数据湖架构概述:从传统模型到 2025 年新范式
数据湖作为存储海量异构数据的中央仓库,其架构设计直接影响企业数据价值的释放效率。传统数据湖架构主要关注数据的存储和管理,而 2025 年的数据湖架构已经演变为更加智能化、自动化的综合性数据平台。
数据湖本质上是一个存储库,允许企业以原生格式存储各类数据,包括结构化、半结构化和非结构化数据。与传统数据仓库相比,数据湖采用“读时模式”(schema-on-read)而非“写时模式”(schema-on-write),这意味着数据可以先存储,后根据需求定义结构,极大提高了数据处理的灵活性。
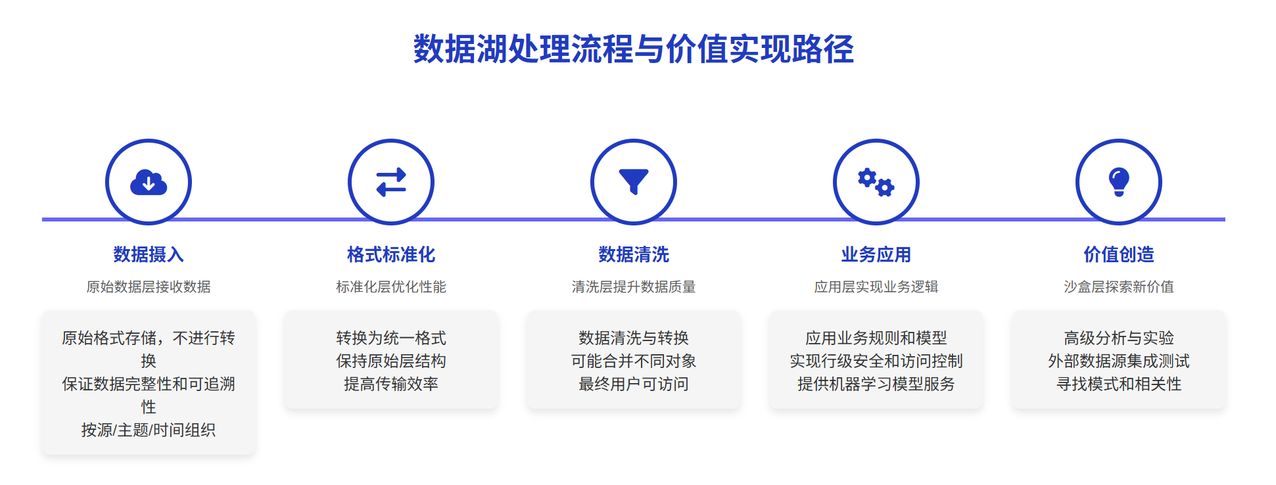
2025 年的数据湖典型架构已经从单纯的存储层次化为多功能平台,主要包括以下核心组件:
- 数据摄入层:负责从各种来源高效地收集数据
- 存储层:以开放格式存储原始数据
- 处理层:执行数据转换和分析
- 查询层:提供高性能数据访问接口
- 治理层:确保数据质量、安全和合规
- 服务层:为各类应用提供数据服务
随着 AI 和实时分析需求的增长,现代数据湖架构正在向“湖仓一体”(Lakehouse)模式演进,这种架构结合了数据湖的灵活性和数据仓库的结构化查询能力,成为 2025 年企业数据架构的主流选择。
数据湖分层架构:从原始数据到业务价值

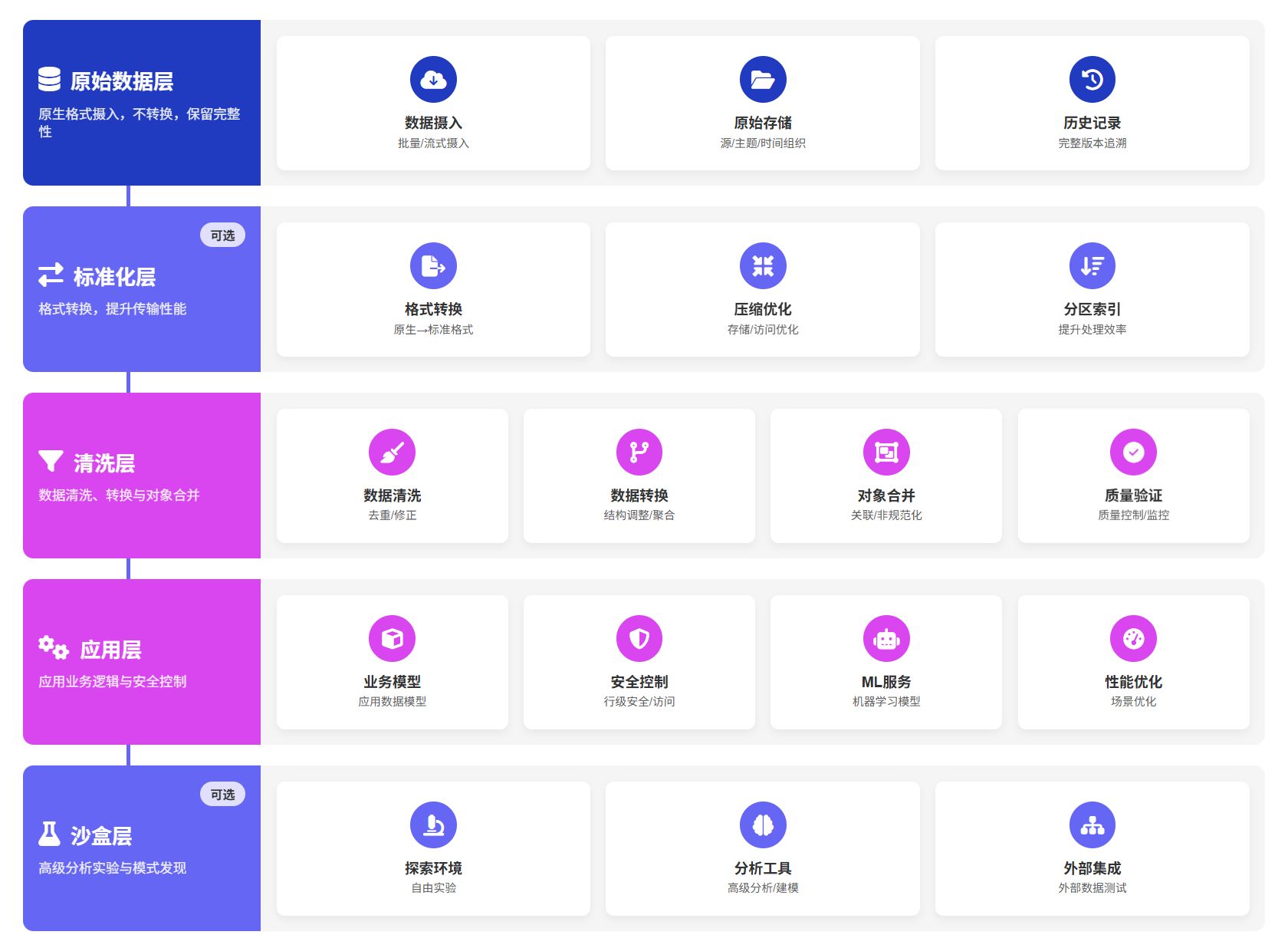
高效的数据湖架构通常采用分层设计,每一层都有明确的职责和处理逻辑。根据行业最佳实践,2025 年的数据湖典型分层架构包括以下几个关键层次:
原始数据层(Raw Layer)
也称为摄入层或登陆区,是数据湖的入口。在这一层,数据以原生格式快速高效地被摄入,不进行任何转换。这确保了数据的完整性和可追溯性,允许企业在需要时回溯到特定时间点。原始层通常按照主题区域/数据源/对象/年/月/日的目录结构组织,以便于管理和查询。重要的是,最终用户通常不应直接访问此层,因为数据尚未准备好被使用。
标准化层(Standardized Layer)
这是一个可选层,主要用于改善从原始层到清洗层的数据传输性能。当预计数据湖将快速增长时,此层尤为重要。在标准化层中,数据从原生格式转换为更适合清洗的格式,但结构与原始层相同。
清洗层(Cleansed Layer)
也称为规范层,这一层包含已转换为可消费数据集的数据。数据经过清洗、转换,并可能进行非规范化和不同对象的合并。这是数据湖中最复杂的部分,因为数据的目的和结构在此阶段已经确定。组织结构相对简单,通常按目的/类型/文件划分。最终用户通常只能访问此层及以上层次。
