开发一个智能的问答系统,该系统支持用户聊天,传输文件。通过自然语言处理技术,机器人能够理解用户的意图。机器人将利用互联网搜索引擎来补充信息,确保用户能够获得全面且准确的回答。
一、web ui界面
我们采用gradio来编写的ui界面
Gradio 是一个简单易用的 Python 库,能够帮助开发者快速搭建用户友好的 Web 应 用,特别适合用于机器学习模型的展示。使用 Gradio 来搭建一个可以与 FastAPI 后端交互的对话机器人。
Gradio Blocks:用于组织界面布局的容器。
Slider:用于调整生成参数,如 temperature 和 top_p。
Textbox:用户输入对话的地方。
Button:发送用户输入或清空历史记录。
Chatbot:用于显示对话历史的组件。
安装:
pip install gradio==5.0.2
import uuid
import gradio as gr
from webui.chat_with_agent_api import chat_with_agent# 定义一个生成唯一会话 ID 的函数
def generate_session_id():return str(uuid.uuid4())# 在 Gradio 应用加载时生成新的会话ID
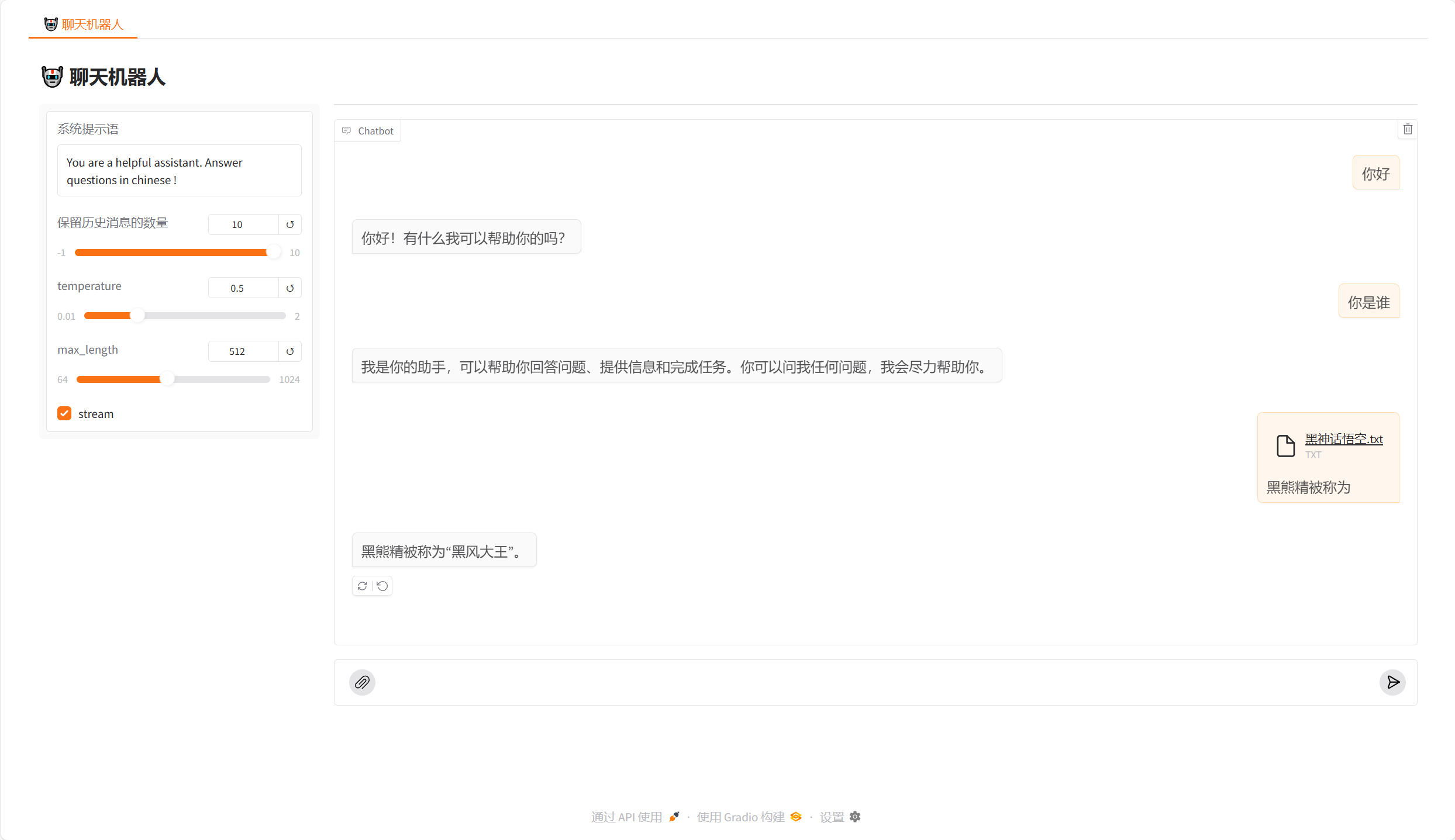
def on_app_load():session_id = generate_session_id()return session_idwith gr.Blocks(fill_width=True, fill_height=True) as demo:# 使用 on_load 事件来生成会话IDsession_state = gr.State(value=on_app_load)with gr.Tab("🤖 聊天机器人"):gr.Markdown("## 🤖 聊天机器人")with gr.Row():with gr.Column(scale=1, variant="panel") as sidebar_left:sys_prompt = gr.Textbox(label="系统提示语", value="You are a helpful assistant. Answer questions in chinese !")history_len = gr.Slider(minimum=-1, maximum=10, value=-1, label="保留历史消息的数量")temperature = gr.Slider(minimum=0.01, maximum=2.0, value=0.5, step=0.01, label="temperature")max_tokens = gr.Slider(minimum=64, maximum=1024, value=512, step=8, label="max_length")stream = gr.Checkbox(label="stream", value=True)with gr.Column(scale=10) as main:chatbot = gr.Chatbot(height=600, type="messages", )gr.ChatInterface(fn=chat_with_agent,multimodal=True,type="messages",theme="soft",chatbot=chatbot,additional_inputs=[sys_prompt,history_len,temperature,max_tokens,stream,session_state, # 使用 session_state 组件来传递会话ID],)
# 启动应用
demo.launch()
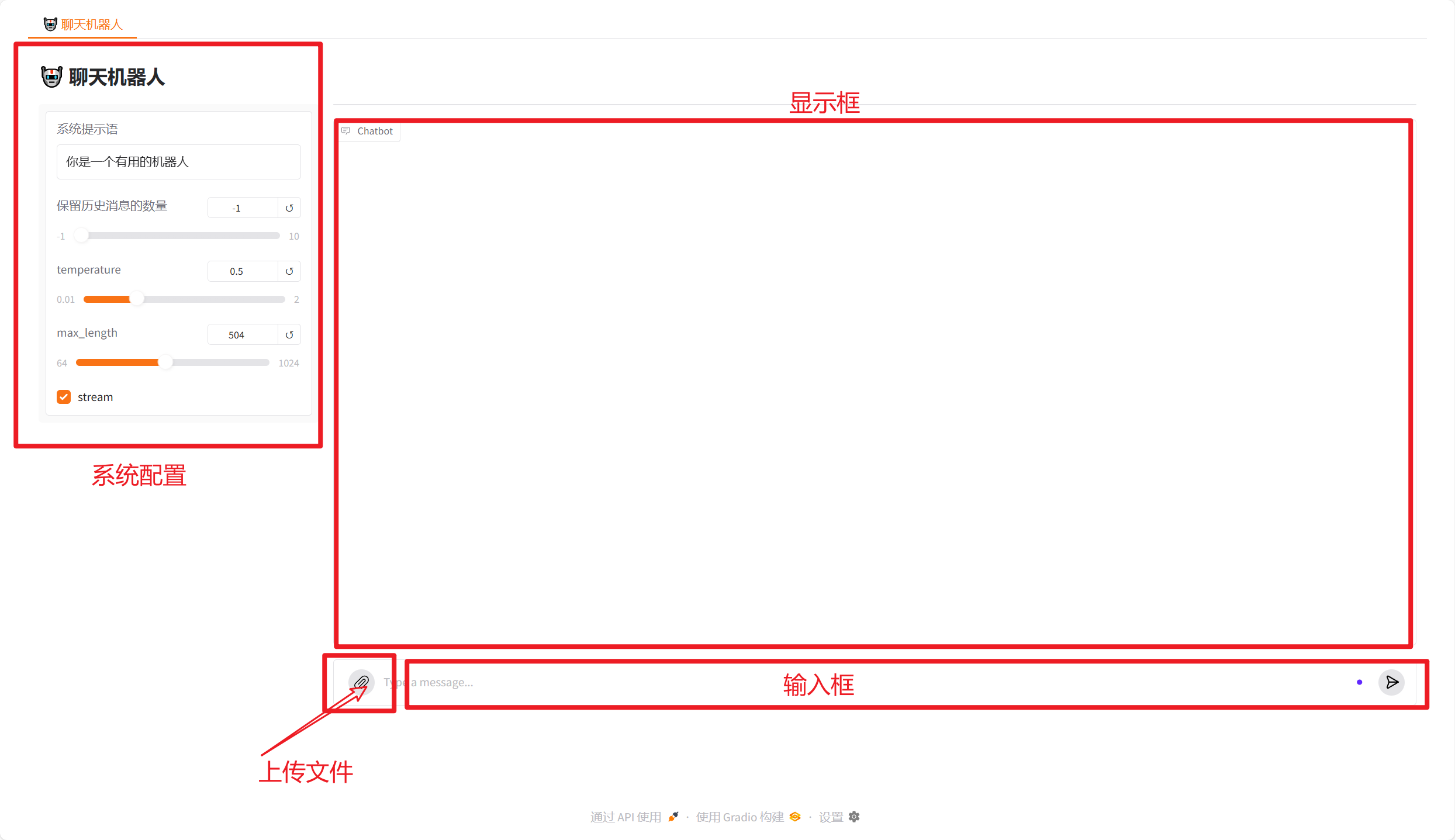
前端和后端进行交互,指向web_ui界面的gr.ChatInterface(fn=chat_with_agent)函数
# 定义后台 API 的 URL
import json
import requestschat_with_agent_url = "http://127.0.0.1:6605/chat/agent_chat"
