最近看到一个有意思的工作,原文来自:
https://blog.voyageai.com/2025/07/23/voyage-context-3/?utm_source=TWITTER&utm_medium=ORGANIC_SOCIAL
voyage-context-3:聚焦分段细节,融入全局文档上下文
概要: Voyage AI 推出了 voyage-context-3,这是一款情境化分段向量模型。它能为文本分段(chunk)生成向量,在无需手动添加元数据或上下文的情况下,自动捕获完整的文档上下文,从而显著提升检索准确性。与传统方法(无论是否进行增强)相比,其检索精度更高。同时,voyage-context-3 更简单、更快、成本效益更优,可直接替代标准向量模型,无需改变现有工作流程,并且降低了对分段策略的敏感性。
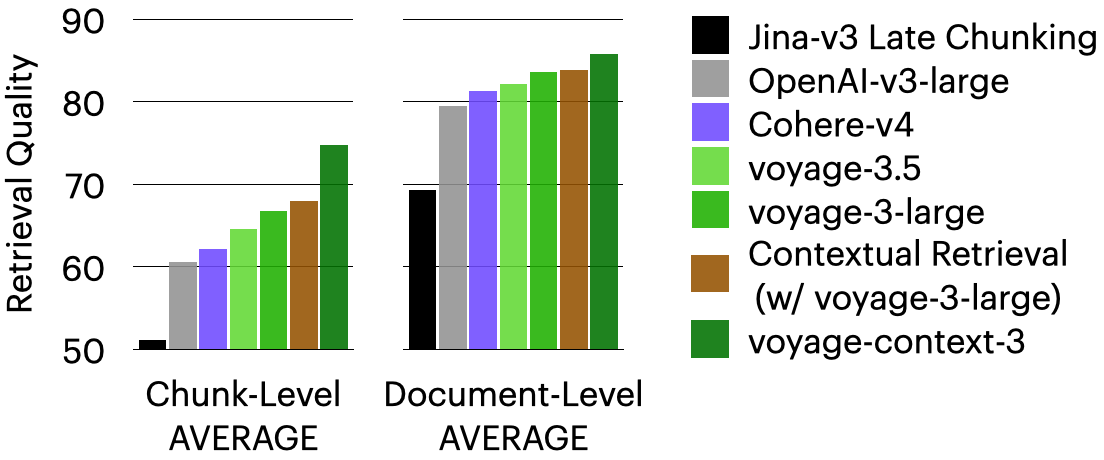
在分段级别和文档级别的检索任务中,voyage-context-3 的表现均优于:
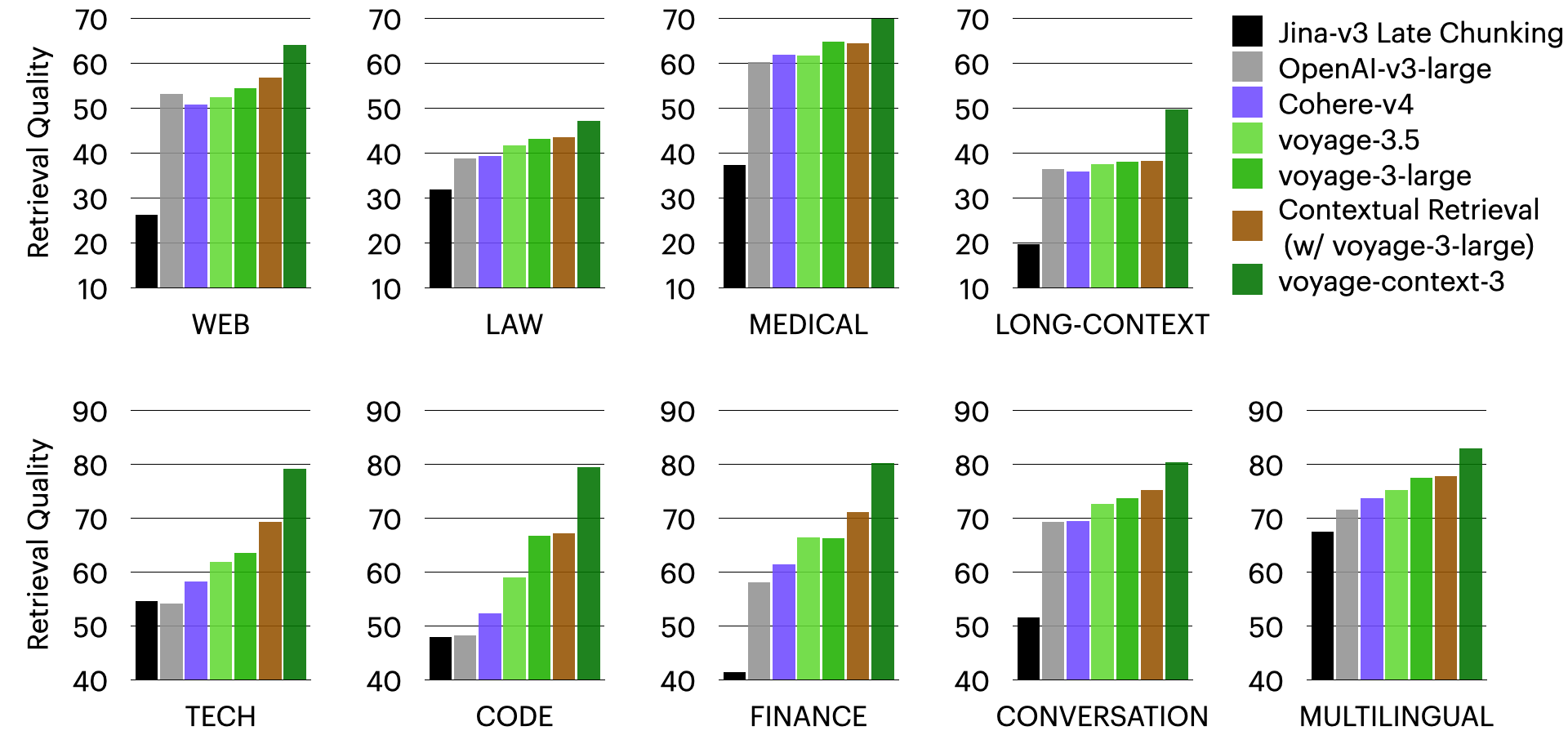
- OpenAI-v3-large 分别高出 14.24%和 12.56%。
- Cohere-v4 分别高出 7.89% 和 5.64%。
- Jina-v3 延迟分段(late chunking)分别高出 23.66% 和 6.76%。
- 情境化检索(contextual retrieval)分别高出 20.54% 和 2.40%。
voyage-context-3 还支持多维度和多种量化选项,这得益于 Matryoshka 学习(Matryoshka learning)和量化感知训练(quantization-aware training),在保持检索精度的同时,显著降低了向量数据库的存储成本。例如,voyage-context-3(二进制,512 维)在性能上超越了 OpenAI-v3-large(浮点,3072维)0.73%,同时将向量数据库存储成本降低了 99.48%——这意味着几乎相同的性能,但成本仅为 0.5%。
