一、二叉排序树(BST)
1、二叉排序树的定义
构造一棵二叉排序树的目的并不是排序,而是提高查找、插入和删除关键字的速度
二叉排序树(也称二叉搜索树)或者是一颗空树,或者是具有以下性质的二叉树
1、若左子树非空,则左子树上所有结点的值均小于根节点的值
2、若右子树非空,则右子树上所有结点的值均大于根节点的值
3、左右子树分别是一颗二叉排序树
(右子树所有结点的值均大于左子树所有结点的值)
对二叉排序树进行中序遍历,可以得到一个递增的有序序列
2、二叉排序树的查找
二叉排序树的查找是从根节点开始,是一个递归的过程
二叉排序树的非递归查找算法 ,空间复杂度O(1)
//二叉排序树的结点
typedef struct BSTNode{int key;struct BSTNode *lchild,*rchild;
}BSTNode, *BSTree;//二叉排序树的非递归查找算法
BSTNode *BST_Search(BSTree T, int key){while(T != NULL && key != T->key){ //若树空或等于根节点值,则结束循环if(key < T->key){ //小于,则在左子树上查找T = T->lchild; //大于,则在右子树上查找}else{T = T->rchild;}}return T;
}
二叉排序树的递归查找算法 ,空间复杂度O(h)
//在二叉排序树中查找值为key的结点(递归实现)
BSTNode *BST_Search_Recursion(BSTree T, int key){if(T == NULL){return NULL; //查找失败}if(key == T->key){return T; //查找成功}else if(key < T->key){return BST_Search_Recursion(T->lchild, key);//在左子树中找}else{return BST_Search_Recursion(T->rchild, key);//在右子树中找}}3、二叉排序树的插入
二叉排序树是一颗动态树,在查找过程中,当树中不存在关键字值等于给定值的结点时进行插入。
若关键字的值小于根结点,则插入左子树;反之,插入右子树;
新插入的结点一定是一个叶节点,且是查找失败时的查找路径上访问的最后一个结点的左孩子或右孩子
如图,虚线表示查找路径
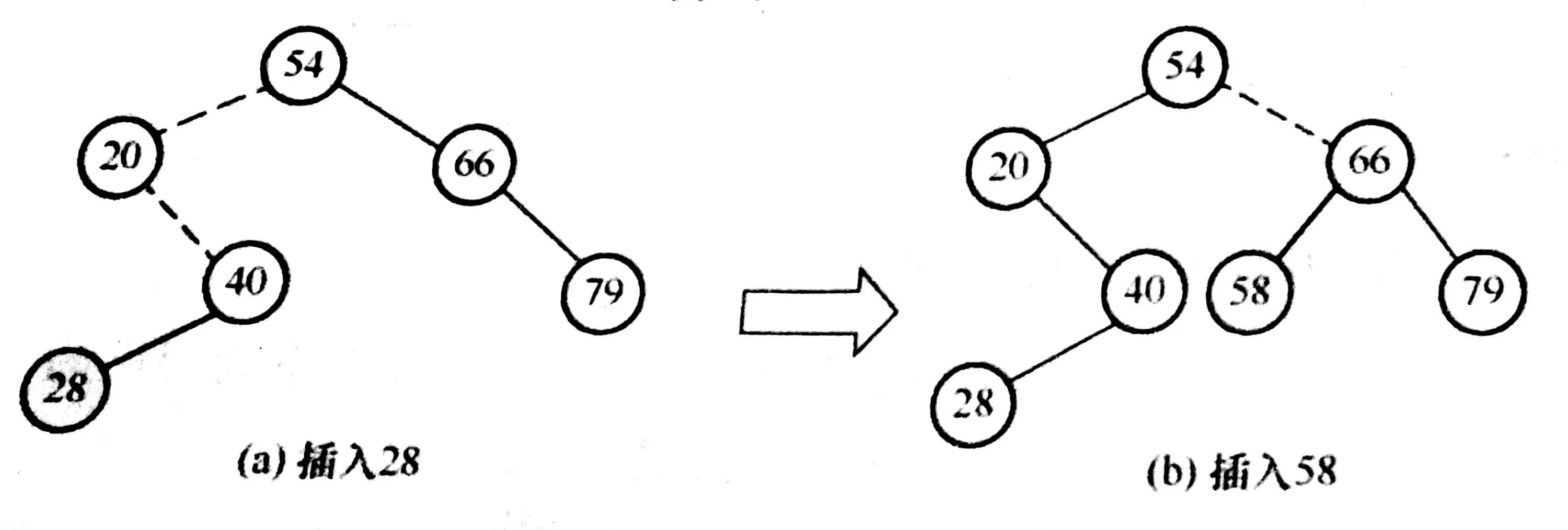
在二叉排序树中插入关键值为key的新结点(递归实现)
注:树中存在相同关键字的结点会导致插入失败
//在二叉排序树中插入关键值为key的新结点(递归实现)
int BST_Insert(BSTree &T, int k){if(T == NULL){ //原树为空,新插入的结点为根节点T = (BSTree)malloc(sizeof(BSTNode)); T->key = k;T->lchild = T->rchild = NULL;return 1; //返回1,插入成功}else if(k == T->key){ //树中存在相同关键字的结点,插入失败return 0;}else if(k < T->key){ //插入到T的左子树return BST_Insert(T->lchild, k);}else{ //插入到T的右子树return BST_Insert(T->rchild, k);}
