性能是个宏大而驳杂话题,从代码,到网络,到实施,方方面面都会涉及到性能问题,网上对性能讲解的文章多如牛毛,从原理到方法再到工具都有详细的介绍,本文虽不能免俗,但期望能从另外一个角度来观察性能:站在硬件的角度看待软件性能。
要探讨高性能,首先要明确一下,什么是高性能? 是每秒过亿的QPS?还是每秒数G的数据传输?这些当然都是高性能的量化指标,但我想再更本质得明确一下高性能的含义,其核心诉求点在于:将硬件资源利用到核心的业务逻辑上,展开来讲:
- 资源利用率:程序能充分的利用硬件资源,到达得性能上限应该是硬件上限而非软件上限。
- 资源能效:完成相同的工作使用更少的资源,硬件资源使用在核心业务逻辑上。
那么如何实现高性能?
软件行业常有一个传言:过早的性能优化是万恶之源。但我想应该额外再补充一句:早期的性能考虑是高效之基。应该在编写第一行代码之前就想好怎么样的设计是高性能,而非等到功能完善之后再回头进行优化。心中时刻谨记高性能,在每个细节处都精益求精,才能真正的实现高性能。前期不管不顾,后期再性能优化面临几个问题:
- 有些程序结构不合理导致的性能问题变更起来牵连甚广,修改成本太高,不优化又不行
- 没有集中的性能问题,各处逻辑时间消耗不长也不短,最终性能不低也不高,却无处着手
这里分别从不同的硬件出发,来探讨如何压榨硬件资源,追求极致性能,本篇文章是第一篇,CPU篇。
CPU构造
现代CPU架构是一个高度复杂且多层次优化的系统,其设计核心目标是 最大化计算效率 和 资源利用率 。可以简单的概括其几个特性:
- 多核设计:现代CPU通常包含多个物理核心,每个核心可以独立的执行指令。单个物理核心通过虚拟化技术模拟多个逻辑核心,共享核心的运算单元和缓存,实现超线程。
- 指令流水线:将指令执行拆分为多个阶段(取指,解码。执行,访存,写回), 各个阶段可以并行工作,以提升吞吐量,数据依赖或分支预测失败会导致流水线停滞
- 多级缓存:L1缓存分指令缓存(L1i)和数据缓存(L1d),每个核心独享,延迟1-3周期。L2缓存:核心独享或共享,延迟约10周期。L3缓存:多核心共享,延迟约30-50周期。多层缓存逐级扩大。通过标记缓存行的状态,确保多核间数据一致性,避免脏读。
这是一个简单的多级缓存多核CPU架构图

