文章目录
- 一、OpenNMT(Neural Machine Translation,NMT)
- 1. 概述
- 2. 核心特性
- 3. 系统架构
- 4. 与其他翻译工具的区别
- 二、基于 OpenNMT-py 的机器翻译框架
- 1. 环境配置(以OpenNMT-py版本为例)
- (1)pip安装:pip install OpenNMT-py
- (2)源码安装
- 2. 模型选择
- 三、通过 Hugging Face 调用 MarianMT 模型
- (1)环境配置
- (2)本地翻译工具 —— 输入固定文本
- (3)本地翻译工具 —— 支持多种文档输入(TXT、PDF、Word)
- (4)本地翻译工具(图形界面版本) —— 只支持文本输入
- (5)本地翻译工具(图形界面版本) —— 支持文本输入 + 多种文档输入(TXT、PDF、Word)
一、OpenNMT(Neural Machine Translation,NMT)
官方网站:https://opennmt.net/
1. 概述
OpenNMT(Open Neural Machine Translation)是一个开源的神经机器翻译(NMT)框架,最初由 Harvard NLP 实验室与 Systran 团队合作开发,目标是提供高性能、可扩展、可定制、可本地部署的翻译模型训练与推理工具,既适合科研,也适合工业应用。
需要注意:
- OpenNMT不是桌面翻译软件
- 它本身没有GUI界面,也没有即点即用的翻译功能。
- 功能核心是训练、评估和推理神经机器翻译模型。
- 用户需要通过命令行或Python API来调用模型完成翻译任务。
- OpenNMT没有官方预训练模型
- 框架只提供模型结构(Transformer、LSTM、GRU)、训练与推理工具。
- 要进行实际翻译,需要用户:自行训练模型(用平行语料)或下载第三方社区预训练模型(Hugging Face、GitHub等)
- 官方仓库提供的示例模型仅供学习和验证流程,通常翻译质量有限。
2. 核心特性
| 特性 | 详细说明 |
|---|---|
| 开源协议 | 采用 MIT License,完全免费,可商用,无使用限制。 |
| 部署方式 | 支持本地离线部署(不依赖云服务),也可在服务器、集群、GPU加速环境运行。 |
| 语言支持 | 理论上支持任意语言对,只要提供平行语料;可处理翻译、文本生成、摘要等任务。 |
| 多框架支持 | 提供两个实现版本: ① OpenNMT-py(PyTorch版)——更新活跃、易于定制。② OpenNMT-tf(TensorFlow版)——适合生产部署。 |
| 模型架构 | 支持多种深度学习结构: ① Transformer(高精度主流架构) ② LSTM / GRU(适合低资源环境) ③ CNN encoder-decoder(实验性) |
| 扩展性 | 可自定义数据预处理、分词、词表、模型层数、注意力机制、损失函数等。 |
| 训练模式 | 支持从零训练、增量训练(fine-tuning)、迁移学习、多GPU分布式训练。 |
| 推理模式 | 支持批量翻译、交互式翻译、服务器API模式(REST API / gRPC)。 |
| 性能优化 | 支持混合精度训练(FP16)、动态batch、beam search解码、缓存机制。 |
3. 系统架构
OpenNMT采用典型的Encoder-Decoder结构:
[输入文本] → [分词/子词编码] → [Encoder] → [Attention] → [Decoder] → [输出文本]"""
Encoder(编码器):将源语言文本转为上下文表示(embedding序列)。
Attention(注意力机制):在解码时动态关注源文本的不同部分。
Decoder(解码器):生成目标语言文本,逐步输出token。
Beam Search:在解码过程中保留多个候选,提高翻译质量。
"""
4. 与其他翻译工具的区别
| 工具 | 部署方式 | 模型可定制性 | 是否需联网 | 适合人群 |
|---|---|---|---|---|
| Google Translate | 云端API | 不可定制 | 必须联网 | 普通用户 |
| DeepL | 云端API/客户端 | 不可定制 | 必须联网 | 普通用户 |
| Marian NMT | 本地部署 | 高 | 可离线 | 开发者、研究者 |
| OpenNMT | 本地部署 | 非常高 | 可离线 | 研究人员、企业 |
二、基于 OpenNMT-py 的机器翻译框架
1. 环境配置(以OpenNMT-py版本为例)
https://github.com/OpenNMT/OpenNMT-py
# 基本环境:
Python >= 3.8
PyTorch >= 2.0 <2.2# 虚拟环境配置:
conda create -n opennmt -y
conda activate opennmt
(1)pip安装:pip install OpenNMT-py
(2)源码安装
git clone https://github.com/OpenNMT/OpenNMT-py.git
cd OpenNMT-py
pip install -e .
