本节我们分享点云处理中的三种常见聚类方法,分别是K-means、欧氏与 DBSCAN聚类。具体介绍如下:
1. K-means 聚类
定义:一种基于距离度量的无监督学习算法,将数据划分为 K 个紧凑的簇,使簇内数据相似度高、簇间差异大。
算法流程:
1)初始化:随机选取 K 个点作为初始质心。
2)分配:计算每个样本到质心的欧氏距离,将其归入最近簇。
3)更新:重新计算各簇的质心(簇内样本的均值)。
4)迭代:重复步骤 2-3,直至质心不变或达到最大迭代次数。特点:计算高效、收敛快,但对初始质心敏感,仅适用于凸形簇。
典型应用:图像分割、客户分群、模式识别。
2. 欧氏聚类(基于欧氏距离的密度聚类)
定义:通过欧氏距离阈值(eps)和最小邻居数(min_points)分割点云数据,识别密集区域。
算法流程:
1)初始化:所有点标记为未访问。
2)扩展簇:
- 任选未访问点,检索其 eps 邻域内的所有点(含自身)。
- 若邻居数 ≥ min_points,则标记为新簇,并递归检查邻居的邻居。
3)终止:所有点被访问后,孤立点(邻居数 < min_points)标记为噪声。特点:无需预设簇数,可识别任意形状簇,但对参数(eps、min_points)敏感。
典型应用:
三维点云分割:如建筑扫描中分离房间或自动驾驶中区分车辆/行人。
噪声过滤:剔除孤立点或小簇,提升数据质量。3. DBSCAN 聚类(Density-Based Spatial Clustering of Applications with Noise)
定义:基于密度的聚类算法,可发现任意形状簇并自动标记噪声。
核心概念:
1)核心点:某点的 ε 邻域内至少包含 min_points个点。