}
在二叉排序树中插入关键值为key的新结点(非递归实现)
//在二叉排序树中插入关键值为key的新结点(非递归实现)
int BST_Insert2(BSTree &T, int key) {BSTNode *newNode = (BSTNode*)malloc(sizeof(BSTNode)); // 创建新节点newNode->key = key;newNode->lchild = newNode->rchild = NULL;if (T == NULL) { // 如果树为空,直接插入新节点作为根T = newNode;return 1; // 插入成功}BSTNode *parent = NULL; // 用来记录父节点BSTNode *current = T; // 当前节点从根开始while (current != NULL) {parent = current; // 记录当前节点为父节点if (key == current->key) {free(newNode); // 如果树中已有相同的key,插入失败,释放新节点return 0; // 插入失败}else if (key < current->key) {current = current->lchild; // key 小于当前节点,移动到左子树}else {current = current->rchild; // key 大于当前节点,移动到右子树}}// 在遍历到NULL时,插入新节点if (key < parent->key) {parent->lchild = newNode; // 插入到父节点的左子树}else {parent->rchild = newNode; // 插入到父节点的右子树}return 1; // 插入成功
}4、二叉排序树的构造
不同的输入序列会得到不同的二叉排序树
与二分查找判定树不同,二分查找仅适用于有序的顺序表,这也就意味着,同一个序列判定树唯一。
//按照str[]中的关键字序列建立二叉排序树
void create_BST(BSTree &T, int str[], int n){T = NULL; //初始时T为空树int i = 0;while(i < n){ //依次将每个关键字插入到二叉排序树中BST_Insert(T, str[i]);i++;}
}5、二叉排序树的删除
①若被删除结点z是叶结点,则直接删除,不会破坏二叉排序树的性质;
②若结点z只有一棵左子树或右子树,则让z的子树替代z的位置;
③若结点z有左、右两棵子树,则进行中序遍历,让z的直接后继(或直接前驱)替代z,然后从二叉排序树中删去这个直接后继(直接前驱),这样就转换成了第一或第二种的情况。
如图,删除76,为第③种情况,找到直接前驱,将直接前驱的值60替代76。而后转变为删除60,此时转变成第②种情况,直接让60的左子树(55)替代60,并释放55即可。
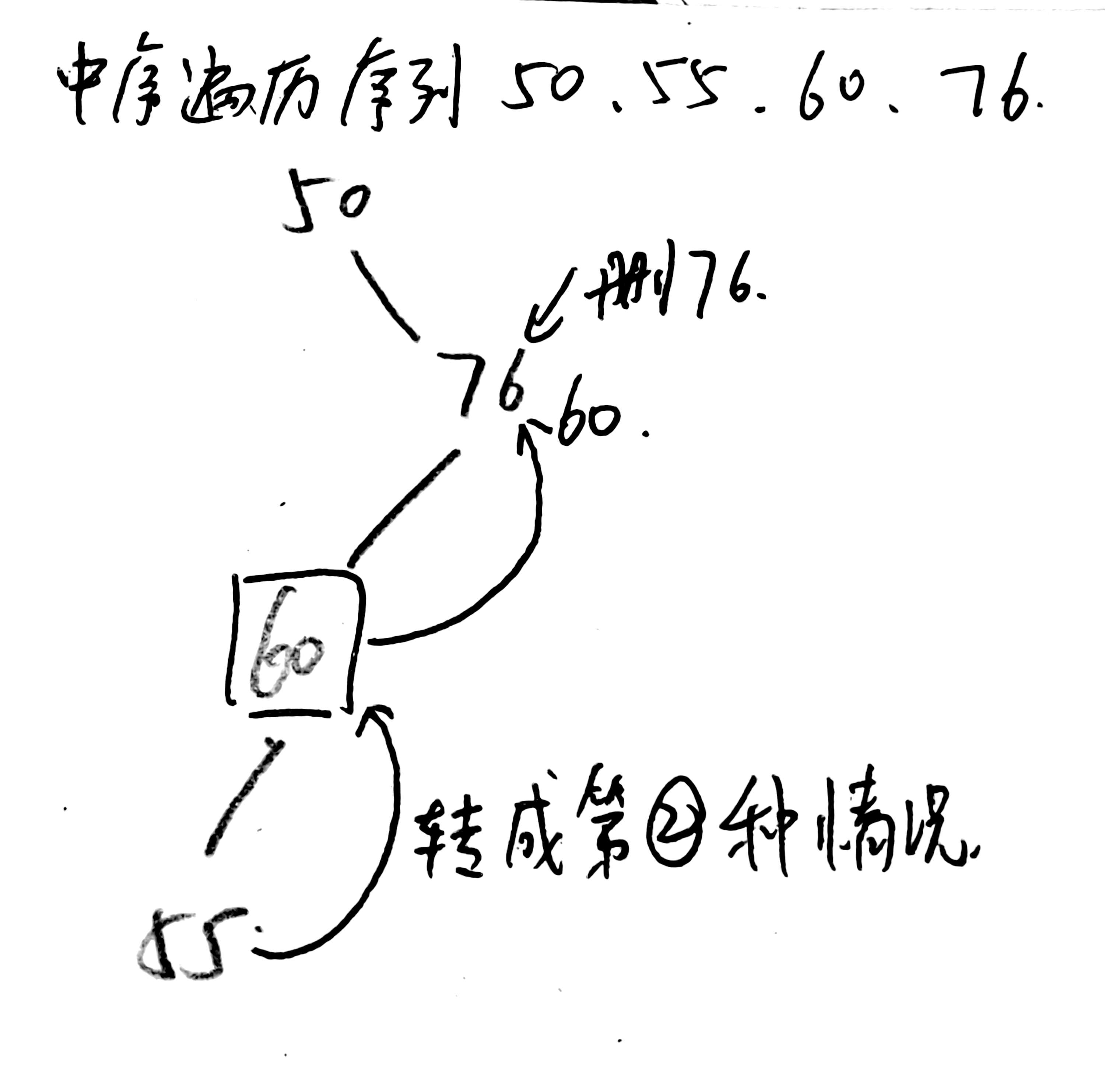
在二叉排序树中删除关键值为key的结点(递归实现)
// 查找二叉树中的最小结点(即直接后继)
