目录
7.1 整体结构
7.2 卷积层
7.2.1 全连接层存在的问题
7.2.2 卷积运算
7.2.3 填充
7.2.5 3维数据的卷积运算
7.2.6 结合方块思考
7.2.7 批处理
7.3 池化层
7.4 卷积层和池化层的实现
7.4.1 4维数组
7.4.2 基于 im2col的展开
7.4.3 卷积层的实现
7.4.4 池化层的实现
7.5 CNN的实现
7.6 CNN的可视化
7.6.1 第 1层权重的可视化
7.6.2 基于分层结构的信息提取
7.7 具有代表性的 CNN
7.7.1 LeNet
7.7.2 AlexNet
7.8 小结
CNN被用于图像识别、语音识别等各种场合,在图像识别的比赛中,基于深度学习的方法几乎都以CNN为基础。本章将详细介绍CNN的结构,并用Python实现其处理内容。
7.1 整体结构
CNN和之前介绍的神经网络一样,可以像乐高积木一样通过组装层来构建。不过,CNN中新出现了卷积层(Convolution层)和池化层(Pooling层).
之前介绍的神经网络中,相邻层的所有神经元之间都有连接,这称为全连接(fully-connected)。另外,我们用Affine层实现了全连接层。如果使用这个Affine层,一个5层的全连接的神经网络就可以通过图7-1所示的网络结构来实现。
如图7-1所示,全连接的神经网络中,Affine层后面跟着激活函数ReLU层(或者Sigmoid层)。这里堆叠了4层“Affine-ReLU”组合,然后第5层是Affine层,最后由Softmax层输出最终结果(概率)。
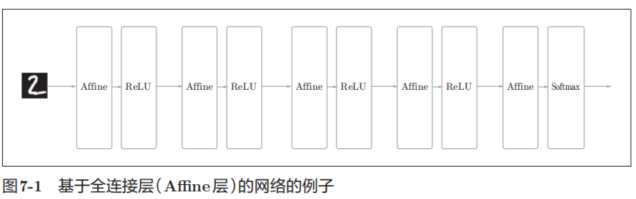
图7-2是CNN的一个例子。
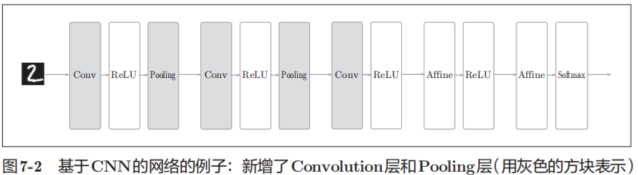
CNN 的层的连接顺序是“Convolution - ReLU -(Pooling)”(Pooling层有时会被省略)。这可以理解为之前的“Affine - ReLU”连接被替换成了“Convolution - ReLU -(Pooling)”连接。
还需要注意的是,在图7-2的CNN中,靠近输出的层中使用了之前的“Affi ne - ReLU”组合。此外,最后的输出层中使用了之前的“Affine -Softmax”组合。这些都是一般的CNN中比较常见的结构。
7.2 卷积层
CNN中出现了一些特有的术语,比如填充、步幅等。此外,各层中传递的数据是有形状的数据(比如,3维数据),这与之前的全连接网络不同,因此刚开始学习CNN时可能会感到难以理解。
7.2.1 全连接层存在的问题
全连接层存在什么问题呢?那就是数据的形状被“忽视”了。比如,输入数据是图像时,图像通常是高、长、通道方向上的3维形状。但是,向全连接层输入时,需要将3维数据拉平为1维数据。实际上,前面提到的使用了MNIST数据集的例子中,输入图像就是1通道、高28像素、长28像素的(1, 28, 28)形状,但却被排成1列,以784个数据的形式输入到最开始的Affine层。
图像是3维形状,这个形状中应该含有重要的空间信息。比如,空间上邻近的像素为相似的值、RBG的各个通道之间分别有密切的关联性、相距较远的像素之间没有什么关联等,3维形状中可能隐藏有值得提取的本质模式。但是,因为全连接层会忽视形状,将全部的输入数据作为相同的神经元(同一维度的神经元)处理,所以无法利用与形状相关的信息。
而卷积层可以保持形状不变。当输入数据是图像时,卷积层会以3维数据的形式接收输入数据,并同样以3维数据的形式输出至下一层。因此,在CNN中,可以(有可能)正确理解图像等具有形状的数据。