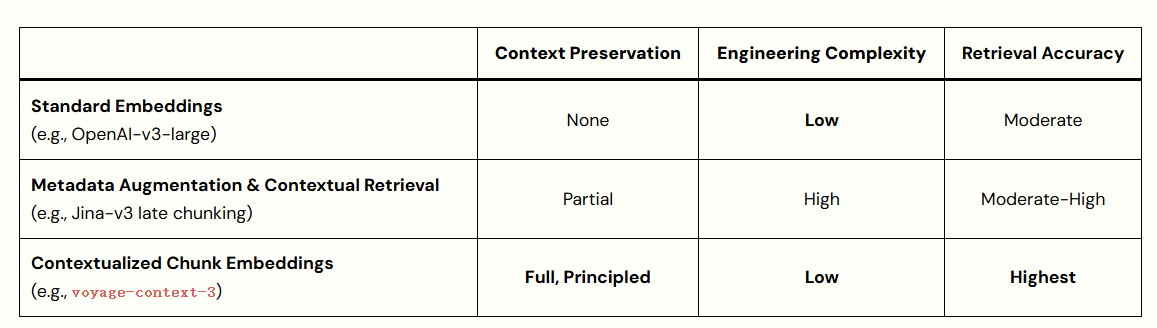
voyage-context-3 是一款新颖的情境化分段向量模型,其分段向量(chunk embedding)不仅编码了分段自身内容,还能够捕获完整文档的上下文信息。voyage-context-3 可以无缝替代现有 RAG(检索增强生成)流水线中使用的标准、上下文无关的向量模型,通过捕获相关上下文信息来提高检索质量。
与采用独立分段的上下文无关模型(例如 OpenAI-v3-large、Cohere-v4),以及通过重叠分段或附加元数据等方式为分段添加上下文的现有方法相比,voyage-context-3 在简化技术栈的同时,显著提升了检索性能。
在分段级别(检索最相关的分段)和文档级别(检索包含最相关分段的文档)检索任务中,voyage-context-3 平均表现均优于:
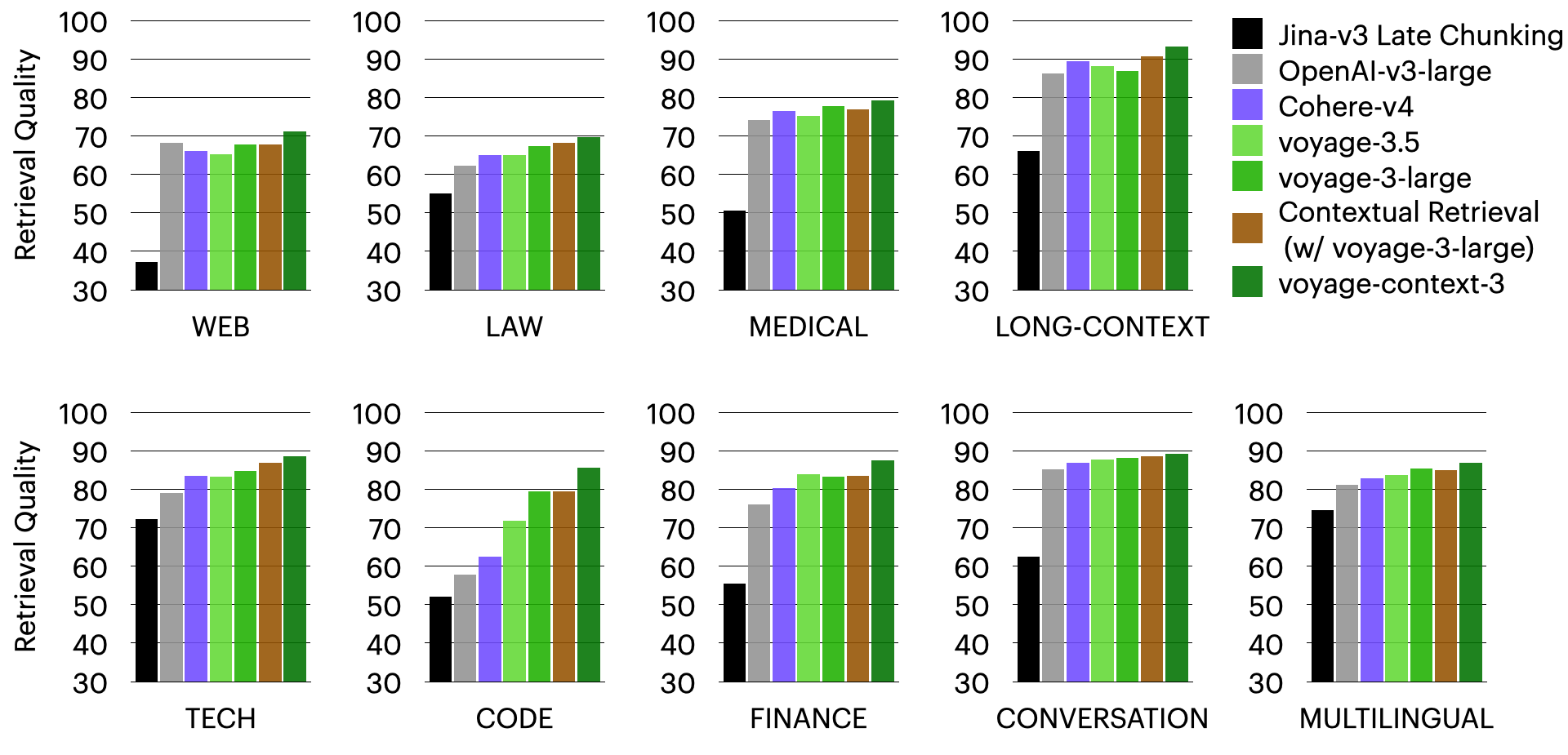
- OpenAI-v3-large:分段级别高出 14.24%,文档级别高出 12.56%。
- Cohere-v4:分段级别高出 7.89%,文档级别高出5.64%。
- 情境增强方法 Jina-v3 延迟分段1:分段级别高出 23.66%,文档级别高出 6.76%。
*情境化检索2:分段级别高出 20.54%,文档级别高出 2.40%。 voyage-3-large:分段级别高出7.96%,文档级别高出 2.70%。
RAG 中的分段挑战
