1)
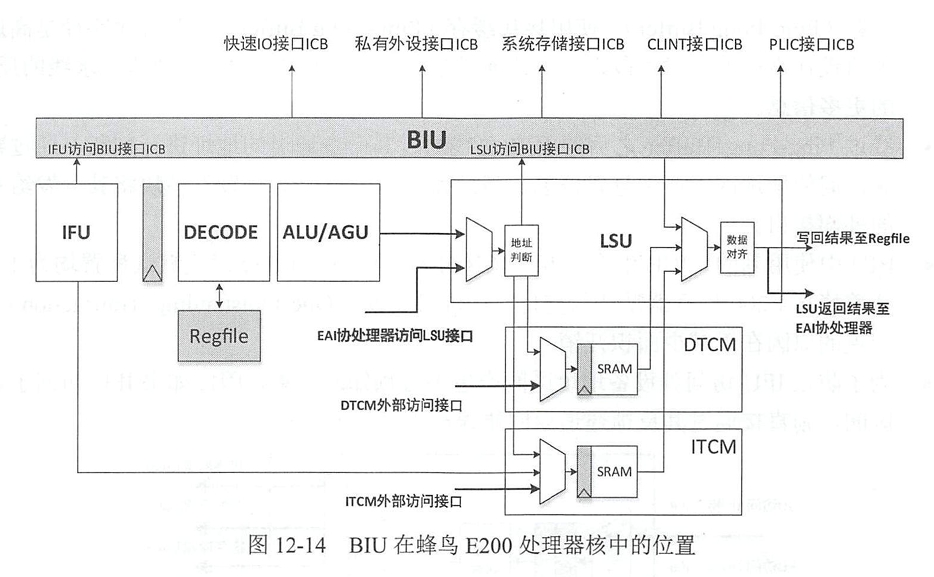
①BIU作为核心通信枢纽,主要承担两大功能:一是连接处理器核内的关键执行单元(包括IFU、LSU和EAI协处理器),统一管理指令和数据的内部传输路径;二是作为"核内计算"与"核外资源"的唯一交互通道,负责对接外部存储(如ITCM、DTCM、SRAM)及外设(包括快速IO、私有外设、CLINT和PLIC)。
②核内计算单元连接方式:
i)IFU通过专用的"IFU-BIU接口"与BIU相连;
ii)LSU通过"LSU-BIU接口"与BIU建立连接;
iii)ALU/AGU和LSU可直接将结果写回寄存器文件。
③核心存储单元配置:
i)ITCM经由BIU接口与IFU对接;
ii)DTCM通过BIU接口与LSU连接。
④核外扩展资源均采用标准化的ICB接口与BIU通信。ITCM/DTCM还额外提供外部访问接口以支持容量扩展需求。
⑤EAI协处理器通过"LSU-EAI接口"间接接入BIU系统
→另一个视角
①指令流
i)取指:IFU通过专用接口向BIU发起指令请求,优先访问ITCM获取指令,若ITCM未命中,则通过ICB接口从外部SRAM加载指令;