另外,CNN 中,有时将卷积层的输入输出数据称为特征图(feature map)。其中,卷积层的输入数据称为输入特征图(input feature map),输出数据称为输出特征图(output feature map)。本书中将“输入输出数据”和“特征图”作为含义相同的词使用。
7.2.2 卷积运算
卷积层进行的处理就是卷积运算。卷积运算相当于图像处理中的“滤波器运算”。
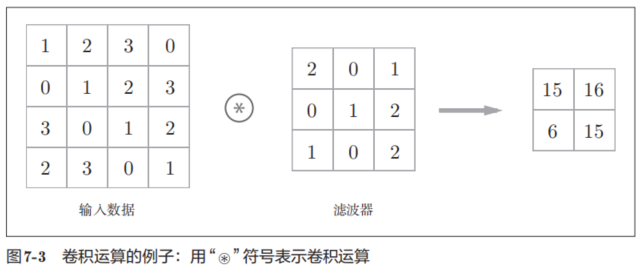
在这个例子中,输入数据是有高长方向的形状的数据,滤波器也一样,有高长方向上的维度。
现在来解释一下图7-3的卷积运算的例子中都进行了什么样的计算。图7-4中展示了卷积运算的计算顺序。
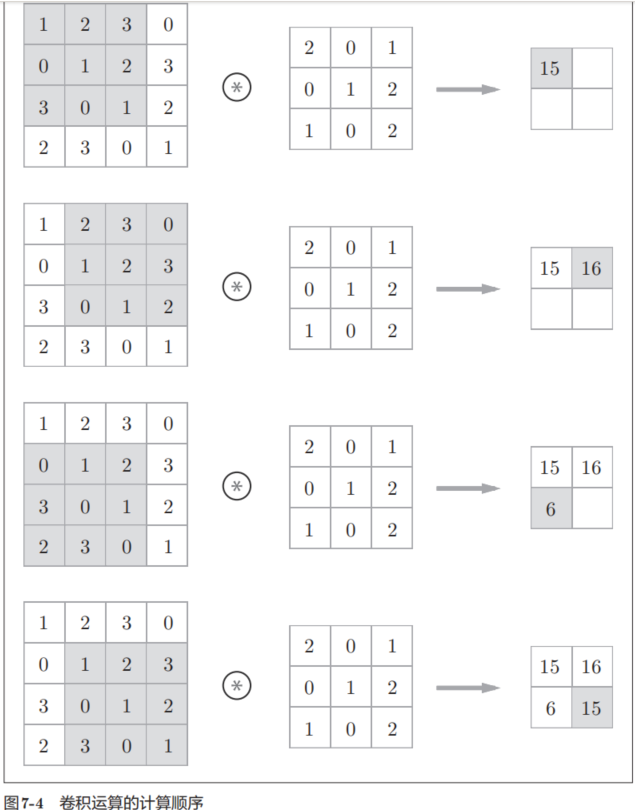
如图7-4所示,将各个位置上滤波器的元素和输入的对应元素相乘,然后再求和(有时将这个计算称为乘积累加运算)。然后,将这个结果保存到输出的对应位置。将这个过程在所有位置都进行一遍,就可以得到卷积运算的输出。
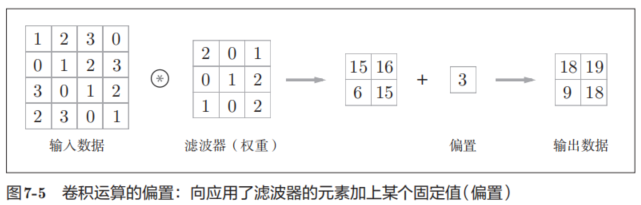
在全连接的神经网络中,除了权重参数,还存在偏置。CNN中,滤波器的参数就对应之前的权重。并且,CNN中也存在偏置。图7-3的卷积运算的例子一直展示到了应用滤波器的阶段。包含偏置的卷积运算的处理流如图7-5所示。
7.2.3 填充
在进行卷积层的处理之前,有时要向输入数据的周围填入固定的数据(比如0等),这称为填充(padding),是卷积运算中经常会用到的处理。比如,在图7-6的例子中,对大小为(4, 4)的输入数据应用了幅度为1的填充。“幅度为1的填充”是指用幅度为1像素的0填充周围。
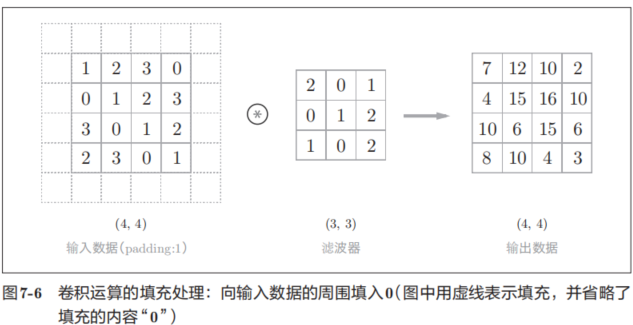
如图7-6所示,通过填充,大小为(4, 4)的输入数据变成了(6, 6)的形状。然后,应用大小为(3, 3)的滤波器,生成了大小为(4, 4)的输出数据。这个例子中将填充设成了1,不过填充的值也可以设置成2、3等任意的整数。在图7-5的例子中,如果将填充设为2,则输入数据的大小变为(8, 8);如果将填充设为3,则大小变为(10, 10)。
使用填充主要是为了调整输出的大小。比如,对大小为(4, 4)的输入数据应用(3, 3)的滤波器时,输出大小变为(2, 2),相当于输出大小比输入大小缩小了 2个元素。这在反复进行多次卷积运算的深度网络中会成为问题。为什么呢?因为如果每次进行卷积运算都会缩小空间,那么在某个时刻输出大小就有可能变为 1,导致无法再应用卷积运算。为了避免出现这样的情况,就要使用填充。在刚才的例子中,将填充的幅度设为 1,那么相对于输入大小(4, 4),输出大小也保持为原来的(4, 4)。因此,卷积运算就可以在保持空间大小不变的情况下将数据传给下一层。
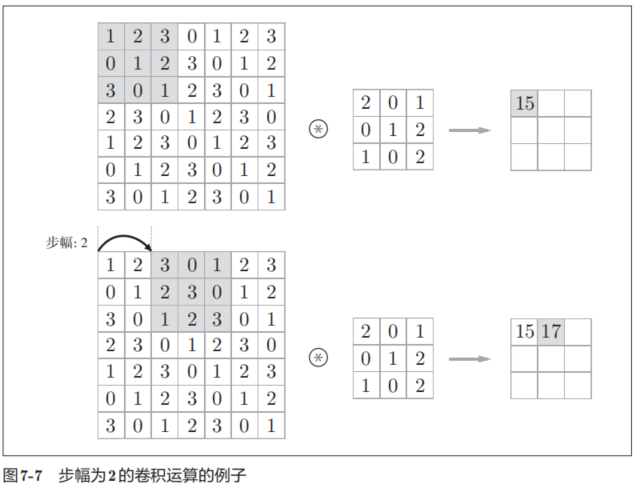
在图7-7的例子中,对输入大小为(7, 7)的数据,以步幅2应用了滤波器。通过将步幅设为2,输出大小变为(3, 3)。像这样,步幅可以指定应用滤波器的间隔。
综上,增大步幅后,输出大小会变小。而增大填充后,输出大小会变大。如果将这样的关系写成算式,会如何呢?接下来,我们看一下对于填充和步幅,如何计算输出大小。
这里,假设输入大小为(H, W),滤波器大小为(FH, FW),输出大小为(OH, OW),填充为P,步幅为S。此时,输出大小可通过式(7.1)进行计算。
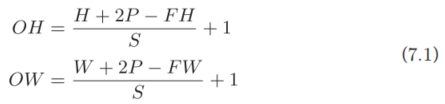
现在,我们使用这个算式,试着做几个计算。