BSTNode* findMin(BSTree T) {while (T && T->lchild) {T = T->lchild;}return T;
}// 查找二叉树中的最大结点(即直接前驱)
BSTNode* findMax(BSTree T) {while (T && T->rchild) {T = T->rchild;}return T;
}// 在二叉排序树中删除关键值为key的结点(递归实现)
BSTree BST_Delete(BSTree T, int key) {if (T == NULL) {return T; // 树为空,直接返回}// 如果key小于当前结点的key,则在左子树中删除if (key < T->key) {T->lchild = BST_Delete(T->lchild, key);}// 如果key大于当前结点的key,则在右子树中删除else if (key > T->key) {T->rchild = BST_Delete(T->rchild, key);}// 找到要删除的结点else {// 1. 删除的是叶结点if (T->lchild == NULL && T->rchild == NULL) {free(T); // 直接释放该结点return NULL; // 返回NULL,删除该结点}// 2. 删除的结点只有一个子树else if (T->lchild == NULL) { // 只有右子树BSTNode* temp = T;T = T->rchild; // 用右子树替代free(temp);}else if (T->rchild == NULL) { // 只有左子树BSTNode* temp = T;T = T->lchild; // 用左子树替代free(temp);}// 3. 删除的结点有两个子树else {// 找到当前结点的直接后继(右子树中的最小节点)BSTNode* temp = findMin(T->rchild);T->key = temp->key; // 用后继节点替代当前节点T->rchild = BST_Delete(T->rchild, temp->key); // 删除后继结点}}return T;
}6、二叉排序树的查找效率分析
二叉排序树的查找效率取决于树的高度。
若二叉排序树左右子树的高度只差的绝对值不超过1(即平衡二叉树),它的平均查找长度为O(
)成正比。
在最坏的情况下,若输入序列为有序的,则会形成只有右孩子的单支树,此时树高为n,即平均查找长度为(n+1)/2
在查找方面,二叉排序树和二分查找的性能差不多,但因为二叉排序树与输入序列有关,所以同一个序列两种方法的平均查找长度(即效率)存在不同。
插入删除结点维护有序性而言,二叉排序树只需要移动指针,时间复杂度为O(
而二分查找本身为有序顺序表,插入或删除需要移动大量元素,时间复杂度为O(n)
二、平衡二叉树(AVL)
平衡因子=左子树高-右子树高
平衡二叉树——平衡因子的绝对值不超过1
1、平衡二叉树的插入
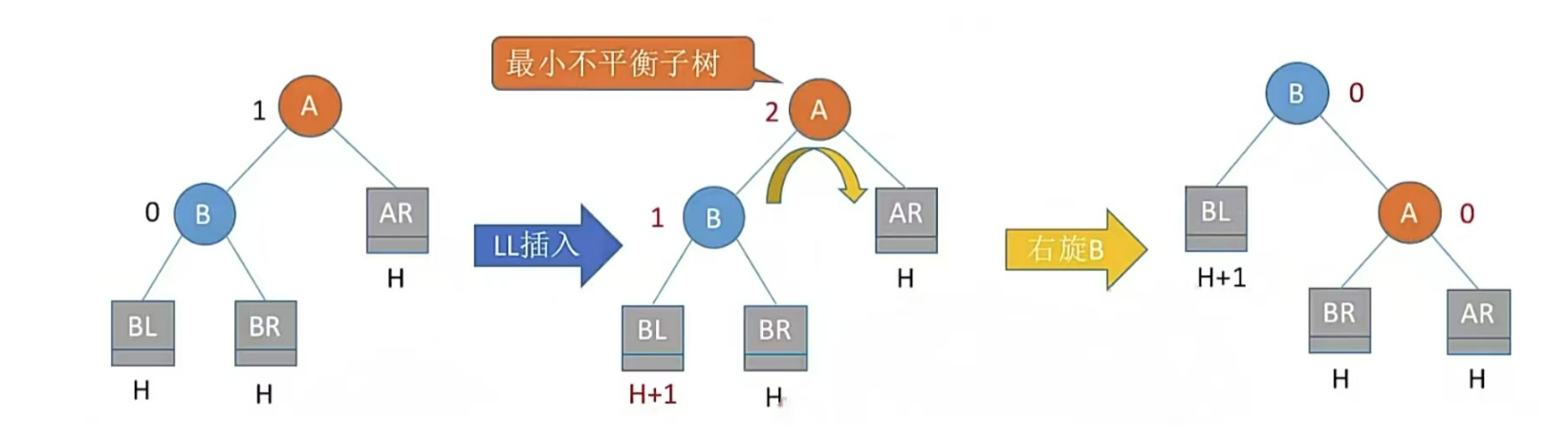
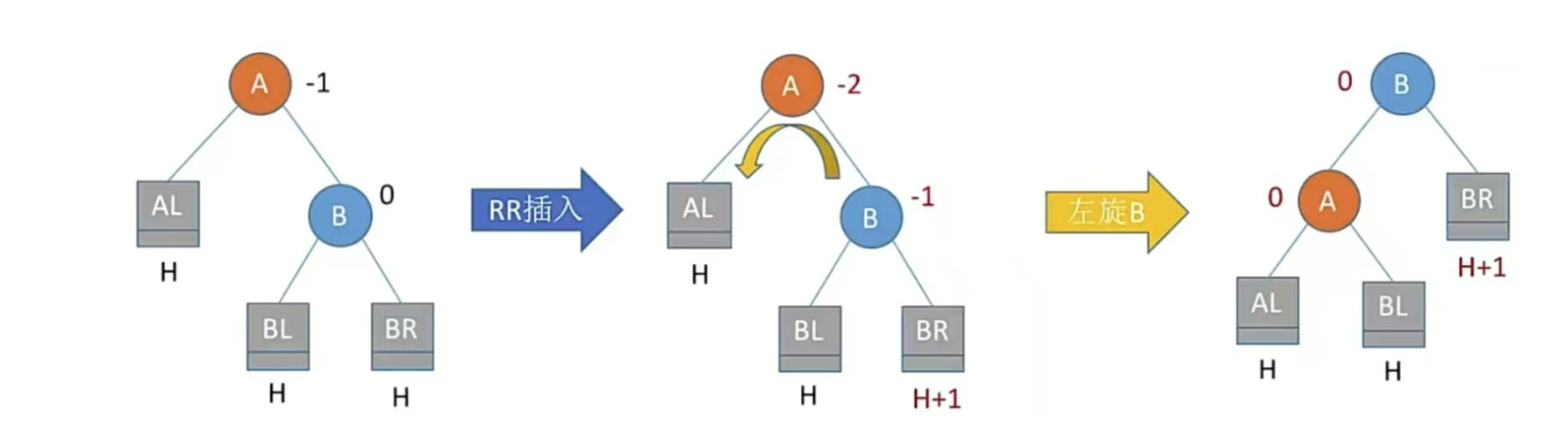
插入一个结点会造成4种情况,处理方法可使用口诀
只有左孩子右上旋,只有右孩子左上旋
