一、连结(Join)
1.1 概念
联结(Join)操作用于将多个表中的列组合在一起,形成一个新的查询结果集。它允许我们从多个表中提取数据,并基于表之间的关系进行查询。
1.2 类型
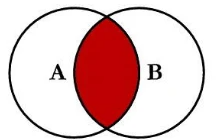
1. 内联结(INNER JOIN)
-
定义:内联结返回两个表中满足连接条件的记录。
-
示例
SELECT student.name, score.grade FROM student INNER JOIN score ON student.id = score.student_id WHERE score.grade > 80;
2. 左联结(LEFT JOIN)

-
定义:左联结返回左表中的所有记录,以及右表中满足连接条件的记录。如果右表中没有匹配的记录,则结果中右表的字段将为 NULL。
-
示例
SELECT student.name, score.grade FROM student LEFT JOIN score ON student.id = score.student_id;
3. 右联结(RIGHT JOIN)

-
定义:右联结返回右表中的所有记录,以及左表中满足连接条件的记录。如果左表中没有匹配的记录,左表的字段将为 NULL。
-
示例
SELECT student.name, score.grade FROM student RIGHT JOIN score ON student.id = score.student_id;
4. 外连接(OUTER JOIN)
-
定义:外连接包括左外连接、右外连接和全外连接。全外连接返回左右表中所有记录,匹配则显示对应字段,不匹配则为 NULL。
-
示例(全外连接)
SELECT student.name, score.grade FROM student FULL OUTER JOIN score ON student.id = score.student_id;
5. 交叉连接(CROSS JOIN)
-
定义:交叉连接返回两个表的笛卡尔积,即左表中的每一行与右表中的每一行组合。
-
示例
SELECT department.dept_name, employee.name FROM department CROSS JOIN employee;
二、集合运算
2.1 概念
集合运算是以行为单位进行的操作,会影响记录行数,但不会改变列的数量。
2.2 类型
1. 并集(UNION)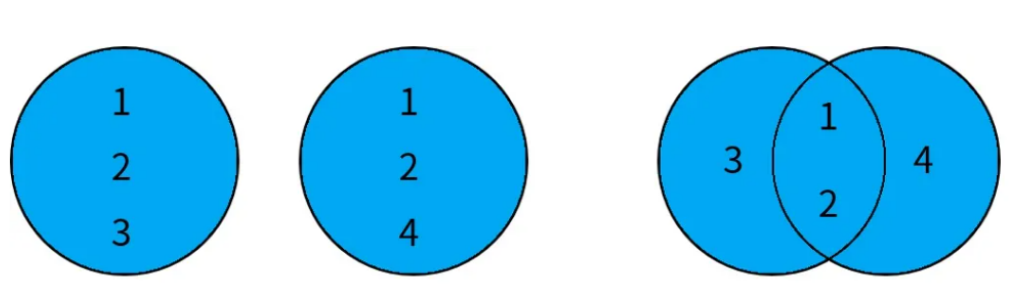
-
定义:并集返回两个查询结果集的合并,包含所有出现在第一个或第二个查询结果中的记录。
-
语法
SELECT column1, column2, ... FROM table1 UNION [DISTINCT | ALL] SELECT col1, col2, ... FROM table2;
2. 交集(INTERSECT)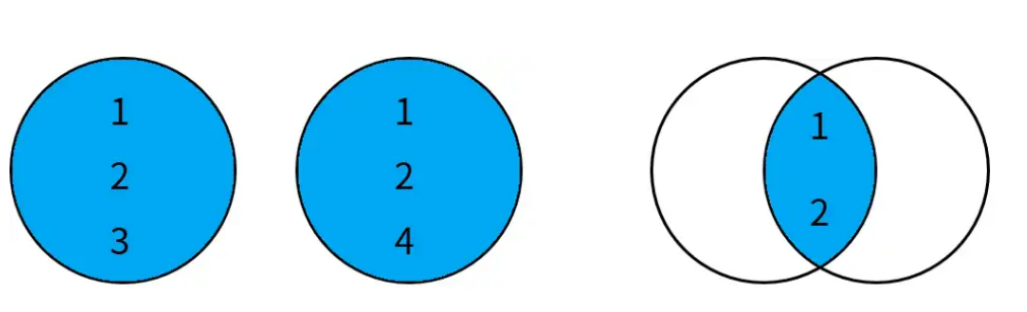
-
定义:交集返回两个查询结果集中都包含的记录。
-
语法
SELECT column1, column2, ... FROM table1 INTERSECT [DISTINCT | ALL] SELECT col1, col2, ... FROM table2;
3. 差集(EXCEPT)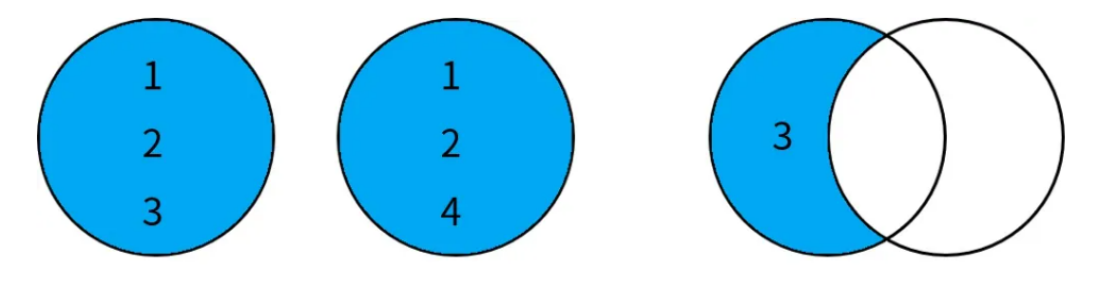
-
定义:差集返回出现在第一个查询结果中但不在第二个查询结果中的记录。
-
语法
SELECT column1, column2, ... FROM table1 EXCEPT [DISTINCT | ALL] SELECT col1, col2, ... FROM table2;
三、数据完整性约束
3.1 主键(Primary Key)
-
定义:用于唯一标识表中的每一行,具有唯一性和非空性。
-
创建示例
CREATE TABLE student (id INT PRIMARY KEY,name VARCHAR(100),age INT );
3.2 外键(Foreign Key)
-
定义:用于建立两个表之间的关联关系,确保数据的一致性和完整性。
-
创建示例