应用层(Application Layer)
也称为可信层或生产层,从清洗层获取数据并应用特定于应用程序的业务逻辑。这可能包括应用程序共享的代理键、行级安全性或其他特定于应用程序的逻辑。如果应用程序使用在数据湖上计算的机器学习模型,这些模型也会在此层提供。
沙盒层(Sandbox Layer)
另一个可选层,专为高级分析师和数据科学家设计。在这里,他们可以进行实验,寻找模式或相关性,也可以用于测试外部数据源的集成。
随着数据在这些层之间流动,每一步都代表了逻辑数据处理的下一阶段。2025 年的趋势是这些层次之间的界限变得更加模糊,更多地采用自动化工具来管理数据流,同时保持数据的可追溯性和质量。
数据湖架构的关键组件
除了分层结构外,一个完整的数据湖架构还包含多个关键组件,这些组件共同确保数据湖的高效运行和价值最大化:
1. 安全机制
虽然数据湖通常不会向广泛的受众公开,但安全性仍然至关重要,尤其是在初始阶段和架构设计时。与关系型数据库不同,数据湖没有一整套现成的安全机制,因此需要特别注意这一方面,避免低估其重要性。
2. 治理框架
监控和日志记录(或血缘)操作对于衡量性能和调整数据湖至关重要。随着数据规模的增长,有效的治理框架变得越来越重要,2025 年的数据湖治理更加注重自动化和智能化。
3. 元数据管理
元数据是关于数据的数据,包括所有架构、重新加载间隔、数据用途的附加描述以及如何使用数据的说明。在 2025 年,元数据管理已经从简单的数据字典演变为支持数据发现、血缘追踪和影响分析的智能系统。
4. 数据管理
根据规模的不同,可能需要单独的团队(角色)或将此责任委托给所有者(用户),可能通过一些元数据解决方案来实现。随着数据湖规模的扩大,有效的数据管理变得越来越重要。
5. 主数据管理
提供可用数据的基本部分。需要找到一种方法在数据湖上存储主数据,或者在执行 ELT 过程时引用它。
6. 归档机制
如果有额外的关系型数据仓库解决方案,可能会面临一些与性能和存储相关的问题。数据湖通常用于保存一些最初来自数据仓库的归档数据。
7. 卸载处理
同样,如果有其他关系型数据仓库解决方案,可能希望使用数据湖来卸载一些耗时/资源的 ETL 过程,这可能更便宜、更快。
8. 编排和 ELT 处理
随着数据从原始层推送到清洗层,再到沙盒层和应用层,需要一个工具来编排流程。很可能需要应用转换,要么选择能够执行此操作的编排工具,要么需要一些额外的资源来执行它们。
