参考链接:https://mp.weixin.qq.com/s/cscrUn7n_o6PdeQRzWpx8g
视频教程:https://www.bilibili.com/video/BV1LGbozkEDY
模型代码:https://github.com/boson-ai/higgs-audio
如果是两个模型加在一起:一个语言模型,一个文本转语音模型有问题
一个是耗时问题,另一个是语音转文本再转语音会丢失非语言信息,比如语气和环境音
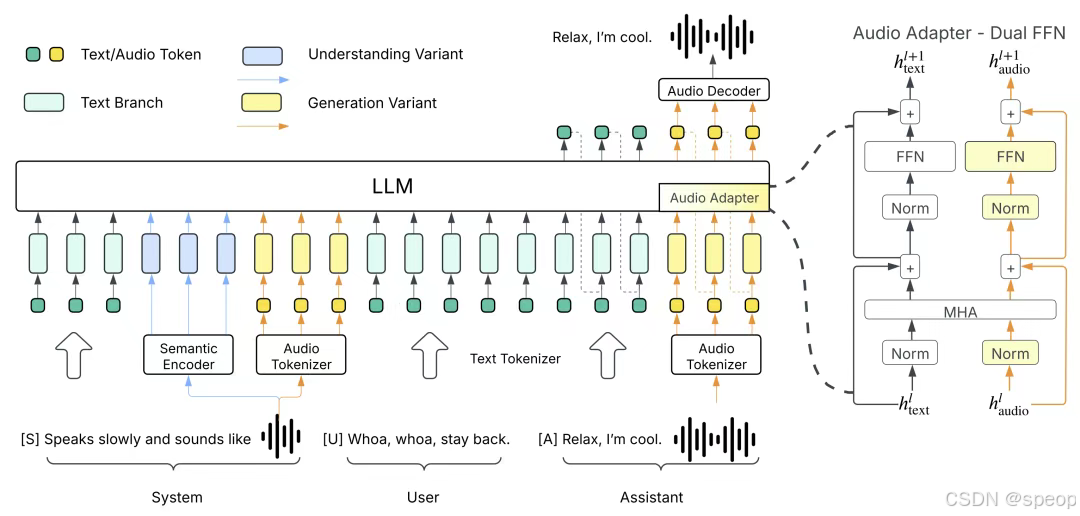
传统的语音和文本模型之间相互独立,李沐老师就想,欸,能不能将两者结合起来,直接让LLM用语音进行沟通。那么首先就要知道文本语言模型的本质是用给定的一段指令去生成预测结果,就是将任务先拆解为系统指令(system)、用户输入(user)、**模型回复(assistant)**三个部分。
system告诉模型,需要做什么事情,例如回答该问题、写一段文字或者其他
user就是告知事情的详细内容,例如问题具体是什么、文字要什么风格。所以如果要让模型支持语音,就需要为模型增加一个系统命令,在user里输入要转录为语音的文字,让模型从system里输出对应语音数据。这样语音任务就能转换成相同的处理格式,直接打通语音和文本之间的映射,通过追加更多的数据和算力,直接scaling law“大力出奇迹”。
中文的一个字:token
语言模型的输出是一个softmax,本质上是一个多分类的问题
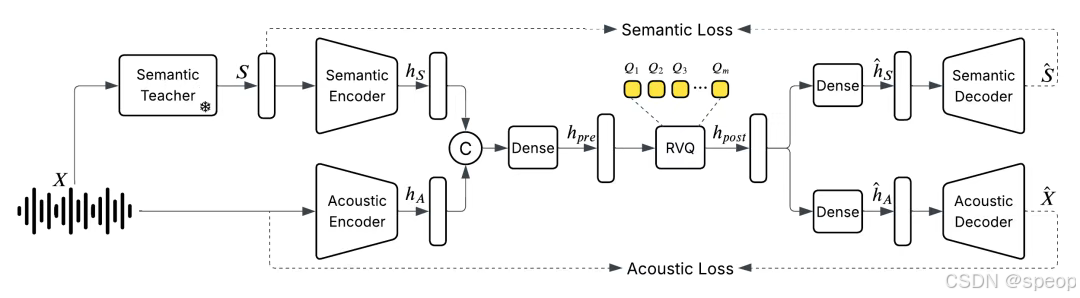
语音tokenizer:需要将语音这样连续的信号变为离散的token
现有的方法是将一秒的语音信号裁切成多段(如100毫秒一段),为每一段匹配最相似的预定义模板(如45个模板),然后将其表示为长度为10的编号序列,也就是一个个token。
但这样做,虽然可以将一小时的音频从60兆压缩到0.16兆,但质量相当糟糕,所以需要优先保留语音的语义信息,而声学信号只保留少量部分,后续再通过其他手段还原。
于是他们训练了一个统一的离散化音频分词器,以每秒25帧的速度运行,同时保持甚至提高音频质量,以捕获语义和声学特征
常用压缩:1小时 128kbps mp3 ~60MB
设64K audio tokens, 24 tokens per second
1秒audio:log2(64K)x24=384bit1小时audio ~0.16MB对比mp3,又压缩了375x
优先应该保持语义的信号
语言模型能将一个东西的语音的表示和文字的表示能够做一个映射
将语音的语义尽量映射回文本,使得能够利用上文本语音模型
将语音对话表示为相应的system(场景描述、声学特征、人物特征等)、user(对话文本)、assistant(对应音频输出)的形式。
同样的模型架构训练一个额外的语音理解模型
用户给你一段语音,请你分析它的场景,它里面有哪些人,说什么东西,情绪,。