chat_url = "http://127.0.0.1:6605/chat/chat"def chat_with_agent(prompt, history, sys_prompt, history_len, temperature, max_tokens, stream, session_id):# 构建文件和表单数据files = [('files', (open(file_path, 'rb'))) for file_path in prompt["files"]]if prompt["files"] != []:# 提取文件路径并拼接到 query 中query = f'{prompt["text"]}\n' + "".join(prompt["files"][0])else:query = f'{prompt["text"]}\n'# 构建请求数据data = {"query": query,"sys_prompt": sys_prompt,"history_len": history_len,"history": [str(h) for h in history],"temperature": temperature,"max_tokens": max_tokens,"session_id": session_id,}# 发送请求到 FastAPI 后端try:response = requests.post(chat_with_agent_url, files=files, data=data, stream=True)if response.status_code == 200:chunks = ""if stream:for chunk in response.iter_content(chunk_size=None, decode_unicode=True):if chunk:data = json.loads(chunk)chunks += data.get('answer', '')yield chunkselse:for chunk in response.iter_content(chunk_size=None, decode_unicode=True):data = json.loads(chunk)chunks += data.get('answer', '')yield chunkselse:yield "请求失败,请检查后台服务器是否正常运行。"except Exception as e:yield f"发生错误:{e}"
二、文本操作
2.1、Rag文本操作读取文本
import os
from langchain.document_loaders import (TextLoader, # 用于txt/csv/md/py等文本文件PDFPlumberLoader, # 用于PDF文件UnstructuredWordDocumentLoader, # 用于docx文件JSONLoader # 用于JSON文件
)def get_file_content(file_path):"""使用LangChain文档加载器读取文件内容Args:file_path (str): 文件路径Returns:str: 文件内容字符串"""filename = os.path.basename(file_path)file_extension = os.path.splitext(filename)[1].lower()try:# 根据文件类型选择对应的加载器if file_extension in ('.txt', '.csv', '.md', '.py'):loader = TextLoader(file_path, encoding='utf-8')elif file_extension == '.json':loader = JSONLoader(file_path,jq_schema=".",text_content=False)elif file_extension == '.pdf':loader = PDFPlumberLoader(file_path)elif file_extension == '.docx':loader = UnstructuredWordDocumentLoader(file_path)else:return "格式不支持,请更换文件!"# 加载文档并合并内容docs = loader.load()file_content = "\n".join([doc.page_content for doc in docs])return file_contentexcept Exception as e:return f"文件读取错误: {str(e)}"# 使用示例
if __name__ == "__main__":res = get_file_content('/home/use_Agent_project/test.csv')print(res)2.2、with open操作读取文本
import json
import os
import fitz
