项目背景
在计算机视觉任务中,我们经常需要对大量图片进行目标检测和标注。YOLO 系列模型凭借其高效性成为目标检测的首选工具之一,但批量处理图片时往往需要编写繁琐的脚本。本文将介绍一个基于 Flask 和 YOLOv11 的 API 服务,支持单张图片和文件夹批量处理,可自定义置信度、交并比等参数,并能返回详细的标注统计结果。
功能特点
- 支持单张图片和文件夹批量处理,自动识别输入类型
- 可自定义置信度阈值 (conf) 和交并比阈值 (iou)
- 自动选择运行设备 (GPU 优先,无则 CPU)
- 生成标注后的图片和检测结果 TXT 文件
- 返回详细的标注统计信息 (每个文件的目标类别及数量)
- 提供完整的任务状态查询和结果下载功能
技术栈
fastapi:用于构建高性能的 Web API。uvicorn:一个快速的 ASGI 服务器,用于运行 FastAPI 应用。pydantic:用于数据验证和设置类型提示。ultralytics:包含 YOLO 模型,用于目标检测。opencv-python:用于图像处理和计算机视觉任务。numpy:用于数值计算。pillow:Python Imaging Library,用于图像处理。torch:PyTorch 深度学习框架,YOLO 模型依赖于此。base64:用于 Base64 编码和解码,虽然是 Python 标准库,但为了完整性列出。
代码实现
完整代码
import os
import shutil
import time
import json
import logging
import cv2
import numpy as np
import base64
from typing import Dict, Any, Optional, List
from fastapi import FastAPI, HTTPException, WebSocket, WebSocketDisconnect, Query
from fastapi.responses import JSONResponse, FileResponse
from fastapi.middleware.cors import CORSMiddleware
from pydantic import BaseModel
from ultralytics import YOLO
from PIL import Image, ImageDraw, ImageFont
import torch
import threading# 配置日志系统,设置日志级别为INFO,记录关键操作和异常信息
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)# 初始化FastAPI应用,设置API标题和版本
app = FastAPI(title="YOLO目标检测API", version="1.0")# 配置CORS(跨域资源共享),允许所有来源的请求访问API
app.add_middleware(CORSMiddleware,allow_origins=["*"],allow_credentials=True,allow_methods=["*"],allow_headers=["*"],
)# 任务状态跟踪字典,用于存储每个检测任务的执行状态和结果
tasks: Dict[str, Dict[str, Any]] = {}# 定义绘制检测框的颜色列表,为不同类别分配不同颜色
COLORS = [(0, 255, 0), (0, 0, 255), (255, 0, 0), (255, 255, 0), (0, 255, 255),(255, 0, 255), (128, 0, 0), (0, 128, 0), (0, 0, 128)
]# 尝试加载Arial字体用于绘制标签,若加载失败则使用默认字体
try:font = ImageFont.truetype("arial.ttf", 18)
except:font = ImageFont.load_default()# 定义检测请求的数据模型,使用pydantic进行参数校验
class DetectRequest(BaseModel):input_path: str # 输入文件或文件夹路径output_dir: str = "demo" # 输出目录,默认为demomodel_path: str = "yolo11n.pt" # 模型路径,默认为YOLO Nano版本device: Optional[str] = None # 设备选择,可选参数(如'0'表示GPU,'cpu'表示CPU)conf: float = 0.25 # 置信度阈值,过滤低置信度的检测结果iou: float = 0.7 # IOU(交并比)阈值,用于非极大值抑制target_classes: Optional[str] = None # 目标类别,逗号分隔的字符串(如"person,car")def draw_annotations(image: np.ndarray, boxes, class_names) -> np.ndarray:"""在图像上绘制检测框和类别标签Args:image: 输入的图像数组(BGR格式)boxes: 过滤后的检测框列表(YOLO模型的Box对象)class_names: 类别名称字典({类别ID: 类别名称})Returns:绘制标注后的图像数组(BGR格式)"""# 将OpenCV的BGR格式转换为PIL的RGB格式,用于绘制文本frame_pil = Image.fromarray(cv2.cvtColor(image, cv2.COLOR_BGR2RGB))draw = ImageDraw.Draw(frame_pil)if len(boxes) == 0:# 若无检测结果,直接返回原图return image# 遍历每个检测框for box in boxes:# 解析框坐标、类别ID和置信度x1, y1, x2, y2 = map(int, box.xyxy[0].tolist()) # 检测框的左上角和右下角坐标class_id = int(box.cls) # 类别IDconf = float(box.conf) # 置信度# 为不同类别分配不同颜色(循环使用预定义颜色列表)color = COLORS[class_id % len(COLORS)]# 