
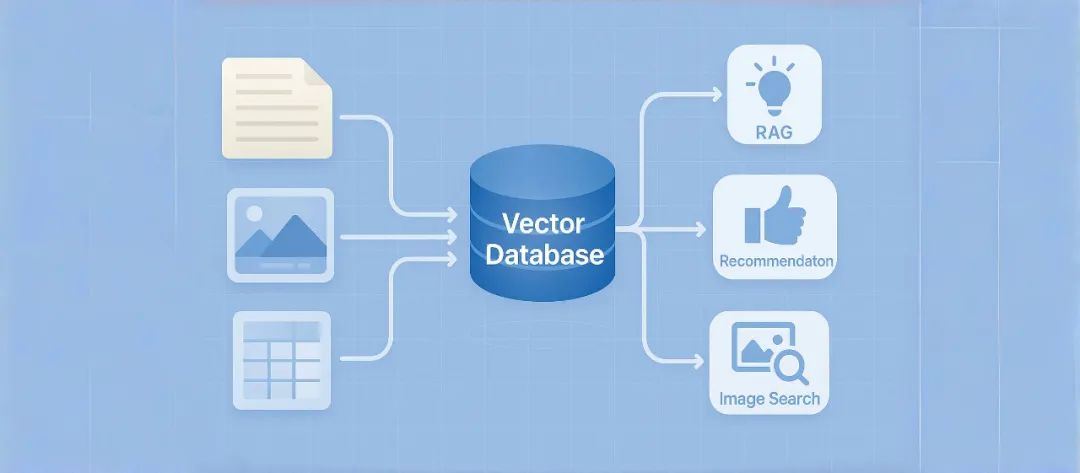
互联网时代,关系型数据库为王。相应的,我们的检索方式也是精确匹配查询为主——查找特定的用户ID、商品编号或订单状态。
但AI时代,语义检索成为常态,向量数据库成为搜索推荐系统,大模型RAG落地,自动驾驶数据筛选等场景的关键基础设施。
但一个问题是,不同场景,对向量数据库的需求不同:
- RAG(检索增强生成):需要在海量文档中找到与用户问题语义相关的内容。对召回质量要求高,可灵活添加元信息,支持多租户,存储成本低。
- 推荐系统:基于用户行为向量找到相似用户或商品。要求高 QPS、低延迟、高可用性,支持数据离线导入和弹性扩缩容。
- 图像搜索:通过图像特征向量实现以图搜图。要求低延迟,高可扩展性,以应对数据急速增长。
- 代码搜索:基于代码语义而非关键字匹配。要求高召回,高 QPS,低延迟,数据规模相对可控。
但是从Elasticsearch 到Milvus 到PG vector,再到Qdrant ,甚至就在昨天,AWS也推出了自己的S3 Vctor。
那么,面对市场上多的让人眼花缭乱的向量数据库产品,如何选择最适合自己业务场景的那一个?
本文将从功能、性能、生态三个核心维度,给出系统的决策框架和最佳实践建议(不涉及任何带货与倾向性引导):
01 如何做业务与VDB的功能匹配
在选择向量数据库时,功能是最基础和关键的考虑因素。以下是评估功能时需要重点关注的几个方面:
完善的向量数据类型
丰富的向量索引算法
全面的向量检索能力
企业级的可扩展架构
1.1 完善的向量数据类型
为什么要把完善的向量数据类型放在最开始?
原因很简单,文本、图像、音频分别对应不同向量类型;一个业务也往往对应多个向量字段,没有完善的向量数据类型支持,功能构建就无从谈起。
以电商平台的商品搜索为例,一个搜索动作,通常会涉及至少三种向量类型:
商品图片经过图像模型处理后生成的稠密向量,可以用于以图搜图和视觉相似性匹配。
商品描述文本经过分词后生成的稀疏向量,可以用于关键词匹配和全文检索。
商品的用户行为特征(如点击、收藏、购买等)会编码为二值向量,用于快速用户兴趣匹配。