有了这些简单的CPU知识,我们就可以进一步讨论如何充分得利用CPU的这些特性以实现高性能。
有效利用多核性能
大家知道现代操作系统调度CPU时间片的单位是线程,所以想充分利用多核特性,就要开启多个线程。
每个线程在Linux系统中都被封装为一个task,每个task包含了自己的堆栈,cpu执行寄存器的上下文(这是线程能够被抢占切换调度的关键),以及一些其他信息。从原理上讲,应该使用和CPU核心数量相当的线程数量,但由于应用程序和CPU之间并非直接的使用关系,中间还有一层调度层,即操作系统。操作系统内核也会有自己的执行进程。所以早期Windows核心编程书中推荐使用cpu核心数*2的线程配置。但不论怎么设置线程数量,都不宜过多或者过少。操作系统需要保证公平且高效的调度让所有线程都有机会在CPU上得到执行,但线程有CPU密集的计算逻辑,也有和外部设备进行数据通信的IO逻辑,如何给不同的线程分配CPU呢?这又是一套很复杂的算法,简单来归纳:CPU密集的线程被调度的次数少,但是执行的时间片长,IO密集型的线程被调度的次数多,但是执行的时间片短。开的线程越多,那么操作系统执行算法需要调度的对象就越多。开的线程太少,则无法有效利用多核特性,自不待言。
操作系统是如何测量线程到底是IO密集还是CPU密集的呢?答案是:操作系统并不能明确的知道。因为IO密集和CPU密集并不是绝对属性,CPU计算的过程中可能会发生IO, 而IO的过程中也会有CPU计算,操作系统只能根据一些操作统计来推断线程行为。这导致一个问题,当一个线程阻塞在一个IO操作上,比如阻塞的向一个socket发送数据,我们知道这个调用send的过程可能很短,只是把用户态的内存拷贝进内核态的缓存中,也可能很长,需要等待内核协议栈将内核缓存的数据发送,留出足够的空闲以容纳新发送的数据。站在应用程序的角度看,就是send发送阻塞了线程的执行。这个阻塞的过程,操作系统是知道的,其会将线程标记为block状态之后让出CPU,问题是操作系统什么时候知道了send已经完成,需要将这个线程切回到CPU上继续执行呢?这需要硬件触发中断来再次触发操作系统的调度逻辑,如果只是简单的调用阻塞的IO接口,那么什么时候切换回CPU执行只能依赖于操作系统的调度策略,时间可长可断,但并不会是一个高效的时机。如果要充分提升CPU的使用率,就要避免使用阻塞式的系统调用,现代操作系统一般都提供了异步响应式的编程接口,将在到另外一篇文章中讨论。
总的来说,开多少个线程合适并不是一个简单的问题,要结合自己的硬件水平,执行逻辑等多方面因素,因地制宜的综合决策。
有效利用缓存
CPU和主存之间每次交换数据需要近百的CPU时间,如果每次数据交互都需要直接访问主存,CPU大多数时间都将消耗在数据等待上。CPU提供的三层缓存机制:第一级最接近CPU核心,访问速度最快,之后每级速度递减,一二级缓存通常单个核心独享,三级缓存多个核心共享,其内部也有自己的数据一致性算法。感兴趣的读者可以自行搜索,本文不再讨论。
每个线程在CPU看来,无非是一堆数据以及对应的计算指令,想要提升缓存的利用率,其实和常规的编程过程是一样的:提升缓存命中率,降低缓存miss。不同的点在于平常的内存操作是显式的,我们明确的知道哪里访问了缓存,哪里发生了miss,CPU的缓存命中与否,并没有那么直观。CPU每次进行缓存交换的单位,称为cache line,每个cache line通常为64字节。从编程的角度出发,可以通过以下措施提升缓存的命中率:
- 避免频繁的线程切换。每个线程都有自己的运行上下文,对CPU来讲就是不同的数据和指令,所以每次在CPU上切换线程,之前缓存的其他线程数据大概率会失效,进而导致需要重新从低访问速度的缓存或者内存中加载数据。现代操作系统都提供了API来实现线程和CPU核心的绑定,支持一个线程一直都被调度到一个CPU核心上,从而提升一二级缓存的命中率。
- 尽量访问内存相邻的数据,以提高cache line的数据使用率,减少缓存数据交换次数。比如我们有个二维数据:
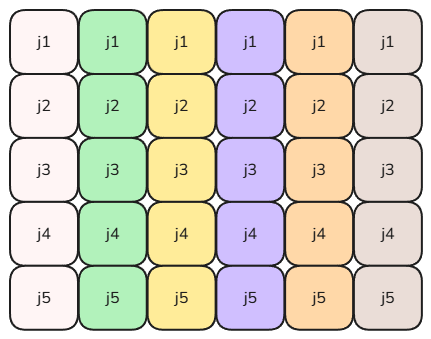
纵向的不同颜色的列表示内存连续的第二维数组,很常见的数据结构。遍历这个二维数组,当横向遍历时,每次访问的都是不连续的内存,当 j 的序列超过一个cache line的时候,意味着每次访问都需要加载一个新的cache line才能读取到新的数据。当纵向的遍历时,每次访问的内存位置是连续的,所以一个cache line上大部分数据都会被利用到。虽然在代码层面来看无论怎么遍历结果都是相同的,但对CPU来讲,纵向的遍历能显著的减少cache line的交换次数,可以大幅提升CPU的吞吐量。
- 避免局部数据的多线程访问。我们都知道多个线程读写相同的变量会导致内存竞争问题,需要进行加锁。那我们在不同线程访问相邻的变量时会发生什么?
struct Data { int32_t param_a_;int32_t param_b_;
};当两个线程分别读写这个结构体的param_a_,param_b_,由于cache line是64字节,而CPU更新缓存的单位只有cache line。所以当A线程访问param_a_时,可能会将param_b_也一并加载,线程B访问param_b_也是相同的道理,当CPU的某个核心修改了cache line的数据,而这个cache line又被其他核心访问,为了防止数据不一致的情况,CPU会将这个cache line失效,以加载最新的数据,这会导致大量的cache line交换。为了避免这种情况的发生,我们需要用一些编程技巧来进行CPU的数据访问隔离。可以使用内存对齐,将不同线程访问的变量按照64字节对齐。或者使用thread local store来降低线程间的数据竞争,当然这会比中心式的数据维护要复杂很多。
提升分支预测准确度
结构化编程最常见的编程结构便是分支控制,我们的代码中充斥的大量的if else,平时编程的时候多一个少一个,怎么排布顺序对程序功能来说无伤大雅。但站在CPU的角度上看,由于分支预测失效会导致数十乃至数百CPU时钟的停顿,提升分支预测的准确性就可以有效的提升CPU的指令执行效率。
好在我们依然可以使用一些简单的编程策略来提升分支准确度:
- 减少代码的判断分支,合并条件判断。这是最直观的降低分支预测的失败的方法。
- 优化分支模式,使分支判断具有局部性。比如遍历一个整数数组,偶数执行A操作,奇数执行B操作,如果数据按照先偶数再奇数的方式排列,就可以有效提升分支预测准确度
- 优先处理高频路径,将最可能执行的分支判断放到最上方
- 避免使用复杂的分支判断,将大量的if else通过查找表实现。
性能优化是个博大精深的问题,本文从CPU的角度出发,介绍了一些性能优化的知识,但知距离全面详实还差的很远。本篇也作为性能问题的一个开篇,之后计划再介绍一下IO的性能优化手段。
Finally, 期望本文能对大家有所启发,你还知道什么特别的CPU利用率的优化知识,也欢迎交流讨论。
![[SC]SystemC在CPU/GPU验证中的应用(三)](http://pic.xiahunao.cn/[SC]SystemC在CPU/GPU验证中的应用(三))

-14)
Unity 物理系统之范围检测)










 变换图像与形态学操作)