###############################################################
# (1)部分高级功能(例如工作预处理的模型或特定的转换)需要额外的包装
# pip install -r requirements.opt.txt
###############################################################
# (2)强烈建议手动安装APEX,其具有快速的性能(尤其是传统的Fusedadam Optimizer和Fusedrmsnorm)
# git clone https://github.com/NVIDIA/apex
# cd apex
# pip3 install -v --no-build-isolation --config-settings --build-option="--cpp_ext --cuda_ext --deprecated_fused_adam --xentropy --fast_multihead_attn" ./
# cd ..
###############################################################
2. 模型选择
通过 Hugging Face 下载开源模型
| 分类 | 情况说明 |
|---|---|
| 官方 | OpenNMT 官方仓库不直接发布预训练权重,只给出示例数据(如 WMT 数据集),示例模型只是演示用,翻译效果有限。 |
| 社区 | 社区有人在 Hugging Face、GitHub 上传基于 OpenNMT 训练好的权重(例如英-法、英-中等),但质量和数据来源需要自己验证。 |
| 替代方案 | 如果想直接用现成的高质量模型,可以考虑 MarianMT(Hugging Face)、M2M-100(Facebook)等,它们都是开箱即用的翻译模型,不必自己训练。 |
| 本地部署 | 如果一定要本地离线运行高质量翻译模型,可以通过 Hugging Face Transformers 加载 MarianMT 或 M2M-100,再结合 OpenNMT 的数据处理流程做微调。 |
三、通过 Hugging Face 调用 MarianMT 模型
下面给出一个基于 Hugging Face Transformers + MarianMT(或 M2M100)的本地论文翻译完整流程,无需依赖 OpenNMT 的自行训练,可以直接离线推理。
| 模型类型 | 模型示例(Hugging Face) | 支持语种 | 优点 | 缺点 |
|---|---|---|---|---|
| MarianMT | Helsinki-NLP/opus-mt-en-zh | 双语对(英2中) | 速度快、模型小、易部署 | 需要为每个语对下载单独模型 |
| M2M100 | facebook/m2m100_418M | 多语种 | 一个模型支持多语言 | 占用显存和磁盘较大 |
(1)环境配置
# 虚拟环境配置:
conda create -n translation -y
conda activate translation
############################################
cd translation
Python >= 3.8
# CPU:pip install torch -i https://pypi.tuna.tsinghua.edu.cn/simple
# GPU:pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
pip install transformers sentencepiece PyMuPDF python-docx reportlab -i https://pypi.tuna.tsinghua.edu.cn/simple"""说明:
torch PyTorch 深度学习框架,模型推理
transformers Hugging Face 模型库
sentencepiece 分词器,支持 BPE 模型
PyMuPDF PDF 文本提取
python-docx Word 文档处理
reportlab PDF 写入生成
"""
(2)本地翻译工具 —— 输入固定文本
import os
import torch
from transformers import MarianMTModel, MarianTokenizerMODEL_NAME = "Helsinki-NLP/opus-mt-en-zh" # 英->中
LOCAL_MODEL_DIR = r"./opus_mt_model" # 本地模型存放目录device = "cuda" if torch.cuda.is_available() else "cpu"def is_model_complete(model_dir):"""检查本地模型目录是否包含必要文件"""required_files = ["config.json", "source.spm", "target.spm", "pytorch_model.bin"]return all(os.path.exists(os.path.join(model_dir, f)) for f in required_files)def load_model():"""加载本地 MarianMT 模型,如果缺失则自动下载。