RAFT:让语言模型更聪明地用文档答题
作者注: 本文旨在面向零基础读者介绍 UC Berkeley 提出的 RAFT(Retrieval-Augmented Fine-Tuning)方法。它是一种训练语言模型的新方式,让模型更好地利用“外部知识”——比如文档、网页或数据库回答问题。
- 无需背景知识,本文将带你从“开卷考试”的类比出发,逐步理解它的核心理念与实践效果。

文章目录
- RAFT:让语言模型更聪明地用文档答题
- 一、背景:大模型真的理解文档了吗?
- 二、RAFT 是什么?
- 三、一场模拟“开卷考试”
- 四、RAFT 的训练方法详解
- 1. 训练输入
- 2. 数据构造比例(P%)
- 五、推理链与引用机制
- 六、效果评估与实验结果
- 七、重要发现:干扰文档不全是坏事
一、背景:大模型真的理解文档了吗?
如今的大语言模型(LLM),如 GPT、Claude、LLaMA 等,已具备强大的通用能力。然而,它们在处理 特定领域、基于文档回答问题 的任务时,表现常常不尽如人意。
为什么?因为它们:
- 要么完全靠记忆作答;
- 要么虽然可以看文档,但从未学会如何使用它们。
换句话说,它们面对“开卷考试”时,不知道怎么查资料。
二、RAFT 是什么?
RAFT,全称 Retrieval-Augmented Fine-Tuning(检索增强微调),是一种专门针对特定领域问答任务的训练方法。核心思想是:
在训练阶段,给模型配上一些 相关文档 + 干扰文档,让它学会辨别、引用和推理,从而提升真实场景下的答题能力。
RAFT 属于“后训练”方法,适用于已有预训练模型基础上,通过额外训练,适配特定文档集合。
三、一场模拟“开卷考试”

RAFT 使用了一个非常易懂的比喻——“开卷考试”,来说明不同方法之间的差别:
| 方法类型 | 比喻 | 特点 |
|---|---|---|
| 闭卷模型 | 考试时不能看书 | 模型只靠预训练知识,答题效果有限 |
| 传统 RAG 方法 | 考试时翻书但没准备 | 模型能看文档,但不懂如何使用,效果不稳定 |
| RAFT 方法 | 考前练习开卷考试 | 模型在训练阶段就学会了用文档答题,表现更好 |
RAFT 的“准备”包括:
- 学会辨认哪些文档是“有用的”
- 学会引用文档内容来回答问题
- 学会写出有逻辑的、带有推理链(Chain-of-Thought) 的回答
四、RAFT 的训练方法详解
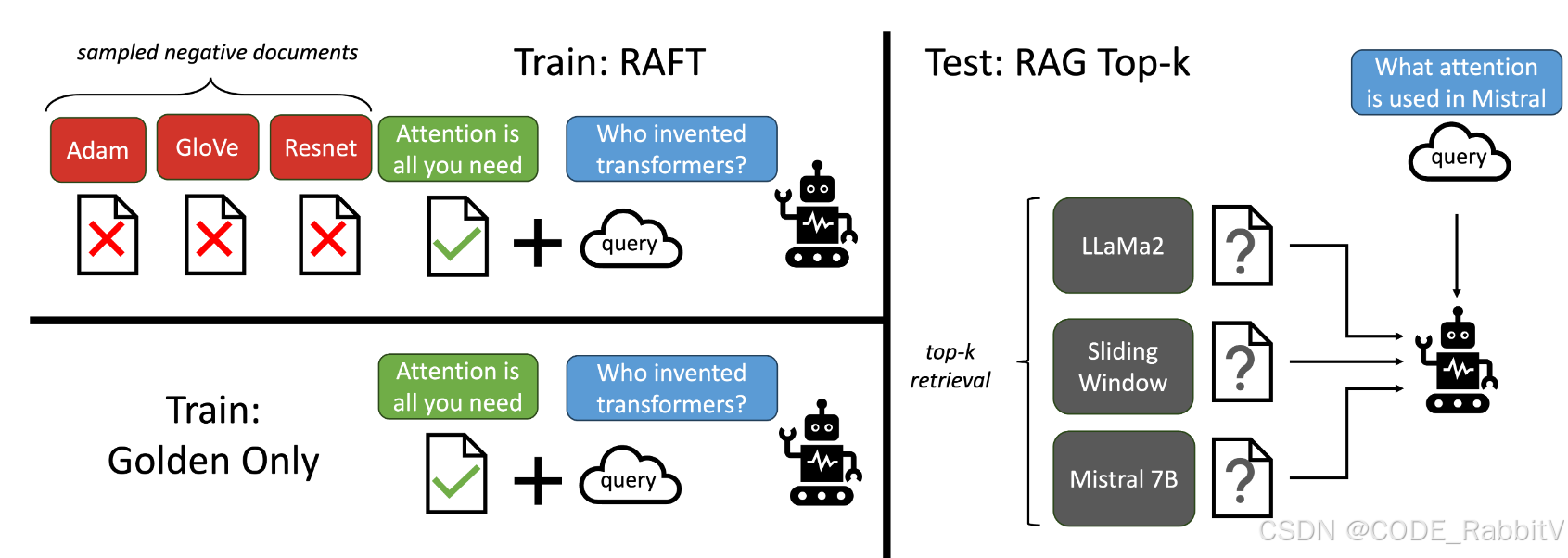
RAFT 的训练数据设计如下:
1. 训练输入
每条训练样本包括:
- 一个问题(Question, Q)
- 一组文档(Documents, Dₖ)
- 1~N 篇“黄金文档”(含有正确信息)
- 若干“干扰文档”(Distractors)
- 一个推理链式答案(Answer, A*)
2. 数据构造比例(P%)
RAFT 有意识地控制黄金文档的出现比例:
- P% 的样本包含黄金文档
- (1-P)% 的样本仅包含干扰项
这样做的目的:
- 一方面训练模型学会从文档中“找答案”
- 另一方面,保留对问题本身的理解能力(即使没有黄金文档,也能作答)
五、推理链与引用机制
RAFT 的答案不是简简单单的一句话,而是具备结构化的推理过程:
- 引用内容用
##begin_quote##...##end_quote##包裹 - 这样训练出来的模型能写出更有逻辑、来源清晰的答案

