谷歌DeepMind团队通过Generative Data Refinement(GDR)技术,成功将极端有毒的4chan讨论数据转化为安全且语义丰富的训练素材,推动了LLM训练数据净化的新范式:
• GDR利用预训练大模型对原始数据进行“重写”,而非简单丢弃敏感或有害内容,极大保留了数据的语义结构与多样性。
• 在超过100种个人身份信息(PII)检测任务中,GDR实现了0.99召回率和0.80精准率,优于行业顶级PII检测工具,且用通用占位符替换敏感信息。
• 针对120万+行多语言代码,GDR不仅准确识别并去除PII,还发现了人类标注遗漏的敏感信息,保障训练数据安全与完整。
• GDR对4chan /pol/板块10万条信息进行净化后,整体毒性评分显著下降,甚至与Gemini模型生成的合成讨论内容相当。
• 使用净化后的“安全4chan”数据微调Gemini模型,既提升了模型准确性,也让对话更自然且难以被识别为AI生成。
• 生成的合成数据不仅保留真实数据的多样性,甚至在多样性指标上超越直接生成的合成样本,解决了训练数据因风险过滤而流失多样性的问题。
• 该方法为日益庞大的潜在训练数据池解锁了安全利用路径,推动了更广泛、更真实的语料资源整合。
这背后的核心突破在于“保留语义精华而非粗暴过滤”,为LLM训练提供了兼顾安全与多样性的理想数据基础。未来模型的安全性和表现力有望因此获得质的飞跃。
详情阅读论文🔗arxiv.org/abs/2509.08653
生成式数据优化:只需请求更好的数据
姜敏琪², João G. M. Araújo¹, Will Ellsworth², Sian Gooding¹以及 Edward Grefenstette²Google DeepMind, ²在Google DeepMind工作期间完成的研究
对于固定的参数大小,大型模型的能力主要由其训练数据的质量和数量决定。因此,训练数据集现在增长的速度超过了网络上新数据索引的速度,导致预计在未来十年内将出现数据枯竭。存在大量未公开索引的用户生成内容,但将其纳入其中会带来相当大的风险,例如泄露私人信息和其他不受欢迎的内容。我们介绍了一个框架,生成式数据优化(GDR),用于使用预训练的生成模型将包含不受欢迎内容的数据集转换为更适合训练的优化数据集。我们的实验表明,GDR在数据集匿名化方面可以优于行业级解决方案,并且能够直接对高度不安全的数据集进行脱毒。此外,我们展示了通过生成基于真实数据集中每个示例的条件合成数据,GDR的优化输出自然地匹配了网络规模数据集的多样性,从而避免了通过模型提示生成多样化合成数据的通常具有挑战性的任务。GDR的简单性和有效性使其成为扩展前沿模型训练数据总量的有力工具。
1. 简介
模型性能随参数规模和训练数据量变化的可预测缩放是大规模生成式建模中最具影响力的发现之一。这种缩放规律(Hoffmann et al., 2022; Kaplan et al., 2020)表明,在为基于Transformer的大型语言模型(LLMs)增加训练的FLOPs预算时,模型参数和训练token必须按比例缩放,以保持计算最优,从而实现最佳测试损失。这些发现已引发模型参数数量和训练数据集规模的快速扩展。由于对许多用例和组织而言,模型规模的持续扩展往往不切实际,因此人们进一步集中关注数据扩展。结果,训练数据集现在估计正以比例给上新数据索引速度更快的速度扩展,导致预计在未来十年内将出现数据枯竭(Villalobos et al., 2022)。
包含用户生成数据以及许多其他形式的专有信息。针对此类数据的训练存在若干关键风险,特别是模型可能记住私人信息、有毒内容和受版权保护的材料。或许,鉴于这些风险,许多近期数据扩展工作都集中于制定生成合成数据的协议——这些是有用数据输出,直接从预训练模型或在一个示例数据集上微调的模型中采样。通常,样本可以进一步通过一个捕获目标标准的代理奖励模型进行过滤。这种纯粹的合成方法有其自身的额外成本和风险:微调模型需要额外的计算和服务开销(Rafailov等人,2024)。此外,该过程可能过拟合到奖励模型(Gao等人,2023),也可能坍缩到满足目标标准的可能样本的一个小子集(Kirk等人,2023)。重要的是,在许多领域,合成样本通常与其试图模仿的自然数据明显不同。
然而,这项分析基于公开索引数据集的大小。在网络上未公开索引的形式下,持续不断地创建着更多数据(GSMA,2022;RadicatiGroup.,2020)。这些内容包
我们为合成数据生成任务引入了一种独特的框架,称为生成数据细化(GDR)。在GDR中,我们应用一个预训练的生成模型来修改一个
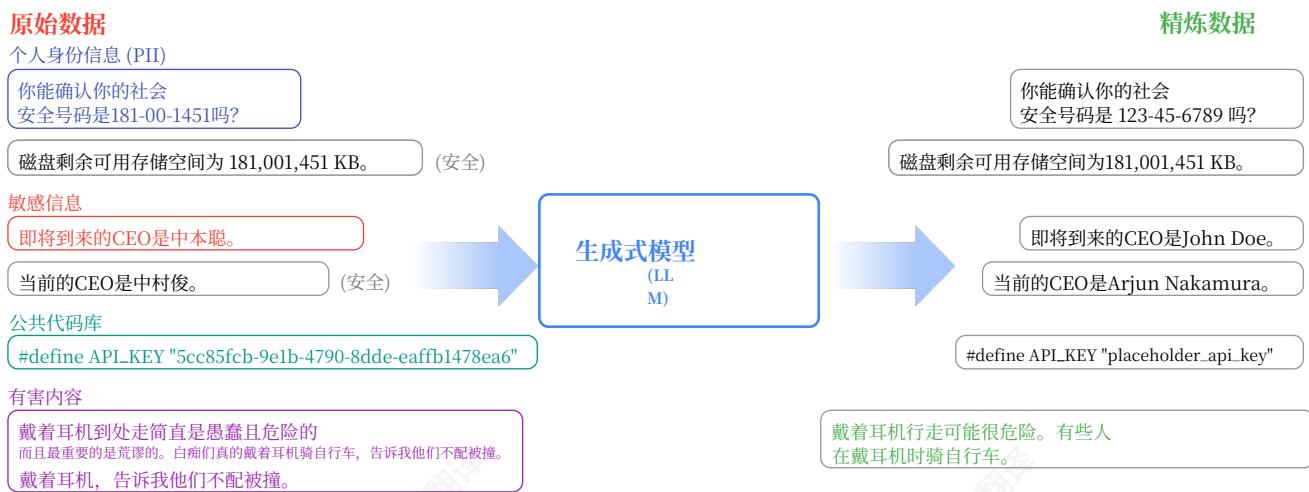
图1|生成式数据优化(GDR)概述。原始数据,可能包含根据一个或多个标准(例如,可识别个人信息的敏感内容、有害内容)的不宜内容,以及应保留的信息,被传递给预训练的生成式模型,例如在大型网络数据上训练的提示LLM,该模型利用其丰富的世界知识来优化每个样本,使其不含不宜内容,同时保留任何其他适当的内容。因此,GDR生成一个适合训练的优化数据集。
真实数据样本集合,使其不包含任何不良内容,例如潜在的个人事实,同时保留任何其他有用信息。我们将锚定在真实数据上的合成数据称为groundedsyntheticdata。通过依赖真实数据样本的内容,GDR方法自然地产生更逼真的输出,这些输出还捕捉了大规模数据集中固有的多样性,从而规避了其他合成数据方法的核心问题此外,GDR可以与额外的模型组件领域特定适应方法相结合,例如任务特定微调、many- shot prompting (Agarwal et al., 2024a; Anil et al., 2024) 和带有奖励模型的搜索。
在这项工作中,我们研究了GDR在文本和代码数据中的应用,重点关注匿名化和解毒等常见数据清理任务。我们的实验表明,GDR,无论是使用零样本提示还是与其他方法(如少样本提示和微调)结合,都可以在多个数据领域显著提高数据匿名化的效果,包括大规模合成数据领域和真实世界的代码库。此外,我们发现GDR在清理高度有毒的对话日志方面非常有效,能够生成毒性显著降低的精炼数据集。
对于这两种数据清理形式,我们展示了GDR的精炼输出可以用于训练模型,这些模型能够在原始数据集中获取有用信息,而不会在其输出中泄露私人或毒性内容。
2.相关工作
2.1.合成数据生成
许多最近的数据扩展工作专注于设计用于从预训练模型中生成高质量样本的协议,这与对齐人类偏好模型或其他奖励模型相一致。这些模型生成的样本然后可以用于进一步微调模型或添加到其他模型的预训练混合中。当模型的自身输出用于训练时,这些样本通常被称为合成数据。在这个讨论中,我们将称生成合成数据的模型为teacher,称在这些样本上训练的模型为学生。这种设置的一个特殊情况是当学生是它自己的teacher,就像在RLHF(Ouyang等人,2022)中一样。最近的工作表明,合成数据方法对于提高模型在领域内任务上的性能非常有效,包括数学推理(Kumar等人,2024;Xin等人,2024),代码生成(Dubey