聚焦细节与全局上下文的权衡。 在检索增强生成(RAG)系统中,将大型文档分解为更小的片段(即分段,chunks)是一个常见且往往必要的步骤。最初,分段主要是受限于模型有限的上下文窗口(尽管 Voyage 模型近期已显著扩展了这一窗口)。更重要的是,分段能使向量包含对相应文本段的精确细粒度信息,从而使搜索系统能够精准定位相关文本段。然而,这种聚焦有时会牺牲更广阔的上下文。此外,如果不进行分段,用户必须将完整的文档传递给下游 LLM,这会增加成本,因为许多 token 可能与查询无关。
例如,如果一份 50 页的法律文件被向量化为一个单一的向量,那么诸如"客户端与服务提供商基础设施之间的所有数据传输应采用 GCM 模式的 AES-256 加密"这样的详细信息,很可能在聚合中被掩盖或丢失。通过将文档分段成段落并分别向量化每个段落,生成的向量可以更好地捕获"AES-256 加密"之类的局部细节。但是,这样的段落可能不包含全局上下文——例如"客户名称"——而这对于回答"客户 VoyageAI 希望使用哪种加密方法?"这样的查询是必需的。
理想情况下,开发者期望同时拥有聚焦细节和全局上下文,且无需进行权衡。目前常用的变通方法——如分段重叠(chunk overlaps)、使用 LLM 进行上下文摘要(例如 Anthropic 的情境化检索),或元数据增强——可能会给本已复杂的 AI 应用流水线引入额外的步骤。这些步骤通常需要进一步的实验来调优,从而增加了开发时间和操作成本。
情境化分段向量模型介绍
Voyage AI 推出了情境化分段向量(contextualized chunk embeddings)模型,它能够同时捕获聚焦细节和全局上下文。该模型能一次性处理整个文档,并为每个分段生成独立的向量。每个向量不仅编码了其分段内的具体信息,还编码了粗粒度的文档级上下文,从而实现了更丰富、语义感知更强的检索。关键在于,神经网络能够同时"看到"所有分段,并智能地决定哪些来自其他分段的全局信息应注入到各个分段的向量中。
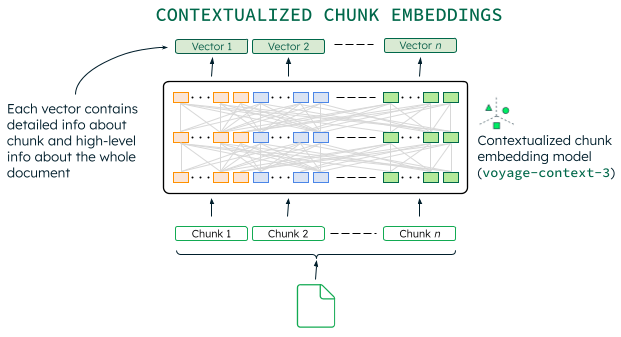