把生成模型出来的东西作为用户的输入
生成模型system prompt是对场景的描述
用户给你的内容作为system的输出
教第一个徒弟打拳
教第二个徒弟踢腿
然后让两个徒弟互相打,最后期望两个徒弟都能够学会拳脚功夫
文字作为上一轮用户的输入,语音作为上一轮系统的输出,在给一段文字就能输出和这个人声音一致的语音。
1. 语音信号离散化表示(关键突破)
问题:语音是连续信号,传统方法(如分段+模板匹配)压缩后质量差。
解决方案:
- 统一音频分词器(Unified Audio Tokenizer)
- 分层离散化:将语音信号分解为两类token:
- 语义token(高层):捕获文本内容、意图(映射到文本空间,类似ASR)。
- 声学token(低层):保留音色、语调等特征(通过矢量量化/VQ-VAE压缩)。
- 高帧率处理:以每秒25帧的速度编码,平衡信息密度和连续性。
- 联合训练:语义和声学token的编码器/解码器端到端优化,避免传统模板匹配的信息丢失。
- 分层离散化:将语音信号分解为两类token:
效果:
- 语音压缩后仍能保留语义和情感信息(如“愤怒”语调的声学特征)。
- 后续用LLM处理离散token时,类似处理文本,无需额外设计连续信号模块。
2. 数据构建与清洗(质量保障)
问题:语音-文本对齐数据稀缺,公开数据质量差。
解决方案:
- 数据来源:购买版权数据+合规抓取,覆盖多样化场景(对话、音乐、环境音等)。
- 严格过滤:
- 通过ASR模型+人工规则剔除低质量音频(如背景噪声大、内容不连贯)。
- 仅保留10%数据(1000万小时高质量数据)。
- 自生成标注:
- 用预训练的AudioVerse模型(语音→文本/场景分析)自动标注语音的
system字段(场景、情绪等)。 - 形成
(system: 场景描述, user: 文本, assistant: 音频)的三元组训练数据。
- 用预训练的AudioVerse模型(语音→文本/场景分析)自动标注语音的
效果:
- 数据多样性高且对齐精准,模型能学习复杂语音-文本关联(如“笑着回答问题”)。
3. 模型架构设计(性能核心)
核心思路:将语音任务转化为LLM熟悉的“文本生成”格式。
具体实现:
- 多任务统一框架:
- 输入:
system指令(如“生成愤怒的男声”)+user文本 → 输出:声学token序列。 - 模型本质是条件式token预测(类似文本生成,但输出是语音token)。
- 输入:
- 双模型协同训练:
- AudioVerse:语音→文本/场景分析(提供
system标注)。 - 主模型:文本+场景→语音生成。
- 两者互促,类似GAN的对抗训练(但更温和)。
- AudioVerse:语音→文本/场景分析(提供
优化点:
- 语义优先:模型优先学习语音的语义token,再细化声学token(避免早期过拟合到音色细节)。
- 延迟优化:流式生成声学token,实时拼接(类似文本模型的逐词生成)。
4. 为什么性能显著提升?
