4、排序分页:
(1)排序:
查询数据的时候进行排序,就是根据某个字段的值,按照升序或者降序的情况将记录显示出来
语法:
select col_name,...
from tb_name
order by col_name [asc|desc]
注意事项:
1. order by语句,只对查询记录显示调整,并不改变查询结果,所以执行权最低,最后执行
2. 排序的默认值是asc:表示升序(可以不写),desc:表示降序
3. 如果有多个列排序,后面的列排序的前提是前面的列排好序以后有重复(相同)的值
先升序排第一列,如果第一列有重复的值,再降序排第二列,以此类推
案例:查看员工的id,名字和薪资,按照薪资的降序排序显示,工资相同就按名字升序排
select id,last_name,salary
from s_emp
order by salary desc,last_name;

(2)分页:
因为表中数据过多,我们并不能一次全都查询出来交给前端去展示,而是需要每次按照提前设置好的要求,查询一部分数据给用户,当用户点击下一页的时候,再查出下一部分数据给用户。
语法:
select 字段列表
from 表名
limit 起始索引, 查询记录数;
案例1:查询s_emp表中,前5条数据
select id,last_name
from s_emp
limit 0,5;
或者
select id,last_name
from s_emp
limit 5;
案例2:查询s_emp表中第二页数据,每页显示5条数据
select id,last_name
from s_emp
limit 5,5;
案例3:查询s_emp表中,第n页,每页显示size条数据
select id,last_name
from s_emp
limit (n-1)*size,size;
注意事项:
1. 起始索引从0开始.计算公式 : 起始索引 = (查询页码 - 1)* 每页显示记录数
2. 分页查询是数据库的方言,不同的数据库有不同的实现,MySQL中是LIMIT
3. 如果查询的是第一页数据,起始索引可以省略,直接简写为 limit 条数
5、多表查询:
多表查询,又称表联合查询,即一条sql语句涉及到的表有多张,表中的数据通过特定的连接,进行联合显示。
注意事项:阿里开发规范中要求多表连接必须给表起别名
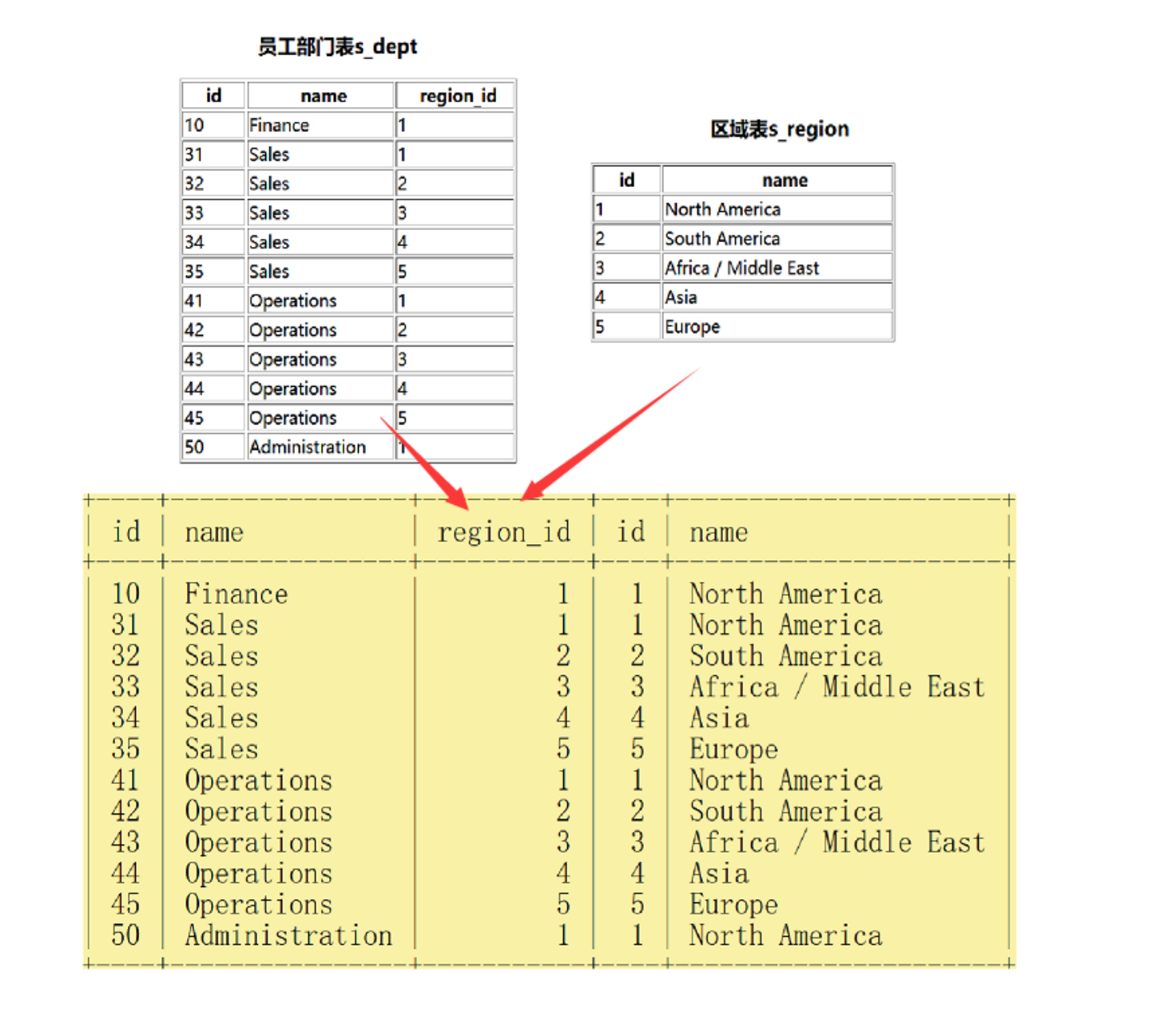
(1)笛卡尔积:
在数学中,两个集合X和Y的笛卡尓积(Cartesian product),又称直积,表示为X × Y
例如,假设集合A={a, b},集合B={0, 1, 2},则两个集合的笛卡尔积为{(a, 0), (a,1), (a, 2), (b, 0), (b, 1), (b, 2)}。
在数据库中,如果直接查询俩张表,那么其查询结果就会产生笛卡尔积。例如这里:s_emp表中25条数据,s_dept表中12条数据,查询俩张表,数据俩俩组合,会得到300条数据
其实,s_emp表中的每一条数据,和s_dept表中的每一条数据进行俩俩组合,这里面大多数的数据是没有意义的,为了这种避免笛卡尔积的产生,在多表查询的时候,可以使用连接查询来解决这个问题。
注意:多表查询本质上将多张小表组合成一张大表,同时要借助连接查询去除无效的笛卡尔积。
(2)等值连接:
等值连接又称为内连接(自然连接),将两张具有关联关系的列的数据连接起来,连接查询where子句中用来连接两个表的条件称为连接条件或者连接谓词,当连接运算为=的时候,称之为等值连接。
语法:
select col_name....