- 自动感知完整文档上下文。 情境化分段向量模型能捕获文档的完整上下文,无需用户手动或明确提供上下文信息。这与独立的片段向量相比,显著提升了检索性能,并且比其他上下文增强方法更简单、更快速、更经济。
- 无缝即插即用,存储成本相当。
voyage-context-3可直接替代现有搜索系统、RAG 流水线和智能体系统中使用的标准、上下文无关的向量模型。它接受相同的输入分段,并生成具有相同输出维度和量化方式的向量——这些向量现已通过文档级上下文进行了丰富,从而提升了检索性能。与引入大量向量和存储成本的 ColBERT 模型不同,voyage-context-3生成的向量数量相同,且完全兼容任何现有向量数据库。 - 对分段策略的敏感度更低。 尽管分段策略仍然会影响 RAG 系统的行为——并且最佳方法取决于数据和下游任务——但情境化分段向量模型在经验上已证明能降低系统对这些策略的敏感度,因为模型会智能地用全局上下文补充过短的分段。
情境化分段向量模型优于手动或基于 LLM 的上下文处理方法,因为神经网络经过训练,能够从大型数据集中智能地捕获上下文,从而超越了特设方法(ad hoc effort)的局限性。voyage-context-3 在训练时同时使用了文档级和分段级相关性标签,并采用了双重目标,旨在使模型在保留分段级粒度的同时,融入全局上下文。
评估详情
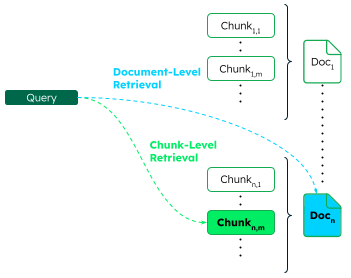
分段级别与文档级别检索。 对于给定的查询,分段级别检索(chunk-level retrieval)返回最相关的分段,而文档级别检索(document-level retrieval)则返回包含这些分段的文档。下图展示了来自 n 个文档的分段在这两种检索级别上的表现。最相关的分段(通常称为"黄金分段")以粗体绿色显示;其对应的父文档以蓝色显示。