ii)解码:IFU将指令传送至DECODE单元,解码器将指令解析为操作码和操作数地址;
iii)运算:ALU/AGU接收解码结果,算术运算则直接执行计算,数据访问则生成目标地址并传递给LSU;
iv)写回:运算结果直接写回寄存器堆,为后续指令执行提供数据支持。
②数据流
i)数据加载:LSU接收来自 ALU/AGU 的地址信息,通过"BIU-LSU接口"向BIU发起数据请求,优先访问DTCM获取目标数据,若DTCM未命中,则BIU通过ICB接口访问外部SRAM;
ii)协处理辅助:当需要进行复杂运算时,EAI协处理器通过LSU接口获取数据,完成运算后将结果数据返回至LSU;
iii)数据存储 / 写回:LSU将加载的数据传送至ALU/AGU参与运算,或直接将数据写入DTCM/SRAM存储器,最终运算结果由LSU写回Regfile,完成整个数据流处理过程。
2)
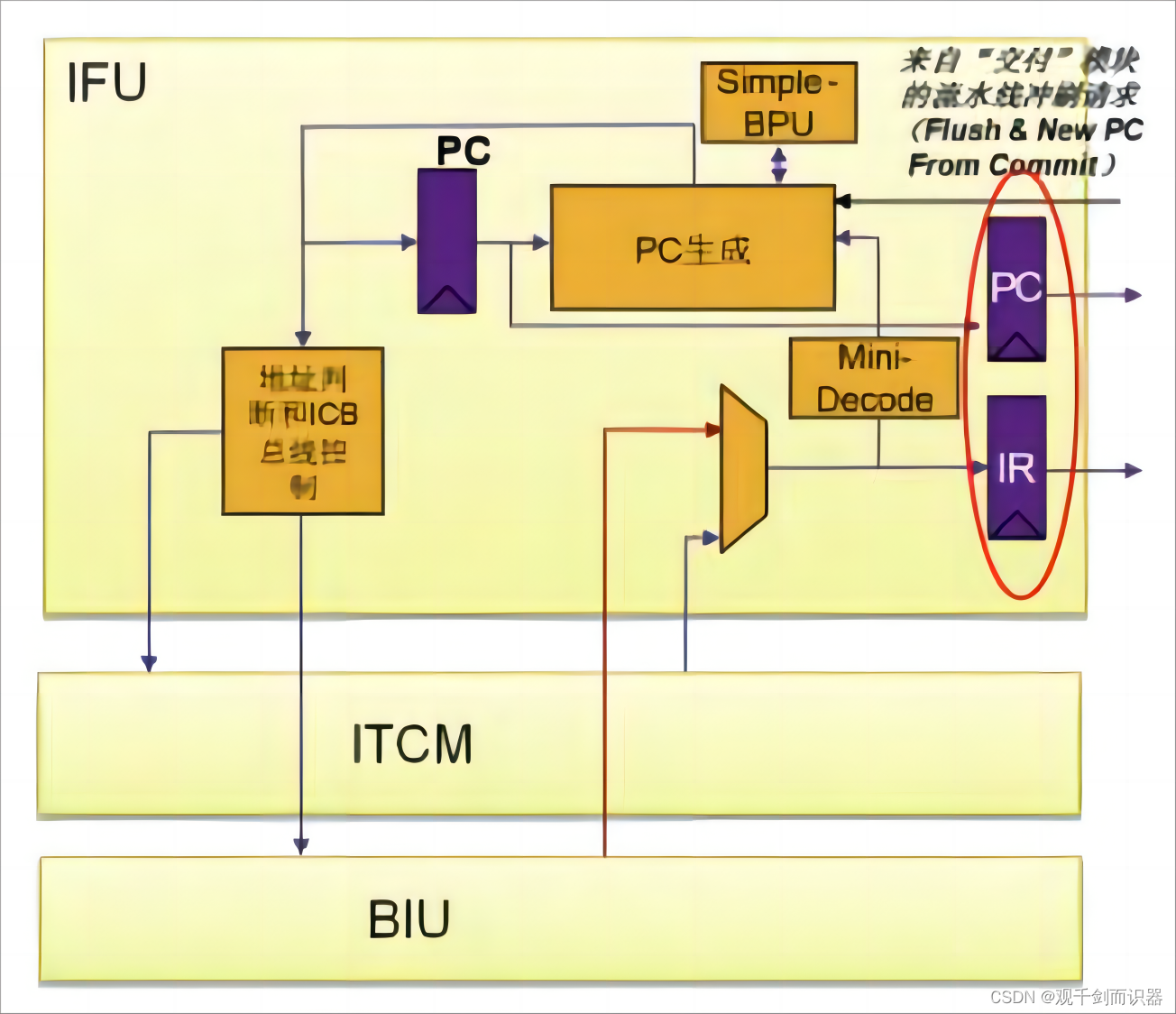
①
3)
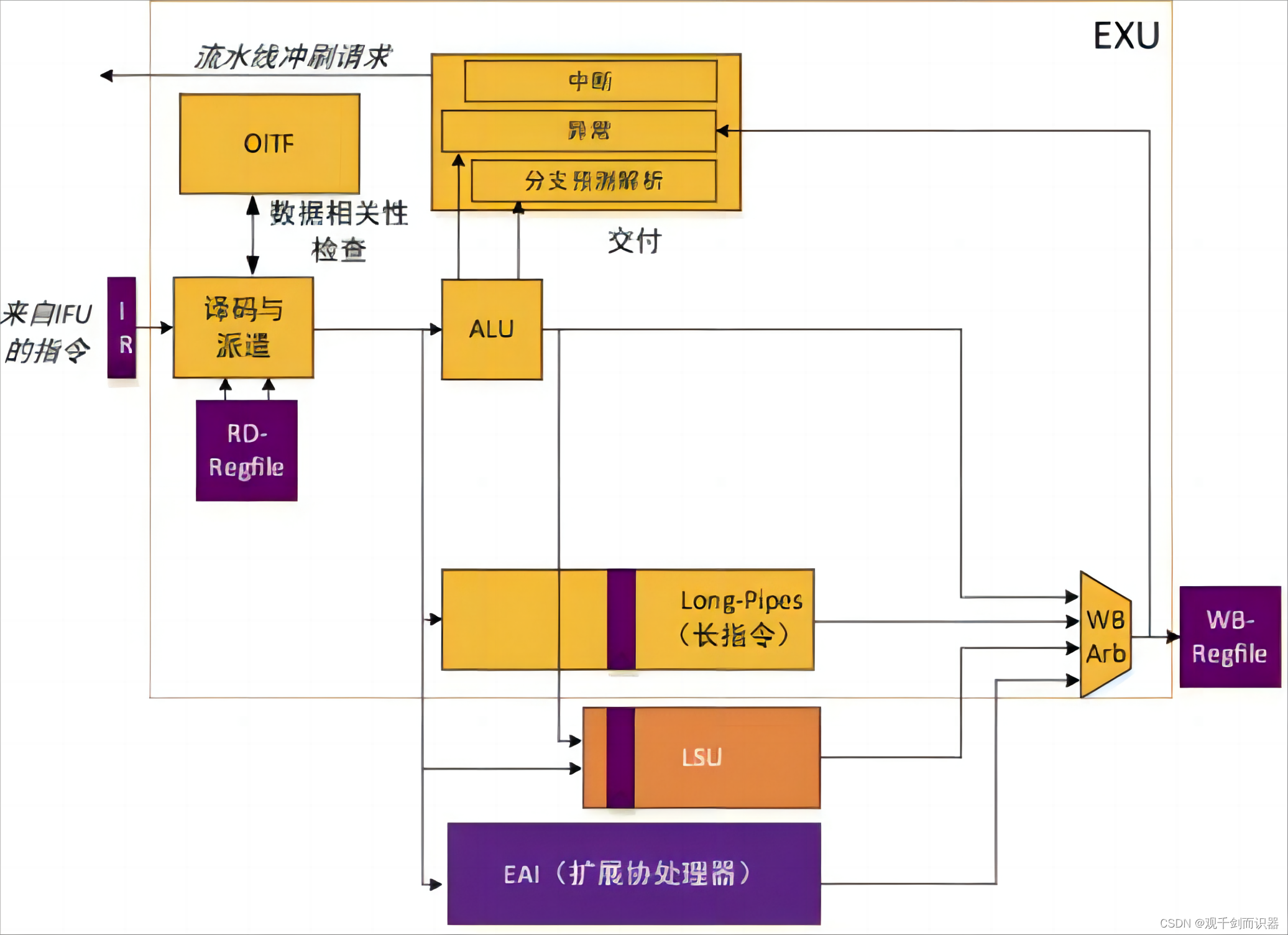
①
4)
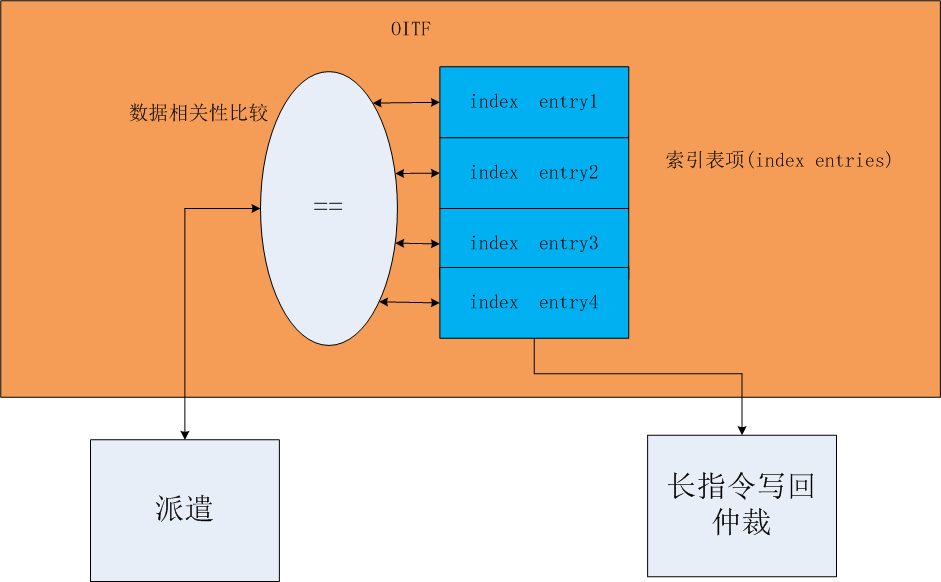
①
5)
①
6)

①sret指令用于从S模式异常处理程序返回低特权级的核心指令.执行时,cpu退出异常处理流程,返回原执行流;
②mret指令用于从M模式的异常处理或中断服务程序中退出,返回到陷入前的特权模式(如S模式或U模式).→在U/S模式下执行会触发非法指令异常.
③WFI核心目的是让处理器进入低功耗待机模式,直到一个不可屏蔽的中断或可屏蔽中断(当前已使能)发生.它是一种提示性hints指令,架构上它向硬件提供了一个明确提示,即程序目前没有工作,具体的硬件实现可以自由决定如何响应这个提示.
→
如果在执行WFI时,中断已经pending,则WFI指令的行为像一个NOP.CPU不会进入等待状态,而是继续执行下一条指令;
否则,CPU会暂停当前线程的执行,并开始进入一种架构性休眠状态.此时,时钟可能被门控,部分功能单元可能被断电,从而显著降低功耗.
→
WFI是本地的,在harts系统中,一个hart执行WFI只会让该hart自己进入休眠状态,不影响其他hart运行.
→
WFI不等于关机和深度睡眠,它只是一种浅睡眠状态,唤醒延迟很低.更深的睡眠状态通常需要通过PMU寄存器来配置.