绘制边界框draw.rectangle([(x1, y1), (x2, y2)], outline=color, width=3)# 构建标签文本(类别名 + 置信度)label = f"{class_names[class_id]}: {conf:.2f}"# 获取文本边界框,用于确定标签背景位置try:text_bbox = draw.textbbox((x1, y1), label, font=font)except AttributeError:# 兼容旧版本PIL,使用textsize方法替代textbboxtext_width, text_height = draw.textsize(label, font=font)text_bbox = (x1, y1, x1 + text_width, y1 + text_height)# 计算标签的垂直位置,避免超出图像边界text_height = text_bbox[3] - text_bbox[1]label_y1 = y1 - text_height - 5 if (y1 - text_height - 5) > 0 else y1 + 5# 绘制标签背景(与边界框颜色相同的矩形)draw.rectangle([(x1, label_y1), (x1 + (text_bbox[2] - text_bbox[0]), label_y1 + text_height)],fill=color)# 绘制标签文本(白色字体)draw.text((x1, label_y1), label, font=font, fill=(255, 255, 255))# 将PIL图像转换回OpenCV的BGR格式return cv2.cvtColor(np.array(frame_pil), cv2.COLOR_RGB2BGR)def batch_detect_and_annotate(task_id: str,input_path: str,output_dir: str = "demo",model_path: str = "yolo11n.pt",device: Optional[str] = None,conf: float = 0.25,iou: float = 0.7,target_classes: Optional[str] = None
):"""批量处理图像或文件夹中的所有图像,执行目标检测并生成标注图像和结果文件Args:task_id: 唯一任务标识符input_path: 输入文件或文件夹路径output_dir: 输出目录model_path: YOLO模型路径device: 推理设备(如'0'表示GPU,'cpu'表示CPU)conf: 置信度阈值iou: IOU阈值target_classes: 目标类别(逗号分隔的字符串)"""# 初始化任务状态为"running"tasks[task_id] = {"status": "running", "progress": 0, "message": "开始处理..."}try:start_time = time.time() # 记录开始时间os.makedirs(output_dir, exist_ok=True) # 创建输出目录(如果不存在)# 自动选择设备:若未指定则优先使用GPU,否则使用CPUselected_device = device if device else ('0' if torch.cuda.is_available() else 'cpu')# 加载YOLO模型try:model = YOLO(model_path)except Exception as e:# 模型加载失败,更新任务状态为"failed"tasks[task_id] = {"status": "failed", "message": f"模型加载失败:{str(e)}"}return# 解析目标类别参数(如果有)target_set = Noneif target_classes:# 将逗号分隔的字符串转换为集合,便于快速查找target_set = set([cls.strip() for cls in target_classes.split(',')])# 验证目标类别是否存在于模型类别中model_classes = set(model.names.values())invalid_classes = [cls for cls in target_set if cls not in model_classes]if invalid_classes:# 若存在无效类别,更新任务状态为"failed"tasks[task_id] = {"status": "failed", "message": f"无效的目标类别: {', '.join(invalid_classes)}"}return# 处理输入路径(文件或文件夹)input_dir = None # 预初始化输入目录变量is_single_file = Falseif os.path.isfile(input_path):# 输入是单个文件image_files = [os.path.basename(input_path)] # 获取文件名input_dir = os.path.dirname(input_path) # 获取文件所在目录is_single_file = Trueelif os.path.isdir(input_path):# 输入是文件夹image_extensions = (".jpg", ".jpeg", ".png", ".bmp", ".gif", ".tiff")# 筛选文件夹中的所有图像文件image_files = [f for f in os.listdir(input_path)if f.lower().endswith(image_extensions) and os.path.isfile(os.path.join(input_path, f))]input_dir = input_path # 输入目录即为指定文件夹is_single_file = Falseelse:# 输入路径不存在,更新任务状态为"failed"tasks[task_id] = {"status": "failed", "message": f"输入路径不存在: {input_path}"}returnif