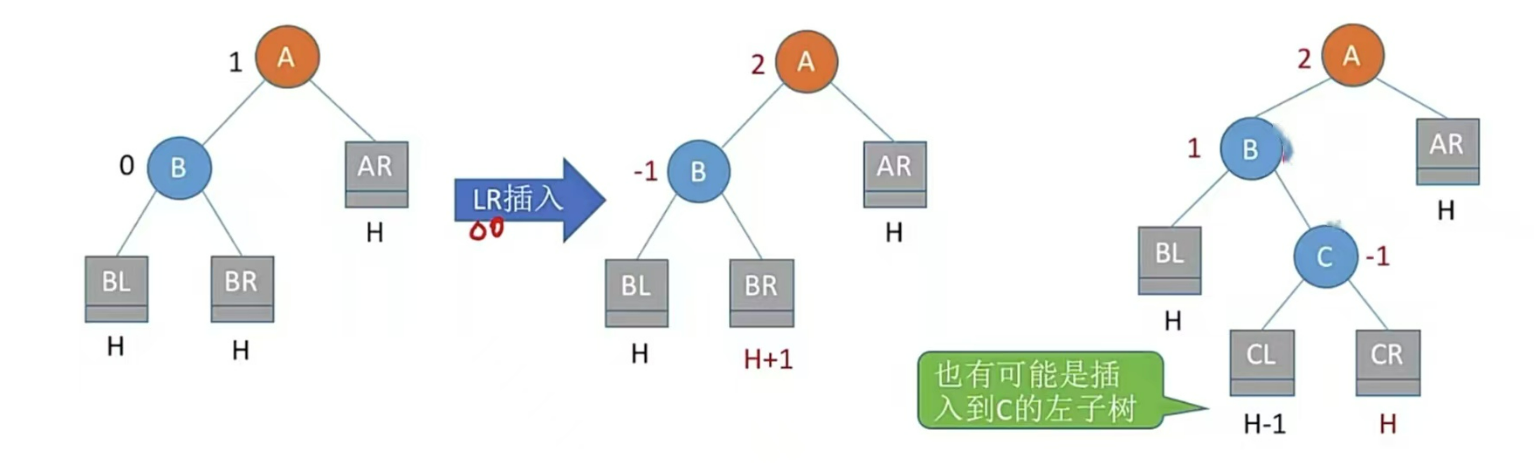
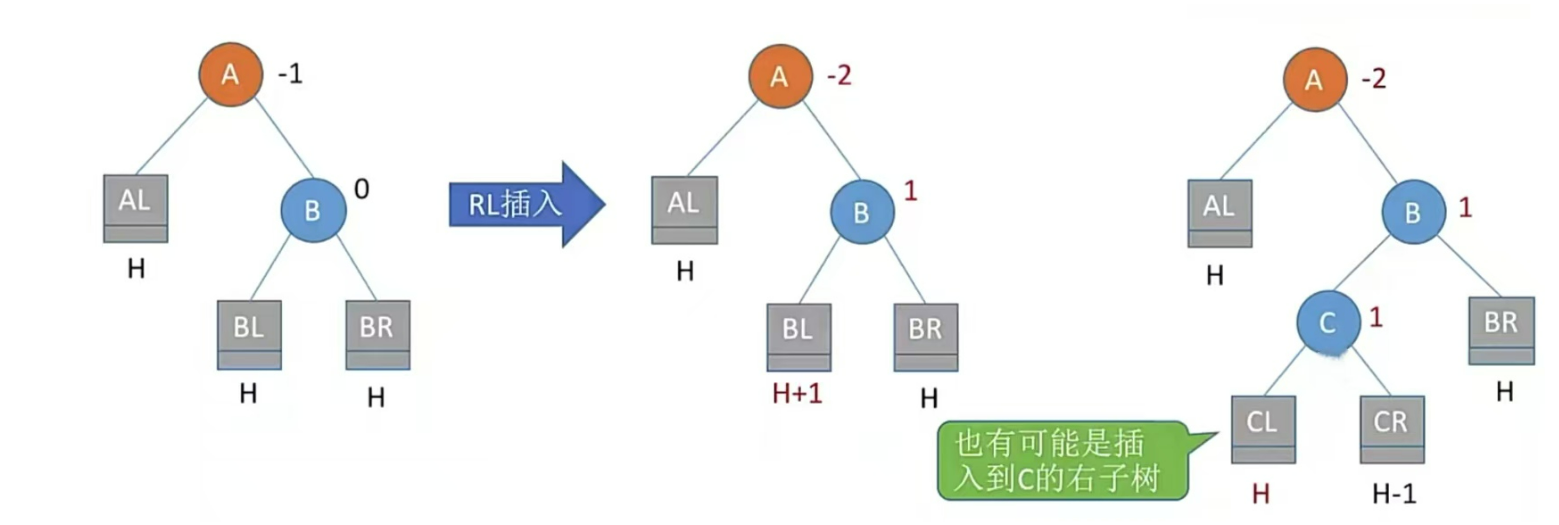
LL、RR儿子旋转一次;LR、RL儿子、孙子各旋转一次(共两次)
RR型,右孩子的右子树插入结点,即儿子右上旋转
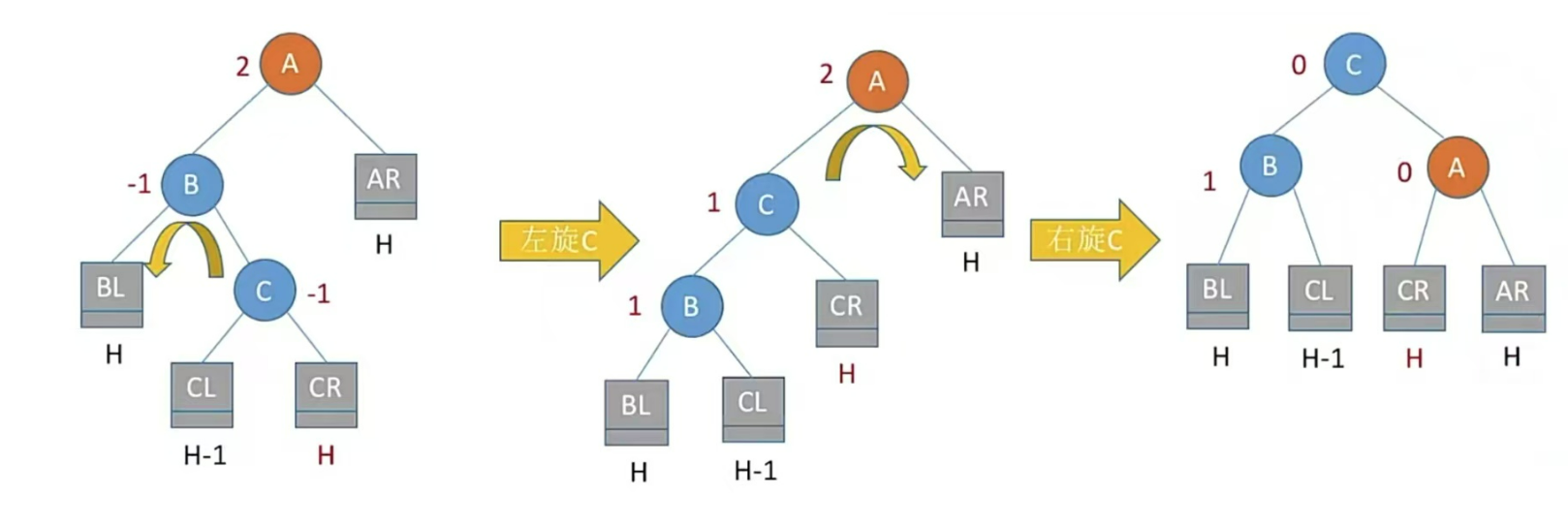
LR型,左孩子的右子树插入结点,即孙子左上旋转,儿子右上旋
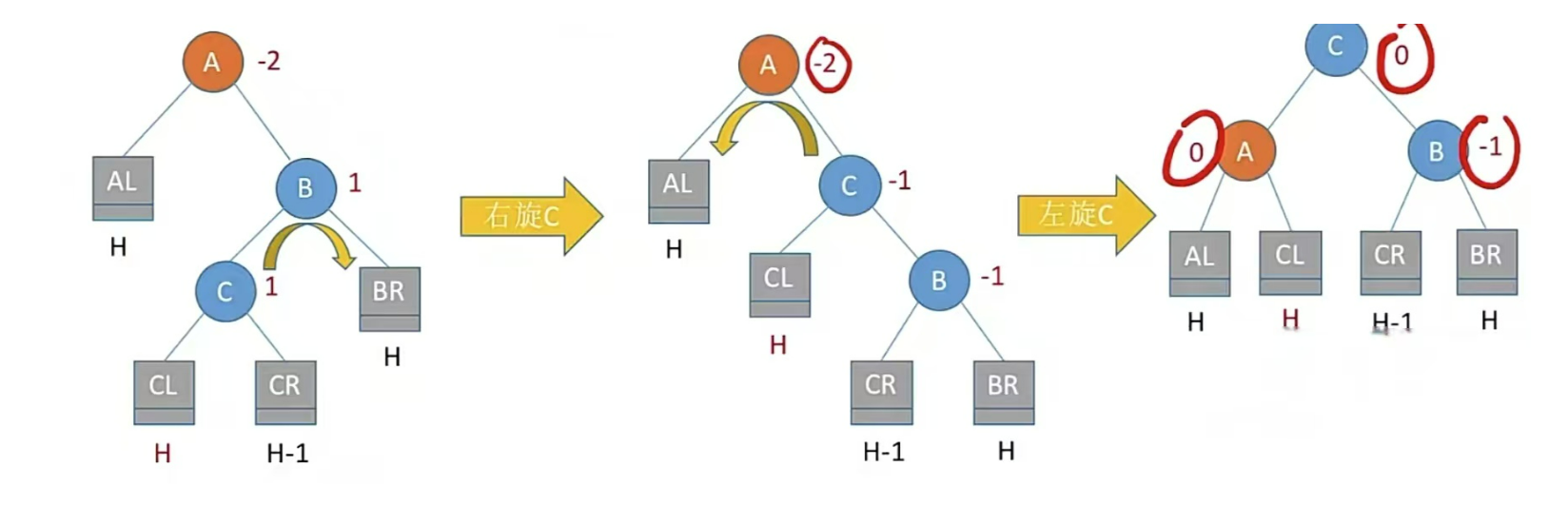
RL型,右孩子的左子树插入结点,即孙子右上旋转,儿子左上旋
注:LR和RL旋转时,新结点究竟插入C的左子树还是右子树不影响旋转结果。最终保证最底层没有H+1
2、平衡二叉树的删除
- 删除结点(方法同“二叉排序树”);
- 一路向北找到最小不平衡子树,找不到就结束;
- 找最小不平衡子树下,“个头”最高的儿子、孙子;
- 根据孙子的位置,调整平衡(LL/RR/LR/RL);
- 如果不平衡向上传导,回到第2条。
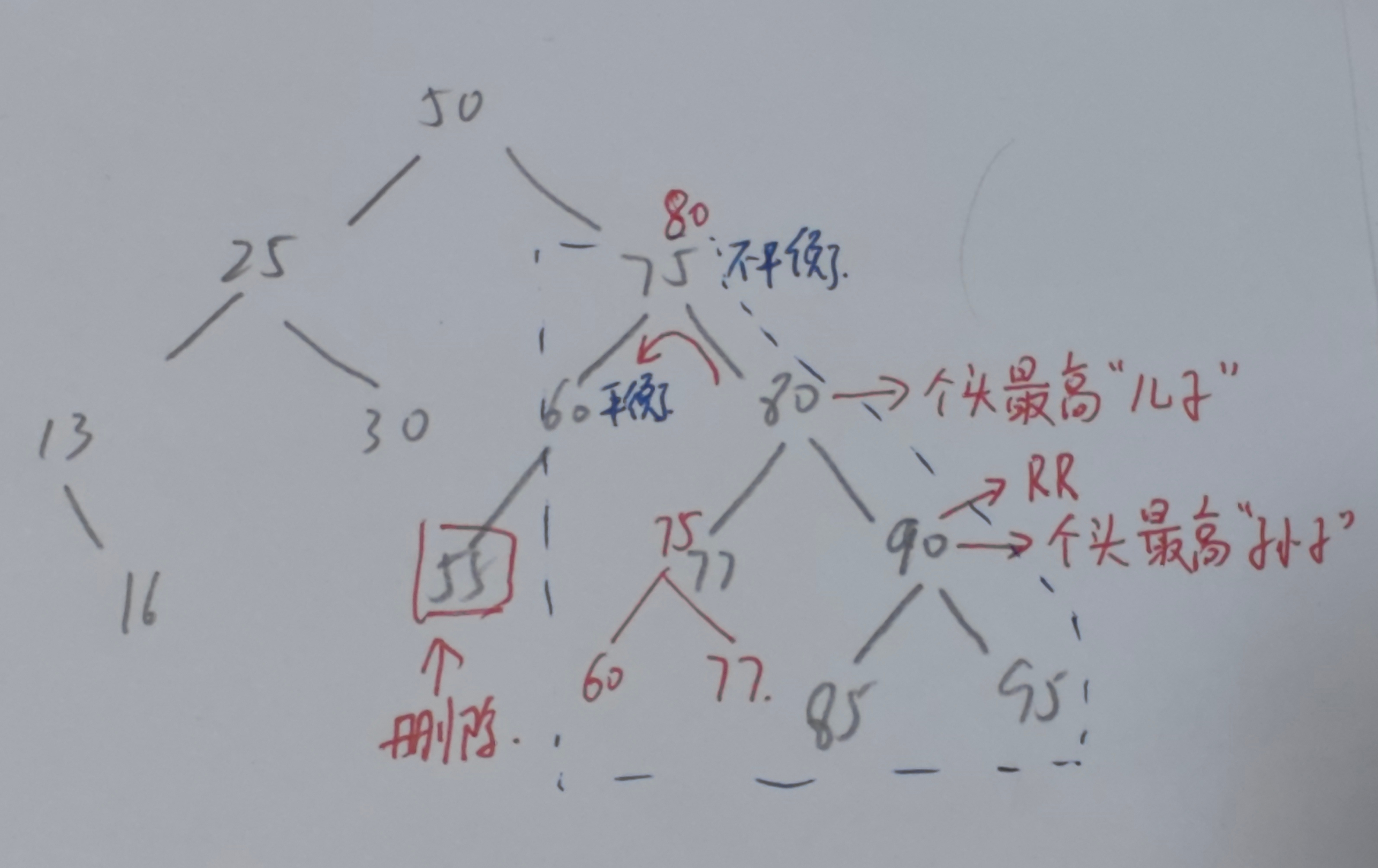
如图,红笔所示为删除后的替换
- 若要删除55,此时55为叶子结点,直接删除
- 删除之后一路向北,60仍然平衡,左右子树均为空;75不平衡,左子树高为1,右子树高为3
- 找个头最高的儿子为80,个头最高的孙子为90
- 孙子90位于爷爷80的RR型,只需要儿子进行左上旋
- 调整完毕,向北探查,发现50也平衡,调整结束
3、平衡二叉树的查找效率
假设以
表示深度为h的平衡树中含有的最少结点数,则:
有
= 0,
= 1,
= 2,并且有
+
+ 1
含有n个结点的平衡二叉树的最大深度有递推式推出,即O(
最小深度即满二叉树情况
三、红黑树
平衡二叉树(AVL):在执行插入或删除操作时,容易破坏其平衡性,因此需要频繁调整树拓扑结构。例如,当插入操作导致不平衡时,系统需要先计算平衡因子,定位最小不平衡子树(这一过程耗时较大),然后执行LL/RR/LR/RL等旋转操作来恢复平衡。
红黑树(RBT):在插入或删除操作时,通常能够保持其红黑特性,因此不需要频繁调整树结构。即使需要调整,也往往能在常数时间内完成操作。
在实际使用中,平衡二叉树适用于以查为主,很少插入/删除的应用场景;而红黑树适用于频繁插入/删除的场景,实用性更强。
1、红黑树的定义
红黑树本质上是二叉排序树
但是在插入时可以插入重复值
满足如下性质的二叉排序树即为红黑树:
- 满足 左子树结点值 ≤ 根节点值 ≤ 右子树结点值;
- 每个结点或是红色的,或是黑色的;
- 根节点是黑色的;
- 叶结点(外部结点、NULL结点、失败结点)均是黑色的;
- 不存在两个相邻的红结点(即红结点的父节点和孩子结点均是黑色);
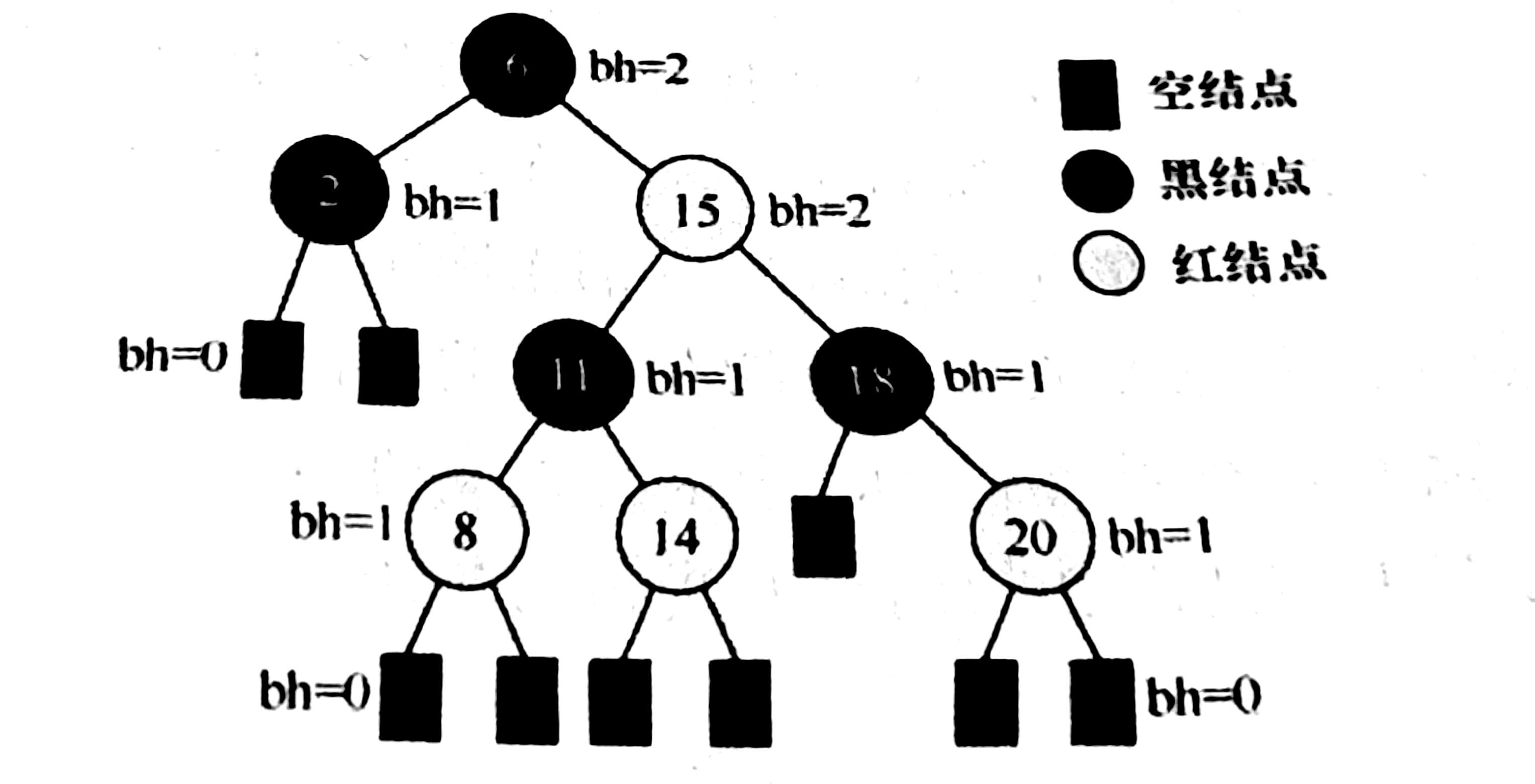
- 对每个结点,从该节点到任一叶结点的简单路径上,所含黑结点的数目相同。
左根右,根叶黑,不红红,黑路同
红黑树的结点定义
struct RBNode{ //红黑树的结点定义int key; //关键字的值RBNode* parent; //双亲结点指针RBNode* lchild; //左孩子指针RBNode* rchild; //右孩子指针int color; //结点颜色,如:可用0/1表示黑/红,也可以使用枚举型enum表示颜色 };
