1.文本预处理
分词,词性标注,命名实体识别
1.1分词:jieba
jieba.lcut(content,cut_all=true) 全模式
jieba.lcut(content,cut_all=false) 精确模式
jieba.lcut_for_search(content) 搜索引擎模式
lcut和cut的区别:cut返回的是一个生成器Generator,lcut返回的是列表
生成器调用的几种方式
变量=next(generater) 第n次调用取第n个生成器的值,可以多次调用或者循环调用
for i in generater i就是每次生成器生成的值
变量= generater.send(value) value传给生成器,生成器传值出来
变量= list(generater) 将生成器所有的数据转换成列表
1.2词性标注 词性:语言中对词的一种分类方法
使用jieba.posseg ss pseg
pseg.lcut(content)
1.3命名实体识别
命名实体: 通常我们将人名, 地名, 机构名等专有名词统称命名实体. 如: 周杰伦, 黑山县, 孔子学院, 24辊方钢矫直机.
一般使用训练好的模型来进行命名实体识别
在迁移学习中使用模型:chinese_pretrain_mrc_roberta_wwm_ext_large
1.4文本的张量表示方法:one-hot,word2vec:cbow,skipgram,word-embedding
one-hot又称独热编码,将每个词表示成具有n个元素的向量,这个词向量中只有一个元素是1,其他元素都是0,不同词汇元素为0的位置不同,其中n的大小是整个语料中不同词汇的总数.
