分布式中间件弹性扩容与rebalance冲平衡
176_如果宕机的数据节点事后再次重启会发生什么事情?
某个之前某个宕机的数据节点DataNode-A又重启后,肯定会再次注册,并进行全量上报的流程,此时,就会导致DataNode-A上的文件副本,实际上在整个DataNode集群中存了3份
177_接收数据节点存储上报的时候发现副本冗余生成删除任务
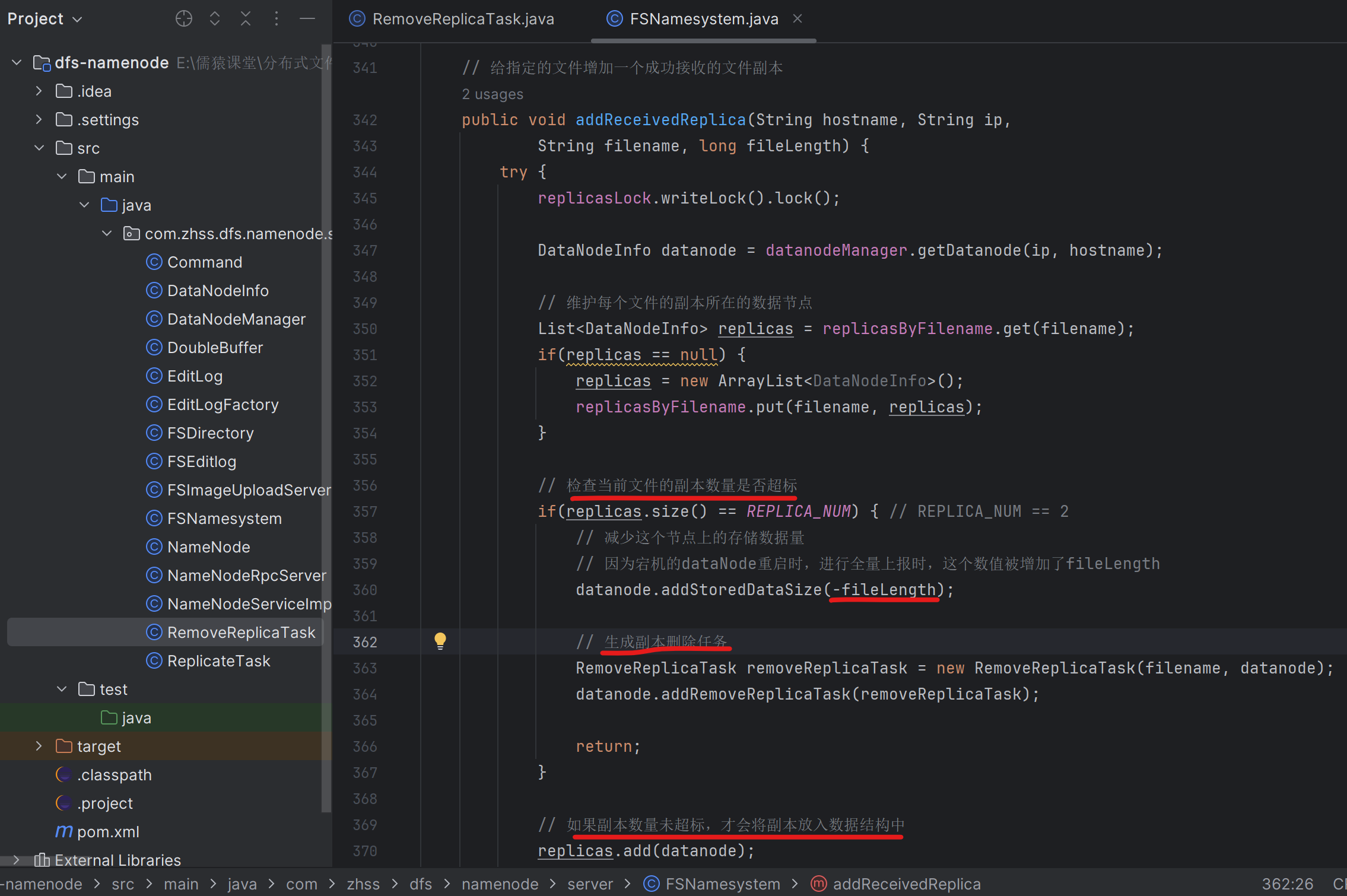
178_将冗余副本的删除任务下发给对应的数据节点
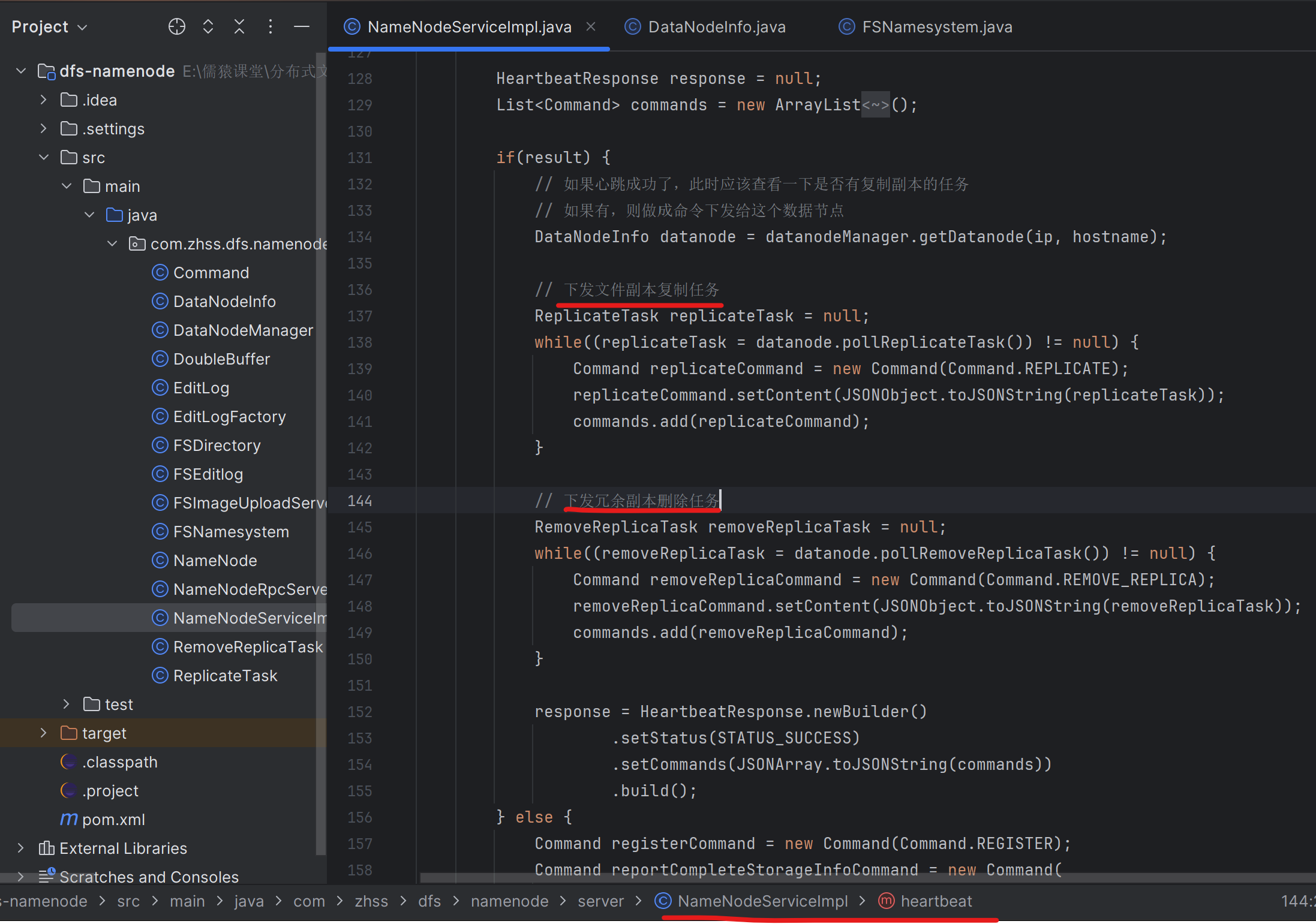
179_在数据节点上删除磁盘上的冗余图片副本
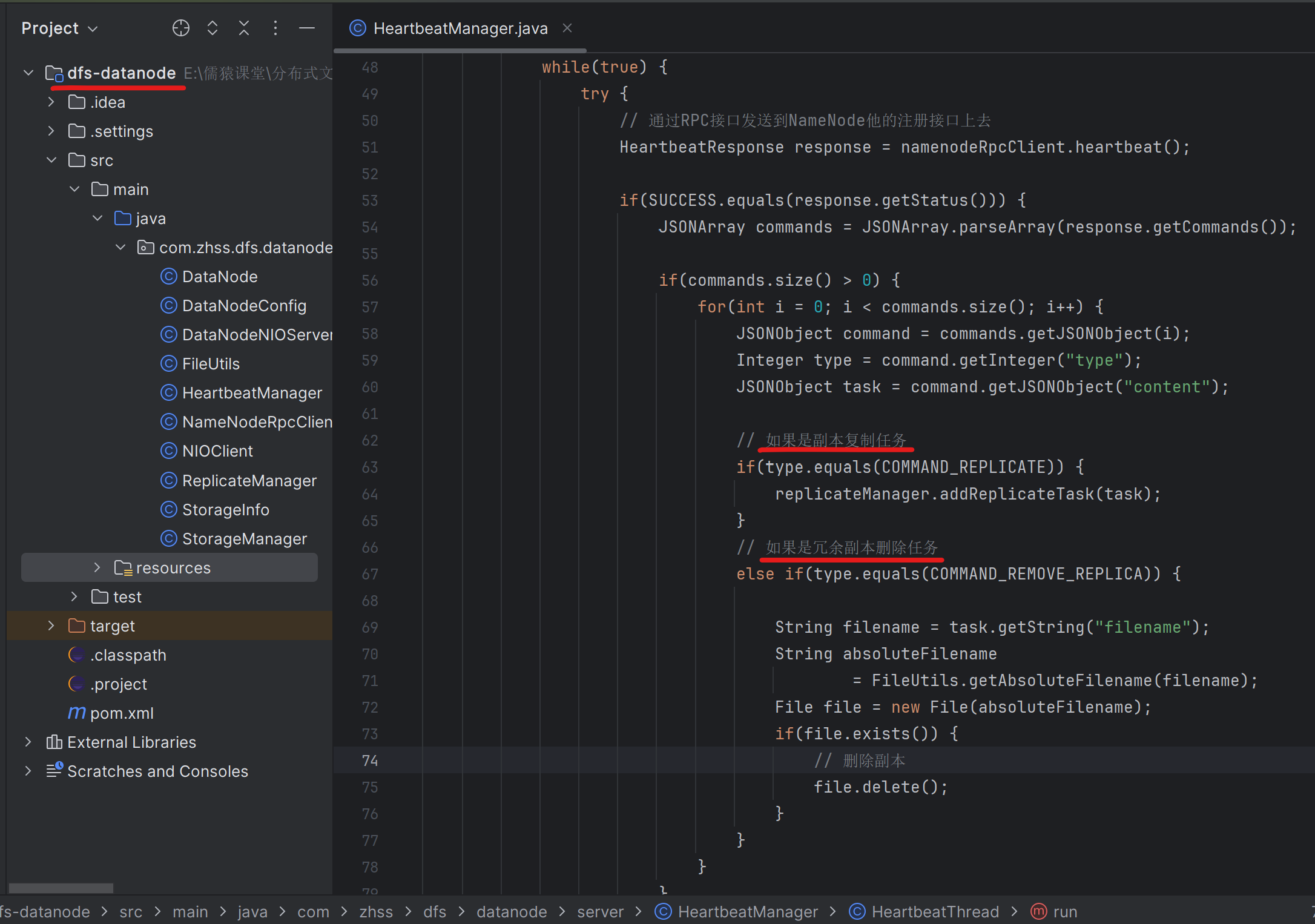
180_测试数据节点挂掉之后副本能否正常复制到其他节点
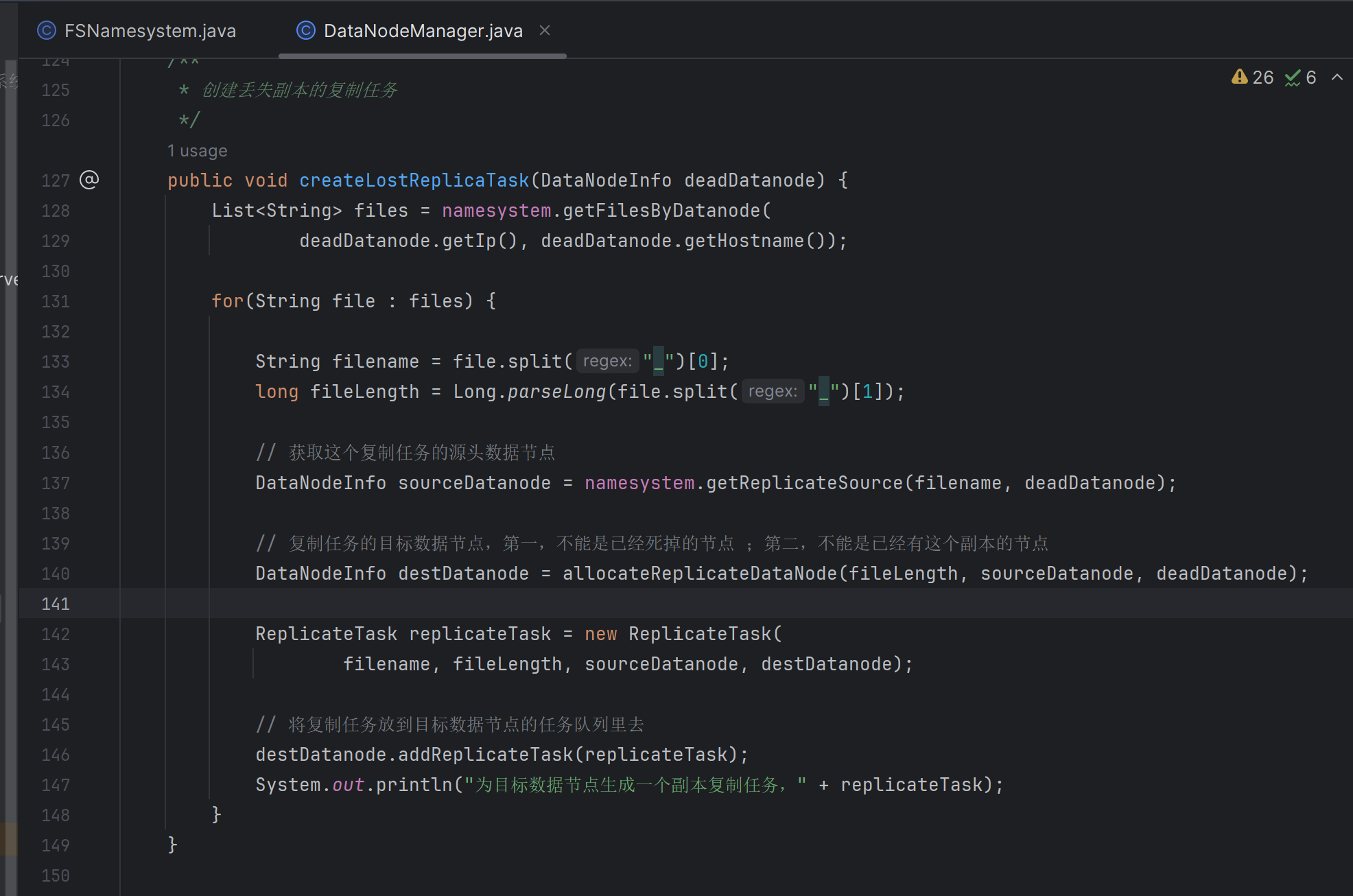
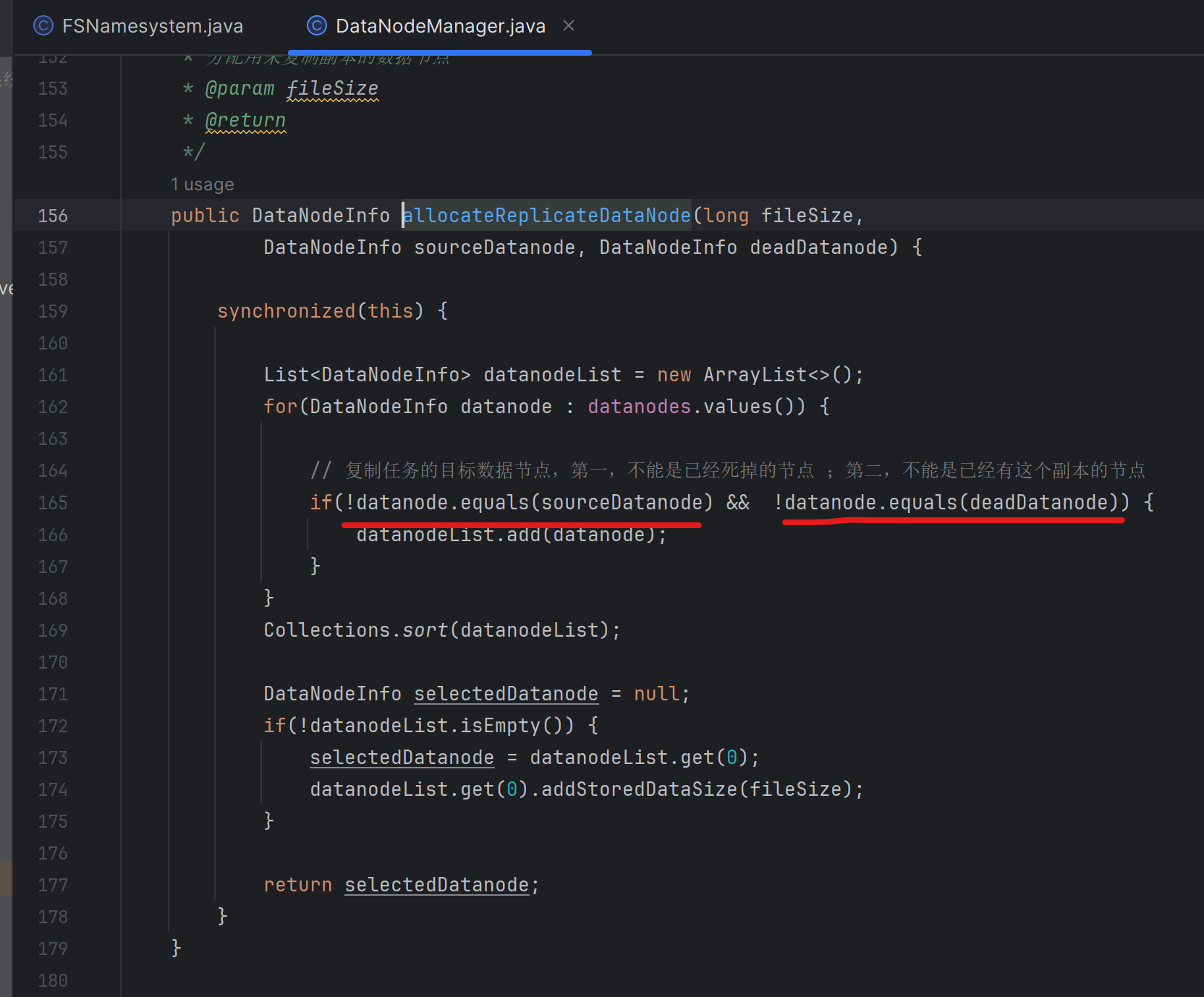
复制任务的目标数据节点
- 第一,不能是已经死掉的节点
- 第二,不能是已经有这个副本的节点
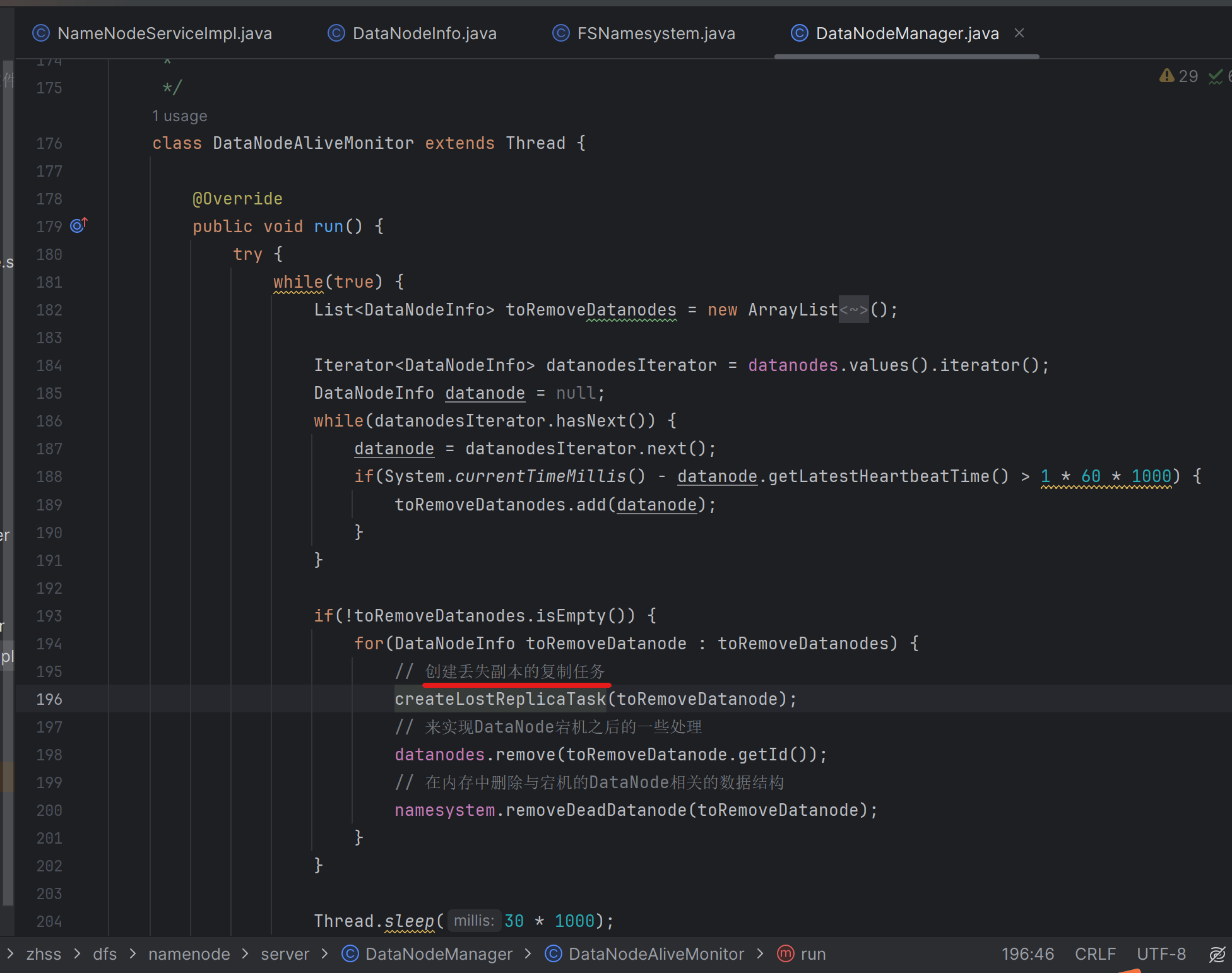
181_测试宕机的数据节点再次重启时能否正常删除冗余副本
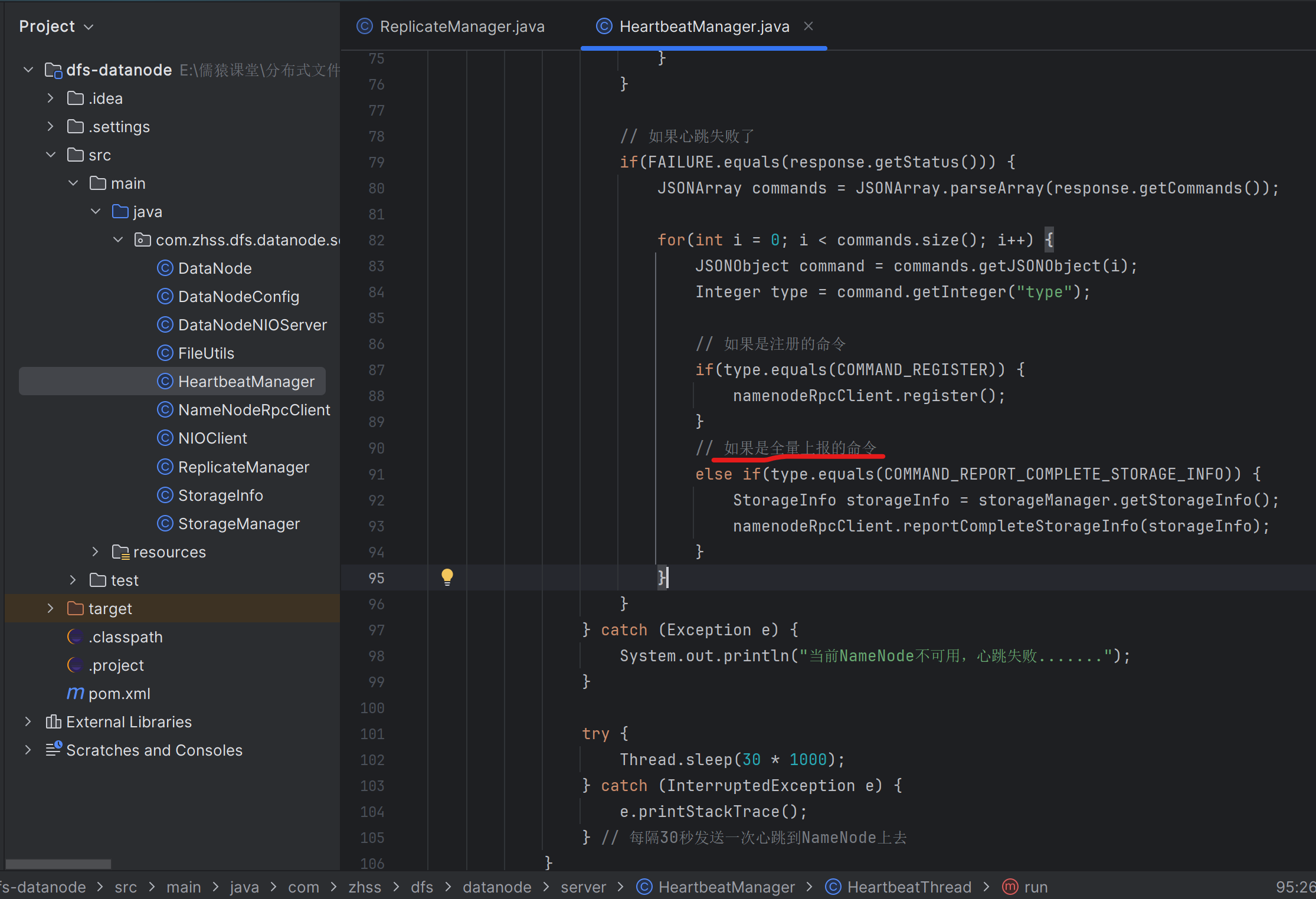
如果宕机的DataNode-A上有25万个文件副本,DataNode-A宕机以后,这25万个文件副本会打散复制到别的DataNode上去