返回:tokenizer, model"""global deviceif os.path.exists(LOCAL_MODEL_DIR) and is_model_complete(LOCAL_MODEL_DIR):print(f"检测到完整本地模型:{LOCAL_MODEL_DIR},加载中...")tokenizer = MarianTokenizer.from_pretrained(LOCAL_MODEL_DIR)model = MarianMTModel.from_pretrained(LOCAL_MODEL_DIR).to(device)else:print("本地模型不完整或不存在,开始下载 MarianMT 模型...")tokenizer = MarianTokenizer.from_pretrained(MODEL_NAME, cache_dir=LOCAL_MODEL_DIR)model = MarianMTModel.from_pretrained(MODEL_NAME, cache_dir=LOCAL_MODEL_DIR).to(device)print(f"模型已下载完成,可将目录 '{LOCAL_MODEL_DIR}' 移动到脚本目录实现离线加载。")return tokenizer, model# -----------------------------
# 测试加载
# -----------------------------
if __name__ == "__main__":tokenizer, model = load_model()text = ["Deep learning significantly improves image recognition performance."]inputs = tokenizer(text, return_tensors="pt", padding=True).to(device)translated = model.generate(**inputs)print("翻译结果:", [tokenizer.decode(t, skip_special_tokens=True) for t in translated])
模型下载后的文件目录
# opus_mt_model/
# ├─ models--Helsinki-NLP--opus-mt-en-zh/
# │ ├─ blobs/
# │ ├─ refs/
# │ └─ snapshots/
# │ └─ 408d9bc410a388e1d9aef112a2daba955b945255/
# │ ├─ config.json
# │ ├─ generation_config.json
# │ ├─ pytorch_model.bin
# │ ├─ source.spm
# │ ├─ target.spm
# │ ├─ tokenizer_config.json
# │ └─ vocab.json"""将【路径1】中所有文件复制或剪贴到【路径2】下,即可实现自动识别本地模型。
【路径1】LOCAL_MODEL_DIR = r".\opus_mt_model\models--Helsinki-NLP--opus-mt-en-zh\snapshots\408d9bc410a388e1d9aef112a2daba955b945255"
【路径2】LOCAL_MODEL_DIR = r"./opus_mt_model"
"""
(3)本地翻译工具 —— 支持多种文档输入(TXT、PDF、Word)
#####################################################################################
# 本地论文翻译工具(支持 TXT / PDF / Word)
# 功能概述:
# 1. 模型管理:自动检测本地 MarianMT 模型,首次运行会下载模型,并提示移动到脚本目录以实现离线使用
# 2. 运行环境:自动检测 GPU/CPU,GPU 可加速推理,CPU 可运行但速度较慢
# 3. 输入输出格式:支持 TXT、PDF、Word,输出与输入格式保持一致
# 4. 批量处理:可在 input_files 中添加多个文件,循环处理
# 5. 可扩展性:
# - 可替换 MarianMT 为 M2M100,实现多语种翻译
# - 可增加 PDF 原排版保留功能,保持段落、标题和表格样式
#####################################################################################import os
import torch
from transformers import MarianMTModel, MarianTokenizer# PDF/Word 处理
import fitz # PyMuPDF
from docx import Document
from reportlab.pdfgen import canvas
from reportlab.lib.pagesizes import letter# -----------------------------
# 1. 配置模型
# -----------------------------
MODEL_NAME = "Helsinki-NLP/opus-mt-en-zh" # 英->中
LOCAL_MODEL_DIR = "./opus_mt_model" # 本地模型存放目录device = "cuda" if torch.cuda.is_available() else "cpu"# -----------------------------