数据集。 评估在 93 个特定领域检索数据集上进行,这些数据集涵盖了九个领域:网络评论、法律、医疗、长文档、技术文档、代码、金融、对话和多语言。具体列表可在此电子表格中查看。每个数据集包含一组查询和一组文档。每份文档由通过合理的分段策略创建的有序分段序列组成。与往常一样,每个查询都有若干相关文档,可能附带一个表示相关程度的分数,称之为文档级相关性标签,可用于评估文档级检索。此外,每个查询还包含一份最相关分段的列表及其相关性分数,这些分段通过包括 LLM 标注在内的各种方式精心整理。这些被称为分段级相关性标签,用于分段级检索评估。
评估还包含了专有的真实世界数据集,例如技术文档和包含标题元数据的文档。最后,使用与先前关于检索质量与存储成本分析相同的数据集,评估了 voyage-context-3 在不同向量维度和各种量化选项下的性能,采用标准单向量检索评估方法。
模型。 评估了 voyage-context-3 以及几种替代模型,包括:OpenAI-v3-large(text-embedding-3-large)、Cohere-v4(embed-v4.0)、Jina-v3 延迟分段(jina-embeddings-v3)、情境化检索、voyage-3.5 和 voyage-3-large。
指标。 对于给定的查询,根据余弦相似度检索出前 10 个文档,并报告归一化折让累积增益(NDCG@10),这是一种用于衡量检索质量的标准指标,也是召回率的一种变体。
结果
所有评估结果都可以在这个电子表格中找到,以下将详细分析这些数据。
特定领域质量。 下面的柱状图显示了 voyage-context-3 在每个领域中,使用全精度 2048 向量时的平均检索质量。在以下分段级检索图表中,可以看到 voyage-context-3 在所有领域中都优于所有其他模型。如前所述,对于分段级检索,voyage-context-3 平均分别优于 OpenAI-v3-large、Cohere-v4、Jina-v3 延迟分段和情境式检索 14.24%、7.89%、23.66% 和 20.54%。