2)密度直达:若点 q 在核心点 p 的 ε 邻域内,则 q 从 p 密度直达。
3)密度可达:若存在点链使相邻点满足密度直达关系,则链首尾两点密度可达。
4)聚类形成:从任一核心点出发,递归合并所有密度可达的点,形成簇。
5)噪声点:未被任何簇包含的点。特点:抗噪声、无需预设簇数,但对高维数据性能下降。
总结对比
| 算法 | 核心思想 | 形状适应性 | 噪声处理 | 参数需求 |
| K-means | 距离优化(质心迭代) | 凸形簇 | 无 | 需预设簇数 K |
| 欧氏聚类 | 密度阈值(eps + min_points) | 任意形状 | 标记噪声 | 需调参 eps/min_points |
| DBSCAN | 密度可达性 | 任意形状 | 自动识别噪声 | 需调参 ε/min_points |
本次使用的数据依然是我们的兔砸!!!!!!!!(破音)
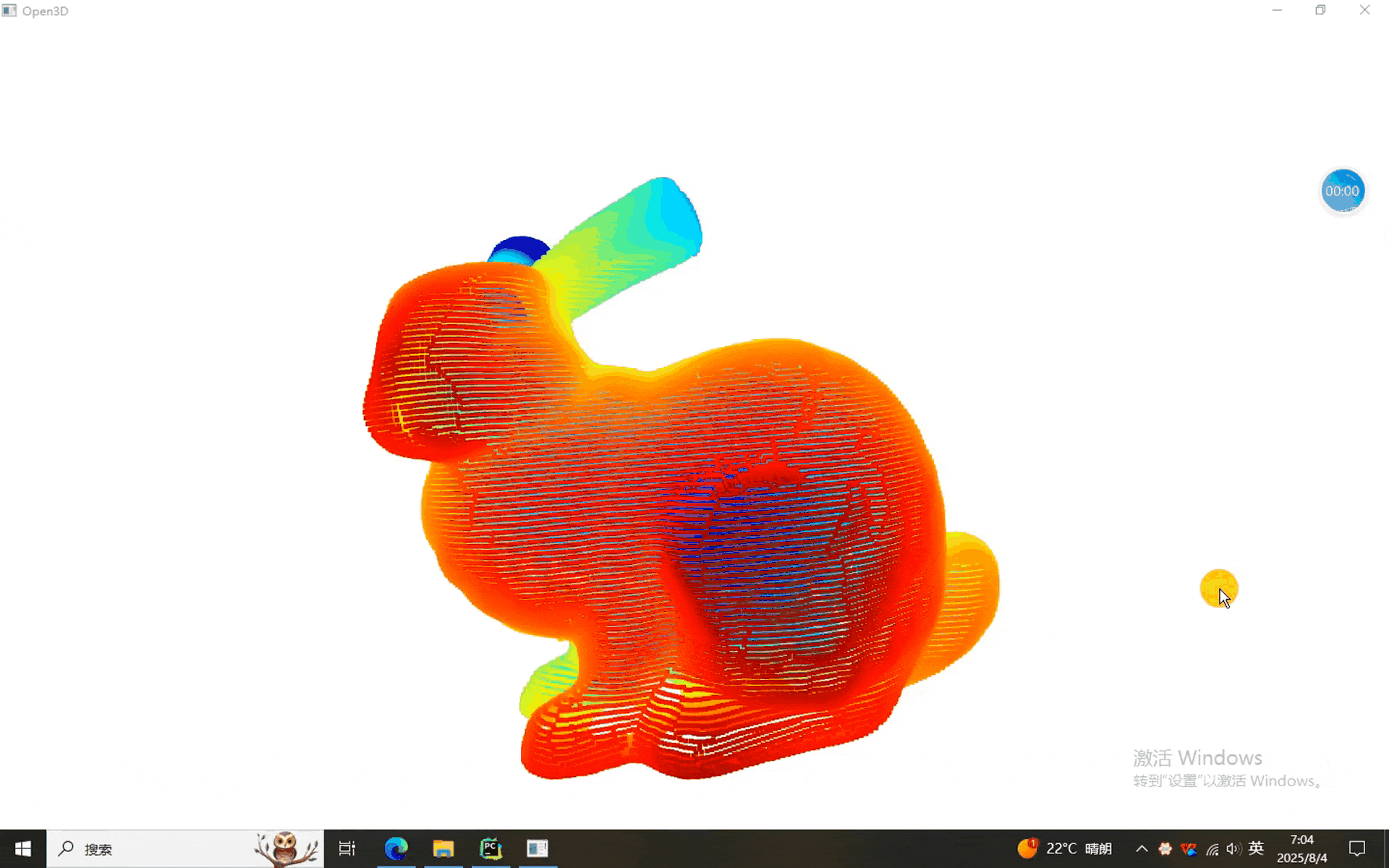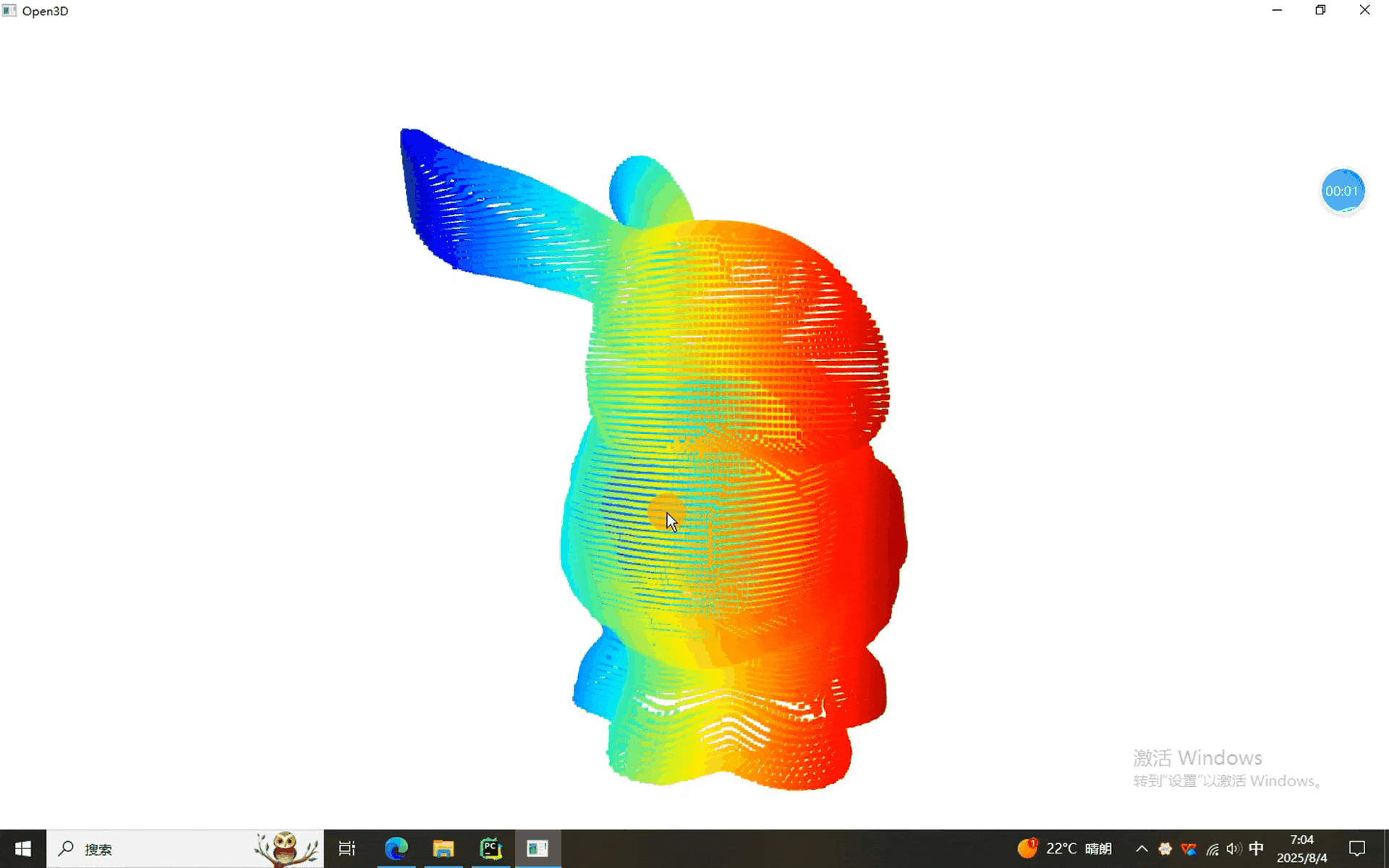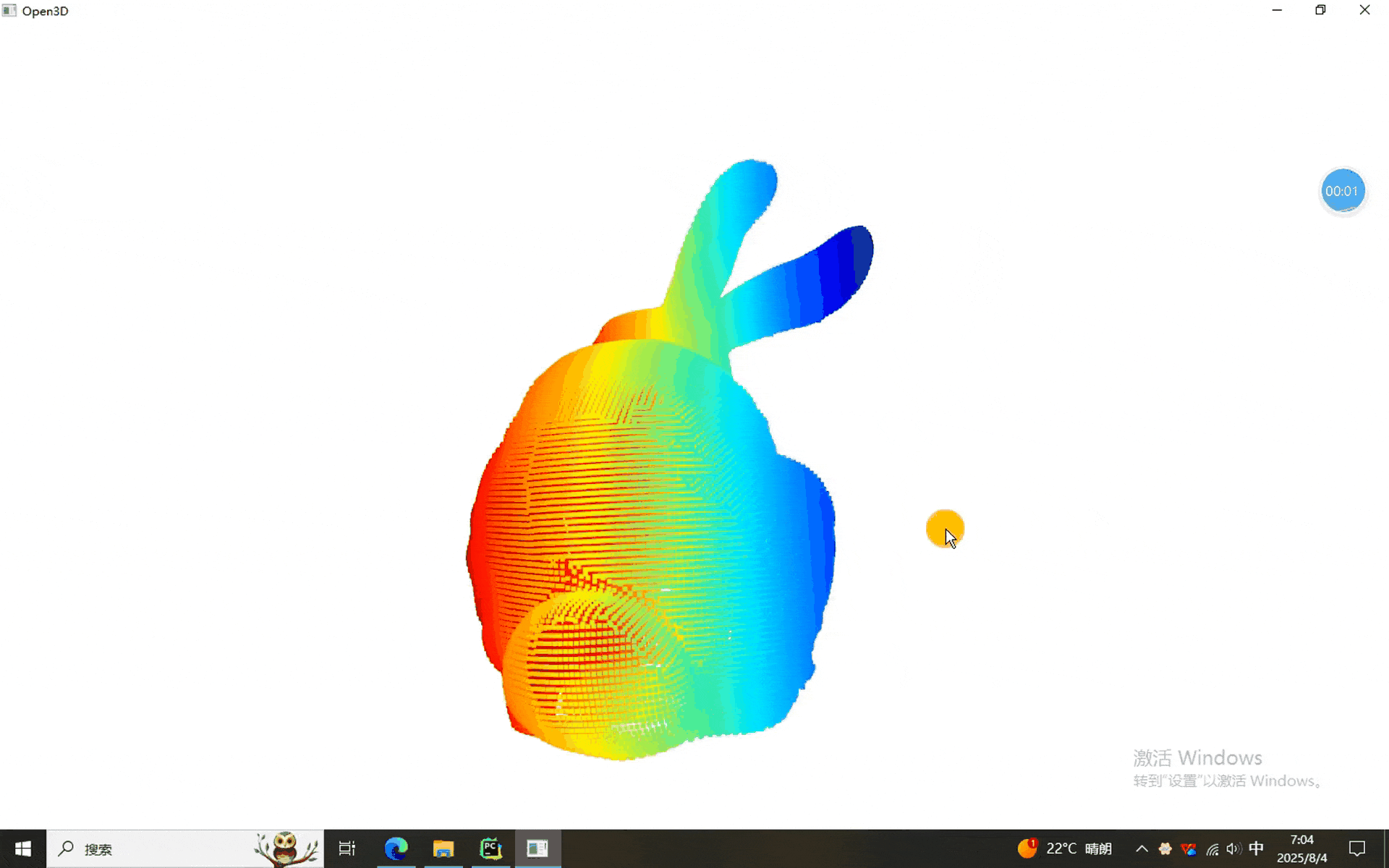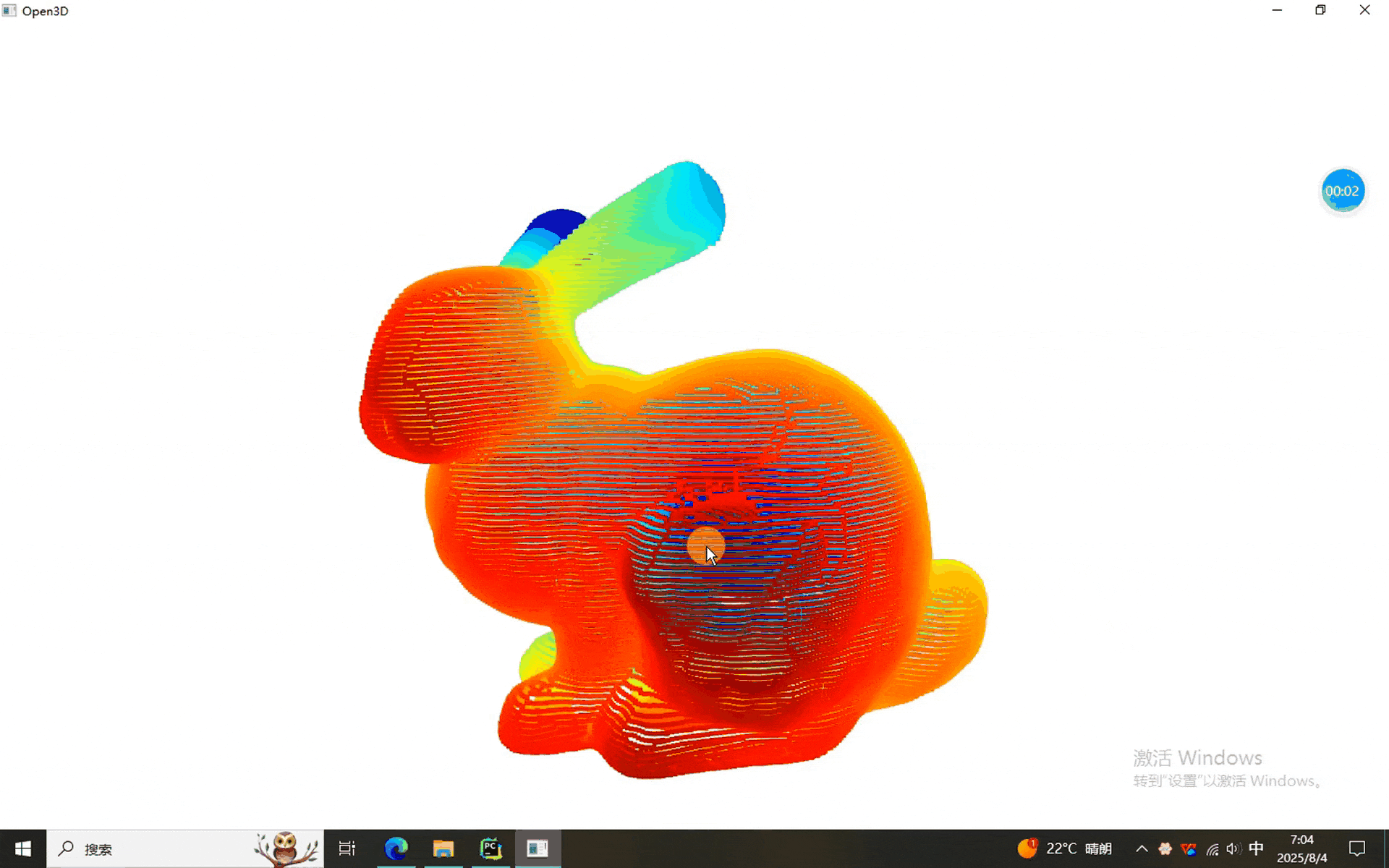
一、Kmeans、欧式和DBSCAN聚类程序
from moviepy.editor import VideoFileClip
import os
import math
import subprocessdef mp4_to_gif(src_file, target_file):# 使用VideoFileClip加载MP4文件video_clip = VideoFileClip(src_file)# 调整视频的尺寸,如果需要的话video_size_w = math.ceil(video_clip.size[0] / 0.9)video_size_h = math.ceil(video_clip.size[1] / 0.9)video_clip = video_clip.resize((video_size_w, video_size_h))# 将视频转换为GIFvideo_clip.write_gif(target_file, fps=10) # 设置帧率,可以根据需要调整# 关闭视频剪辑对象video_clip.close()def shrink_gif(file):# subprocess.run(["D:/gifsicle/gifsicle.exe", "-b", "-O2", "--lossy=40", "--colors=256", file])subprocess.run(["D:/gif_ya_suo/gifsicle-1.95-win64/gifsicle.exe","-b", "-O2", "--lossy=40","--colors=256", file])# video_path = 'E:/CSDN/视频/1_点云读写/随机颜色_1.mp4'
# target_folder = 'E:/CSDN/视频/1_点云读写/随机颜色_1.gif'original_folder = 'E:/CSDN/视频/23_Kmeans+ou+DBSCAN聚类/1'
target_folder = original_folder
for filename in os.listdir(original_folder):# 检查文件名是否包含旧字符串if '.mp4' in filename:src_filepath = os.path.join(original_folder, filename)target_filepath = os.path.join(target_folder, filename.replace('mp4', 'gif'))print(src_filepath)mp4_to_gif(src_filepath, target_filepath) # 将mp4转为gifshrink_gif(target_filepath) # 压缩gif# break
print("All files done.")记得运行上述程序是需要安装库的哦,不是程序里面的sklearn,是scikit-learn。不知道怎么安装的同学可以看往期的分享,这里就不着重说了。
