深入理解Transformer架构:从原理到实践
引言
Transformer架构自2017年由Google在论文《Attention Is All You Need》中提出以来,已经彻底改变了自然语言处理(NLP)领域,并逐渐扩展到计算机视觉、语音识别等多个领域。本文将深入解析Transformer的核心原理、关键组件以及现代变体,帮助读者全面理解这一革命性架构。
一、Transformer诞生的背景
在Transformer出现之前,自然语言处理主要依赖以下架构:
- RNN(循环神经网络):处理序列数据,但难以并行化且存在长程依赖问题
- LSTM/GRU:改进的RNN,缓解梯度消失问题,但仍无法完全解决长序列建模
- CNN(卷积神经网络):可以并行处理,但难以捕获全局依赖关系
Transformer的创新在于:
- 完全基于注意力机制,摒弃了传统的循环和卷积结构
- 实现了高效的并行计算
- 能够直接建模任意距离的依赖关系
二、Transformer核心架构
1. 整体架构概览
Transformer采用编码器-解码器结构(也可单独使用):
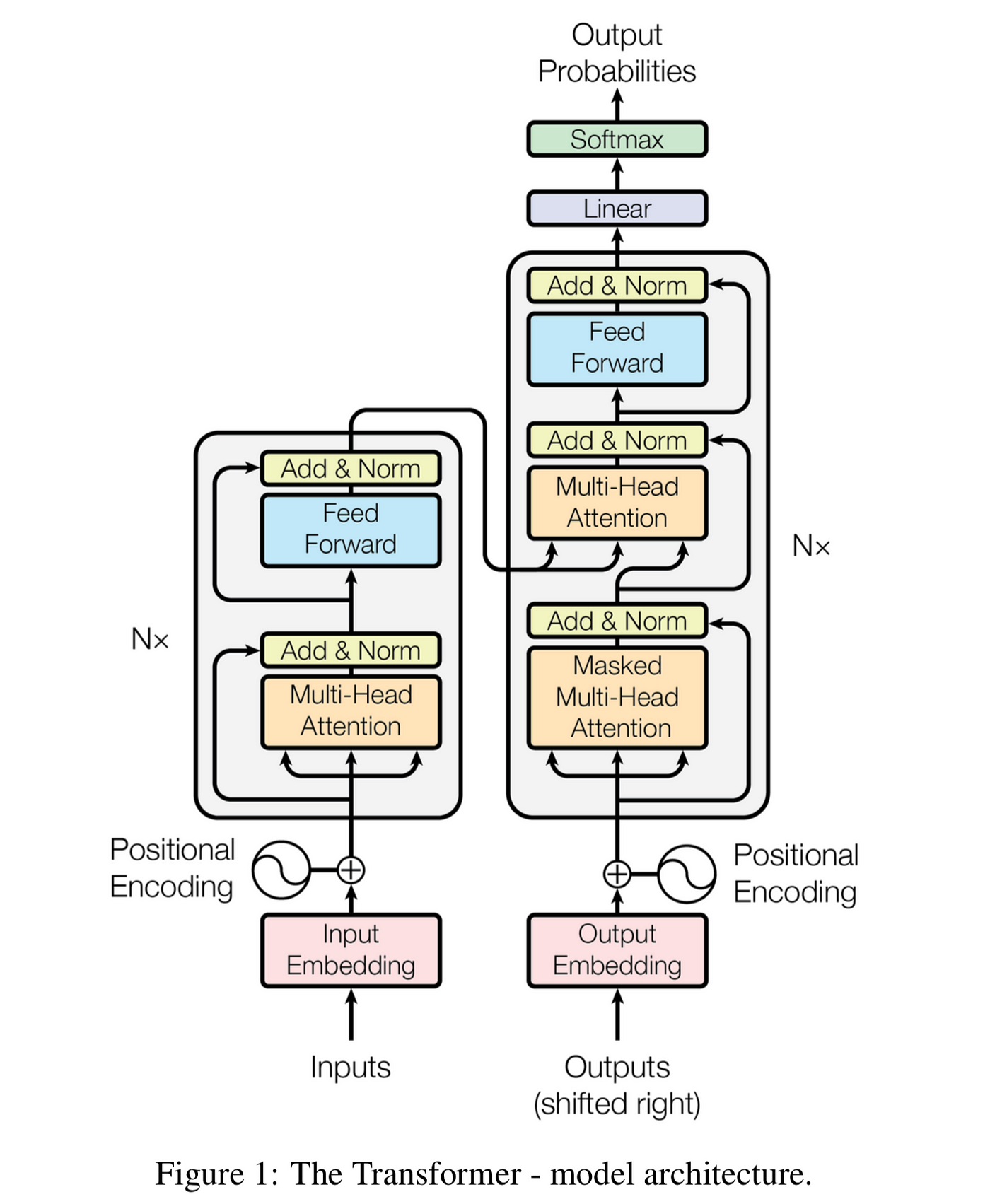
主要组件:
- 输入嵌入(Input Embedding)
- 位置编码(Positional Encoding)
- 多头注意力机制(Multi-Head Attention)
- 前馈网络(Feed Forward Network)
- 残差连接(Residual Connection)和层归一化(Layer Normalization)
2. 关键组件详解
2.1 自注意力机制(Self-Attention)
自注意力是Transformer的核心,计算过程可分为三步:
1. 计算Q、K、V矩阵:
Q = X * W_Q # 查询(Query)
K = X * W_K # 键(Key)
V = X * W_V # 值(Value)
2. 计算注意力分数:
scores = Q * K^T / sqrt(d_k) # d_k是key的维度
3. 应用softmax和加权求和:
attention = softmax(scores) * V
数学表达:
[ Attention(Q,K,V) = softmax(\frac{QK^T}{\sqrt{d_k}})V ]
2.2 多头注意力(Multi-Head Attention)
将自注意力机制并行执行多次,增强模型捕捉不同位置关系的能力:
MultiHead(Q,K,V) = Concat(head_1,...,head_h)W^O
where head_i = Attention(QW_i^Q, KW_i^K, VW_i^V)
优势:
- 允许模型共同关注来自不同位置的不同表示子空间的信息
- 提高模型的表达能力
2.3 位置编码(Positional Encoding)
由于Transformer没有循环或卷积结构,需要显式注入位置信息:
[ PE_{(pos,2i)} = sin(pos/10000^{2i/d_{model}}) ]
[ PE_{(pos,2i+1)} = cos(pos/10000^{2i/d_{model}}) ]
特点:
- 可以表示绝对和相对位置
- 可以扩展到比训练时更长的序列
2.4 前馈网络(Feed Forward Network)
由两个线性变换和一个ReLU激活组成:
[ FFN(x) = max(0, xW_1 + b_1)W_2 + b_2 ]
2.5 残差连接和层归一化
每个子层都有残差连接和层归一化:
[ LayerNorm(x + Sublayer(x)) ]
作用:
- 缓解梯度消失问题
- 加速模型训练
- 提高模型稳定性
三、Transformer工作流程
1. 编码器(Encoder)流程
- 输入序列经过输入嵌入层
- 加上位置编码
- 通过N个相同的编码器层(每层包含:
- 多头自注意力
- 前馈网络
- 残差连接和层归一化)
- 输出上下文相关的表示
2. 解码器(Decoder)流程
- 目标序列经过输出嵌入层
- 加上位置编码
- 通过N个相同的解码器层(每层包含:
- 带掩码的多头自注意力(防止看到未来信息)
- 多头编码器-解码器注意力
- 前馈网络
- 残差连接和层归一化)
- 通过线性层和softmax生成输出概率
四、Transformer的现代变体
1. BERT (Bidirectional Encoder Representations)
特点:
- 仅使用编码器
- 双向上下文建模
- 使用掩码语言模型(MLM)和下一句预测(NSP)预训练
2. GPT (Generative Pre-trained Transformer)
特点:
- 仅使用解码器
- 自回归生成
- 使用单向上下文建模
3. Vision Transformer (ViT)
特点:
- 将图像分割为patch序列
- 应用标准Transformer编码器
- 在计算机视觉任务中表现优异
4. Transformer-XH
改进:
- 相对位置编码
- 更高效处理长序列
5. Efficient Transformers
包括:
- Reformer (局部敏感哈希注意力)
- Linformer (低秩投影)
- Performer (基于核的注意力近似)
五、Transformer的优势与局限
优势:
- 强大的序列建模能力
- 高效的并行计算
- 可扩展性强(模型大小、数据量)
- 灵活的架构设计
局限:
- 计算复杂度高(O(n²)的注意力计算)
- 内存消耗大
- 对位置编码的依赖
- 小数据集上容易过拟合
六、实践建议
-
预训练模型选择:
- 文本分类:BERT
- 文本生成:GPT
- 跨模态任务:UNITER、VL-BERT
-
处理长序列:
- 使用稀疏注意力变体
- 分块处理
- 内存优化技术
-
训练技巧:
- 学习率预热
- 梯度裁剪
- 标签平滑
-
部署优化:
- 模型量化
- 知识蒸馏
- 模型剪枝
七、未来发展方向
- 更高效的注意力机制
- 多模态统一架构
- 更强的记忆和推理能力
- 与神经符号系统的结合
- 更绿色的AI(减少计算资源消耗)
结语
Transformer架构已经成为现代AI的基础构建块,理解其核心原理和变体对于从事AI研究和应用开发至关重要。随着技术的不断发展,Transformer家族仍在快速进化,持续推动着人工智能的边界。掌握这一架构不仅能帮助你在当前任务中获得更好表现,也为理解和适应未来的模型发展奠定了基础。
希望本文能帮助你建立起对Transformer架构的系统性理解。在实际应用中,建议从经典实现开始,逐步探索更高级的变体和优化技术。




![[网页五子棋][用户模块]客户端开发(登录功能和注册功能)](http://pic.xiahunao.cn/[网页五子棋][用户模块]客户端开发(登录功能和注册功能))

)



)
)