from table_name1,table_name2
where [table_name1].[col_name]=[table_name2].[col_name]
或
select col_name....
from table_name1 inner join table_name2
on [table_name1].[col_name]=[table_name2].[col_name]
案例:查询员工的名字、部门编号、部门名字
select last_name,dept_id,s_dept.id,name
from s_emp,s_dept
where s_emp.dept_id=s_dept.id;
为了表述的更加清楚,可以给每张表起别名
select se.last_name,se.dept_id,sd.id,sd.name
from s_emp se,s_dept sd
where se.dept_id=sd.id;
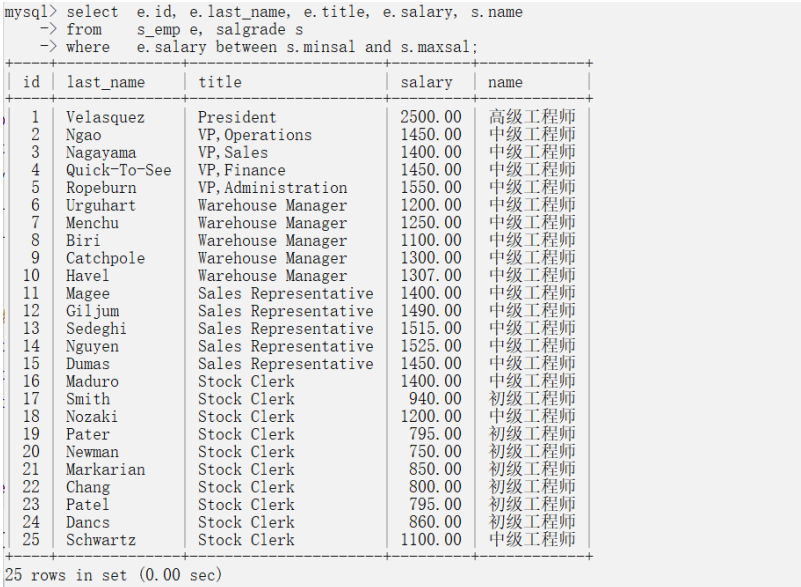
(3)不等值连接:
两张没有关联关系(主外键)的表,通过某个特定场景的业务连接起来,为不等值连接
假设数据库中还有一张工资等级表, salgrade
工资等级表 salgrade :
- gradeName 列表示等级名称
- losal 列表示这个级别的最低工资数
- hisal 列表示这个级别的最高工资数
#新建等级表create table salgrade(id int primary key auto_increment,name varchar(20),minsal float,maxsal float);#往表中插入数据insert