目录
1.程序功能描述
2.测试软件版本以及运行结果展示
3.部分程序
4.算法理论概述
5.完整程序
1.程序功能描述
在信息爆炸的时代,用户面临着海量文本信息的筛选难题,文本序列推荐系统应运而生。双向长短期记忆网络(Bi-directional Long Short-Term Memory, Bi-LSTM)凭借其对序列数据前后向信息的捕捉能力,为解决文本序列推荐中的核心问题提供了有效途径。基于双向 LSTM 的文本序列推荐系统能够深入挖掘用户行为序列或文本内容序列中的潜在规律,为用户精准推送符合其兴趣偏好的文本信息。
2.测试软件版本以及运行结果展示
MATLAB2022A/MATLAB2024B版本运行
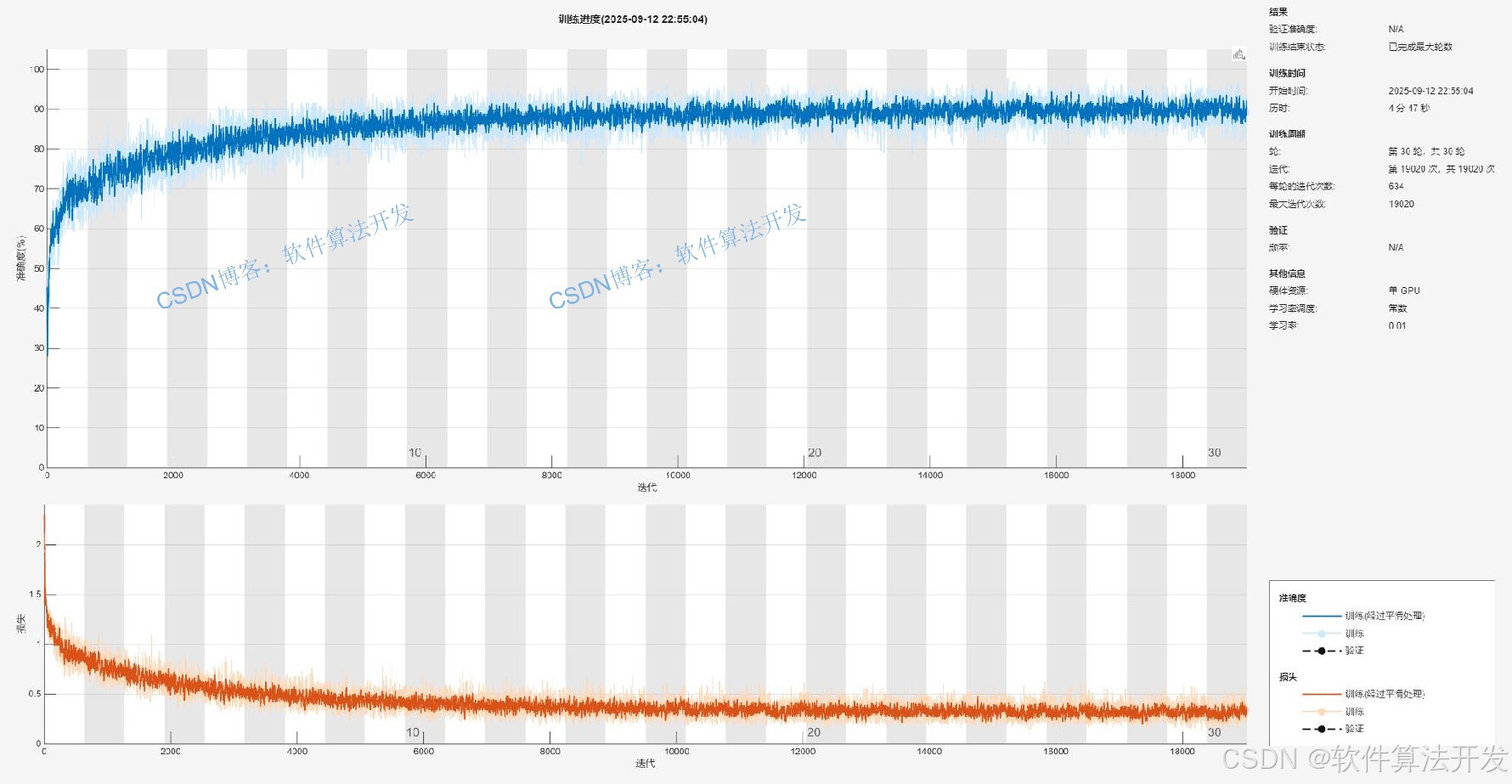
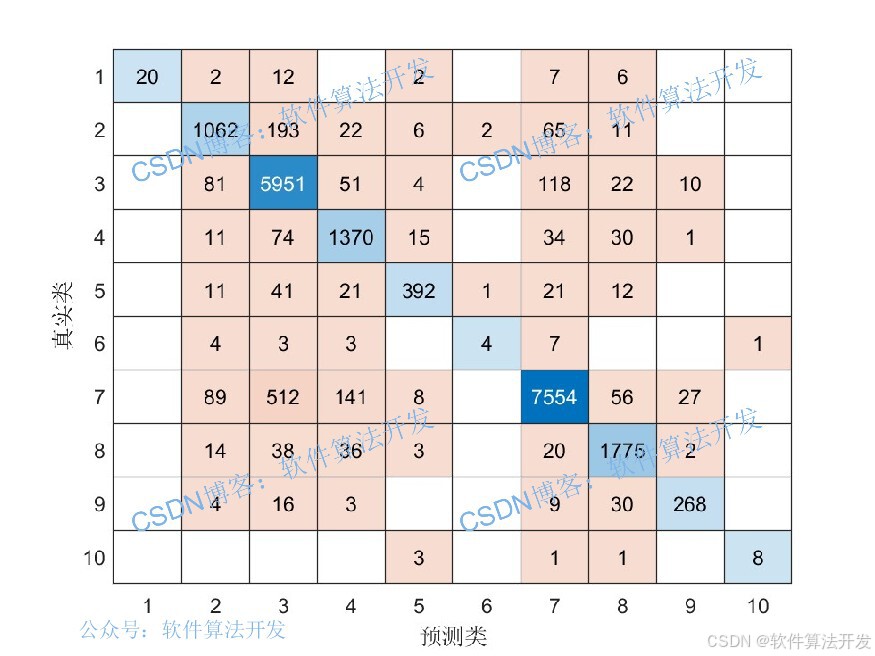
3.部分程序
% 设置网络训练选项(使用Adam优化器)
options = trainingOptions('adam',... 'MaxEpochs',30,... % 最大训练轮数:30轮(遍历训练集30次)'GradientThreshold',1,... % 梯度阈值:限制梯度最大范数为1,防止梯度爆炸'InitialLearnRate',0.01,... % 初始学习率:0.01(Adam优化器的初始步长)'Plots','training-progress',... % 训练过程可视化:显示训练进度图(含训练损失、准确率等)'Verbose', false); % 训练日志显示:false表示不打印每轮的详细训练信息% 训练神经网络:输入训练集特征、训练集标签、网络层结构、训练选项
% 输出训练完成的网络模型net
net = trainNetwork(TrainIn,TrainOut,layers,options);% 保存训练好的网络模型到recommend.mat文件,便于后续加载使用(如测试、推理)
save recommend.mat net
1104.算法理论概述
传统LSTM仅能从序列的起始位置(前向)向后传递信息,捕捉前向的时序依赖关系。然而,在文本序列推荐场景中,文本的语义理解和用户行为的预测往往需要同时考虑序列前后向的信息。例如,在分析用户阅读新闻的序列时,用户当前阅读的新闻选择不仅受之前阅读历史的影响,也可能与之后的阅读偏好存在关联;在理解文本内容时,某个词汇的含义需要结合其上下文(前文和后文)来确定。