例3
输入大小:(28, 31);填充:2;步幅:3;滤波器大小:(5, 5)
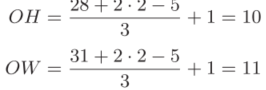
里需要注意的是,虽然只要代入值就可以计算输出大小,但是所设定的值必须使式(7.1)中的
![]()
分别可以除尽。当输出大小无法除尽时(结果是小数时),需要采取报错等对策。
7.2.5 3维数据的卷积运算
之前的卷积运算的例子都是以有高、长方向的2维形状为对象的。但是,图像是3维数据,除了高、长方向之外,还需要处理通道方向。这里,我们按照与之前相同的顺序,看一下对加上了通道方向的3维数据进行卷积运算的例子。
图7-8是卷积运算的例子,图7-9是计算顺序。这里以3通道的数据为例,展示了卷积运算的结果。和2维数据时(图7-3的例子)相比,可以发现纵深方向(通道方向)上特征图增加了。通道方向上有多个特征图时,会按通道进行输入数据和滤波器的卷积运算,并将结果相加,从而得到输出。
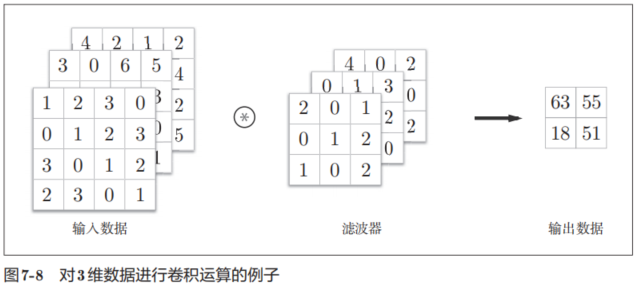
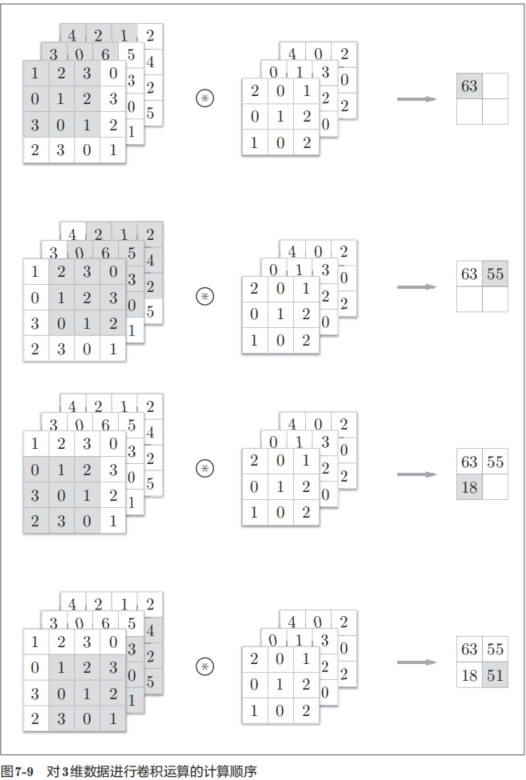
需要注意的是,在3维数据的卷积运算中,输入数据和滤波器的通道数要设为相同的值。在这个例子中,输入数据和滤波器的通道数一致,均为3。
7.2.6 结合方块思考
将数据和滤波器结合长方体的方块来考虑,3维数据的卷积运算会很容易理解。方块是如图7-10所示的3维长方体。把3维数据表示为多维数组时,书写顺序为(channel, height, width)。比如,通道数为C、高度为H、长度为W的数据的形状可以写成(C, H, W)。滤波器也一样,要按(channel, height, width)的顺序书写。比如,通道数为C、滤波器高度为FH(Filter Height)、长度为FW(Filter Width)时,可以写成(C, FH, FW)。
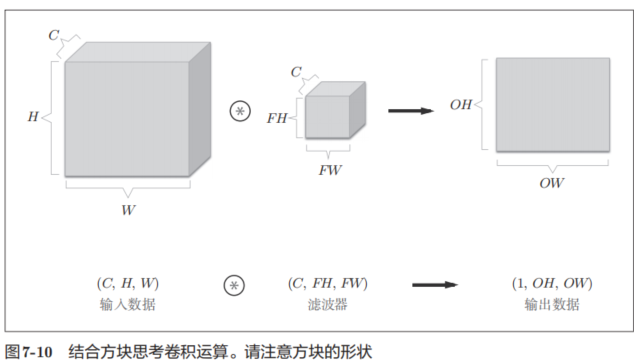
在这个例子中,数据输出是1张特征图。所谓1张特征图,换句话说,就是通道数为1的特征图。那么,如果要在通道方向上也拥有多个卷积运算的输出,该怎么做呢?为此,就需要用到多个滤波器(权重)。用图表示的话,如图7-11所示。