六、效果评估与实验结果
RAFT 在多个基准任务上进行了测试,包括:
- PubMed QA(医学问答)
- Hotpot QA(多跳问答)
- Gorilla APIBench(API 使用理解)
结果如下:
| 模型版本 | Hotpot QA 分数 | HuggingFace 分数 |
|---|---|---|
| LLaMA2 + RAG | 0.03 | 26.43 |
| Domain-Specific + RAG | 4.41 | 42.59 |
| RAFT(Ours) | 35.28 | 74.00 |
我们可以看出 RAFT 相比现有方法,优势非常明显。
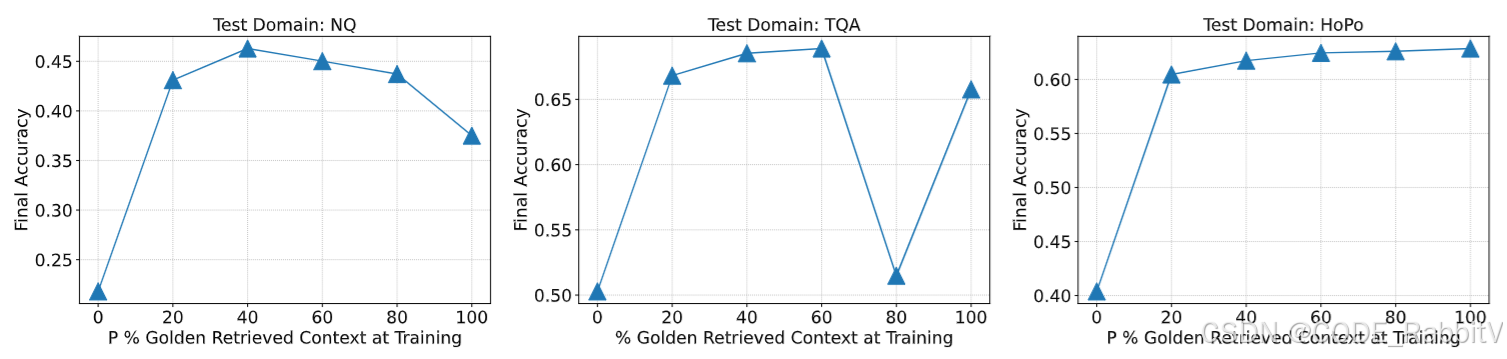
七、重要发现:干扰文档不全是坏事
训练中适度加入干扰文档,反而能提升模型的鲁棒性——帮助它识别无关内容而不过度“记忆”答案。
黄金文档比例 P% 对模型性能的影响 (原文图 5):
如果你正面临“模型不会读文档”的问题,RAFT 是一个值得尝试的方案 – 但是训练代价比较大 (个人级不推荐!)
资源链接:
- 论文原文:RAFT: Adapting Language Model to Domain Specific RAG
- 代码仓库(包含数据和模型训练脚本)










![[驱动开发篇] Can通信进阶 --- CanFD 的三次采样](http://pic.xiahunao.cn/[驱动开发篇] Can通信进阶 --- CanFD 的三次采样)


)


)

