1. YOLOv8姿态估计与部署
姿态估计(Pose estimation)是一项涉及识别图像中关键点位置的任务。 关键点可以表示对象的各个部分,如关节、地标或其他独特特征,关键点的位置通常表示为一组2D[x, y]或3D[x, y, visible]坐标。
YOLOv8-Pose人体姿态估计,会先检测出图像中所有的人体检测框,然后每个检测框进行人体姿态估计。 YOLOv8-Pose使用的数据集是 COCO Keypoints 2017 ,总共包含20万张图像,支持人体17个关键点。
YOLOv8-Pose提供了不同版本模型,适用于不同的环境:
-
YOLOv8n-pose: 轻量级的模型,适用于计算资源受限的环境。
-
YOLOv8s-pose: 相对轻量级但性能更好的模型,平衡了速度和准确度。
-
YOLOv8m-pose: 中等大小的模型,提供较高的准确度,适用于需要更准确结果的场景。
-
YOLOv8l-pose: 较大的模型,具有更高的准确度,但速度较慢,适用于高精度要求的应用。
-
YOLOv8x-pose: 精确最大的的模型,但速度最慢,适用于对准确度有极高要求的场景。
-
YOLOv8x-pose-p6: 支持高分辨率图像输入,更高的准确度和更强的检测能力,但需要更多的计算资源。
详细请查看:GitHub - ultralytics/ultralytics: Ultralytics YOLO 🚀 。
1.1. YOLOv8-pose简单测试
YOLOv8n-pose模型推理测试(使用python):
123456789 10 11 12 13 | from ultralytics import YOLO# Load a model
model = YOLO("./yolov8n-pose.pt")# Predict with the model
results = model("https://ultralytics.com/images/bus.jpg", save=True)# 打印输出结果
for result in results:boxes = result.boxes #Boxes对象keypoints = result.keypoints # Keypoints对象print(boxes, keypoints)
|
# 获取yolov8n-pose.pt (yolov8) llh@anhao: wget https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8n-pose.pt # 推理测试 (yolov8) llh@anhao: python yolov8n_pose.py Downloading https://ultralytics.com/images/bus.jpg to 'bus.jpg'... 100%|███████████████████████████████████████████████████████████████| 134k/134k [00:00<00:00, 1.03MB/s] image 1/1 /mnt/e/work/yolov8/bus.jpg: 640x480 4 persons, 53.6ms Speed: 4.5ms preprocess, 53.6ms inference, 120.5ms postprocess per image at shape (1, 3, 640, 480) Results saved to runs/pose/Predictultralytics.engine.results.Boxes object with attributes:cls: tensor([0., 0., 0., 0.], device='cuda:0') conf: tensor([0.8908, 0.8800, 0.8732, 0.4125], device='cuda:0') data: tensor([[4.5000e+01, 3.9700e+02, 2.4200e+02, 9.0600e+02, 8.9082e-01, 0.0000e+00],[6.7000e+02, 3.9000e+02, 8.1000e+02, 8.7800e+02, 8.8004e-01, 0.0000e+00],[2.2400e+02, 4.0400e+02, 3.4400e+02, 8.5600e+02, 8.7320e-01, 0.0000e+00],[0.0000e+00, 4.8500e+02, 7.2000e+01, 8.9300e+02, 4.1249e-01, 0.0000e+00]], device='cuda:0') id: None is_track: False orig_shape: (1080, 810) shape: torch.Size([4, 6]) xywh: tensor([[143.5000, 651.5000, 197.0000, 509.0000],[740.0000, 634.0000, 140.0000, 488.0000],[284.0000, 630.0000, 120.0000, 452.0000],[ 36.0000, 689.0000, 72.0000, 408.0000]], device='cuda:0') #省略.................