# 2. 加载模型
# -----------------------------
def load_model():global tokenizer, model# 检查本地模型是否存在if os.path.exists(LOCAL_MODEL_DIR):print(f"加载本地模型: {LOCAL_MODEL_DIR}")tokenizer = MarianTokenizer.from_pretrained(LOCAL_MODEL_DIR)model = MarianMTModel.from_pretrained(LOCAL_MODEL_DIR).to(device)else:print("本地模型不存在,首次运行需要下载模型,请耐心等待...")tokenizer = MarianTokenizer.from_pretrained(MODEL_NAME, cache_dir=LOCAL_MODEL_DIR)model = MarianMTModel.from_pretrained(MODEL_NAME, cache_dir=LOCAL_MODEL_DIR).to(device)print(f"模型已下载到默认缓存目录,请将 {LOCAL_MODEL_DIR} 移动到当前脚本目录,以便离线使用。")return tokenizer, model# -----------------------------
# 3. 文本翻译函数
# -----------------------------
def translate_text(text_list, batch_size=8):results = []for i in range(0, len(text_list), batch_size):batch = text_list[i:i+batch_size]inputs = tokenizer(batch, return_tensors="pt", padding=True, truncation=True).to(device)translated = model.generate(**inputs, max_length=1024)decoded = [tokenizer.decode(t, skip_special_tokens=True) for t in translated]results.extend(decoded)return results# -----------------------------
# 4. PDF 文本提取/保存
# -----------------------------
def pdf_to_text(pdf_path):doc = fitz.open(pdf_path)paragraphs = []for page in doc:paragraphs.extend(page.get_text("text").split("\n"))paragraphs = [p.strip() for p in paragraphs if p.strip()]return paragraphsdef text_to_pdf(text_list, out_pdf_path):c = canvas.Canvas(out_pdf_path, pagesize=letter)width, height = lettery = height - 50for para in text_list:lines = []while len(para) > 0:lines.append(para[:100])para = para[100:]for line in lines:c.drawString(50, y, line)y -= 15if y < 50:c.showPage()y = height - 50c.save()# -----------------------------
# 5. Word 文本提取/保存
# -----------------------------
def docx_to_text(docx_path):doc = Document(docx_path)paragraphs = [p.text.strip() for p in doc.paragraphs if p.text.strip()]return paragraphsdef text_to_docx(text_list, out_docx_path):doc = Document()for para in text_list:doc.add_paragraph(para)doc.save(out_docx_path)# -----------------------------
# 6. TXT 文本处理
# -----------------------------
def txt_to_text(txt_path):with open(txt_path, "r", encoding="utf-8") as f:paragraphs = [line.strip() for line in f.readlines() if line.strip()]return paragraphsdef text_to_txt(text_list, out_txt_path):with open(out_txt_path, "w", encoding="utf-8") as f:for para in text_list:f.write(para + "\n")# -----------------------------
