1 apply()函数
1.1 apply()函数简介
- Pandas提供了很多数据处理的API,但当提供的API不能满足需求的时候,需要自己编写数据处理函数, 这个时候可以使用
apply()函数; apply()函数可以接收一个自定义函数,可以将DataFrame的行或列数据传递给自定义函数处理;apply()函数类似于编写了一个for循环,遍历行/列的每一个元素,但比使用for循环效率高很多。
1.2 使用方法
-
数据准备:
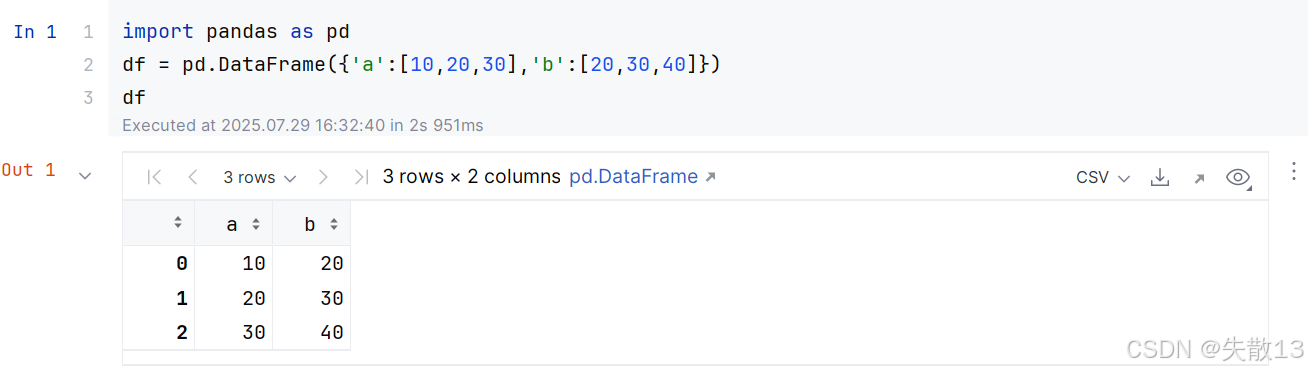