into salgrade(name,minsal,maxsal) values('初级工程师',0,1000);insert into salgrade(name,minsal,maxsal) values('中级工程师',1001,2000);insert into salgrade(name,minsal,maxsal) values('高级工程师',2001,3000);#删除表drop table salgrade;案例:查询出员工的名字、职位、工资、工资等级名称
select e.id, e.last_name, e.title, e.salary, s.name from s_emp e, salgrade s where e.salary between s.minsal and s.maxsal;
(4)自连接:
自连接就是一张表,自己和自己连接后进行查询
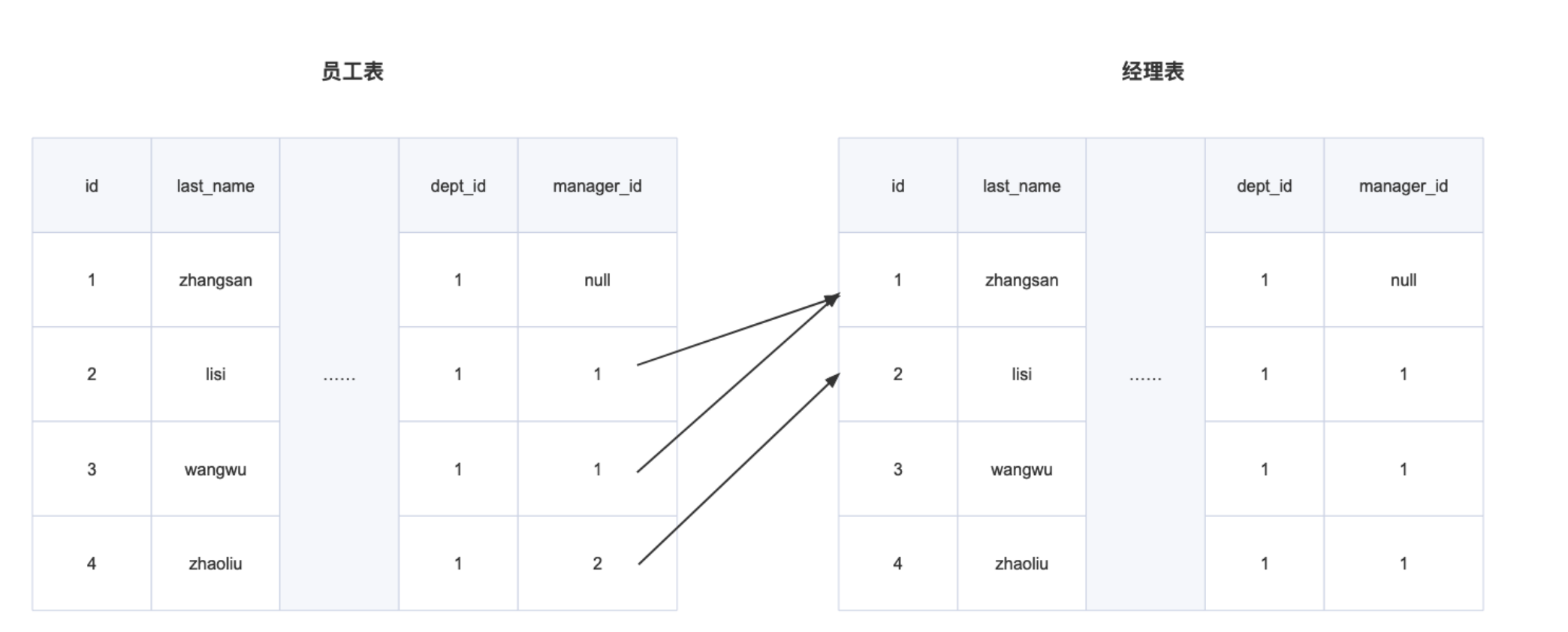
案例1:查询每个员工的名字以及员工对应的管理者的名字
select s1.id,s1.last_name,s2.id,s2.last_name manager_name
from s_emp s1,s_emp s2
where s1.manager_id = s2.id;
# 可理解s1为员工表,s2为经理表
(5)内连接:
内连接查询:查询两表或多表中交集部分数据。
内连接从语法上可以分为: 隐式内连接 与 显式内连接
隐式内连接语法:
select 字段列表
from table_name1,table_name2
where 条件 ... ;
显式内连接语法:
select 字段列表