7)
①
8)
①
9)
①
10)
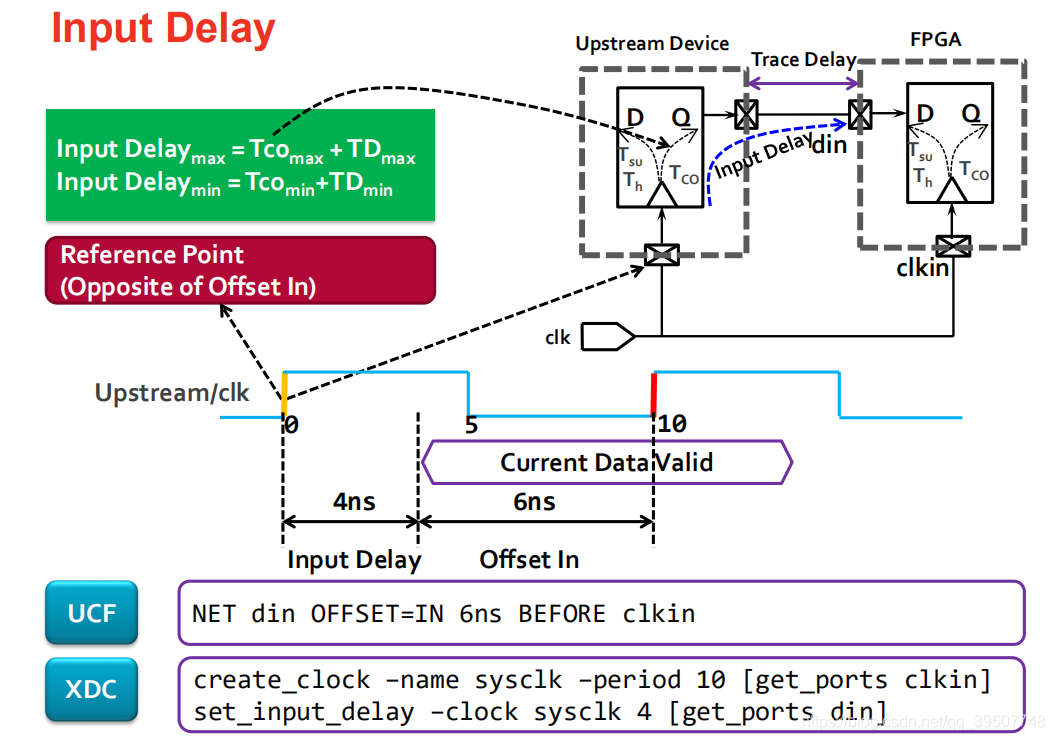
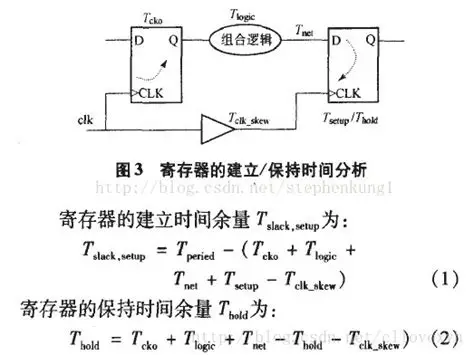
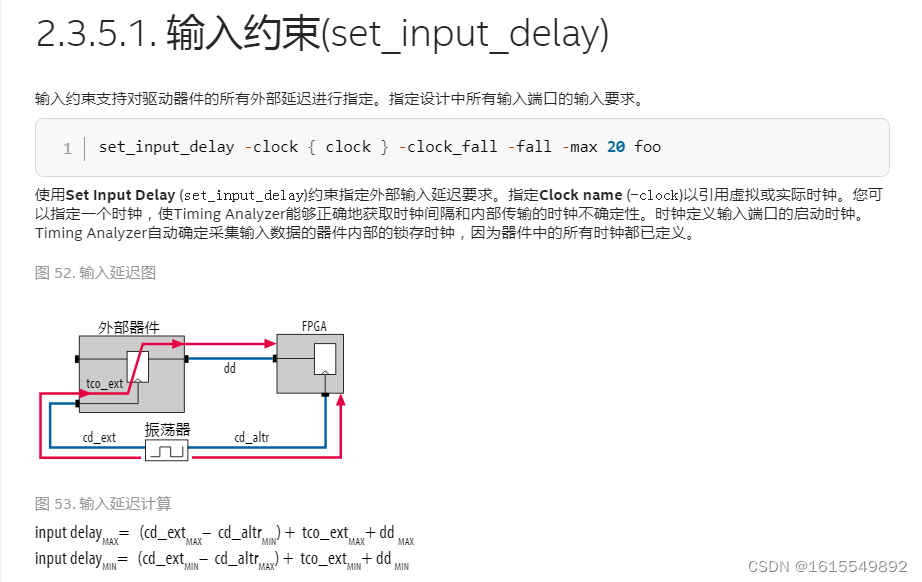 ①set_input_delay的根本目的,是告诉VIVADO时序分析器,FPGA芯片外部的信号,相对于其对应的外部时钟,是何时到达FPGA输入引脚的.(如果没有这个约束,VIVADO会假设外部信号是完美的,与时钟边沿完美对齐);
①set_input_delay的根本目的,是告诉VIVADO时序分析器,FPGA芯片外部的信号,相对于其对应的外部时钟,是何时到达FPGA输入引脚的.(如果没有这个约束,VIVADO会假设外部信号是完美的,与时钟边沿完美对齐);
②set_input_delay的工作原理基于一个标准的source-synchronous接口模型.时序分析器会为这条路径计算两个最坏情况;建立时间检查(最慢路径)和保持时间检查(最快路径).因此set_input_delay也需要指定-max和-min.
