回的状态码和错误信息。不同接⼝格式统⼀状态码含义相同)
• 请求和响应⽰例:为了更好地描述接⼝的使⽤,接⼝⽂档中会提供⼀些具体的接⼝请求和响应⽰
例,以供读者参考。
public class R<T> {/*** 消息状态码*/private int code;/*** 消息内容*/private String msg;/*** 数据对象*/private T data;
}
Http协议状态码

⾃定义状态码和统一数据返回
1000 SUCCESS
服务器报错
2000 ERROR 服务繁忙请稍后重试(前端根据错误码显⽰:服务繁忙请稍后重试)
操作失败,但是服务器不存在异常,这个是执行错误
3000 FAILED 操作失败
这个业务错误是自己判断出来的错误,比如密码错误,用户名重复等等
3001 FAILED_UNAUTHORIZED 未授权
@Data
public class R <T>{private int code;private String msg;private T data;
}
@AllArgsConstructor
@Getter
public enum ResultCode {//操作唱功SUCCESS (1000, "操作成功"),//服务器内部错误,友好提⽰ERROR (2000, "服务繁忙请稍后重试"),//操作失败,但是服务器不存在异常FAILED (3000, "操作失败"),FAILED_UNAUTHORIZED (3001, "未授权"),FAILED_PARAMS_VALIDATE (3002, "参数校验失败"),FAILED_NOT_EXISTS (3003, "资源不存在"),FAILED_ALREADY_EXISTS (3004, "资源已存在"),AILED_USER_EXISTS (3101, "⽤⼾已存在"),FAILED_USER_NOT_EXISTS (3102, "⽤⼾不存在"),FAILED_LOGIN (3103, "⽤⼾名或密码错误"),FAILED_USER_BANNED (3104, "您已被列⼊⿊名单, 请联系管理员.");private int code;private String msg;
}
枚举类型必须定义一个构造函数,所以用注解AllArgsConstructor
接口文档定义
@RequestMapping("/login")public R<Void> login(LoginDTO loginDTO){return sysUserService.login(loginDTO.getUserAccount(), loginDTO.getPassword());}
@Overridepublic R<Void> login(String userAccount, String password) {LambdaQueryWrapper<SysUser> queryWrapper = new LambdaQueryWrapper<>();queryWrapper.select(SysUser::getPassword).eq(SysUser::getUserAccount, userAccount);SysUser sysUser = sysUserMapper.selectOne(queryWrapper);R<Void> r = new R<>();if(sysUser == null){r.setCode(ResultCode.FAILED_USER_NOT_EXISTS.getCode());r.setMsg(ResultCode.FAILED_USER_NOT_EXISTS.getMsg());return r;}if(!sysUser.getPassword().equals(password)){r.setCode(ResultCode.FAILED_LOGIN.getCode());r.setMsg(ResultCode.FAILED_LOGIN.getMsg());return r;}r.setCode(ResultCode.SUCCESS.getCode());r.setMsg(ResultCode.SUCCESS.getMsg());return r;}
Swagger
介绍
官网
Swagger是⼀个接⼝⽂档⽣成⼯具,它可以帮助开发者⾃动⽣成接⼝⽂档。当项⽬的接⼝发⽣变更时,Swagger可以实时更新⽂档,确保⽂档的准确性和时效性。Swagger还内置了测试功能,开发者可以直接在⽂档中测试接⼝,⽆需编写额外的测试代码。
引入
这是一个公共的组件,所以得在oj-common里面使用,但是并不是所有的模块都要使用,所以创建一个oj-common-swagger
<dependency><groupId>org.springdoc</groupId><artifactId>springdoc-openapi-starter-webmvc-ui</artifactId><version>2.2.0</version></dependency>
<springdoc-openapi.version>2.2.0</springdoc-openapi.version>
@Configuration
public class SwaggerConfig {@Beanpublic OpenAPI openAPI() {return new OpenAPI().info(new Info().title("在线oj系统").description("在线oj系统接⼝⽂档").version("v1"));}
}
这个是swagger的配置类
定义在oj-common-swagger
但是这个配置类是一个bean,被其他模块引入的时候,是不会自动注入到其他模块的bean中的
所以还要配置,让oj-common-swagger中的bean,在oj-common-swagger被引入依赖的时候,自动注入到那个引入它的模块中
在resources目录下创建文件夹META-INF/spring,spring是子文件夹,然后再里面创建文件
org.springframework.boot.autoconfigure.AutoConfiguration.imports
配置com.ck.common.swagger.SwaggerConfig
这样就可以了