1.2 丰富的向量索引算法与精细化参数设置
不同场景对向量检索的要求,通常可以概括为三方面:高召回率、高性能和低成本,但这三个目标之间往往又会构成一个不可能三角。
但通常来说,三者取其二,就能满足99%以上的需求。那么究竟选哪两者,需要不同的高效索引算法来支持。以下是不同索引算法,对应的不同场景总结:
基于内存索引算法:
Flat索引适合追求极致召回率的场景
IVF索引适合大规模数据的快速检索
HNSW索引则在召回率和性能之间取得良好平衡
基于磁盘的索引方案,可以突破内存容量限制,实现PB级大规模数据的经济存储和高效检索
基于GPU等硬件加速的GPU 索引,满足对延迟极其敏感的在线推理场景
提供细粒度的参数调优能力,支持用户根据业务特点精确控制索引行为
而基于多样化的索引选择,向量数据库还应具备精细的参数配置,让用户在有限的资源投入下实现最优的性能产出。
1.3 全面的向量检索能力
Top-K相似性检索是最常见的向量检索需求,但除此之外过滤检索、阈值检索、分组检索和混合检索,也是一个企业级向量数据库的必备功能。
还是以电商平台的智能商品推荐为例,场景设置为用户要买一条裙子。那么一个推荐动作,其实可以被拆解为以下几个服务的结合:
Top-K相似性检索
基于当前商品的图片和文本描述向量,检索视觉和语义相似的商品
智能过滤
通过价格区间筛选(标量过滤)、库存状态过滤(布尔过滤)和相似度阈值控制(设定最低相似度分数为0.8)进行智能筛选
多样性优化
按商品品类分组(连衣裙、半身裙、套装等)并对每个品类精选Top-3展示(分组检索)
个性化推荐
通过融合用户画像向量、结合历史购买行为,实现多模态混合检索(商品文本稀疏向量 + 图片稠密向量)
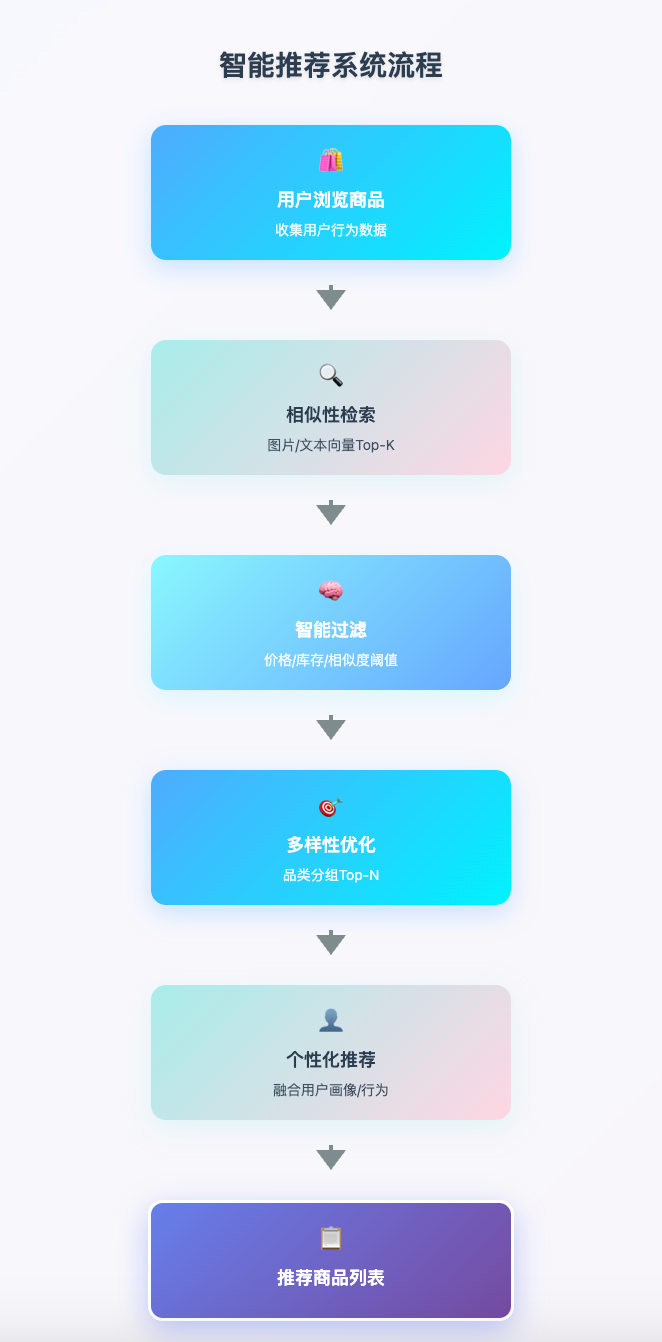
看似简单的相关商品推荐背后,实际需要向量数据库提供一整套完备的检索能力。
1.4 企业级的可扩展架构
相比传统结构化数据,非结构化数据最大的特点就是数据量足够大。IDC数据显示,到2027年,全球非结构化数据将占到数据总量的86.8%,达到246.9ZB。
这些数据通过各类AI模型处理后会产生海量的向量数据。
相应的,一个好的的向量数据库必须采用高度灵活和可扩展的云原生架构,以应对这种指数级的数据增长。同时,系统需要具备完善的高可用机制,包括多副本容灾、自动故障切换等特性,确保服务的连续性。
02 如何做VDB的性能评估
建立在完整的功能需求之上,性能是我们最关注的特性。
通常来说,性能评估,可以从以下几个维度系统性进行考察:
查询延迟:包括P50、P95、P99等分位点,反映大部分和极端情况下的响应速度。
吞吐量(QPS):单位时间内可处理的查询数量,体现系统并发能力。
准确率(Recall@K):近似检索场景下,结果的准确性同样重要。
数据规模适应性:在百万、千万、亿级数据量下的性能表现,是否能平滑扩展。
过滤查询性能:在不同过滤比例(如1%、10%、50%、90%、99%)下的向量检索性能表现,体现系统处理复杂查询的能力。
流式处理性能:在持续写入和实时查询的场景下,系统的写入延迟、查询延迟波动情况,以及数据一致性保证。
资源消耗:CPU、内存、磁盘IO等资源占用,决定了系统的性价比和可持续性。
知道需要评估的指标以后,选择一个好的评测工具也很重要。在算法层面,ANN-Benchmark是一个广受认可的近似最近邻算法评测平台,但它主要面向底层算法库的性能对比,忽略了动态场景、数据集维度也有些过时、用例相对简单,不适用生产环境。
而关于生产环境的向量数据库评测,我们更推荐同样开源的VDBBench。其特性可以参考我们的历史文章:
https://mp.weixin.qq.com/s/LK2aC2AkPeBGRn41Bd6l-A
使用 VDBBench 的典型测试流程:
确定使用场景:选择合适的数据集(如SIFT1M、GIST1M等)和业务场景(如TopK检索、过滤检索、边写入边检索等)。
配置数据库和VDBBench参数:保证测试环境公平、可复现。
在Web界面上配置并启动测试,自动收集各项性能指标,对其进行对比后,做综合选型决策。
03 不要忽略VDB的生态
生态系统的完善程度会直接决定VDB的可用性、可推广性和长期生命力。
我们的考量维度可以从以下几个方面来展开
大模型生态的适配
一个优秀的向量数据库应当能够无缝对接主流大模型(如OpenAI、Claude、Qwen等)和Embedding服务,支持多种主流向量生成方式。同时,还可以和LangChain、LlamaIndex、Dify等AI开发框架深度集成,方便开发者快速构建RAG、智能问答、推荐系统等应用。
工具体系的适配
一个高效简洁的交互与监测系统,会直接决定用户的数据库使用体验,常见的配套工具体系主要有以下几个:
可视化管理工具:支持数据管理、性能监控、权限配置等一站式操作
备份与恢复工具:支持全量/增量备份、数据恢复,保障数据安全
容量规划工具:帮助用户科学评估资源需求,合理规划集群规模
诊断与调优工具:支持日志分析、性能瓶颈定位、故障排查等
监控与告警体系:如Prometheus/Grafana集成,便于实时监控系统健康状态
是否开源与中立
向量数据库是个尚在进化中的进行时产品,开源意味着可以听到更多用户声音,率先完成进化。同时,借助活跃的开源社区,也能够降低用户的使用与认知门槛。
但只有开源是不够的,大型开源项目的迭代维护是需要很高的人力投入,单靠个人开发者几乎无法支撑,业界知名的数据服务相关的开源项目,比如Spark、MongoDB、Kafka,背后都是有成熟的商业化公司在运营。
在此基础上,VDB的商业化方案,则应该保持云中立,在保证弹性、低运维投入的基础上,能满足不同业务、不同地区产品,以及不同阶段企业的多样化需求。
是否有足够的成功落地案例
一个成功的落地案例抵得上一万句解释与论证。在选型一款向量数据库之前,不妨先看看这个产品的官网和公众号上是否有涵盖各种行业(互联网、金融、制造、医疗、法律等),各种应用场景(搜索、推荐、风控、智能客服、质量检测等)的落地案例。
一个产品能服务好同行,自然能更好的服务自己。
如果还有担心,那么实践是检验真理的唯一标准,先做个POC测试验证一下肯定没错。
尾声
写这篇文章的起因,是最近很多朋友问到我关于向量数据库选型的问题。
但数据库选型是一个复杂的决策过程,选完之后可能会用三五年甚至更久,甚至决定一批开发者的职业生涯,给出建议必须慎之又慎。
所以我将自己的一些经验写成文章系统的分享出来,如果大家关于VDB选型或者应用、发展趋势的更多问题,欢迎扫描文末二维码,随时和我们交流!
作者介绍

李成龙
Zilliz 资深开源布道师
推荐阅读
开源|VDBBench 1.0正式官宣,完全复刻业务场景,支持用户自定义数据集
实战|TRAE+Milvus MCP,现在用自然语言就能搞定向量数据库部署了!
Milvus Week | Kafka 很好, Pulsar也不错,但WoodPecker才是未来
Milvus Week | 1bit极度量化+高召回,RaBitQ才是最好的向量量化算法











)


)
)


|SVM-几何距离)
![[每日随题11] 贪心 - 数学 - 区间DP](http://pic.xiahunao.cn/[每日随题11] 贪心 - 数学 - 区间DP)
)