实现简单但完全割裂了词语词之间的关系
word2vec::构建神经网络模型, 将网络参数作为词汇的向量表示
捕捉词语之间的语义和语法关系,但无法处理多义词切忽略词序,同时依赖大数据
cbow 上下文预测中间
skipgram 中间预测上下文
使用fasttext工具训练词向量
word embedding:通过一定方式将词汇映射到指定维度
torch.nn.Embedding(vocab_size, embedding_dim=8) 传入的时候索引不能大于vocab_size不然会索引越界报错
文本数据分析:标签数量分布,句子长度分布,词频统计,关键词词云
词云模组: from wordcloud import WordCloud
词性识别 import jieba.posseg as pseg
文本特征处理:n-gram,文本长度规范
n-gram set(zip(*[input_list[i:] for i in range(ngram_range)]))
zip作用是把多个可迭代对象打包
a = [1, 2, 3]
b = ['a', 'b', 'c']
print(list(zip(a, b))) # 输出: [(1, 'a'), (2, 'b'), (3, 'c')][1,3,5](@ref)
文本长度规范
一般使用padding进行补齐,截断的方式可以采用切片
随机森林的截断方式 df_data['text'].apply(lambda x: " ".join(jieba.lcut(x)[:30]))
bert的补齐与截断
text_tokens = conf.tokenizer.batch_encode_plus(texts,add_special_tokens=True,padding='max_length', #补齐max_length=conf.pad_size,truncation=True, #截断return_attention_mask=True)
文本数据增强:回译数据增强(写论文)
翻译成另一种语言在翻译回来,或者a-b-c-d-a
RNN及其变体
传统rnn模型:优势简单:劣势 梯度更新序列太长容易消失(梯度无法更新训练失败)或者爆炸(溢出nan)
把当前步的输入x(t)和上一步的输出h(t-1)拼起来经过一个全连接层使用tanh作为激活函数得到下一步时间步ht(t)与下一个时间步输入x(t+1)重复这个过程
如果是x是第一个则拼接的是初始化的隐藏层h0
最终输出
output 包含所有隐藏输出h0-hn
hn (能代表这个语句)
隐藏层创建rnn = nn.RNN(input_size, hidden_size, num_layer)
x的维度 隐藏层输出维度 隐藏层层数
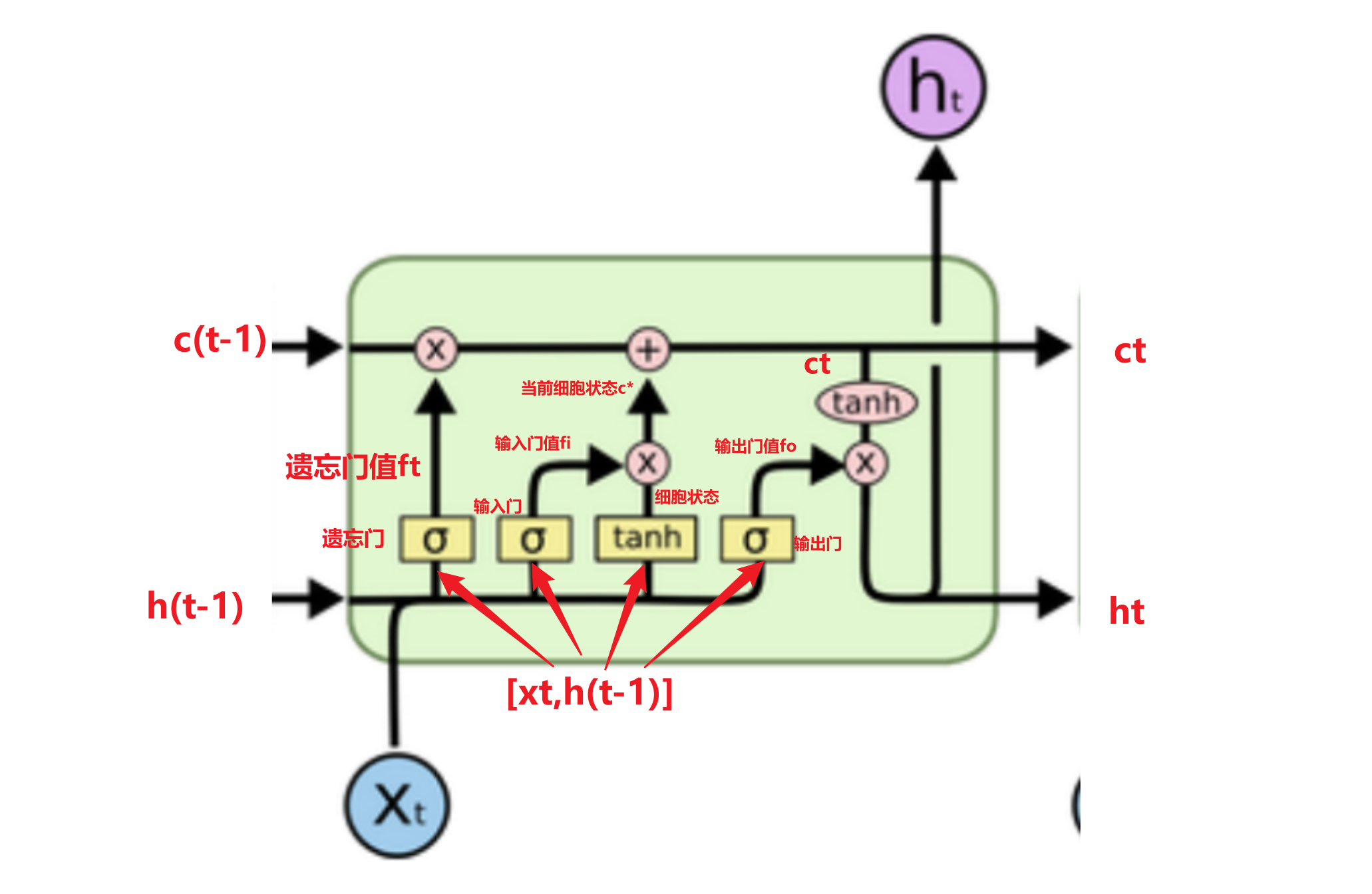
lstm
gru
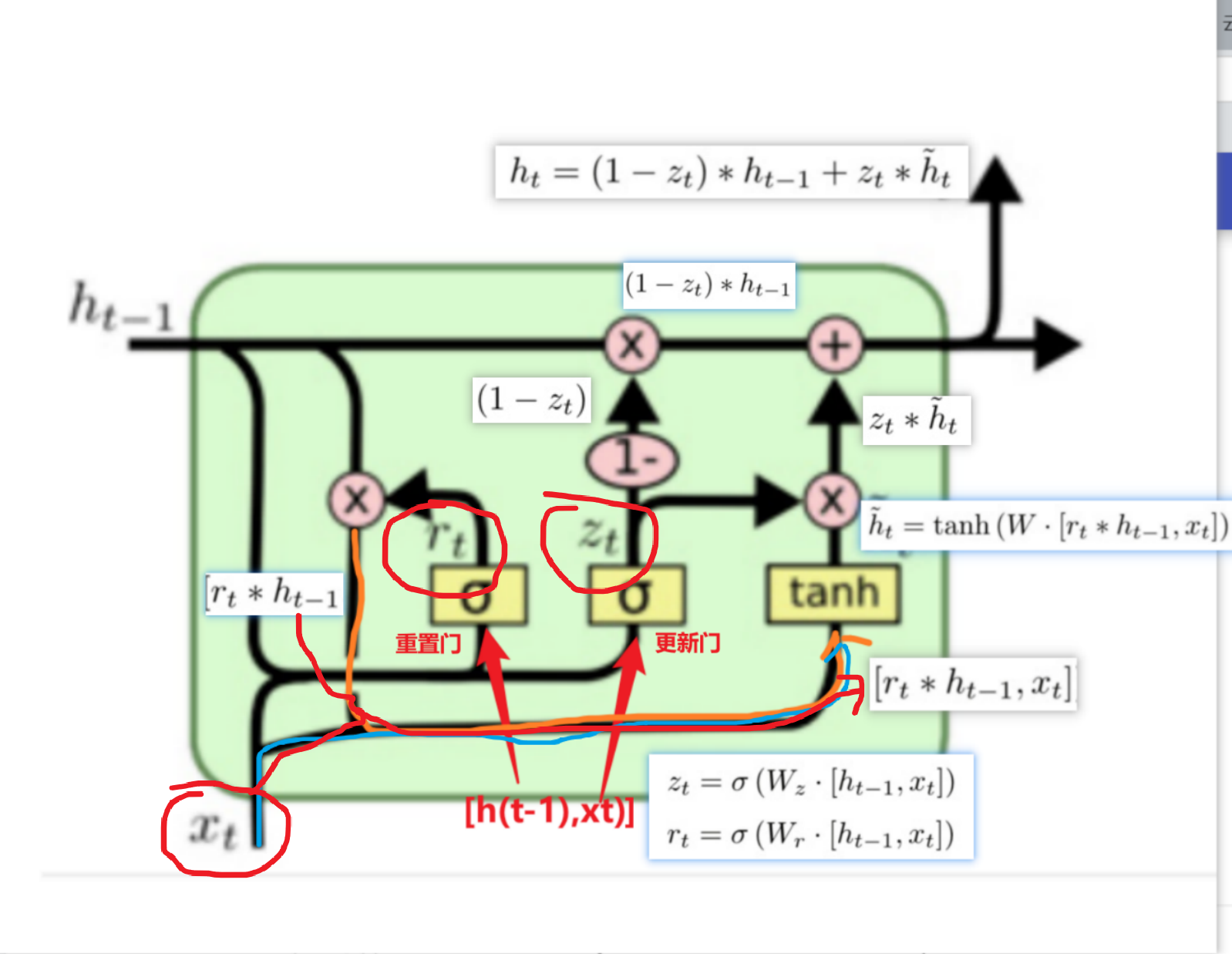
GRU和LSTM作用相同, 在捕捉长序列语义关联时, 能有效抑制梯度消失或爆炸, 效果都优于传统RNN且计算复杂度相比LSTM要小.