③对于建立时间检查(set_input_delay -clock < clk_name > -max < value > [get_ports < name >]),分析器考虑最慢的数据路径和最快的时钟路径.
④对于保持时间检查,分析器考虑最快的数据路径和最慢的时钟路径.
11)
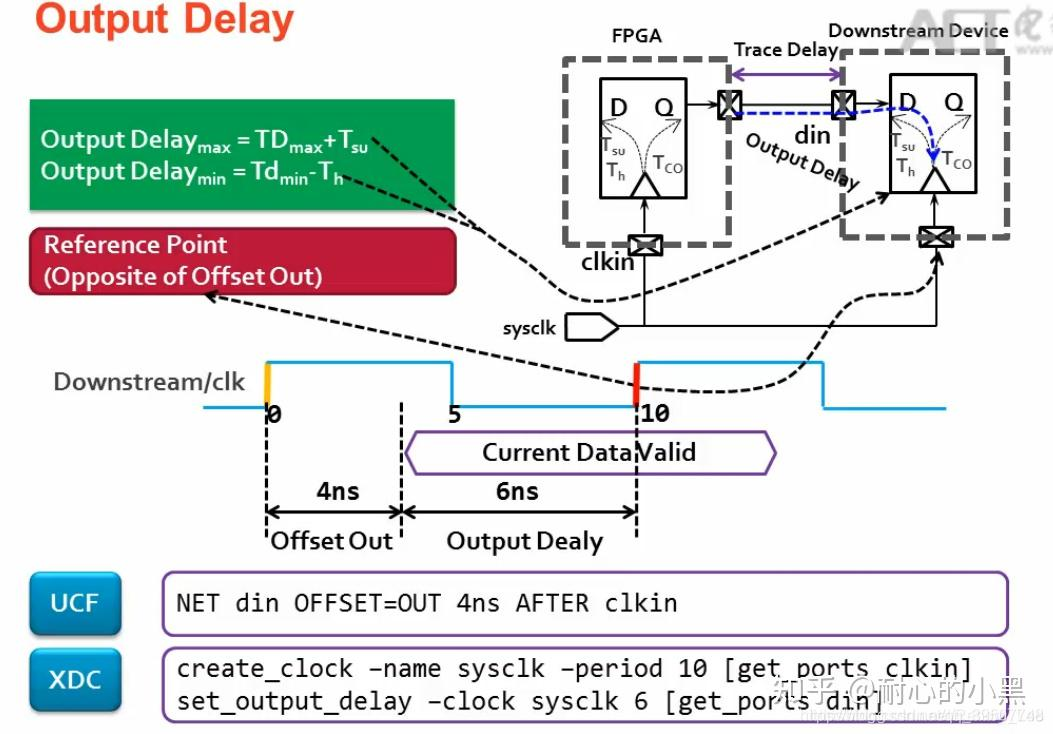
①set_output_delay约束的本质,就是告诉FPGA时序分析工具,外部接收芯片的时序要求.根据这个要求,工具反过来约束FPGA内部的逻辑和布线,确保数据在正确的时间出现在FPGA IO引脚.
②难点在于,数据的有效窗口,不仅取决于FPGA内部,还取决于整个系统的时钟网络.
③set_output_delay定义了,相对于参考时钟,数据在FPGA引脚之后的有效时间是多少.