# 7. 主函数:翻译文件
# -----------------------------
def translate_file(input_path, output_path=None):ext = os.path.splitext(input_path)[1].lower()if ext == ".pdf":paragraphs = pdf_to_text(input_path)elif ext in [".docx", ".doc"]:paragraphs = docx_to_text(input_path)elif ext in [".txt"]:paragraphs = txt_to_text(input_path)else:raise ValueError(f"不支持的文件格式: {ext}")# 翻译文本translated_paras = translate_text(paragraphs)# 输出路径if output_path is None:base, extname = os.path.splitext(input_path)output_path = f"{base}_translated{extname}"# 根据类型保存if ext == ".pdf":text_to_pdf(translated_paras, output_path)elif ext in [".docx", ".doc"]:text_to_docx(translated_paras, output_path)elif ext == ".txt":text_to_txt(translated_paras, output_path)print(f"翻译完成,已保存至: {output_path}")# -----------------------------
# 8. 示例运行
# -----------------------------
if __name__ == "__main__":load_model() # 加载或下载模型input_files = ["../paper/example.pdf","../paper/example.docx","../paper/example.txt"]for file in input_files:if os.path.exists(file):translate_file(file)else:print(f"文件不存在: {file}")
(4)本地翻译工具(图形界面版本) —— 只支持文本输入
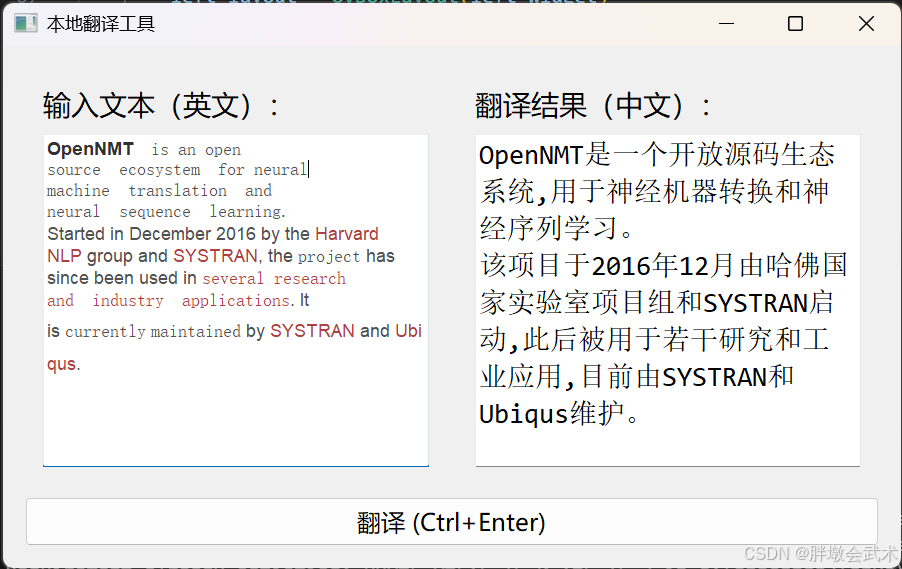
"""
功能特点
首次运行联网下载模型,下次启动直接用本地缓存。
离线可用,支持 GPU/CPU 自动切换。
实时翻译(键盘停止输入 0.5 秒自动翻译)。
双栏布局:左输入、右输出,方便对照。
批量翻译段落(按换行分段)。
"""
import os
import sys
import torch
from PyQt5.QtWidgets import (QApplication, QWidget, QHBoxLayout, QVBoxLayout, QTextEdit,QPushButton, QLabel, QSplitter
)
from PyQt5.QtCore import Qt
from transformers import MarianMTModel, MarianTokenizer# -----------------------------
# 配置模型
# -----------------------------
MODEL_NAME = "Helsinki-NLP/opus-mt-en-zh"
LOCAL_MODEL_DIR = r"./opus_mt_model"
device = "cuda" if torch.cuda.is_available() else "cpu"# -----------------------------
# 加载模型
# -----------------------------
def load_model():global tokenizer, modelif os.path.exists(LOCAL_MODEL_DIR):print(f"加载本地模型: {LOCAL_MODEL_DIR}")tokenizer = MarianTokenizer.from_pretrained(LOCAL_MODEL_DIR)model = MarianMTModel.from_pretrained(LOCAL_MODEL_DIR).to(device)else:print("首次运行,正在下载模型...")tokenizer = MarianTokenizer.from_pretrained(MODEL_NAME, cache_dir=LOCAL_MODEL_DIR)model = MarianMTModel.from_pretrained(MODEL_NAME, cache_dir=LOCAL_MODEL_DIR).to(device)print(f"模型已下载到缓存: {LOCAL_MODEL_DIR}")return tokenizer, model# -----------------------------