voyage-context-3 在文档级检索中也超越了所有其他模型,这在下面的相应图表中有所体现。平均而言,voyage-context-3 在文档级检索方面分别优于 OpenAI-v3-large、Cohere-v4、Jina-v3 延迟分段和情境式检索 12.56%、5.64%、6.76% 和 2.40%。
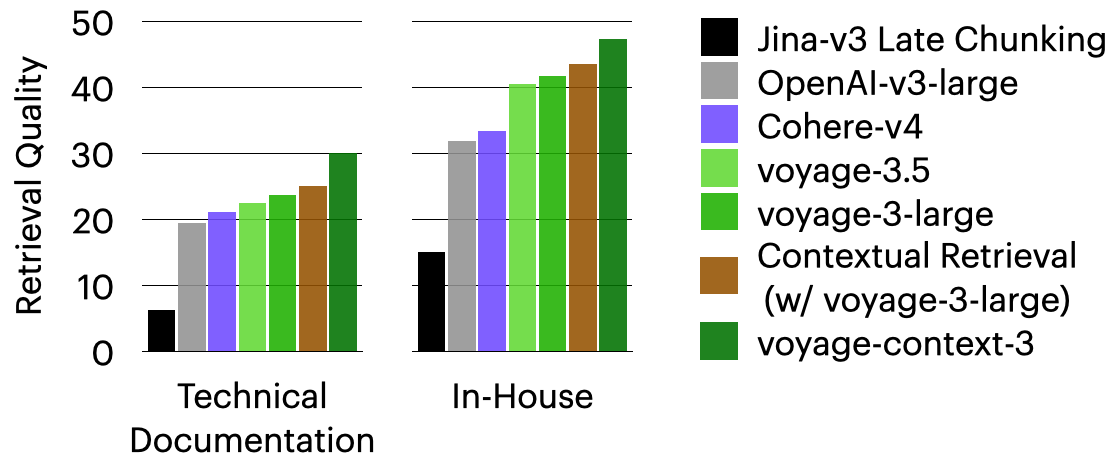
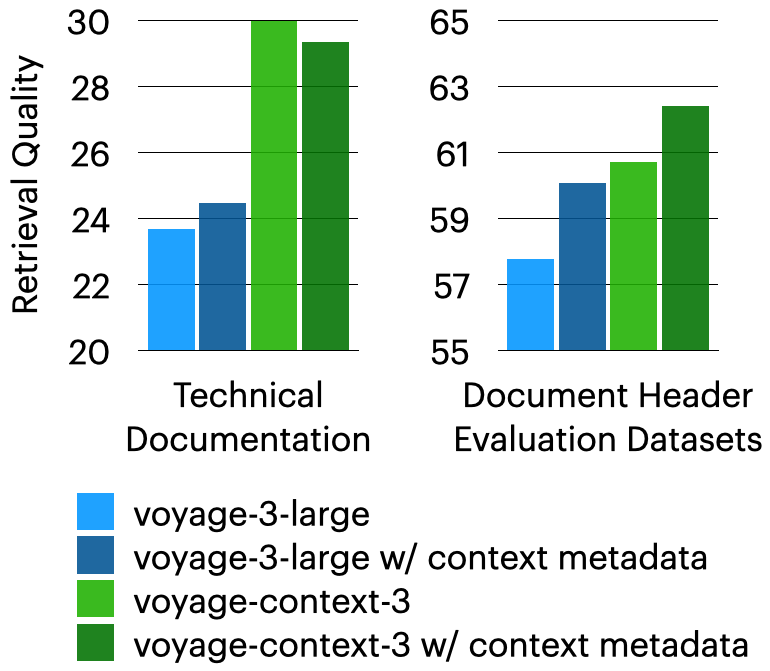
真实世界数据集。 voyage-context-3 在专有的真实世界技术文档和内部数据集上表现强劲,超越了所有其他模型。以下柱状图展示了分段级检索结果。文档级检索结果可在评估电子表格中查看。
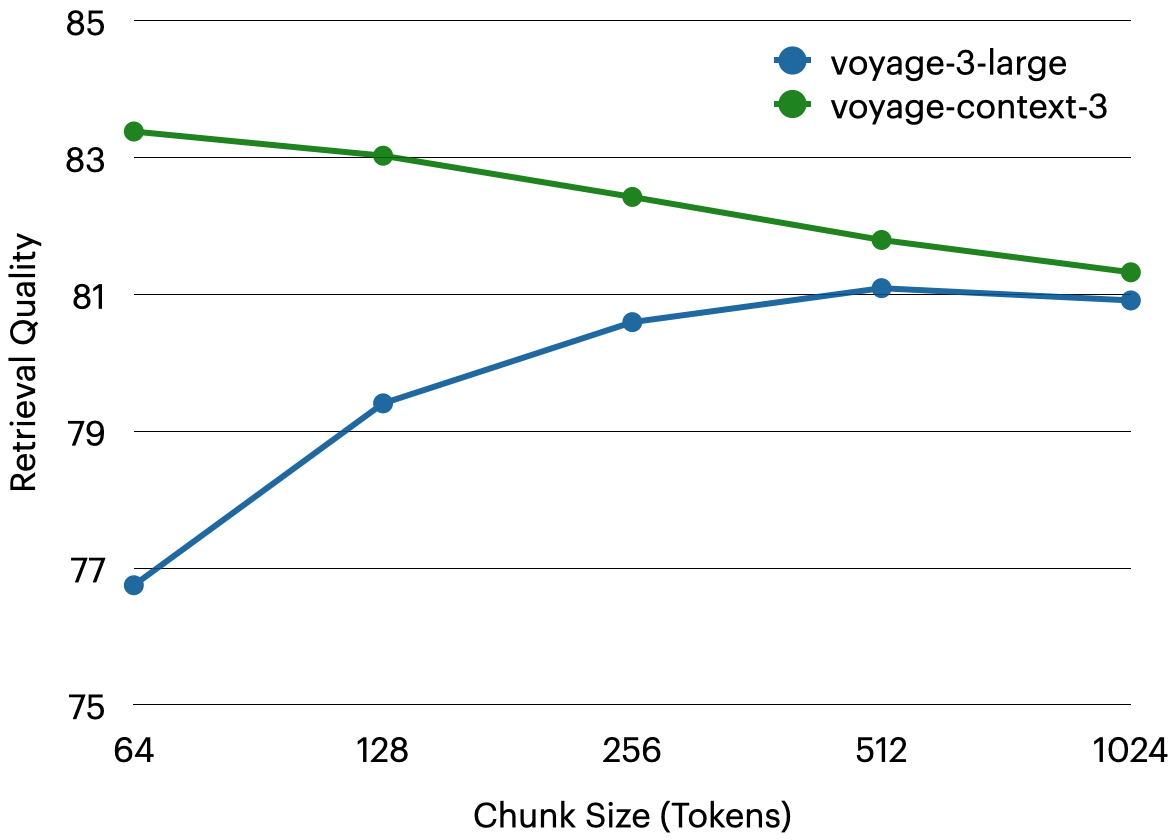
分段敏感度。 与标准、上下文无关的向量模型相比,voyage-context-3 对分段大小变化的敏感度较低,并且在分段较小时表现更强。例如,在文档级检索中,voyage-context-3 的方差仅为 2.06%,而 voyage-3-large 的方差为 4.34%。当使用 64 token 分段时,voyage-context-3 性能优于 voyage-3-large6.63%。
上下文元数据。 同时评估了当上下文元数据被前置到分段时的性能。即使将元数据前置到由 voyage-3-large 向量的分段中,voyage-context-3 仍然能够超越它高达 5.53%,这表明 voyage-context-3 在无需额外工作和资源来前置元数据的情况下,实现了更好的检索性能。
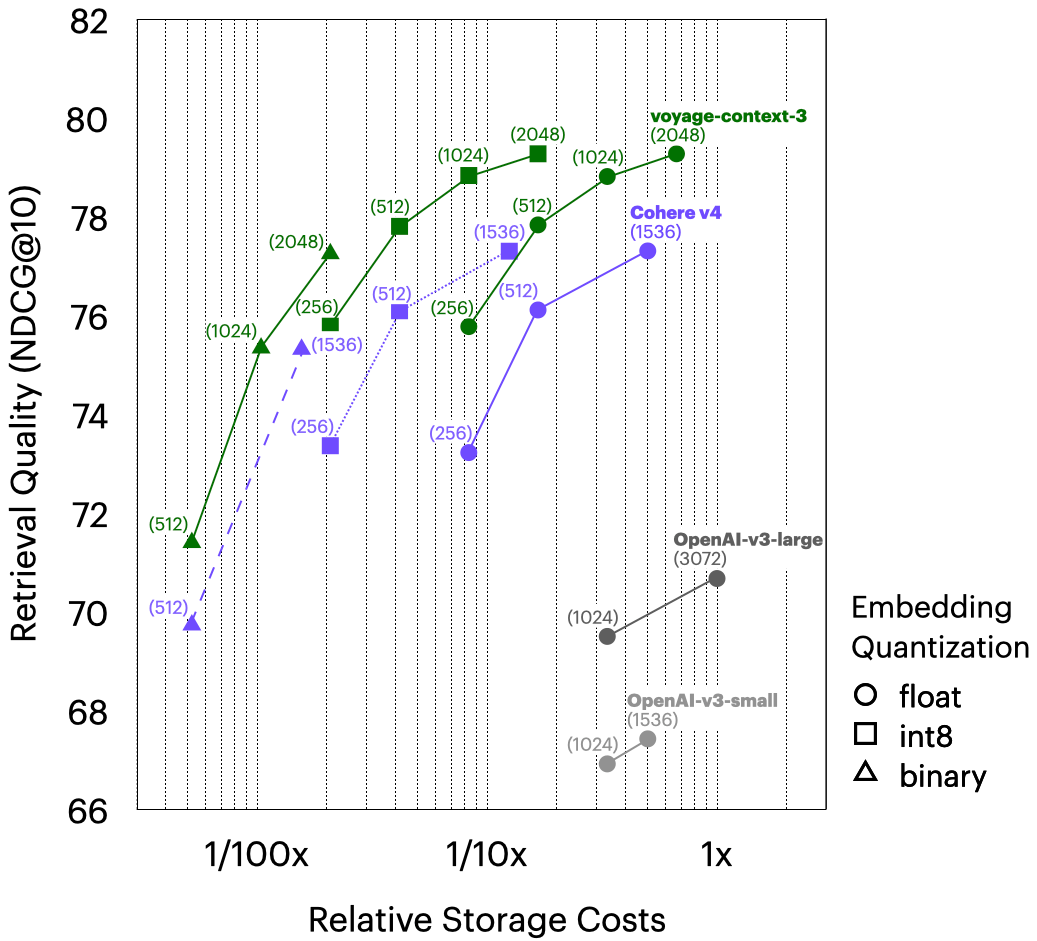