etal.,2024),图像生成和理解(Boesel和Rombach;Fan等人,2024),网络翻译(Gulcehre等人,2023),以及安全对齐(Bai等人,2022)。
合成数据方法的主要限制源于从对某些真实分布的近似模型中进行采样。根据数据处理不等式(Thomas和Joy,2006),我们无法生成比用于训练的联合数据集中原本存在的更多信息。因此,当从固定模型中进行采样时,合成数据受限于用于训练教师模型的数据库(并且在教师进一步指令微调的情况下,受限于用于训练相关奖励模型的数据库)。此外,通常情况下,教师本身也进行了指令微调,导致输出多样性降低(Kirk等人,2023)。最后,当教师微调以最大化奖励信号时,生成的合成数据可能与真实世界数据差异很大(Kirchner等人,2024;Lewis等人,2017)。
一种生成合成数据的补充方法利用了大规模真实世界数据集的自然多样性。最近的研究探索了这种替代路径,我们称之为基于真实数据的合成数据生成。这些方法通过基于真实示例进行生成来缓解数据真实性和多样性方面的问题。这些方法与少样本或多样本学习相关,而少样本或多样本学习本身可以被视为这种模式的特例。最近的研究已经研究了这种方法用于生成额外的任务数据(Lupidi等人,2024;Yang等人,2024)以及提高现有数据的质量(Boesel和Rombach;Maini等人,2024)。
GDR是一种基于真实数据的合成数据生成实例,我们通过这种方式生成真实数据集的改进版本,而不会产生任何使其不适合用于训练的不良内容。与之前的方法不同,GDR改进现有的真实数据集,而不是生成全新的数据集或增加现有示例的数量。我们相信这种策略可以非常有效地增加可供前沿模型使用的训练token总量,因为由于可能存在敏感或其他不良内容,大量未索引的数据仍然无法用于训练。
GDR因此与之前的方法互补:GDR可以用于改进数据集,这些数据集随后在复合生成管道中由其他合成数据生成方法使用。
2.2.差分隐私
在差分隐私(DP)的范式下,算法向数据点添加噪声,以确保其输出不会泄露任何特定个人的信息,例如该个人贡献的特定数据点。例如,如果算法A被称为 ϵ\epsilonϵ - 差分(Dwork,2006)隐私的,那么对于所有权在一个个体的数据上不同的数据集 D1D_{1}D1 和 D2D_{2}D2 , P(A(D1))/P(A(D2))≤eϵP(\mathcal{A}(D_1)) / P(\mathcal{A}(D_2))\leq e^{\epsilon}P(A(D1))/P(A(D2))≤eϵ 因此,当 ϵ\epsilonϵ 接近零时,任何个人的数据的存在都无法显著改变算法输出的分布,从而无法在置信度为 ϵ\epsilonϵ 的水平上推断任何个人的数据的存在。
虽然DP对任何个人的数据的统计可识别性提供了一定的保证,但这些保证并不适用于存在于许多个人数据点中的任何敏感信息。例如,考虑从一个专注于训练新的前沿LLM模型的私营公司收集的电子邮件数据集。如果其中许多电子邮件包含敏感信息,例如最新模型的参数数量,那么移除任何事实的实例将不会显著改变A在生成的数据集上操作的输出分布,因为这些信息在其他地方仍然得到了很好的表示。换句话说,DP并不直接解决数据泄露问题。DP的另一个缺点是,通过注入噪声,它会剥夺数据中潜在的有用信息,在模型性能和隐私之间创造了一种权衡(Bambauer等人,2013年;Domingo- Ferrer等人,2021年)。
差分隐私已成为在可能包含敏感个人身份信息(PII)的数据集上训练深度学习网络的流行方法。模型泄露此类PII会危及该信息所属个人的隐私和安全(Carlini等人,2019年,2021年;Lukas等人,2023年)。一种常见的方法是DP- SGD(Song等人,2013年),
它通过向每个样本的梯度中注入噪声来修改SGD中的梯度,以确保e- DP保证。虽然理论上合理,但在实践中,DP- SGD的额外梯度操作大大增加了计算成本并延长了训练时间。此外,通过向梯度更新添加噪声,DP- SGD可能会降低样本效率以及训练数据中特定事实的召回率。这种召回通常对模型用于合成数据生成时很重要。差分隐私已成为在可能包含敏感个人身份信息(PII)的数据集上训练深度学习网络的流行方法。模型泄露PII会危及该信息所属个人的隐私和安全(Carlini等人,2019年,2021年;Lukas等人,2023年)。一种常见的方法是DP- SGD(Song等人,2013年),它通过向每个样本的梯度中注入噪声来修改SGD中的梯度,以确保e- DP保证。虽然理论上合理,但在实践中,DP- SGD大大增加了计算成本并延长了训练时间。此外,通过向梯度更新添加噪声,DP- SGD可能会降低样本效率以及训练数据中特定事实的召回率。这种召回通常对模型用于合成数据生成时很重要。
2.3.内容净化
网络和其他媒体上的内容通常包含攻击性或其他不适当的内容,通常在“有毒内容”这一总称下进行标记。许多方法已被提出用于检测有毒内容以进行删除(Li等人,2024;Pavlopoulos等人,2020)。几项近期研究展示了预训练语言模型如何被用于选择性地重写有毒文本,同时保留文本的含义(Bhan等人,2024;Dale等人,2021;Laugier等人,2021)。然而,这些方法依赖于在有毒数据集上训练过的专门LLM或分类器。我们的工作不同之处在于,我们证明了经过充分训练的LLM的GDR能够直接净化文本内容,而无需任何专门模型。此外,我们的实验揭示了通过GDR方法获得的精炼数据集的多样性和信息价值,为除标准内容审核设置之外的去毒性提供了重要的实证论据,展示了它们在模型训练数据集管理这一重要设置中的实用性。
3.生成式数据优化
相比之下,GDR通过在训练之前直接从数据集中移除任何敏感信息实例来解决数据泄露的互补问题(即在使用A处理数据之前)。给定一个足够强大的生成模型(Achiam等人,2023;Anthropic,2023;Dubey等人,2024),经过GDR处理的数据不会出现原始数据集中其他非敏感信息的低召回率。与大多数差分隐私方法在数据处理管道中盲目添加高斯噪声不同,GDR利用大型生成模型中固有的世界知识来选择性地重写数据中存在问题的部分。通过这种方式,GDR将生成模型用作智能噪声操作符,类似于最近那些在进化算法中替换掉简单(通常是高斯)噪声(或“变异”)操作符的研究(Bradley等人,2023;Lange等人,2024;Lehman等人,2023;Samvelyan等人,2024)。
我们的合成数据生成问题设置,称为生成式数据优化(GDR),寻求一个生成过程,将数据集 DDD 重写为更适合训练的形式。
问题设置
设 ggg 为一个生成过程,包括任何潜在的关联生成模型和提示。设h为一个指示函数,用于我们的合成数据域,以评估某个感兴趣的标准。对于原始数据集 DDD 中的所有 xix_{i}xi ,如果 xix_{i}xi 满足标准,则 h(xi)\mathrm{h}(x_i)h(xi) =1= 1=1 ,否则为 h(xi)=0∘h(x_i) = 0_\circh(xi)=0∘ 此外,设 Δ(\Delta (Δ( x,y)x,y)x,y) 为数据域中两点之间的距离函数。