from docx import Documentdef get_file_content(file_path):filename = os.path.basename(file_path)file_extension = os.path.splitext(filename)[1].lower()# 读取不同类型的文件内容if file_extension == '.txt' or file_extension == '.csv':with open(file_path, "r", encoding="utf-8") as f:file_content = f.read()elif file_extension == '.json':with open(file_path, "r", encoding="utf-8") as f:file_content = json.dumps(json.load(f), indent=4, ensure_ascii=False)elif file_extension == '.pdf':file_content = ""with fitz.open(file_path) as pdf_document:for page_num in range(pdf_document.page_count):page = pdf_document[page_num]file_content += page.get_text() + "\n"elif file_extension == '.docx':file_content = ""document = Document(file_path)for paragraph in document.paragraphs:file_content += paragraph.text + "\n"elif file_extension == '.md' or file_extension == '.py':with open(file_path, "r", encoding="utf-8") as f:file_content = f.read()else:file_content = "格式不支持,请更换文件!"return file_contentres=get_file_content('/home/use_Agent_project/黑神话悟空.txt')
print(res)2.3、uuid+文本名称+文本内容
import os
from typing import List, Union
from fastapi import UploadFiledef files_rag(files: List[Union[str, UploadFile]], uuid: str) -> str:"""处理文件集合并返回格式化内容Args:files: 文件列表,可以是文件路径字符串或UploadFile对象uuid: 用于创建唯一存储目录的标识符Returns:str: 格式化后的文档内容字符串"""# 定义存储路径kb_file_storage_path = os.path.join("./temp/data", uuid)result = []# 确保存储目录存在os.makedirs(kb_file_storage_path, exist_ok=True)# 处理文件上传或路径if files:for file in files:if isinstance(file, UploadFile):# 处理上传文件file_path = os.path.join(kb_file_storage_path, file.filename)with open(file_path, "wb") as f:f.write(file.file.read())elif isinstance(file, str):# 处理文件路径if os.path.isfile(file):filename = os.path.basename(file)file_path = os.path.join(kb_file_storage_path, filename)with open(file_path, "wb") as f_out, open(file, "rb") as f_in:f_out.write(f_in.read())else:print(f"文件不存在: {file}")continueelse:print(f"不支持的文件类型: {type(file)}")continue# 遍历目录中的所有文件并读取内容for filename in os.listdir(kb_file_storage_path):file_path = os.path.join(kb_file_storage_path, filename)if os.path.isfile(file_path):try:file_content = get_file_content(file_path)result.append(f"document: {file_path}\ncontent: {file_content}\n")except Exception as e:print(f"处理文件 {filename} 时出错: {str(e)}")continuereturn "\n".join(result)# 使用示例