from table_name1 [inner] join table_name2
on 连接条件 ... ;
案例1:查询员工的姓名及所属的部门名称
隐式内连接实现
select se.id,se.last_name,se.dept_id,sd.id,sd.name
from s_emp se,s_dept sd
where se.dept_id = sd.id;显式内连接实现
select se.id,se.last_name,se.dept_id,sd.id,sd.name
from s_emp se inner join s_dept sd
on se.dept_id = sd.id;注意事项:
一旦为表起了别名,就不能再使用表名来指定对应的字段了,此时只能够使用别名来指定字段。
(6)外连接:
外连接分为,左外连接、右外连接
左外连接:保留表关系中所有匹配的数据记录,包含关联左边表中不匹配的数据记录
语法:
select col_name....
from table_name1 left [outer] join table_name2
on [table_name1].[col_name]=[table_name2].[col_name]
案例1:查询所有员工,以及对应的部门的名字,没有部门的员工也要显示出来
#这里的outer,是可以省去不写
select se.id,se.last_name,se.dept_id,sd.name
from s_emp se left outer join s_dept sd
on se.dept_id=sd.id; 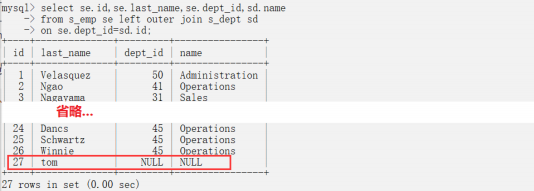
