文章目录
- 引言
- 筑路之备:快速上手ProtoBuf
- 步骤一:创建.proto文件
- ==⽂件规范==
- ==添加注释==
- 指定 proto3 语法
- package 声明符
- 定义消息(message)
- 定义消息字段
- 【定义联系人 message】
- 字段唯一编号的范围
- 步骤2:编译 contacts.proto ⽂件,⽣成 C++ ⽂件
- 编译命令
- 编译命令⾏格式为:
- 编译 `contacts.proto` ⽂件命令如下 :
- 【-I 指定搜索目录】
- 编译 contact.proto 文件效果
- 【自动生成方法】:
- 【序列化和反序列化方法】:
- 步骤3:序列化与反序列化的使⽤
- 编译指令:
- 小结

引言
为何用 “数据秘语” 编织通讯录?
- 传统通讯录数据的 “困境”:文本格式(如
JSON/CSV)的冗余与解析慢,恰似 “联络信笺” 的冗长絮语 ProtoBuf的 “秘语优势”:二进制压缩、跨语言兼容,为通讯录搭建 “高效联络通道”- 本实战 1.0 的核心目标:用
ProtoBuf实现 “联系人数据的序列化存储与反序列化读取”,完成基础联络功能
ProtoBuf的后续学习,将通过项目实战——书写通讯录的方式进行
筑路之备:快速上手ProtoBuf
需求:在快速上⼿中,会编写第⼀版本的通讯录 1.0。在通讯录 1.0 版本中,将实现:
- 对⼀个联系⼈的信息使⽤ PB 进⾏序列化,并将结果打印出来。
- 对序列化后的内容使⽤ PB 进⾏反序列,解析出联系⼈信息并打印出来。联系⼈包含以下信息: 姓名、年龄。
通过通讯录 1.0,我们便能了解使⽤
ProtoBuf初步要掌握的内容,以及体验到ProtoBuf的完整使⽤流程
步骤一:创建.proto文件
⽂件规范
• 创建 .proto ⽂件时,⽂件命名应该使⽤全⼩写字⺟命名,多个字⺟之间⽤ _ 连接。 例如lower_snake_case.proto 。
• 书写 .proto ⽂件代码时,应使⽤ 2 个空格的缩进。
我们为通讯录 1.0 新建⽂件: contacts.proto
添加注释
向⽂件添加注释,可使⽤ // 或者 /* … */
指定 proto3 语法
Protocol Buffers语⾔版本3,简称proto3,是.proto⽂件最新的语法版本。proto3简化了
Protocol Buffers语⾔,既易于使⽤,⼜可以在更⼴泛的编程语⾔中使⽤。它允许你使⽤Java,C++,Python
等多种语⾔⽣成protocol buffer代码。
在.proto⽂件中,要使⽤syntax = "proto3";来指定⽂件语法为 proto3,并且必须写在除去注释内容的第⼀⾏。
注意:如果没有指定,编译器会使⽤proto2语法。 在通讯录 1.0 的 contacts.proto ⽂件中,可以为⽂件指定 proto3 语法
syntax = "proto3";
package 声明符
package 是⼀个可选的声明符,能表⽰.proto⽂件的命名空间,在项⽬中要有唯⼀性。它的作⽤是为了避免我们定义的消息出现冲突。
可以理解为这个C++,命令空间,避免多个message冲突。在通讯录 1.0 的 contacts.proto ⽂件中,可以声明其命名空间,内容如下:
syntax = "proto3";
package contacts;定义消息(message)
消息(message): 要定义的结构化对象,我们可以给这个结构化对象中定义其对应的属性内容。
【问题】:为什么要定义消息?