-
自定义一个求平方的函数:

-
apply()函数有一个func参数,用于接收一个函数,然后应用于Series的每个元素- 注意:传入的是函数名,不要带上
()
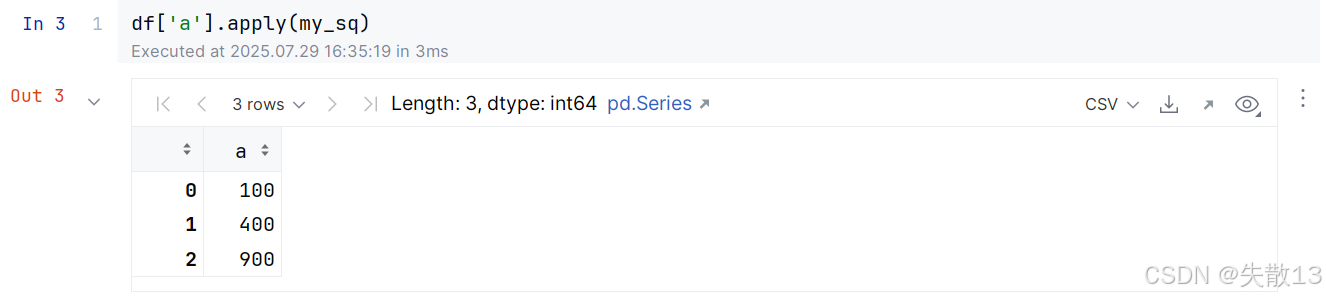
- 注意:传入的是函数名,不要带上
-
如果自定义的函数有其它参数需要传入时:
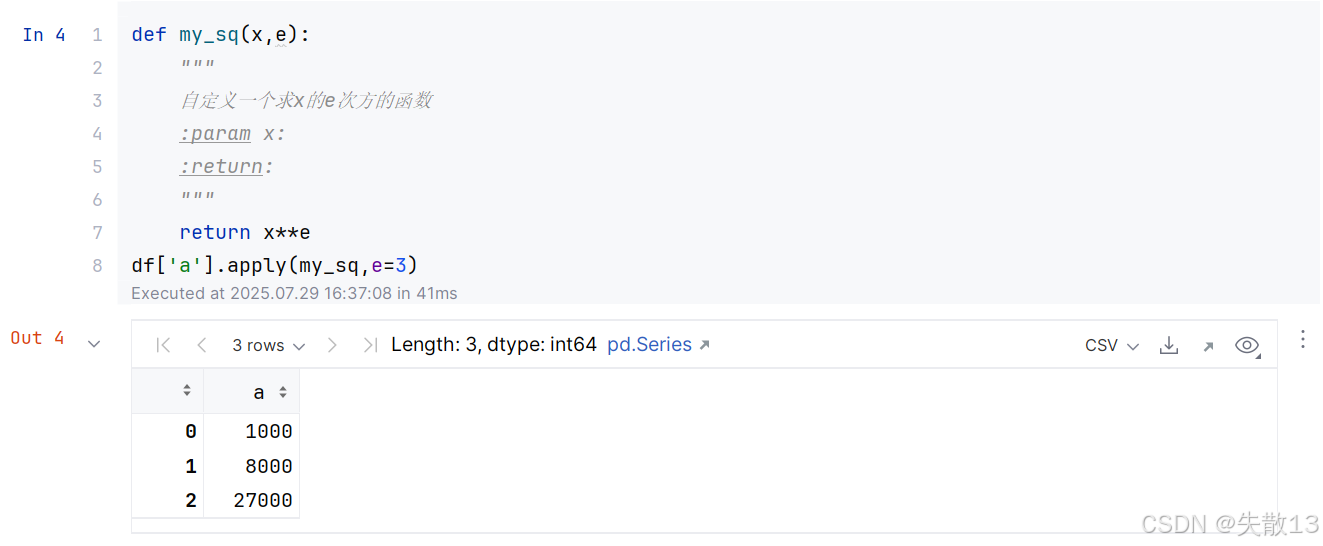
-
上面是将自定义函数作用于Series,也可以作用于一整个DataFrame:
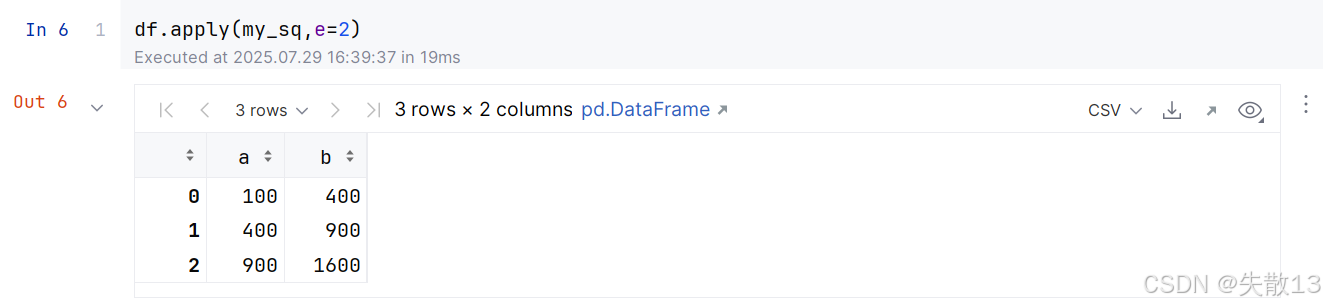
-
如果自定义函数中有输出语句:
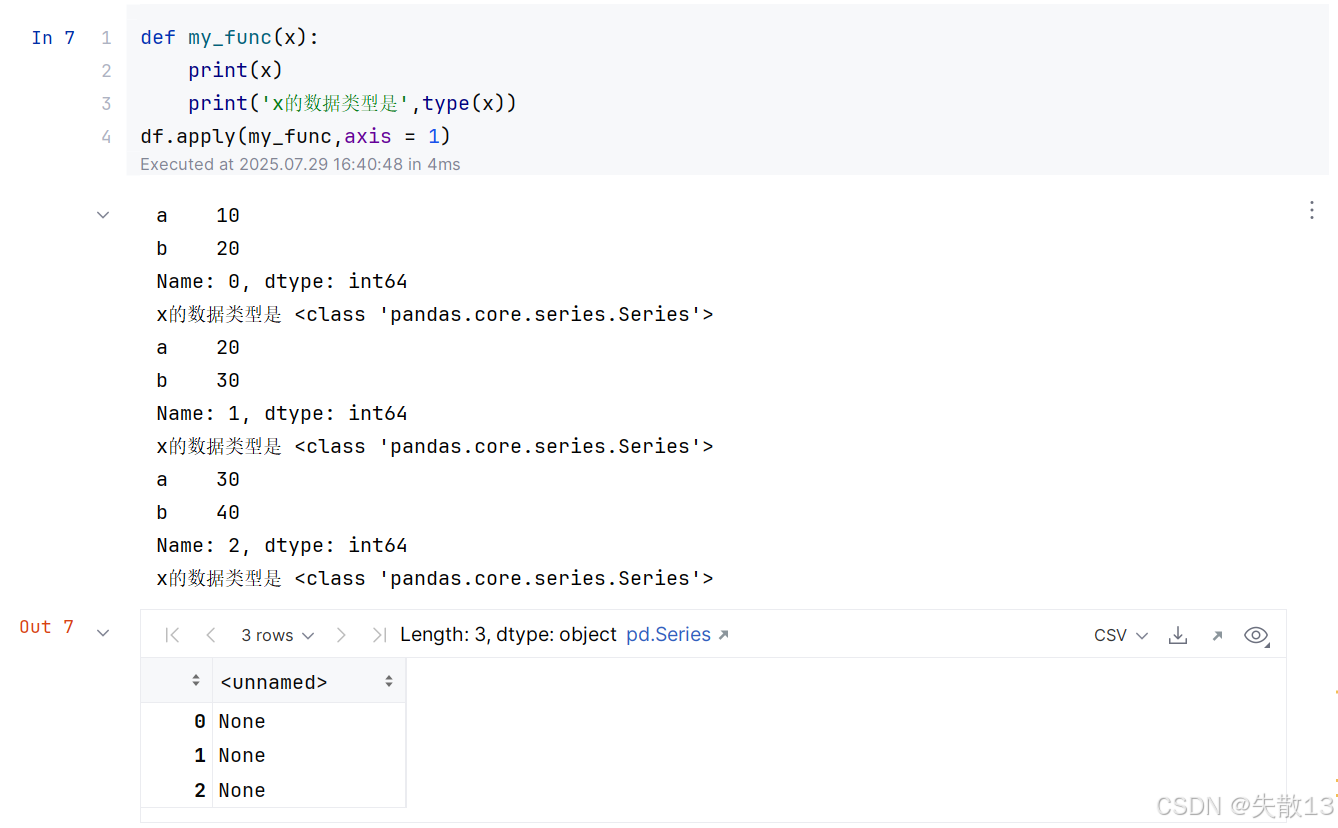
-
注意:
apply()函数是直接将一整个DataFrame或者Series作为一个参数传递给自定义函数
- 从报错的信息中看到,实际上
avg_3函数接收到的只有一个变量,这个变量可以是DataFrame的行也可以是DataFrame的列;
- 从报错的信息中看到,实际上
-
使用