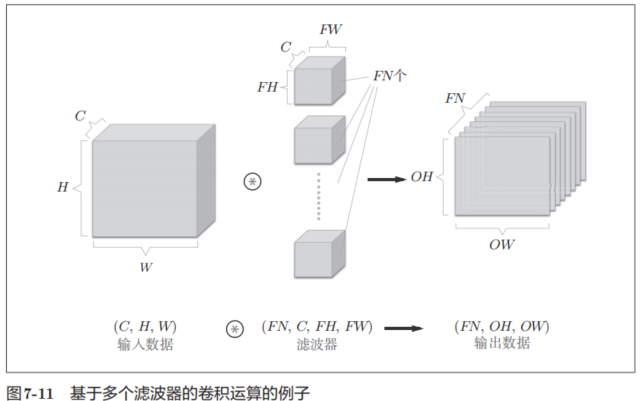
图7-11中,通过应用FN个滤波器,输出特征图也生成了FN个。如果将这FN个特征图汇集在一起,就得到了形状为(FN, OH, OW)的方块。将这个方块传给下一层,就是CNN的处理流。
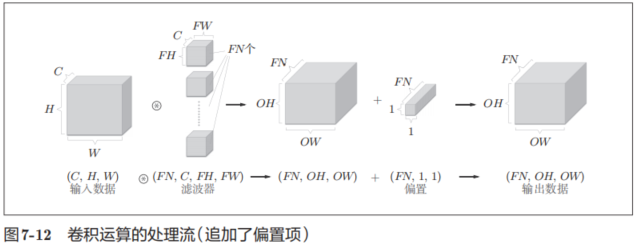
如果进一步追加偏置的加法运算处理,则结果如下面的图7-12所示。
图7-12中,每个通道只有一个偏置。这里,偏置的形状是(FN, 1, 1),滤波器的输出结果的形状是(FN, OH, OW)。这两个方块相加时,要对滤波器的输出结果(FN, OH, OW)按通道加上相同的偏置值。
7.2.7 批处理
我们希望卷积运算也同样对应批处理。为此,需要将在各层间传递的数据保存为4维数据。具体地讲,就是按(batch_num, channel, height, width)的顺序保存数据。比如,将图7-12中的处理改成对N个数据进行批处理时,数据的形状如图7-13所示。
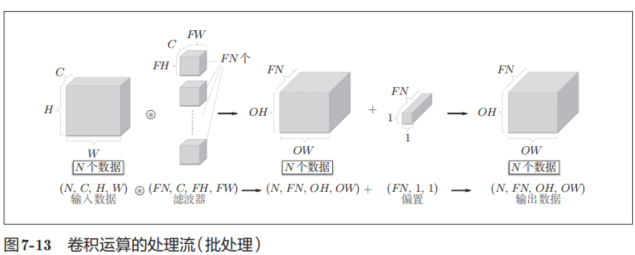
图7-13的批处理版的数据流中,在各个数据的开头添加了批用的维度。像这样,数据作为4维的形状在各层间传递。这里需要注意的是,网络间传递的是4维数据,对这N个数据进行了卷积运算。也就是说,批处理将N次的处理汇总成了1次进行。
7.3 池化层
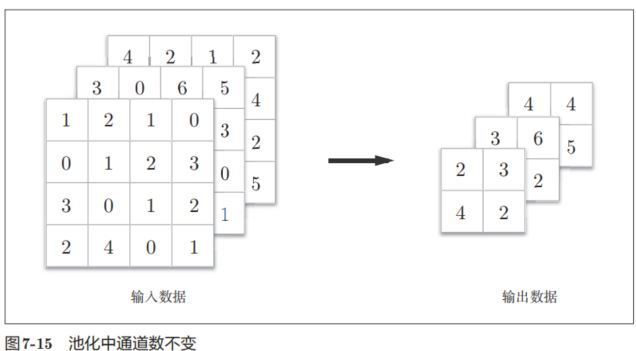
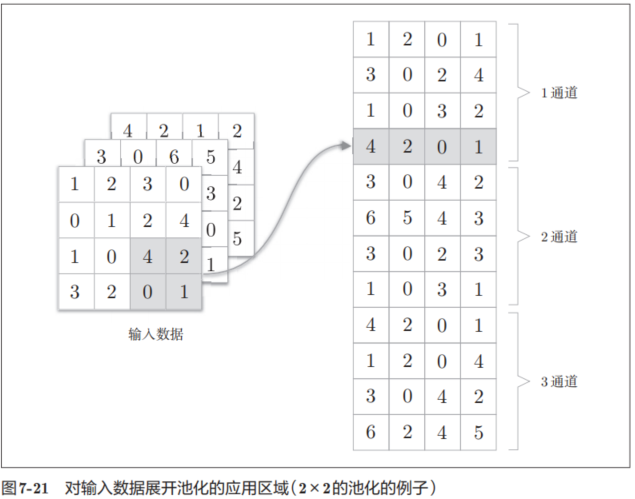
池化是缩小高、长方向上的空间的运算。比如,如图7-14所示,进行将2 × 2的区域集约成1个元素的处理,缩小空间大小。
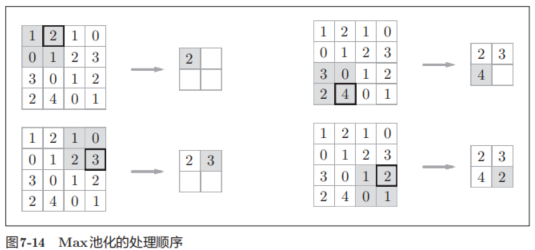
图7-14的例子是按步幅2进行2 × 2的Max池化时的处理顺序。“Max池化”是获取最大值的运算,“2 × 2”表示目标区域的大小。如图所示,从2 × 2的区域中取出最大的元素。此外,这个例子中将步幅设为了2,所以2 × 2的窗口的移动间隔为2个元素。另外,一般来说,池化的窗口大小会和步幅设定成相同的值。比如,3 × 3的窗口的步幅会设为3,4 × 4的窗口的步幅会设为4等。
池化层的特征