-
在⽹络传输中,我们需要为传输双⽅定制协议。定制协议说⽩了就是定义结构体或者结构化数据,⽐如,
tcp,udp报⽂就是结构化的。 再⽐如将数据持久化存储到数据库时,会将⼀系列元数据统⼀⽤对象组织起来,再进⾏存储。 -
所以
ProtoBuf就是以message的⽅式来⽀持我们定制协议字段,后期帮助我们形成类和⽅法来使⽤。在通讯录 1.0 中我们就需要为联系⼈定义⼀个message。
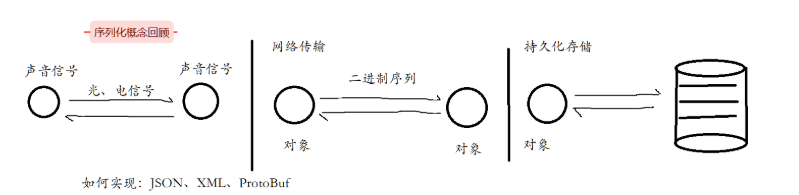
proto⽂件中定义⼀个消息类型的格式为 :
message 消息类型名{
}
消息类型命令规范:使用驼峰命名法,首字母大写
定义消息字段
在 message 中我们可以定义其属性字段,字段定义格式为:字段类型 字段名 = 字段唯⼀编号
- 字段名称命名规范:全⼩写字⺟,多个字⺟之间⽤ _ 连接
- 字段类型分为:标量数据类型 和 特殊类型(包括枚举、其他消息类型等)
- 字段唯⼀编号:⽤来标识字段,不能使用相同的字段编号
【定义联系人 message】
其中,我们必须要把这个字段编号带上,跟PB特点:高效,序列化,结果更小有关系。跟Protobuf编译原理有关。
message PeopleInfo{ //建议驼峰string name = 1;//姓名 标识字段编号int32 age = 2; //年龄
}该表格展⽰了定义于消息体中的标量数据类型,以及编译.proto⽂件之后⾃动⽣成的类中与之对应的字段类型。在这⾥展⽰了与 C++ 语⾔对应的类型。 (了解即可)
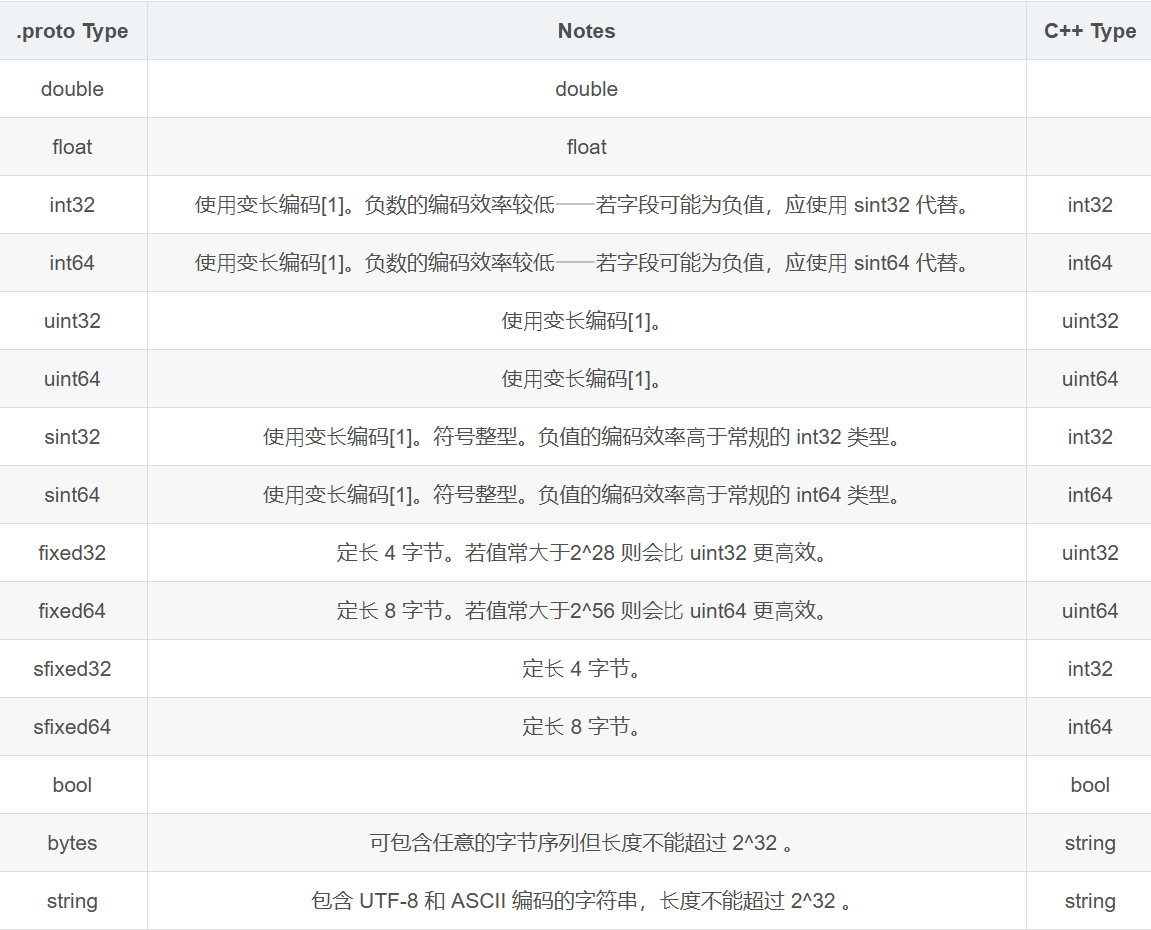
字段唯一编号的范围
1 ~ 536,870,911 (2^29 - 1) ,其中 19000 ~ 19999 不可⽤