对于所有输入 xix_{i}xi 在 DDD 中,GDR寻求一个生成过程 ggg ,其中 yi∼g(⋅∣xi)y_{i}\sim g(\cdot |x_{i})yi∼g(⋅∣xi) 满足 h(yi)=1h(y_i) = 1h(yi)=1 并具有最小的 Δ(xi,yi)\Delta (x_i,y_i)Δ(xi,yi) ,并因此产生一个新的精炼数据集 D′={yi}∘D^{\prime} = \{y_{i}\}_{\circ}D′={yi}∘
由指标h捕获的感兴趣标准可以是任何可以通过某些验证函数评估的数据点约束。例如,标准可以是文本是否包含拼写错误,或者图像是否包含日出。在这项工作中,我们关注生成过程 ggg 是一个经过大规模数据集训练的提示式LLM的简单情况。
在真实数据上对合成数据生成进行条件化是一个概念上简单的转变,具有深远的意义。流行的合成数据方法通常依赖于在某个数据集上训练过的生成模型的重复采样,导致数据多样性降低因为输出倾向于偏向训练混合中频繁表示的结构(Long等人,2024)。相比之下,真实世界的数据集通常具有更大的多样性,特别是在丰富、开放式的领域,其中大型生成模型能够提供最大的效益(Gao等人,2020)。通过将合成数据生成重新定义为对这类真实数据集的精炼,GDR的输出可以继承真实世界的数据多样性,同时利用预训练模型的生成能力。
一方面,由于GDR以黑盒方式使用生成模型作为其数据转换,任何GDR实例都有望从底层生成建模方法的快速改进中受益。例如,改进的指令跟随能力可以直接转化为更好的遵循转换指令。另一方面,GDR可能计算密集,在最坏的情况下,需要大约是同一数据集完整训练运行三分之一的FLOP成本(Kaplan等人,2020)。然而,这种后者的成本会随着时间的推移而摊销,因为最终的精炼数据集可以在未来的模型训练运行中重复使用。更实际的是,实际成本可能要低得多,因为较小的模型可以被微调以达到较大模型的质量(正如我们的实验将显示的那样),以及通过利用最初较大的模型进行蒸馏或其他改进。
在这项工作中,我们研究了自然语言和代码领域中GDR,其中LLMs
可以作为许多细化标准的通用转换。我们专注于将GDR应用于数据匿名化和内容去毒化任务这是在为前沿LLMs扩展训练数据时面临的两个普遍挑战。
4.匿名化数据
我们将GDR与2024年9月版本的商业方法进行比较,该方法通常用于实践中用于检测个人身份信息(PII)。我们称此服务为基于检测器的信息删除服务(DIRS),它包含一组用于识别PII子字符串的PII检测器,每个检测器专门用于特定的PII类别,例如真实姓名和国家/地区特定的国家ID。这些检测器的实现方式各不相同。一些检测器,例如真实姓名检测,使用特定领域的统计分类器,这种方法受限于较小训练数据集的范围,而LLM预训练中使用的互联网规模数据集则更大。大部分检测器依赖于基于正则表达式和热词的使用规则启发式方法。这些方法通常比较脆弱,并且无法考虑父文本上下文中的潜在PII。相比之下,GDR利用预训练LLM中的庞大世界知识来识别PII,同时考虑父文本的完整上下文。与DIRS不同,GDR使用单个模型,该模型可以预期在许多PII类别中泛化。
GDR是一种生成式方法,而DIRS是一种判别式方法。DIRS可以作为数据重写管道的第一阶段,但在重写中使用的替换内容必须由核心检测逻辑之外的某个独立模块指定。例如,DIRS服务提供了一种选项,可以用预定义的安全字符串库中提供的值替换检测到的子字符串。鉴于DIRS主要的判别性质,基于DIRS的数据清理管道通常使用它来标记可能包含PII的文档并将这些文档标记为从训练集中移除。相比之下,GDR直接生成上下文相关的替换内容来替换PII。关键在于,这种区别使GDR能够挽救这些数据用于训练。
4.1.GDR在PII类别中的有效性
表1|针对108个PII类别的20k个句子进行交叉验证的精确率、召回率和F分数。
| 回忆 | 精度 | F分数 | |
| DIRS | 0.53 | 0.52 | 0.52 |
| GDR | 0.99 | 0.80 | 0.88 |
4.1. GDR在PII类别中的有效性表1|针对108个PII类别的20k个句子进行交叉验证的精确率、召回率和F分数。
| 回忆 | 精度 | F分数 | |
| DIRS | 0.53 | 0.52 | 0.52 |
| GDR | 0.99 | 0.80 | 0.88 |
在图1中,我们报告了每种方法在所有类别上的平均召回率,以及数字PII类别的平均精确率。我们的结果表明,基于GeminiPro1.5的单个、共享的零样本提示,用于所有108个类别的PII移除,在召回率和精确率方面均显著优于DIRS的专用检测器集合(有表示例句子及其通过附录A中的提示使用GDR进行的改进,请参见附录K中的表6和表7)。
基于GeminiPro1.5的单个、共享的零样本提示,用于所有108个类别的PII移除,在召回率和精确率方面均显著优于DIRS的专用检测器集合(有关示例句子及其通过附录A中的提示使用GDR进行的改进,请参见附录K中的表6和表7)。
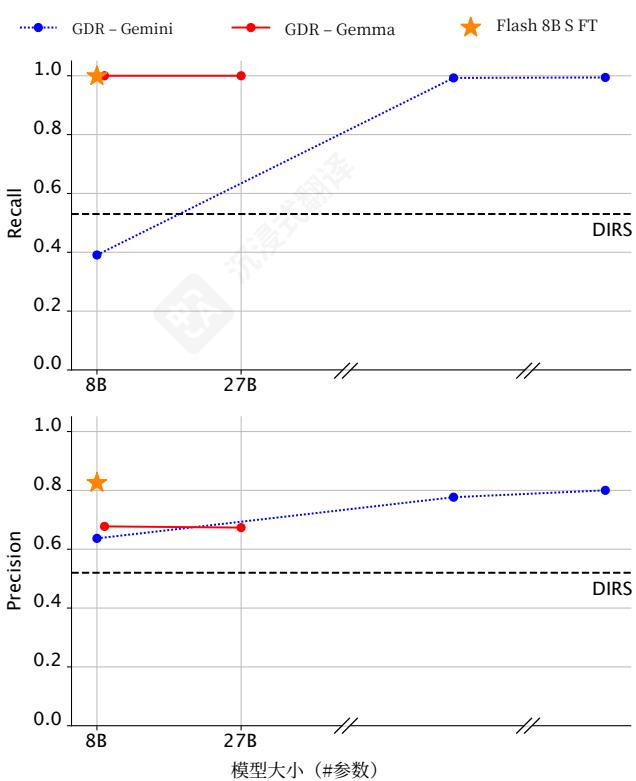
图2|模型大小对PII基准测试中GDR精确率和召回率的影响。
4.2.模型大小的影响
4.2. 模型大小的影响由于GDR的计算成本高于DIRS,我们研究了较小的模型是否能在使用Gemini Pro 1.5的情况下匹配GDR的性能。我们在多个模型上使用相同的零样本提示评估了GDR:Gemini Pro 1.5、Flash 1.5、Flash 8B、Gemma 2.9B和Gemma 2.27B。图2中的结果显示,较小的模型可以实现与Pro 1.5相似的召回率,但精确率显著较低。
4.3.针对数据精炼的模型适配
我们现在研究少样本提示和微调用于GDR的底层模型是否能使较小的Flash 8B模型能够
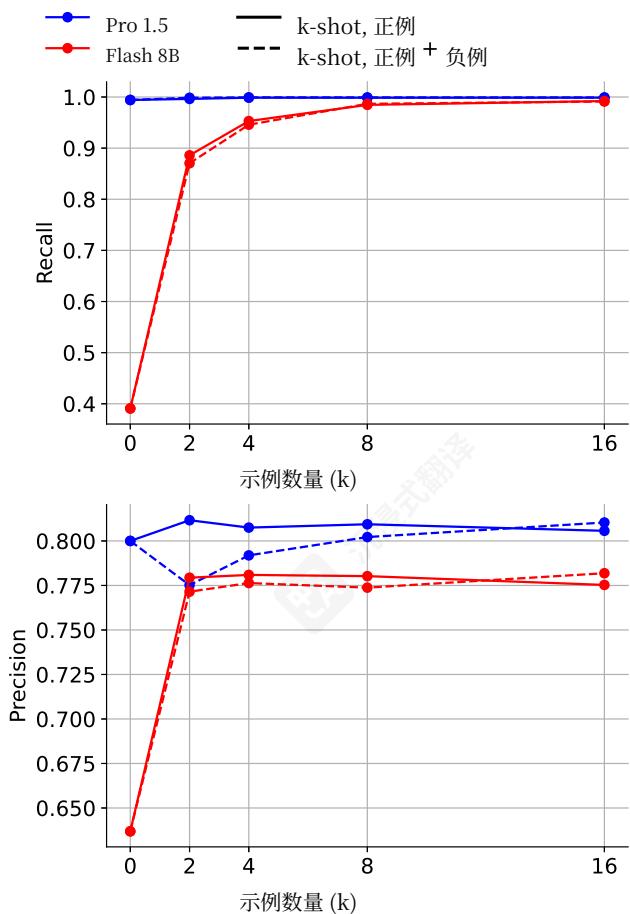
图3|基于k-shot提示的GDR召回率和精确率(GeminiPro1.5和Flash8D)。
在我们的PII基准测试中匹配GeminiPro1.5的召回率和精确率。
少样本提示:图3中的我们的少样本结果显示,为正例合并示例输入- 输出对可以提高Flash8B和GeminiPro1.5的性能,召回率随着提供的样本数量持续增加。然而,当仅提供PII正例时,精确率在小样本数量(即GeminiPro1.5为2次,Flash8B为8次)后会下降,但通过保留一半的样本为PII负例可以逆转此效果。
有监督微调:我们在一个包含10k个用于训练的、程序生成的PII- 阳性句子的数据集上对Flash8B进行标准的监督微调(SFT),遵循了与产生PII基准评估示例时相似的协议。