对微小的位置变化具有鲁棒性(健壮)
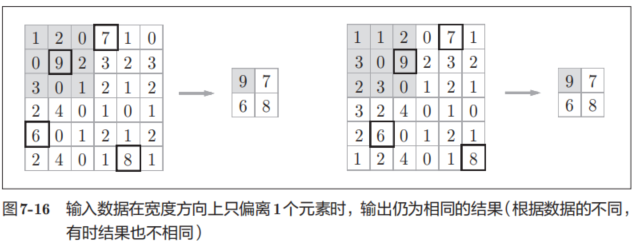
输入数据发生微小偏差时,池化仍会返回相同的结果。因此,池化对输入数据的微小偏差具有鲁棒性。比如,3 × 3的池化的情况下,如图7-16所示,池化会吸收输入数据的偏差(根据数据的不同,结果有可能不一致)。
7.4 卷积层和池化层的实现
7.4.1 4维数组
如前所述,CNN中各层间传递的数据是4维数据。所谓4维数据,比如数据的形状是(10, 1, 28, 28),则它对应10个高为28、长为28、通道为1的数据。用Python来实现的话,如下所示。

这里,如果要访问第1个数据,只要写x[0]就可以了(注意Python的索引是从0开始的)。同样地,用x[1]可以访问第2个数据。
![]()
如果要访问第1个数据的第1个通道的空间数据,可以写成下面这样。
![]()
像这样,CNN中处理的是4维数据,因此卷积运算的实现看上去会很复杂,但是通过使用下面要介绍的im2col这个技巧,问题就会变得很简单。
7.4.2 基于 im2col的展开
如果老老实实地实现卷积运算,估计要重复好几层的for语句。这样的实现有点麻烦,而且,NumPy中存在使用for语句后处理变慢的缺点(NumPy中,访问元素时最好不要用for语句)。这里,我们不使用for语句,而是使用im2col这个便利的函数进行简单的实现。
im2col是一个函数,将输入数据展开以适合滤波器(权重)。如图7-17所示,对3维的输入数据应用im2col后,数据转换为2维矩阵(正确地讲,是把包含批数量的4维数据转换成了2维数据)。
im2col会把输入数据展开以适合滤波器(权重)。具体地说,如图7-18所示,对于输入数据,将应用滤波器的区域(3维方块)横向展开为1列。im2col会在所有应用滤波器的地方进行这个展开处理。
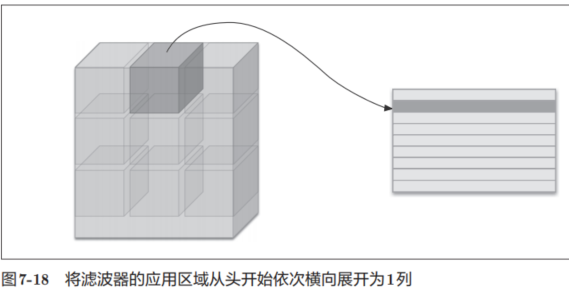
在图7-18中,为了便于观察,将步幅设置得很大,以使滤波器的应用区域不重叠。而在实际的卷积运算中,滤波器的应用区域几乎都是重叠的。在滤波器的应用区域重叠的情况下,使用im2col展开后,展开后的元素个数会多于原方块的元素个数。因此,通过归结到矩阵计算上,可以有效地利用线性代数库
im2col这个名称是“image to column”的缩写,翻译过来就是“从图像到矩阵”的意思。Caffe、Chainer 等深度学习框架中有名为im2col的函数,并且在卷积层的实现中,都使用了im2col。
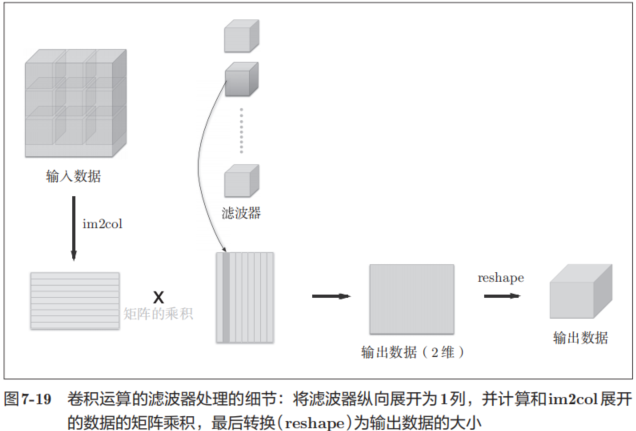
使用im2col展开输入数据后,之后就只需将卷积层的滤波器(权重)纵向展开为1列,并计算2个矩阵的乘积即可(参照图7-19)。这和全连接层的Affine层进行的处理基本相同。
如图7-19所示,基于im2col方式的输出结果是2维矩阵。因为CNN中数据会保存为4维数组,所以要将2维输出数据转换为合适的形状。以上就是卷积层的实现流程。
7.4.3 卷积层的实现
class Convolution:def __init__(self, W, b, stride=1, pad=0):self.W = W # 卷积滤波器权重,形状为 (FN, C, FH, FW)# FN:滤波器个数, C:通道数, FH:滤波器高, FW:滤波器宽self.b = b # 偏置参数self.stride = stride # 卷积步长self.pad = pad # 填充大小def forward(self, x):FN, C, FH, FW = self.W.shape # 获取卷积核的维度:滤波器数量,通道数,高度,宽度N, C, H, W = x.shape # 获取输入数据的维度:批大小,通道数,高度,宽度# 计算输出特征图的尺寸out_h = int(1 + (H + 2*self.pad - FH) / self.stride) # 输出高度out_w = int(1 + (W + 2*self.pad - FW) / self.stride) # 输出宽度col = im2col(x, FH, FW, self.stride, self.pad) # 将输入图像转换为列矩阵col_W = self.W.reshape(FN, -1).T # 将卷积核重塑并转置为二维矩阵out = np.dot(col, col_W) + self.b # 矩阵乘法实现卷积计算并加上偏置# 将输出结果重塑为标准四维格式:(批大小, 滤波器数量, 输出高度, 输出宽度)out = out.reshape(N, out_h, out_w, -1).transpose(0, 3, 1, 2)return out卷积层的初始化方法将滤波器(权重)、偏置、步幅、填充作为参数接收。滤波器是 (FN, C, FH, FW)的 4 维形状。另外,FN、C、FH、FW分别是 FilterNumber(滤波器数量)、Channel、Filter Height、Filter Width的缩写。