在 2025 年的数据湖架构中,这些组件已经高度集成,形成了一个协同工作的生态系统,而不是孤立的功能模块。特别是,AI 技术的应用使这些组件能够更智能地协作,自动化程度更高,从而减少了人工干预的需求。

数据湖 vs 数据仓库:2025 年的融合趋势
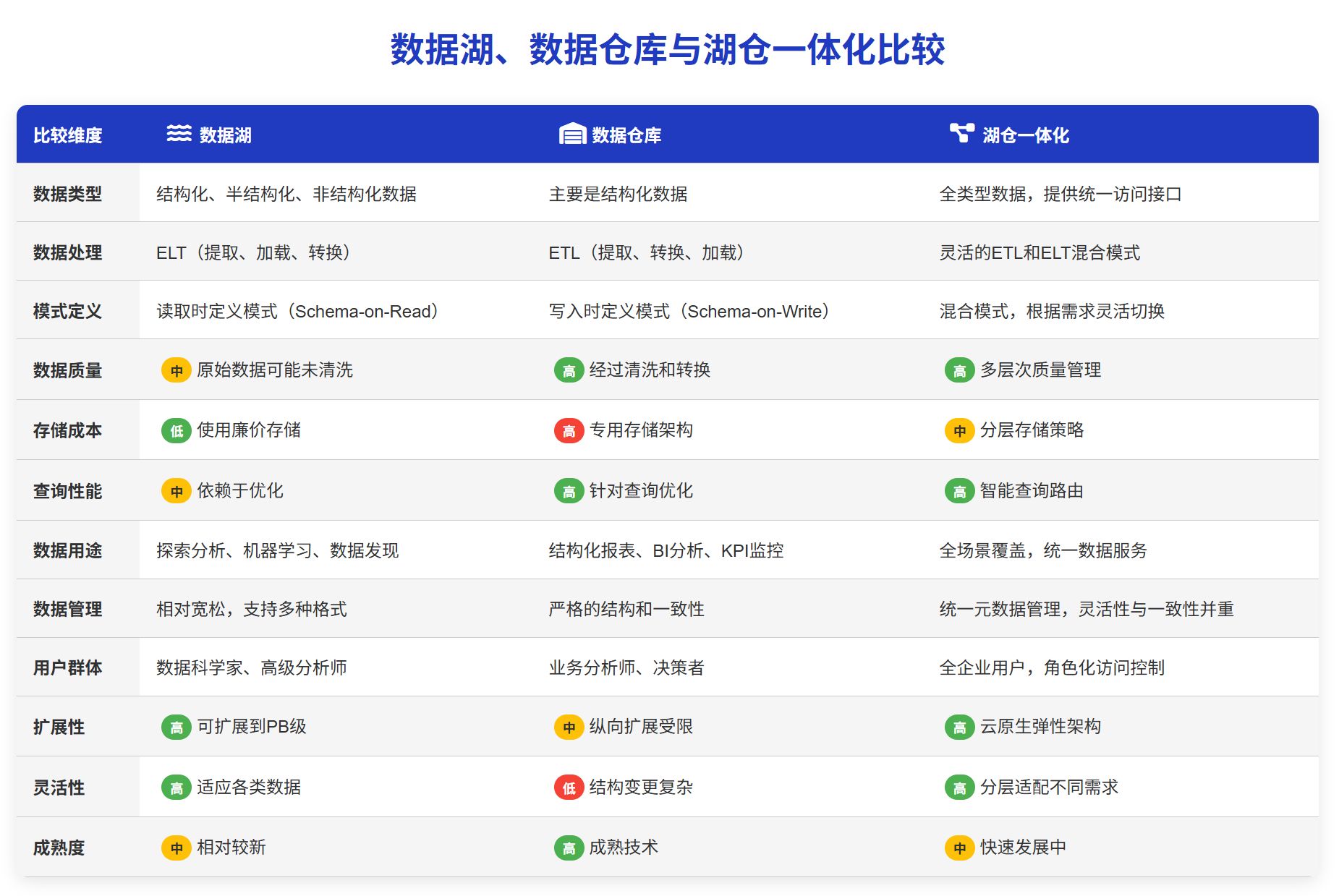
随着数据技术的不断发展,数据湖和数据仓库之间的界限正在变得越来越模糊。2025 年,我们看到这两种架构正在向湖仓一体化(Lakehouse)方向融合,但了解它们的核心差异仍然很重要。
数据类型与处理模式
数据湖能够存储非结构化、半结构化和结构化数据,而数据仓库主要处理结构化数据。在处理模式上,数据湖采用 ELT(提取、加载、转换)模式,而数据仓库则使用 ETL(提取、转换、加载)模式。这种差异反映了它们的设计理念:数据湖优先考虑数据的收集和存储,而数据仓库则优先考虑数据的结构和查询效率。
理想使用场景
数据湖最适合存储未来处理的原始数据,特别是当数据的最终用途尚不明确时。相比之下,数据仓库专为执行结构化查询而设计,适合已知的分析需求。
架构与数据管理
在架构上,数据湖采用“读时模式”(schema-on-read),允许数据先存储后定义结构;而数据仓库使用“写时模式”(schema-on-write),要求在数据加载前定义结构。这使得数据湖更加灵活,但也增加了数据管理的复杂性。
数据质量与治理
数据湖存储原始数据,需要额外的治理措施来确保数据质量;而数据仓库存储高度策划的数据,通常具有内置的数据质量控制机制。
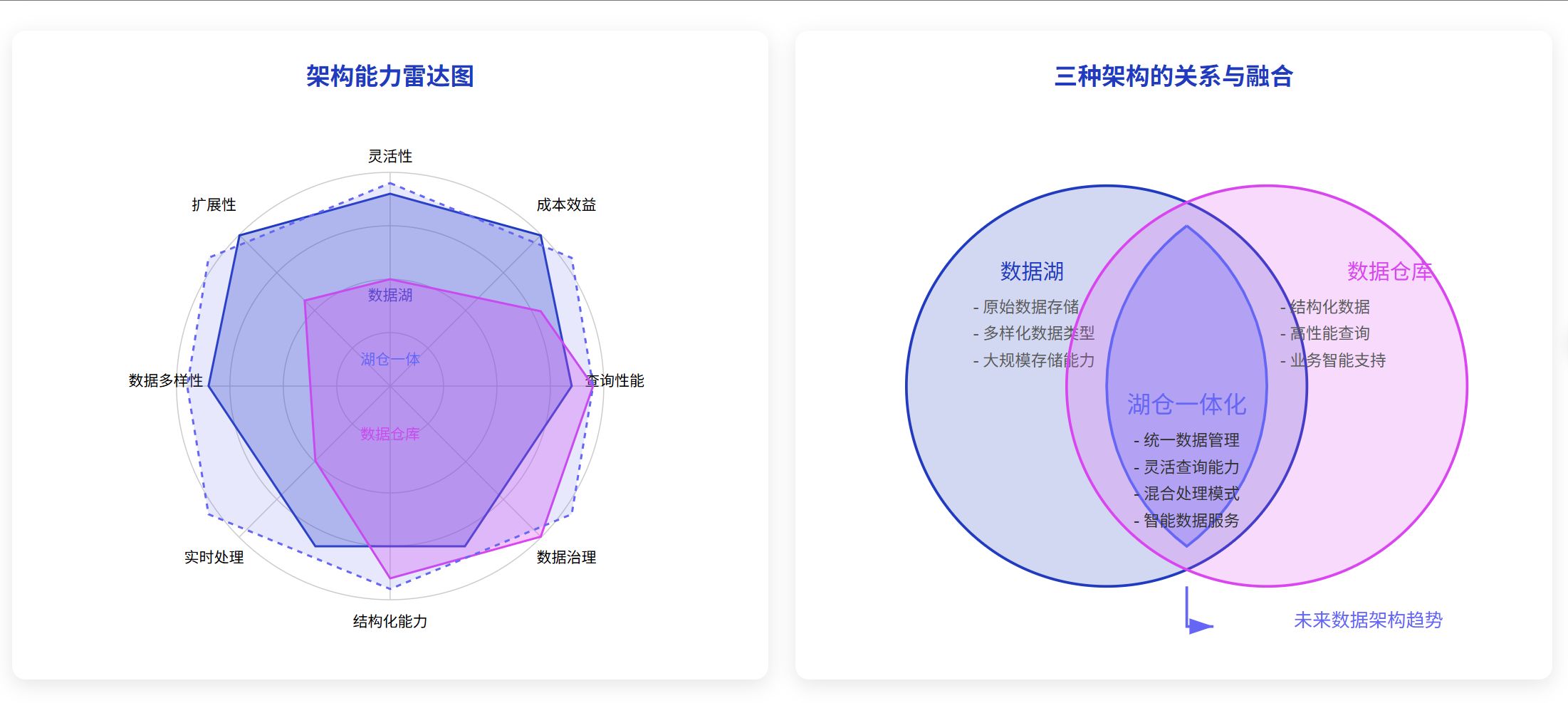
2025 年的融合趋势:湖仓一体化
2025 年,我们看到数据湖和数据仓库正在向湖仓一体化(Lakehouse)架构融合。这种新型架构结合了数据湖的灵活性和可扩展性,以及数据仓库的结构化和性能优势。主要特点包括:
- 统一存储与计算:在同一平台上处理结构化和非结构化数据
- 开放格式支持:采用开放表格式如 Apache Iceberg、Apache Hudi 和 Delta Lake
- ACID 事务支持:确保数据一致性和可靠性
- 高性能 SQL 查询:提供数据仓库级别的查询性能
- 端到端数据管理:从摄入到治理的全流程管理
- AI/ML 集成:原生支持机器学习和人工智能工作负载
这种融合不仅简化了数据架构,还提高了数据利用效率,降低了总体拥有成本。企业不再需要维护分离的数据湖和数据仓库系统,而是可以在一个统一的平台上满足各种数据需求。