if __name__ == "__main__":# 使用文件路径rest = files_rag(['/home/use_Agent_project/黑神话悟空.txt'], 'uuid123')print(rest)# 使用UploadFile对象(需要实际运行FastAPI)# from fastapi import UploadFile# with open('/home/use_Agent_project/黑神话悟空.txt', 'rb') as f:# upload_file = UploadFile(filename="黑神话悟空.txt", file=f)# rest = files_rag([upload_file], 'uuid456')# print(rest)三、Agent工具
在Langchain中,Agent代理是一种智能化的计算机制,它能够根据输入的指令或环 境上下文,动态选择和调用特定的工具(如搜索引擎、数据库、API等)来完成任 务。 这种代理通过预先定义的逻辑流程或者学习到的策略,帮助开发者实现自动化、动态 化和上下文敏感的计算与决策。
3.1、天气查询
心知天气:心知天气 - 高精度气象数据 - 天气数据API接口 - 行业气象解决方案
# 心知天气API工具类
import requests
from pydantic import Field
TIME_OUT = 60
class WeatherCheck:city: str = Field(description="City name,include city and county")def __init__(self, api_key):self.api_key = api_keydef run(self, city):city = city.split('\n')[0] # 清除多余的\n不然API会报错。url = f"https://api.seniverse.com/v3/weather/now.json?key={self.api_key}&location={city}&language=zh-Hans&unit=c"# 发送请求到心知天气API# print(url)response = requests.get(url, timeout=TIME_OUT)# print(response.status_code)# 如果请求成功,解析返回数据if response.status_code == 200:data = response.json()# 获取天气信息weather = data['results'][0]['now']['text']temperature = data['results'][0]['now']['temperature']return f"{city}的天气是{weather},温度为{temperature}°C"else:return f"错误码: {response.status_code}, 无法获取{city}的天气信息"weather_check = WeatherCheck("SfYdoqNuCW39UQUvb")print(weather_check.run('北京'))北京的天气是雾,温度为30°C
3.2、联网搜索
地址:https://serpapi.com/
# 网络搜索API工具类
import requests
from pydantic import Field
TIME_OUT=60
class WebSearch:query: str = Field(description="需要网上查找的内容")def __init__(self, api_key):# 初始化函数,用于创建类的实例self.api_key = api_keydef run(self, query):base_url = "https://serpapi.com/search"params = {"q": query,"api_key": self.api_key,"engine": "baidu","rn": 5, # 检索结果前5个"proxy": "http://api.wlai.vip" # 代理(用了这个好像不会减使用次数)}# 发送请求到网络搜索API# print(url)response = requests.get(base_url, params=params, timeout=TIME_OUT)# print(response.status_code)# 如果请求成功,解析返回数据if response.status_code == 200:data = response.json()print(data)organic_results = data['organic_results'][0]['related_news'] if data['organic_results'][0].get('related_news') else data['organic_results']# 获取网络信息results = "".join([f"titles:\n{result.get('title', '')} \nlinks:\n{result.get('link', '')}\nsnippets:\n{result.get('snippet', '')}\n" for result in organic_results])return resultselse:return f"无法获取{query}的信息"web_search = WebSearch("0c38eac10d9b5c03b6007ece56f6c84372cdf86358e5c780fc4b87ae471ff582")
print(web_search.run('王者荣耀韩信出装'))3.3、时间服务
from datetime import datetimeclass Get_time:def run(self, text: str):# 获取当前时间,格式为 年-月-日 小时:分钟:秒current_time = datetime.now().strftime("%Y-%m-%d %H:%M:%S")return current_timeget_time = Get_time()print(get_time.run(text=''))
3.4、代码执行
# 导入必要的库
import base64 # 用于Base64编解码(处理图像数据)
import os # 操作系统接口(文件路径处理)
import re # 正则表达式(清理代码)
from uuid import uuid4 # 生成唯一文件名
from codeboxapi import CodeBox # 代码沙箱执行环境MEDIA_DIR = 60 # 建议改为:MEDIA_DIR = "media"class CodeInterpreter:"""代码解释器类,用于执行Python代码并处理输出"""def __init__(self):"""初始化方法"""self.output_files = "" # 存储输出文件路径(如图像)self.output_codes = "" # 存储执行的原始代码self.codebox = CodeBox(api_key="local") # 创建本地代码沙箱实例self.codebox.start() # 启动沙箱环境def get_outputs(self):"""获取输出结果的方法返回:tuple: (output_files, output_codes) 输出文件路径和原始代码"""return self.output_files, self.output_codesdef run(self, code: str):"""执行代码的核心方法参数:code (str): 要执行的Python代码(可能包含Markdown代码块标记)返回:str: 执行结果文本或图像保存确认信息"""# 清理代码:移除Markdown代码块标记(```python等)clean_code = re.sub(r'(```python|```py|```)\s*', '', code, flags=re.IGNORECASE)clean_code = clean_code.strip() # 移除首尾空白字符# 移除空行并重新组合lines = [line for line in clean_code.split('\n') if line.strip()]cleaned_code = '\n'.join(lines)# 在沙箱中执行清理后的代码output = self.codebox.run(cleaned_code)# 处理图像类型输出if output.type == "image/png":# 生成唯一文件名filename = f"{MEDIA_DIR}/image-{uuid4()}.png"# Base64解码图像数据decoded_image = base64.b64decode(output.content)# 写入媒体文件(注意:MEDIA_DIR需要是有效目录)try:with open(filename, 'wb') as file:file.write(decoded_image)except Exception as e:return f"文件保存失败: {str(e)}"# 生成可访问的URL路径image_url = f"/media/{os.path.basename(filename)}"# 保存输出记录self.output_files = image_urlself.output_codes = codereturn "已生成图像并发送给用户"else:# 返回文本类型输出return output.content# 使用示例