展开滤波器的部分(代码段中的粗体字)如图7-19所示,将各个滤波器的方块纵向展开为1列。这里通过reshape(FN,-1)将参数指定为-1,这是reshape的一个便利的功能。通过在reshape时指定为-1,reshape函数会自动计算-1维度上的元素个数,以使多维数组的元素个数前后一致。比如,(10, 3, 5, 5)形状的数组的元素个数共有750个,指定reshape(10,-1)后,就会转换成(10, 75)形状的数组。
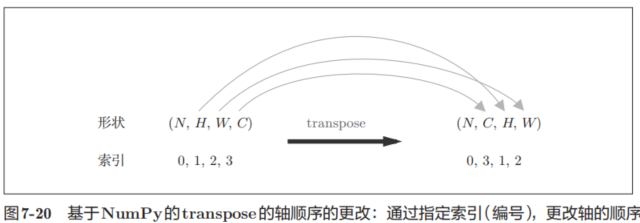
forward的实现中,最后会将输出大小转换为合适的形状。转换时使用了NumPy的transpose函数。transpose会更改多维数组的轴的顺序。如图7-20所示,通过指定从0开始的索引(编号)序列,就可以更改轴的顺序。
以上就是卷积层的forward处理的实现。通过使用im2col进行展开,基本上可以像实现全连接层的Affine层一样来实现(5.6节)。
接下来是卷积层的反向传播的实现,因为和Affine层的实现有很多共通的地方,所以就不再介绍了。但有一点需要注意,在进行卷积层的反向传播时,必须进行im2col的逆处理。除了使用col2im这一点,卷积层的反向传播和Affine层的实现方式都一样。
7.4.4 池化层的实现
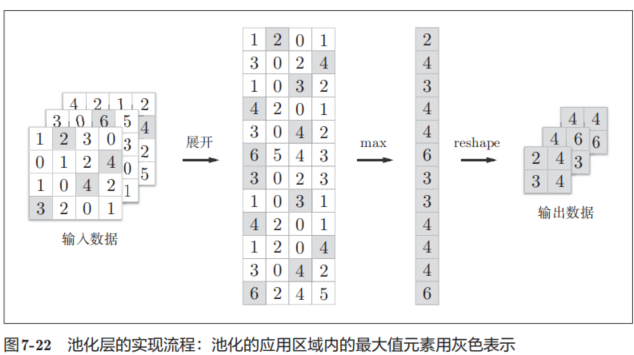
像这样展开之后,只需对展开的矩阵求各行的最大值,并转换为合适的形状即可(图7-22)。
上面就是池化层的forward处理的实现流程。下面来看一下Python的实现示例。
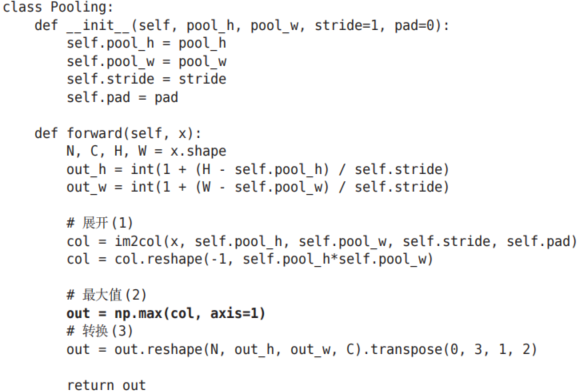
class Pooling:def __init__(self, pool_h, pool_w, stride=1, pad=0):self.pool_h = pool_h # 池化窗口的高度self.pool_w = pool_w # 池化窗口的宽度 self.stride = stride # 卷积步长(窗口移动的步长)self.pad = pad # 边缘填充大小def forward(self, x):N, C, H, W = x.shape # 获取输入数据的维度:批大小,通道数,高度,宽度# 计算输出特征图的尺寸out_h = int(1 + (H - self.pool_h) / self.stride) # 输出高度out_w = int(1 + (W - self.pool_w) / self.stride) # 输出宽度# 展开(1):将输入数据转换为二维矩阵,每行代表一个池化窗口内的所有元素col = im2col(x, self.pool_h, self.pool_w, self.stride, self.pad)# 调整矩阵形状,将每个池化窗口展平为一行col = col.reshape(-1, self.pool_h * self.pool_w)# 最大值(2):对每一行(即每个池化窗口)取最大值,实现最大池化操作out = np.max(col, axis=1)# 转换(3):将结果重塑为四维张量并调整维度顺序为标准格式 (批大小, 通道数, 高, 宽)out = out.reshape(N, out_h, out_w, C).transpose(0, 3, 1, 2)return out # 返回池化后的输出结果如图7-22所示,池化层的实现按下面3个阶段进行。
1.展开输入数据。
2.求各行的最大值。
3.转换为合适的输出大小。
各阶段的实现都很简单,只有一两行代码。
以上就是池化层的forward处理的介绍。如上所述,通过将输入数据展开为容易进行池化的形状,后面的实现就会变得非常简单。
7.5 CNN的实现
这里将由初始化参数传入的卷积层的超参数从字典中取了出来(以方便后面使用),然后,计算卷积层的输出大小。接下来是权重参数的初始化部分。