此时,如果宕机的DataNode-A重新启动,那么它就会向NameNode进行全量上报,把25万个文件副本都全量上报到NameNode上去。NameNode就会生成25万个冗余副本删除任务RemoveReplicaTask,并放入NameNode内存中管理的DataNode-A对应的DataNodeInfo中的删除任务阻塞队列removeReplicaTaskQueue中去
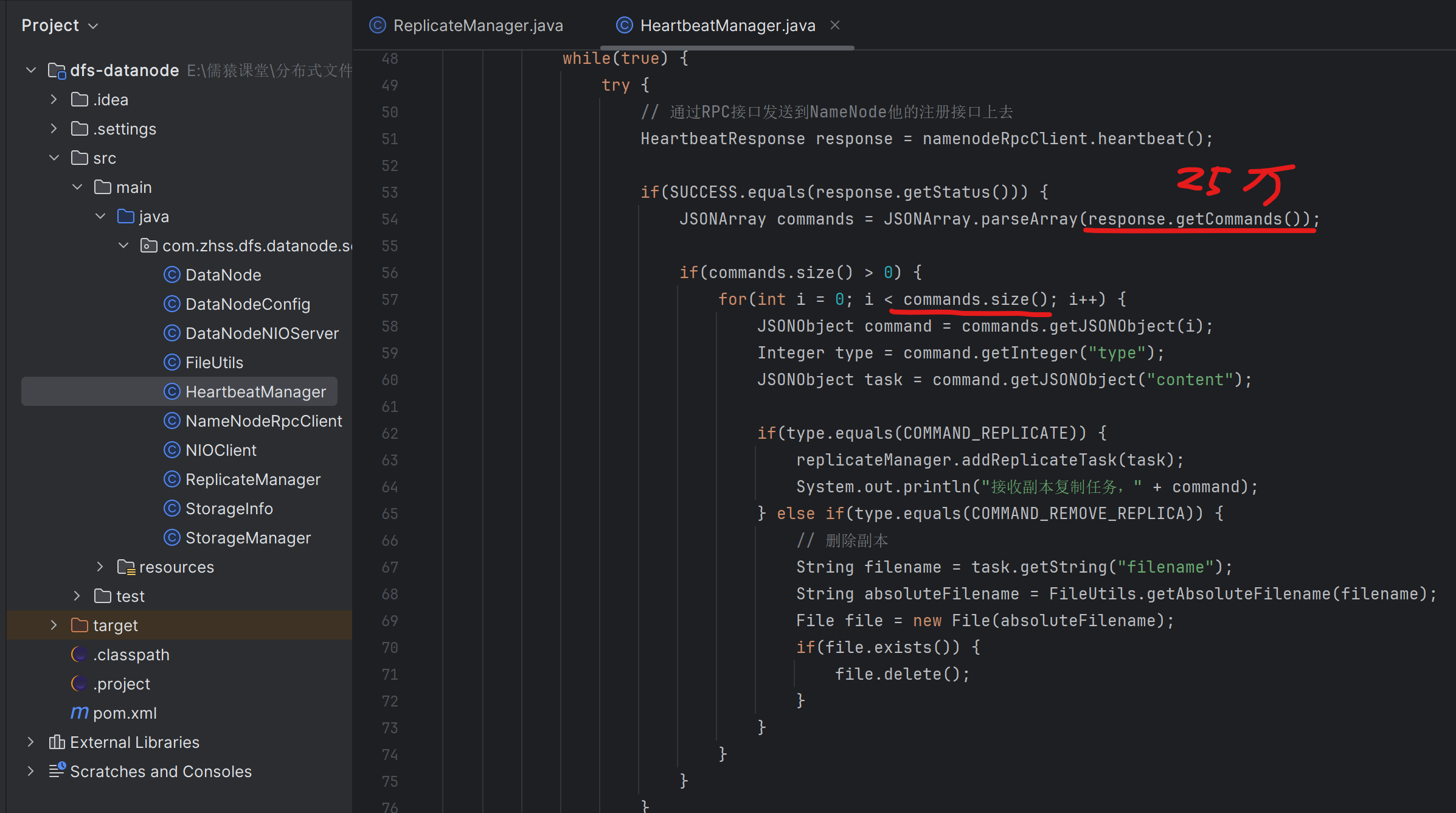
当宕机的DataNode-A重新启动后的下一次心跳发送到NameNode时,NameNode就会把这25w个RemoveReplicaTask都下发给DataNode-A,DataNode-A拿到这25w个RemoveReplicaTask后,就会开始执行它们,对应的也就是删除DataNode-A本地的25万个文件副本。对应的实现代码如上
182_在上传文件的时候发现数据节点宕机该如何进行处理?
最最典型的一个客户端上传的容错机制,就是感知到网络故障之后,就得去进行一些容错的处理
解决方案就是:
客户端找某个DataNode上传文件如果失败,那么客户端就将宕机的DataNode传给NameNode,让NameNode重新分配除了宕机的DataNode以外的另一个DataNode,客户端再次进行上传
183_在客户端的代码中找找如何感知到上传过程中的网络故障?
