
1. 引言
传统企业通常将常见问题(FAQ)发布在网站上,方便客户自助查找信息。然而,随着生成式 AI 技术的迅速发展与商业渗透,这些企业正积极探索构建智能问答系统的新途径。这类系统不仅能显著提升客户体验,还能有效降低人工支持成本,实现客户服务的智能化转型。
本文将详细分享如何利用 Amazon Q Developer CLI(以下简称 Q CLI) 和 Amazon Bedrock Knowledge Bases(以下简称 Bedrock KB) 快速构建端到端的智能问答系统。我们将从网页爬取 FAQ 开始,到构建高效知识库,实现全流程自动化,帮助企业轻松迈入 AI 客户服务新时代。
📢限时插播:Amazon Q Developer 来帮你做应用啦!
🌟10分钟帮你构建智能番茄钟应用,1小时搞定新功能拓展、测试优化、文档注程和部署
⏩快快点击进入《Agentic Al 帮你做应用 -- 从0到1打造自己的智能番茄钟》实验
免费体验企业级 AI 开发工具的真实效果吧
构建无限,探索启程!
2. 智能问答系统构建
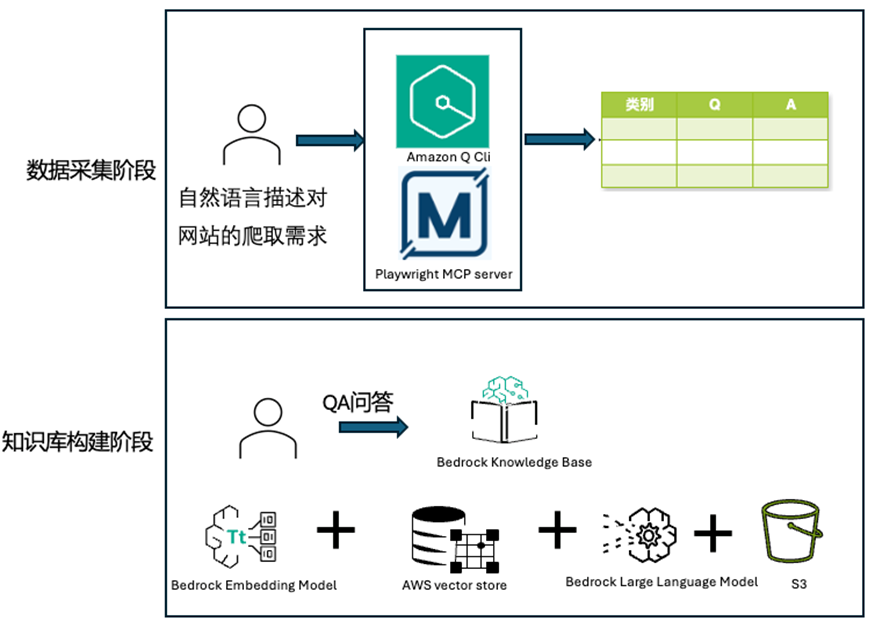
我们的解决方案分为两个核心阶段:
1、数据采集阶段 – 利用 Q CLI 和 Playwright MCP Server 自动从网页爬取 Q&A 问答对,整理到 Excel 表中。
该阶段主要解决的问题是从网页中快速、自动提取结构化信息,特别是对于常见问题解答(FAQ)页面,能够自动化提取问答对并将其转化为结构化数据,可以为知识库建设、客户支持系统和智能问答机器人提供信息资源。本文将分享如何利用 Q CLI 和 Playwright MCP Server 快速构建一个自动化工作流,实现网页爬取、内容识别和问答对提取。
2、知识库构建阶段 – 将结构化数据导入 Bedrock KB,构建 Q&A 系统。
该阶段主要解决的核心问题是:如何将结构化的 Q&A 对 Excel 文件转化为智能可查询的知识库,并确保系统能准确理解和匹配用户问题。这一挑战尤为关键,因为网站 FAQ 中的问题通常按类别组织,在原始上下文中意义清晰,但一旦脱离分类结构,同样的问题可能变得模糊不清。例如,”如何修改订单?”这个问题在不同业务场景下可能有完全不同的答案。我们需要确保智能问答系统不仅存储问答对,还能根据上下文进行问题分类,以实现精准的语义匹配和回答检索。