1、从某个结点(不包含该结点)出发,到达一个叶结点的任意一个简单路径上的黑结点总数称为该结点的黑高。(由性质6黑路同确定)
2、从根结点到叶结点的最长路径不大于最短路径的两倍。
3、根结点黑高为h,至少
内部结点, 即只有黑结点,并且满树的情况。(由性质56确定),最多是
4、由于红结点最多间隔插入黑结点,所以黑高
,于是
2、红黑树的插入
1、先查找,确定插入位置(原理同二叉排序树),插入新结点
2、新结点是 根——染为黑色
3、新结点 非根——染为红色
- 若插入新结点后依然满足红黑树定义,则插入结束
- 若插入新结点后不满足红黑树定义,需要调整,使其重新满足红黑树定义
黑叔:旋转+染色
LL型:右单旋,父换爷+染色
RR型:左单旋,父换爷+染色
LR型:左、右双旋,儿换爷+染色
RL型:右、左双旋,儿换爷+染色
红叔:染色+变新
叔父爷染色,爷变为新结点
红黑树的插入,更多注意不红红的情况,而后是根叶黑,至于左根右、黑路同,在插入的时候规则就考虑了。
四、完整代码实现
1、二叉排序树部分
#include <iostream>
#include <cstdlib>using namespace std;//二叉排序树的结点
typedef struct BSTNode{int key;struct BSTNode *lchild,*rchild;
}BSTNode, *BSTree;//二叉排序树的非递归查找算法
BSTNode *BST_Search(BSTree T, int key){while(T != NULL && key != T->key){ //若树空或等于根节点值,则结束循环if(key < T->key){ //小于,则在左子树上查找T = T->lchild; //大于,则在右子树上查找}else{T = T->rchild;}}return T;}//在二叉排序树中查找值为key的结点(递归实现)
BSTNode *BST_Search_Recursion(BSTree T, int key){if(T == NULL){return NULL; //查找失败}if(key == T->key){return T; //查找成功}else if(key < T->key){return BST_Search_Recursion(T->lchild, key);//在左子树中找}else{return BST_Search_Recursion(T->rchild, key);//在右子树中找}}//在二叉排序树中插入关键值为key的新结点(递归实现)
int BST_Insert(BSTree &T, int k){if(T == NULL){ //原树为空,新插入的结点为根节点T = (BSTree)malloc(sizeof(BSTNode)); T->key = k;T->lchild = T->rchild = NULL;return 1; //返回1,插入成功}else if(k == T->key){ //树中存在相同关键字的结点,插入失败return 0;}else if(k < T->key){ //插入到T的左子树return BST_Insert(T->lchild, k);}else{ //插入到T的右子树return BST_Insert(T->rchild, k);}