学习所需的参数是第1层的卷积层和剩余两个全连接层的权重和偏置。 将这些参数保存在实例变量的params字典中。将第1层的卷积层的权重设为关键字W1,偏置设为关键字b1。同样,分别用关键字W2、b2和关键字W3、b3来保存第2个和第3个全连接层的权重和偏置。
最后,生成必要的层。

从最前面开始按顺序向有序字典(OrderedDict)的layers中添加层。只有最后的SoftmaxWithLoss层被添加到别的变量lastLayer中。
以上就是SimpleConvNet的初始化中进行的处理。像这样初始化后,进行推理的predict方法和求损失函数值的loss方法就可以像下面这样实现。

这里,参数x是输入数据,t是教师标签。用于推理的predict方法从头开始依次调用已添加的层,并将结果传递给下一层。在求损失函数的loss方法中,除了使用 predict方法进行的 forward处理之外,还会继续进行forward处理,直到到达最后的SoftmaxWithLoss层。
接下来是基于误差反向传播法求梯度的代码实现。
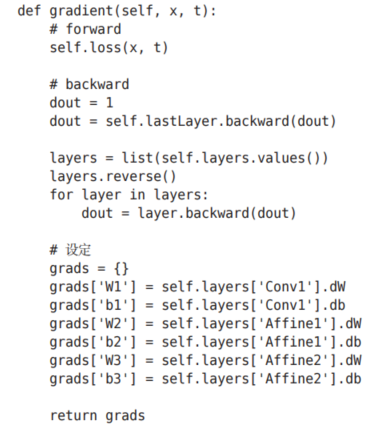
参数的梯度通过误差反向传播法(反向传播)求出,通过把正向传播和反向传播组装在一起来完成。因为已经在各层正确实现了正向传播和反向传播的功能,所以这里只需要以合适的顺序调用即可。最后,把各个权重参数的梯度保存到grads字典中。这就是SimpleConvNet的实现。
7.6 CNN的可视化
CNN中用到的卷积层在“观察”什么呢?本节将通过卷积层的可视化,探索CNN中到底进行了什么处理。
7.6.1 第 1层权重的可视化
刚才我们对MNIST数据集进行了简单的CNN学习。当时,第1层的卷积层的权重的形状是(30, 1, 5, 5),即30个大小为5 × 5、通道为1的滤波器。滤波器大小是5 × 5、通道数是1,意味着滤波器可以可视化为1通道的灰度图像。现在,我们将卷积层(第1层)的滤波器显示为图像。这里,我们来比较一下学习前和学习后的权重,结果如图7-24所示