可以看出,左边的第一张表中,新增的一条数据tom,原来等值连接不上,现在也被查询出来了。
右外连接:保留表关系中所有匹配的数据记录,包含关联右边表中不匹配的数据记录。
语法:
select col_name....
from table_name1 right [outer] join table_name2
on [table_name1].[col_name]=[table_name2].[col_name]
案例1:查询所有员工 以及对应的部门的名字,没有任何员工的部门也要显示出来
select se.id,se.last_name,se.dept_id,sd.namefrom s_emp se right outer join s_dept sdon se.dept_id=sd.id;可以看出,右边的第二张表中,新增的一条数据st,原来等值连接不上,现在也被查询出来了
6、单行函数:
函数在计算机语言的使用中贯穿始终,函数可以把我们经常使用的代码封装起来,需要的时候直接调用即可。这样既提高了代码效率,又提高了可维护性 。
在 SQL 中我们也可以使用函数对检索出来的数据进行函数操作。使用这些函数,可以极大地提高用户对数据库的管理效率。
SQL中的函数可以分为两类:单行函数和聚合函数,本章我们重点讨论单行函数。
单行函数接受参数返回一个结果,只对一行进行变换,每行返回一个结果,可以嵌套,参数可以是一列或一个值。
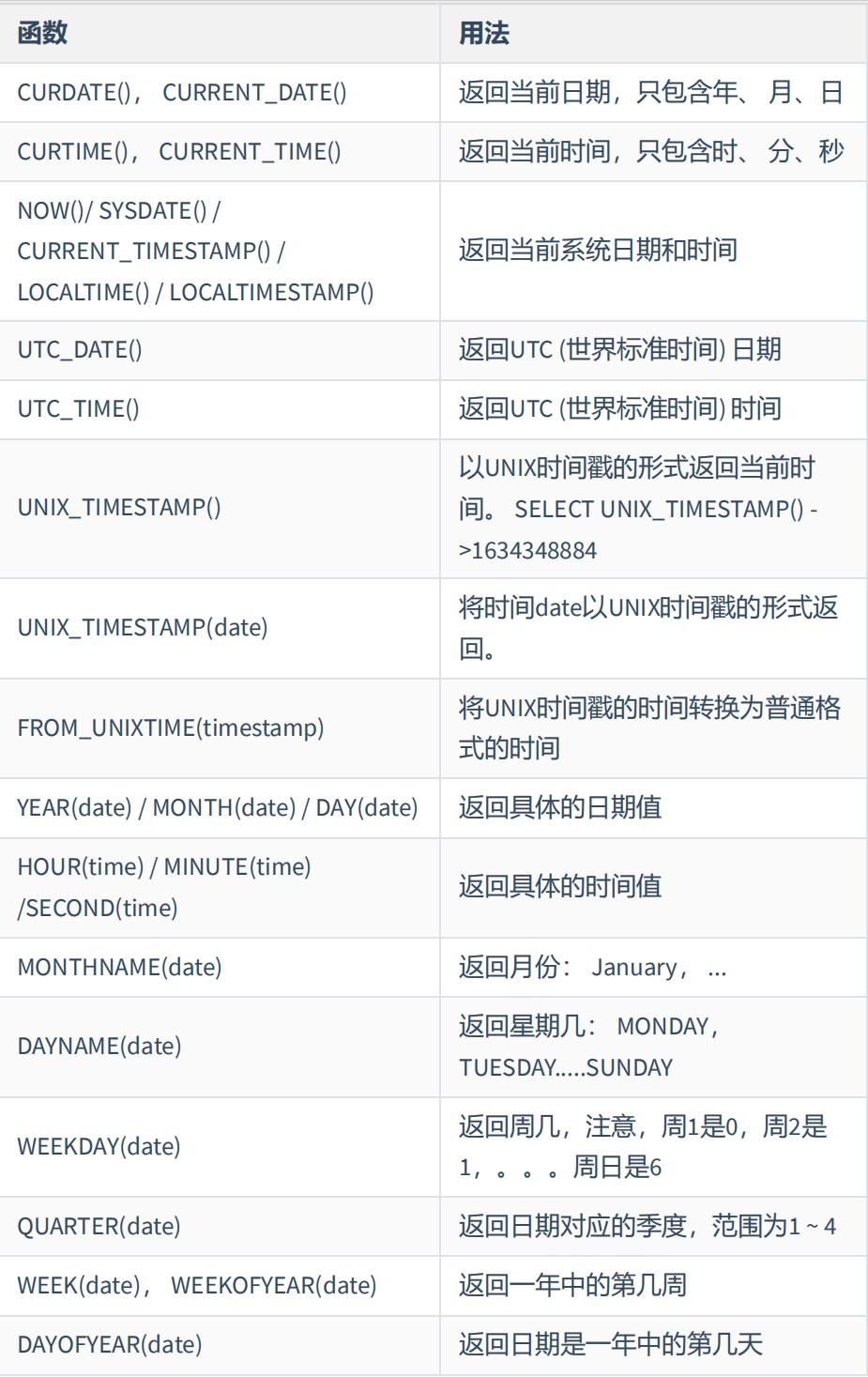
(1)数值函数:
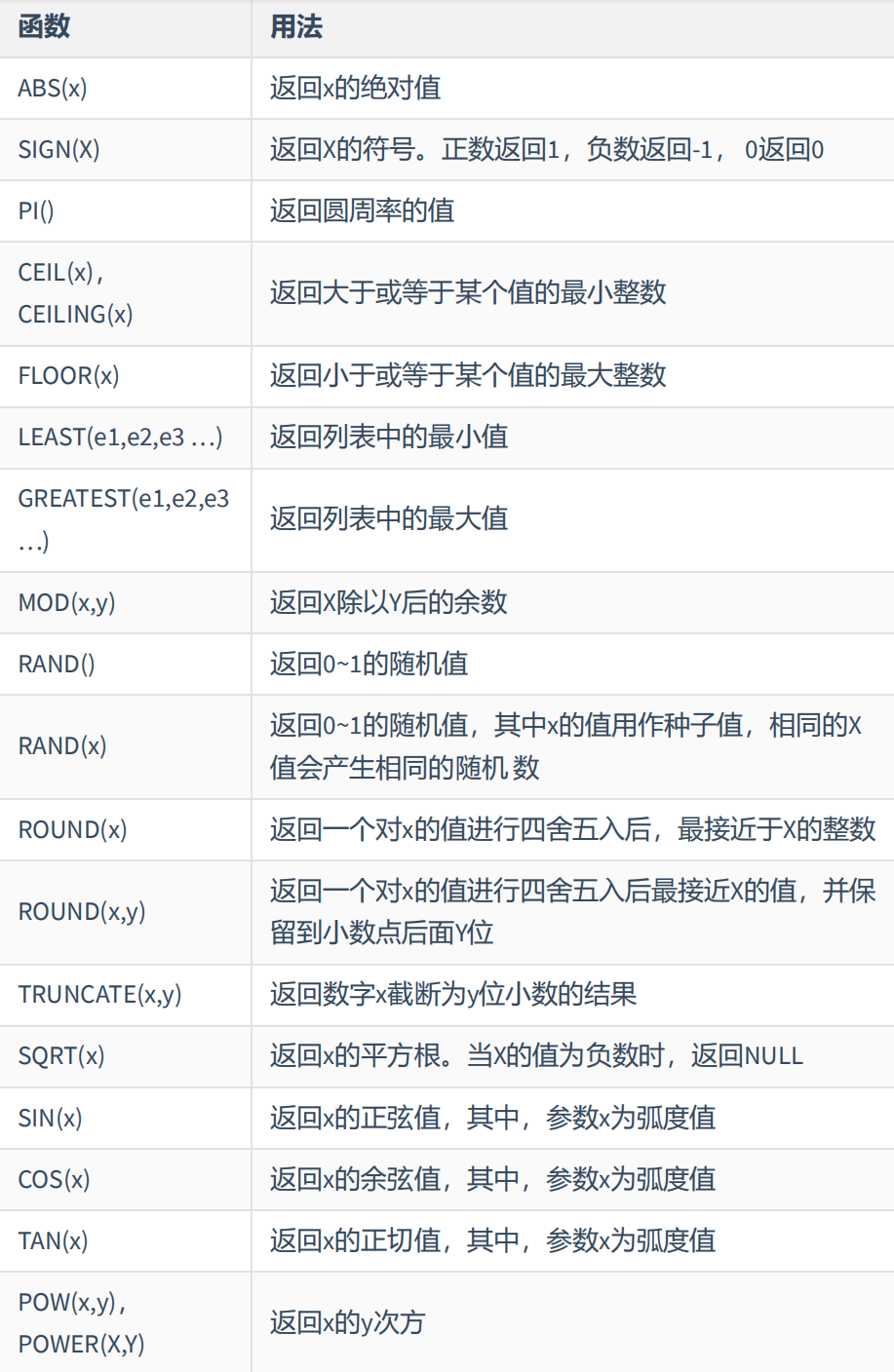
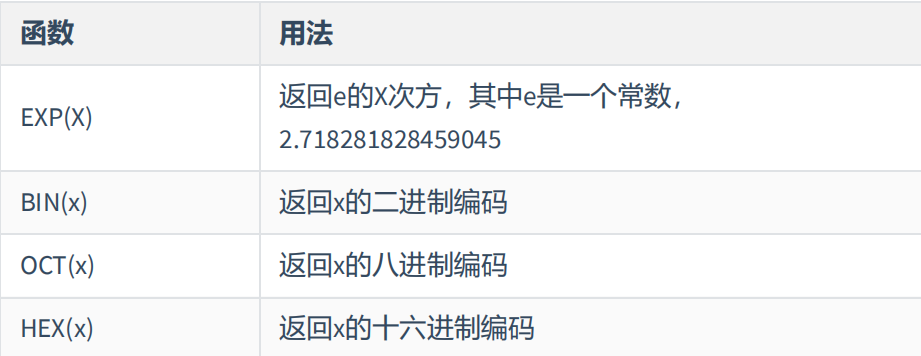
案例展示:
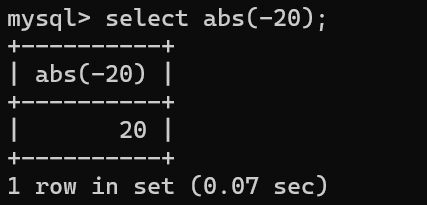
案例1:返回-20的绝对值 select abs(-20);
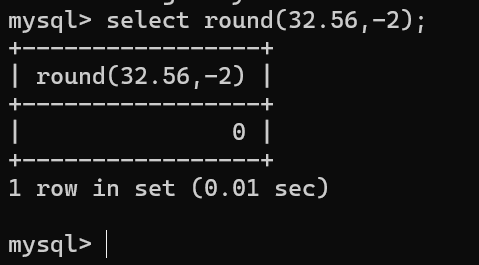
案例2:返回32.56的四舍五入保留小数点后-2位 select round(32.56,-2);
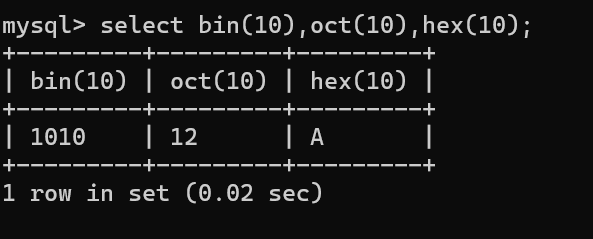
案例3:将10转化为二进制、八进制、十六进制 select bin(10),oct(10),hex(10);
(2)字符串函数:

案例展示:
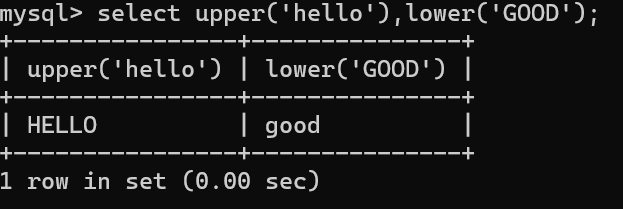
案例1:将hello转化为大写,将GOOD转化为小写 select upper('hello'),lower('GOOD');
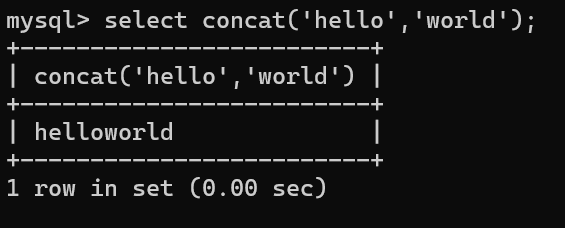
案例2:将hello和world字符串拼接 select concat('hello','world');
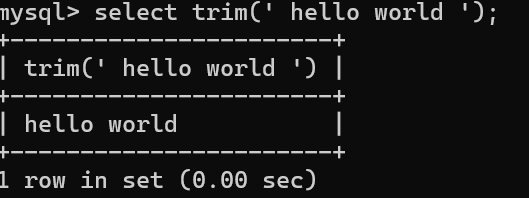
案例3:去除字符串中前后的空白字符 select trim(' hello world ');
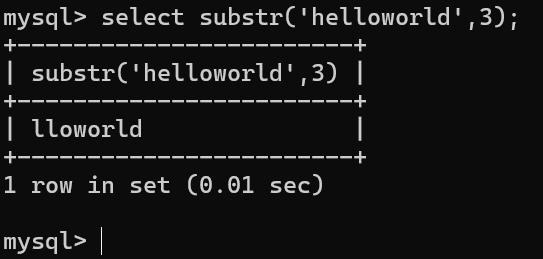
案例4:将helloworld从第3个位置开始截取 select substr('helloworld',3);
(3)时间日期:

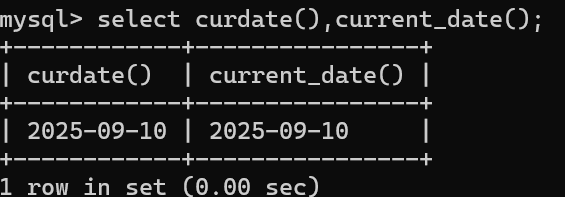
案例1:获取当前时间,包括年月日 select curdate(),current_date();