19000 ~ 19999 不可⽤是因为:在 Protobuf 协议的实现中,对这些数进⾏了预留。如果⾮要在.proto⽂件中使⽤这些预留标识号,例如将 name 字段的编号设置为19000,编译时就会报警:
// 消息中定义了如下编号,代码会告警:
// Field numbers 19,000 through 19,999 are reserved for the protobuf
implementation
string name = 19000;值得⼀提的是,范围为 1 ~ 15 的字段编号需要⼀个字节进⾏编码, 16 ~ 2047 内的数字需要两个字节进⾏编码。编码后的字节不仅只包含了编号,还包含了字段类型。
注意:所以 1 ~ 15 要⽤来标记出现⾮常频繁的字段,要为将来有可能添加的、频繁出现的字段预留⼀些出来
步骤2:编译 contacts.proto ⽂件,⽣成 C++ ⽂件
注意:在使用过程中,如果没有"颜色亮光",需要下载Protobuf插件
编译命令
编译命令⾏格式为:
protoc [--proto_path=IMPORT_PATH] --cpp_out=DST_DIR path/to/file.proto
protoc是 Protocol Buffer 提供的命令⾏编译⼯具。--proto_path指定 被编译的.proto⽂件所在⽬录,可多次指定。可简写成 -IIMPORT_PATH 。如不指
定该参数,则在当前⽬录进⾏搜索。当某个.proto ⽂件 import 其他.proto ⽂件时,或需要编译的 .proto ⽂件不在当前⽬录下,这时就要⽤-I来指定搜索⽬录。--cpp_out= 指编译后的⽂件为 C++ ⽂件。OUT_DIR编译后⽣成⽂件的⽬标路径。path/to/file.proto要编译的.proto⽂件。