Matryoshka 向量与量化。 voyage-context-3 支持 2048、1024、512 和 256 维的向量,这得益于 Matryoshka 学习(Matryoshka learning)3。同时,它还支持多种向量量化选项——包括 32 位浮点、有符号和无符号 8 位整数以及二进制精度——并能最大限度地减少质量损失。为了进一步阐释上述图表,下图展示了文档中的单向量检索。与 OpenAI-v3-large(浮点,3072 维)相比,voyage-context-3(int8,2048 维)在检索质量提高 8.60% 的同时,将向量数据库成本降低了 83%。此外,将 OpenAI-v3-large(浮点,3072 维)与 voyage-context-3(二进制,512 维)进行比较,向量数据库成本降低了 99.48%,而检索质量提高了 0.73%;这意味着几乎相同的检索性能,但成本仅为 0.5%。
如何使用 voyage-context-3
voyage-context-3 现已推出免费 2 亿个 token 。可以通过此快速入门教程开始体验。
我们可以直接传递文本分割器(chunker)的输出,它已经被构造为所需的列表列表 - 每个内部列表包含单个文档的块。
# Contextualized embedding model
query_embd_context = vo.contextualized_embed(inputs=[[query]], model="voyage-context-3", input_type="query").results[0].embeddings[0]embds_obj = vo.contextualized_embed(inputs=texts,model="voyage-context-3",input_type="document"
)contextualized_chunk_embds = [emb for r in embds_obj.results for emb in r.embeddings]