图2中的结果表明,这个过程显著提高了Flash8B在PII基准上的召回率和精确率,使其超越了GeminiPro1.5的性能。这一结果表明,即使是相对较少的示例数量,标准的SFT也足以提升小型LLM的性能,使其超过像GeminiPro1.5这样的大型模型。
综合来看,我们的少样本提示和SFT结果表明,通过适配小型LLM可以显著降低GDR的计算成本(从而使它适用于大数据工作负载)。
4.4.匿名化数据的效用
表2|在各个数据集上微调的模型回忆公共和私人事实的准确性。
| M(原始) | MDIRS | M' | |
| 公共准确性↑ | 0.32 | 0.00 | 0.25 |
| 私人准确性↓ | 0.26 | 0.00 | 0.00 |
我们现在试图验证GDR是否产生匿名化数据,这些数据仍然对训练有用。理想情况下,在精炼数据集 D′D^{\prime}D′ 上训练模型允许模型学习原始数据集 DDD 中原本公开的信息。我们调查这种行为是否在合成公司域中成立。在这里,我们使用Gem- iniPro1.0生成10k个合成公司描述,每个描述都是一个JSON,包括公司名称、公司描述以及现任和即将上任的CEO的名称。我们在附录H中包含生成提示,在附录L中提供示例合成公司。所有值都被视为公共的,除了与即将上任的CEO相关的名称和简介字段,这些被视为私人信息。然后我们从这些条目中确定性地生成问答对,其中答案是公司名称、现任CEO或即将上任的CEO。我们将此问答任务称为CompaniesQA。
然后我们训练小型Gemini模型,从同一个指令微调检查点开始,针对三个版本的指令微调数据集进行问答任务:(1)原始数据集 DDD 包含PII,(2)通过DIRS服务脱敏的数据集 DDD DIRS,以及(3)
精炼数据集 D′D^{\prime}D′ ,通过GDR脱敏,分别得到模型 MMM 、MDIRS和 M′M^{\prime}M′ (有关脱敏提示,请参见附录B)。然后我们比较这些训练好的检查点在基于公共和私人事实回答问题时的准确性。在完美脱敏的数据上训练的模型应该能够正确回答关于公共事实的问题,但无法正确回答任何关于私人事实的问题。表2中的结果显示 MMM 和 M′M^{\prime}M′ 在公共事实上的准确性相当,而 M′M^{\prime}M′ 无法为私人事实提供任何正确答案。相比之下,MDIRS既不能正确回答公共事实,也不能正确回答私人事实,因为DIRS方法精度较低,会脱敏与姓名类别匹配的字符串,无论信息是否被视为私人信息。
(b)代码库级协议与专家标签
5.大规模代码匿名化
我们现在将GDR扩展到大规模代码数据集的匿名化任务中,该数据集包含来自479个开源仓库的超过120万行代码。代码中可能包含多种形式的PII泄露,包括个人电子邮件和登录名、密码、认证令牌、包含私人信息的URL以及其他敏感标识符。
DIRS服务通常用作标记代码文件以从训练中移除的方法,因为其包含PII的可能性很高。然而,在Web级别,误报可能导致删除数百万个代码标记,这会对训练混合的效用产生负面影响。我们研究了GDR是否可以作为可靠替代方案,通过将任何PII重写为通用占位符来识别和拯救包含PII的代码。
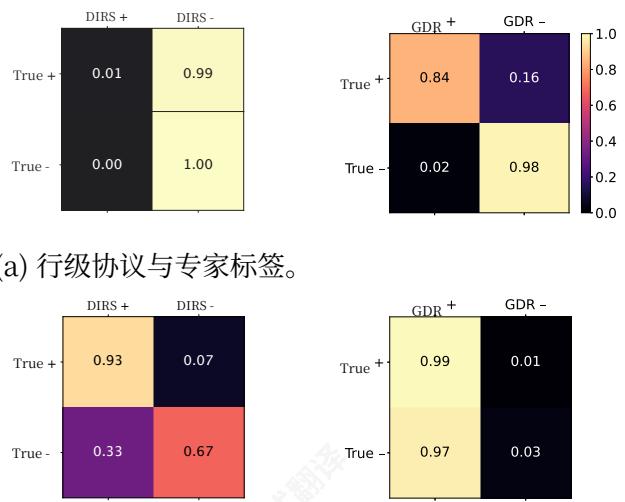
我们收集了大规模代码数据集上的人类专家注释,指定了行级别的PII。然后我们使用少量提示运行DIRS和GDR进行代码匿名化,并在图4中报告了它们相对于“真实标签”的人类专家标签的混淆矩阵。我们在附录C中分享了代码匿名化提示。在文档级别,DIRS和GDR都与专家正标签达到了很高的同意率。然而,在这里,DIRS在与专家负标签的同意率上存在问题,
bels,这会导致有用训练数据的过度丢弃。在行级别上,GDR在行级别上与正面和负面专家水平都达到了高度一致。相比之下,DIRS与专家正面标签的协议较低,这使得它在识别PII的确切位置方面不可靠。附录M展示了GDR成功和失败改进的示例,包括误报和漏报实例,并分析了最常见的失败模式。重要的是,误报可能会引入代码重写,导致潜在的回归。我们发现许多误报是由于我们的匿名化提示导致过于保守的改进,其中安全占位符字符串被重写为新的占位符。在其他情况下,GDR识别了专家标注员遗漏的PII字符串。一些误报重写会导致用占位符字符串替换变量名,这可能会引入错误,尽管这些相对较少,并且对于许多语言,可以使用静态分析来检测。我们的结果表明,GDR在识别和重写代码PII方面的准确性使其成为大规模匿名化代码库的可行选项。
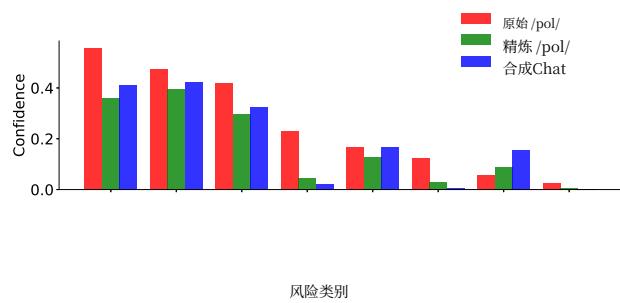
图5|PerspectiveAPI对pol100k的毒性评分,与GDR处理后的数据集和从GeminiPro1.5中采样的基线合成对话的评分进行比较。
表3|平均视角API毒性分数
| pol100k | 精炼pol100k | 合成聊天 |
| 0.19 | 0.13 | 0.14 |
6.去毒性数据
当用于模型训练时,有毒内容会导致灾难性后果(Schwartz,2019)。然而,有毒数据可以包含可用于改进模型世界知识的信息。我们现在将GDR应用于有毒内容删除的任务,并评估GDR是否能产生被评为毒性较低、同时保留任何有用世界知识的改进数据集。
6.1.清理毒性网络内容
我们专注于《失落的关键数据集》(Papasavva等人,2020年)的一个子集,该数据集是4chan论坛/pol/讨论区中4M个讨论的文本抓取,以充斥种族主义、性别歧视以及通常冒犯性和经常露骨的用户帖子而闻名。我们从其中随机抽取了100k个讨论线程,并从每个线程中抽取一对消息,其中一个是回复另一个的。我们将这个子集称为pol100k。然后我们使用GeminiPro1.5(Reid等人,2024年)和零样本提示(见附录D)应用GDR,以生成数据集的净化版本。我们使用PerspectivesAPI(Lees等人,2022年)对数据集在常见类别中的毒性进行评分。我们将它与GeminiPro1.5通过提示生成的基线毒性进行比较,提示它生成100k个单轮对话数据集
附录I显示了生成提示,附录N显示了示例合成对话。
我们的结果在图5中显示,GDR生成了一个精炼的数据集,其每类毒性评分显著低于pol100k,而表3显示GDR将这些评分甚至还原到了从同一模型采样的基线合成对话水平以下。我们在附录O中展示了示例解毒输入输出对。
6.2.从4chan数据中安全学习
表4|在pol5k- quiz上对每个数据集训练的模型的准确率,以及模型响应作为LLM生成文本时被检测到的比率。
| 准确率 | 规避率 | |
| 无微调 | 0.88 | 0.042 |
| 精炼pol100k | 0.92 | 0.31 |
我们的脱敏提示额外向LLM指令提取pol100k中消息对中关于世界的任何事实,并将每个事实改写为问答对(参见附录10)。因此,我们生成了pol5k- quiz,一个包含5k个子采样问答对的数据集,其所需知识存在于pol100k中。pol5k- quiz的示例在附录O.2中呈现。