架构图如下:
3. 基于 Q CLI + Playwright MCP Server 的自动化数据采集
Amazon Q CLI 是亚马逊推出的一种命令行工具,作为 Amazon Q Developer 的一部分,它允许开发者直接在命令行界面与 Amazon Q 的人工智能能力进行交互。为了延伸 Q CLI 调用外部工具的能力,Q CLI 从 1.9.0 版本开始支持模型上下文协议(Model Context Protocol MCP),借助外部 MCP Server,可以极大地扩充 Q CLI 的能力。
Playwright 是一款开源浏览器自动化框架,提供了跨浏览器的自动化测试和网页交互能力。而 Playwright MCP Server 则是基于 MCP 协议为大语言模型(LLM)提供了使用 Playwright 进行浏览器自动化的能力。具有以下核心功能:
-
网页导航与交互:允许 AI 模型打开网页、点击按钮、填写表单,等等。
-
屏幕截图和网站文字获取:捕获当前网页的截图,帮助 AI 分析页面内容。
-
JavaScript 执行:在浏览器环境中运行 JavaScript 代码,实现复杂交互,等等。
当 Q CLI 集成 Playwright MCP Server 后,我们在 Q CLI 中通过自然语言交互就能够实现网页的打开、点击,网页文字内容的读取存储和解析,无需手工操作处理。
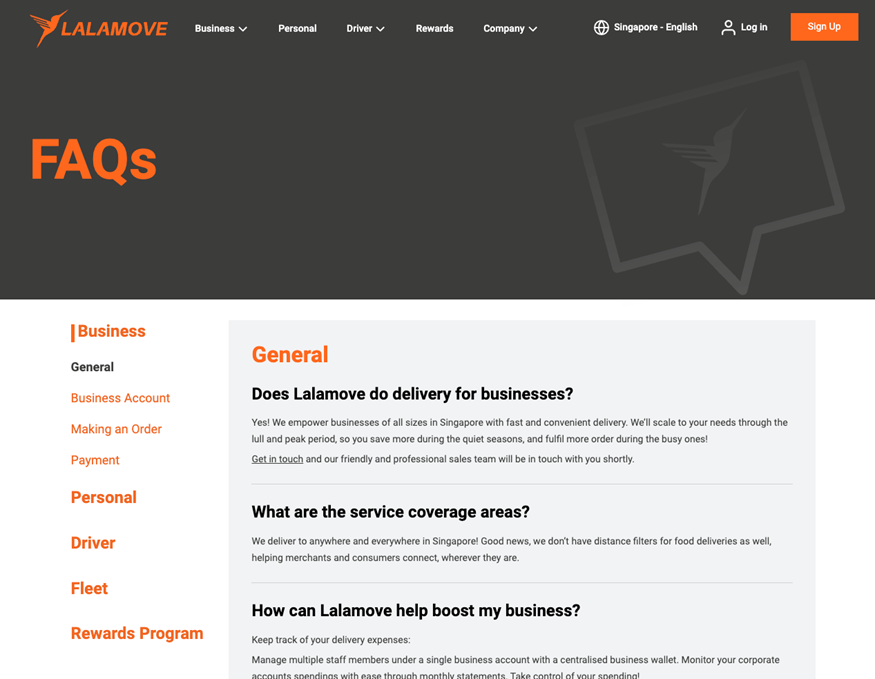
比如如下的网页,Q&A 已经使用问答形式将客户关心的问题和答案做了分类整理,但如果我们想导入知识库,就需要把网站的内容导出到 Excel 文件,便于后续处理。
下面我们就向大家一步步展示 Q CLI 集成 Playwright MCP Server 后的强大能力。
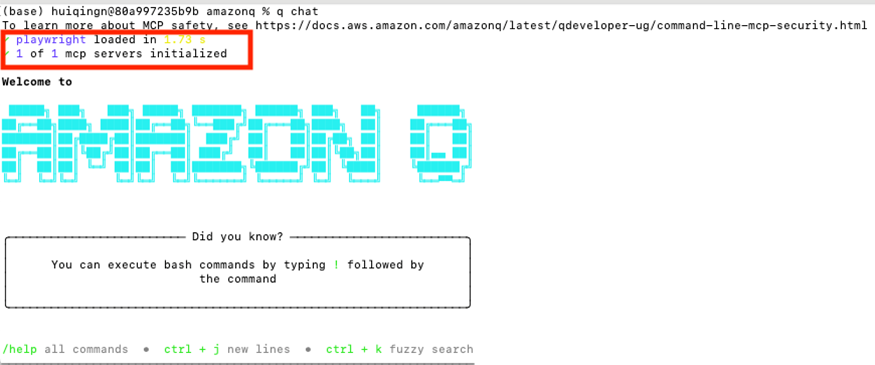
3.1 配置 Q CLI 集成 Playwright MCP Server
在 Q CLI 中集成 MCP Server 非常简单,在 Q Developer 的安装目录,通常是~/.aws/amazonq/mcp.json 文件中配置 playwright MCP Server,如下:
参考:https://github.com/executeautomation/mcp-playwright
{"mcpServers": {"playwright": {"command": "npx","args": ["-y", "@executeautomation/playwright-mcp-server"]}}
}启动 Q Chat 可以看到配置的 Playwright MCP server 已经正常启动了。
3.2 通过自然语言交互实现爬网
在 Q Chat 中输入:
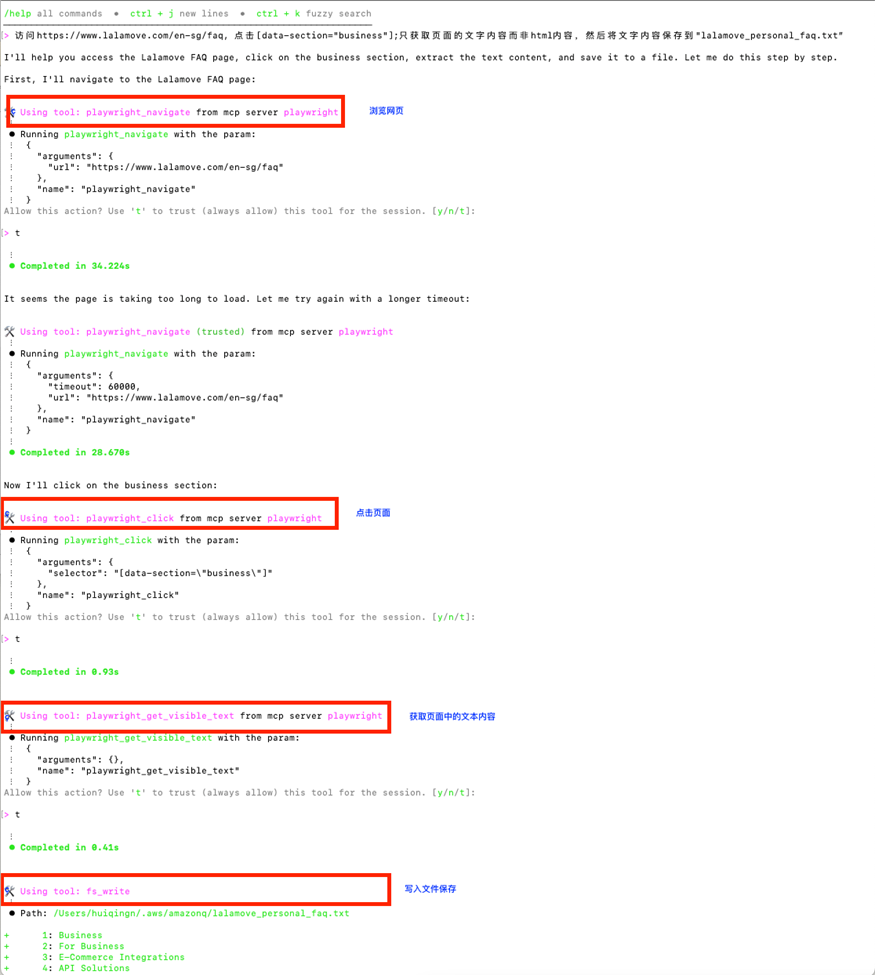
访问 Courier & Delivery Services FAQs | Lalamove Singapore,点击[data-section=”business”];只获取页面的文字内容而非 html 内容,然后将文字内容保存到”lalamove_personal_faq.txt”
就可以看到 Amazon Q 已经开始理解我们的需求,并调用 Playwright MCP Server 提供的合适的工具开始爬网了。它分别使用:
-
playwright_navigate 工具打开指定的网站
-
playwright_click 点击上面网页的“Business”链接
-
playwright_get_visible_text 工具获得网站上的文字内容
-
fs_write 将文字内容保存在本地文件
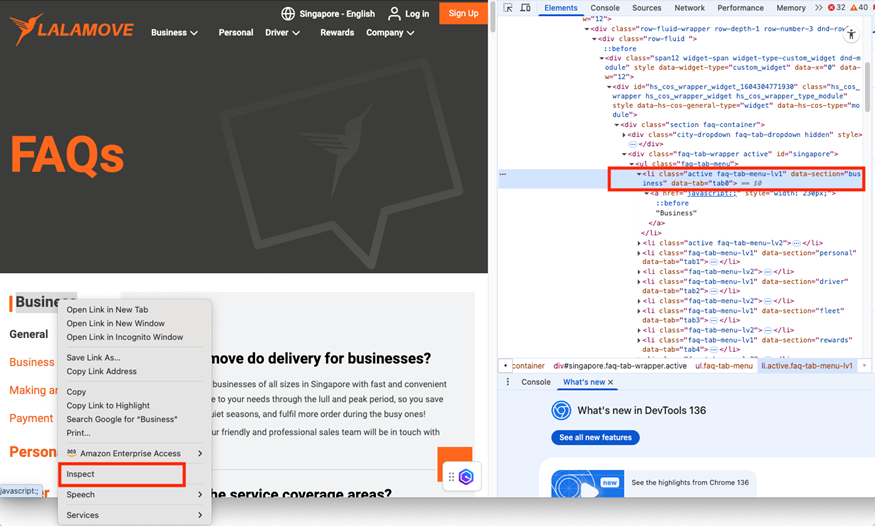
这里有个有趣的点值得一提:你会发现我们的提示词里面特别添加了点击[data-section=”business”]
访问 Courier & Delivery Services FAQs | Lalamove Singapore,点击[data-section=”business”];只获取页面的文字内容而非 html 内容,然后将文字内容保存到”lalamove_personal_faq.txt”
这样做的原因是,网站中有多个“business”的字样,如果不做特别说明,LLM 通常会根据开发习惯猜测点击时使用的 selector,将该参数传递给 Playwright 工具,当与实际情况不符时,Playwright 往往难以点击到正确的链接。我们通过如下的方法获得准确的 selector 放入指令中,LLM 就可以生成准确的参数,实现精准的点击。