使用上下文化的块嵌入执行语义相似性搜索。现在,我们可以执行相同的语义相似性搜索,但使用上下文化的块嵌入。
# Compute the similarity
# Voyage embeddings are normalized to length 1, therefore dot-product and cosine
# similarity are the same.
similarities_context = np.dot(contextualized_chunk_embds, query_embd_context)# Rank similiarities
ranks_context = np.argsort(np.argsort(-similarities_context)) + 1# Combine chunks with their ranks and similarities
ranked_contextualized_chunks = []
for i, (chunk_data, similarity, rank) in enumerate(zip(all_chunks, similarities_context, ranks_context)):ranked_contextualized_chunks.append({"chunk": chunk_data["chunk"],"doc_id": chunk_data["doc_id"],"similarity": float(similarity),"rank": int(rank)})print(f"Contextualized chunk similarities:\n{json.dumps(ranked_contextualized_chunks, indent=2)}")
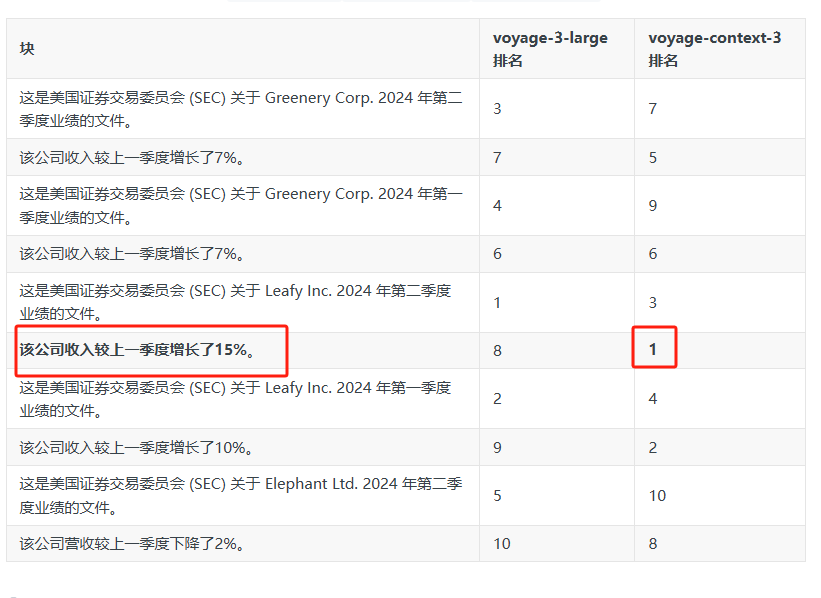
下表总结了(上下文无关)和(上下文化块嵌入)的检索排名。我们可以看到,在上下文严重丢失的情况下,上下文化块嵌入可以显著提高检索准确率。它没有优先考虑引用 SEC 文件的块,而是正确地将 Leafy Inc. 收入增长的信息列为最相关信息,并将“黄金块”置于顶部。
输入问题:query = “What was the revenue growth for Leafy Inc. in Q2 2024?”
用户可以将 voyage-context-3 无缝集成到任何现有的 RAG 流水线中,无需进行任何下游更改。情境化分段向量模型尤其适用于:
- 长篇、非结构化文档,例如白皮书、法律合同和研究报告。
- 跨分段推理,即查询需要跨越多个章节的信息。
- 高敏感度检索任务——例如金融、医疗或法律领域——在这些领域,遗漏上下文可能导致代价高昂的错误。
Jina. " 长上下文向量模型中的延迟分段。"2024 年 8 月22 日。 ↩︎
Anthropic. " 情境化检索介绍。"2024 年 9 月 19 日。 ↩︎
Matryoshka 学习:相关论文可参考 https://arxiv.org/abs/2205.13147。 ↩︎



的花店系统)


?)







)