注意力机制
引入Attention的原因1:长距离的信息会被弱化,就好像记忆能力弱的人,记不住过去的事情是一样的。原因2 :好使
深度学习中的注意力机制通常可分为三类: 软注意(全局注意)、硬注意(局部注意)和自注意(内注意)
- 软注意机制(Soft/Global Attention: 对每个输入项的分配的权重为0-1之间,也就是某些部分关注的多一点,某些部分关注的少一点,因为对大部分信息都有考虑,但考虑程度不一样,所以相对来说计算量比较大。
- 硬注意机制(Hard/Local Attention,[了解即可]): 对每个输入项分配的权重非0即1,和软注意不同,硬注意机制只考虑那部分需要关注,哪部分不关注,也就是直接舍弃掉一些不相关项。优势在于可以减少一定的时间和计算成本,但有可能丢失掉一些本应该注意的信息。
- 自注意力机制( Self/Intra Attention): 对每个输入项分配的权重取决于输入项之间的相互作用,即通过输入项内部的"表决"来决定应该关注哪些输入项。和前两种相比,在处理很长的输入时,具有并行计算的优势。
注意力计算规则:
* 它需要三个指定的输入Q(query), K(key), V(value), 然后通过计算公式得到注意力的结果, 这个结果代表query在key和value作用下的注意力表示. 当输入的Q=K=V时, 称作自注意力计算规则.

注意力机制的作用
- 在解码器端的注意力机制: 能够根据模型目标有效的聚焦编码器的输出结果, 当其作为解码器的输入时提升效果. 改善以往编码器输出是单一定长张量, 无法存储过多信息的情况.
- 在编码器端的注意力机制: 主要解决表征问题, 相当于特征提取过程, 得到输入的注意力表示. 一般使用自注意力(self-attention).
transformer
核心架构
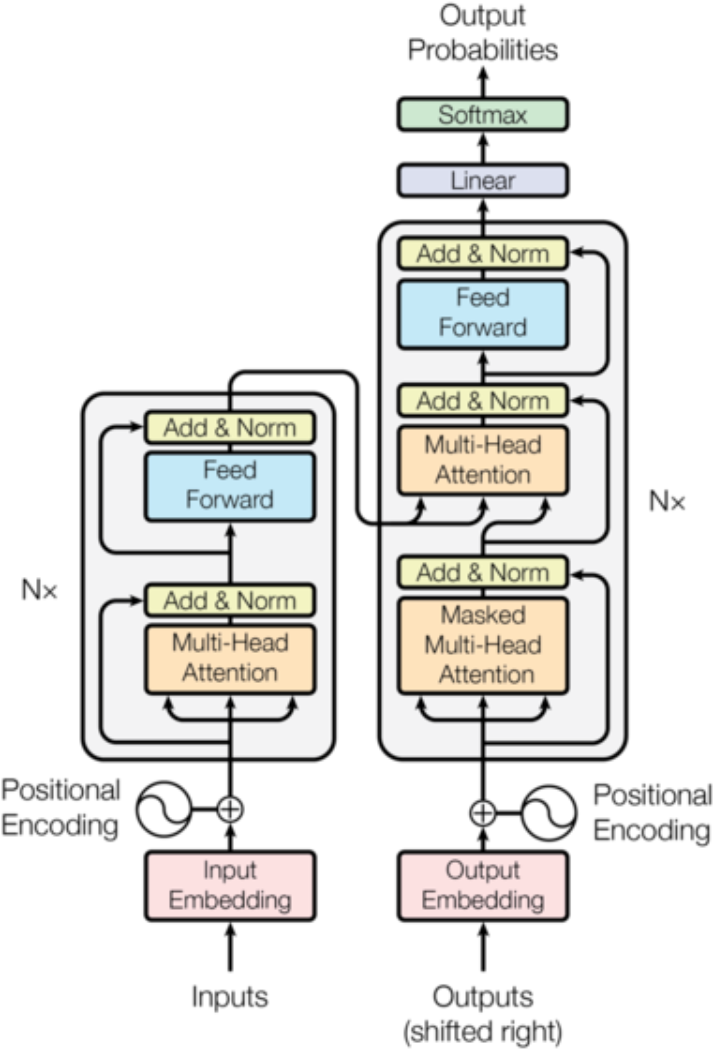
输入部分构成:input(output)embedding+position encoding
embedding作用是将文本中词汇的数量表示转换为更高维度的向量表示
position encoding的作用将词汇位置不同可能会产生不同语义的信息加入到词嵌入张量中, 以弥补位置信息的缺失.