数据湖架构最佳实践:避免数据沼泽的关键策略
构建高效的数据湖架构需要遵循一系列最佳实践,以避免数据湖变成难以管理的“数据沼泽”(Data Swamp)。以下是 2025 年数据湖实施的关键策略:
数据编目(Data Cataloging)
没有适当的组织,数据湖很容易变成数据沼泽。如果用户对数据湖的内容感到困惑,它就失去了其目的。数据目录通常包括有关数据健康状况和位置的详细信息,以及使用该数据的应用程序。通过提供数据湖架构中存在的数据的准确信息,数据编目使组织能够高效地处理数据。
在 2025 年,数据编目已经从简单的元数据管理演变为智能化的数据发现和血缘追踪系统,能够自动识别数据关系和使用模式,大大减轻了数据管理的负担。
数据治理与访问控制
简单地将数据推入数据湖是不够的,因为无监管的数据很快会变成数据泛滥。明确的数据治理策略将允许用户从存储的数据中提取有用的事实,并为组织的利益做出明智的、数据驱动的决策。
2025 年的数据治理已经从静态策略转变为动态、自适应的治理框架,能够根据数据使用模式和业务需求自动调整访问控制和数据处理规则。
数据组织策略
数据湖的组织可能受到多种因素的影响:
- 时间分区:按时间维度组织数据,便于历史分析和数据生命周期管理
- 数据加载模式:根据实时、流式、增量、全量加载等不同模式组织数据
- 主题区域/来源:按业务领域或数据来源组织,提高数据发现效率
- 安全边界:基于访问权限需求划分数据区域
- 下游应用/目的/用途:根据数据的最终使用目的组织
- 所有者/管理:按数据责任人组织,明确责任划分
- 保留策略:根据数据保留需求(临时、永久、固定时间)组织
- 业务影响:按数据对业务的重要性(关键、高、中、低)组织
- 机密分类:根据数据敏感度(公共信息、仅内部使用、供应商/合作伙伴机密、个人身份信息、敏感财务信息)组织
2025 年的趋势是采用多维度的数据组织策略,结合自动化工具和 AI 技术,根据数据特性和使用模式自动确定最优的组织方式。
技术选型与集成
选择适合企业需求的数据湖技术栈至关重要。2025 年,云原生数据湖解决方案因其高弹性和低存储成本成为主流选择。主要的数据湖解决方案包括:
- AWS 数据湖:基于 S3 的全托管数据湖解决方案,提供全面的数据处理和分析服务
- Azure 数据湖:与 Microsoft 生态系统深度集成的数据湖服务
- Google Cloud 数据湖:提供强大的 AI 和机器学习能力的数据湖平台