编译 contacts.proto ⽂件命令如下 :
protoc --cpp_out=. contacts.proto【-I 指定搜索目录】
场景:查找contacts.ptoto(文件名)
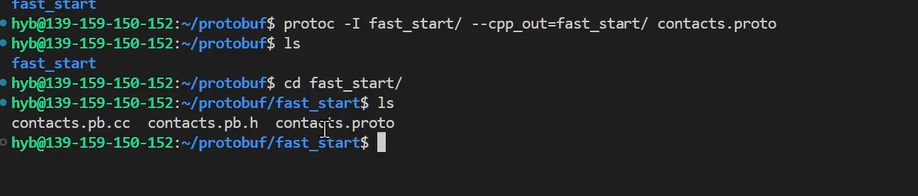
编译 contact.proto 文件效果
编译
contacts.proto⽂件后,会⽣成所选择语⾔的代码,我们选择的是C++,所以编译后⽣成了两个⽂件:
contacts.pb.hcontacts.pb.cc
对于编译⽣成的 C++ 代码,包含了以下内容 :
- 对于每个 message ,都会⽣成⼀个对应的消息类。
- 在消息类中,编译器为每个字段提供了获取和设置⽅法以及⼀下其他能够操作字段的⽅法。
- 编辑器会针对于每个
.proto⽂件⽣成.h和.cc⽂件,分别⽤来存放类的声明与类的实现
【自动生成方法】:
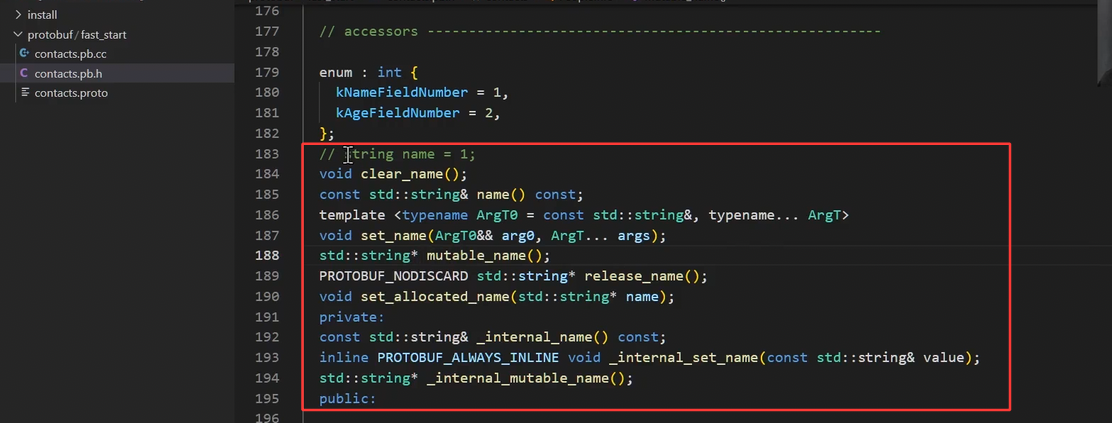
上述的例⼦中:
- 每个字段都有设置和获取的⽅法,
getter的名称与⼩写字段完全相同,setter⽅法以set_开头。 - 每个字段都有⼀个
clear_⽅法,可以将字段重新设置回empty状态
【序列化和反序列化方法】:
序列化和反序列化方法,不在Message类中,在消息类的父类MessageLite 中,提供了读写消息实例的方法,包括了序列化方法和反序列化方法。Message类继承MessageLite父类的属性和方法
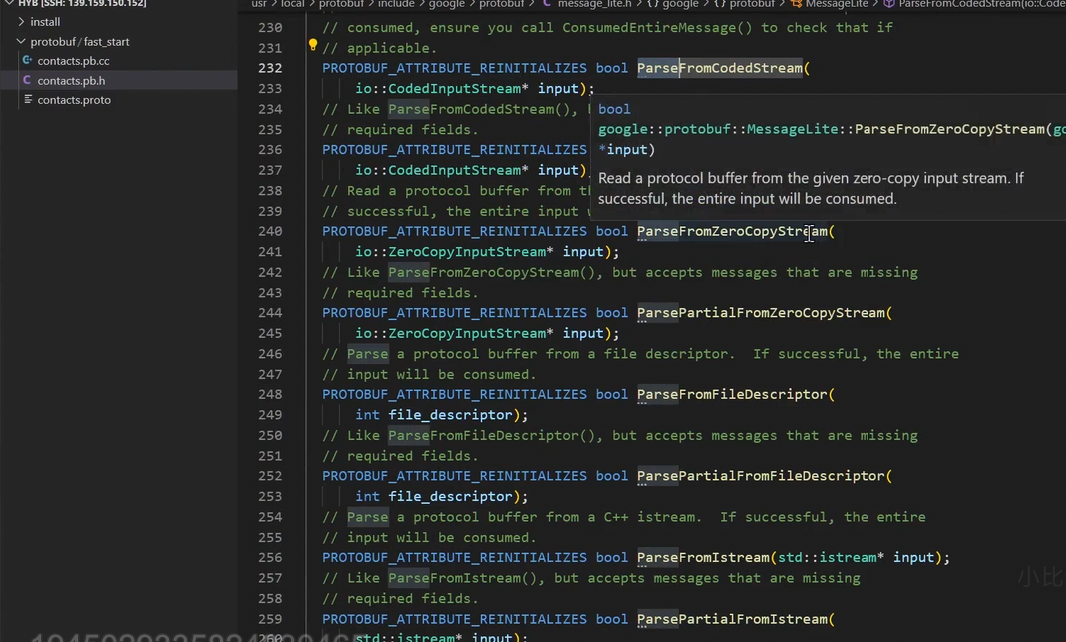
注意:
- 序列化的结果为⼆进制字节序列,⽽⾮⽂本格式。
- 以上三种序列化的⽅法没有本质上的区别,只是序列化后输出的格式不同,可以供不同的应⽤场景使⽤。