这里做的比较粗,就是最外层的catch到Exception,就认为是上传过程中出现了网络故障。就不管它是在建立短连接的过程中就建立失败,还是连接建立成功后,channel.write(file)执行失败抛出了异常
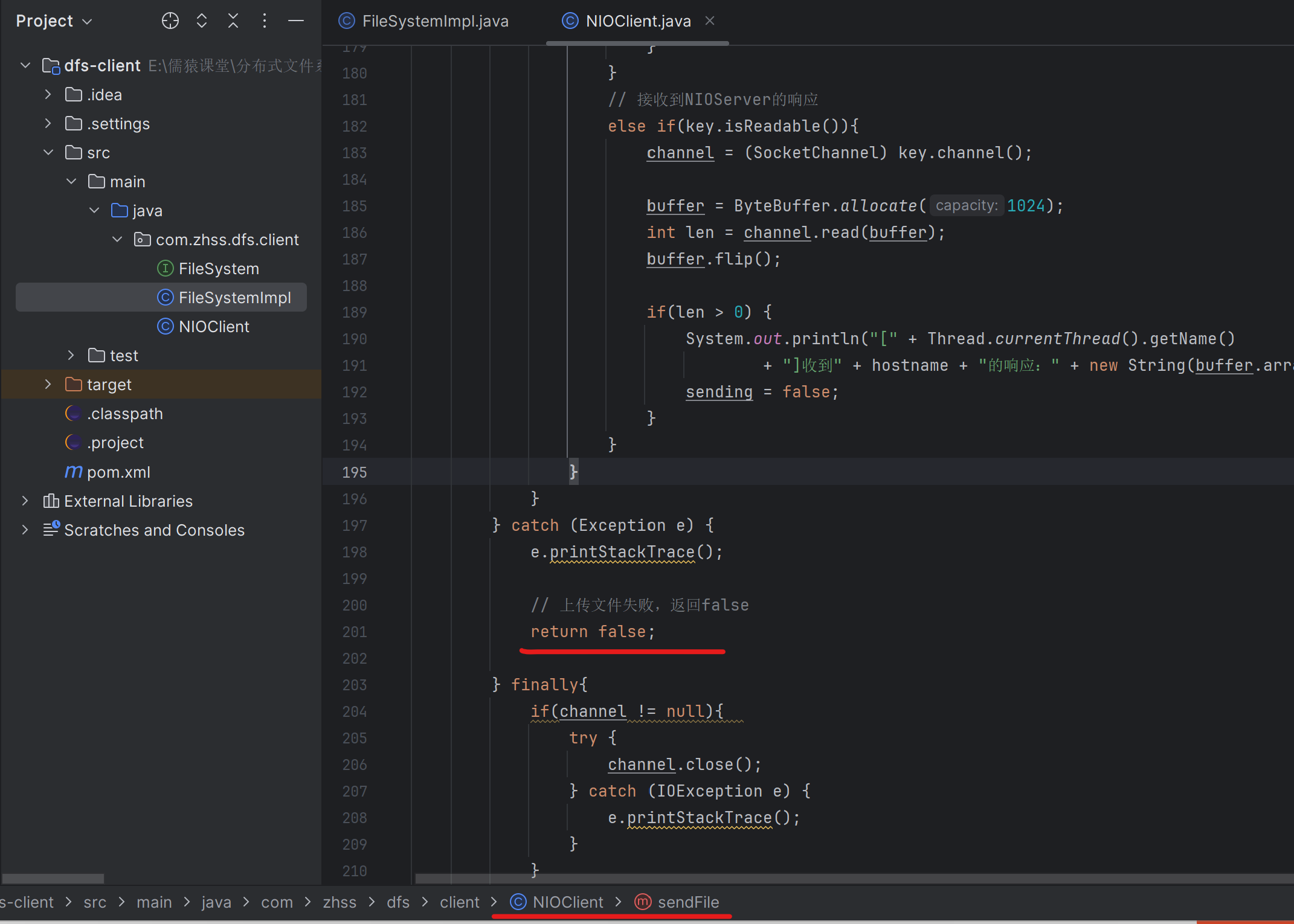
184_改造代码实现发现网络故障时重新分配一个数据节点
通过这种方式,实现客户端的容错、故障的转移,如果一个数据节点有故障,在客户端是可以进行容错的,客户端在找一个数据节点上传失败,就会找NameNode重新分配一个DataNode并重新进行上传
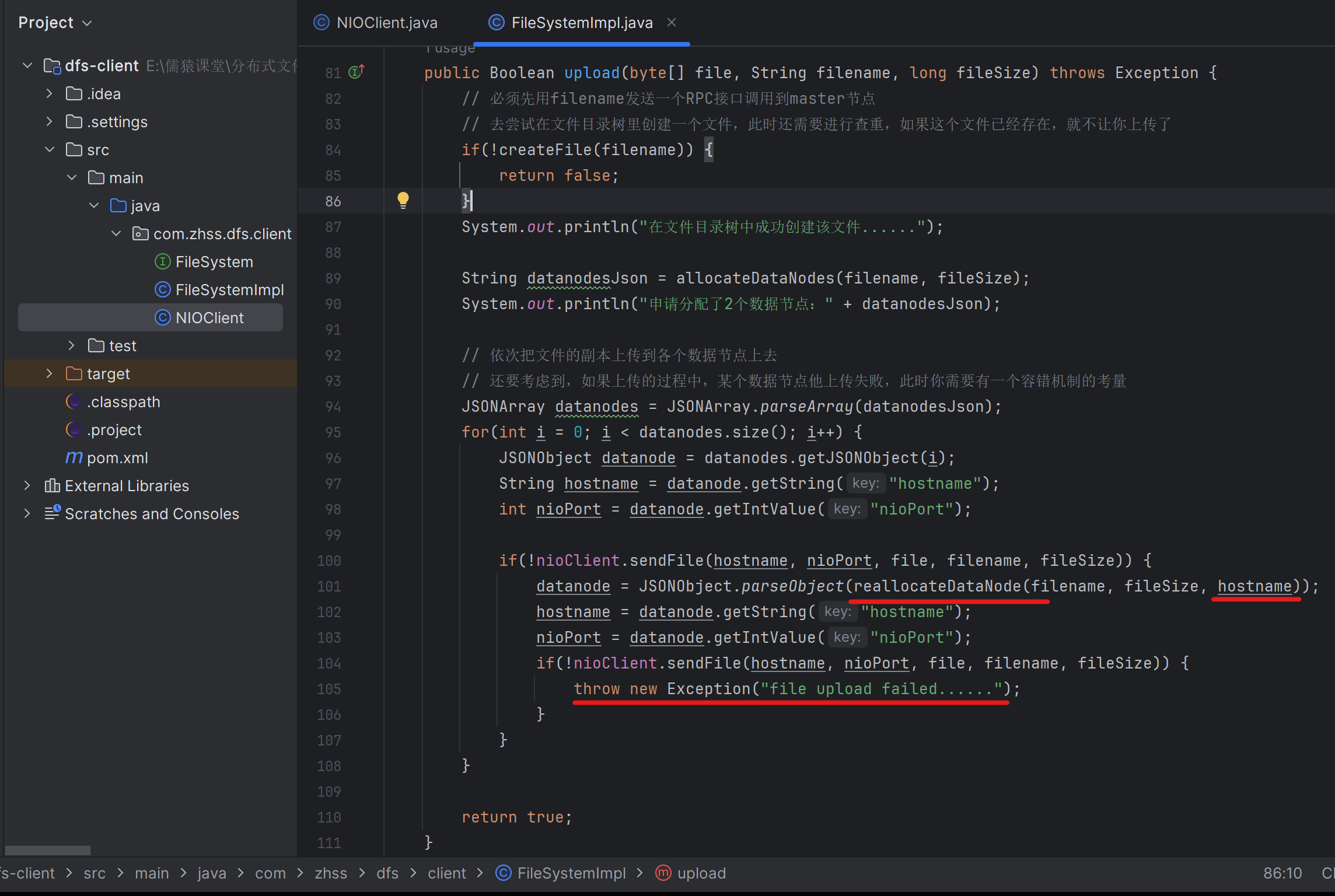
给上传文件的方法,变成了有返回值的,上传成功返回true,失败返回false
185_定义一个新接口:重新分配数据节点以及排除故障节点
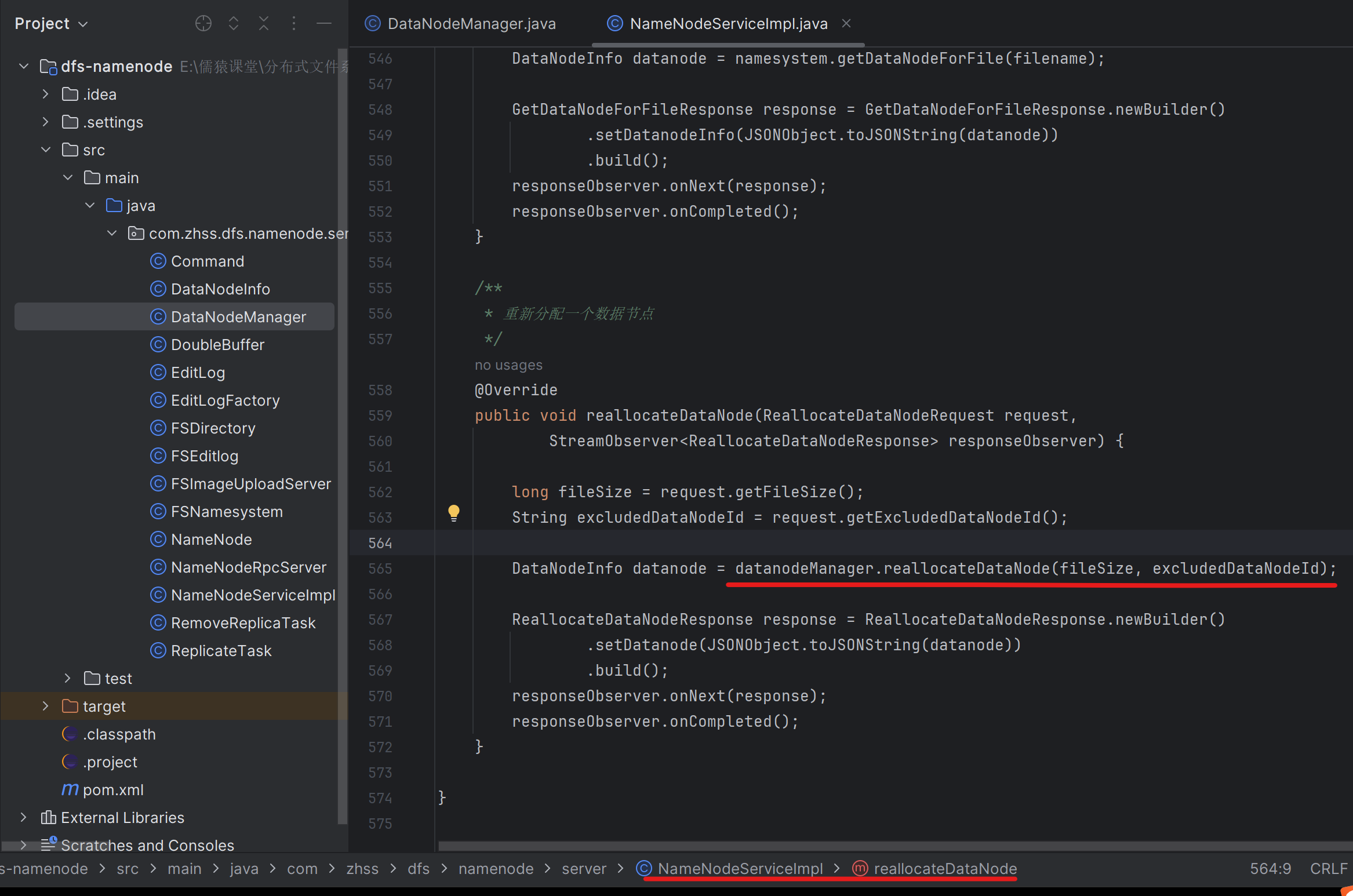
186_实现重新分配数据节点这个接口的代码业务逻辑
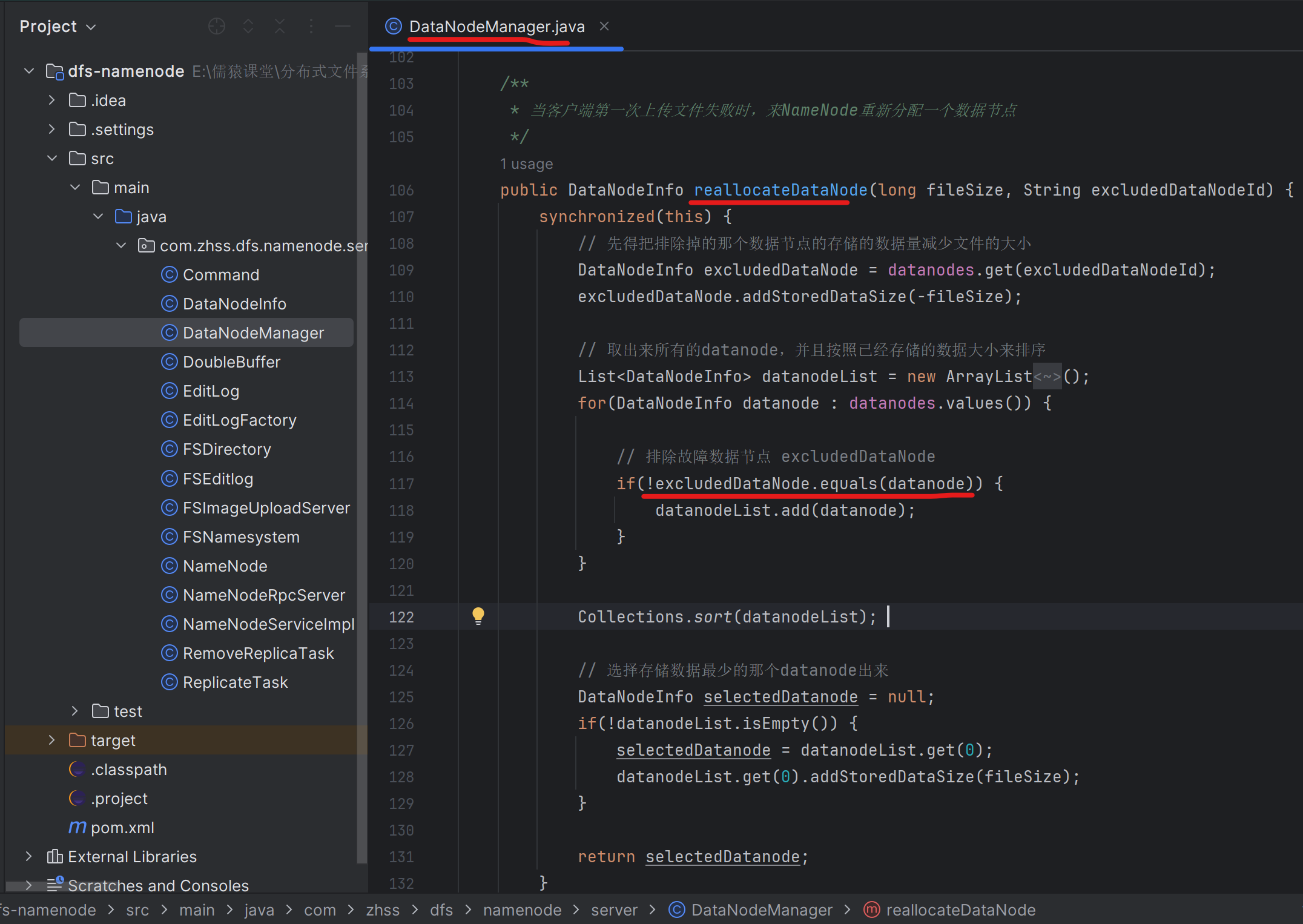
187_在下载文件的时候发现数据节点宕机该如何进行处理?
如果某个数据节点挂了,某个数据节点刚挂,NameNode还没有感知到它挂了,就把它分配给了客户端,客户端此时对着这个挂了个数据节点上传文件/下载文件,肯定就会失败的
188_在客户端的代码中找找如何感知到下载过程中的网络故障?
