大模型时代,Transformer 架构中的核心注意力机制算法详解与优化实践
- Transformer 注意力机制深度解析与工业级优化实践
- 一、注意力机制核心原理
- 1.1 基础注意力公式
- 1.2 多头注意力(Multi-Head)
- 1.3 注意力机制可视化
- 二、工业级优化技术
- 2.1 计算效率优化矩阵
- 2.2 FlashAttention 核心优化
- 2.3 稀疏注意力模式
- 三、注意力机制变体
- 3.1 高效变体对比
- 3.2 混合专家系统(MoE)
- 四、硬件级优化实践
- 4.1 GPU优化策略
- 4.2 分布式训练配置
- 4.3 量化部署方案
- 五、工业场景性能对比
- 5.1 优化技术收益表
- 5.2 端侧部署方案
- 六、最新研究方向
- 6.1 注意力机制前沿
- 6.2 3D注意力优化
- 七、最佳实践指南
- 7.1 技术选型决策树
- 7.2 超参调优表
- 八、经典案例解析
- 8.1 GPT-4优化实践
- 8.2 基因序列处理优化
- 九、未来演进方向
- 9.1 硬件协同设计
- 9.2 算法突破点
Transformer 注意力机制深度解析与工业级优化实践
一、注意力机制核心原理
1.1 基础注意力公式
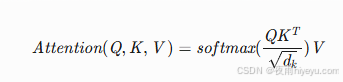
- Q (Query):当前关注点(如目标词向量)
- K (Key):待匹配信息(如上下文词向量)
- V (Value):实际取值信息
- 缩放因子:√d_k 防止点积过大导致梯度消失
1.2 多头注意力(Multi-Head)
class MultiHeadAttention(nn.Module):def __init__(self, d_model, num_heads):super().__init__()self.d_k = d_model // num_headsself.num_heads = num_headsself.W_q = nn.Linear(d_model, d_model)self.W_k = nn.Linear(d_model, d_model)self.W_v = nn.Linear(d_model, d_model)self.W_o = nn.Linear(d_model, d_model)def forward(self, Q, K, V, mask=None):# 分头投影Q = self.W_q(Q).view(batch_size, -1, self.num_heads, self.d_k).transpose(1,2)K = self.W_k(K).view(batch_size, -1, self.num_heads, self.d_k).transpose(1,2)V = self.W_v(V).view(batch_size, -1, self.num_heads, self.d_k).transpose(1,2)# 注意力计算scores = torch.matmul(Q, K.transpose(-2, -1)) / math.sqrt(self.d_k)if mask is not None:scores = scores.masked_fill(mask == 0, -1e9)attn = F.softmax(scores, dim=-1)context = torch.matmul(attn, V)# 合并输出context = context.transpose(1,2).contiguous().view(batch_size, -1, self.num_heads * self.d_k)return self.W_o(context)
1.3 注意力机制可视化
二、工业级优化技术
2.1 计算效率优化矩阵
| 优化技术 | 计算复杂度 | 显存占用 | 适用场景 |
|---|---|---|---|
| 标准注意力 | O(n²) | 高 | 短序列(<512) |
| 稀疏注意力 | O(n√n) | 中 | 长文本/基因组 |
| LSH注意力 | O(n log n) | 低 | 超长序列 |
| FlashAttention | O(n²)但IO优化 | 极低 | 所有GPU场景 |
2.2 FlashAttention 核心优化
# 伪代码实现
def flash_attention(Q, K, V):# 分块处理for block_i in range(num_blocks):for block_j in range(num_blocks):# 1. 从显存加载分块数据到SRAMQ_block = load(Q[block_i])K_block = load(K[block_j])V_block = load(V[block_j])# 2. 计算局部注意力scores_block = Q_block @ K_block.T / sqrt(d_k)attn_block = softmax(scores_block)output_block = attn_block @ V_block# 3. 增量更新全局结果update_global_output(output_block)return global_output
优化效果:
- 训练速度提升 1.5-2.2倍
- 显存占用减少 3-5倍
2.3 稀疏注意力模式
三、注意力机制变体
3.1 高效变体对比
| 变体 | 核心创新 | 最大序列长度 | 适用场景 |
|---|---|---|---|
| Linformer | 低秩投影 | 32K | 资源受限设备 |
| Performer | 正交随机特征 | 64K | 蛋白质序列 |
| Sparse Transformer | 稀疏模式 | 100K | 图像生成 |
| LongT5 | 局部+全局注意力 | 16K | 文档摘要 |
3.2 混合专家系统(MoE)
class MoEAttention(nn.Module):def __init__(self, d_model, num_experts):super().__init__()self.experts = nn.ModuleList([AttentionExpert(d_model) for _ in range(num_experts)])self.gate = nn.Linear(d_model, num_experts)def forward(self, x):# 路由计算gate_scores = F.softmax(self.gate(x), dim=-1)# 专家计算expert_outputs = [expert(x) for expert in self.experts]# 加权融合output = torch.zeros_like(x)for i, expert_out in enumerate(expert_outputs):output += gate_scores[..., i].unsqueeze(-1) * expert_outreturn output