apply()函数的时候,可以通过axis参数指定按行或者按列传入数据;-
axis = 0:按列处理(默认)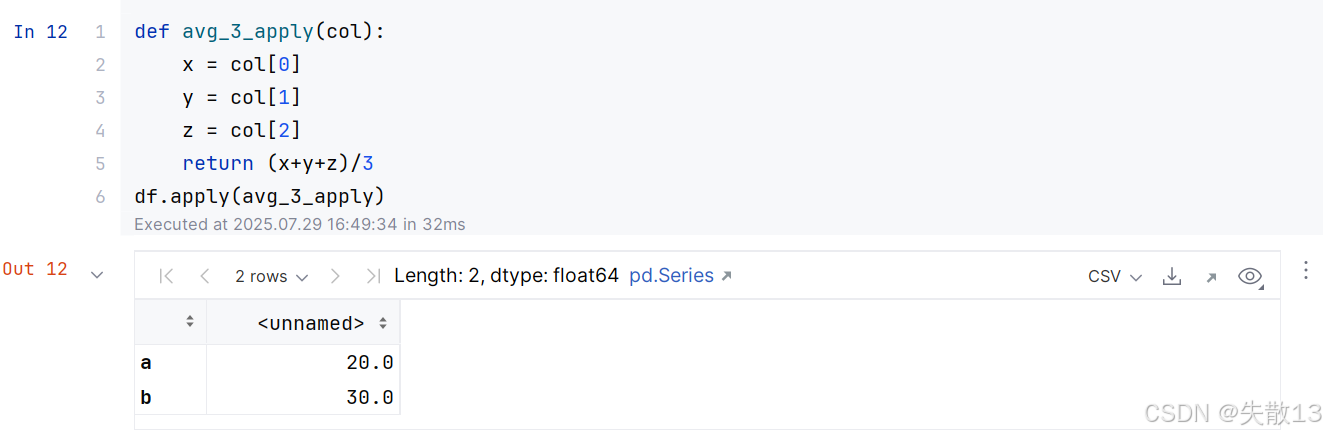
-
axis = 1:按行处理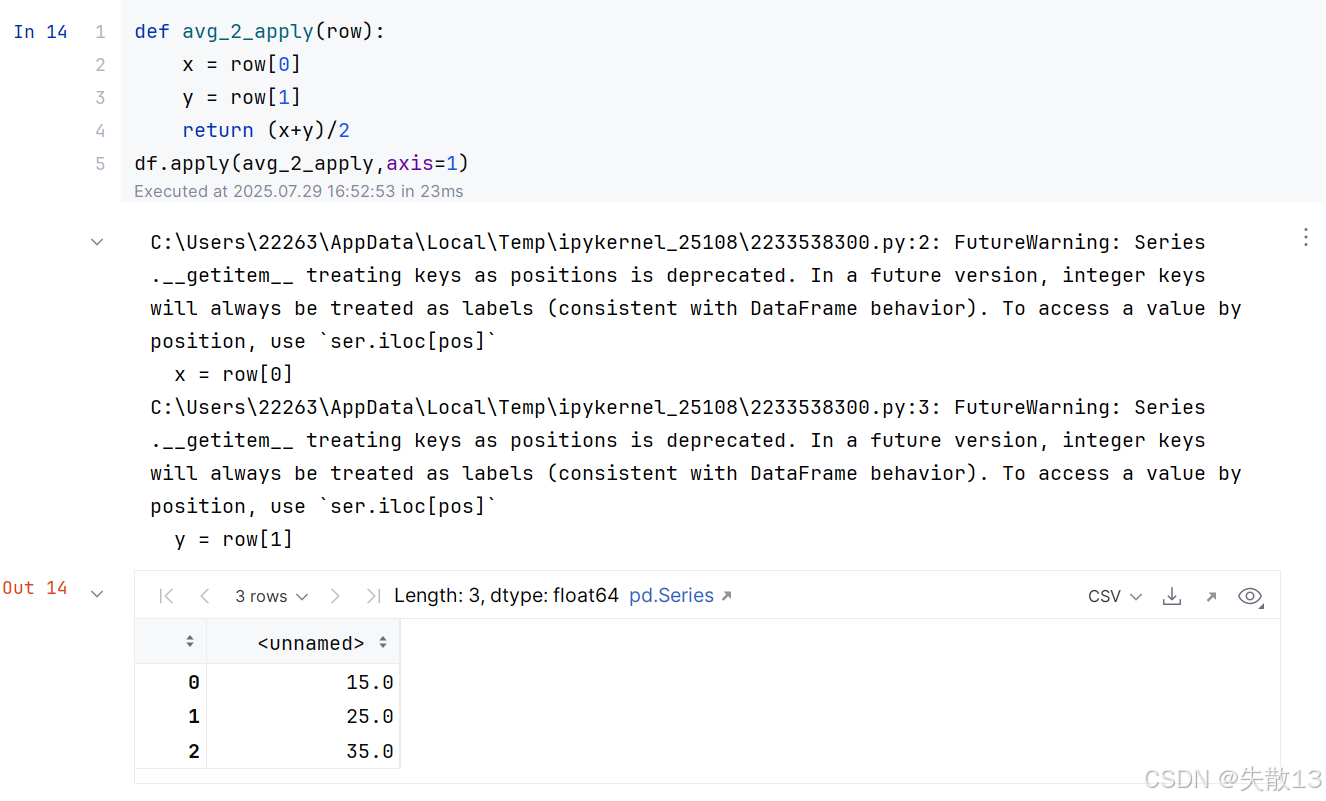
-
2 apply()使用案例
-
使用titanic数据集,先加载数据:
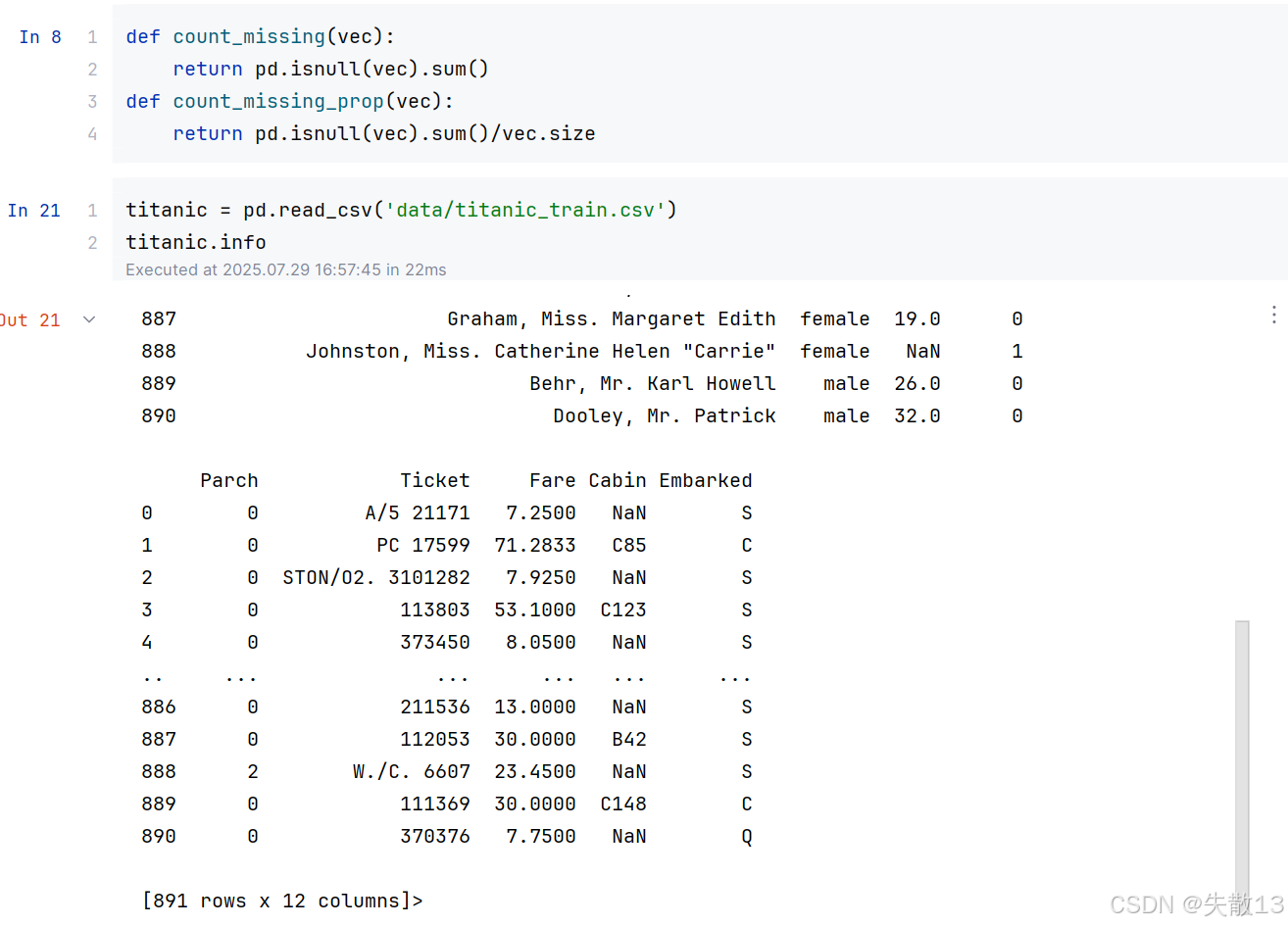
-
准备三个函数:
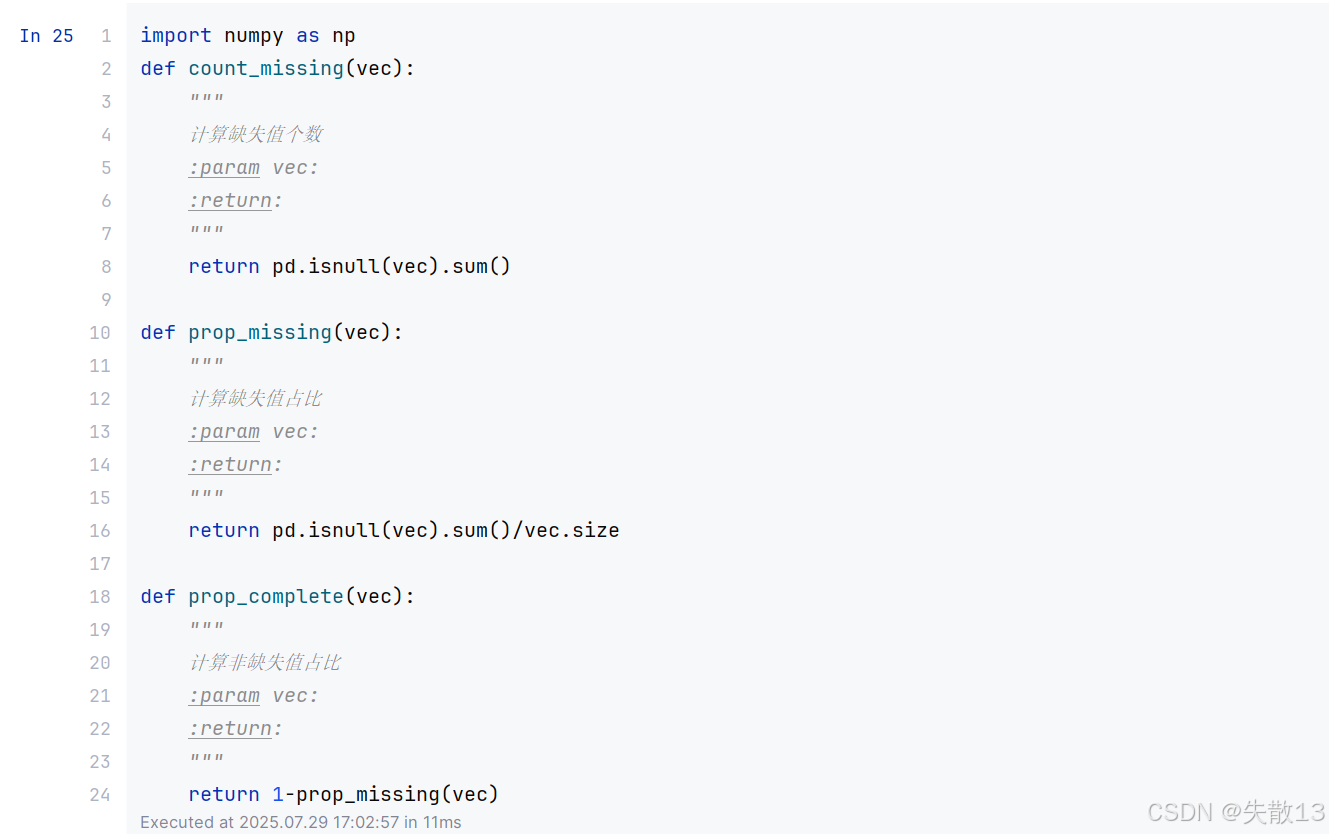