# 翻译函数
# -----------------------------
def translate_text(text_list, batch_size=8):results = []for i in range(0, len(text_list), batch_size):batch = text_list[i:i+batch_size]inputs = tokenizer(batch, return_tensors="pt", padding=True, truncation=True).to(device)translated = model.generate(**inputs, max_length=1024)decoded = [tokenizer.decode(t, skip_special_tokens=True) for t in translated]results.extend(decoded)return results# -----------------------------
# GUI 界面
# -----------------------------
class TranslatorGUI(QWidget):def __init__(self):super().__init__()self.init_ui()def init_ui(self):self.setWindowTitle("本地翻译工具")self.resize(1200, 700)# 主布局main_layout = QVBoxLayout(self)# 分割器实现左右布局splitter = QSplitter(Qt.Horizontal)# 左侧:输入文本left_widget = QWidget()left_layout = QVBoxLayout(left_widget)self.input_label = QLabel("输入文本(英文):")self.input_label.setStyleSheet("font: 14pt '微软雅黑';")left_layout.addWidget(self.input_label)self.input_box = QTextEdit()self.input_box.setStyleSheet("font: 14pt 'Consolas';")left_layout.addWidget(self.input_box)splitter.addWidget(left_widget)# 右侧:输出文本right_widget = QWidget()right_layout = QVBoxLayout(right_widget)self.output_label = QLabel("翻译结果(中文):")self.output_label.setStyleSheet("font: 14pt '微软雅黑';")right_layout.addWidget(self.output_label)self.output_box = QTextEdit()self.output_box.setStyleSheet("font: 14pt 'Consolas';")self.output_box.setReadOnly(True)right_layout.addWidget(self.output_box)splitter.addWidget(right_widget)splitter.setSizes([600, 600])main_layout.addWidget(splitter)# 按钮布局self.translate_btn = QPushButton("翻译 (Ctrl+Enter)")self.translate_btn.setStyleSheet("font: 12pt '微软雅黑'; padding:8px;")self.translate_btn.clicked.connect(self.on_translate)main_layout.addWidget(self.translate_btn)# 快捷键self.input_box.keyPressEvent = self.key_press_eventdef key_press_event(self, event):# Ctrl+Enter 翻译if event.key() == Qt.Key_Return and (event.modifiers() & Qt.ControlModifier):self.on_translate()else:QTextEdit.keyPressEvent(self.input_box, event)def on_translate(self):src_text = self.input_box.toPlainText().strip()if not src_text:returnparagraphs = [line.strip() for line in src_text.split("\n") if line.strip()]translated_paras = translate_text(paragraphs)self.output_box.setPlainText("\n".join(translated_paras))# -----------------------------
# 主程序
# -----------------------------
if __name__ == "__main__":tokenizer, model = load_model()app = QApplication(sys.argv)gui = TranslatorGUI()gui.show()sys.exit(app.exec_())(5)本地翻译工具(图形界面版本) —— 支持文本输入 + 多种文档输入(TXT、PDF、Word)
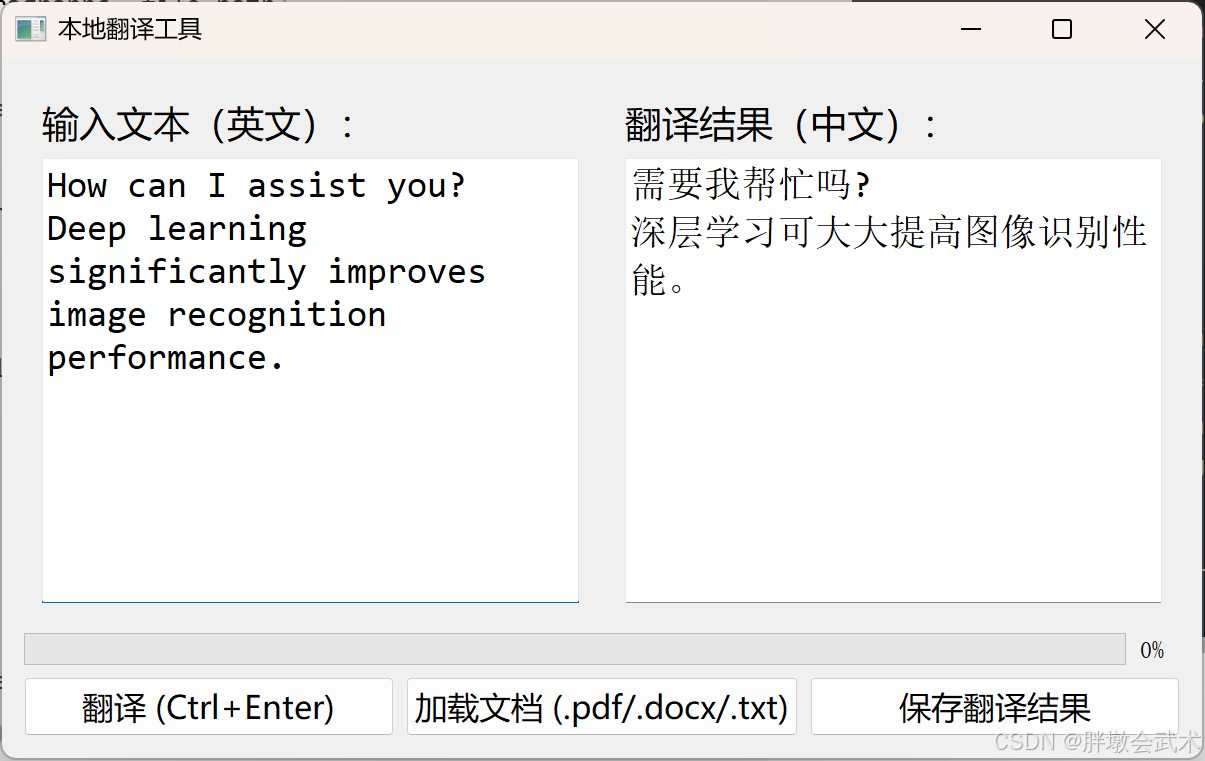
- 不支持保存为pdf格式
- 加载文档的翻译模式(局限性),是将其转换为文本,然后翻译。
- 文本/文档翻译是有输入上限的,因此需要分阶段/拆分翻译!!!