这样就可以了
然后再oj-system里面
<dependency><groupId>com.ck</groupId><artifactId>oj-common-swagger</artifactId><version>${oj-common-swagger.version}</version></dependency>
就可以使用swagger了
Swagger注解使用
@Tag(name = "管理员用户接口API")
public class SysUserController {
Tag注解使用在类的上面,表示对这个类的所有接口进行分组的描述
@Operation(summary = "新增管理员", description = "根据提供的信息新增管理员⽤⼾")@PostMapping("/add")@ApiResponse(responseCode = "1000", description = "操作成功")@ApiResponse(responseCode = "2000", description = "服务繁忙请稍后重试")@ApiResponse(responseCode = "3101", description = "⽤⼾已存在")public R<Void> add(@RequestBody SysUserSaveDTO saveDTO) {return null;}
Operation在方法上面使用,表示对这个接口的总体描述
ApiResponse描述code和msg
@Data
public class SysUserSaveDTO {@Schema(description = "用户账号")private String userAccount;@Schema(description = "用户密码")private String password;
}
Schema用于描述字段
@DeleteMapping("/{userId}")@Operation(summary = "删除⽤⼾", description = "通过⽤⼾id删除⽤⼾")@Parameters(value = {@Parameter(name = "userId", in = ParameterIn.PATH, description = "⽤⼾ID")})@ApiResponse(responseCode = "1000", description = "成功删除⽤⼾")@ApiResponse(responseCode = "2000", description = "服务繁忙请稍后重试")@ApiResponse(responseCode = "3101", description = "⽤⼾不存在")public R<Void> delete(@PathVariable Long userId) {return null;}
@Parameters
◦ 介绍:⽤于指定@Parameter注解对象数组,描述操作的输⼊参数。
◦ ⽤于:⽅法。
• @Parameter
◦ 介绍:⽤于描述输⼊参数。
◦ ⽤于:⽅法。
◦ 常⽤属性:
▪ name:参数的名称。
▪ in:参数的位置,可以是 path、query、header、cookie 中的⼀种。
▪ description:参数的描述。
其中如果是PathVariable 类型的话,对应就是PATH
@Operation(summary = "⽤⼾详情", description = "根据查询条件查询⽤⼾详情")@GetMapping("/detail")@Parameters(value = {@Parameter(name = "userId", in = ParameterIn.QUERY, description = "⽤⼾ID"),@Parameter(name = "sex", in = ParameterIn.QUERY, description = "⽤⼾性别")})@ApiResponse(responseCode = "1000", description = "成功获取⽤⼾信息")@ApiResponse(responseCode = "2000", description = "服务繁忙请稍后重试")@ApiResponse(responseCode = "3101", description = "⽤⼾不存在")public R<SysUserVO> detail(@RequestParam(required = true) Long userId, @RequestParam(required = false) String sex) {return null;}
如果是get请求的RequestParam的话,对应就是QUERY
访问接口文档
访问网址http://127.0.0.1:9201/swagger-ui/index.html
这样就成功了

swaggerconfig配置的就是最上面的标题和描述
然后完善一下我们的login接口
@PostMapping("/login")@Operation(summary = "用户登录", description = "用户用账号和密码登录")@ApiResponse(responseCode = "1000", description = "操作成功")@ApiResponse(responseCode = "2000", description = "服务繁忙请稍后重试")@ApiResponse(responseCode = "3102", description = "⽤⼾不存在")@ApiResponse(responseCode = "3103", description = "⽤⼾名或密码错误")public R<Void> login(LoginDTO loginDTO){return sysUserService.login(loginDTO.getUserAccount(), loginDTO.getPassword());}
测试功能
swagger还有一个测试功能
其实很简单,就是打断点,然后用debug的形式启动项目
然后去接口文档上面try it ot
就可以了



这样就成功了



)










-实现四层负载均衡)




:sqlmap快速上手)