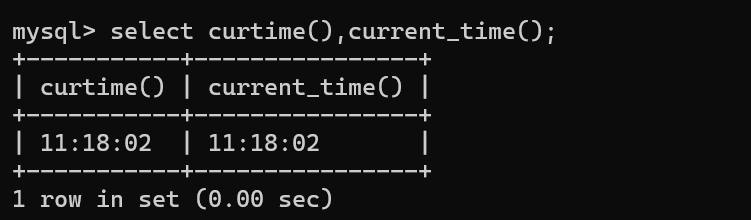
案例2:获取当前时间,包括小时、分钟、秒 select curtime(),current_time();
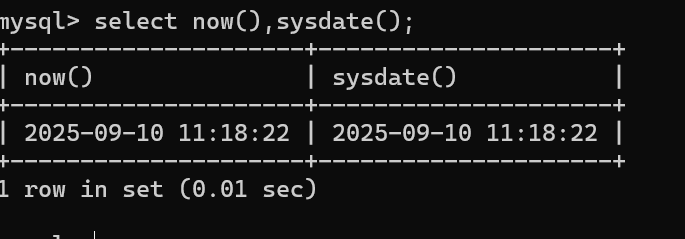
案例3:获取当前系统时间 select now(),sysdate();
案例4:获取世间标准日期和时间 select utc_date(),utc_time();
案例5:获取当前系统时间戳 select unix_timestamp();
案例6:将当前时间转化为时间戳 select unix_timestamp(now());
案例7:将时间戳转化为时间 select from_unixtime(1661789223);
案例8:返回当前是那年 select year(now());
案例9:返回当前时间的年月select extract(year_month from now());
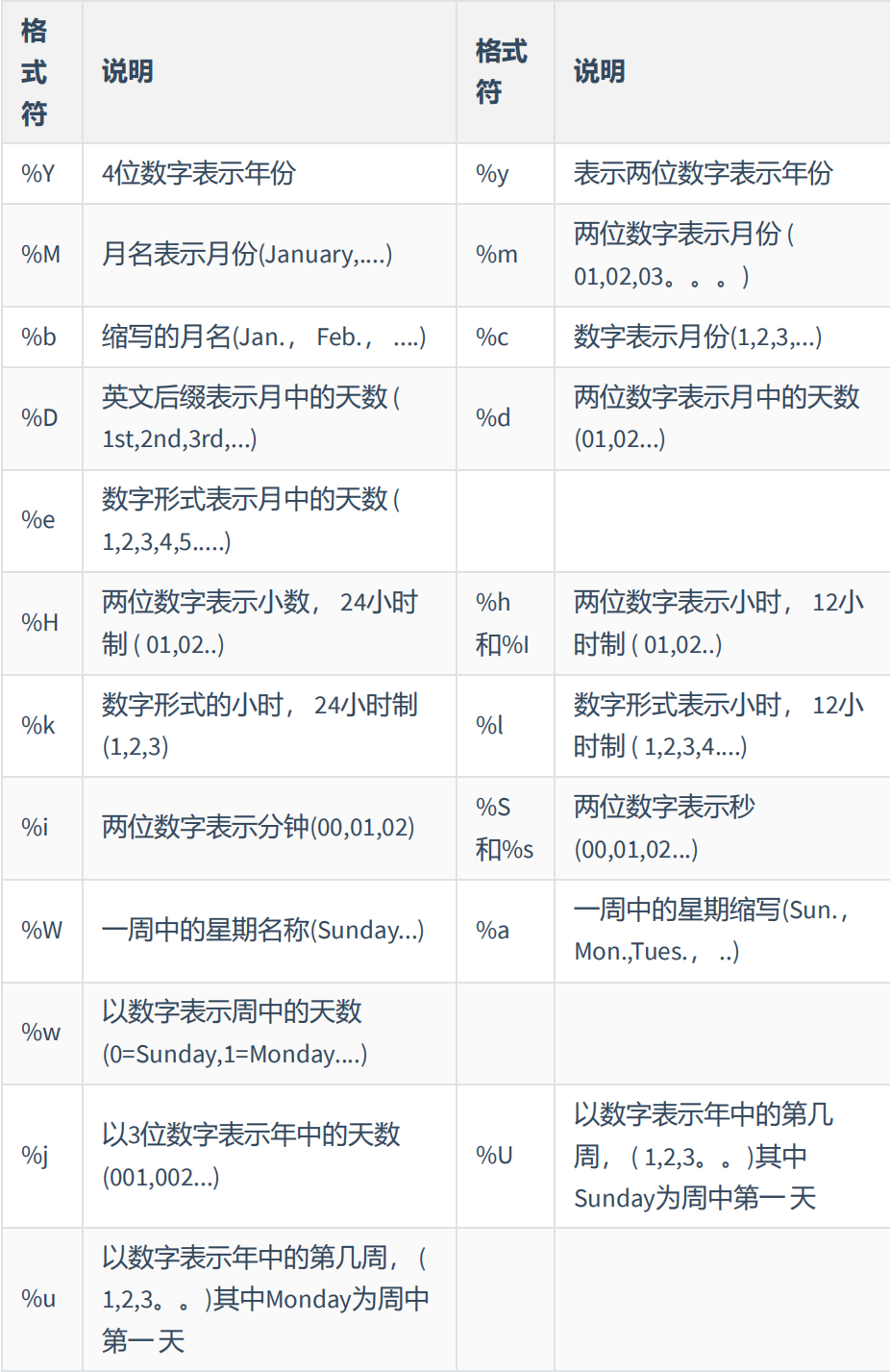
案例10:将当前时间转化为年-月-日 select date_format(now(),'%Y-%m-%d');
fm格式:
(4)流程控制:
流程处理函数可以根据不同的条件,执行不同的处理流程。
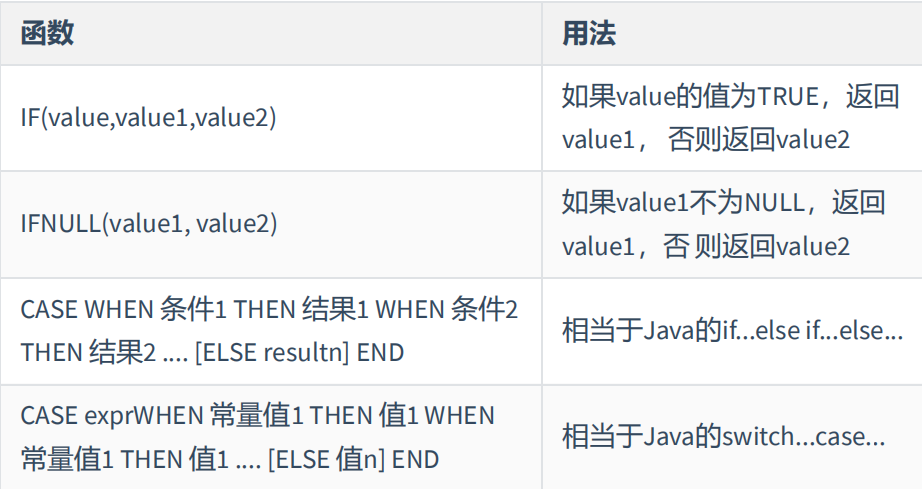
案例1:员工薪水大于1500,显示蓝领,否则白领
select id,last_name,salary,if(salary>2000,'蓝领','白领')from s_emp;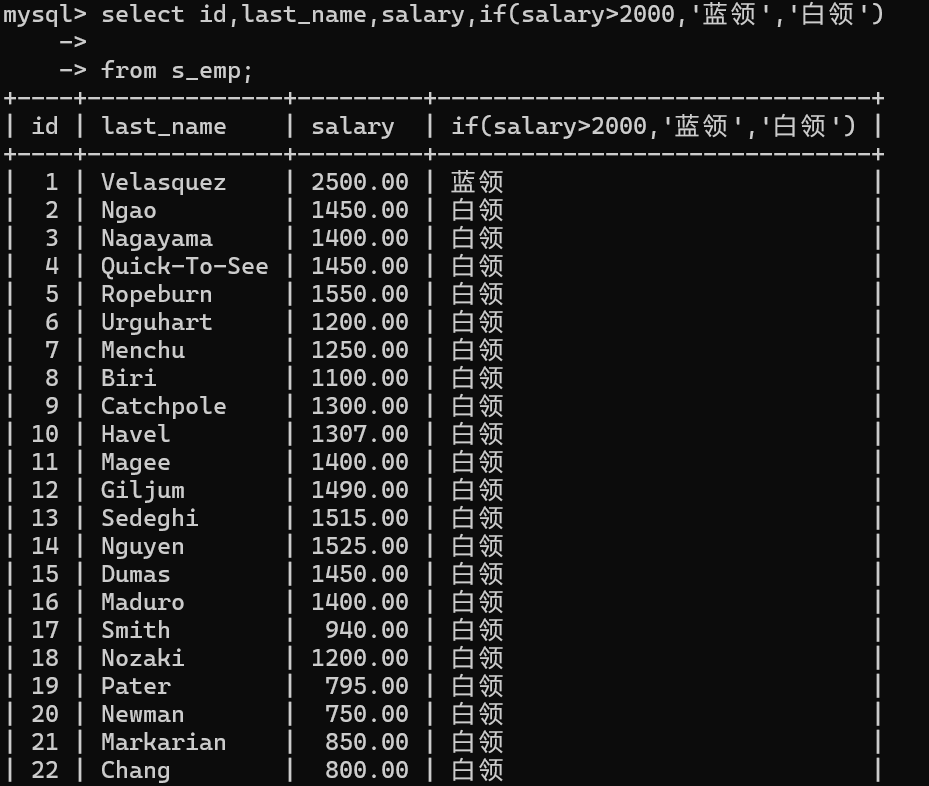