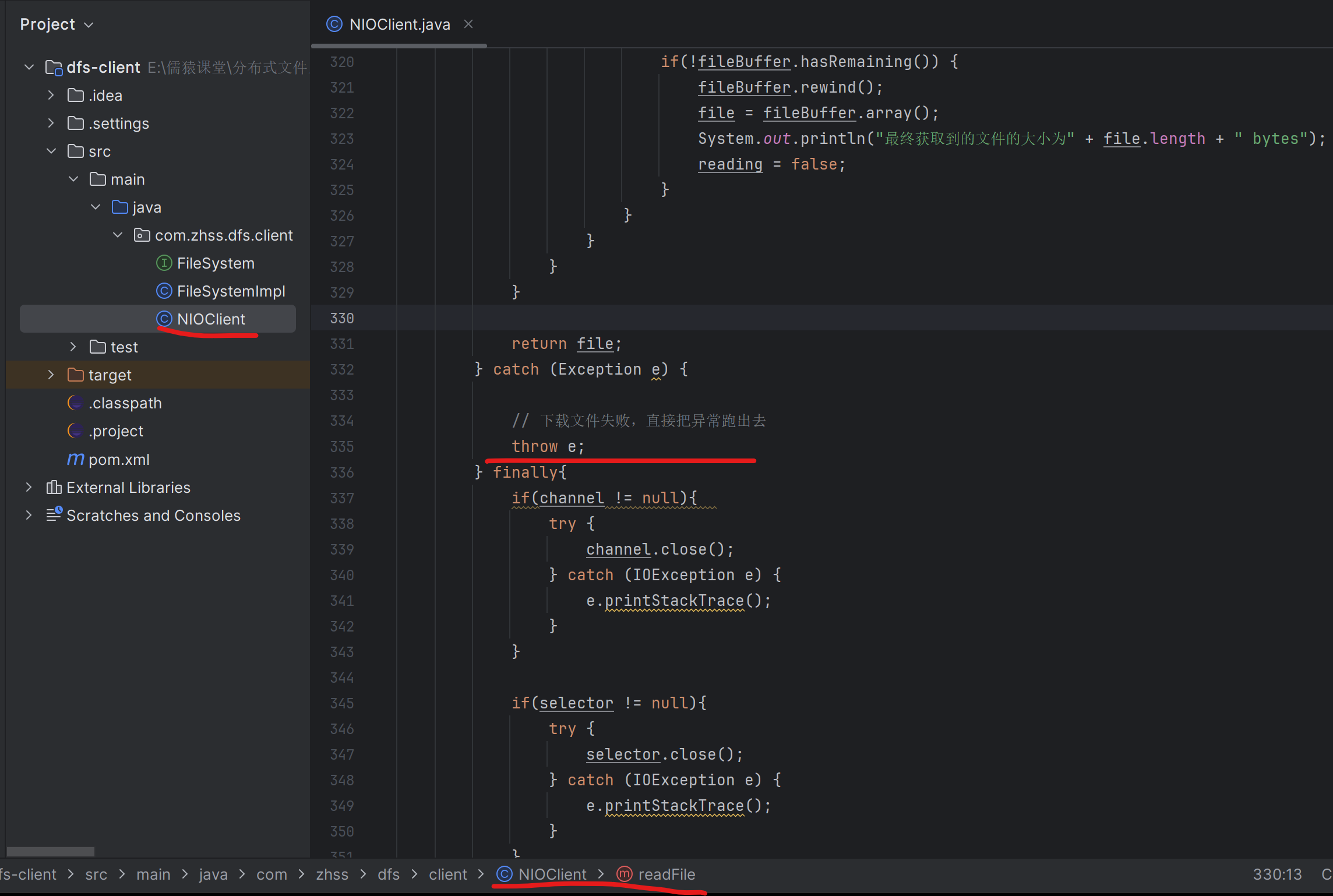
189_改造代码实现下载文件发现网络故障重新申请一个数据节点
客户端往第一个数据节点下载文件失败时,需要找NameNode节点重新分配一个除了这个下载失败的节点以外的别的数据节点
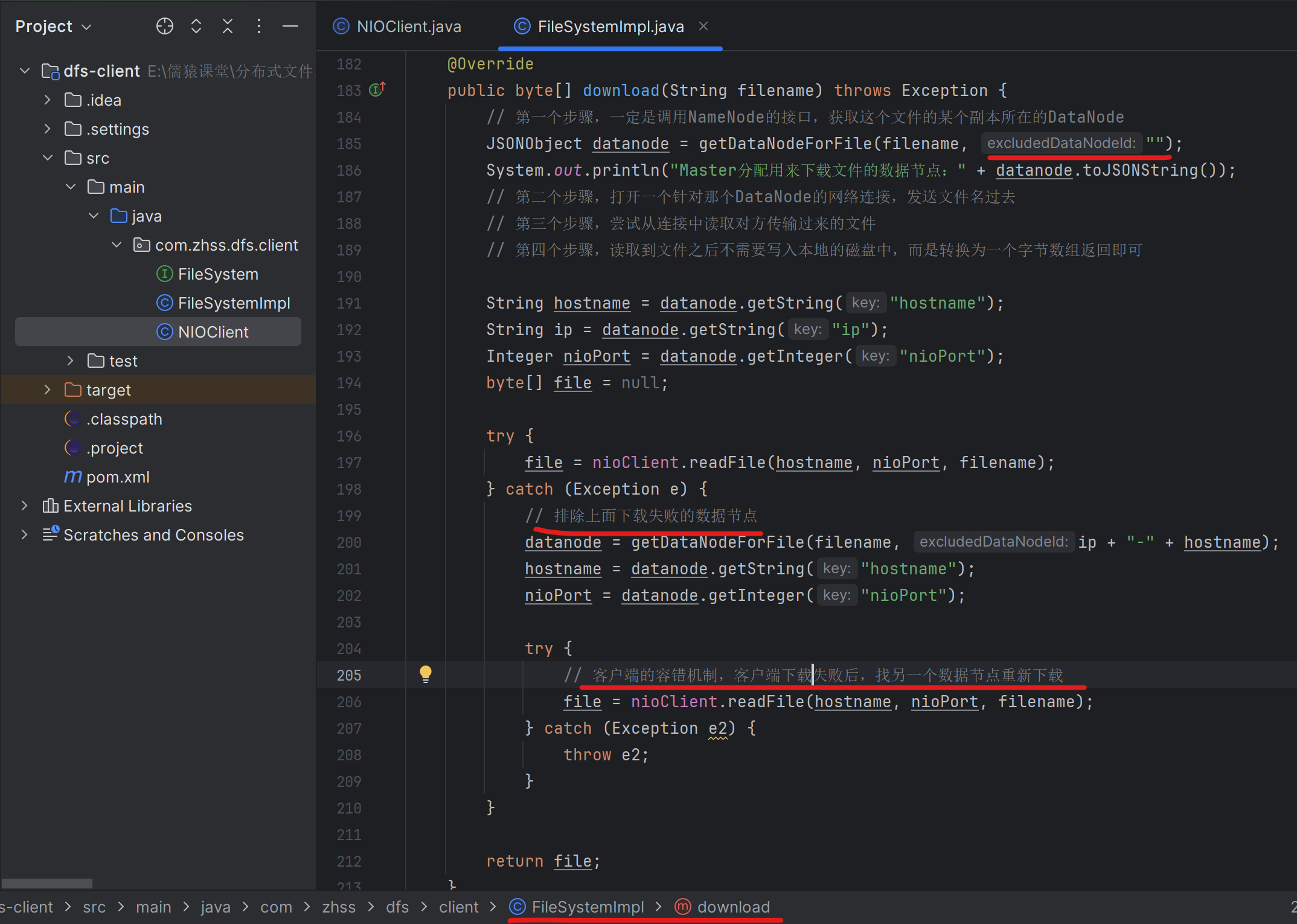
190_改造已有的旧接口:为下载文件重新分配一个数据节点
191_重写为下载文件分配数据节点的接口:加入排除故障节点逻辑
将前面的getDatanodeForFile()改成了下面的chooseDataNodeFromReplicas(),就是从几台有fileName文件对应的副本的数据节点中,随机的选择出一台数据节点,且这个选出的数据节点还不能是第一次下载失败的数据节点
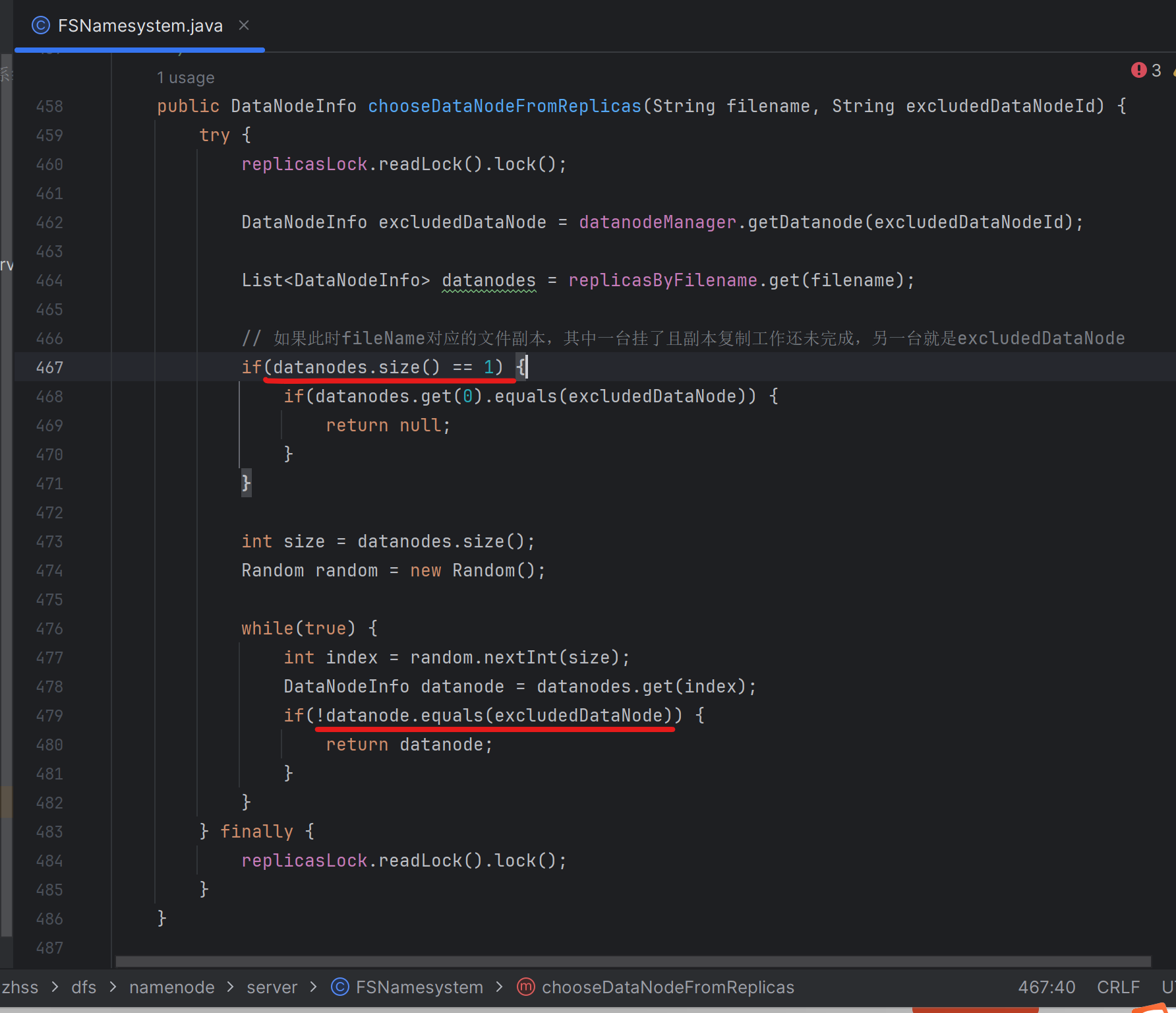
第479行,就是在排除第一次下载文件失败的数据节点
192_海量数据存储:分布式存储、多副本冗余以及高可用架构
海量数据的存储,主要针对的各种小文件、小图片。海量数据的存储,用一台机器肯定是不行,所以首先做的就是分布式存储架构
多副本冗余,高可用架构(任何一台机器宕机数据不会丢,上传、下载的过程中失败,可以换数据节点重试)
一边要多思考里面的架构设计思想,FastDFS和TFS。FastDFS是一个国产的开源项目,c语言开发的,中小型公司在使用,一般在分布式文件存储的场景中,都会采用FastDFS来使用,最大缺点就是c语言开发,我们没办法阅读里面的源码,出问题的时候极坑,全部c异常,Java工程师没有能力维护FastDFS集群的。我们需要有发现问题,改源码、编译、打包重新部署的能力
我们可以百度一下“FastDFS架构原理”,分布式存储、副本冗余、高可用架构,跟我们设计的这套架构类似的
TFS,淘宝内部开发的分布式文件系统,主要是针对淘宝上面,大量的店铺中的商品的小图片,4kb~400mb之间,分布式存储,元数据管理机制,副本冗余,高可用架构,和我们的架构也是类似的。但是,和我们的有一点不同的是,很多小图片会被合并为一个大文件来存储,每个文件都会有一个对应的索引文件。网上关于FastDFS和TFS的资料也不会太多
我们这边参考了HDFS的架构,Hadoop分成了三大系统:Hadoop分布式文件系统,分布式计算系统,分布式资源调度系统,尤其是里面的元数据管理架构完全参考了HDFS
193_分布式文件系统的可伸缩架构值的是什么以及如何设计
六大架构
分布式存储架构:
容错架构:
高可用架构:除了NameNode需要依赖zk还没做
可伸缩架构:可以随时增加或下线机器
高性能架构:让上传和下载速度更快
高并发架构:大量客户端同时连接过来,进行上传下载
可伸缩架构,对于集群而言,就是可以保证加机器去里面,或者是下线机器都可以实现
加一台机器,你接下来如何做,假设已经有4台机器,每台机器上的磁盘空间都快满了,这个是很常见的场景,大数据的同学玩HDFS的时候就会有这种情况,已有的几台机器的磁盘空间都满了,无法写入新的数据了
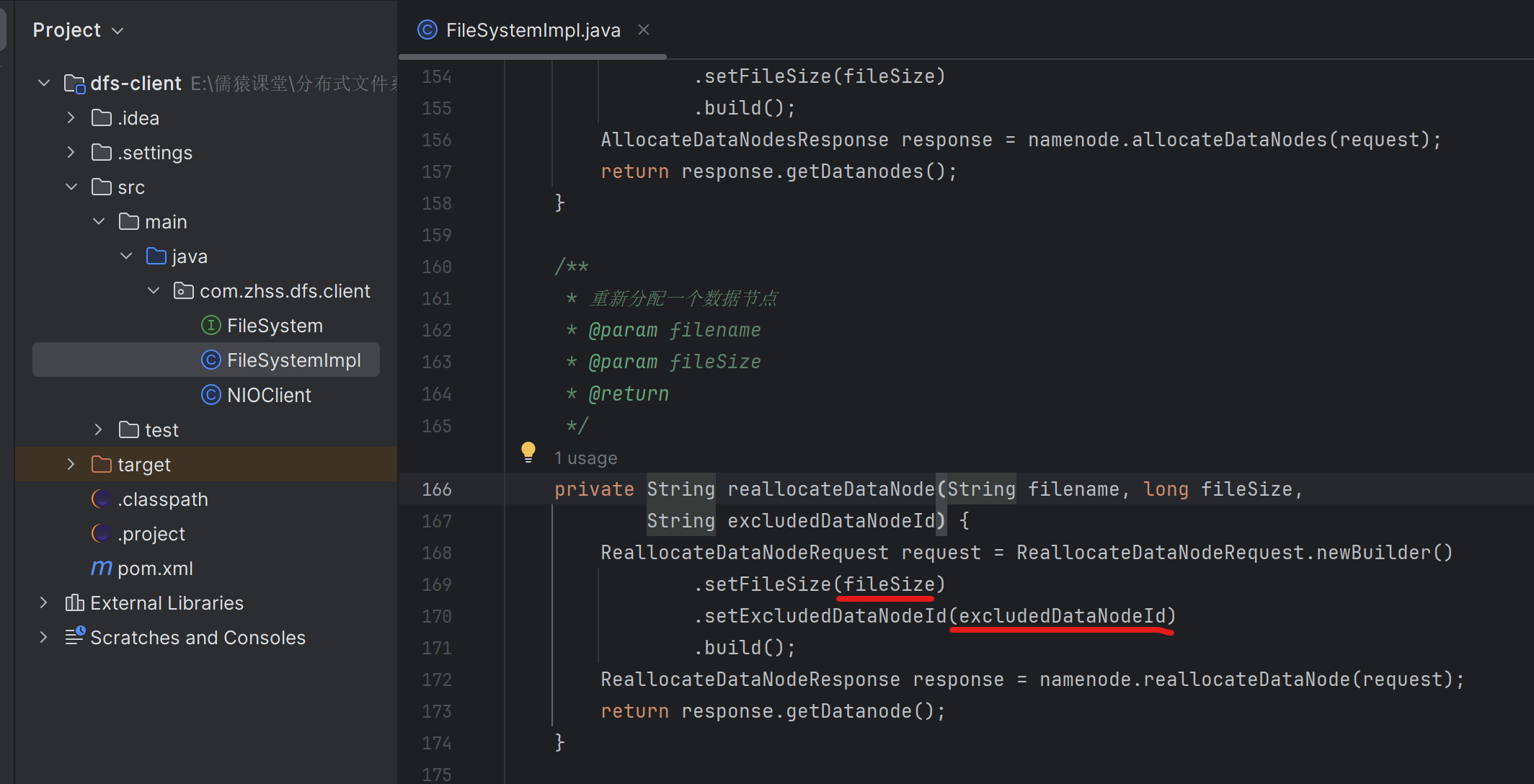
首先你得保证接下来要优先往最空的这台机器去写入数据,接下来在后台应该启动一大堆的定时任务,要慢慢的把快满的4台机器上的数据逐步逐步的迁移到空的机器上去,缓解已有4台机器的存储压力,可以让空机器放更多的数据
下线机器,有某一台机器不需要了,关闭DataNode,把机器干掉。这种情况就可以看做是属于机器的宕机,NameNode感知到以后,会自动的去进行副本的复制,保证数据不丢失
194_上线新机器之后是否会自动优先往里面写入数据?