pip install scikit-learn二、Kmeans、欧式和DBSCAN聚类结果
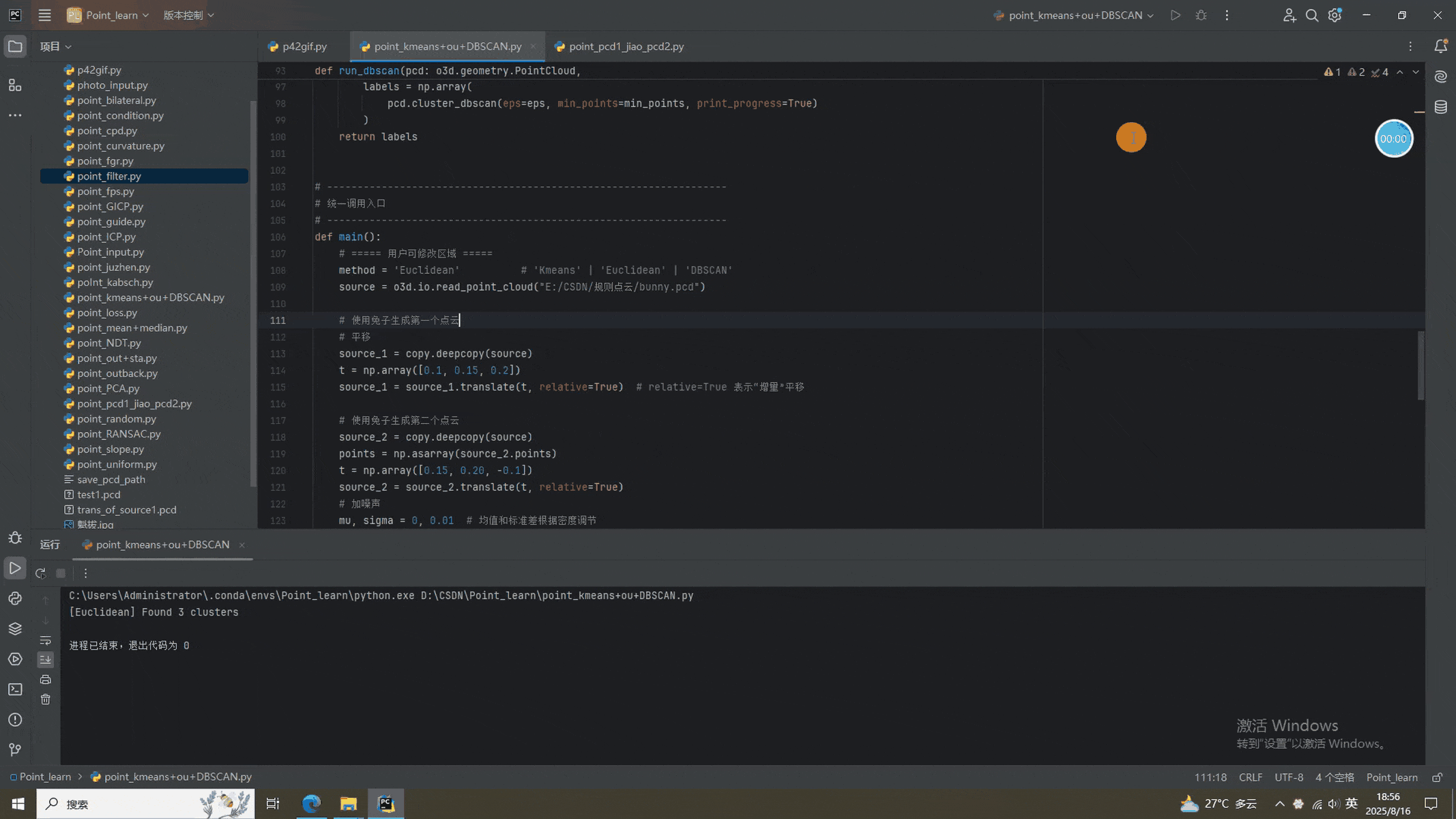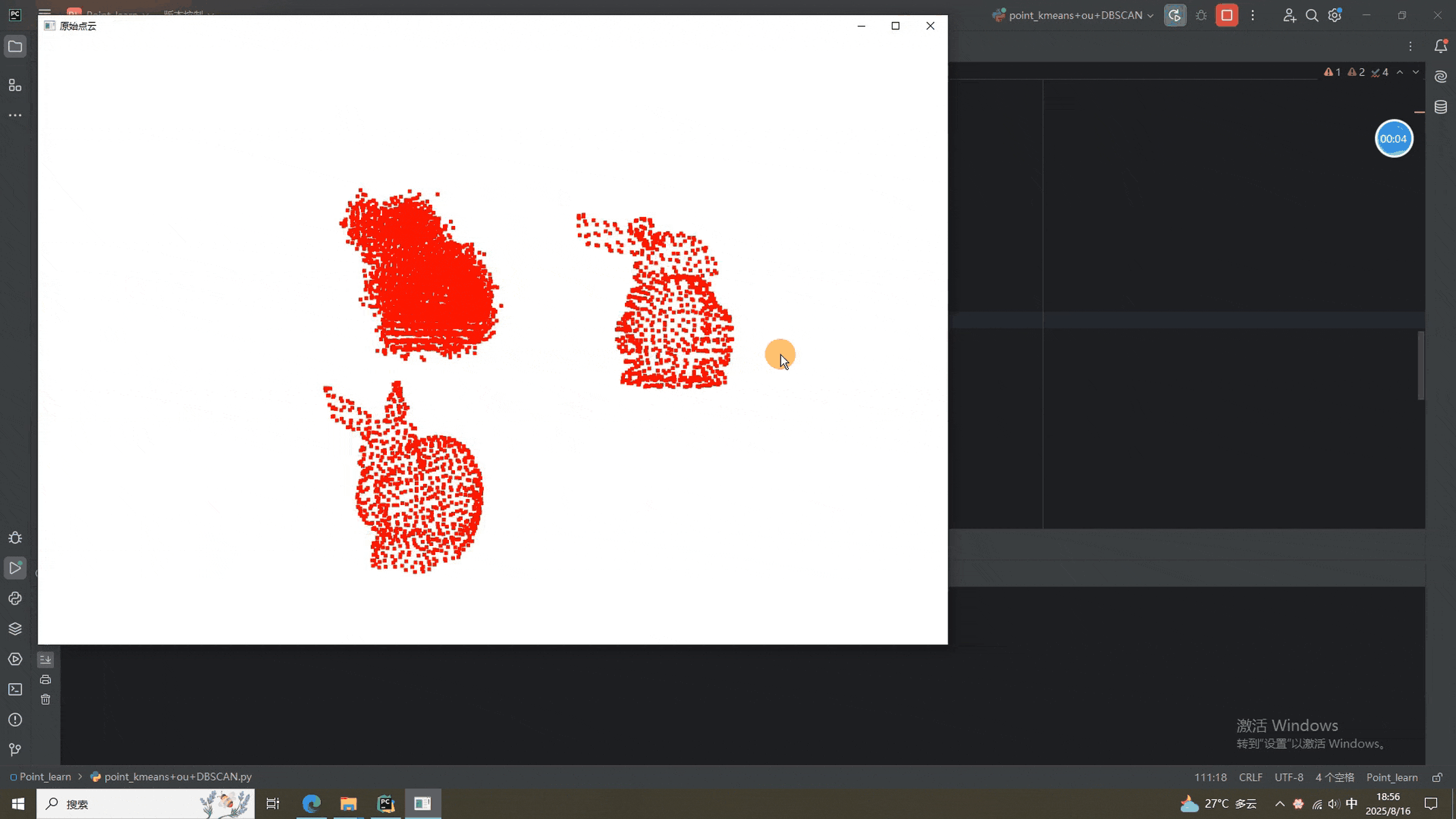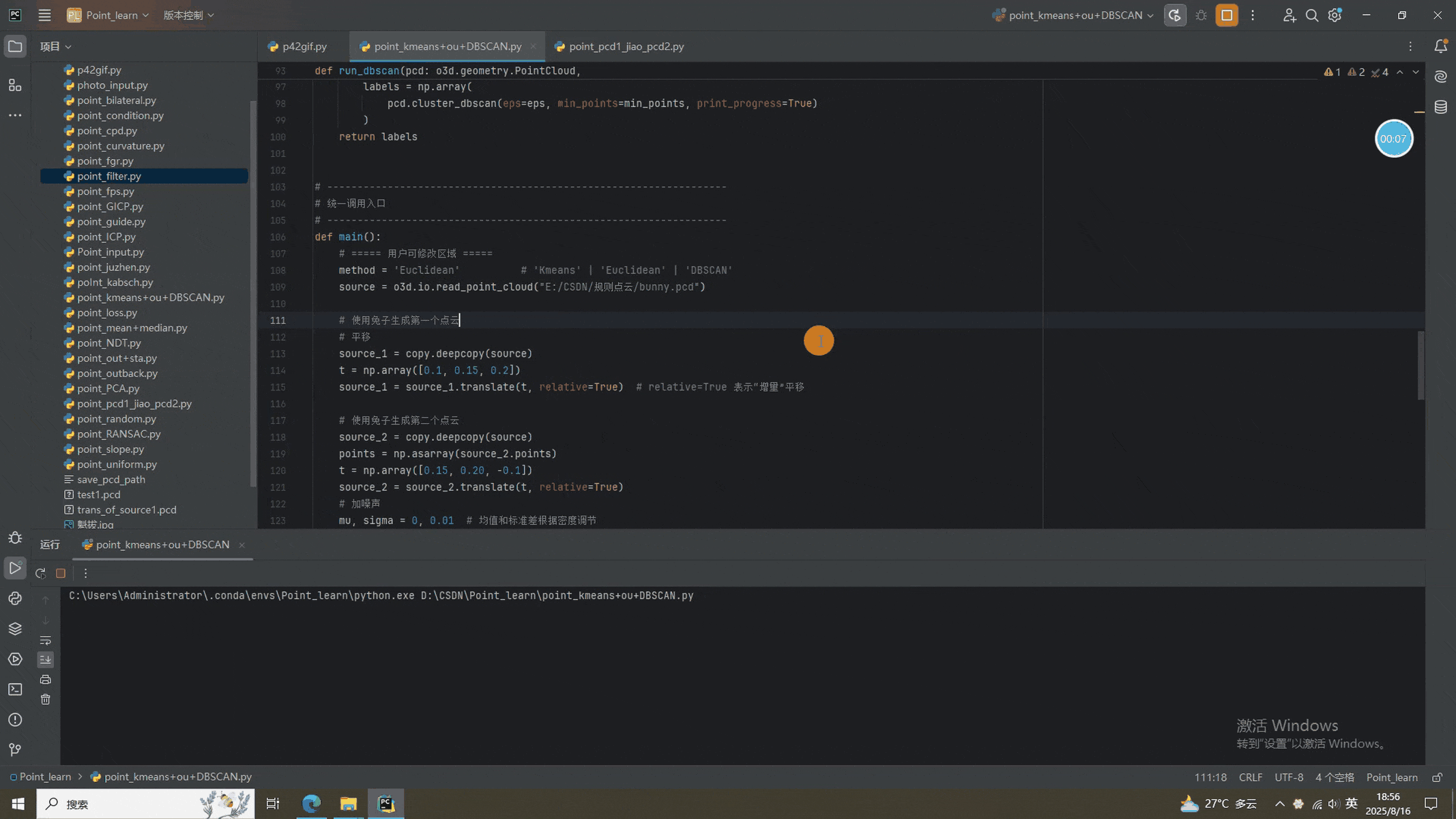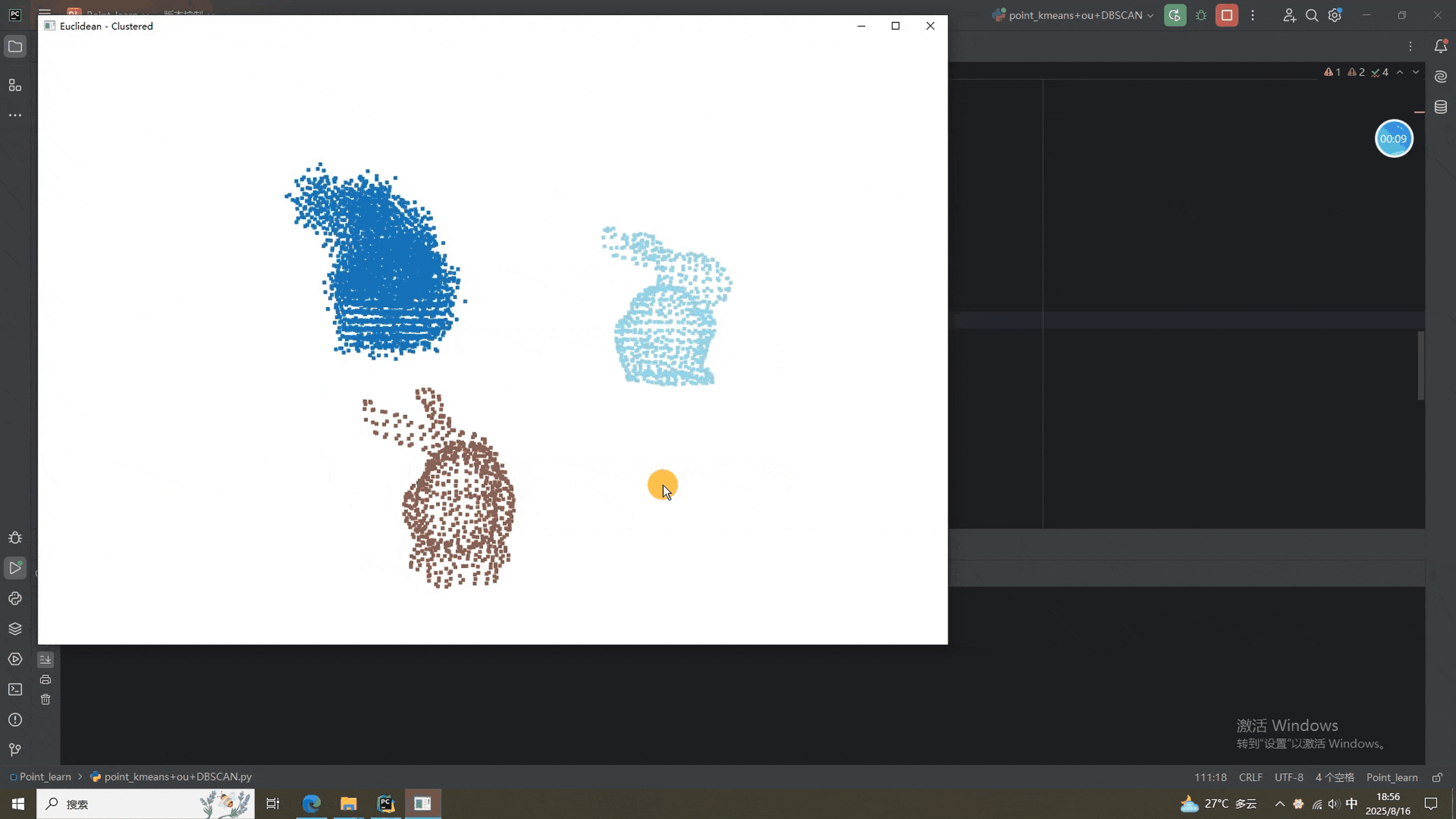
从结果来看,三个兔砸可以正常的分割。换其他点云的时候记得调节参数啊,前面表格里有详细的说明。就酱,下次见^-^









)
)

安全管理(3)-行级访问控制)
的核心区别,以及 Wi-Fi 技术未来的发展方向)

进阶)》)
)


)