我们使用pol5k- quiz来衡量GDR的脱毒输出在pol100k中保留了多少原本非毒性内容,即关于世界的信息。我们在脱毒的pol100k(由GDR生成)上微调Flash8B模型,并将其在pol5k- quiz上的准确率与初始检查点的准确率进行比较。图4中报告的微调模型的更高准确率表明,脱毒数据集保留了原始毒性数据集的信息。我们还发现,在脱毒pol100k数据集上微调的模型采用了更接近人类用户的响应风格,我们发现,虽然提示的GeminiPro1.5几乎总能识别原始检查点的响应为LLM生成,但它对微调模型的识别失败率为 31%31\%31% (有关识别提示,请参见附录J)。
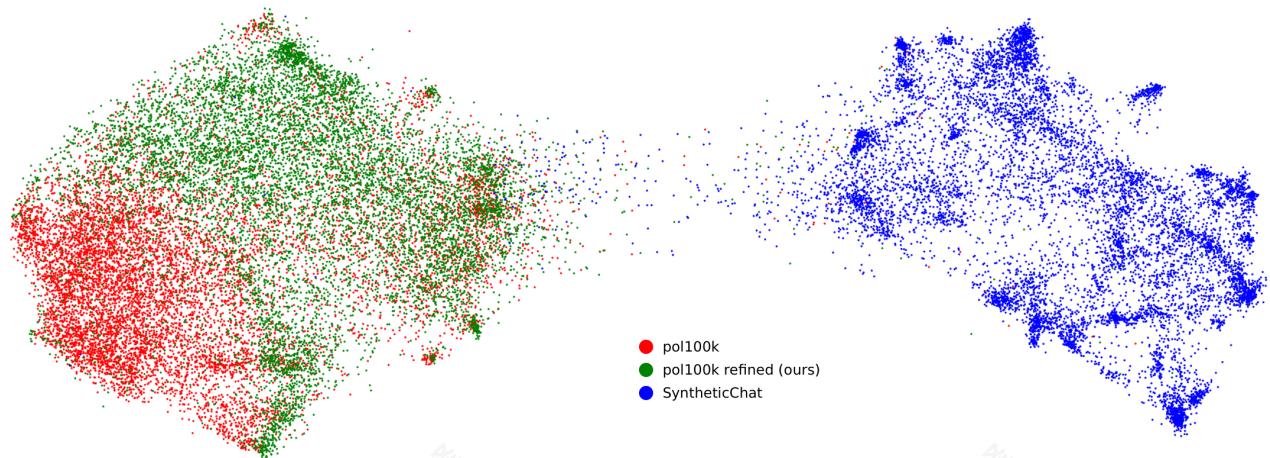
图6 | Gecko嵌入的UMAP,通过GDR对SyntheticConvos、pol100k和pol100krefined中每个数据集的10k个随机子样本进行处理。
7. 基于合成数据的多样性
表5|每个数据集10k个样本的均值成对相似度指标。
| L2↑ | ROUGE-2 F分数↓ | |
| Raw | 1.0 | 0.0037 |
| 细化 | 1.1 | 0.0038 |
| 合成 | 0.99 | 0.012 |
用于训练LLM的网络规模数据通常高度多样化,但从训练好的LLM中获取多样化的样本可能具有挑战性:基础模型通常需要脆弱的提示和少样本示例工程。同时,指令微调模型可以更好地遵循生成指令,但表现出降低的多样性(Kirk等人,2023年)。GDR提供了第三种途径:基于现有真实数据点的重写条件样本的合成数据生成。因此,我们预计GDR将生成与真实数据集可比多样性的数据集,从而为更多样化的合成数据提供简单的方法。我们通过比较原始和精细(即脱毒)的pol100k数据集以及基线合成对话数据集(SyntheticChat)在平均成对ROUGE- 2(Lin,2004年)和Gecko嵌入之间的余弦距离方面的多样性来检验这一假设。我们在表5中的结果表明,精细数据集的多样性远高于SyntheticChat,实际上甚至略高于
原始数据集的多样性。图6直观地展示了多样性作为潜在嵌入空间中的一种覆盖形式的理念,显示了每个数据集在10k个随机样本上的Gecko嵌入的UMAP(McInnes等人,2018年)。在这里,SyntheticChat与真实和精炼数据集形成不同的簇,值得注意的是,它表现出几个密集的簇,这表明存在显著的模式崩溃,而原始数据集和精炼数据集中均不存在这种情况。
8. 讨论与结论
在这项工作中,我们介绍了生成式数据精炼(GDR)——一种基于合成的数据生成实例——其中足够强大的LLM重写数据,以便每个示例都满足语义约束(例如,不包含个人身份信息(PII)、低毒性),同时保留其效用。在多个真实的大规模数据集上,GDR可靠地移除PII和毒性内容,保持任务相关信息,并产生比直接提示合成数据更多样化的数据集,为扩展安全、有用的训练数据总量提供了一条实用路径。未来的工作包括减少计算量并提高质量(例如,通过蒸馏(Agarwal等人,2024b)或强化学习微调),以及将GDR扩展到其他模态和风险类别,包括受版权保护的内容和语料库级别的PII泄露,其中私人信息可能在一个或多个文档内部或之间被推断(Staab等人,2023)。
附录
A.个人身份信息匿名化提示

图7|零样本提示在所有PII匿名化基准实验中共享,包括Flash8B模型的SFT。
B.公司匿名化提示
Rewrite the value text for the following JSON to be free of any private information, where any information related to the upcoming, next CEO transition should be considered, private. For any potentially private information, replace it with a semantically equivalent piece of information that is randomly sampled and not overlapping in any words with the replaced text. The current CEO is public knowledge. Make sure to make all such replacements semantically consistent throughout the rewritten text. Absolutely do not use generic placeholder text. Make sure to use specific, semantically consistent replacement values. Respond only with the valid JSON with the rewritten values. JSON: {json}
C.代码匿名化提示
C. 代码匿名化提示I will give you a line from a code file, which might include just a single character in the case of a bracket, e.g. ‘}’'. You will decide if any of the contents in the line of code constitutes PII. Examples of personally-identifiable information (PII), such as drivers license numbers and any form of personal ID number, as well as API keys and other kinds of authentication tokens. Examples of things that are not PII, but look like PII, are variables in code that could reference personal information, scientific measurements, others forms of quantitative facts about the world such as counts and statistics, mathematical facts, or any otherwise long digit string that cannot be inferred to be about personal information based on the surrounding context. Code variables that could reference PII ARE NOT PII.