如果每次扩容,一般来说针对我们的这个系统,要么不扩容,要么扩容都是>=2台机器起步来进行扩容,每次扩容2台机器,那么在这里一排序,就会优先往2台空的机器里写入数据,就可以立马缓解住已有的4台机器磁盘快写满的压力
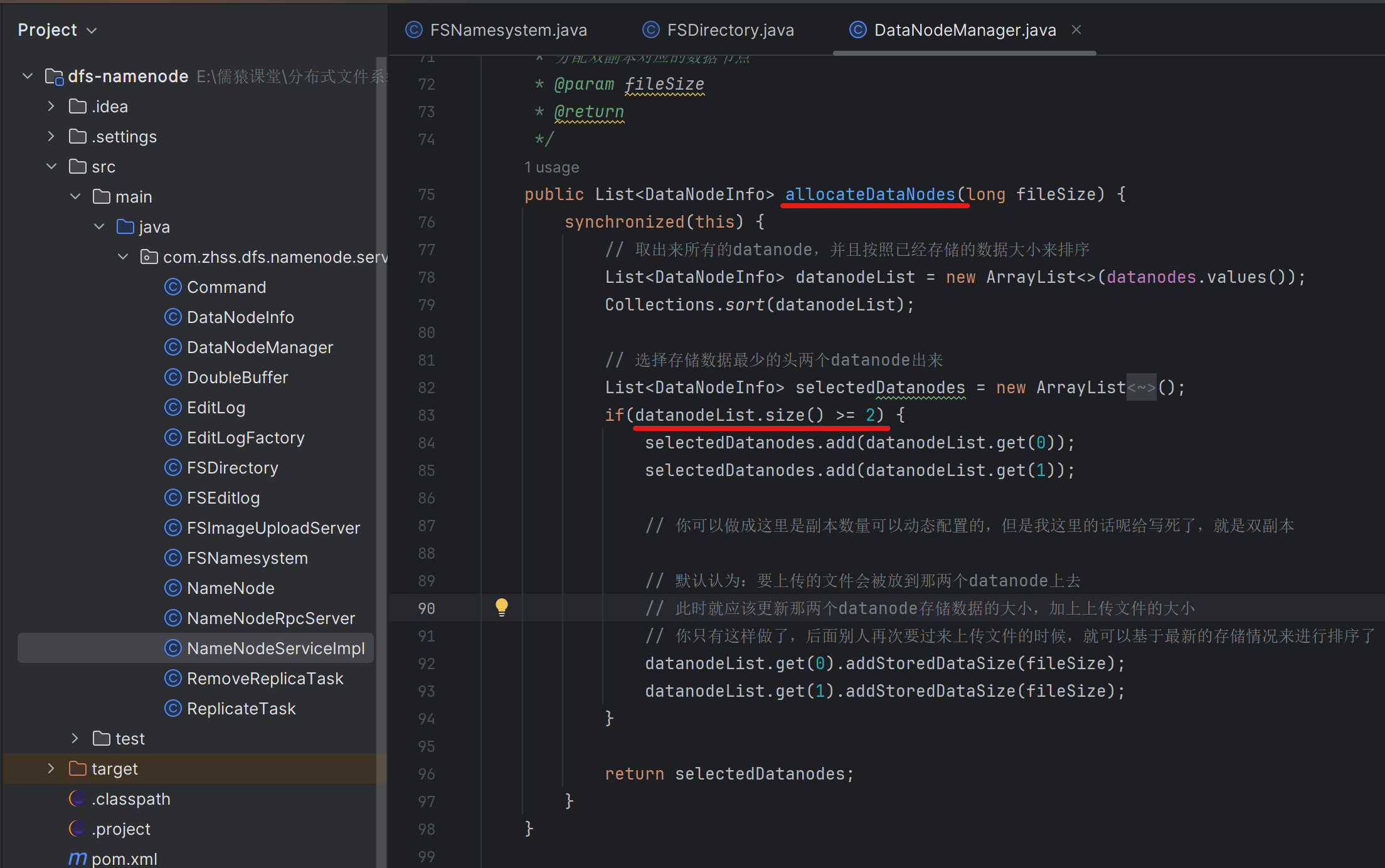
195_到底什么时候应该从磁盘快满的机器缓慢迁移数据出去
假设每台机器是100GB存储空间:
机器01:90GB
机器02:90GB
机器03:90GB
机器04:90GB
新加入两台机器:
机器05:0GB
机器06:0GB
把所有的机器全部加起来,算一个平均数,一共360GB,每台平均60GB
(机器01、机器02、机器03、机器04) ->(机器05、机器06)
举个例子:机器01 -> 机器05,迁移30GB,首先要确定这30G具体包含对应的是哪些文件。需要生成两种任务,第一种任务是复制任务。对于机器05而言有复制任务,他需要从机器01复制指定的文件过来
第二种就是删除任务。对机器01而言就有删除任务。每隔一段时间,你都可以让他去进行一次全量存储的汇报,把这个节点原先的各种存储信息重新刷新一遍,同时在全量存储汇报的时候,就可以检查一下每个图片的副本数量,如果超出了2个,就生成删除任务也可以
196_定义一个新接口:手动触发集群数据的rebalance
上线了新的几台机器,立马就应该执行一个命令
我们可以提供一个用python编写的脚本,在脚本里基于python调用gRPC提供的接口,调用到Master上去,执行某个命令触发rebalance,gRPC本来就是支持多语言的
同理,shutdown()之类的接口,我们也可以写Python脚本,来手动调用shutdown,来优雅关闭
199_实现rebalance的核心算法:集群存储资源重平衡算法逻辑
假设现在
机器01:90GB
机器02:90GB
机器03:90GB
机器04:90GB
机器05:0GB
机器06:0GB
平均就是应该每台60G
/*** 这个组件,就是负责管理集群里的所有的datanode的*/
public class DataNodeManager {/*** 为重平衡去创建副本复制的任务*/public void createReBalanceTasks() {// 冲平衡时,加大锁synchronized(this) {long totalStoredDataSize = 0;for(DataNodeInfo datanode : datanodes.values()) {totalStoredDataSize += datanode.getStoredDataSize();}// 计算集群节点存储数据的平均值long averageStoredDataSize = totalStoredDataSize / datanodes.size();// 将集群中的节点区分为两类:迁出节点和迁入节点List<DataNodeInfo> sourceDataNodes = new ArrayList<>();List<DataNodeInfo> destDataNodes = new ArrayList<>();for(DataNodeInfo datanode : datanodes.values()) {// 迁出节点if(datanode.getStoredDataSize() > averageStoredDataSize) {sourceDataNodes.add(datanode);}// 迁入节点if(datanode.getStoredDataSize() < averageStoredDataSize) {destDataNodes.add(datanode);}}// 为迁入节点生成复制的任务,为迁出节点生成删除的任务// 在这里生成的删除任务统一放到24小时之后延迟调度执行,咱们可以实现一个延迟调度执行的线程List<RemoveReplicaTask> removeReplicaTasks = new ArrayList<>();for(DataNodeInfo sourceDatanode : sourceDataNodes) {// 当前源数据节点,需要迁移的数据大小long toRemoveDataSize = sourceDatanode.getStoredDataSize() - averageStoredDataSize;for(DataNodeInfo destDatanode : destDataNodes) {// 直接将sourceDatanode要迁移的数据,一次性放到一台destDatanode机器就可以了if(destDatanode.getStoredDataSize() + toRemoveDataSize <= averageStoredDataSize) {createReBalanceTasks(sourceDatanode, destDatanode, removeReplicaTasks, toRemoveDataSize);break;}// 只能把部分数据放到这台机器上去else if(destDatanode.getStoredDataSize() < averageStoredDataSize) {// sourceDatanode要迁移的数据,最多只能迁移maxRemoveDataSize的数据,到destDatanode上去// 比如sourceDatanode要迁移的数据一共30G,但是当前的destDatanode最多只能接收15G数据long maxRemoveDataSize = averageStoredDataSize - destDatanode.getStoredDataSize();long removedDataSize = createReBalanceTasks(sourceDatanode, destDatanode, removeReplicaTasks, maxRemoveDataSize);// 将本sourceDatanode节点,待迁移的量toRemoveDataSize,减去本次迁移的量removedDataSizetoRemoveDataSize -= removedDataSize;} }}// 交给一个延迟线程去24小时之后执行删除副本的任务// 保证开始执行删除任务时,前面的复制任务已经全部执行完毕了new DelayRemoveReplicaThread(removeReplicaTasks).start(); } }private long createReBalanceTasks(DataNodeInfo sourceDatanode, DataNodeInfo destDatanode,List<RemoveReplicaTask> removeReplicaTasks, long maxRemoveDataSize) {List<String> files = namesystem.getFilesByDatanode(sourceDatanode.getIp(), sourceDatanode.getHostname());long removedDataSize = 0;// 遍历文件,不停的为每个文件生成一个复制的任务,直到准备迁移的文件的大小// 超过了待迁移总数据量maxRemoveDataSize为止for(String file : files) {String filename = file.split("_")[0];long fileLength = Long.parseLong(file.split("_")[1]);if(removedDataSize + fileLength >= maxRemoveDataSize) {break;}/** 为这个文件生成,针对目标节点的复制任务 */ReplicateTask replicateTask = new ReplicateTask(filename, fileLength, sourceDatanode, destDatanode);// 复制任务时立马下发的destDatanode.addReplicateTask(replicateTask); destDatanode.addStoredDataSize(fileLength); /** 为这个文件生成,针对源节点的删除任务 */sourceDatanode.addStoredDataSize(-fileLength); namesystem.removeReplicaFromDataNode(sourceDatanode.getId(), file); RemoveReplicaTask removeReplicaTask = new RemoveReplicaTask(filename, sourceDatanode);// 针对删除任务,统一攒起来,24小时后一起执行removeReplicaTasks.add(removeReplicaTask); // 迁移一个文件,就累加一份fileLengthremovedDataSize += fileLength;}return removedDataSize;}/*** 延迟删除副本的线程*/static class DelayRemoveReplicaThread extends Thread {private final List<RemoveReplicaTask> removeReplicaTasks;public DelayRemoveReplicaThread(List<RemoveReplicaTask> removeReplicaTasks) {this.removeReplicaTasks = removeReplicaTasks;}@Overridepublic void run() {long start = System.currentTimeMillis();while(true) {try {long now = System.currentTimeMillis();if(now - start > 24 * 60 * 60 * 1000) {for(RemoveReplicaTask removeReplicaTask : removeReplicaTasks) {// 真正的将删除任务下发下去,相应的DataNode下一轮心跳过来,就能认领这些删除任务removeReplicaTask.getDatanode().addRemoveReplicaTask(removeReplicaTask); }break;}Thread.sleep(60 * 1000); } catch (Exception e) {e.printStackTrace();}}}}}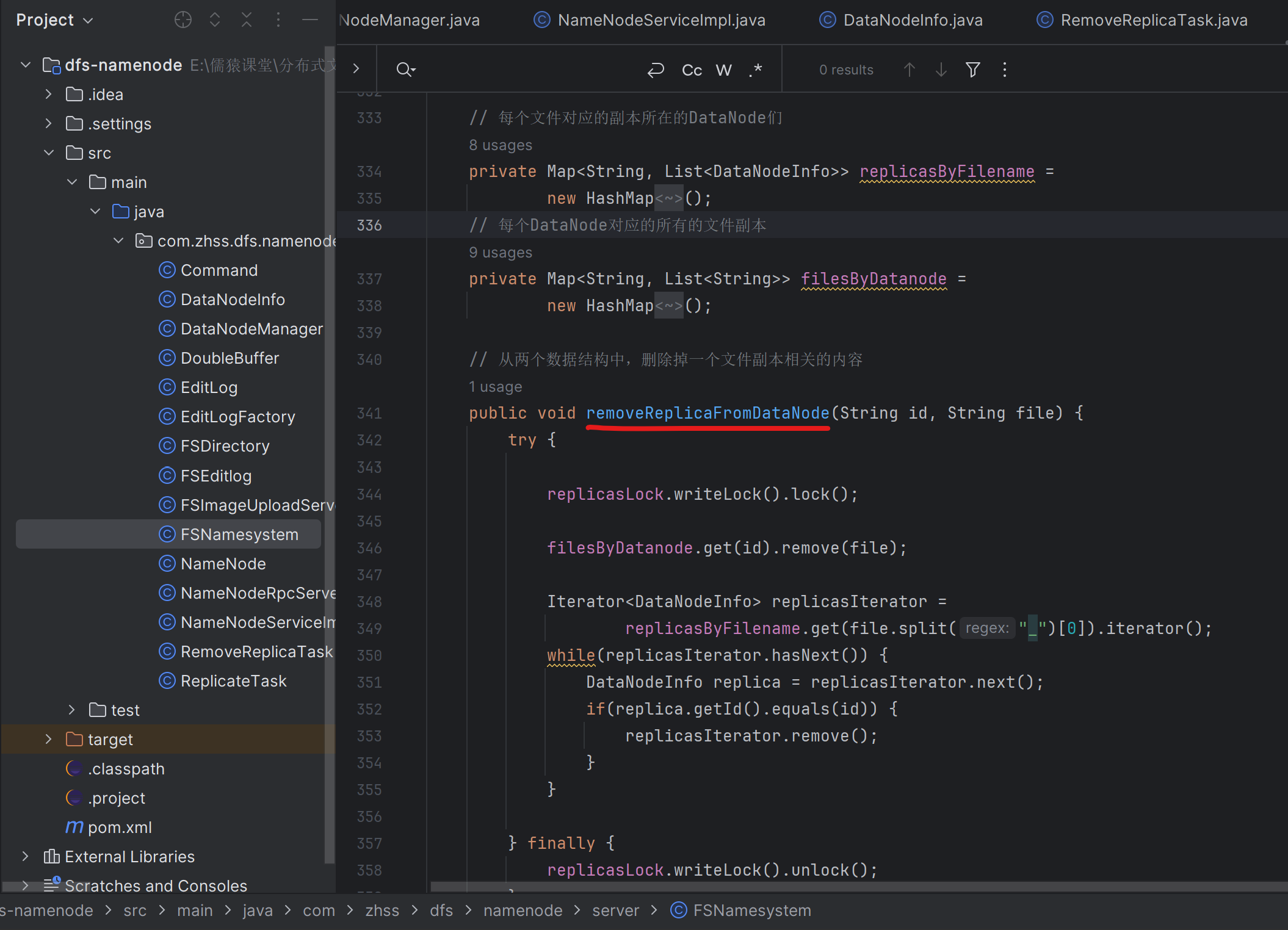
200_基于可伸缩架构实现集群扩容支撑海浪数据的存储
海量数据存储架构:分布式存储架构 + 可伸缩架构
高可用+高容错架构:多副本冗余 + 副本自动迁移(数据节点宕机时) + 冗余副本自动删除(宕机数据节点重启后) + 客户端容错机制(文件上传、下载时更换数据节点)
高性能架构:尽可能提升客户端文件上传和下载的性能和速度
高并发架构:尽可能让每个数据节点可以支撑更多的客户端的并发上传和下载
201_在分布式文件系统中高并发主要指的是什么?
