关于企业数字化建设的几点思考

工业软件领军人才的培训课中,如上的一个PPT,给人以许多反思。
- 一是看企业成功的数字化案例时,也许只看到别人面上的东西,可能还有面下很多看不到的东西支撑着,因此可能只看到或学到别人的皮毛;
- 二是一个企业其实有很多东西不愿意别人参与或了解;
- 三是企业数字化除了借助外力,很多东西要靠自己才能解决,这是一个不断迭代、持续推进的过程;
- 四是工业技术软件化,除了显性知识软件化以外,还有很多很多隐性知识需要不断转化,逐步实现软件化,
一、数字化成功案例的"冰山现象"
企业在学习成功数字化案例时往往只看到浮出水面的很少一部分:
- 可见部分:如ERP系统界面、MES看板、智能仓储机器人等
- 隐藏支撑:包括组织架构调整(如设立CDO职位)、流程再造(平均需要优化200+业务流程)、数据治理体系(可能历时3-5年建设)、员工数字化能力培养等
以某汽车制造企业为例,其智能工厂展示的AGV物流系统背后,实际需要:
- 18个月的生产工艺数字化建模
- 供应链数据中台建设
- 2000+小时的操作人员培训
在一个宣称2个月开发完成的AGV物流系统的背后,其实也也有类似的情况:
- 软件的开发耗时只用了不到2个月时间;
- 但是流程的梳理和优化- 什么订单、什么时刻触发、触发后如何拆分、拆分订单如何配送、配送异常如何处理等过程,需要多部门的专家耗时超过4个月梳理并优化,
- 系统上线的培训和流程优化耗时也超过2个月
二、企业核心know-how的保护边界
企业数字化转型中涉及三类敏感领域:
- 工艺秘点:如特殊材料配方参数
- 运营数据:真实产能、良品率等经营指标
- 客户资源:供应商/经销商网络关系
这些关键信息通常采用"黑箱化"处理,即使引入外部顾问也会通过NDANon-Disclosure Agreement(保密协议)划定知识边界。
比如某些公司,对于敏感数据,如果数据安全等级过高,一般也要求外部顾问或者实施团队直接驻厂办公且使用内部设备的方式来避免知识的外泄。
三、数字化转型的自主进化特征
典型实施路径包括:
启动期(0-6个月):
- 业务流程诊断
- 数字成熟度评估
- 制定实施路线图
攻坚期(6-24个月):
- 试点场景验证
- 组织能力建设
- 技术平台搭建
持续优化期(24个月+):
- 数据价值挖掘
- 智能应用迭代
- 生态体系构建
很多公司宣称的数字化项目中,可以看到很多项目都有重复申报和宣扬的情况,这就是由于这些项目,都是基于典型路径进行实施:
- 项目的启动期
- 项目的试点期
- 项目的推广期
- 项目的持续改进
这些过程看起来每个都不长(小于一年),但是四大环节叠加后,可能超过两到三年的持续积累实践才能出现满意的效果。
某家电企业实践表明,其数字化升级历时5年历经3个主要版本迭代,每次迭代涉及40%以上的功能重构。
四、工业知识软件化的分层转化
工业技术软件化一个关键的问题是知识的数字化,这就涉及到数据(Data)——信息(Information)——知识(Knowledge)——智慧(Wisdom),即知识数字化转化需要考虑的DIKW模型。
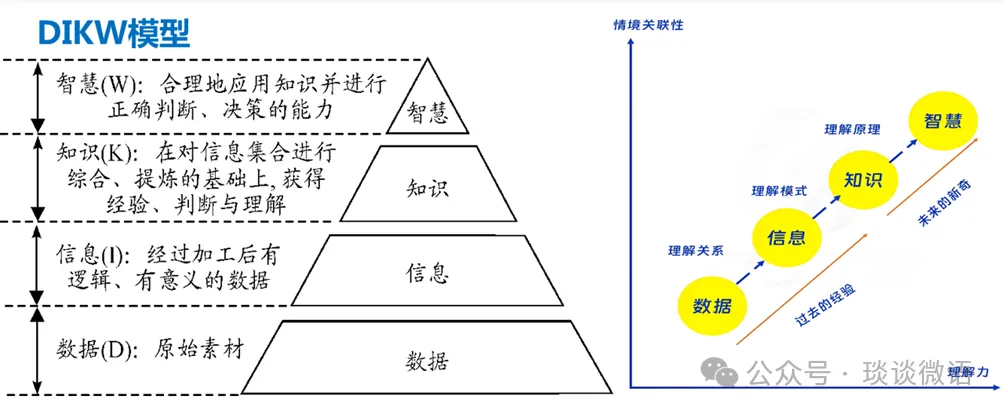
比如对于钢铁行业,中国的钢铁企业的设备普遍比外国企业好,因为我们起步比别人晚,但外国企业的数据很好用。他说的数据其实就是DIKW模型中的知识。
阶段一:
“一五”计划期间苏联援建的硬质合金企业,当时苏联只告诉我们怎么做,所以我们不知道为什么,按照DIKW模型,我们只掌握了信息。
阶段二:
上世纪八十年代改革开放,该企业从西方国家引进技术,派了个团队过去学习,大家白天紧张的学习,晚上还要复盘交流总结,对别人的技术不仅知其然,而且知其所以然,也就是我们常说的掌握了“know-how”,即DIKW模型中的知识。
阶段三:
有了阶段二的基础,企业不断改进和创新,成为我国最优秀的硬质合金企业,这就形成了智慧。
五、如何确保企业数字化成功
企业数字化不仅以知识转化为基础,而且还有通过数字化不断创新知识、完善知识、积累知识,而知识数字化金字塔包含两个部分:
-
显性知识:
- 标准操作规程
- 设备参数手册
- 质量检验标准
-
隐性知识:
- 老师傅的工艺诀窍(如特殊焊接手法)
- 异常处理经验(如设备故障的"听音辨症")
- 生产节拍把控(如换模时间的预判调整)
企业需要加强知识管理,将许许多多团队的显性知识汇集成组织的显性知识,变成标准或规范,从而实现将这些标准和规范不断的复用持续赋能企业内部的个体,如此循环往复、螺旋式上升。



