3.3 通过自然语言交互实现文本到 Excel 的转换
我们继续与 Q CLI 进行交互:
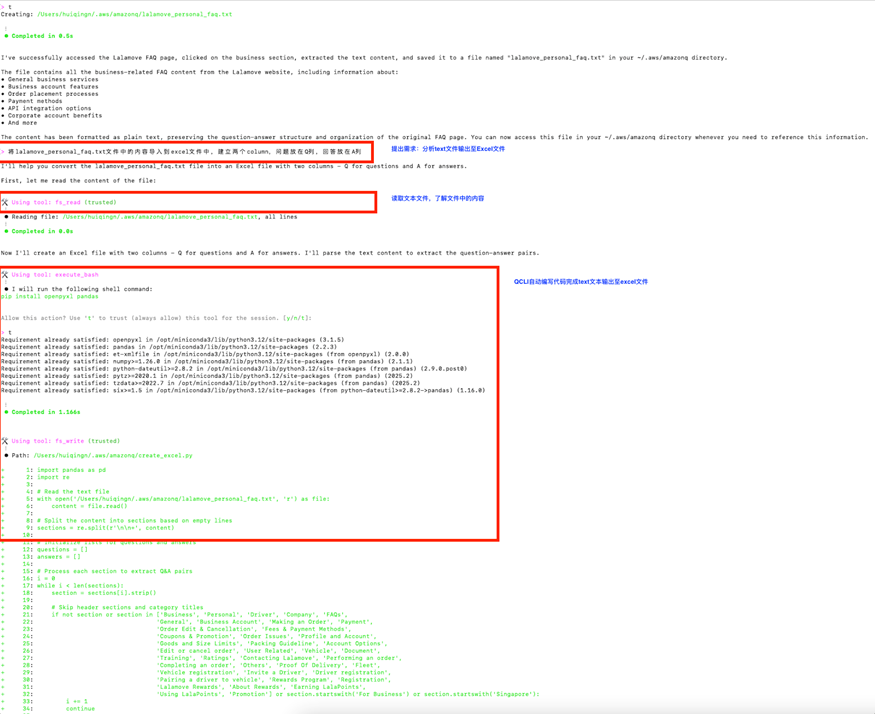
Q CLI 经过上面的一系列的自动操作几分钟之内就将网页的 Q&A 对整理到 Excel 文件中:

4. 基于 Amazon Bedrock Knowledge Bases 的知识库构建
该项目中我们主要遇到两个挑战:
-
网站中的 FAQ 是按类别组织的,同样的问题在不同上下文回答可能完全不同。
为了解决这个问题,我们利用 Bedrock KB 的元数据过滤功能(Amazon Bedrock Knowledge Bases now supports metadata filtering to improve retrieval accuracy | AWS Machine Learning Blog),允许您根据文档的特定属性细化搜索结果,提高检索准确性和响应的相关性。
-
客户是通过多轮会话进行提问的,每轮会话的意图(或是对应的分类)都有可能变化。
为了解决这个问题,我们采用结合历史会话和当前问题进行问题分类,结合 Bedrock KB 的元数据过滤能力进行知识库的问题搜索。
4.1 基于元数据的 Q&A 问题导入
为了实现基于元数据的 Q&A 问题导入,我们对前面整理出来的 Excel 文件进行拆解,每个 Q&A 问题对都对应一个 Excel 文件和一个元数据 metadata.json 文件,如下:
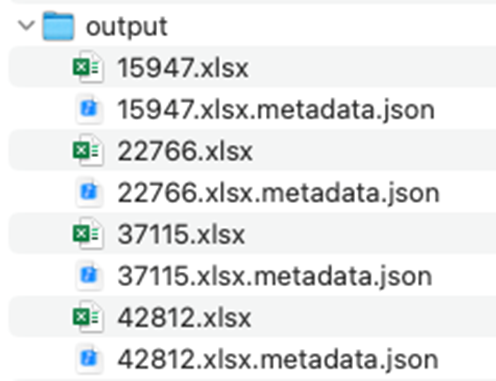
每个 Excel 文件内容:

对应的 metadata.json 文件内容:
{"metadataAttributes": {"Category": "Business","Sub-Category": "General"}
}将这些文件作为数据统一放在 S3 中作为数据源导入到 Bedrock KB 中。
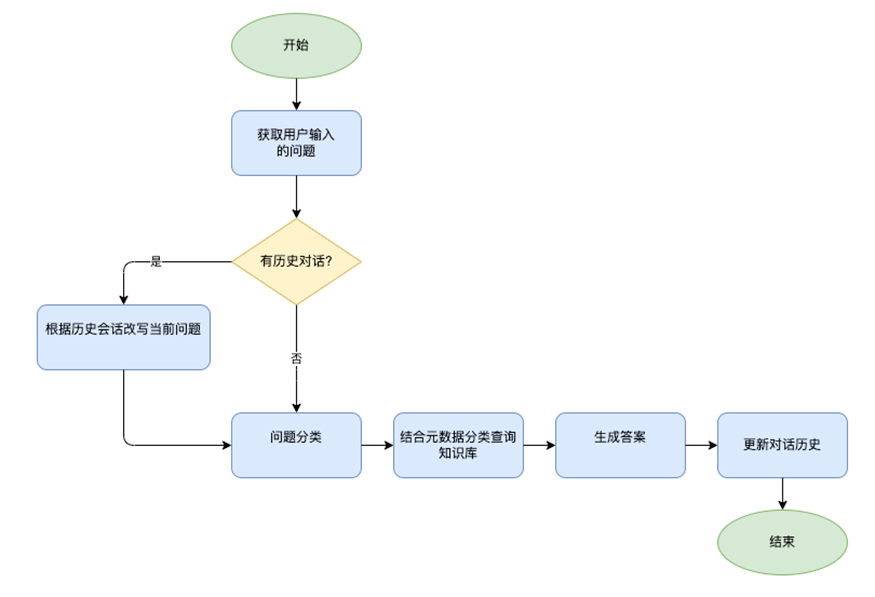
4.2 基于多轮会话的意图识别和 Bedrock KB 查询
结合历史会话做意图分类的逻辑如下:
基于 Bedrock KB 做信息检索的代码片段:
try:# 设置Bedrock KB配置最多返回3条信息retrieval_config = {'vectorSearchConfiguration': {'numberOfResults': 3}}# 根据问题做的分类来添加过查询bedrock KB的过滤条件if category != "others":# 添加分类过滤条件retrieval_config['vectorSearchConfiguration']['filter'] = {'equals': {'key': 'Category','value': category}}logger.info(f"使用分类过滤: {category}")else:logger.info("未使用分类过滤,将搜索所有分类")# 调用知识库检索APIresponse = bedrock_agent_runtime.retrieve(retrievalQuery={'text': query},knowledgeBaseId=KNOWLEDGE_BASE_ID,retrievalConfiguration=retrieval_config)# 打印检索结果logger.info(json.dumps(response['retrievalResults'], ensure_ascii=False, indent=2))return response['retrievalResults']except Exception as e:logger.error(f"查询知识库时出错: {str(e)}")return []基于 Bedrock KB 的回取内容做答案生成的代码片段:
try:# 结合客户需求,当知识库中没有相关信息时直接返回,不需要LLM做总结。if not reference_items: return "抱歉,知识库中没有找到相关信息。"# 构建提示词system_prompt, user_message = build_prompts(query, reference_items)# 设置对话消息system_prompts = [{"text": system_prompt}]messages = [{"role": "user","content": [{"text": user_message}]}]# 设置推理参数inference_config = {"temperature": 0}additional_model_fields = {"top_k": 50}# 调用模型APIresponse = bedrock_runtime.converse(modelId=MODEL,messages=messages,system=system_prompts,inferenceConfig=inference_config,additionalModelRequestFields=additional_model_fields)# 获取模型响应output_message = response['output']['message']response_text = output_message['content'][0]['text']return response_textexcept Exception as e:logger.error(f"生成答案时出错: {str(e)}")return f"处理您的问题时出错: {str(e)}"5. 总结
Amazon Q CLI 可以与 MCP Server 实现方便的集成。本项目通过 Q CLI 与 Playwright MCP 集成,为网页内容提取和问答对识别提供了一种高效、智能的解决方案。通过简单的自然语言指令,我们就可以快速实现从网页爬取到结构化数据生成的全流程自动化。这不仅大大提高了开发效率,也为构建智能知识库和问答系统提供了坚实基础。
同时,结合 Amazon Bedrock Knowledge Bases 的元数据过滤功能,我们可以首先基于历史会话对问题进行分类,在准确的类别中再完成知识库的搜索和答案生成,进一步提升 Q&A 回复的准确率。
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您了解行业前沿技术和发展海外业务选择推介该服务。
本篇作者
本期最新实验为《Agentic AI 帮你做应用 —— 从0到1打造自己的智能番茄钟》
✨ 自然语言玩转命令行,10分钟帮你构建应用,1小时搞定新功能拓展、测试优化、文档注释和部署
💪 免费体验企业级 AI 开发工具,质量+安全全掌控
⏩️[点击进入实验] 即刻开启 AI 开发之旅构建无限, 探索启程!





——进程(控制篇——下))



)


)


算法深度解析)