高并发和高性能的架构改造,这是比较升华的一个部分
第一块:NameNode,元数据变更,能否承载高并发
第二块:DataNode,文件的上传和下载,能否承载高并发
对于NameNode而言,假设高峰时期,一万个客户端,同时发起请求要创建文件,一秒钟内高峰期直接来一万个请求去访问NameNode
对于DataNode而言,1000个客户端连接到DataNode上去,同时进行文件的 上传和下载,能否扛得住
202_看看NameNode中有哪些接口可能会被高并发的访问?
上传接口:create、allocateDataNodes、informReplicaReceived
下载接口:chooseDataNodeFromReplicas
203_分析一下文件上传的三个接口能否支撑几千的QPS
NameNode节点,一般在生产部署的时候,肯定是高配置物理机,不会是虚拟机,起码都是32核128G的配置。这种配置正常情况下,应该一台机器极限支撑个每秒几万的请求都是可以的
比如,一秒钟来1万个请求,每个请求排队获取锁,从而进入执行更新文件目录树的代码逻辑。因为是基于纯内存的操作,一个请求需要多少时间,1毫秒都不会到,可能一个请求就0.01毫秒,1毫秒可以执行100个请求,一秒就可以执行100 * 1000 = 10w个请求
虽然说有并发逻辑里会加锁,但是不要紧,只要基于纯内存,每个请求速度依然是极快的,就可以做到每秒处理几万个请求
绝大部分的创建文件的请求,可能就两个操作:更新内存里的文件目录树 、editlog写入内存缓冲 -> 0.01毫秒 -> 每秒执行10w次请求没问题。可能只有隔一段时间才会有一个请求,双缓冲的currentBuffer满了的时候,才会轮到这个线程执行一下刷磁盘,并且这个刷磁盘也是顺序写
Kafka之类的中间件系统,其实本质也是大量的基于内存来实现核心逻辑的,在高配置物理机的场支持下,抗下来每秒10万的QPS完全不是问题
204_分析一下文件上传的三个接口能否支撑几千的QPS(2)
平时写CRUD的业务系统,用不着高并发、IO、网络、磁盘、Netty、ZK一些技术。Java Web里最复杂的一块东西,其实是Tomcat,人家Tomcat作为一个Web服务器,他底层就要去做网络通信监听某个端口、内存管理、并发控制。你写的Servlet、SSM,其实就是嵌入在Tomcat容器里,执行的一些业务代码,你就是CRUD。互联网系统,缓存,MQ,数据库,ES,NoSQL,架构设计
但是我们现在自己写中间件系统,分布式文件系统,微服务注册中心给完成,这两个项目搞完有三层意义:第一个,把你底层的技术全部打通,基础会极度的扎实;第二个,后面看一些开源中间件系统的源码,会非常的轻松;第三个,这两个都是工业级的项目,直接是可以在出去面试的时候写简历上的,比如起个名字叫“盘古”分布式图片存储系统,替换你的很Low的CRUD的一些项目经历
每秒10w的文件上传/下载的请求,在NameNode这块是没有任何的瓶颈的,虽然NameNode是单机,但是也是高配的物理机。而有很多的中间件系统是基于zk来做元数据管理,每次更新元数据的时候,都需要走网络请求,纯内存一般就是0.001毫秒~0.01毫秒,这个时候性能就没办法保证了
因为只要一走网络请求,耗时直接就到毫秒级,一个请求过来,你需要去请求zk来做一些事情,直接就会到1毫秒+,几毫秒,10毫秒,直接会导致你的NameNode承载的并发能力,可能下降到每秒几千QPS了
虽然,后面我们也会用ZK,但是不是用ZK管理分布式文件系统中的各种元数据,而是负责管理NameNode集群的高可用。我们目前NameNode使用的是单机,没有办法做到某台NameNode挂了以后,自动切换到另一台NameNode对外提供服务,所以需要ZK的协助
205_DataNode的NIO网络通信架构能支撑高并发吗?
后面会把这套分布式图片存储系统整合到电商平台里去,电商平台中大量的用到了很多的图片,图片其实都应该存储在在这个分布式图片系统里,对图片的读取,主要也是走图片系统,评论晒图、商品图片。主要的压力就是图片读取,评论晒图的频率一般都是很低的,毕竟写评论的人是少数
主要的压力可能就是来自电商首页、商品详情页,可能会有很多图片读取的请求,每秒上万的请求。但是针对这种情况,你肯定必须得做静态化图片的缓存,不可能说每次都从分布式图片系统里来读图片,前置的Nginx本身就可以做静态图片的缓存
CDN缓存,大量的静态资源可以在前置的很多地方做缓存,Nginx、缓存服务器、CDN做缓存和加速,不需要每次都请求到底层的分布式图片系统里去的
比如说假设你每秒有1万个请求,一共部署了10台数据节点,每台机器要每秒要承担1000个QPS,目前的一个DataNode架构,每台机器接收1000个连接和请求能否实现?
目前的网络NIO通信架构,一个selector线程就需要监听1000个sockeChannel,后面只有3个worker线程,要同时做两件事情:1. 解析自定义的二进制通信协议的请求之外(很快),2. 最核心最笨重的就是执行本地磁盘的读写逻辑(很慢)
这个架构最大的问题,就是将解析请求和磁盘IO混在了一起,如果其中一个磁盘IO卡住了,那么这个worker负责的后续的所有请求的处理都会跟着受影响,从而导致高并发过来后,会产生大量积压
206_基于Reactor模式重新设计DataNode的网络通信架构
直接参考Kafka服务端的网络通信架构,就是基于如下的Reactor模式来实现的
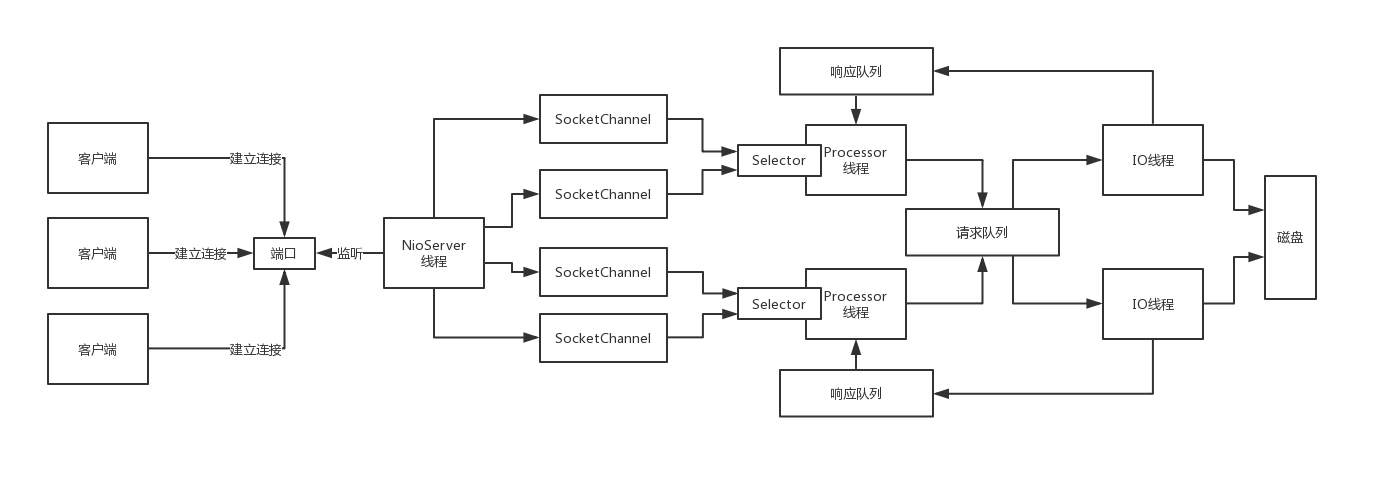
1000个客户端同时连接过来,发送请求,高并发的场景下,用Reactor模式来支撑是很轻松的
10个Processor线程,每个线程也就处理100个客户端
30个IO线程:执行比较慢的磁盘IO操作
207_重写DataNode的NioServer让其仅仅监听客户端连接请求

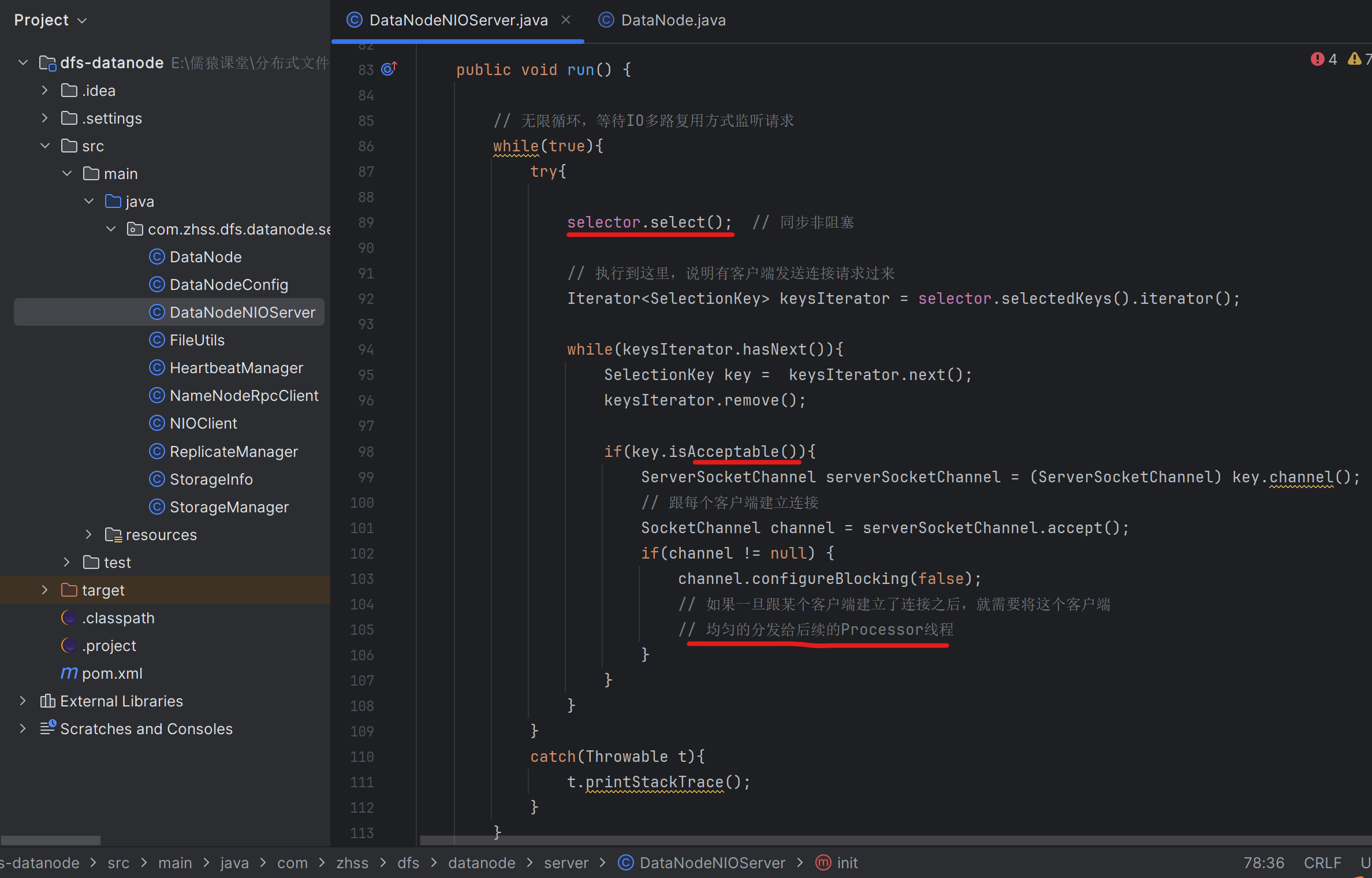
208_让NioServer将建立好的连接均匀分发给Processor线程
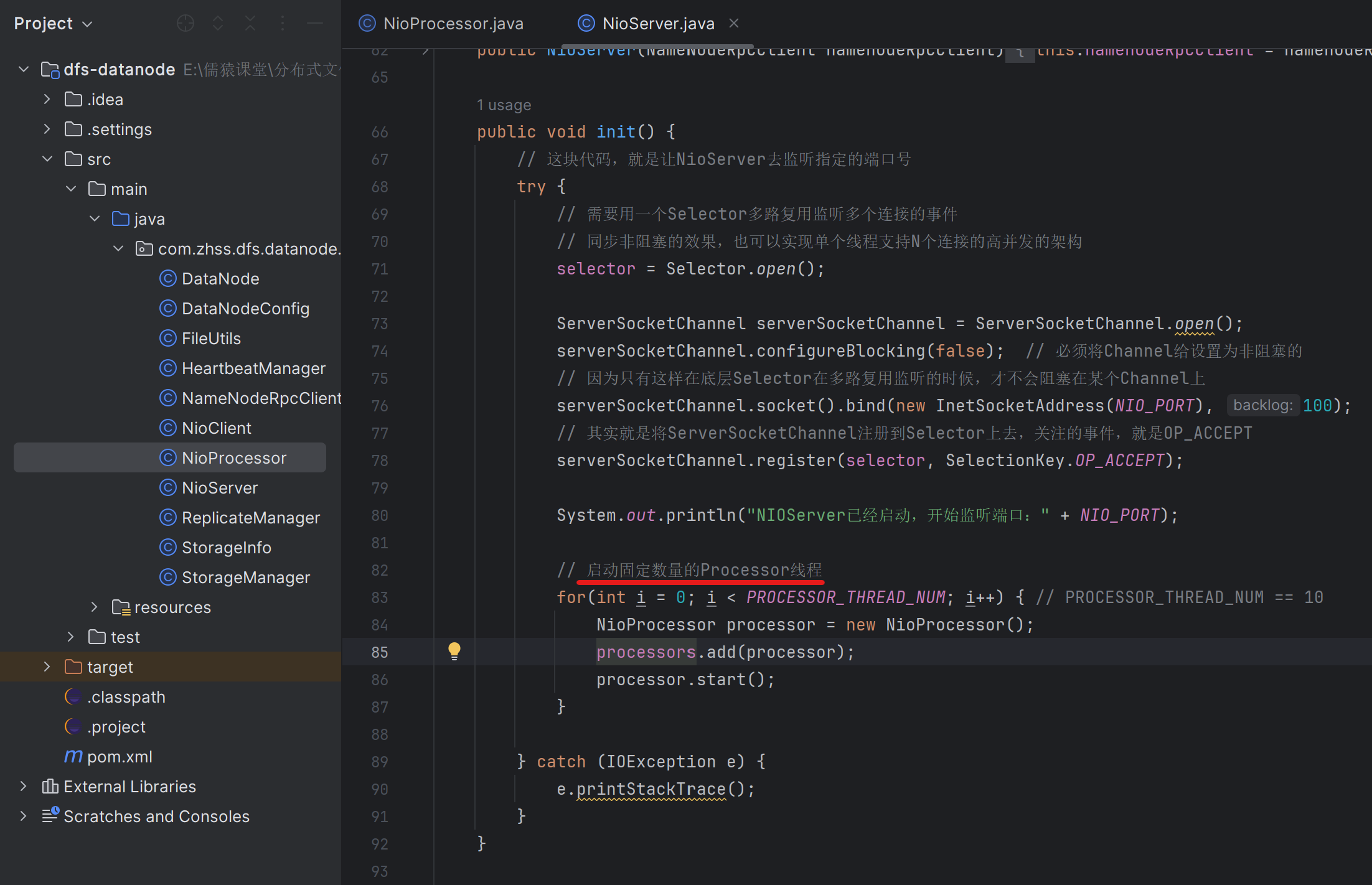
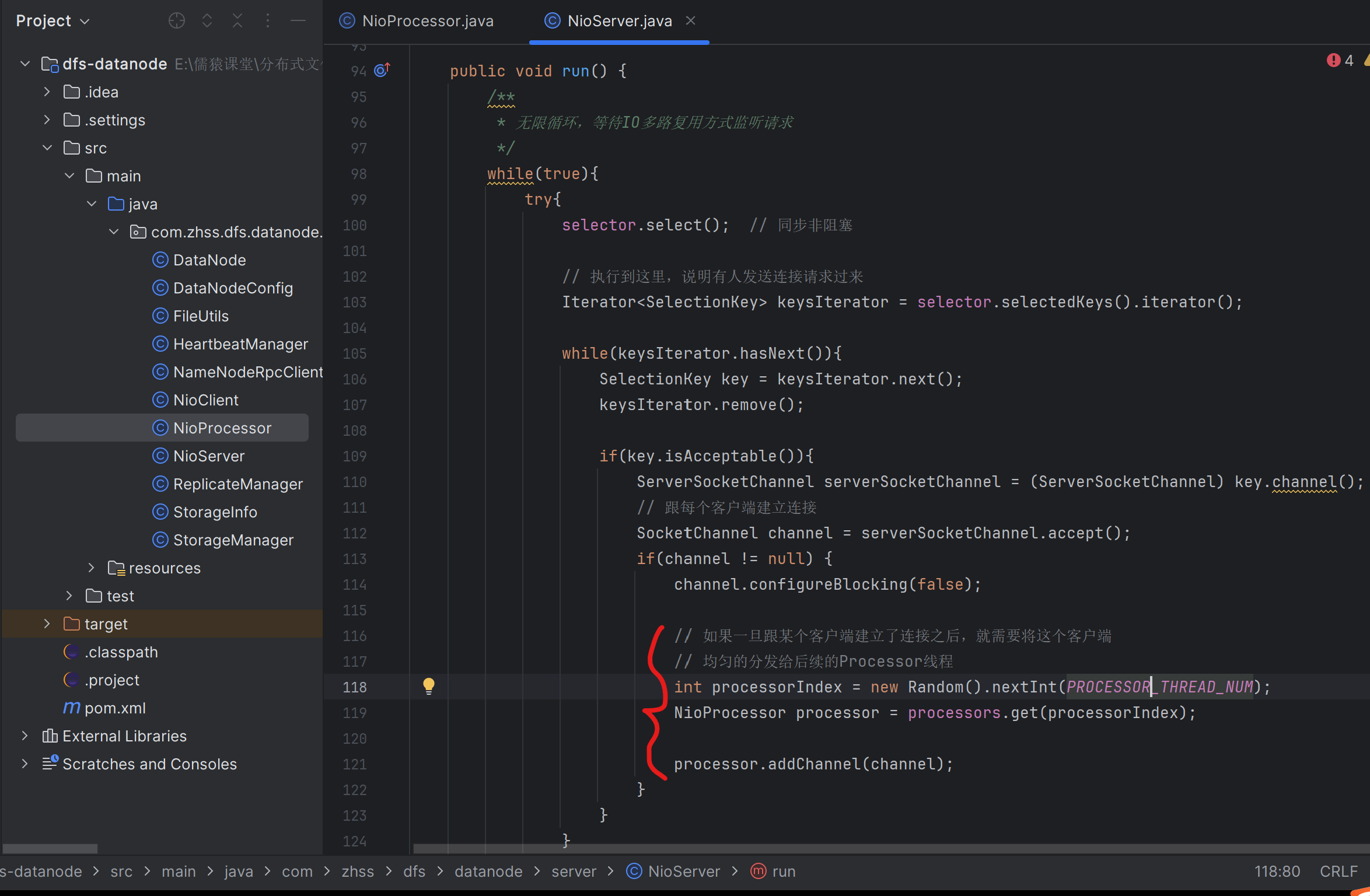
209_Processor线程将均匀分配的连接注册到自己的Selector上
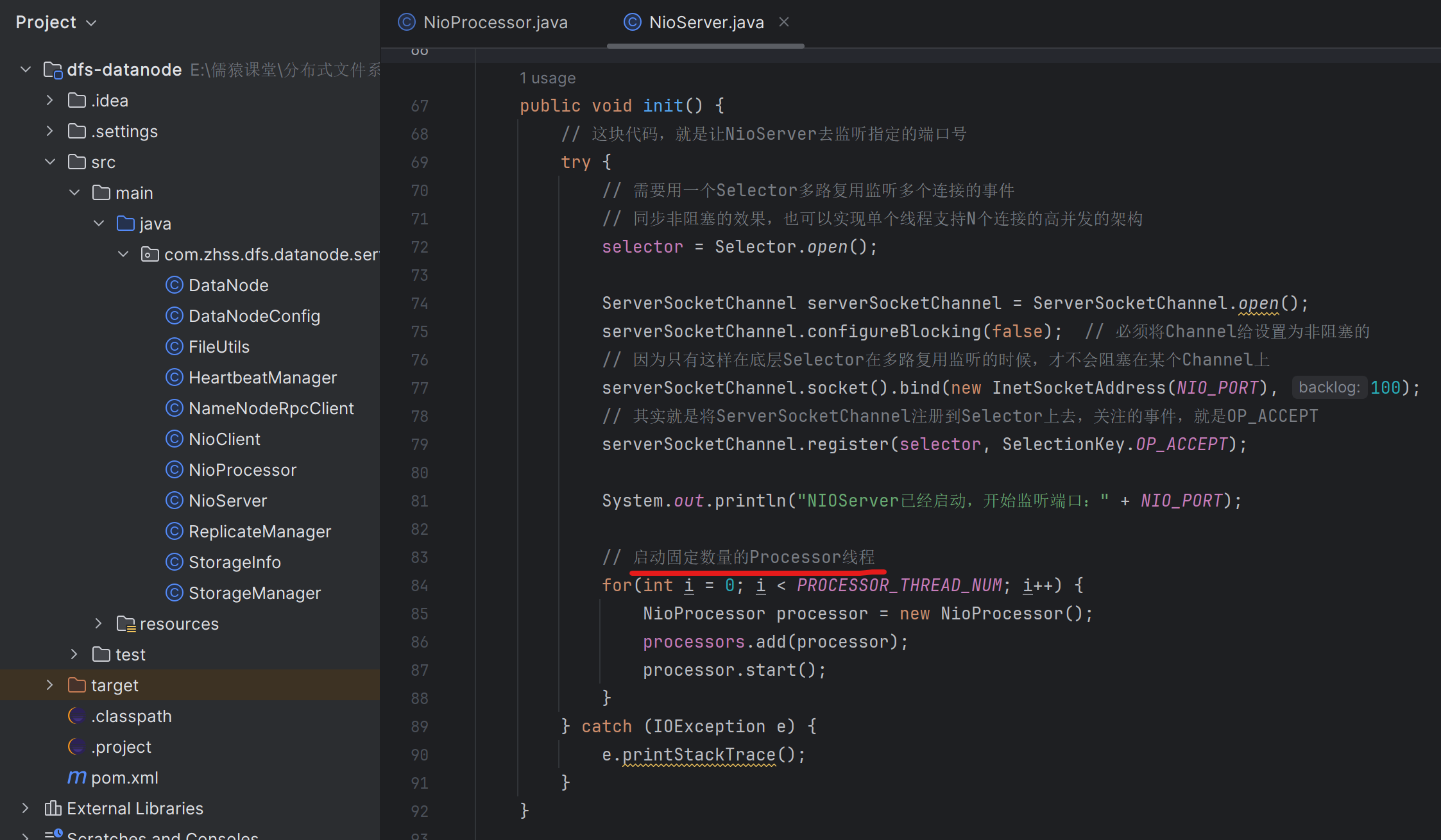
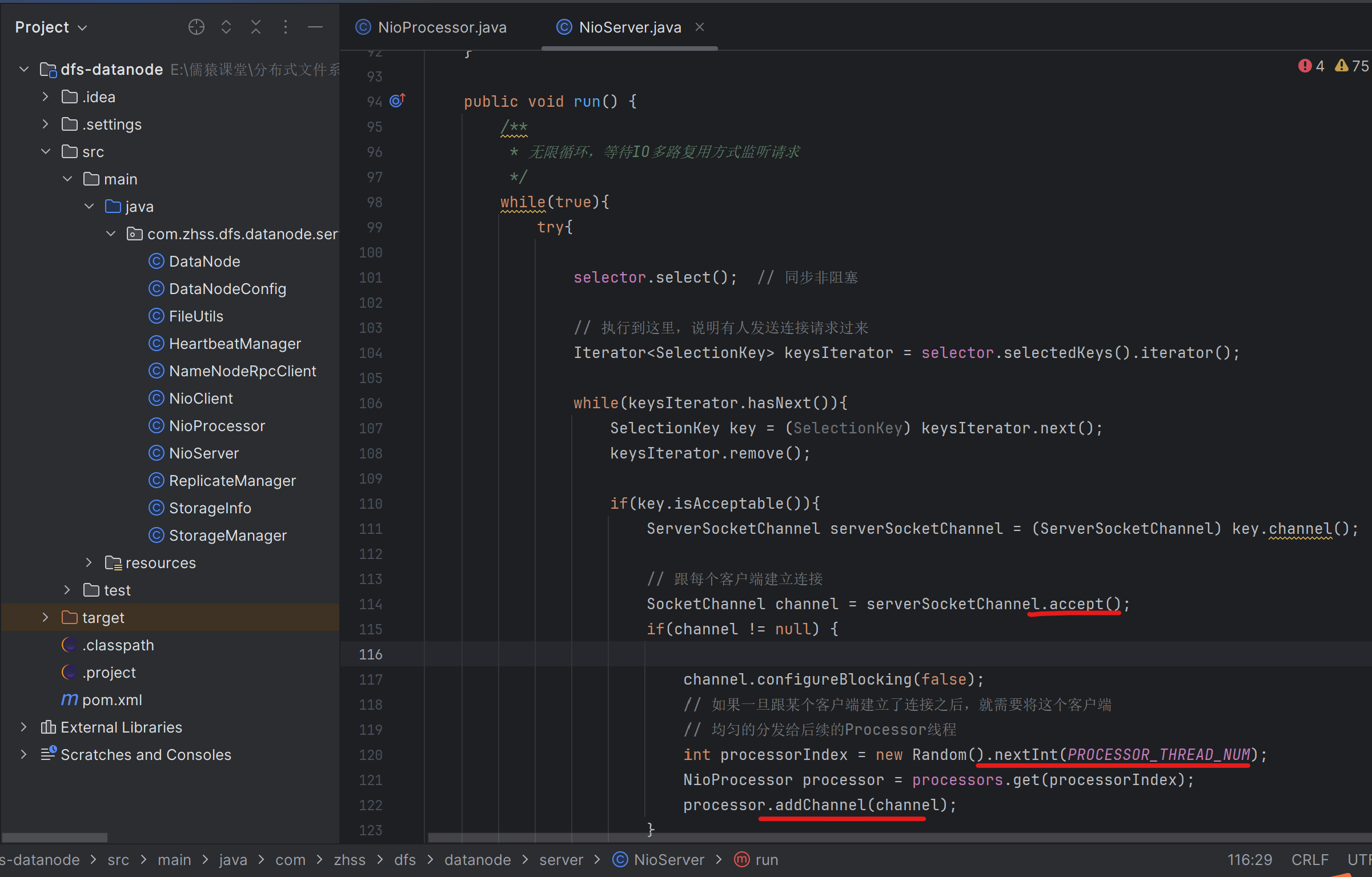
210_在一个循环中以限时阻塞的方式完成客户端请求的感知
NioProcessor
/*** 负责解析请求以及发送响应的线程*/
public class NioProcessor extends Thread {/*** 多路复用监听时的最大阻塞时间*/public static final Long POLL_BLOCK_MAX_TIME = 1000L;// 等待注册的网络连接的队列private ConcurrentLinkedQueue<SocketChannel> channelQueue = new ConcurrentLinkedQueue<SocketChannel>();// 每个Processor私有的Selector多路复用器private Selector selector;public NioProcessor() {try {this.selector = Selector.open();} catch (IOException e) {e.printStackTrace();}}/*** 给这个Processor线程分配一个网络连接*/public void addChannel(SocketChannel channel) {channelQueue.offer(channel);// 唤醒在POLL_BLOCK_MAX_TIME处,等待的selectorselector.wakeup();}/*** 线程的核心主逻辑*/@Overridepublic void run() {while(true) {try {// 注册排队等待的连接registerQueuedClients();// 以限时阻塞的方式感知连接中的请求poll();} catch (Exception e) {e.printStackTrace(); }}}/*** 将排队中的等待注册的连接注册到Selector上去*/private void registerQueuedClients() {SocketChannel channel = null;while((channel = channelQueue.poll()) != null) {try {channel.register(selector, SelectionKey.OP_READ);} catch (ClosedChannelException e) {e.printStackTrace();}}}/*** 以多路复用的方式来监听各个连接的请求*/private void poll() {try {// 以限时阻塞的方式完成客户端请求的感知(在一个循环中)int keys = selector.select(POLL_BLOCK_MAX_TIME);if(keys > 0) {Iterator<SelectionKey> keyIterator = selector.selectedKeys().iterator();while(keyIterator.hasNext()) {SelectionKey key = keyIterator.next();keyIterator.remove();// 如果接受到了某个客户端的请求if(key.isReadable()) {SocketChannel channel = (SocketChannel) key.channel();}}}} catch (Exception e) {e.printStackTrace();}}}
注意这里的selector.wakeup()的使用场景
213_封装NetworkRequest来解析与抽取一个完整的请求
NetworkRequest
/*** 从channel中读取一次二进制格式的网络请求数据解析,并封装为一个NetworkRequest对象NetworkRequest对象中的CachedRequest的内部,会记录解析出来的文件名,文件内容等信息 */