为什么embedding之后要乘以根号下d_model
原因1:为了防止position encoding的信息覆盖我们的word embedding,所以进行一个数值增大
原因2:符合标准正态分布
位置编码器实现方式:三角函数来实现的,sin\cos函数
为什么使用三角函数来进行位置编码:
保证同一词汇随着所在位置不同它对应位置嵌入向量会发生变化
正弦波和余弦波的值域范围都是1到-1这又很好的控制了嵌入数值的大小, 有助于梯度的快速计算
三角函数能够很好的表达相对位置信息
编码器部分
1、N个编码器层堆叠而成
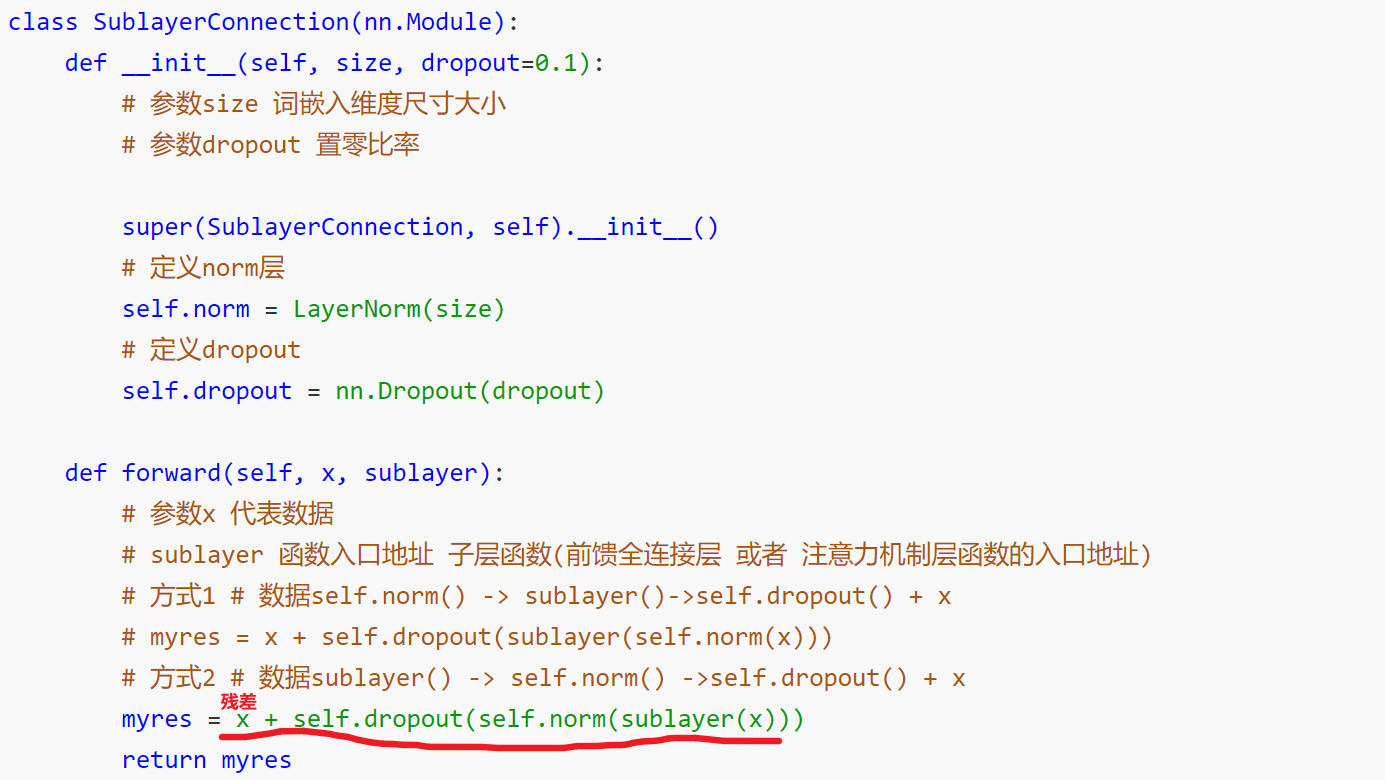
2、每个编码器有两个子层连接结构构成
3、第一个子层连接结构:多头自注意力层+规范化层+残差连接层