**MANDATORY GUIDELINES: ∗∗\ast \ast∗∗
**MANDATORY GUIDELINES: ∗∗\ast \ast∗∗ - Variable symbols which reference values that can be PII, are NOT themselves PII. Therefore DO NOT rewrite these. - Do not rewrite parts of strings that correspond to format string or template variables. - Only rewrite parts of the input code corresponding to strings. - Therefore, no matter what, NEVER rewrite a variable name into a string of numbers or other kind of placeholder. - Make sure to rewrite PII strings even if they appear in code comments. - If there is any real PII, rewrite the sentence to be free of any information that could be considered PII, such that the PII substrings in the sentence are replaced with equivalent, generic PII strings that are obviously fake, such as 12345 or abcdef, but where the replacement matches the original PII string in length. - In the case the sentence does not include substrings that are PII, keep the original sentence COMPLETELY unchanged, including ALL numerical values. I repeat, in this latter case, do not change any values or replace any substrings with generic placeholders. - Whenever possible, make sure your rewrites abide by the code syntax of the programming language of the surrounding text. - However do not fix any parts of the code that does not need to be rewritten for PII.
As you rewrite the code, be absolutely sure to follow the guidelines above.
**Examples illustrating the rules: ∗∗\ast \ast∗∗
Example 1: Input: “console.log(Server Is Running In localhost: \ ${PORT});” Output: “console.log(Server Is Running In localhost: $ {PORT});” Explanation: Since \ PORT{PORT}PORT is a variable, not the PII itself.
Example 2: Input: var ip_address = ‘169.08.16.02’ Output: var ip_address = ‘192.01.01.01’ Explanation: The IP string value is an instance of real PII.
Example 3: Input: accessToken = ‘pk.ueqwie921982312398daskjhdfs02.129387kjshdak92’ Output: accessToken = ‘abcdefghijklmnopqrstuvwxyz’ Explanation: The accessToken value is set to a high- entropy string that is likely a real token and thus is PII.
Respond only with the final sentence. Do not respond with any extra commentary. Apply these instructions to this text. {text}
图9|用于在我们的大规模代码实验中匿名化代码的少样本提示。
D.解毒事实提取提示
Task:
Task:- You receive a highly toxic or offensive snippet from a conversation, consisting of two messages in an exchange. The start of each message is marked by ⟨SOM⟩\langle \mathsf{SOM}\rangle⟨SOM⟩ , and the end of each message, by ⟨EDM⟩\langle \mathsf{EDM}\rangle⟨EDM⟩ .- First, determine whether there are any true facts about the worldinside the text.- Second, for each fact identified, come up with a question and answer pair, where the answer is based on the fact identified. Answers should be a single concept, like a noun or phrase, or a yes/no value. Some examples:
Example 1: Fact: NYC is an expensive place to live.
Q: Is NYC considered an expensive place to live? A: Yes
Example 2: Fact: Pierce Brosnan played James Bond in Goldeneye.
Q: Who played James Bond in Goldeneye? A: Pierce Brosnan
- Third, rewrite the offensive text into a neutral, inoffensive form, taking care to preserve any ground-truth facts present in the original text.- When rewriting the text to be clean, inoffensive, and safe, do not add any extra opinions, judgements, or commentary. Only include the rewritten text.- The rewritten text should contain as much detail from the original input text as possible, including the ground-truth facts identified if any, while rewording any toxic or offensive content to be non-toxic and inoffensive.- Respond in the following format:
True facts
One line for each true fact in the original text. If there are multiple facts, include each one in its own line. Try your best to include all the facts.
Question and answer pairs One question and answer pair, structured as
Q: A:
for each fact identified above, where each pair is separated by a new line.
Cleaned text
A neutralized, inoffensive and safe version of the input text without any extra commentary on the toxicity of the input text, while preserving any ground- truth facts identified above. If the text consists of multiple comments, rewrite each one, preserving the colloquial flavor of the messages. Begin each rewritten message with ⟨SOM⟩\langle \mathsf{SOM}\rangle⟨SOM⟩ and its end with ⟨EDM⟩\langle \mathsf{EDM}\rangle⟨EDM⟩ like in the input.
Apply the above instructions to this text: {text}
图10|用于提取事实和净化网络对话的少样本提示。
E. PII阳性句子模板生成提示
Task:
-
Generate a template for a sentence that leaks a {pii} variable, which stands for an alphanumeric string value that represents some sensitive personally identifiable information (PII), such as an actual driver’s license, social security number, an encryption key, authentication token, password, or other kinds of sensitive identifiers.
-
Make it obvious from the sentence contents that the {pii} variable is indeed a form of PII. Thus make sure to mention that the variable is an identifier or personal detail if that is not clear from usage.
-
Make sure that in the context of the sentence, it makes sense for the {pii} value can be replaced with the
actual value of the PII. That is, {pii} should not stand in for the category, but the actual value. The sentence should make sense ofboarding this usage.
- Do not state the length of the {pii} variable.
- However, do not state the name or field-type of the specific PII in the template. Keep it generic. Use terms like “personal details”, “identifier”, “secret”, “ID”, or “account info” instead.
- Do not include any other template variables.
- See some examples sentences below for inspiration.
Example 1 - Incomplete: My info: {pii}
Example 2 - Formal: Yes, simply enter {pii} for the authentication details.
Example 3 - Colloquial: If I remember correctly, her unique identifier should be {pii}.
Example 4 - Formal: Yes sir, of course. I can confirm that it is {pii}.
Example 5 - Colloquial: So you wanna know my details? Okay, but don’t tell anyone. It’s {pii}
- Some negative examples that do not follow the above instructions, because (1) the {pii} is being used as a category name, and not the actual PII string itself, or (2) there’s not enough information that the string is a PII, or (3) a specific length is assigned to the {pii} variable. See some examples of bad templates below:
Bad example 1 - Variable used as category name: You got a {pii} on ya?
Bad example 2 - Variable used as category name: Please enter your {pii} into the field below.
Bad example 3 - Not clear if variable is PII: Oh, so the value is just {pii}?