双向LSTM通过构建两个独立的LSTM网络(前向LSTM和后向LSTM)来解决这一问题。前向LSTM按照文本序列的正常顺序(从左到右)处理数据,捕捉序列的前向依赖关系,得到前向隐藏状态序列h1,h2,...,hT(其中T为序列长度);后向LSTM则按照文本序列的逆序(从右到左)处理数据,捕捉序列的后向依赖关系,得到后向隐藏状态序列h1,h2,...,hT。
对于序列中每个时刻t,双向LSTM将该时刻的前向隐藏状态ht和后向隐藏状态ht进行拼接(Concatenation)操作,得到双向隐藏状态ht=[ht;ht]。这个双向隐藏状态融合了序列在该时刻前后向的上下文信息,能够更全面、准确地表示文本序列的语义特征和用户行为的时序规律,为后续的推荐任务提供更优质的特征输入。
基于双向LSTM的文本序列推荐系统的核心思想是:将文本序列(如用户行为序列、文本内容序列)作为输入,通过双向LSTM网络挖掘序列中的前后向时序依赖和语义关联,提取出具有代表性的序列特征,再结合推荐任务的目标(如预测用户下一个可能感兴趣的文本、对文本进行排序)设计相应的预测模型,最终实现精准的文本推荐。
文本数据属于非结构化数据,无法直接输入到双向LSTM网络中,因此需要先将文本序列转换为计算机可处理的数值向量形式,即数据表示(Embedding)。
文本分词与预处理:首先对原始文本进行预处理操作,包括去除文本中的特殊字符、标点符号、停用词(如“的”“了”“是”等无实际语义的词汇),然后进行分词(对于中文文本,常用的分词工具如 jieba、HanLP;对于英文文本,可直接按空格分词),得到文本的词汇序列w1,w2,...,wT。
词汇嵌入(Word Embedding):将分词后的词汇序列转换为低维稠密的向量表示。常用的词汇嵌入方法包括Word2Vec(Skip-gram、CBOW模型)、GloVe、FastText等。这些方法通过在大规模语料库上进行训练,将每个词汇映射到一个固定维度的向量空间中,使得语义相近的词汇在向量空间中的距离较近。例如,通过Word2Vec训练后,“苹果”(水果)和 “香蕉” 的向量距离会比 “苹果” 和 “电脑” 的向量距离更近。词汇嵌入不仅解决了传统one-hot编码导致的维度灾难问题,还能有效捕捉词汇的语义信息,为后续的序列特征提取奠定基础。经过词汇嵌入后,文本词汇序列被转换为向量序列x1,x2,...,xT,其中xt∈Rd(d为嵌入向量维度)。
5.完整程序
VVV
——微调Transformer语言模型进行多标签文本分类)
程序发布)




)

——ServiceManager启动)

)


)





)