public class NetworkRequest {public static final Integer REQUEST_SEND_FILE = 1;public static final Integer REQUEST_READ_FILE = 2;// 本次网络请求对应的连接private SelectionKey key;// 本次网络请求对应的连接private SocketChannel channel;// 缓存中的数据private final CachedRequest cachedRequest = new CachedRequest();private ByteBuffer cachedRequestTypeBuffer;private ByteBuffer cachedFilenameLengthBuffer;private ByteBuffer cachedFilenameBuffer;private ByteBuffer cachedFileLengthBuffer;private ByteBuffer cachedFileBuffer;public SelectionKey getKey() {return key;}public void setKey(SelectionKey key) {this.key = key;}public SocketChannel getChannel() {return channel;}public void setChannel(SocketChannel channel) {this.channel = channel;}/*** 从网络连接中读取与解析出来一个请求*/public void read() {try {// 假如说你这个一次读取的数据里包含了多个文件的话// 这个时候我们会先读取文件名,然后根据文件的大小去读取这么多的数据// 需要先提取出来这次请求是什么类型:1 发送文件;2 读取文件Integer requestType = null;if(cachedRequest.requestType != null) {requestType = cachedRequest.requestType;} else {requestType = getRequestType(channel); // 但是此时channel的position肯定也变为了4}if(requestType == null) {return;}System.out.println("从请求中解析出来请求类型:" + requestType); // 拆包,就是说人家一次请求,本来是包含了:requestType + filenameLength + filename [+ imageLength + image]// 这次OP_READ事件,就读取到了requestType的4个字节中的2个字节,剩余的数据// 就被放在了下一次OP_READ事件中了if(REQUEST_SEND_FILE.equals(requestType)) {handleSendFileRequest(channel, key);} else if(REQUEST_READ_FILE.equals(requestType)) {handleReadFileRequest(channel, key);}} catch (Exception e) {e.printStackTrace();}}/*** 获取本次请求的类型*/public Integer getRequestType(SocketChannel channel) throws Exception {Integer requestType = null;if(cachedRequest.requestType != null) {return cachedRequest.requestType;}ByteBuffer requestTypeBuffer = null;if(cachedRequestTypeBuffer != null) {requestTypeBuffer = cachedRequestTypeBuffer;} else {requestTypeBuffer = ByteBuffer.allocate(4);}channel.read(requestTypeBuffer); // 此时requestType ByteBuffer,position跟limit都是4,remaining是0if(!requestTypeBuffer.hasRemaining()) {// 已经读取出来了4个字节,可以提取出来requestType了requestTypeBuffer.rewind(); // 将position变为0,limit还是维持着4requestType = requestTypeBuffer.getInt();cachedRequest.requestType = requestType;} else {cachedRequestTypeBuffer = requestTypeBuffer; }return requestType;}/*** 是否已经完成了一个请求的读取* @return*/public Boolean hasCompletedRead() {return cachedRequest.hasCompletedRead;}/*** 获取文件名同时转换为本地磁盘目录中的绝对路径* @param channel* @return* @throws Exception*/private Filename getFilename(SocketChannel channel) throws Exception {Filename filename = new Filename(); if(cachedRequest.filename != null) {return cachedRequest.filename;} else {String relativeFilename = getRelativeFilename(channel);if(relativeFilename == null) {return null;}String absoluteFilename = getAbsoluteFilename(relativeFilename);// /image/product/iphone.jpgfilename.relativeFilename = relativeFilename;filename.absoluteFilename = absoluteFilename;cachedRequest.filename = filename;} return filename;}/*** 获取相对路径的文件名*/private String getRelativeFilename(SocketChannel channel) throws Exception {Integer filenameLength = null;String filename = null;// 读取文件名的大小if(cachedRequest.filenameLength == null) {ByteBuffer filenameLengthBuffer = null;if(cachedFilenameLengthBuffer != null) {filenameLengthBuffer = cachedFilenameLengthBuffer;} else {filenameLengthBuffer = ByteBuffer.allocate(4);}channel.read(filenameLengthBuffer); if(!filenameLengthBuffer.hasRemaining()) { filenameLengthBuffer.rewind();filenameLength = filenameLengthBuffer.getInt();cachedRequest.filenameLength = filenameLength;} else {cachedFilenameLengthBuffer = filenameLengthBuffer;return null;}}// 读取文件名ByteBuffer filenameBuffer = null;if(cachedFilenameBuffer != null) {filenameBuffer = cachedFilenameBuffer;} else {filenameBuffer = ByteBuffer.allocate(filenameLength);}channel.read(filenameBuffer);if(!filenameBuffer.hasRemaining()) {filenameBuffer.rewind();filename = new String(filenameBuffer.array()); } else {cachedFilenameBuffer = filenameBuffer;}return filename;}/*** 获取文件在本地磁盘上的绝对路径名*/private String getAbsoluteFilename(String relativeFilename) {String[] relativeFilenameSplited = relativeFilename.split("/"); String dirPath = DATA_DIR;for(int i = 0; i < relativeFilenameSplited.length - 1; i++) {if(i == 0) {continue;}dirPath += "\\" + relativeFilenameSplited[i];}File dir = new File(dirPath);if(!dir.exists()) {dir.mkdirs();}String absoluteFilename = dirPath + "\\" + relativeFilenameSplited[relativeFilenameSplited.length - 1];return absoluteFilename;}/*** 从网络请求中获取文件大小*/private Long getFileLength(SocketChannel channel) throws Exception {Long fileLength = null;if(cachedRequest.fileLength != null) {return cachedRequest.fileLength;} else {ByteBuffer fileLengthBuffer = null;if(cachedFileLengthBuffer != null) { fileLengthBuffer = cachedFileLengthBuffer;} else {fileLengthBuffer = ByteBuffer.allocate(8);}channel.read(fileLengthBuffer);if(!fileLengthBuffer.hasRemaining()) {fileLengthBuffer.rewind();fileLength = fileLengthBuffer.getLong();cachedRequest.fileLength = fileLength;} else {cachedFileLengthBuffer = fileLengthBuffer;}}return fileLength;}/*** 