- 语义理解更强:
- 语音token与文本空间对齐,模型能利用文本预训练知识(如GPT的推理能力)。
- 例:生成“悲伤的诗歌朗读”时,模型先理解“悲伤”的文本语义,再匹配对应声学特征。
- 端到端联合训练:
- 传统TTS分模块(文本→音素→声学),而沐神模型统一优化,避免误差累积。
- 数据规模效应:
- 1000万小时数据远超传统TTS数据集(如LJSpeech仅24小时),覆盖长尾场景。
5. 关键优化总结
| 模块 | 传统方法 | 沐神团队的优化 | 提升点 |
|---|---|---|---|
| 语音表示 | 手工模板匹配 | 分层离散化token(语义+声学) | 质量↑,兼容文本模型 |
| 数据构建 | 小规模纯净数据 | 海量数据+严格过滤+自生成标注 | 多样性↑,对齐精度↑ |
| 模型训练 | 独立训练ASR/TTS模块 | 语音-文本联合训练,双模型互促 | 语义和声学协同优化 |
| 任务泛化 | 单一任务(如TTS) | 统一框架支持生成、分析、实时交互 | 多任务性能均衡 |
6. 可玩性功能示例
- 声音克隆:输入目标语音片段(5秒),模型提取声学token后生成新内容。
- 实时情绪交互:检测用户语音情绪(如愤怒),生成共情的语音回复。
- 音乐生成:将歌词+风格描述(
system)转换为歌唱音频。
若想深入技术细节,建议阅读代码中的tokenizer.py(音频离散化)和trainer.py(多任务损失函数),关键是如何平衡语义和声学token的损失权重。
音频分词器:https://github.com/boson-ai/higgs-audio/blob/main/tech_blogs/TOKENIZER_BLOG.md
提出的DualFFN架构:https://github.com/boson-ai/higgs-audio/blob/main/tech_blogs/ARCHITECTURE_BLOG.md

这里可以试用
from boson_multimodal.serve.serve_engine import HiggsAudioServeEngine, HiggsAudioResponse
from boson_multimodal.data_types import ChatMLSample, Message, AudioContentimport torch
import torchaudio
import time
import clickMODEL_PATH = "bosonai/higgs-audio-v2-generation-3B-base"
AUDIO_TOKENIZER_PATH = "bosonai/higgs-audio-v2-tokenizer"system_prompt = ("Generate audio following instruction.\n\n<|scene_desc_start|>\nAudio is recorded from a quiet room.\n<|scene_desc_end|>"
)messages = [Message(role="system",content=system_prompt,),Message(role="user",content="The sun rises in the east and sets in the west. This simple fact has been observed by humans for thousands of years.",),
]
device = "cuda" if torch.cuda.is_available() else "cpu"serve_engine = HiggsAudioServeEngine(MODEL_PATH, AUDIO_TOKENIZER_PATH, device=device)output: HiggsAudioResponse = serve_engine.generate(chat_ml_sample=ChatMLSample(messages=messages),max_new_tokens=1024,temperature=0.3,top_p=0.95,top_k=50,stop_strings=["<|end_of_text|>", "<|eot_id|>"],
)
torchaudio.save(f"output.wav", torch.from_numpy(output.audio)[None, :], output.sampling_rate)






)
![学习:JS[8]本地存储+正则表达式](http://pic.xiahunao.cn/学习:JS[8]本地存储+正则表达式)



![[学习] CORDIC算法详解:从数学原理到反正切计算实战](http://pic.xiahunao.cn/[学习] CORDIC算法详解:从数学原理到反正切计算实战)