- MarianMTModel不支持图像中的文字翻译
import sys
import os
import torch
from PyQt5.QtWidgets import (QApplication, QWidget, QHBoxLayout, QVBoxLayout, QTextEdit,QPushButton, QLabel, QSplitter, QFileDialog, QMessageBox,QProgressBar
)
from PyQt5.QtCore import Qt, QThread, pyqtSignal
from transformers import MarianMTModel, MarianTokenizer
from docx import Document
from reportlab.pdfgen import canvas
from reportlab.lib.pagesizes import A4
from reportlab.pdfbase import pdfmetrics
from reportlab.pdfbase.ttfonts import TTFont# -----------------------------
# 模型配置
# -----------------------------
MODEL_NAME = "Helsinki-NLP/opus-mt-en-zh"
LOCAL_MODEL_DIR = r"./opus_mt_model"
device = "cuda" if torch.cuda.is_available() else "cpu"# -----------------------------
# 加载模型
# -----------------------------
def load_model():global tokenizer, modelif os.path.exists(LOCAL_MODEL_DIR):print(f"加载本地模型: {LOCAL_MODEL_DIR}")tokenizer = MarianTokenizer.from_pretrained(LOCAL_MODEL_DIR)model = MarianMTModel.from_pretrained(LOCAL_MODEL_DIR).to(device)else:print("首次运行,正在下载模型...")tokenizer = MarianTokenizer.from_pretrained(MODEL_NAME, cache_dir=LOCAL_MODEL_DIR)model = MarianMTModel.from_pretrained(MODEL_NAME, cache_dir=LOCAL_MODEL_DIR).to(device)print(f"模型已下载到缓存: {LOCAL_MODEL_DIR}")return tokenizer, model# -----------------------------
# 文本翻译函数(支持批量)
# -----------------------------
def translate_text(text_list, batch_size=8, progress_callback=None):results = []total = len(text_list)for i in range(0, total, batch_size):batch = text_list[i:i+batch_size]inputs = tokenizer(batch, return_tensors="pt", padding=True, truncation=True).to(device)translated = model.generate(**inputs, max_length=1024)decoded = [tokenizer.decode(t, skip_special_tokens=True) for t in translated]results.extend(decoded)if progress_callback:progress_callback(min(i+batch_size, total), total)return results# -----------------------------
# 文档处理函数
# -----------------------------
def docx_to_text(docx_path):doc = Document(docx_path)return [p.text.strip() for p in doc.paragraphs if p.text.strip()]def text_to_docx(text_list, out_docx_path):doc = Document()for para in text_list:doc.add_paragraph(para)doc.save(out_docx_path)def txt_to_text(txt_path):with open(txt_path, "r", encoding="utf-8") as f:return [line.strip() for line in f.readlines() if line.strip()]def text_to_txt(text_list, out_txt_path):with open(out_txt_path, "w", encoding="utf-8") as f:for para in text_list:f.write(para + "\n")def pdf_to_text(pdf_path):try:import fitzdoc = fitz.open(pdf_path)paragraphs = []for page in doc:paragraphs.extend(page.get_text("text").split("\n"))return [p.strip() for p in paragraphs if p.strip()]except Exception:return []def text_to_pdf(text_list, out_pdf_path):try:# 注册中文字体(需系统存在SimSun.ttf或替换为其他)pdfmetrics.registerFont(TTFont("SimSun", "SimSun.ttf"))c = canvas.Canvas(out_pdf_path, pagesize=A4)width, height = A4y = height - 50for para in text_list:lines = []# 按长度换行,防止文字超出页面while len(para) > 0:lines.append(para[:50])para = para[50:]for line in lines:c.setFont("SimSun", 12)c.drawString(50, y, line)y -= 18if y < 50:c.showPage()y = height - 50c.save()except Exception as e:raise RuntimeError(f"PDF保存失败: {e}")# -----------------------------
# 翻译线程
# -----------------------------
class TranslateThread(QThread):progress_signal = pyqtSignal(int, int)finished_signal = pyqtSignal(list)def __init__(self, paragraphs):super().__init__()self.paragraphs = paragraphsdef run(self):translated = translate_text(self.paragraphs, batch_size=8, progress_callback=self.emit_progress)self.finished_signal.emit(translated)def emit_progress(self, current, total):self.progress_signal.emit(current, total)# -----------------------------
