重排01:物品相似性的度量、提升多样性的方法_哔哩哔哩_bilibili
github-PPT
前面的讨论中提到 在链路的最后进行重排,重排要插入广告和运营笔记,还要做规则打散,提高推荐的丰富性,比如说一个人特别爱看足球,但也不能一页所有内容全都给他推足球,需要多样性。

粗排和精排 目标是对每个物品准确打分(融合reward)但没有考虑物品的相关性。
后处理主要为了提升多样性。从 n 个候选物品中选出 k 个,既要它们的总分高,也需要它们有多样性。
重排01:物品相似性的度量、提升多样性的方法
度量相似性可以通过属性标签和向量。
·物品属性标签:类目、品牌、关键词等
·下例根据一级类目、二级类目、品牌计算相似度。
·物品i 三个属性分别为:美妆、彩妆、香奈儿。
·物品j 三个属性分别为:美妆、香水、香奈儿。
·两两进行 相似度: sim1(i,j)=1,sim2(i,j)=0,sim3(i,j)=1 再进行加权。
双塔模型 分别对用户和物品计算一个向量;如果拿物品塔输出的向量 去刻画物品相似性。
新物品和长尾物品的点击量比较少,模型学不好。
基于图文内容的向量表征:
对图文笔记 图片用CNN 文字用BERT分别输出一个向量再拼起来。
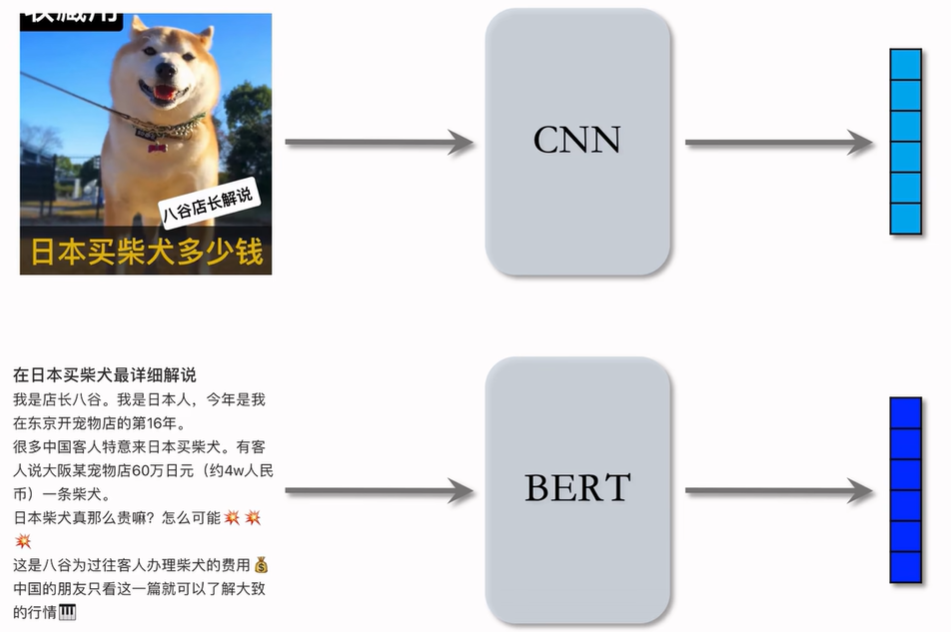
如何训练 CNN和BERT?
如果外界数据集 迁移到小红书可能效果不好。如果小红书自己数据集 还需要人工标注?
可以CLIP预训练 对于图片一文本二元组,预测图文是否匹配。
优势:无需人工标注 因为大多数笔记中 图片和文字还是强相关的。(天然正负样本)
利用大规模图文对,通过对比学习训练图像编码器和文本编码器,让它们在同一个语义空间里对齐,从而实现跨模态理解。