not image_files:# 未找到图像文件,更新任务状态为"failed"tasks[task_id] = {"status": "failed", "message": f"未找到图片文件: {input_path}"}returntotal_files = len(image_files) # 总文件数success_count = 0 # 成功处理的文件数fail_count = 0 # 处理失败的文件数file_annotations = {} # 存储每个文件的检测结果# 遍历所有图像文件for i, img_file in enumerate(image_files, 1):img_path = os.path.join(input_dir, img_file) # 构建完整文件路径img_name = os.path.splitext(img_file)[0] # 获取不带扩展名的文件名# 更新任务进度progress = int((i / total_files) * 100)tasks[task_id]["progress"] = progresstasks[task_id]["message"] = f"正在处理:{img_file}"try:# 执行目标检测results = model(img_path, device=selected_device, conf=conf, iou=iou)all_boxes = results[0].boxes # 获取所有检测框# 过滤检测框(如果指定了目标类别)filtered_boxes = []if target_set:# 仅保留目标类别中的检测框for box in all_boxes:cls_name = model.names[int(box.cls)]if cls_name in target_set:filtered_boxes.append(box)else:# 未指定目标类别时,保留所有检测框filtered_boxes = list(all_boxes)# 读取原始图像image = cv2.imread(img_path)if image is None:raise Exception(f"无法读取图像: {img_path}")# 生成标注图像annotated_img = draw_annotations(image, filtered_boxes, model.names)# 定义输出文件路径output_img_name = f"{img_name}_annotated.jpg"output_txt_name = f"{img_name}_detections.txt"output_img_path = os.path.join(output_dir, output_img_name)txt_path = os.path.join(output_dir, output_txt_name)# 保存标注图像cv2.imwrite(output_img_path, annotated_img)# 保存检测结果到文本文件with open(txt_path, "w", encoding="utf-8") as f:for box in filtered_boxes:cls_name = model.names[int(box.cls)]confidence = round(float(box.conf), 4)x1, y1, x2, y2 = map(round, box.xyxy[0].tolist())f.write(f"{cls_name} {confidence} {x1} {y1} {x2} {y2}\n")# 统计每个类别的检测数量annotations = {}for box in filtered_boxes:cls_name = model.names[int(box.cls)]annotations[cls_name] = annotations.get(cls_name, 0) + 1# 记录当前文件的检测结果file_annotations[img_name] = {"annotated_image": output_img_path,"detection_txt": txt_path,"class_counts": annotations}success_count += 1 # 成功计数加1except Exception as e:# 单个文件处理失败,记录错误并继续处理下一个fail_count += 1logger.error(f"处理{img_file}失败: {str(e)}")# 计算总处理时间total_time = round(time.time() - start_time, 2)# 更新任务状态为"completed",并保存详细结果tasks[task_id] = {"status": "completed", "progress": 100,"total_time": total_time,"success_count": success_count,"fail_count": fail_count,"total_files": total_files,"output_dir": os.path.abspath(output_dir),"input_path": input_path,"is_single_file": is_single_file,"parameters": {"confidence_threshold": conf,"iou_threshold": iou,"device": selected_device,"target_classes": list(target_set) if target_set else None},"annotations": file_annotations,"message": "处理完成"}except Exception as e:# 发生未知错误,更新任务状态为"failed"tasks[task_id] = {"status": "failed", "message": f"未知错误:{str(e)}"}@app.post("/detect")