上面YOLOv8n-pose模型预测,最后还打印输出了boxes和keypoints。boxes显示有检测出的四个框的类别(cls)、四个框的置信度(conf)、 框坐标和置信度(data)、原始图像尺寸(orig_shape)、边界框的中心坐标和尺寸(xywh)等等。
结果图片保存在当前目录的runs/pose/Predict中,查看如下:

1.2. YOLOv8-pose模型导出
使用 airockchip/ultralytics_yolov8 导出适合部署到rknpu上的模型,模型的改动:
-
修改输出结构, 移除后处理结构(后处理结果对于量化不友好);
-
dfl结构在NPU处理上性能不佳,移至模型外部的后处理阶段,此操作大部分情况下可提升推理性能;
获取自行训练或者官方的yolov8-pose模型,根据模型路径调整./ultralytics/cfg/default.yaml中model路径,然后导出模型:
(yolov8) llh@anhao: cd ultralytics_yolov8 (yolov8) llh@anhao: export PYTHONPATH=./ (yolov8) llh@anhao: python ./ultralytics/engine/exporter.py Ultralytics YOLOv8.2.82 🚀 Python-3.9.19 torch-2.4.1+cu121 CPU (Intel Core(TM) i7-14700F) YOLOv8n-pose summary (fused): 187 layers, 3,289,964 parameters, 0 gradients, 9.2 GFLOPsPyTorch: starting from '../yolov8n-pose.pt' with input shape (16, 3, 640, 640) BCHW and output shape(s) ((), (16, 17, 3, 8400)) (6.5 MB)RKNN: starting export with torch 2.4.1+cu121...RKNN: feed ../yolov8n-pose.onnx to RKNN-Toolkit or RKNN-Toolkit2 to generate RKNN model. Refer https://github.com/airockchip/rknn_model_zoo/tree/main/models/CV/object_detection/yolo RKNN: export success ✅ 0.4s, saved as '../yolov8n-pose.onnx' (12.6 MB)Export complete (3.3s) Results saved to /xxx/yolov8 Predict: yolo predict task=pose model=../yolov8n-pose.onnx imgsz=640 Validate: yolo val task=pose model=../yolov8n-pose.onnx imgsz=640 data=/usr/src/app/ultralytics/datasets/coco-pose.yaml Visualize: https://netron.app# 测试使用模型为yolov8n-pose.pt,在对应目录下生成yolov8n-pose.onnx模型。
可以使用 netron 查看导出的onnx模型的网络结构:
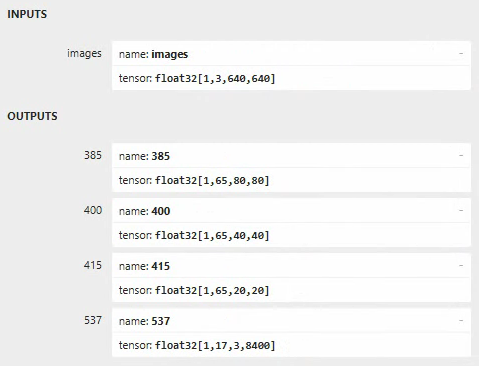
1.3. 导出rknn模型
导出的yolov8-pose模型,使用toolkit2将器转换成rknn模型。
# 获取配套例程的转换程序onnx2rknn.py# python onnx2rknn.py <onnx_model> <TARGET_PLATFORM> <dtype(optional)> <output_rknn_path(optional)> (toolkit2.2) llh@anhao:/xxx/yolov8$ python onnx2rknn.py ./yolov8n-pose.onnx rk3588 fp I rknn-toolkit2 version: 2.2.0 --> Config model done --> Loading model I Loading : 100%|██████████████████████████████████████████████| 144/144 [00:00<00:00, 67581.94it/s] done --> Building model W build: The dataset='../datasets/COCO/coco_subset_20.txt' is ignored because do_quantization = False! I OpFusing 0: 100%|██████████████████████████████████████████████| 100/100 [00:00<00:00, 717.31it/s] I OpFusing 1 : 100%|█████████████████████████████████████████████| 100/100 [00:00<00:00, 438.48it/s] I OpFusing 0 : 