- 序列化的 API 函数均为
const成员函数,因为序列化不会改变类对象的内容, ⽽是将序列化的结果保存到函数⼊参指定的地址中。 - 详细
message API可以参⻅完整列表
步骤3:序列化与反序列化的使⽤
创建⼀个测试⽂件 main.cc,⽅法中我们实现:
- 对⼀个联系⼈的信息使⽤
PB进⾏序列化,并将结果打印出来。 - 对序列化后的内容使⽤
PB进⾏反序列,解析出联系⼈信息并打印出来。
main.cc
#include<iostream>
#include"contacts.pb.h"int main()
{std::string people_str;{// 对一个联系人使用 PB 进行序列化,并将结果打印出来contacts::PeopleInfo people; // 定义对象people.set_name("张三"); // 设置姓名people.set_age(20); // 设置年龄// 使用正确的序化方法if(!people.SerializeToString(&people_str)){std::cerr << "Failed to serialize people." << std::endl;return -1;}std::cout << "Serialized data: " << people_str << std::endl;}{// 对一个联系人使用 PB 进行反序列化,并将结果打印出来contacts::PeopleInfo people; // 定义对象// 使用正确的反序列化方法if(!people.ParseFromString(people_str)){std::cerr << "Failed to parse people." << std::endl;return -1;}std::cout << "Name: " << people.name() << std::endl; // 获取姓名std::cout << "Age: " << people.age() << std::endl; // 获取年龄}return 0;}
编译指令:
g++ main.cc contacts.pb.cc -o TestPb -std=c++11 -lprotobuf
- -lprotobuf:必加,不然会有链接错误。
- -std=c++11:必加,使⽤C++11语法。
执⾏ TestPb,可以看⻅ people 经过序列化和反序列化后的结果:

由于ProtoBuf是把联系⼈对象序列化成了⼆进制序列,这⾥⽤ string 来作为接收⼆进制序列的容器。所以在终端打印的时候会有换⾏等⼀些乱码显⽰。
所以相对于 xml 和 JSON 来说,因为被编码成⼆进制,破解成本增⼤,ProtoBuf 编码是相对安全的。
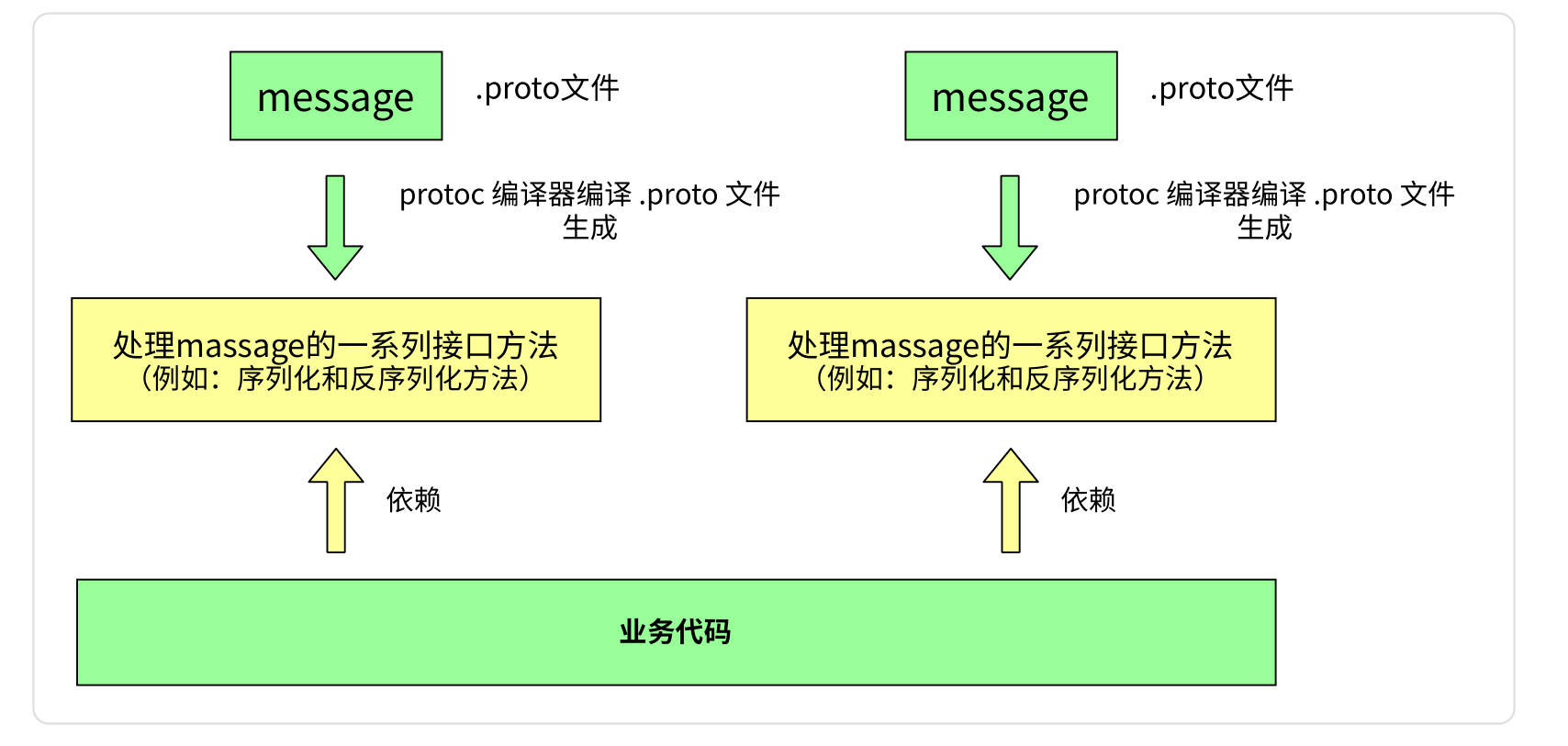
- 编写 .proto ⽂件,⽬的是为了定义结构对象(message)及属性内容。
- 使⽤ protoc 编译器编译 .proto ⽂件,⽣成⼀系列接⼝代码,存放在新⽣成头⽂件和源⽂件中。
- 依赖⽣成的接⼝,将编译⽣成的头⽂件包含进我们的代码中,实现对
.proto⽂件中定义的字段进⾏设置和获取,和对message对象进⾏序列化和反序列化。
小结
当你用 ProtoBuf 的 “数据秘语” 织就通讯录的存储与读取,这座精简高效的联络小筑,便已在你手中落成。
1.0 的启步札记虽止于此,却为你推开了数据通信的门,更精彩的 “秘语续篇”,正待后续续写。















简介与应用分享)