async def detect(request: DetectRequest):"""接收参数并启动目标检测任务(同步模式)Args:request: 检测请求参数Returns:任务执行结果"""logger.info(f"收到检测请求: {request.input_path}")# 验证参数范围if not (0 <= request.conf <= 1):raise HTTPException(status_code=400, detail="conf参数必须在0-1之间")if not (0 <= request.iou <= 1):raise HTTPException(status_code=400, detail="iou参数必须在0-1之间")# 生成唯一任务ID(使用时间戳确保唯一性)task_id = str(int(time.time() * 1000))logger.info(f"创建任务: {task_id}")try:# 执行检测任务(同步调用,会阻塞直到完成)batch_detect_and_annotate(task_id, request.input_path, request.output_dir, request.model_path, request.device, request.conf, request.iou, request.target_classes)# 获取任务结果task_result = tasks.get(task_id)if not task_result:raise HTTPException(status_code=500, detail="任务执行失败,未获取到结果")if task_result["status"] == "failed":# 任务执行失败,返回错误信息return JSONResponse(status_code=400,content={"task_id": task_id,"status": "failed","message": task_result["message"]})logger.info(f"任务完成: {task_id}, 处理时间: {task_result['total_time']}秒")return task_result # 返回完整的任务结果except Exception as e:# 处理请求过程中发生异常logger.exception(f"请求处理失败: {str(e)}")raise HTTPException(status_code=500, detail=f"请求处理失败: {str(e)}")@app.get("/status/{task_id}")
async def get_status(task_id: str):"""获取指定任务的执行状态Args:task_id: 任务IDReturns:任务状态信息"""status = tasks.get(task_id, {"status": "not_found", "message": "任务ID不存在"})return status@app.get("/results/{task_id}")
async def get_results(task_id: str):"""获取指定任务的结果(仅当任务完成时可用)Args:task_id: 任务IDReturns:任务结果信息"""task = tasks.get(task_id)if not task:raise HTTPException(status_code=404, detail="任务ID不存在")if task["status"] != "completed":# 任务未完成,返回当前状态和错误信息return {"status": task["status"],"progress": task["progress"],"message": task["message"],"error": "任务未完成,无法获取结果"}# 返回完整的任务结果return {"task_id": task_id,"status": "completed","total_time": task["total_time"],"success_count": task["success_count"],"fail_count": task["fail_count"],"total_files": task["total_files"],"input_path": task["input_path"],"is_single_file": task["is_single_file"],"output_dir": task["output_dir"],"parameters": task["parameters"],"annotations": task["annotations"],"message": "处理完成"}@app.get("/download/{task_id}/{filename:path}")
async def download_file(task_id: str, filename: str):"""下载任务结果文件Args:task_id: 任务IDfilename: 要下载的文件名Returns:文件响应"""task = tasks.get(task_id)if not task or task["status"] != "completed":raise HTTPException(status_code=400, detail="任务未完成或不存在")output_dir = task["output_dir"]file_path = os.path.join(output_dir, filename)if not os.path.isfile(file_path):raise HTTPException(status_code=404, detail="文件不存在")# 返回文件内容供客户端下载return FileResponse(path=file_path,filename=os.path.basename(filename),media_type="application/octet-stream")@app.websocket("/ws/video_detection")