4、第二个子层连接结构:前馈全连接层+规范化层+残差连接层
掩码:掩就是遮掩、码就是张量。掩码本身需要一个掩码张量,掩码张量的作用是对另一个张量进行数据信息的掩盖。一般掩码张量是由0和1两种数字组成,至于是0对应位置或是1对应位置进行掩码,可以自己设定
掩码分类:
PADDING MASK: 句子补齐的PAD,去除影响 ,位置:编码器的自注意力层(Self-Attention),编码器-解码器注意力层
SETENCES MASK:防止未来信息被提前利用,位于解码器的自注意力层
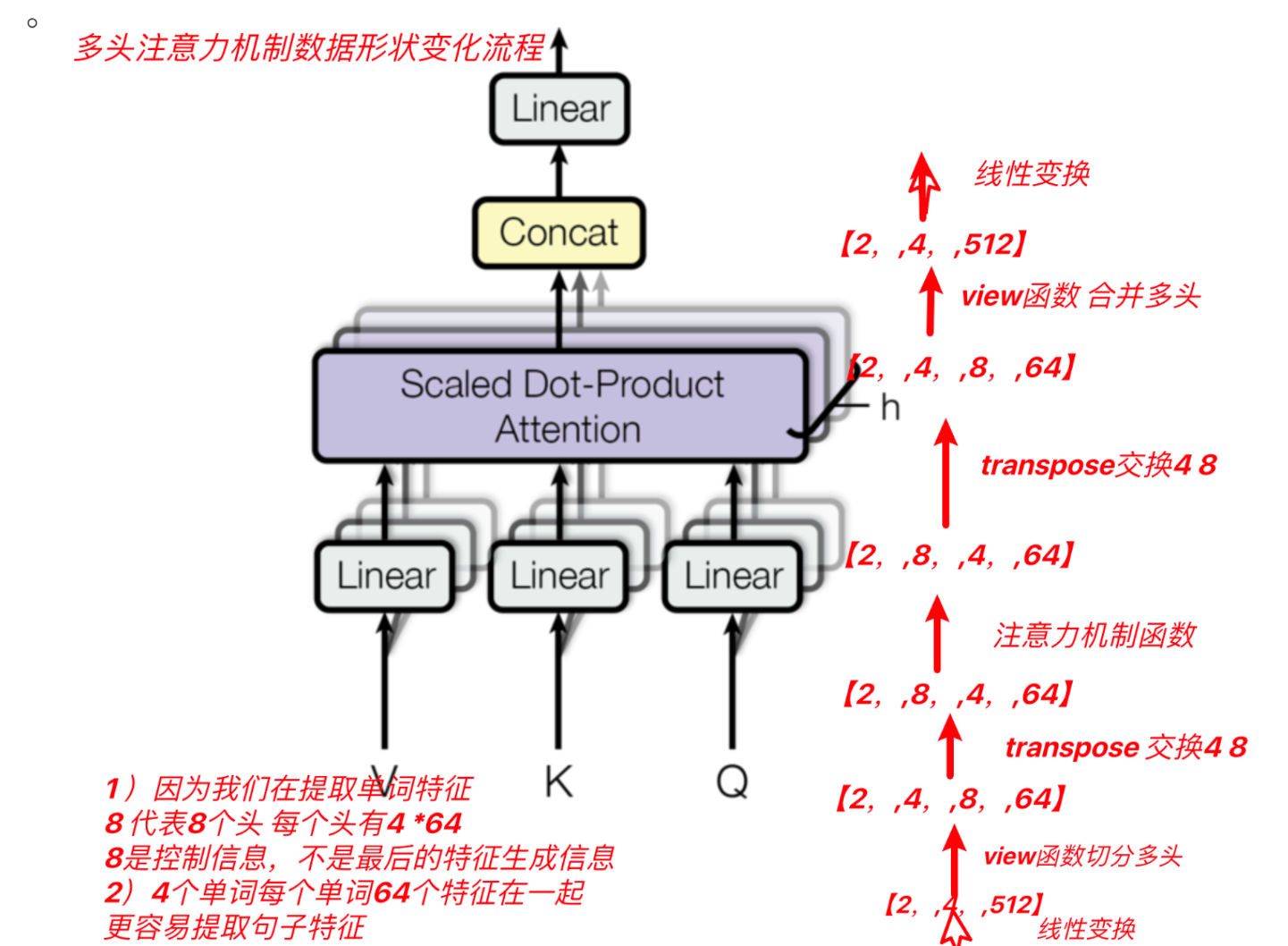
多头自注意力机制
将模型分为多个头, 可以形成多个子空间, 让模型去关注不同方面的信息, 最后再将各个方面的信息综合起来得到更好的效果.