-
把前面定义好的函数应用于数据的各列:
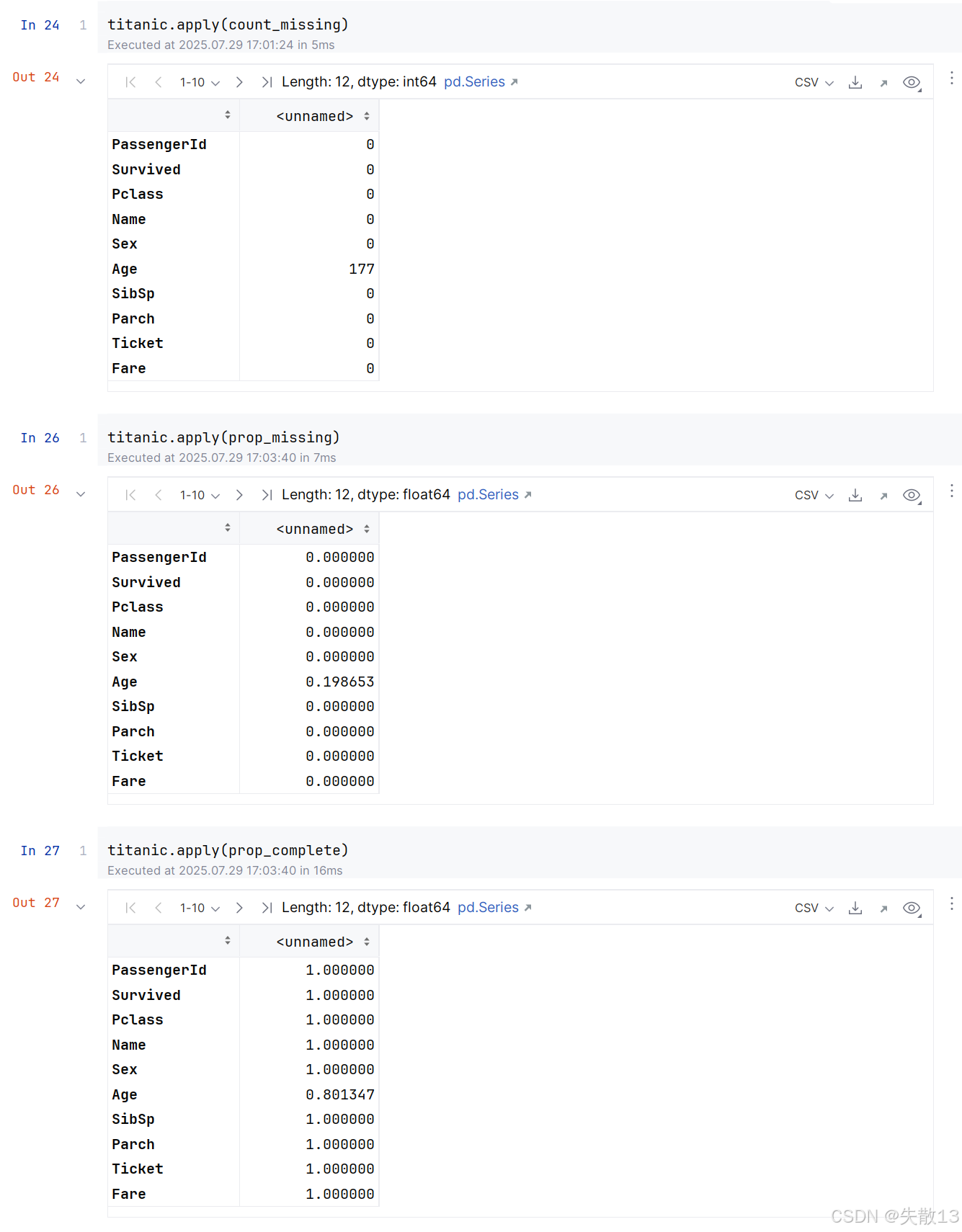
-
把前面定义好的函数应用于数据的各行:
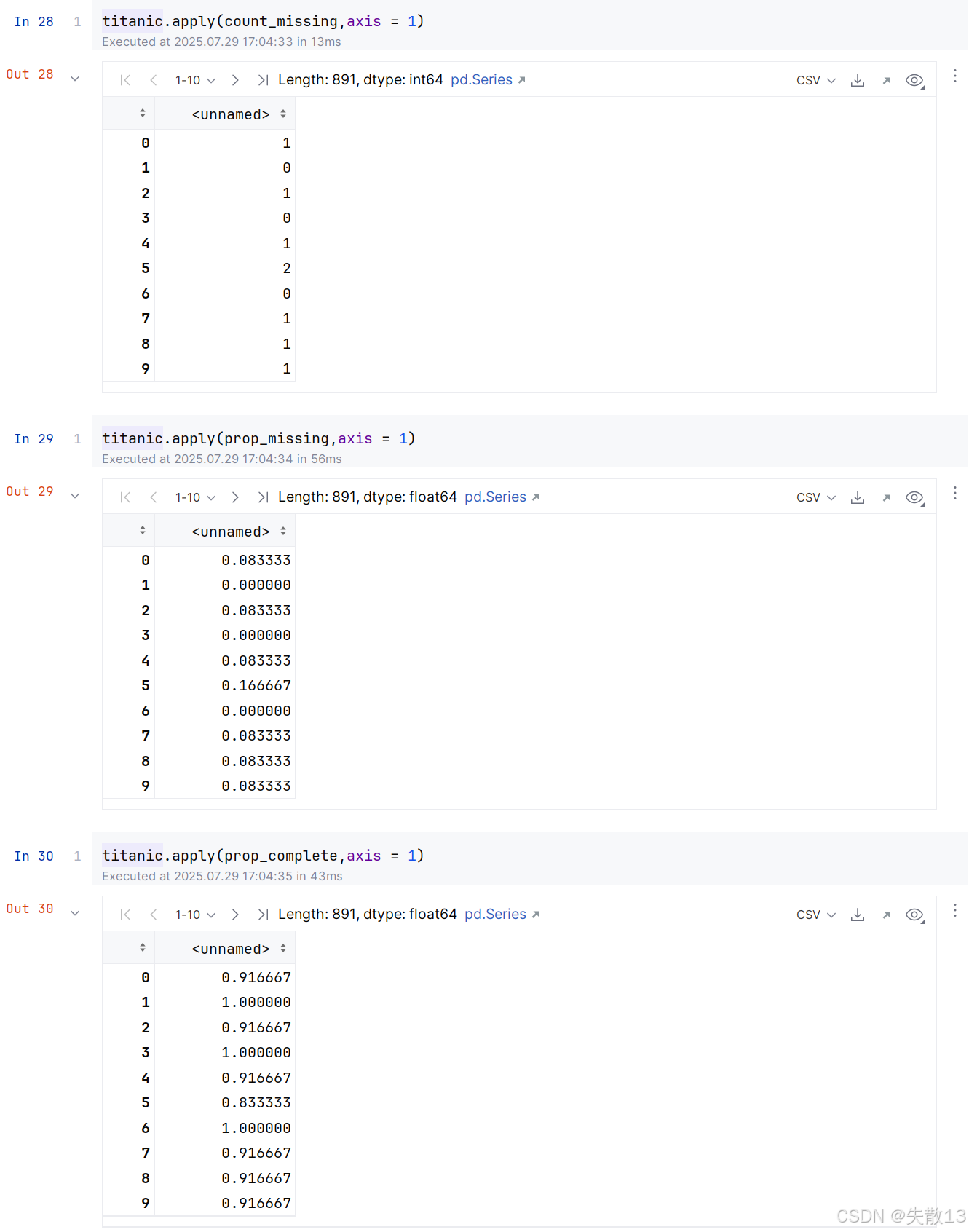
3 函数向量化
-
准备一个DataFrame:
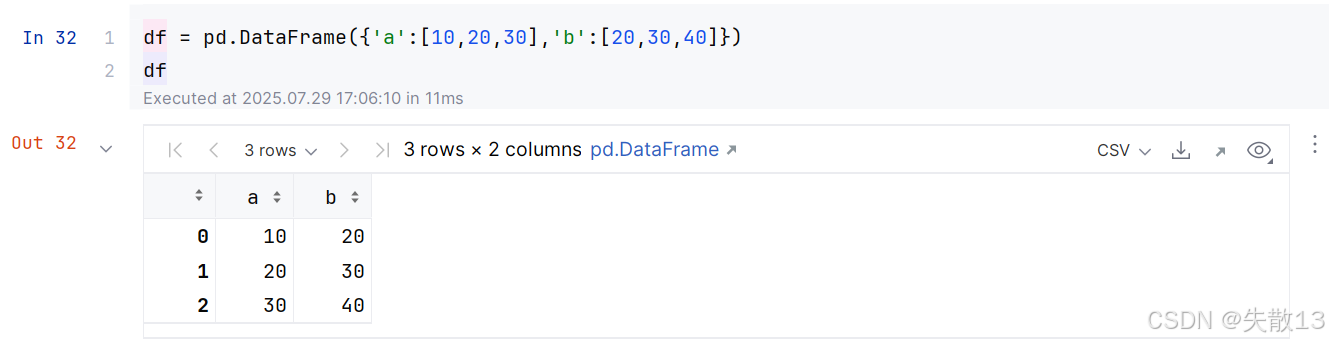
-
创建一个自定义函数,用于计算DataFrame中每行的平均值:
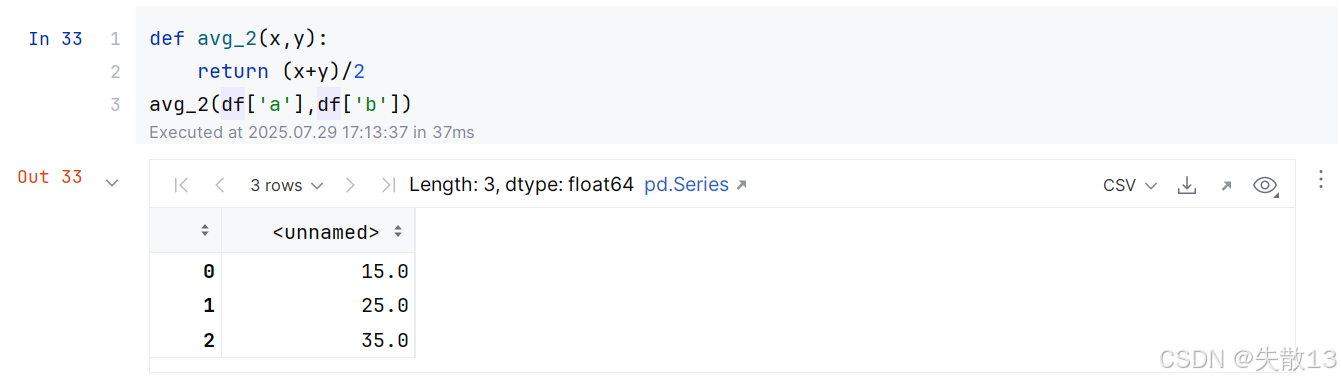
-
修改一下上面的自定义函数,在其中加入一个
if判断,结果发现报错: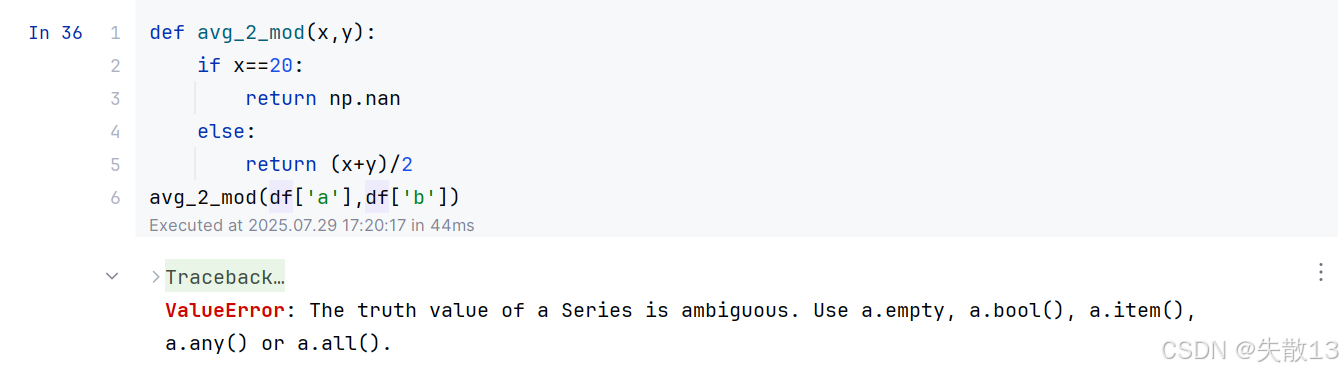
ValueError: The truth value of a Series is ambiguous. Use a.empty, a.bool(), a.item(), a.any() or a.all().是因为在avg_2_mod函数中,尝试对pandas的Series对象进行布尔判断,而这种判断在pandas中是不明确的;x == 20的问题:- 在