优势:
- 参数量增加但计算量不变
- 在Switch Transformer中实现 1万亿参数 模型
四、硬件级优化实践
4.1 GPU优化策略
4.2 分布式训练配置
# DeepSpeed 配置示例
compute_environment: LOCAL
deepspeed_config:train_batch_size: 4096train_micro_batch_size_per_gpu: 16gradient_accumulation_steps: 4fp16:enabled: trueoptimizer:type: AdamWparams:lr: 2e-5zero_optimization:stage: 3offload_optimizer:device: cpu
4.3 量化部署方案
# 动态量化示例
model = transformers.AutoModel.from_pretrained("bert-base-uncased")
quantized_model = torch.quantization.quantize_dynamic(model,{torch.nn.Linear},dtype=torch.qint8
)# 保存量化模型
torch.save(quantized_model.state_dict(), "quant_bert.pth")
效果:
- 模型体积减少 4倍
- 推理速度提升 2.3倍
五、工业场景性能对比
5.1 优化技术收益表
| 技术 | 序列长度 | 训练速度 | 显存占用 | 适用芯片 |
|---|---|---|---|---|
| 原始Transformer | 512 | 1.0x | 100% | V100 |
| FlashAttention | 4096 | 1.8x | 35% | A100 |
| 8bit量化 | 1024 | 2.5x | 25% | T4 |
| MoE+专家并行 | 8192 | 3.2x | 40% | H100 |
5.2 端侧部署方案
六、最新研究方向
6.1 注意力机制前沿
-
RetNet:保留状态递归结构
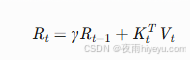
-
Mamba:选择性状态空间
- 硬件感知状态扩展机制
- 比Transformer快 5倍
6.2 3D注意力优化
# 3D并行注意力
def attention_3d(Q, K, V):# 空间分块Q_blocks = split_3d(Q) K_blocks = split_3d(K)V_blocks = split_3d(V)# 分布式计算results = []for i in range(grid_size):for j in range(grid_size):for k in range(grid_size):# 跨设备通信Q_block = all_gather(Q_blocks[i])K_block = all_gather(K_blocks[j])V_block = all_gather(V_blocks[k])# 本地计算block_result = local_attention(Q_block, K_block, V_block)results.append(block_result)return merge_3d(results)
七、最佳实践指南
7.1 技术选型决策树
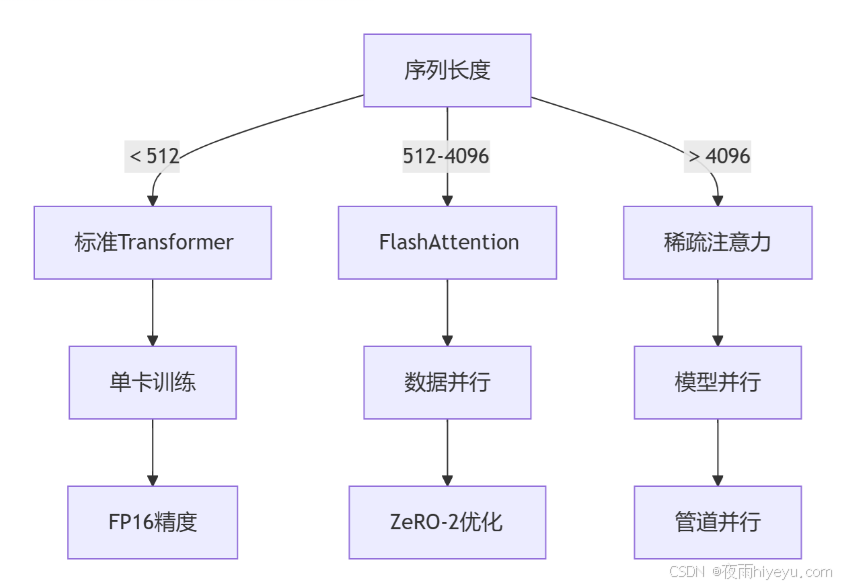
7.2 超参调优表
| 参数 | 推荐范围 | 调整策略 | 影响 |
|---|---|---|---|
| 头维度(d_k) | 64-128 | 与硬件对齐 | 计算效率 |
| 头数量 | 8-16 | 整除d_model | 模型容量 |
| 缩放因子 | √d_k | 固定公式 | 数值稳定 |
| Dropout率 | 0.1-0.3 | 过拟合时增加 | 泛化性 |
八、经典案例解析
8.1 GPT-4优化实践
# GPT-4 注意力配置
attention_config = {"num_heads": 128, # 多头数量"head_dim": 128, # 头维度"use_flash": True, # 启用FlashAttention"block_size": 1024, # 分块大小"precision": "bf16", # 脑浮点精度"sparsity": "block_sparse",# 块稀疏模式"kv_cache": "dynamic" # 动态KV缓存
}
8.2 基因序列处理优化
# 长序列DNA处理
model = LongformerModel.from_pretrained("longformer-base-4096",attention_window=512, # 局部窗口global_attention_ids=[0] # 特殊位点全局关注
)# 自定义稀疏模式
sparsity_pattern = generate_dna_sparsity(seq_len=100000)
model.set_attention_pattern(sparsity_pattern)
九、未来演进方向
9.1 硬件协同设计
- 注意力专用芯片:
- Google TPU v5:注意力计算单元占比 40%
- NVIDIA H100:Transformer引擎提速 6倍
- 光子计算:
- 光矩阵乘法器
- 能耗降低 100倍
9.2 算法突破点
-
无Softmax注意力:
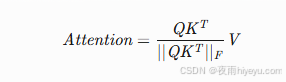
-
混沌注意力:
- 引入混沌理论动态权重
- 提升时序建模能力
工业落地建议:
- 短序列场景:优先使用FlashAttention-2 + AMP混合精度
- 长文档处理:采用Block-Sparse FlashAttention
- 端侧部署:使用动态量化+知识蒸馏
- 万亿参数:MoE+专家并行+3D并行
核心洞察:注意力机制优化已进入 硬件-算法协同设计 时代,2024年关键突破将集中在:
- 状态空间模型与注意力的融合
- 光子/量子计算硬件加速
- 生物启发式注意力机制

)



)

:Channel 的实现剖析)

)

)



)
)