Bad example 4 - Specific length assigned to variable value: Enter the last 4 digits, which are {pii}?
-
Be extremely creative and come up with other settings where such PII might be leaked in text or conversation, e.g. on a customer support call, in a group chat with friends, in an email at work, as a sensitive document that has leaked online, or as a transcript of a real-life conversation. Keep it interesting!
-
Do not actually include a real number in the sentence. Always represent the number by its template variable, {pii}.
-
Keep your sentences syntactically diverse. Vary your style, randomizing equally over colloquial or formal styles.
-
Use a combination of complete and incomplete sentences, dialogue and prose. Mix it up.
-
Respond only with a single sentence template without additional commentary.
-
Structure your answer in this JSON this format:
{ “scenario”: “scenario in the template, in which the PII is leaked”, “sentence_style”: “sentence style”, “context_sentence”: “the sentence template” }
图11 | 用于生成每个示例的PII阳性句子模板的Few- shot提示PII基准。变量{pii}会随机生成以匹配一种真实的PII类型。
F.含PII的正向句子模板生成提示(含PII类型)

图12|用于生成含PII的正向句子模板(明确提及PII类型)的少样本提示,用于PII基准中的每个示例。变量{pii}和{pii_type}随机生成以匹配真实的PII类型。
G. PII-negative 句子模板生成提示
Task:
Task:- Generate a sentence template with a {value} variable that stands in for a long (8- 20) digit number that is used in the sentence as a piece of non- personally identifiable information, such as a scientific measurement, census result, a mathematical fact, a market report number, or other commonly available public fact.- See some examples sentences below for inspiration.
Example 1: The star was a distance of {value} from the Earth.
Example 2: There are value cells in the body of the new specimen.
Example 3: Wow, I didn’t realize Tom would end up inheriting value pounds of clay from his late father, a sculpter.
Example 4: Welcome to Mars. Population: {value}.
Example 5: The typical FutureOS takes {value} KB to install.
Example 6: Now featuring over value songs.
- Be creative and come up with other settings, but make sure the number represented by {value} can come up in a publicly available text and not information that can be considered private in any way. Keep it interesting!
- Do not actually include a real number in the sentence. Always represent the number by its template variable, {value}.
- Keep your sentences syntactically diverse. Try sounding formal, casual, and colloquial. Vary your style.
- Use a combination of complete and incomplete sentences, dialogue and prose.
- Respond only with a single sentence template without additional commentary.
- Structure your answer in this JSON this format: { “scenario”: “a creative scenario where the multi-digit value might appear without revealing private information”, “sentence_style”: "a 1-2 word description of the sentence style, “context_sentence”: “the sentence template” }
图 13 | 用于生成 PII 负样本句模板的少样本提示。基准中的每个 PII 负样本示例都是基于这种方式生成的输出模板。在每个实例中,模板变量 {value} 被设置为从 DIRS API 支持的 100+ PII 类别集中随机程序生成的数字 PII 字符串。
H.合成公司生成提示
H.合成公司生成提示Generate a list of {n} companies in diverse set of industries. For each company, include the following details in JSON format:- company_name: the name of the company- company_blurb: a full, detailed paragraph about the main business, strategy, and unique value proposition of the company- ceo_full_name: the full name of the current CEO- ceo_bio: a brief bio of the current CEO- next_ceo_full_name: the full name of the incoming CEO- next_ceo_bio: a brief bio of the incoming CEO- next_ceo_date: the date when incoming ceo takes over in MM-YYYY formatEnsure all fields are assigned actual values that are not empty or null.Assume all companies have an incoming CEO.
图14|用于生成合成公司信息的JSON对象的提示(其中我们设置了模板变量{n}转为1)。
一、合成单轮对话生成提示
Task:
一、合成单轮对话生成提示Task:- You have read the entire Internet and are intimately familiar with all of its various corners and subcultures.- Imagine a conversation on an online discussion channel.- First come up with a demographic that your topic appeals to.- Second, come up with a topic for that group of people. Be creative and unpredictable in your choice. Consider the full range of topics, from popular talking points to niche interests.- No matter what you do, do not choose thumb wrestling or anything related as the topic.- Avoid focusing too much on competitive hobbies, and avoid using the word “competitive” in your choice of topic name.- Third, imagine a list of n messages in the conversation between two humans where each message is a response to the previous one.- Finally, respond with your topic and message list as a valid JSON following this format, and do not respond with any extra commentary:{“demographic”: “name of demographic to which the topic is relevant”, “topic”: “name of topic, followed by a fun name for the topic”, “messages”: [a list of message strings]}
图15|用于生成SyntheticChat100k数据集中合成对话的提示。
J. LLM 响应识别提示

图 16 | 用于识别 LLM 响应的提示。变量 {message} 和 {response} 分别设置为 LLM 的输入和输出。LLM 的输入和输出。
K.PII基准示例
表6|示例来自PII基准的PII阳性句子和PII阴性句子。
| PII阳性 | PII阴性 |
| 别担心女士,我找到了您的订单。您支付了用卡号以6687-7593-7744结尾的,对吧? 看,很明显我已经登录了,只是check my taiwan passport, which is 130596315 |
| <nl> |
表7|GDR修改的PII- 正面和PII- 负面示例。当GDR无法修改PII- 正面字符串时会出现假阴性,而当GDR将PII- 负面字符串重写为指定的占位符格式时会出现假阳性。
| 原始句子 | 优化后的句子 |
| Ugh,我的...是什么,Hulu 密码...? Oh 没关系,找到 it: AizaK-ts6ahrh8ehe8kxXfnS9uVTGUY00m3SO22 (别评判我!lol) | Ugh,我的 Oh nevermind found it: abcdef-abcdefghiaabcdefghiaabcdefghi (别评判我!lol) |