在模拟transformer中qkv分别经过一个线性层
前馈全连接层:作用:增强模型的拟合能力(两个线性层)
规范化层:作用:随着网络深度的增加,模型参数会出现过大或过小的情况,进而可能影响模型的收敛,因此进行规范化,将参数规范致某个特征范围内,辅助模型快速收敛。
残差链接:作用:引入加法防止梯度消失
解码器部分
1、N个解码器堆叠而成
2、每个解码器有三个子层连接结构构成
3、第一个子层连接结构:多头自注意力层+规范化层+残差连接层
SETENCES MASK:解码器端,防止未来信息被提前利用
4、第二个子层连接结构:多头注意力层+规范化层+残差连接层
这里的Q查询张量是上一个子层输入,K和V是编码器的输出
5、第三个子层连接结构:前馈全连接层+规范化层+残差连接层
输出部分:作用:通过线性变化得到指定维度的输出
迁移学习
预训练模型:
定义: 简单来说别人训练好的模型。一般预训练模型具备复杂的网络模型结构;一般是在大量的语料下训练完成的
预训练模型的分类:
自回归语言模型Auto Regressive Language Model AR)(做文本语言生成)
概念:根据上文内容预测下一个可能的单词
优点:从左向右的处理文本,天然文本生成
缺点:只能利用上文或者下文的信息,不能同时利用上文和下文的信息
代表模型:GPT、GPT2、Transformer-XL、XLNET
自编码语言模型(Auto Encoder Language Model AE)(适合做语言理解)
概念:对输入的句子随机Mask其中的单词,根据上下文单词来预测这些被Mask掉的单词
优点:融入双向语言模型,同时看到被预测单词的上文和下文
缺点:训练时使用[Mask]标记,导致预训练阶段和Fine-tuning阶段不一致的问题
代表模型:BERT、ALBERT、RoBERTa、ELECTRA
迁移学习的两种方式
开箱即用: 当预训练模型的任务和我们要做的任务相似时,可以直接使用预训练模型来解决对应的任务
微调: 进行垂直领域数据的微调,一般在预训练网络模型后,加入自定义网络,自定义网络模型的参数需要训练,但是预训练模型的参数可以全部微调或者部分微调或者不微调。
fasttext
作为NLP工程领域常用的工具包, fasttext有两大作用:
- 进行文本分类
- 训练词向量
Fasttext模型架构
- FastText 模型架构和 Word2Vec 中的 CBOW 模型很类似, 不同之处在于, FastText 预测标签, 而 CBOW 模型预测中间词.
- FastText的模型分为三层架构:
- 输入层: 是对文档embedding之后的向量, 包含N-gram特征
- 隐藏层: 是对输入数据的求和平均
- 输出层: 是文档对应的label
fasttext的数据要求:
__label__fish arctic char available in north-america
模型调优的手段:
原始数据处理:
数据处理后进行训练并测试:
增加训练轮数:
调整学习率:
增加n-gram特征:
修改损失计算方式:
自动超参数调优:
模型的保存与加载
# 使用model的save_model方法保存模型到指定目录
# 你可以在指定目录下找到model_cooking.bin文件 >>>
model.save_model("data/model/model_cooking.bin")
# 使用fasttext的load_model进行模型的重加载 >>>
model = fasttext.load_model("data/model/model_cooking.bin")
常见的预训练模型
Bert

GPT

)








)




![Nacos中feign.FeignException$BadGateway: [502 Bad Gateway]](http://pic.xiahunao.cn/Nacos中feign.FeignException$BadGateway: [502 Bad Gateway])



 ---驱动与内核交互)
)