async def detect_video_websocket(websocket: WebSocket):"""通过WebSocket处理实时视频帧检测(适用于实时视频流)Args:websocket: WebSocket连接对象"""await websocket.accept() # 接受WebSocket连接logging.info("WebSocket 连接已建立。")try:while True:# 接收客户端发送的数据data_str = await websocket.receive_text()data = json.loads(data_str)# 解析请求参数model_name = data['model_name']base64_str = data['image_base64']conf = data.get('conf', 60) / 100.0 # 默认置信度阈值为0.6iou = data.get('iou', 65) / 100.0 # 默认IOU阈值为0.65# 加载YOLO模型model = YOLO(model_name)# 解码Base64格式的图像try:header, encoded_data = base64_str.split(",", 1)if not encoded_data:logging.warning("接收到空的Base64数据,已跳过。")continueimage_bytes = base64.b64decode(encoded_data)if not image_bytes:logging.warning("Base64解码后数据为空,已跳过。")continueexcept (ValueError, TypeError, IndexError) as e:logging.warning(f"Base64解析失败: {e},已跳过。")continue# 将字节数据转换为OpenCV图像image_cv2 = cv2.imdecode(np.frombuffer(image_bytes, np.uint8), cv2.IMREAD_COLOR)if image_cv2 is None:logging.warning("图像解码失败,已跳过。")continue# 执行目标检测并过滤结果(如果指定了目标类别)target_classes = data.get('target_classes')target_set = set(target_classes.split(',')) if target_classes else Noneresults = model(image_cv2, conf=conf, iou=iou, verbose=False)all_boxes = results[0].boxesfiltered_boxes = []if target_set:# 过滤出目标类别for box in all_boxes:cls_name = model.names[int(box.cls)]if cls_name in target_set:filtered_boxes.append(box)else:# 保留所有类别filtered_boxes = list(all_boxes)# 绘制标注(调用之前定义的函数)annotated_image = draw_annotations(image_cv2, filtered_boxes, model.names)# 将标注后的图像编码为Base64格式_, buffer = cv2.imencode('.jpg', annotated_image)result_base64 = base64.b64encode(buffer).decode("utf-8")# 将结果发送回客户端await websocket.send_json({"image_base64": f"data:image/jpeg;base64,{result_base64}"})except WebSocketDisconnect:# 客户端断开连接logging.info("WebSocket 客户端断开连接。")except Exception as e:# 处理WebSocket异常error_message = f"WebSocket 处理错误: {type(e).__name__}"logging.error(f"{error_message} - {e}")await websocket.close(code=1011, reason=error_message)if __name__ == '__main__':import uvicorn# 打印API启动信息和可用端点print("启动YOLO目标检测API服务...")print("支持的API端点:")print(" POST /detect - 启动检测任务")print(" GET /status/<task_id> - 获取任务状态")print(" GET /results/<task_id> - 获取结果")print(" GET /download/<task_id>/<filename> - 下载结果文件")print(" WS /ws/video_detection - 实时视频帧检测")# 启动FastAPI应用uvicorn.run(app, host="0.0.0.0", port=5000)核心参数说明
| 参数名 | 类型 | 说明 | 默认值 |
| input_path | String | 输入路径(支持单张图片或文件夹) | 无(必填) |
| output_dir | String | 结果输出文件夹路径 | "demo" |
| model_path | String | YOLO 模型路径 | "yolo11n.pt" |
| device | String | 运行设备("cpu" 或 "0") | 自动选择 |
| conf | Float | 置信度阈值(0-1) | 0.25 |
| iou | Float | 交并比阈值(0-1) | 0.7 |
| target_classes | String | 目标类别(逗号分隔的字符串) | 无 |
部署与使用
1. 安装依赖
pip install fastapi uvicorn pydantic ultralytics opencv-python numpy pillow torch base642. 启动服务
ython yolo_api.py服务启动后会监听本地 5000 端口,输出如下:
启动YOLO目标检测API服务...