100%|█████████████████████████████████████████████| 100/100 [00:00<00:00, 373.56it/s] I OpFusing 1 : 100%|█████████████████████████████████████████████| 100/100 [00:00<00:00, 331.13it/s] I OpFusing 2 : 100%|█████████████████████████████████████████████| 100/100 [00:00<00:00, 177.53it/s] I rknn building ... I rknn buiding done. done --> Export rknn model output_path: ./yolov8_pose.rknn done
模型转换测试设置了目标是rk3588,如果是lbcat-0/1/2,需要设置目标为rk3566/rk3568,并且没有量化模型。
1.4. 部署测试
YOLOv8-pose模型板卡上部署,其推理和后处理大致步骤:
-
预处理,对输入图像进行letterbox,具体通过rga或者cpu实现,图像归一化等操作在rknn模型中;
-
模型推理;
-
后处理,根据设置的置信度阈值BOX_THRESH,对检测框进行筛选,然后对符合要求的检测框进行解码,并进行nms,解码关键点,还原到原图尺度等。
板卡上编译测试例程,编译前系统要安装opencv:
# 鲁班猫板卡系统默认是debian或者ubuntu发行版,直接使用apt安装opencv,或者自行编译安装opencv sudo apt update sudo apt install libopencv-dev# 获取教程配套例程,,或者从https://github.com/airockchip/rknn_model_zoo获取测试例程# 其中-t指定目标设备,这里测试使用lubancat-4,设置rk3588,如果是lubancat-0/1/2就设置rk356x # 如果系统内存大于4G的,设置参数-d cat@lubancat:~/xxx$ cd example/yolov8/yolov8_pose cat@lubancat:~/xxx/example/yolov8/yolov8_pose$ ./build-linux.sh -t rk3588 -d
重要
部署使用的librknnrt库的版本需要与模型转换的Toolkit2的版本一致。
编译输出程序在当前目录的install/rk3588_linux中,测试yolov8_pose_image例程:
cat@lubancat:~/xxx/install/$ ./yolov8_pose_image_demo ./model/yolov8_pose.rknn ./model/bus.jpg load lable ./model/yolov8_pose_labels_list.txt model input num: 1, output num: 4 input tensors: index=0, name=images, n_dims=4, dims=[1, 640, 640, 3], n_elems=1228800, size=2457600, fmt=NHWC, type=FP16, qnt_type=AFFINE, zp=0, scale=1.000000 output tensors: index=0, name=385, n_dims=4, dims=[1, 65, 80, 80], n_elems=416000, size=832000, fmt=NCHW, type=FP16, qnt_type=AFFINE, zp=0, scale=1.000000 index=1, name=400, n_dims=4, dims=[1, 65, 40, 40], n_elems=104000, size=208000, fmt=NCHW, type=FP16, qnt_type=AFFINE, zp=0, scale=1.000000 index=2, name=415, n_dims=4, dims=[1, 65, 20, 20], n_elems=26000, size=52000, fmt=NCHW, type=FP16, qnt_type=AFFINE, zp=0, scale=1.000000 index=3, name=537, n_dims=4, dims=[1, 17, 3, 8400], n_elems=428400, size=856800, fmt=NCHW, type=FP16, qnt_type=AFFINE, zp=0, scale=1.000000 model is NHWC input fmt model input height=640, width=640, channel=3 origin size=640x640 crop size=640x640 input image: 640 x 640, subsampling: 4:2:0, colorspace: YCbCr, orientation: 1 scale=1.000000 dst_box=(0 0 639 639) allow_slight_change=1 _left_offset=0 _top_offset=0 padding_w=0 padding_h=0 src width=640 