12)
①
①
☆)
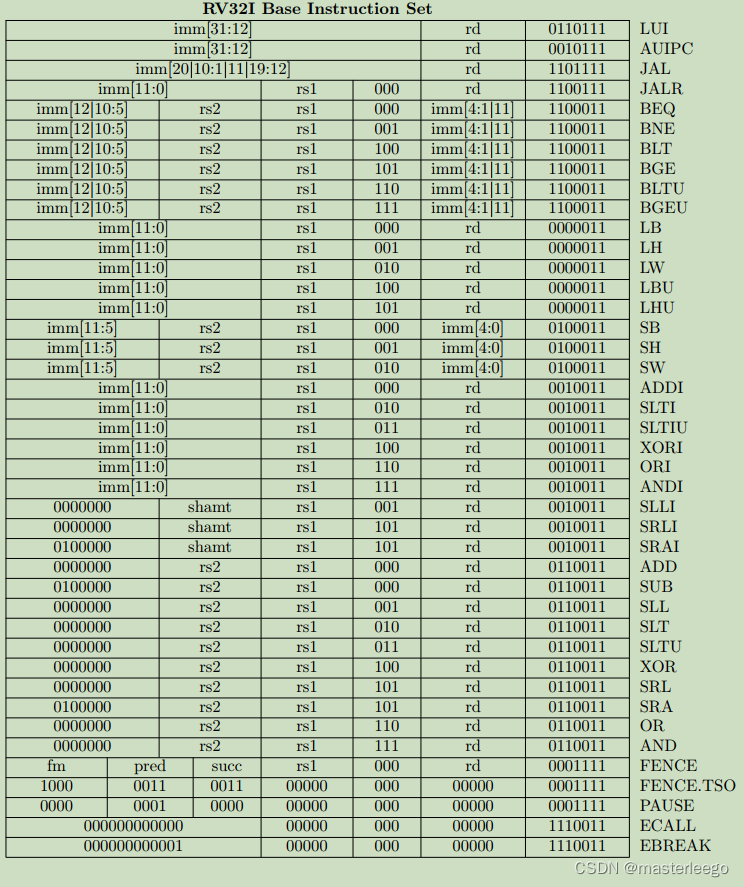
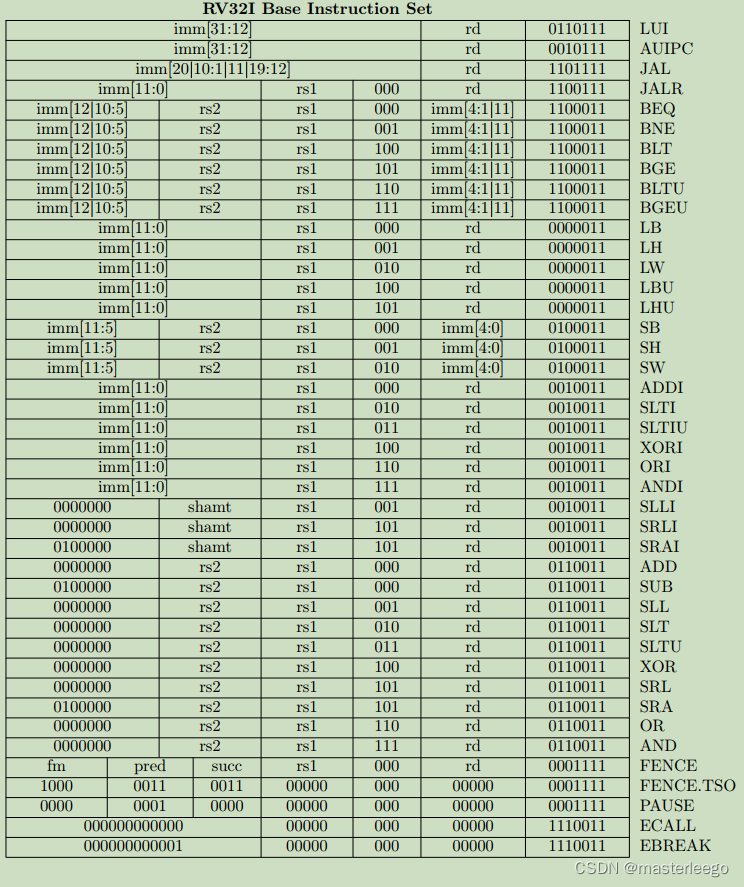
①B型指令其分支偏移量在指令中编码为12位,且在计算目标地址时该偏移量会被硬件左移1位,以实现字节寻址下的指令地址对齐,因此相当于当前指令地址PC的跳转范围是±4KB.如需实现更大范围的跳转,需结合LUI指令(加载高位立即数)或AUIPC指令(PC相对加载高位立即数)来构造完整目标地址.
②JAL作为J型指令唯一用于实现带链接直接跳转指令,其功能是将下一条指令地址保存到指定寄存器中,同时跳转到由20位立即数计算得出的目标地址处继续执行程序.该指令支持相对于当前PC值±1MB的大地址范围跳转.
→
i)jal采用PC相对寻址,偏移范围±1MB.适用于跳转到固定偏移位置.
ii)jalr采用寄存器间接寻址,适用于动态目标地址(如函数返回/函数指针调用).
→
调用约定,函数调用jal固定使用ra保存返回地址;函数返回jalr通过ra间接跳转.
③LUI(load upper immediate)指令用于将20位立即数加载到寄存器的高位,低12bit补零.
④在RV32I指令集中,B指令的立即数仅13位,跳转范围±4KB.若需长距离跳转,需组合指令条件分支+JAL实现(多指令序列).(注意比较指令和条件跳转指令的区别)
⑤lw指令用于从内存中读取一个32位数据,通过基址加偏移量的方式计算内存地址,并要求地址对齐.→避免在访问每次访问不同地址时都需要修改基址寄存器,增加指令数量.→lh需要2字节对齐,lb无对齐要求.
⑥fence指令的pred前序操作集/succ后序操作集位域解析→i表示设备输入(内存加载或外设寄存器读),o表示设备输出,r表示内存读(普通内存加载操作),w表示内存写.→
fence rw,w表示所有读写操作必须在该屏障前完成,之后才能执行写操作.