- Snowflake:市场上最具竞争力的数据湖解决方案之一,允许客户在 S3、Azure 或 Google Cloud 上拥有数据湖,并在 Snowflake 内部集成它们
2025 年的技术选型更加注重生态系统的开放性和互操作性,以及与 AI 和实时分析工具的集成能力。
避免常见陷阱
实施数据湖时需要避免以下常见陷阱:
- 缺乏明确目标:没有明确的业务目标和用例
- 忽视数据质量:未建立数据质量控制机制
- 治理不足:缺乏有效的数据治理框架
- 技能缺口:团队缺乏必要的技术和业务技能
- 用户采用率低:数据科学家可能是唯一能够舒适处理非结构化数据的人。由于涉及的复杂性,大量用户远离数据湖,这与建立数据湖的初衷相悖。
2025 年,成功的数据湖实施更加注重用户体验和自助服务能力,通过直观的界面和 AI 辅助工具降低使用门槛,提高用户采用率。
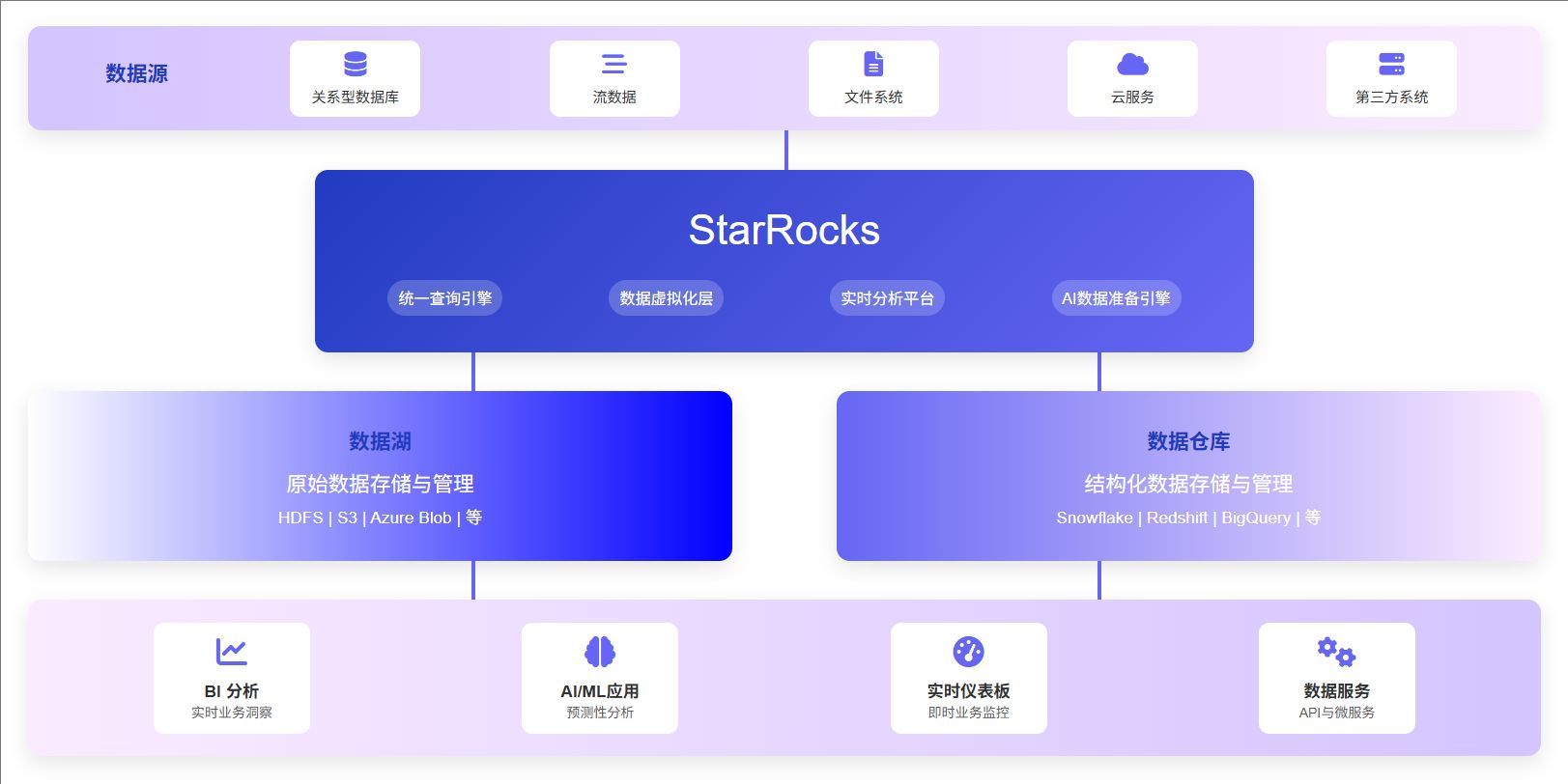
StarRocks 湖仓一体解决方案:重塑数据湖架构
在 2025 年的数据分析领域,StarRocks 凭借其创新的湖仓一体解决方案,正在重新定义数据湖架构。镜舟数据库(StarRocks 的企业版)通过将数据湖的灵活性与数据仓库的性能相结合,为企业提供了一种全新的数据管理和分析范式。
StarRocks 湖仓一体架构的核心优势
1. 统一的数据访问层
StarRocks 提供了一个统一的 SQL 接口,可以无缝查询多种数据源,包括数据湖中的 Apache Iceberg、Apache Hudi、Apache Paimon 等开放表格式,以及传统数据仓库和外部系统。这种统一访问能力消除了数据孤岛,使企业能够在不移动数据的情况下获得全面的数据洞察。
2. 极速查询性能
基于 Apache Arrow 的列式存储和向量化执行引擎,StarRocks 能够提供比传统数据湖查询引擎(如 Trino)高出 10 倍的查询性能。这种性能优势使得实时分析和交互式查询成为可能,极大地提升了数据分析的效率。
3. 智能缓存与查询加速
StarRocks 实现了多层次的缓存策略,包括查询结果缓存、数据块缓存和元数据缓存,能够智能地识别热点数据并优化缓存策略,显著提升查询性能。此外,StarRocks 的异步物化视图功能可以预计算常用查询结果,进一步加速数据湖查询。
4. 开放表格式支持
StarRocks 原生支持主流开放表格式,包括:
- Apache Iceberg:提供 ACID 事务、时间旅行和架构演化等企业级功能
- Apache Hudi:支持增量处理和行级更新
- Apache Paimon:专为流式数据设计的表格式