重排02:MMR 多样性算法(Maximal Marginal Relevance)
粗排/精排 给了一个物品本身的reward,后处理要兼具reward和多样性。
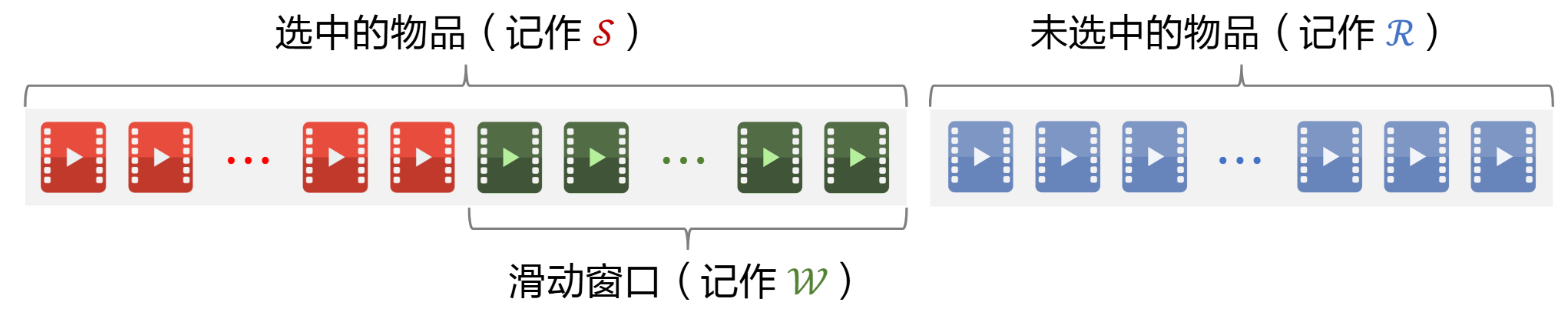
可以维护一个已经选中的物品集合S,候选项集合R。从R选综合分数最高的加入S。
多样性高 就是和S集合中物品最大相似度sim越小越好;对reward和sim进行加权得分MR
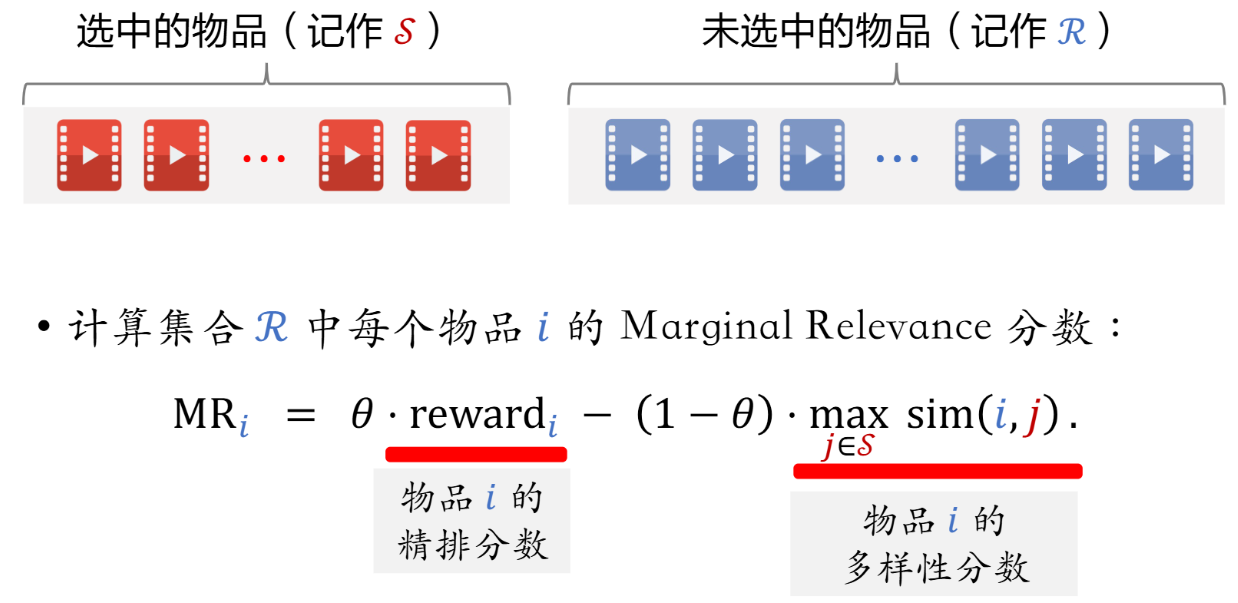
当S集合累积比较大的时候 因为多样性 已经涵盖各种类型的物体了,这会导致R中物品算出的sim大多为1(都会S中有强相似度的 相当于这一项就无效了)
于是进行一个滑动窗口的操作,只用最新进入S的十个物体 去和R计算相似度。
一举两得 防止S集合过大 使得sim项无效,也降低了计算复杂度。
重排03:业务规则约束下的多样性算法
重排规则:为了用户体验的一些条件约束 如下列例子
1. 最多连续出现 k 篇某种笔记(比如小红书有图文类和视频类 不能全是图文/全是视频)
2. 每 k 篇笔记最多出现 1 篇某种笔记(推广广告等用户不太想经常看到的 不能出现太多)
3. 前 t 篇笔记最多出现 k 篇某种笔记(前t篇特别重要 在用户刷到的最前面 比如小红书的前4为首屏)
原来的上面的MMR算法 是对整个集合R为候选子集。
现在在这些规则下,在挑选max前要先对子集R根据规则筛一遍为R',再对R'找max。
重排04:DPP多样性算法
把物体分别表示为单位向量,夹角越大 相似度越低 多样性越高。
正交则多样性好 线性相关则多样性差,可以建模为 这些单位向量所对应的平行多面体的体积。
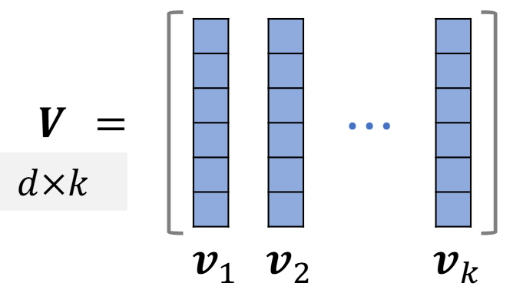