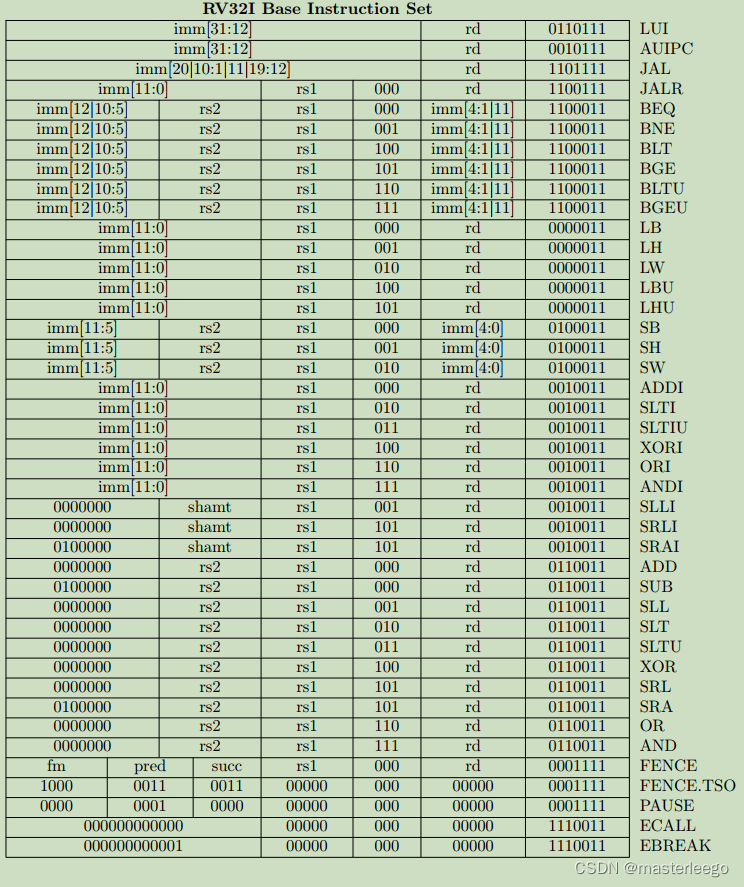
①fence指令用于控制内存访问顺序,确保其前后的特定内存操作满足顺序约束,避免因乱序执行导致的数据一致性问题.
②amo指令直接执行原子性读-修改-写操作(如原子加/交换/位操作等),在单条指令内保证操作的原子性,无需额外锁机制,属于可选的A扩展指令集.其通过硬件直接实现原子性.
③LR/SC指令通过lr.w(加载保留)和sc.w(条件存储)的组合实现原子操作.属于A扩展指令集.通过标记-检查机制实现原子性
④fencei指令用于确保在该指令之前对指令存储空间的所有写入操作,在该指令之后对同一hart的取指操作可见.→程序可能修改自身正在执行或即将执行的代码区域.如果没有同步机制,处理器可能继续执行旧的指令.→fencei强制硬件执行流水线冲刷、无效指令缓存、同步取指逻辑.→只保证当前执行它的hart能看到指令修改的效果.具体的冲刷和失效范围(是整个i-cache还是仅相关区域)以及精确的硬件行为是implementation-defined.
⑤ecall(environment call)指令用于主动请求来自执行环境的服务,是用户模式程序(u-mode)与更高特权级别(m-mode/s-mode)进行沟通的核心机制,主要用于实现系统调用.→当处理器执行ecall指令时,处理器会产生一个同步异常.处理器将当前pc保存到异常程序计数器mepc/sepc寄存器中,这个值指向ecall本身的地址或下一条指令的地址.→处理器将发生异常时的特权模式保存到异常状态寄存器mstatus/sstatus中.→处理器将异常原因码写入异常状态寄存器mcause/sstatus.→特权级别提升与跳转.→软件异常处理程序接管.→返回到用户程序.
⑥ebreak(environment break)是RV32I指令集中重要调试指令.执行指令时,处理器会产生一个断点异常.→异常进入时,处理器将当前pc存储mepc,设置mcause为3,设置mtval(陷阱值寄存器)为0,跳转到mtvec指定的异常处理程序.