图7-24中,学习前的滤波器是随机进行初始化的,所以在黑白的浓淡上没有规律可循,但学习后的滤波器变成了有规律的图像。我们发现,通过学习,滤波器被更新成了有规律的滤波器,比如从白到黑渐变的滤波器、含有块状区域(称为blob)的滤波器等。
如果要问图7-24中右边的有规律的滤波器在“观察”什么,答案就是它在观察边缘(颜色变化的分界线)和斑块(局部的块状区域)等。比如,左半部分为白色、右半部分为黑色的滤波器的情况下,如图7-25所示,会对垂直方向上的边缘有响应。
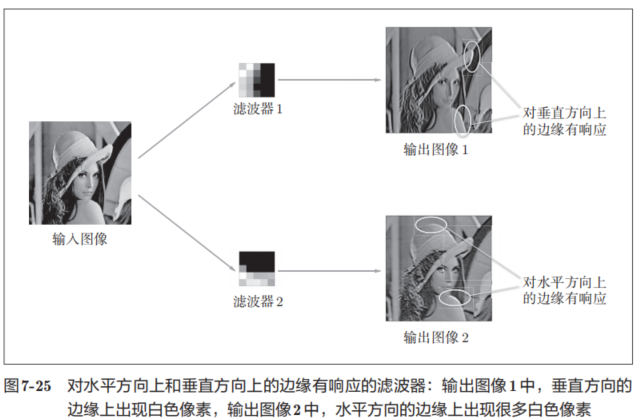
图7-25中显示了选择两个学习完的滤波器对输入图像进行卷积处理时的结果。我们发现“滤波器1”对垂直方向上的边缘有响应,“滤波器2”对水平方向上的边缘有响应。
由此可知,卷积层的滤波器会提取边缘或斑块等原始信息。而刚才实现的CNN会将这些原始信息传递给后面的层。
7.6.2 基于分层结构的信息提取
上面的结果是针对第1层的卷积层得出的。第1层的卷积层中提取了边缘或斑块等“低级”信息,那么在堆叠了多层的CNN中,各层中又会提取什么样的信息呢?随着层次加深,提取的信息(正确地讲,是反映强烈的神经元)也越来越抽象。
图7-26中展示了进行一般物体识别(车或狗等)的8层CNN。这个网络结构的名称是下一节要介绍的AlexNet。AlexNet网络结构堆叠了多层卷积层和池化层,最后经过全连接层输出结果。图7-26的方块表示的是中间数据,对于这些中间数据,会连续应用卷积运算
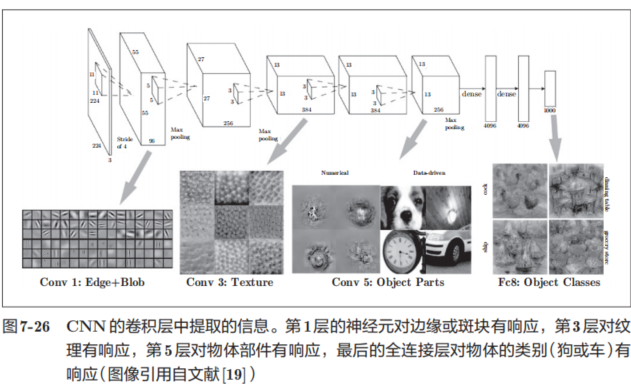
如图7-26所示,如果堆叠了多层卷积层,则随着层次加深,提取的信息也愈加复杂、抽象,这是深度学习中很有意思的一个地方。最开始的层对简单的边缘有响应,接下来的层对纹理有响应,再后面的层对更加复杂的物体部件有响应。也就是说,随着层次加深,神经元从简单的形状向“高级”信息变化。
7.7 具有代表性的 CNN
关于CNN,迄今为止已经提出了各种网络结构。这里,我们介绍其中特别重要的两个网络,一个是在1998年首次被提出的CNN元祖LeNet,另一个是在深度学习受到关注的2012年被提出的AlexNet
7.7.1 LeNet
LeNet在1998年被提出,是进行手写数字识别的网络。如图7-27所示,它有连续的卷积层和池化层(正确地讲,是只“抽选元素”的子采样层),最后经全连接层输出结果。
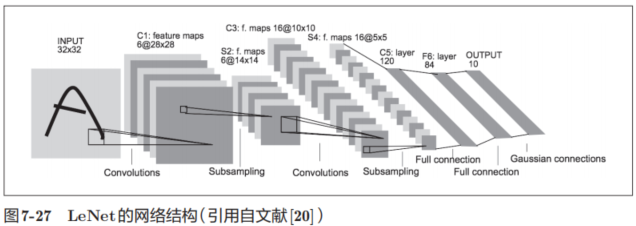
和“现在的CNN”相比,LeNet有几个不同点。第一个不同点在于激活函数。LeNet中使用sigmoid函数,而现在的CNN中主要使用ReLU函数。此外,原始的LeNet中使用子采样(subsampling)缩小中间数据的大小,而现在的CNN中Max池化是主流。
7.7.2 AlexNet
AlexNet是引发深度学习热潮的导火线,不过它的网络结构和LeNet基本上没有什么不同,如图7-28所示。

AlexNet叠有多个卷积层和池化层,最后经由全连接层输出结果。虽然结构上AlexNet和LeNet没有大的不同,但有以下几点差异。

大多数情况下,深度学习(加深了层次的网络)存在大量的参数。因此,学习需要大量的计算,并且需要使那些参数“满意”的大量数据。可以说是 GPU和大数据给这些课题带来了希望。
7.8 小结
• CNN在此前的全连接层的网络中新增了卷积层和池化层。
• 使用im2col函数可以简单、高效地实现卷积层和池化层。
• 通过CNN的可视化,可知随着层次变深,提取的信息愈加高级。
• LeNet和AlexNet是CNN的代表性网络。
• 在深度学习的发展中,大数据和GPU做出了很大的贡献。


))
、GitHub Desktop(版本控制工具)、VSCode(代码编辑器))

 sync.Pool)

 选择器详解:为什么它是“父选择器”?如何实现真正的容器查询?)

后训练方法)





)
控制相机旋转,限制角度)
归并排序)

:项目探索)