height=640 fmt=0x1 virAddr=0x0x7fa71f2010 fd=0 dst width=640 height=640 fmt=0x1 virAddr=0x0x7fa70c6000 fd=8 src_box=(0 0 639 639) dst_box=(0 0 639 639) color=0x72 rga_api version 1.10.0_[2] person @ (108 235 224 536) 0.888 person @ (211 241 284 507) 0.872 person @ (476 234 560 518) 0.861 write_image path: out.png width=640 height=640 channel=3 data=0x7fa71f2010
在当前目录的install/rk3588_linux中,还有一个yolov8_pose_videocapture_demo,可以打开摄像头或者视频文件,下面测试打开摄像头,并拍摄其他屏幕显示的画面。
# 执行例程请注意摄像头的设备号,支持的分辨率,编解码格式等等,具体请查看yolov8_pose_videocapture_demo.cc源文件 cat@lubancat:~/xxx/install/$ ./yolov8_pose_videocapture_demo ./model/yolov8_pose.rknn 0 load lable ./model/yolov8_pose_labels_list.txt model input num: 1, output num: 4 input tensors: index=0, name=images, n_dims=4, dims=[1, 640, 640, 3], n_elems=1228800, size=2457600, fmt=NHWC, type=FP16, qnt_type=AFFINE, zp=0, scale=1.000000 output tensors: index=0, name=385, n_dims=4, dims=[1, 65, 80, 80], n_elems=416000, size=832000, fmt=NCHW, type=FP16, qnt_type=AFFINE, zp=0, scale=1.000000 index=1, name=400, n_dims=4, dims=[1, 65, 40, 40], n_elems=104000, size=208000, fmt=NCHW, type=FP16, qnt_type=AFFINE, zp=0, scale=1.000000 index=2, name=415, n_dims=4, dims=[1, 65, 20, 20], n_elems=26000, size=52000, fmt=NCHW, type=FP16, qnt_type=AFFINE, zp=0, scale=1.000000 index=3, name=537, n_dims=4, dims=[1, 17, 3, 8400], n_elems=428400, size=856800, fmt=NCHW, type=FP16, qnt_type=AFFINE, zp=0, scale=1.000000 model is NHWC input fmt model input height=640, width=640, channel=3 scale=1.000000 dst_box=(0 80 639 559) allow_slight_change=1 _left_offset=0 _top_offset=80 padding_w=0 padding_h=160 src width=640 height=480 fmt=0x1 virAddr=0x0x55923ea480 fd=0 dst width=640 height=640 fmt=0x1 virAddr=0x0x7f79666000 fd=26 src_box=(0 0 639 479) dst_box=(0 80 639 559) color=0x72 rga_api version 1.10.0_[2] fill dst image (x y w h)=(0 0 640 640) with color=0x72727272 rknn_run # 省略...................
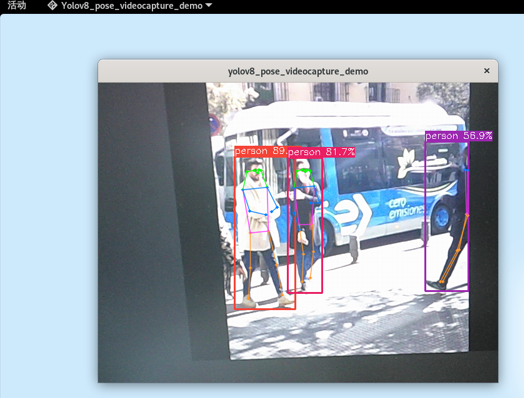
更多rknn模型例程请参考 rknn_model_zoo仓库 。
需要注意:测试usb摄像头,请确认摄像头的设备号,修改例程中摄像头支持的分辨率和MJPG格式等, 如果是mipi摄像头,需要opencv设置转换成rgb格式以及设置分辨率大小等等。
12.5. 参考链接
Install Ultralytics - Ultralytics YOLO Docs
GitHub - ultralytics/ultralytics: Ultralytics YOLO 🚀
GitHub - airockchip/ultralytics_yolov8: NEW - YOLOv8 🚀 in PyTorch > ONNX > CoreML > TFLite
GitHub - airockchip/rknn_model_zoo
)
)









-- 性能优化与调试)
)



)