- Delta Lake:提供可靠的数据湖操作
这种开放性使企业能够避免供应商锁定,灵活选择最适合其需求的技术组合。
5. 端到端数据管理
StarRocks 提供了完整的数据生命周期管理能力,从数据摄入、转换、存储到查询和分析,实现了端到端的数据管理。特别是在数据治理方面,StarRocks 的统一元数据管理(基于 Apache Polaris)提供了全面的数据血缘和影响分析能力,确保数据的可追溯性和合规性。
StarRocks 在现代数据湖架构中的角色
在 2025 年的数据湖架构中,StarRocks 扮演着核心引擎的角色,负责连接和优化各个组件之间的数据流动。具体而言,StarRocks 在数据湖架构中的定位包括:
- 统一查询引擎:为各类应用提供高性能 SQL 查询能力
- 数据虚拟化层:实现跨源数据的统一访问和管理
- 实时分析平台:支持流式数据的实时摄入和分析
- AI 数据准备引擎:为机器学习和 AI 应用提供高质量的训练数据
通过这些角色,StarRocks 不仅简化了数据湖架构,还提高了数据利用效率,降低了总体拥有成本,使企业能够更快地从数据中获取价值。
StarRocks 与传统数据湖解决方案的对比
为了更全面地理解 StarRocks 在数据湖领域的优势,我们将其与传统数据湖解决方案进行对比:
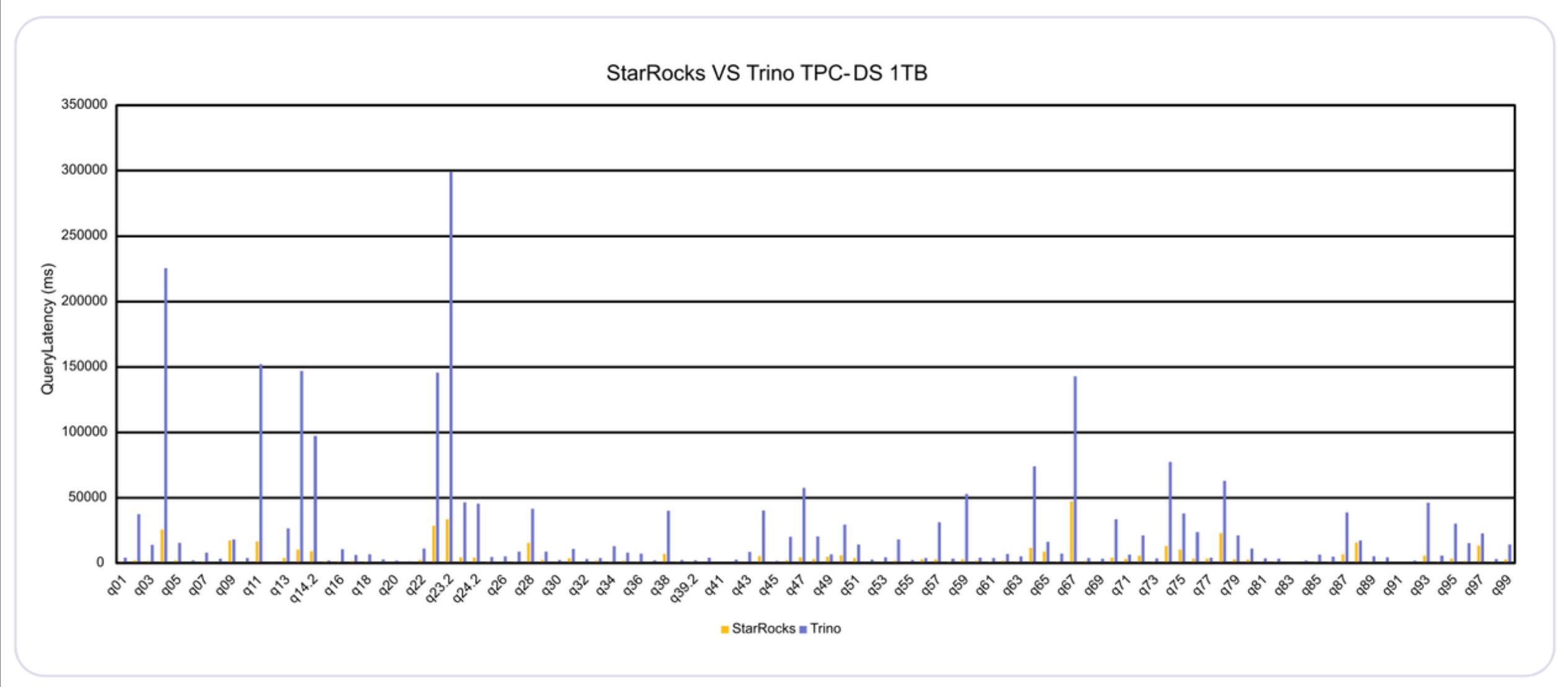
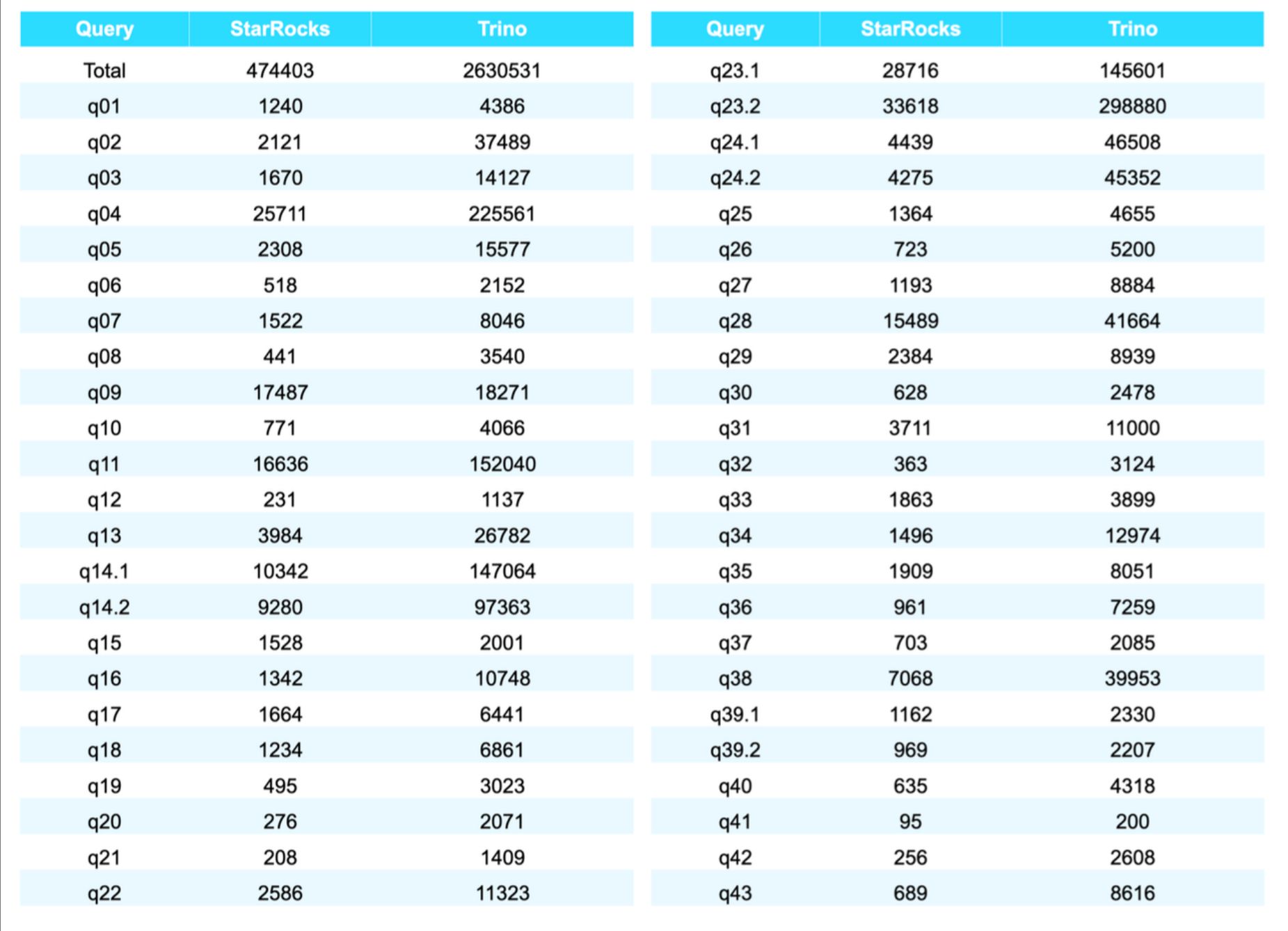
1. 查询性能对比
在 TPC-H 和 SSB 等标准基准测试中,StarRocks 的查询性能显著优于传统数据湖查询引擎:
- 相比 Trino,StarRocks 在复杂分析查询上性能提升 3-10 倍
- 相比直接查询 Iceberg 表,StarRocks 通过智能缓存和查询优化提供 5-20 倍的性能提升
- 在高并发场景下,StarRocks 能够保持稳定的性能,而传统解决方案往往出现性能下降
2. 资源效率对比
StarRocks 的高效执行引擎和智能资源管理使其在资源利用率方面具有显著优势:
- 相同查询负载下,StarRocks 通常只需要传统解决方案 1/3 到 1/5 的计算资源
- 存算分离架构使 StarRocks 能够根据负载动态调整资源,进一步提高资源利用率
- 智能缓存机制减少了对存储层的访问,降低了存储成本和网络开销
3. 易用性对比
StarRocks 提供了更简单、更统一的用户体验:
- 统一的 SQL 接口,无需学习多种查询语言或 API