avg_2_mod()函数中,x是df['a'],它是一个pandas的Series对象; x == 20会返回一个布尔型的Series,表示df['a']中每个元素是否等于 20;- 然而,
if语句需要一个单一的布尔值,而不是一个布尔型的Series,因此会导致报错;
- 在
-
解决1:使用
np.vectorize()将函数向量化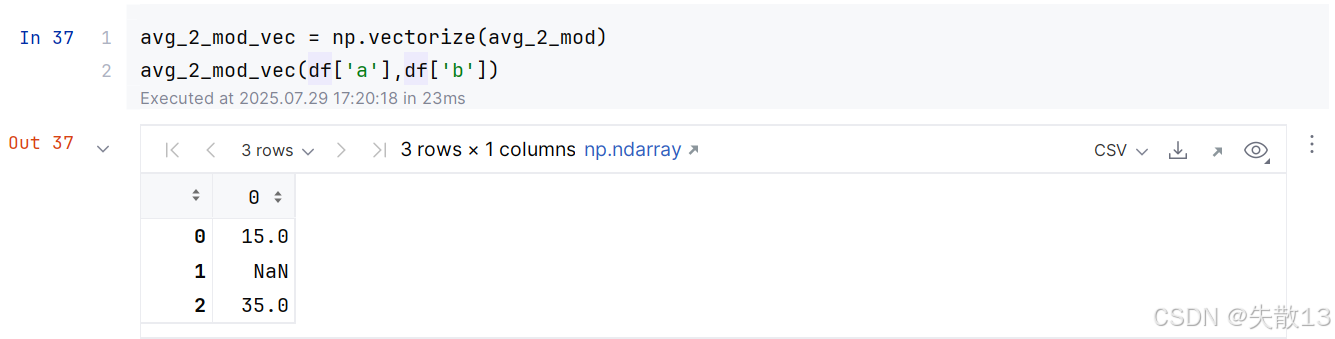
-
解决2:使用