}//在二叉排序树中插入关键值为key的新结点(非递归实现)
int BST_Insert2(BSTree &T, int key) {BSTNode *newNode = (BSTNode*)malloc(sizeof(BSTNode)); // 创建新节点newNode->key = key;newNode->lchild = newNode->rchild = NULL;if (T == NULL) { // 如果树为空,直接插入新节点作为根T = newNode;return 1; // 插入成功}BSTNode *parent = NULL; // 用来记录父节点BSTNode *current = T; // 当前节点从根开始while (current != NULL) {parent = current; // 记录当前节点为父节点if (key == current->key) {free(newNode); // 如果树中已有相同的key,插入失败,释放新节点return 0; // 插入失败}else if (key < current->key) {current = current->lchild; // key 小于当前节点,移动到左子树}else {current = current->rchild; // key 大于当前节点,移动到右子树}}// 在遍历到NULL时,插入新节点if (key < parent->key) {parent->lchild = newNode; // 插入到父节点的左子树}else {parent->rchild = newNode; // 插入到父节点的右子树}return 1; // 插入成功
}//按照str[]中的关键字序列建立二叉排序树
void create_BST(BSTree &T, int str[], int n){T = NULL; //初始时T为空树int i = 0;while(i < n){ //依次将每个关键字插入到二叉排序树中BST_Insert(T, str[i]);i++;}
}// 查找二叉树中的最小结点(即直接后继)
BSTNode* findMin(BSTree T) {while (T && T->lchild) {T = T->lchild;}return T;
}// 查找二叉树中的最大结点(即直接前驱)
BSTNode* findMax(BSTree T) {while (T && T->rchild) {T = T->rchild;}return T;
}// 在二叉排序树中删除关键值为key的结点(递归实现)
BSTree BST_Delete(BSTree T, int key) {if (T == NULL) {return T; // 树为空,直接返回}// 如果key小于当前结点的key,则在左子树中删除if (key < T->key) {T->lchild = BST_Delete(T->lchild, key);}// 如果key大于当前结点的key,则在右子树中删除else if (key > T->key) {T->rchild = BST_Delete(T->rchild, key);}// 找到要删除的结点else {// 1. 