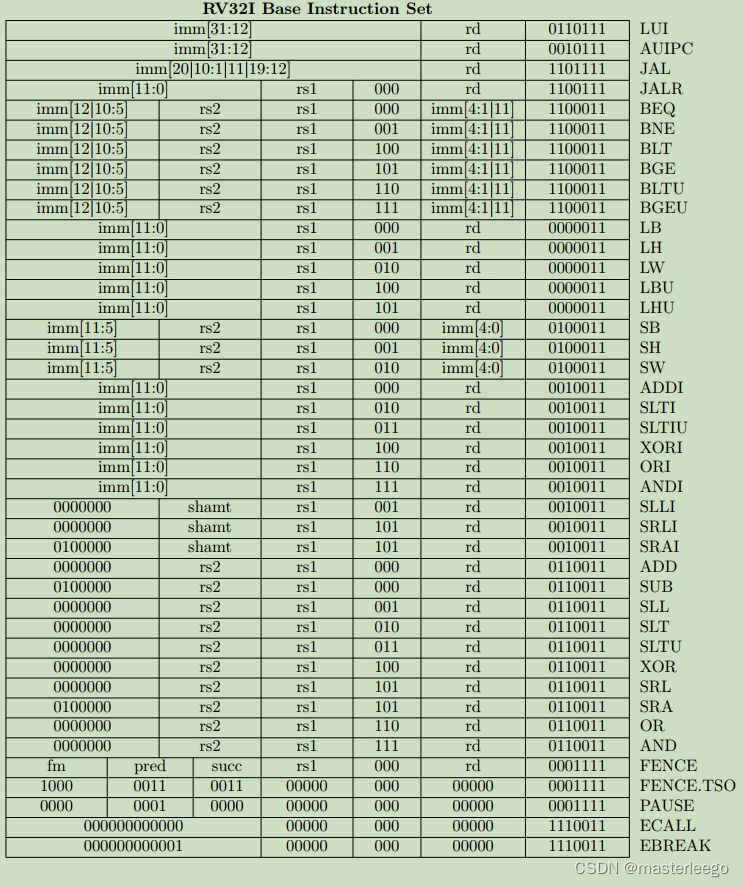
①csrrw用于原子性交换CSR和通用寄存器中的值,其行为是:读取CSR旧值,零扩展至32位后写入通用寄存器rd;将源通用寄存器rs1中的值写入该CSR.注意,若rd=x0或rs1=x0,则跳过读取操作或清零CSR.→csrrw提供原子操作,避免因中断或上下文切换导致的数据不一致.
②csrrs用于原子化读取并置位CSR,其原子化读取目标CSR的当前值,并将其扩展至XLEN位,存入整数寄存器rd中.同时将源寄存器rs1的值视为bitmask,对CSR执行按位或,若rs1中某位为1,则CSR对应位置1,其他位保持不变.→读取、修改、写入三步操作在硬件层面原子完成,中间不会被中断或上下文切换打断.→注意!硬件确保CSR指令不会被异步异常打断,但可能被同步异常打断,比如指令执行中触异常(如非法地址),此时终止执行并跳转异常处理.此外还可能被调试中断打断.
③csrrc提供了一种原子方法来清除CSR中的特定位,同时不会影响其他位,并且能够获取修改前的状态.
④fence指令→处理器和编译器为了优化性能(乱序执行/缓存层次结构),可能会重排内存读写指令的执行顺序.在单线程中这通常是安全的,但在并发多线程环境下,这种重排可能导致程序逻辑错误(违反内存一致性模型).→fence指令不提供任何原子性保证,它只强制特定类型指令执行的相对顺序符合预期,例如,fence前的所有store必须在fence后的任何load/store之前对其他处理器可见.
⑤AMO指令在单个不可分割的步骤中,完成读-修改-写一个内存位置的操作.→当异步中断在AMO执行过程到达时,此时立即冻结AMO操作(暂停在微操作的任意阶段),并且保留关键状态(内存锁保持占用/寄存器值暂存),中断返回后再重新执行AMO指令.
⑥LR/SC提供一种更复杂原子结构的底层原语.其提供了一种有条件的原子性.SC成功执行意味着从LR到SC这段时间内,目标内存位置没有被干扰,因此整个序列(加载/计算/条件存储)的效果是原子的.如果SC失败,则需要重试整个序列.
①ecall指令是risc-v架构中实现特权级跃迁的核心机制.其本质是触发同步异常,强制将控制权从低特权级转移到高特权级(通常是M/S模式).
→
执行ecall指令时,cpu立即停止当前指令流.硬件自动保存PC和原因寄存器,确保异常入口的状态完整性.
②ebreak指令会立即引发一个断点异常,强制暂停当前程序执行,并将控制权转移给调试环境或异常处理程序执行,并将控制权转移给调试环境或异常处理程序.→执行:返回地址保存/异常原因记录/指令编码获取至mtval/跳转至处理程序.→注意!软件需修正mepc以避免死循环.
③add指令忽略算术溢出.其压缩格式为c.add rd,rs2.
④amoadd指令会执行三个操作:i)从内存地址(由rs1指定)加载数据到临时寄存器,将这个数据存入rd寄存器;ii)将加载的数据与rs2寄存器中的值进行加法;iii)将结果写回原始内存地址.所有操作原子完成.→可以通过可选后缀aq/rl控制内存屏障行为.

】哈希表——242.有效的字母异位词、349.两个数组的交集、202.快乐数、1.两数之和)



 用户手册)


)







![[手写系列]Go手写db — — 第三版(实现分组、排序、聚合函数等)](http://pic.xiahunao.cn/[手写系列]Go手写db — — 第三版(实现分组、排序、聚合函数等))