if __name__ == "__main__":code_interpreter = CodeInterpreter()text = '''print(1+1)'''res = code_interpreter.run(text)print(res) # 输出执行结果| 组件 | 作用 |
|---|---|
CodeBox | 提供安全的代码执行沙箱(类似Docker容器) |
正则清理clean_code | 去除Markdown代码块标记(```python等),确保纯代码执行 |
base64处理 | 解码图像输出(常见于matplotlib等库的图形渲染场景) |
| 文件管理 | 自动保存图像到MEDIA_DIR并生成可访问URL |

3.5、定义工具
from langchain_core.tools import Tool
from tools.code_interpreter import code_interpreter
from tools.weather_check import weather_check
from tools.web_search import web_search
from tools.get_time import get_time# 将API工具封装成Langchain的Tool对象
tools = [Tool(name="weather check",func=weather_check.run,description="获取当前地点或指定城市的实时天气信息,包括温度、天气状况等。"),Tool(name="web search",func=web_search.run,description="通过网络搜索获取最新资讯、回答问题或查找特定主题的相关内容。"),Tool(name="get time",func=get_time.run,description="获取当前时间。输入应始终为空字符串"),Tool(name="code interpreter",func=code_interpreter.run,description="一个Python shell。使用它来执行python代码。输入应该是一个有效的python代码字符串。在与开头引号相同的行开始编写代码。不要以换行开始你的代码。"),
]
四、提示模板
PROMPT_TEMPLATES = {"agent": 'Answer the following questions as best you can. If it is in order, you can use some tools and knowledgebases ''appropriately. ''You have access to the following tools:\n\n''{tools}\n\n''You have access to the following knowledge bases:\n\n''{knowledgebases}\n\n''You have the following documents:\n\n''{documents}\n\n''Use the following format:\n''Question: the input question you must answer\n''Thought: you should always think about what to do and what tools to use.\n''Action: the action to take, should be one of [{tool_names}]\n''Action Input: the input to the action\n''Observation: the result of the action\n''... (this Thought/Action/Action Input/Observation can be repeated zero or more times)\n''Thought: I now know the final answer\n''Final Answer: the final answer to the original input question\n''Begin!\n\n''History: {history}\n\n''Question: {input}\n\n''Thought: {agent_scratchpad}\n',