删除的是叶结点if (T->lchild == NULL && T->rchild == NULL) {free(T); // 直接释放该结点return NULL; // 返回NULL,删除该结点}// 2. 删除的结点只有一个子树else if (T->lchild == NULL) { // 只有右子树BSTNode* temp = T;T = T->rchild; // 用右子树替代free(temp);}else if (T->rchild == NULL) { // 只有左子树BSTNode* temp = T;T = T->lchild; // 用左子树替代free(temp);}// 3. 删除的结点有两个子树else {// 找到当前结点的直接后继(右子树中的最小节点)BSTNode* temp = findMin(T->rchild);T->key = temp->key; // 用后继节点替代当前节点T->rchild = BST_Delete(T->rchild, temp->key); // 删除后继结点}}return T;
}// 在二叉排序树中删除关键值为key的结点(非递归实现)
BSTree BST_Delete2(BSTree T, int key) {BSTNode* parent = NULL;BSTNode* current = T;while (current != NULL && current->key != key) {parent = current;if (key < current->key) {current = current->lchild;} else {current = current->rchild;}}// 如果树中没有该结点if (current == NULL) {return T; // 不删除任何结点}// 删除的结点有两个子树if (current->lchild != NULL && current->rchild != NULL) {// 找到右子树中的最小结点作为后继BSTNode* successorParent = current;BSTNode* successor = current->rchild;while (successor->lchild != NULL) {successorParent = successor;successor = successor->lchild;}// 替换当前结点的值为后继结点的值current->key = successor->key;// 删除后继结点if (successorParent->lchild == successor) {successorParent->lchild = successor->rchild;} else {successorParent->rchild = successor->rchild;}free(successor);}// 删除的结点没有左子树,只有右子树else if (current->lchild == NULL) {if (parent == NULL) { // 如果删除的是根结点T = current->rchild;} else if (parent->lchild == current) {parent->lchild = current->rchild;} else {parent->rchild = current->rchild;}free(current);}// 删除的结点没有右子树,只有左子树else if (current->rchild == NULL) {if (parent == NULL) { // 如果删除的是根结点T = current->lchild;} else if (parent->lchild == current) {parent->lchild = current->lchild;} else {parent->rchild = current->lchild;}free(current);}return T;
}void inorderTraversal(BSTree T) {if (T != NULL) {inorderTraversal(T->lchild);cout << T->key << " ";inorderTraversal(T->rchild);}
}int main() {BSTree T = NULL;int keys[] = {50, 30, 70, 20, 40, 60, 80};int n = sizeof(keys) / sizeof(keys[0]);// 创建二叉排序树create_BST(T, keys, n);// 打印树的中序遍历cout << "中序遍历输出:";inorderTraversal(T);cout << endl;// 查找某个元素int searchKey = 40;BSTNode* result = BST_Search(T, searchKey);if (result != NULL) {cout << "找到节点:" << result->key << endl;} else {cout << "未找到节点" << endl;}// 递归查找result = BST_Search_Recursion(T, searchKey);if (result != NULL) {cout << "递归查找找到节点:" << result->key << endl;} else {cout << "递归查找未找到节点" << endl;}// 删除一个结点并展示中序遍历int deleteKey = 70;cout << "删除结点 " << deleteKey << endl;T = BST_Delete(T, deleteKey);inorderTraversal(T);cout << endl;return 0;
}

题目,纯手工注入教程)
![[硬件电路-140]:模拟电路 - 信号处理电路 - 锁定放大器概述、工作原理、常见芯片、管脚定义](http://pic.xiahunao.cn/[硬件电路-140]:模拟电路 - 信号处理电路 - 锁定放大器概述、工作原理、常见芯片、管脚定义)
)
 深度解析与实践)







![C语言-指针[指针数组和数组指针]](http://pic.xiahunao.cn/C语言-指针[指针数组和数组指针])





免安装中文版)