- 自动优化的查询计划,减少了手动调优的需求
- 丰富的连接器和集成,简化了与现有系统的集成
- 直观的管理界面和监控工具,降低了运维复杂性
4. 生态系统集成对比
StarRocks 在生态系统集成方面也具有优势:
- 与主流 BI 工具(如 Tableau、Power BI、Superset 等)的原生集成
- 与 Apache Flink、Apache Spark 等数据处理框架的无缝对接
- 支持多种数据源和格式,包括关系型数据库、NoSQL 数据库、消息队列等
- 与云原生技术(如 Kubernetes、Docker 等)的深度集成
通过这些比较,我们可以看到 StarRocks 在性能、效率、易用性和生态系统集成方面都具有显著优势,使其成为 2025 年数据湖架构的理想选择。
企业级数据湖架构实践:StarRocks 成功案例分析
在 2025 年的数据分析领域,越来越多的企业选择 StarRocks 作为其数据湖架构的核心组件。以下是几个典型的企业级实践案例,展示了 StarRocks 如何帮助企业构建高效、可扩展的数据湖解决方案。
案例一:小红书湖仓架构的跃迁之路
挑战:
小红书作为中国领先的生活方式分享平台,面临着海量用户生成内容和行为数据的分析挑战。传统的数据仓库架构难以满足其对实时分析和灵活查询的需求,同时成本也随着数据量的增长而急剧上升。
解决方案:
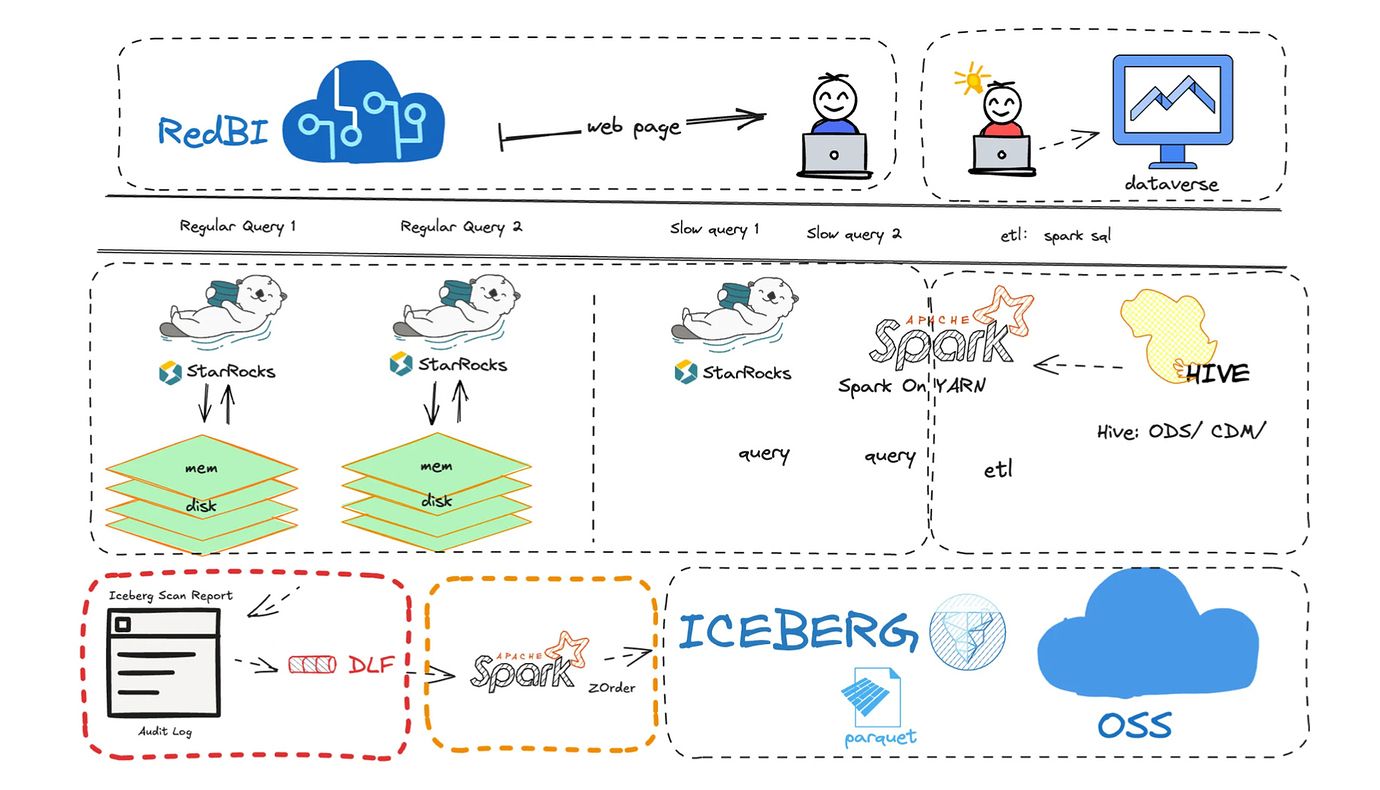
小红书采用 StarRocks 构建了湖仓一体化架构,主要包括以下几个方面:
- 利用 Apache Iceberg 作为数据湖存储格式,保存原始数据
- 部署 StarRocks 作为统一查询引擎,直接分析 Iceberg 数据
- 针对热点查询场景,使用 StarRocks 的异步物化视图进行加速
- 实现数据湖和数据仓库的无缝集成,统一元数据管理
成果:
- 查询性能提升 100 倍,实现了秒级响应的交互式分析
- 存储成本降低 40%,通过减少数据复制和优化存储格式
- 数据时效性从 T+1 提升到分钟级,满足了实时分析需求
- 自助分析能力显著增强,分析师可以直接访问和分析原始数据
案例二:腾讯游戏基于 StarRocks 的湖仓一体实践
挑战:
腾讯游戏需要处理来自全球数亿用户的游戏行为数据,用于游戏优化、用户体验改进和营销决策。传统的分析架构面临数据孤岛、查询性能瓶颈和高昂的维护成本等问题。
解决方案:
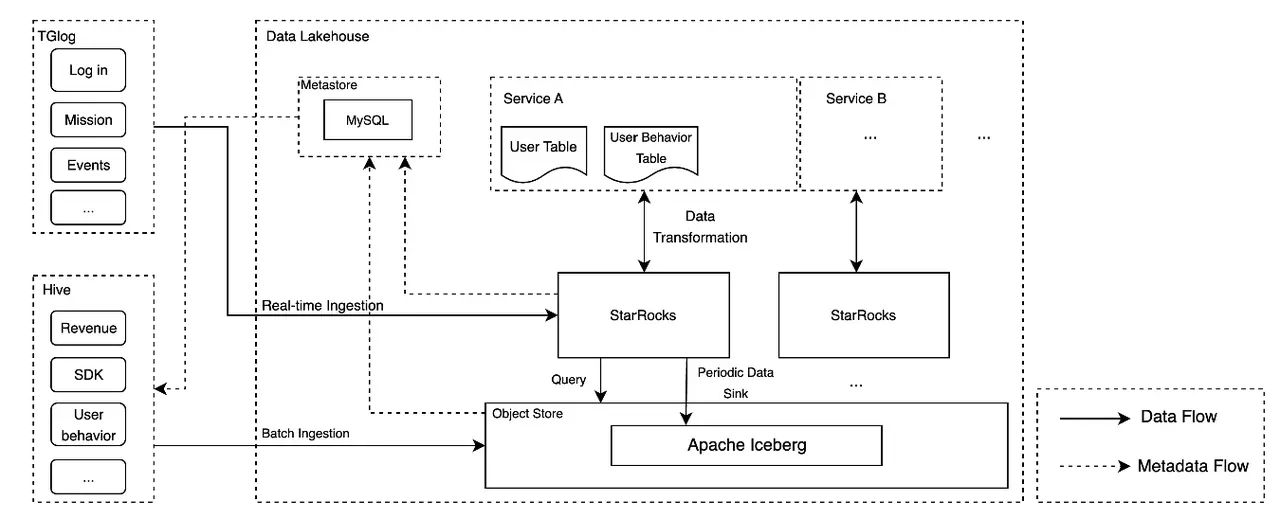