}五、fastapi后端响应
5.1、agent_chat后端构建
import json
import asyncio
import os
from ast import literal_eval
from uuid import uuid4
from fastapi import APIRouter, UploadFile, Form
from fastapi.responses import StreamingResponse
from tools.tools_select import tools
from typing import List, AsyncIterable
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain.agents import create_react_agent, AgentExecutor
from langchain.prompts import SystemMessagePromptTemplate, HumanMessagePromptTemplate
from configs.prompt import PROMPT_TEMPLATES
from configs.setting import chat_model_name, api_key, base_url, TIME_OUT, TEMP_FILE_STORAGE_DIR
from utils.callback import CustomAsyncIteratorCallbackHandler
from tools.code_interpreter import code_interpreter
from utils.load_docs import files_rag# 初始化FastAPI路由
chat_router = APIRouter(prefix="/chat", tags=["Chat 对话"])@chat_router.post("/agent_chat")
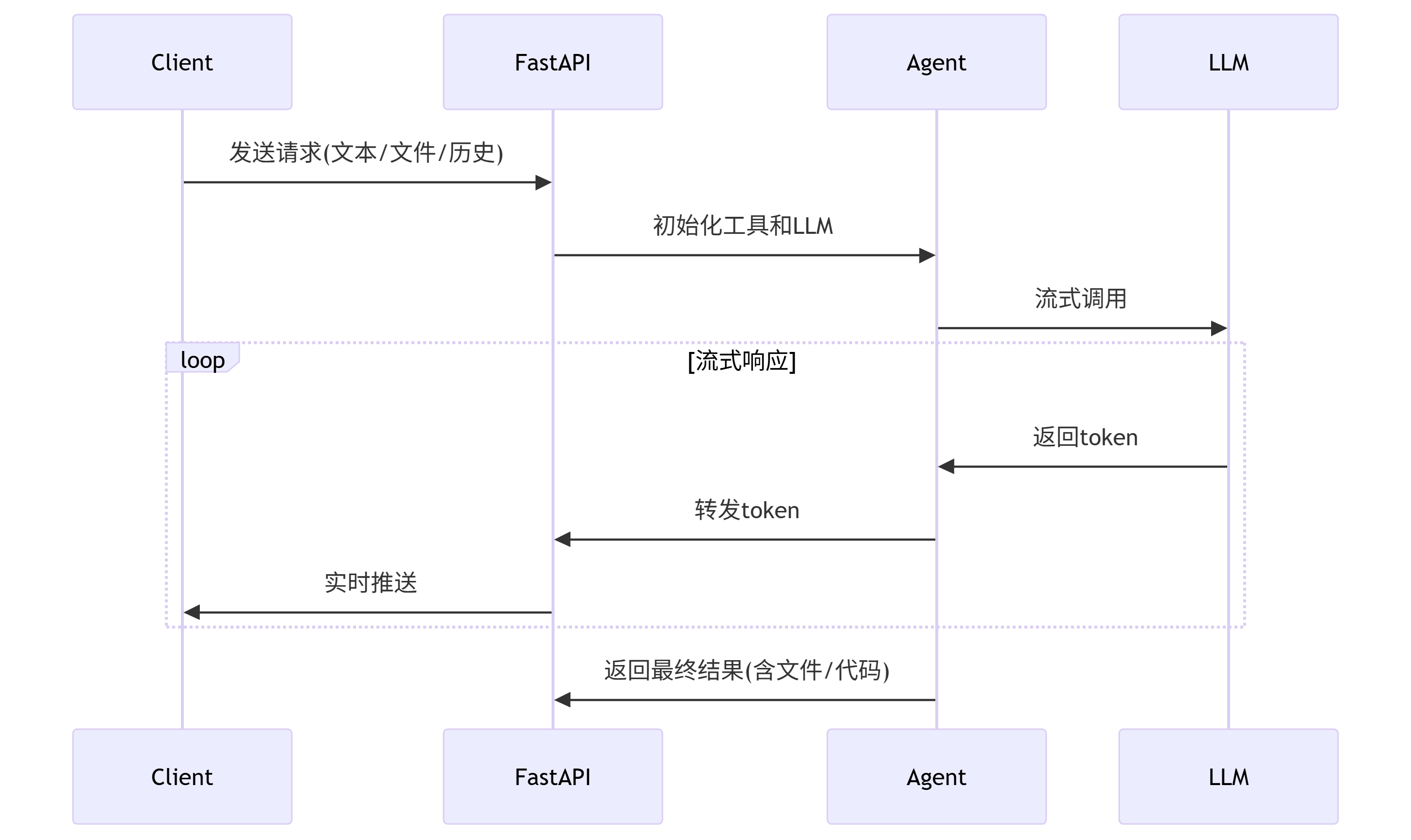
async def agent_chat(files: List[UploadFile] = None,query: str = Form(..., description="用户输入"),sys_prompt: str = Form("You are a helpful assistant.", description="系统提示"),history_len: int = Form(-1, description="保留历史消息的数量"),history: List[str] = Form([], description="历史对话"),temperature: float = Form(0.5, description="LLM采样温度"),max_tokens: int = Form(1024, description="LLM最大token数配置"),session_id: str = Form(None, description="会话标识"),
):"""Agent对话接口核心逻辑:1. 处理上传文件并提取文本内容2. 加载历史对话3. 初始化LLM和Agent4. 流式返回响应"""# 1. 文件处理try:documents = files_rag(files, session_id if session_id else str(uuid4()))except Exception as e:documents = f"文件处理错误: {str(e)}"# 2. 历史消息处理try:history = [literal_eval(item) for item in history]except (ValueError, SyntaxError):history = []# 控制历史记录长度histories = ""if history_len > 0:history = history[-2 * history_len:] # 每条记录含role和content两个元素# 格式化历史消息for msg in history:role = msg.get('role', 'unknown')content = msg.get('content', '')histories += f"{role}:{content}\n\n"async def agent_chat_iterator() -> AsyncIterable[str]:"""流式响应生成器"""# 初始化回调处理器callback = CustomAsyncIteratorCallbackHandler()callbacks = [callback]# 3. 