支持的API端点:
POST /detect - 启动检测任务并返回结果
GET /status/<task_id> - 获取任务状态
GET /results/<task_id> - 获取结果(与/detect相同)
GET /download/<task_id>/<filename> - 下载结果文件
* Running on http://0.0.0.0:5000/ (Press CTRL+C to quit)
3. 使用 Postman 调用 API
处理图片
- 请求 URL: http://localhost:5000/detect
- 请求方法: POST
- 请求体:
{
"input_path": "C:/Users/HUAWEI/Desktop/yoloapi/tupian/", // 待检测图片文件夹
"output_dir": "C:/Users/HUAWEI/Desktop/yoloapi/output", // 结果输出文件夹
"model_path": "yolo11n.pt", // 模型路径(默认会自动下载)
"device": null, // 自动选择设备(也可指定"cpu"或"0")
"conf": 0.1, // 置信度阈值(越高越严格,默认0.25)
"iou": 0.6, // 交并比阈值(越高越严格,默认0.7)
"target_classes" : "car"
}
4. 返回结果示例
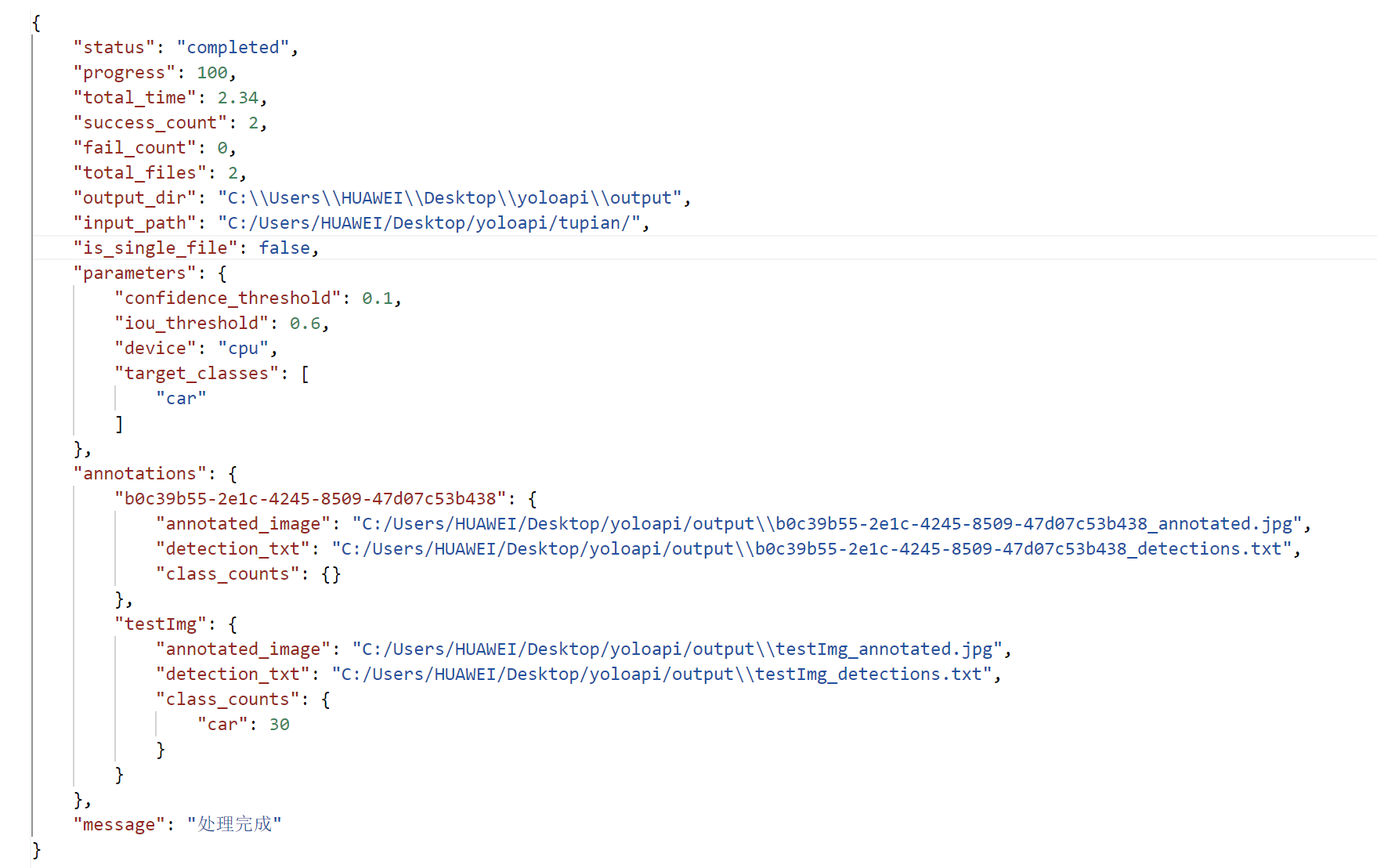







)

)








)
)