CREATE TABLE order (order_id INT PRIMARY KEY,customer_id INT,order_date DATE,FOREIGN KEY (customer_id) REFERENCES customer (id) );
3.3 唯一约束(Unique)
-
定义:确保列中的值唯一,允许 NULL 值。
-
创建示例
CREATE TABLE users ( id INT AUTO_INCREMENT PRIMARY KEY, username VARCHAR(50), email VARCHAR(100) UNIQUE, phone VARCHAR(20), CONSTRAINT uk_users_phone UNIQUE (phone) );
四、索引
4.1 定义
索引是用于提高数据查询速度的数据库对象,通过创建额外的数据结构来快速定位和访问表中的数据行。
4.2 分类
按数据结构分类
| 索引类型 | 数据结构特点 | 适用场景 |
|---|---|---|
| B-Tree 索引 | 基于平衡树,支持范围查询和排序操作 | 适用于需要频繁进行范围查询和排序的场景 |
| Hash 索引 | 基于哈希表,支持快速等值查询 | 适用于需要快速进行等值查询的场景 |
| 全文索引 | 用于文本数据的全文检索 | 适用于需要对文本内容进行搜索的场景 |
按逻辑结构分类
| 索引类型 | 特点 |
|---|---|
| 普通索引 | 基本索引类型,无唯一性约束 |
| 唯一索引 | 索引列的值必须唯一 |
| 组合索引 | 由多个列组合而成的索引 |
| 主键索引 | 特殊的唯一索引,通常与主键关联 |
五、视图
5.1 定义
视图是一个虚拟表,基于一个或多个基表的定义。视图中的数据是动态的,依赖于基表的数据。
5.2 优点
-
便捷整合:封装复杂的 SQL 查询,简化操作。
-
保密:隐藏基表结构,保护敏感数据。
-
简化权限管理:通过视图授权,减少对基表的直接访问。
5.3 缺点
-
耗费时间:查询时需要转换为基表查询。
-
修改不便:复杂视图的更新操作受限较多。
5.4 操作
| 操作类型 | 语法示例 |
|---|---|
| 创建视图 | CREATE VIEW view_name AS SELECT ... |
| 查询视图 | SELECT * FROM view_name |
| 删除视图 | DROP VIEW view_name |
六、存储过程
6.1 定义
存储过程是一组预编译的 SQL 语句,存储在数据库中,可通过名称调用执行。
6.2 优点
-
提高代码复用性
-
减少网络传输
-
提高执行效率
-
增强安全性
6.3 创建示例
CREATE OR REPLACE PROCEDURE proc_name
AS
BEGIN-- SQL 语句
END;七、函数
7.1 定义
函数是用于计算和返回值的预编译代码块,可在 SQL 查询中使用。
7.2 创建示例
CREATE OR REPLACE FUNCTION fun_sum (P_N NUMBER)
RETURN NUMBER
ISS NUMBER := 0;
BEGINFOR I IN 1..P_N LOOPS := S + I;END LOOP;RETURN S;
EXCEPTIONWHEN OTHERS THENROLLBACK;
END;7.3 调用示例
SELECT fun_sum(100) FROM DUAL;八、触发器
8.1 定义
触发器是一种特殊的数据库对象,当特定事件发生时自动执行预定义的操作。
8.2 创建示例
CREATE OR REPLACE TRIGGER tri_insert
BEFORE INSERT ON emp1
FOR EACH ROW
BEGININSERT INTO emp2 (empno) VALUES (1);
END;8.3 优缺点
-
优点:实现复杂的数据约束、审计等。
-
缺点:可能影响数据库性能,设计和维护复杂。





![[大语言模型]在个人电脑上部署ollama 并进行管理,最后配置AI程序开发助手.](http://pic.xiahunao.cn/[大语言模型]在个人电脑上部署ollama 并进行管理,最后配置AI程序开发助手.)






)