# PyQt GUI
# -----------------------------
class TranslatorGUI(QWidget):def __init__(self):super().__init__()self.init_ui()def init_ui(self):self.setWindowTitle("本地翻译工具")self.resize(1200, 700)main_layout = QVBoxLayout(self)splitter = QSplitter(Qt.Horizontal)# 左侧输入left_widget = QWidget()left_layout = QVBoxLayout(left_widget)self.input_label = QLabel("输入文本(英文):")self.input_label.setStyleSheet("font: 14pt '微软雅黑';")left_layout.addWidget(self.input_label)self.input_box = QTextEdit()self.input_box.setStyleSheet("font: 14pt 'Consolas';")left_layout.addWidget(self.input_box)splitter.addWidget(left_widget)# 右侧输出right_widget = QWidget()right_layout = QVBoxLayout(right_widget)self.output_label = QLabel("翻译结果(中文):")self.output_label.setStyleSheet("font: 14pt '微软雅黑';")right_layout.addWidget(self.output_label)self.output_box = QTextEdit()self.output_box.setStyleSheet("font: 14pt 'Consolas';")self.output_box.setReadOnly(False) # 可编辑right_layout.addWidget(self.output_box)splitter.addWidget(right_widget)splitter.setSizes([600, 600])main_layout.addWidget(splitter)# 进度条self.progress_bar = QProgressBar()self.progress_bar.setValue(0)main_layout.addWidget(self.progress_bar)# 按钮布局btn_layout = QHBoxLayout()self.translate_btn = QPushButton("翻译 (Ctrl+Enter)")self.translate_btn.setStyleSheet("font: 12pt '微软雅黑'; padding:8px;")self.translate_btn.clicked.connect(self.on_translate)btn_layout.addWidget(self.translate_btn)self.load_doc_btn = QPushButton("加载文档 (.pdf/.docx/.txt)")self.load_doc_btn.setStyleSheet("font: 12pt '微软雅黑'; padding:8px;")self.load_doc_btn.clicked.connect(self.load_document)btn_layout.addWidget(self.load_doc_btn)self.save_doc_btn = QPushButton("保存翻译结果")self.save_doc_btn.setStyleSheet("font: 12pt '微软雅黑'; padding:8px;")self.save_doc_btn.clicked.connect(self.save_document)btn_layout.addWidget(self.save_doc_btn)main_layout.addLayout(btn_layout)self.input_box.keyPressEvent = self.key_press_eventdef key_press_event(self, event):if event.key() == Qt.Key_Return and (event.modifiers() & Qt.ControlModifier):self.on_translate()else:QTextEdit.keyPressEvent(self.input_box, event)def on_translate(self):src_text = self.input_box.toPlainText().strip()if not src_text:returnparagraphs = [line.strip() for line in src_text.split("\n") if line.strip()]self.progress_bar.setValue(0)self.translate_thread = TranslateThread(paragraphs)self.translate_thread.progress_signal.connect(self.update_progress)self.translate_thread.finished_signal.connect(self.display_result)self.translate_thread.start()def update_progress(self, current, total):self.progress_bar.setMaximum(total)self.progress_bar.setValue(current)def display_result(self, translated_paras):self.output_box.setPlainText("\n".join(translated_paras))self.progress_bar.setValue(0)def load_document(self):file_path, _ = QFileDialog.getOpenFileName(self, "选择文档", "", "文档 (*.pdf *.docx *.txt)")if not file_path:returnext = os.path.splitext(file_path)[1].lower()try:if ext == ".pdf":text = "\n".join(pdf_to_text(file_path))elif ext == ".docx":text = "\n".join(docx_to_text(file_path))elif ext == ".txt":text = "\n".join(txt_to_text(file_path))else:QMessageBox.warning(self, "错误", "不支持的文档格式")returnexcept Exception as e:QMessageBox.critical(self, "加载失败", f"文档加载出错: {e}")returnself.input_box.setPlainText(text)def save_document(self):file_path, _ = QFileDialog.getSaveFileName(self, "保存翻译结果", "", "文档 (*.pdf *.docx *.txt)")if not file_path:returntext = self.output_box.toPlainText().strip()if not text:returnext = os.path.splitext(file_path)[1].lower()paragraphs = [line.strip() for line in text.split("\n") if line.strip()]try:if ext == ".pdf":text_to_pdf(paragraphs, file_path)elif ext == ".docx":text_to_docx(paragraphs, file_path)elif ext == ".txt":text_to_txt(paragraphs, file_path)else:QMessageBox.warning(self, "错误", "不支持的保存格式")returnexcept Exception as e:QMessageBox.critical(self, "保存失败", f"保存文档出错: {e}")# -----------------------------
# 主程序
# -----------------------------
if __name__ == "__main__":tokenizer, model = load_model()app = QApplication(sys.argv)gui = TranslatorGUI()gui.show()sys.exit(app.exec_())



)

)!)




)


![第十六届蓝桥杯青少组C++省赛[2025.8.10]第二部分编程题(6、魔术扑克牌排列)](http://pic.xiahunao.cn/第十六届蓝桥杯青少组C++省赛[2025.8.10]第二部分编程题(6、魔术扑克牌排列))



)
)
Hbase替代方案)