初始化LLMchat_model = ChatOpenAI(model=chat_model_name,api_key=api_key,base_url=base_url,temperature=temperature,max_tokens=max_tokens,streaming=True,callbacks=callbacks)# 4. 构建提示模板system_prompt = SystemMessagePromptTemplate.from_template(sys_prompt)human_prompt = HumanMessagePromptTemplate.from_template(PROMPT_TEMPLATES["agent"] # 使用ReAct模板)chat_prompt = ChatPromptTemplate.from_messages([system_prompt, human_prompt])# 5. 创建Agentagent = create_react_agent(chat_model,tools,chat_prompt,stop_sequence=["\nObservation:"] # 修正停止标记)agent_executor = AgentExecutor.from_agent_and_tools(agent=agent,tools=tools,verbose=True,)# 6. 执行Agent任务code_interpreter.output_files, code_interpreter.output_codes = "", ""task = asyncio.create_task(agent_executor.acall(inputs={"input": query,"history": histories,"documents": documents}))# 7. 流式输出async for token in callback.aiter():yield json.dumps({"answer": token}).encode('utf-8')# 8. 处理代码解释器输出await asyncio.wait_for(task, TIME_OUT)output_files, output_codes = code_interpreter.get_outputs()if output_files:yield json.dumps({"answer": f'\n\n{output_codes}\n\n'}).encode('utf-8')elif output_codes:yield json.dumps({"answer": f'\n\n{output_codes}'}).encode('utf-8')return StreamingResponse(agent_chat_iterator(), media_type="application/json")5.2、主程序
from fastapi import FastAPI
from fastapi.middleware.cors import CORSMiddleware
from chat.chat_routes import chat_router
from fastapi.staticfiles import StaticFiles
from configs.setting import MEDIA_DIR# 创建FastAPI实例
app = FastAPI()# 允许跨域请求
app.add_middleware(CORSMiddleware,allow_origins=["*"],allow_credentials=True,allow_methods=["*"],allow_headers=["*"],
)# 挂载路由
app.include_router(chat_router)# 挂载静态文件目录
app.mount("/media", StaticFiles(directory=MEDIA_DIR), name="media")# 程序主入口
if __name__ == "__main__":# 导入unicorn服务器的包import uvicorn# 运行服务器uvicorn.run(app, host="127.0.0.1", port=6605, log_level="info")










之ForwardAdd(简化版))





行为型:模板方法模式详解)