案例2:显示员工年薪薪水为null的用0计算
select id,last_name,salary,ifnull(salary,0)*13 sum_salfrom s_emp;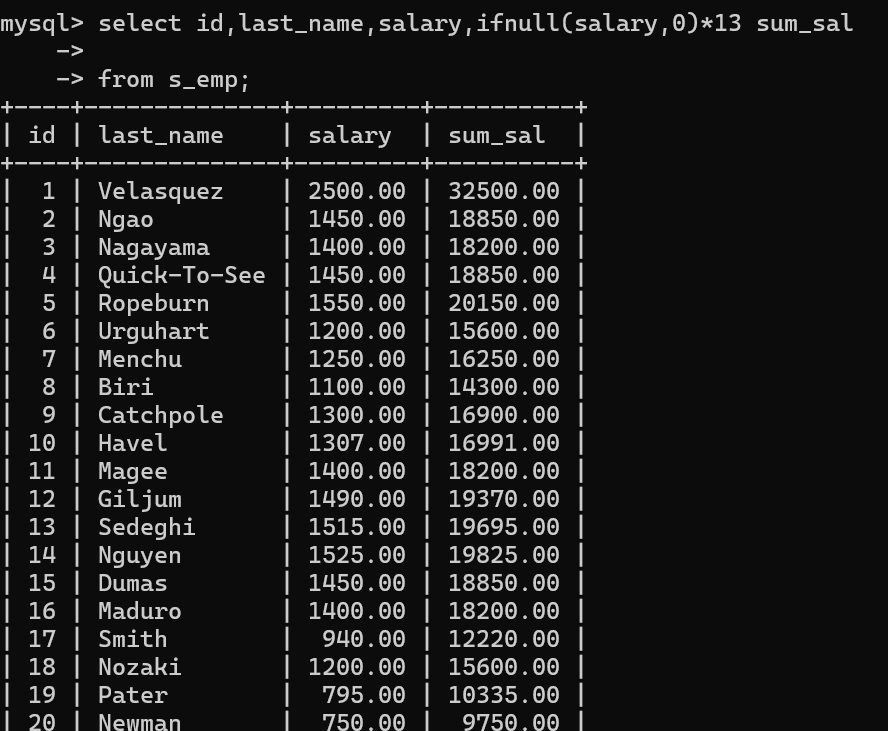
案例3:员工薪水大于2500,显示金领,1500-2500蓝领,否则白领
select id,last_name,salary,case when salary>2500 then '金领'when salary<=2500 and salary>=1500 then '蓝领'else '白领' endas "rank"from s_emp;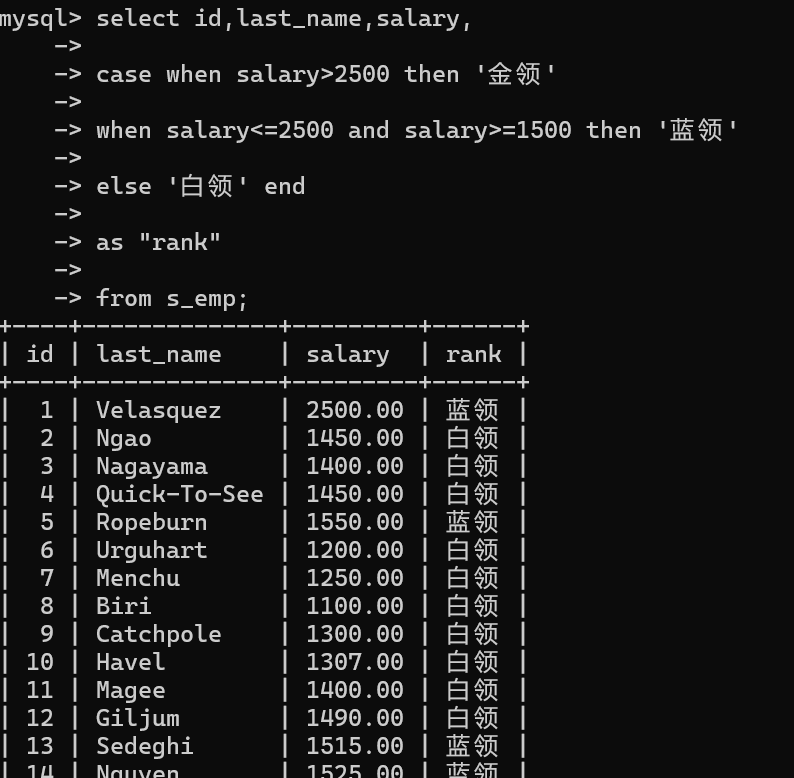
案例4:按照员工编号指定3组员工
select id,last_name,salary,case id%3 when 1 then '1group'when 2 then '2group'else '3group' endas "group"from s_emp;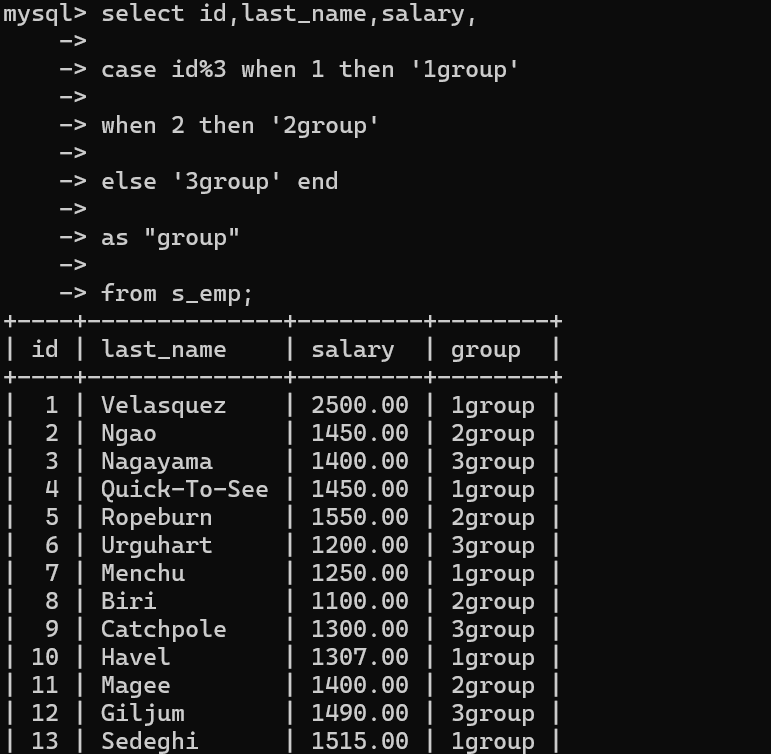









![【python实用小脚本-211】[硬件互联] 桌面壁纸×Python梦幻联动|用10行代码实现“开机盲盒”自动化改造实录(建议收藏)](http://pic.xiahunao.cn/【python实用小脚本-211】[硬件互联] 桌面壁纸×Python梦幻联动|用10行代码实现“开机盲盒”自动化改造实录(建议收藏))


)






:融合Self-Attention的CNN架构)