1、什么是权值共享
权重共享是指在模型的不同层之间复⽤相同的参数。这可以减少模型的总体参数数量,并使得模型在训练时更容易学习。
2、在Transformer中的应用
常见的做法是共享词嵌入层(embedding layer)和输出层(output layer)之间的权重。
这意味着在⽣成词汇的概率分布时,使⽤的嵌⼊矩阵和线性层是相同的。这样可以有效地利⽤已经学习到的词向量,并且减少了参数量。具体来说,如果嵌⼊矩阵 (W_e) 用于将输⼊标记转换为嵌⼊表示,则同样的矩阵也可以用于输出层:
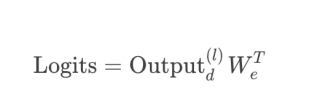
位置编码的权重共享:
在Transformer中,位置编码通常是通过学习的固定向量来实现的,这些向量与输⼊的词嵌⼊相加以表⽰单词在序列中的位置信息。在编码器和解码器中,可以共享相同的位置编码矩阵,这样不同位置的输⼊在不同层之间可以有相同的表⽰。
编码器和解码器的词嵌⼊权重共享:
在机器翻译任务中,源语⾔和⽬标语⾔虽然不同,但它们可以共⽤⼀个⼤型的词表,尤其是考虑到⼀些词汇如数字、标点符号等在多种语⾔中是通⽤的。这使得源语⾔和⽬标语⾔Embedding层可以共享权重。当使⽤BPE(Byte Pair Encoding)这样的⼦词(subword)编码技术时,最⼩的单元不再是完整的单词,⽽是更⼩的⼦词⽚段。英语和德语等同属⽇⽿曼语族的语⾔有许多相同的⼦词,可以共享相似的语义表⽰。⽽对于汉语和英语这种差异较⼤的语⾔对,共享的语义可能较少,共享权重的意义不是很⼤。然⽽,共享词表会导致词表规模显著增加,这可能增加softmax层的计算负担,影响模型的训练速度和推理效率。因此,在实际应⽤中,是否进⾏权重共享需要权衡模型的性能提升与计算资源的消耗。
解码器自注意力中的权重共享:
在解码器的⾃注意⼒层中,可能会采⽤权重共享策略,即使⽤相同的查询、键和值的权重矩阵。这种共享可以提⾼模型的效率,减少参数数量,并且可以使模型更容易训练。



:Skywalking 与 Easyearch 集成)



——使用PyTorch构建神经网络)
)


)
-三层缓存的回收过程)


)