目标函数写成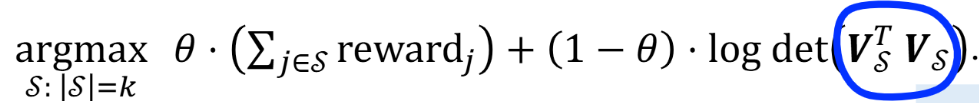
![]()
加上滑动窗口和规则约束;先筛成R' 每次选最近的集合W 新行列式A 就是W∪(i∈R')
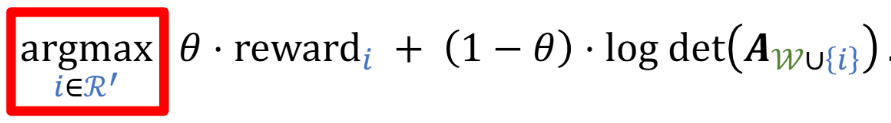
求解方法 加最好的 i 使得目标函数最大
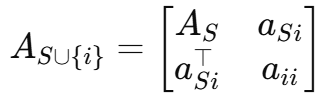
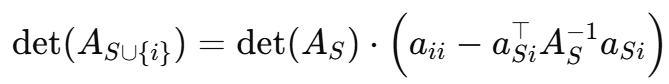 后面一项就是Schur 补 si
后面一项就是Schur 补 si
![]()
![]()
其中 si 为把 𝑖 加入 𝑆 后的 Schur 补,比较各 𝑖 时,只需比较 ![]()
优化计算速度主要来自 可继承的 Cholesky 分解 ![]()

实例代码演示与API文档说明)
![[Sync_ai_vid] UNet模型 | 音频特征提取器(Whisper)](http://pic.xiahunao.cn/[Sync_ai_vid] UNet模型 | 音频特征提取器(Whisper))








Ansible)







:Skywalking 与 Easyearch 集成)