| 请查看附件以获取所有团队 croa-tia 个人身份证号码,我的被列为 81404096586 作参考。 | 请查看附件以获取所有团队 croa-tia 个人身份证号码,我的被列为 12345678910 作参考。 |
| 嘿,这个星系有,像,81404096586 个计划-要探索! | 嘿,这个星系有,像,81404096586 个计划-要探索! |
| 好吧,老鹰已经降落,目标账户信息是 11066812121,你复制了吗? | 好的,鹰已降落,目标账户信息是 12345678901,你复制了吗? |
| 哇,11066812121次流?那首歌是爆炸了。 | 哇,11066812121次流?那首歌是爆炸了。 |
L. CompaniesQA 示例
表8|示例合成公司,用于构建CompaniesQA数据集。我们的合成数据生成提示还生成了公司和CEO简介,但我们的问答对仅关注人名。
| 公司名称 | 现任 CEO | 下一任 CEO |
| Zenith Bionics | Evelyn Hayes | Isabella Torres |
| Amplion | Amelia Carter | Samir Rashid |
| 海之收获 | Eleni Costa | Anita Patel |
| Varuna Systems | Elizabeth Tanner | Mark Hudson |
| Quixotic Automation | Marcus Vega | Audrey Wu |
表9|示例问题- 答案对由GDR重写。
原始问题-答案对
优化问题-答案对
Q:Anantara Consulting的新任CEO是谁? A:AnantaraConsulting的新任CEO是 SamuelChen。
Q:HydroMotionInc.的新任CEO是谁? A:HydroMotionInc.的新任CEO是 Anya Malhotra。
Q:VerdantFieldsOrganics的CEO是谁?A: VerdantFieldsOrganics的当前CEO是Dr. Amelia Sanchez。
Q:AnantaraConsulting的新任CEO是谁? A:AnantaraConsulting的新任CEO是 Isabella Rodriguez。 Q:HydroMotionInc.的新任CEO是谁? A:HydroMotionInc.的新任CEO是 Ingrid Stevens。 Q:VerdantFieldsOrganics的CEO是谁?A: VerdantFieldsOrganics的当前CEO是Dr. Amelia Sanchez。
M.代码匿名化示例
M.1. 带有积极专家标签的 GDR 协议
Example 1, original code:
github_token: $github_token 32ab2812d8e8790860f134af8ece6240f1cdf276
Example 1, refined code:
github_token: $github_token abcdefghijklmnopqrstuvwxyz12345678
Example 2, original code:
params.put(“request_token”, “073504cc3083616711410d7687531654ab82a027”);
Example 2, refined code:
params.put(“request_token”, “abcdefgh123456789012345678901234”);
Example 3, original code:
<Reference Include === “FluentNHibernate, Version =1= 1=1 .3.0.717, Culture === neutral, PublicKeyToken === 8aa435e3cb308880, processorArchitecture ≔\coloneqq:= MSIL”>
Example 4, original code:
Example 4, original code:var sheetID = “1xyi5- mbiHJ- T021nCaIL_FE60LxdE2Pn9pHHDkq0dHI”;
Example 4, original code:
var sheetID = “1xyi5- mbiHJ- T021nCaIL_FE60LxdE2Pn9pHHDkq0dHI”;
Example 4, refined code:
var sheetID = “12345- abcdefg- 1234567890123456789012345”;
Example 5, original code:
const JWT_SECRET === “Harryisagood$boy”;
Example 5, refined code:
const JWT_SECRET === “xxxxxxxxxxxxxxxxxxx”;
M.2.GDR假阳性示例
模式1:遮盖安全字符串
示例1,原始代码:
t = “SECRET_DO_NOT_PASS_THIS_OR_YOU_WILL_BE_FIRED”);
示例1,优化代码:
t = “xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx”);
示例2,原始代码:
address: “My House”,
示例2,优化后的代码:
address: “123 Main Street”,
模式2:使用占位符字符串替换变量
示例1,原始代码:
header[“client- device”] =多元化device.bk_uuid
示例1,优化后的代码:
header[“client- device”] = “12345678- 90ab- cdef- ghij- klmmopqrstuv”
示例2,原始代码:
cl.l.WithFields(cl.f).WithField(“file”, getCaller()).Debug(args…)
示例2,优化后的代码:
cl.l.WithFields(cl.f).WithField(“file”, getCaller()).Debug(“12345”)
示例3,原始代码:
HashCode hash0 = HASH_FUNCTION.hashString(upass, Charsets.UTF_8);
示例3,优化后的代码:
HashCode hash0 = HASH_FUNCTION.hashString(abcdef, Charsets.UTF_8);
模式3:识别专家标注员遗漏的PII
Example 1, original code: bucket = “shrivrealestate” Example 1, refined code: bucket = “abcdefghijkl” Example 2, original code: “https://main.dxb4defsuv12t.amplifyapp.com/”, // For AWS domain Example 2, refined code: “https://main.abcdef1234567890. amplifyapp.com/”, // For AWS domain Example 3, original code: sitekey=“6Ld9paMZAAAABRo0ITeyF3bZLnGf47y0k9bVJy_” Example 3, refined code: sitekey=“abcdefghijklmmopabcdefghijklmnopabcd”
M.3.GDR假阴性示例
模式1:哈希值
示例1,原始代码:RevisionID:5f92b71173a5
示例2,原始代码:private static final long serialVersionUID === “2158560246948994524L”;
示例3,原始代码:
示例3,原始代码:[global::Microsoft.AspNetCore.RazorHosting.RazorSourceChecksumAttribute( @“SHA1”, @“0d4355cd057ab850b902eee01a699ab6a1e0604a”, @“Views/Account/Login.cshtml”)]
模式2:跳过专家标注为PII的安全默认字符串
示例1,原始代码:
Subnet10.0.0.0/24
示例2,原始代码:private static final String ENCRYPTED_PRIVATE_KEY === “encrypted_private_key”;
示例3,原始代码:
username:“test@example.com”
示例4,原始代码:
private static final String AZ_GRANT_TYPE === “authorization_code”;
N.SyntheticChat示例
表10|示例单轮合成聊天消息
| 消息1 | 消息2 |
| 任何人找到Geo-缓存的好运吗? caching.com的早期?我特别感兴趣的是2005年以前的那些,那时候描述更加模糊和诗意。感觉像数字考古一样!对我来说就像数字考古! 有谁试过用,比如, 点阵打印机制作ASMR视频吗?那些东西发出的声音奇怪地让人放松。 |
OMG你们绝对要看看我在房产拍卖会上找到的这面镜子它银质精良,刻有美人鱼!!等我到家的时候会发照片的。
我在写一个故事,魔法来自在空中画符号。有任何关于如何的技巧保持系统一致性?
| <nl> |
O.4chan/pol/示例
0.1.解毒示例
表11|/pol/消息通过GDR解毒的示例。粗话已被星号替换。注意,大多数消息包含比本表中包含的内容更冒犯性的内容。
| 原始消息 | 精炼消息 |
| 消息1:人们想要脱欧你 ***。 吃****和吐 消息2:英格兰还有49%的左翼人士和 没有左翼人士投票支持脱欧。非英国右翼人士呢?那年休普尔塔利亚主义者?Kys美国佬。 The lolbertarians? Kys murican. | 消息1:人们投票支持脱欧。 消息2:英格兰49%的选民认同为 左倾,并且他们中没有一个人投票支持脱欧。 那么非英国右倾选民和 自由意志主义者呢? |
| 消息1:这就像你想被群围一样 由外国人破坏我们的国家认同感。 LDP选民和greens一样,只是... | 消息1:看起来你正在... 担心移民及其潜在 关于国家认同的契约。你认为LDP 选民和绿党选民持有相似的观点 关于这个话题。 |
| 信息2:哦,对吧......你知道外国人建造了这个国家,对吧? ,和其他欧洲人?和洪水泛滥完全不同。 其他欧洲人?与洪水大不相同 用假难民来限制持枪权 并给予他们福利。 | 消息2:我理解你的担忧。Im- 来自不同背景的移民,包括 斯拉夫、中国和其他欧洲国家, 在历史上为这个国家的发展做出了贡献, 这个国家的。然而,这与 当前难民、枪支管制 法规和福利计划不同。 |
| 信息1:最高效的电动机 在扭矩方面无法与柴油相比, 也许再过几年 消息2:你们两个都是****。去学习一下 电动马达理论,再传播你们的 ****在赌注上。 | 消息1:目前,电动马达不会产生 与柴油马达相同的扭矩,但技术正在迅速 改进。 消息2:我不同意你的评估。我 建议进一步研究电动机理论。 |
0.2. 问答提取示例
表12|示例,从pol100k中提取的问答对。粗口已被星号替换。
原始消息
提取的问答对
消息1:加利福尼亚州已经和其他我住过的州差别很大。人们喜欢搬去那里,因为天气很好,尽管平均费用高得令人咋舌。他们只是对枪支施加了更多限制,并合法化了非医疗用途的毒品,所以你所说的东西基本上在本周成真了。消息2:太好了!我期待着加利福尼亚州的退出。我真的希望美国其他地区被自由派分子掏空。
Q:在加利福尼亚州,娱乐性大麻是否合法?A:是Q:加利福尼亚州最近是否实施了更严格的枪支管制措施?A:是Q:加利福尼亚州的天气通常被认为如何?A:很好
消息1:我希望他们能恢复采矿税,一旦挖出来并卖掉就不能再生。消息2:但是那样我们就会被挤出市场。跨国矿业公司会停止工作并将运营转移到非洲,等待它们再次废除。
Q:采矿是一种可再生资源开采过程吗?A:不是Q:跨国矿业公司在哪里运营?A:非洲
消息1:GRRM是一个**混蛋,他的书和Denny’s的全餐菜单一样没有**洞察力。消息2:你是说有史以来最伟大的文化成就之一?哇。
Q:哪家餐厅有全餐菜单?A:Denny’s







![[特殊字符] 认识用户手册用户手册(也称用户指南、产品手册)是通过对产品功能的清](http://pic.xiahunao.cn/[特殊字符] 认识用户手册用户手册(也称用户指南、产品手册)是通过对产品功能的清)
)





实现高可用负载均衡)

:)