腾讯游戏构建了基于 StarRocks 的湖仓一体平台,称为“天穹”:
- 采用多级存储架构,结合对象存储和本地存储
- 使用 StarRocks 作为统一的 SQL 查询引擎
- 实现 AI 驱动的自动化数据治理和优化
- 构建统一的元数据管理和数据血缘追踪系统
成果:
- 查询性能提升 10 倍,支持复杂的多维分析
- 运维成本降低 50%,通过自动化管理和优化
- 数据分析民主化,使业务用户能够自助进行数据探索
- 支持 AI 和机器学习应用,如游戏平衡性分析和用户行为预测
案例三:TRM Labs 构建 PB 级数据分析平台
挑战:
TRM Labs 是一家区块链情报公司,需要分析和监控多个区块链网络的交易数据,数据量达到 PB 级别。传统数据库无法满足其对大规模数据处理和实时分析的需求。
解决方案:

TRM Labs 基于 StarRocks 和 Apache Iceberg 构建了 PB 级数据分析平台:
- 使用 Apache Iceberg 存储原始区块链数据
- 部署 StarRocks 作为分析引擎,提供高性能 SQL 查询
- 实现实时数据摄入和分析流程
- 构建多层次缓存策略,优化查询性能
成果:
- 查询性能提升 20 倍,实现了交互式分析体验
- 存储成本降低 60%,通过数据分层和压缩优化
- 支持实时风险监控和异常检测
- 系统可扩展性显著提升,能够轻松应对数据量增长
结语:数据湖架构的未来与 StarRocks 的战略价值
随着数据量的爆炸性增长和分析需求的日益复杂化,数据湖架构已经成为企业数据战略的核心组成部分。通过本文的探讨,我们可以得出以下关键结论:
数据湖架构的演进与价值
数据湖架构正在经历从简单存储库向智能数据平台的转变。2025 年的数据湖不再仅仅是存储各类数据的场所,而是融合了存储、处理、分析和服务的综合性平台。这种演进为企业带来了多方面的价值:
- 数据民主化:使各级用户都能便捷地访问和分析数据
- 分析灵活性:支持从探索性分析到生产级应用的各类场景
- 成本优化:通过分层存储和计算资源动态分配降低总体拥有成本
- 创新加速:为 AI 和机器学习应用提供高质量的训练数据
- 业务敏捷性:使企业能够更快地响应市场变化和机会
然而,成功实施数据湖架构仍面临诸多挑战,包括数据质量管理、性能优化、安全治理等。这些挑战需要通过先进的技术和最佳实践来解决。







栈式窗体 QStackedWidget:本类里代码很少。举例,以及源代码带注释。)










)