发送文件*/private void handleSendFileRequest(SocketChannel channel, SelectionKey key) throws Exception {// 从请求中解析文件名Filename filename = getFilename(channel); System.out.println("从网络请求中解析出来文件名:" + filename); if(filename == null) {return;}// 从请求中解析文件大小Long fileLength = getFileLength(channel); System.out.println("从网络请求中解析出来文件大小:" + fileLength); if(fileLength == null) {return;}// 循环不断的从channel里读取数据,并写入磁盘文件ByteBuffer fileBuffer = null;if(cachedFileBuffer != null) {fileBuffer = cachedFileBuffer;} else {fileBuffer = ByteBuffer.allocate(Integer.parseInt(String.valueOf(fileLength)));}channel.read(fileBuffer);if(!fileBuffer.hasRemaining()) {fileBuffer.rewind();cachedRequest.file = fileBuffer;cachedRequest.hasCompletedRead = true;System.out.println("本次文件上传请求读取完毕......."); } else {cachedFileBuffer = fileBuffer;System.out.println("本次文件上传出现拆包问题,缓存起来,下次继续读取......."); }}/*** 读取文件*/private void handleReadFileRequest(SocketChannel channel, SelectionKey key) throws Exception {// 从请求中解析文件名// 已经是:F:\\development\\tmp1\\image\\product\\iphone.jpgFilename filename = getFilename(channel); System.out.println("从网络请求中解析出来文件名:" + filename); if(filename == null) {return;}cachedRequest.hasCompletedRead = true;}/*** 文件名*/class Filename {// 相对路径名String relativeFilename;// 绝对路径名String absoluteFilename;@Overridepublic String toString() {return "Filename [relativeFilename=" + relativeFilename + ", absoluteFilename=" + absoluteFilename + "]";}}/*** 缓存文件*/class CachedRequest {Integer requestType;Filename filename;Integer filenameLength;Long fileLength;ByteBuffer file;Boolean hasCompletedRead = false;}}
214_将读取完毕的网络请求分发到全局的请求队列中
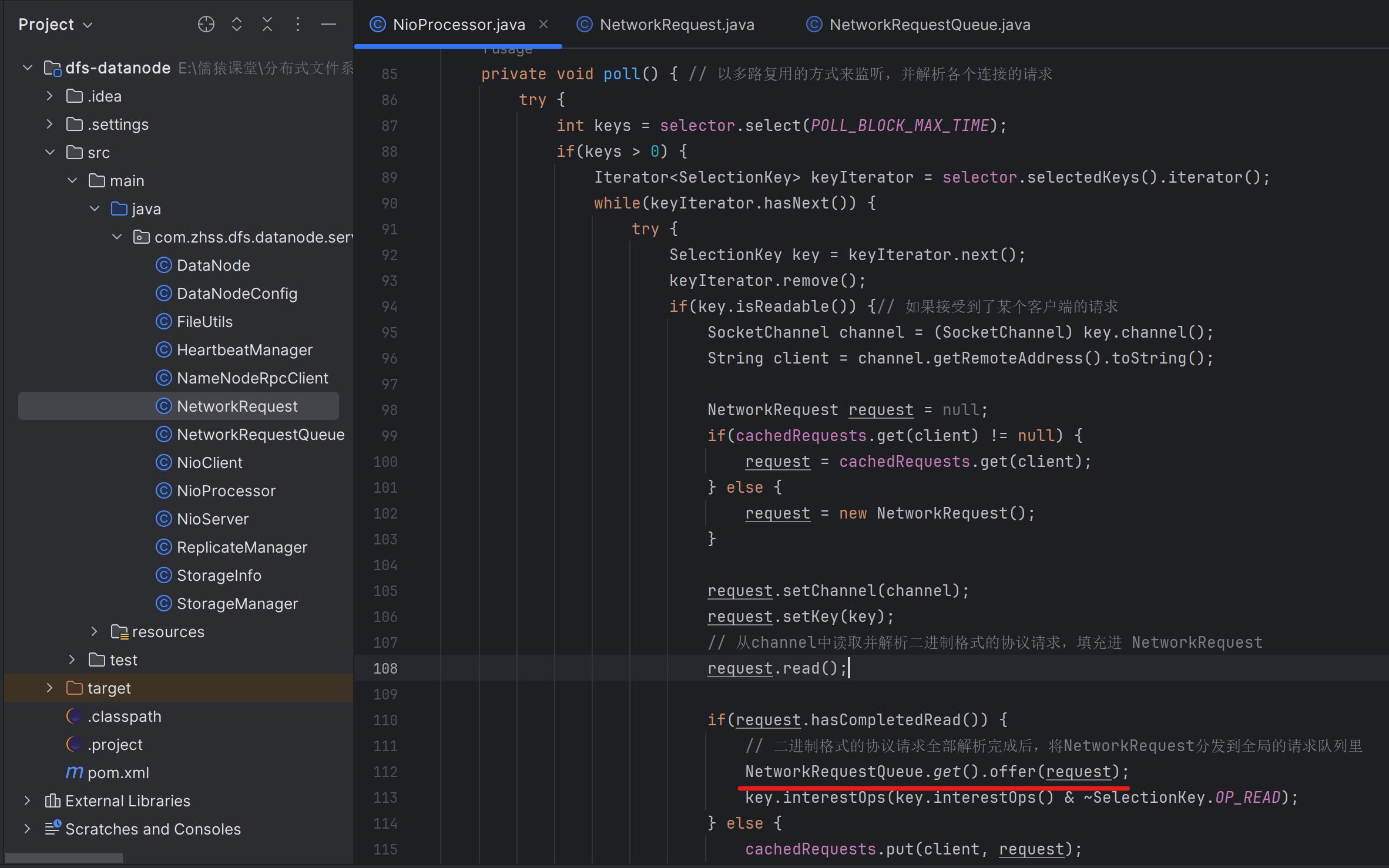
NetworkRequestQueue
package com.zhss.dfs.datanode.server;import java.util.concurrent.ConcurrentLinkedQueue;/*** 公共网络请求存放队列*/
public class NetworkRequestQueue {private static volatile NetworkRequestQueue instance = null;public static NetworkRequestQueue get() {if(instance == null) {synchronized(NetworkRequestQueue.class) {if(instance == null) {instance = new NetworkRequestQueue();}}}return instance;}// 一个全局的请求队列private final ConcurrentLinkedQueue<NetworkRequest> requestQueue = new ConcurrentLinkedQueue<NetworkRequest>();public void offer(NetworkRequest request) {requestQueue.offer(request);}public NetworkRequest poll() {return requestQueue.poll();}}
216_实现IO线程从请求队列中争抢请求以及执行磁盘IO操作
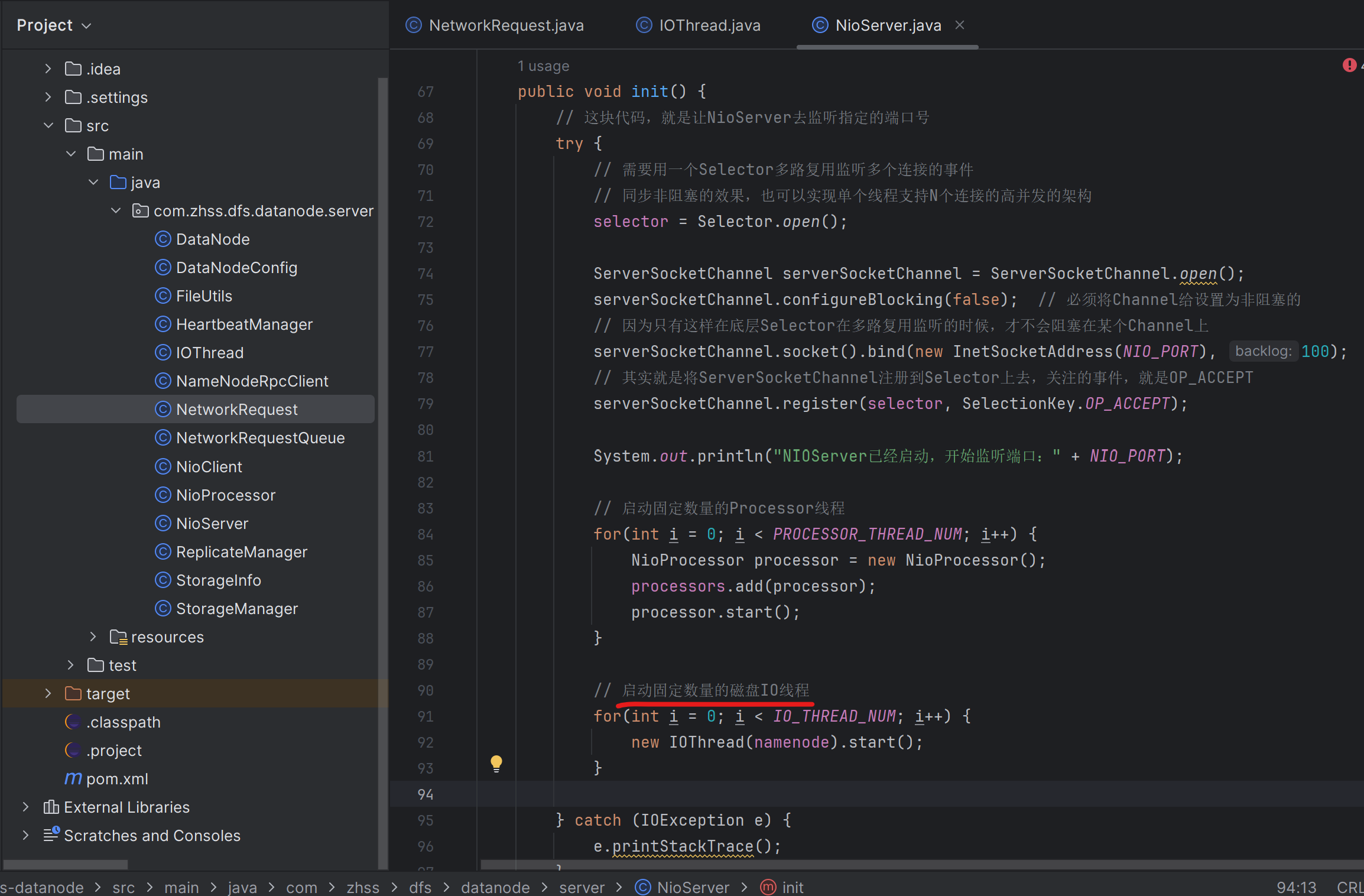
IOThread
/*** 负责执行磁盘IO的线程*/
public class IOThread extends Thread {public static final Integer REQUEST_SEND_FILE = 1;public static final Integer REQUEST_READ_FILE = 2;// 拿出单例的公共请求存放队列private final NetworkRequestQueue requestQueue = NetworkRequestQueue.get();private final NameNodeRpcClient namenode;public IOThread(NameNodeRpcClient namenode) {this.namenode = namenode;}@Overridepublic void run() {while(true) {try {NetworkRequest request = requestQueue.poll();if(request == null) {Thread.sleep(100);continue;}Integer requestType = request.getRequestType();if(requestType.equals(REQUEST_SEND_FILE)) {// 对于上传文件,将文件写入本地磁盘即可writeFileToLocalDisk(request);} else if(requestType.equals(REQUEST_READ_FILE)) {// 对于下载文件,从本地磁盘读取文件readFileFromLocalDisk(request);}} catch (Exception e) {e.printStackTrace();}}}private void readFileFromLocalDisk(NetworkRequest request) throws Exception {FileInputStream localFileIn = null;FileChannel localFileChannel = null;try {File file = new File(request.getAbsoluteFilename());Long fileLength = file.length();localFileIn = new FileInputStream(request.getAbsoluteFilename()); localFileChannel = localFileIn.getChannel();// 循环不断的从channel里读取数据,并写入磁盘文件ByteBuffer buffer = ByteBuffer.allocate(8 + Integer.parseInt(String.valueOf(fileLength)));buffer.putLong(fileLength);int hasReadImageLength = localFileChannel.read(buffer);System.out.println("从本次磁盘文件中读取了" + hasReadImageLength + " bytes的数据"); buffer.rewind();} finally {if(localFileChannel != null) {localFileChannel.close();}if(localFileIn != null) {localFileIn.close();}}}private void writeFileToLocalDisk(NetworkRequest request) throws Exception {// 构建针对本地文件的输出流FileOutputStream localFileOut = null;FileChannel localFileChannel = null;try {localFileOut = new FileOutputStream(request.getAbsoluteFilename()); localFileChannel = localFileOut.getChannel();localFileChannel.position(localFileChannel.size());System.out.println("对本地磁盘文件定位到position=" + localFileChannel.size()); int written = localFileChannel.write(request.getFile());System.out.println("本次文件上传完毕,将" + written + " bytes的数据写入本地磁盘文件......."); // 增量上报Master节点自己接收到了一个文件的副本// /image/product/iphone.jpgnamenode.informReplicaReceived(request.getRelativeFilename() + "_" + request.getFileLength());System.out.println("增量上报收到的文件副本给NameNode节点......"); } finally {localFileChannel.close();localFileOut.close();}}}

)


)











- 绘制子图)