@np.vectorize装饰器,可以自动将一个普通的 Python 函数转换为向量化函数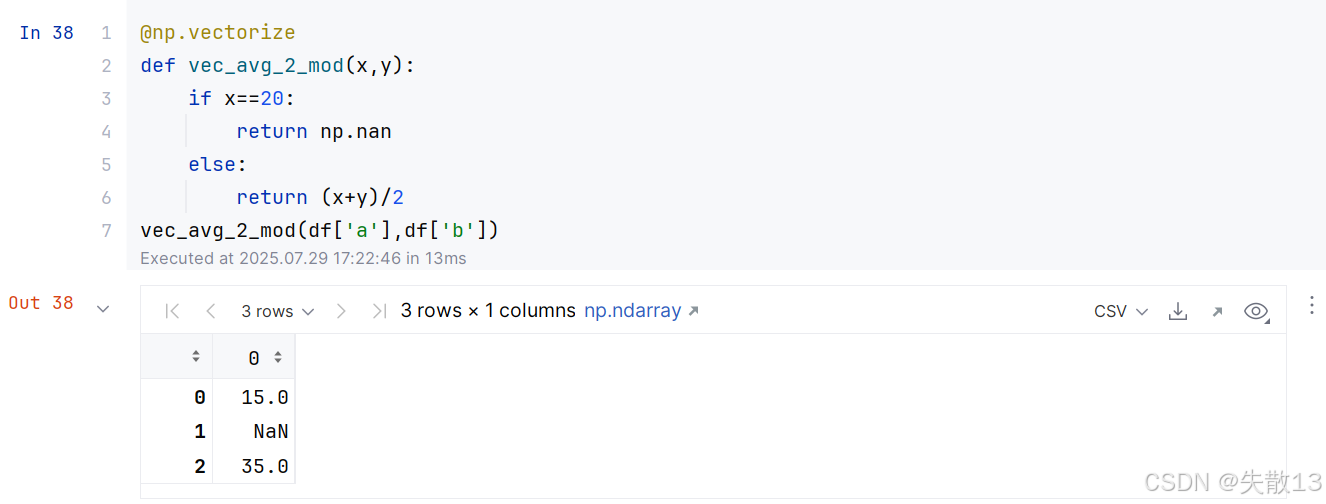
4 Lambda表达式
-
当函数比较简单的时候, 没有必要用
def创建函数,可以使用Lambda表达式创建匿名函数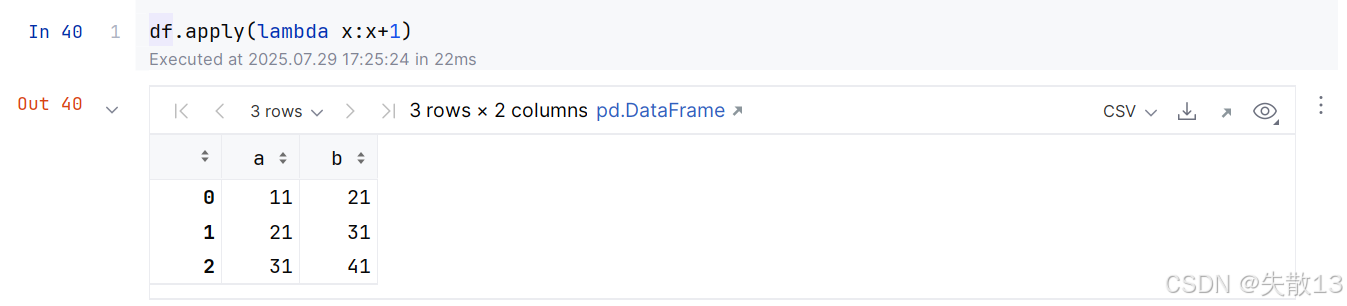
lambda x: x + 1是一个匿名函数,它接受一个参数x,并返回x + 1;
-
或者:



)












)



)