1. cuda介绍
CUDA(Compute Unified Device Architecture,统一计算设备架构)是NVIDIA推出的一种并行计算平台和编程模型。它允许开发者利用NVIDIA GPU的强大计算能力来加速计算密集型任务。CUDA通过提供一套专门的API和编程接口,使得开发者能够编写在GPU上运行的程序,从而实现大规模并行计算。
首先来看我们的 CUDA 程序代码:
#include <stdio.h>
#include <iostream>
#include <cuda_runtime.h>
using namespace std;__global__ void hello_world(void) {printf("thread idx: %d\n", threadIdx.x);if (threadIdx.x == 0) {printf("GPU: hello_world\n");}
}int main(void) {printf("CPU: Hello world!\n");hello_world<<<1, 32>>>();cudaDeviceSynchronize();cudaError_t err = cudaGetLastError();if (err != cudaSuccess) {cerr << "CUDA error: " << cudaGetErrorString(err) << endl;} else { cout << "GPU: Hello world finished!" << endl; }cout << "CPU: Hello world finished!" << endl;return 0;
}这个程序虽然简单,却包含了 CUDA 编程的多个核心要素,让我们逐一解析。
1. CUDA 程序的特殊头文件与命名空间
CUDA(Compute Unified Device Architecture,统一计算设备架构)是NVIDIA推出的一种GPU编程组件,它是一种原生支持GPU编程的软硬件架构。CUDA突破了过去必须通过图形API来使用GPU计算能力的限制,使得开发者可以直接在GPU上编写和执行通用计算程序。以下是CUDA技术栈的分层结构及其主要组成部分:
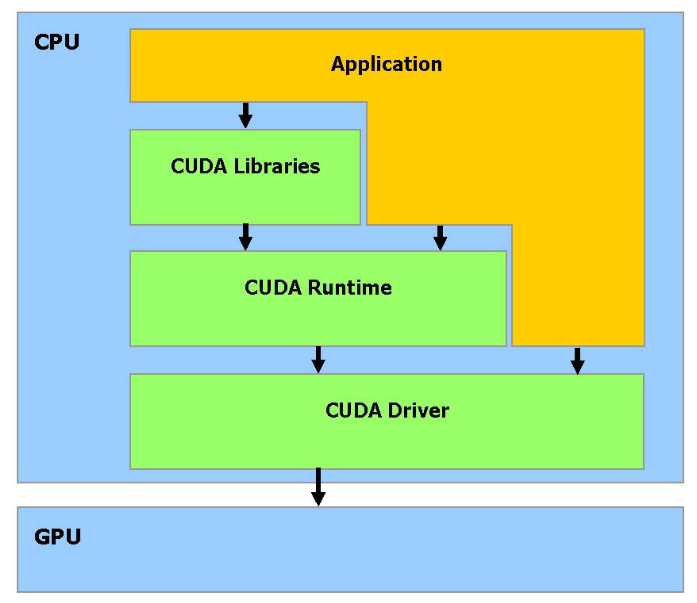
硬件驱动层(CUDA Driver)
功能:负责与GPU硬件通信,提供底层支持。
作用:作为硬件与软件之间的桥梁,确保CUDA程序能够正确地与GPU硬件交互。
应用编程接口(API)与运行时(Runtime)
功能:为开发者提供简洁易用的编程接口和执行环境。
作用:简化开发流程,使得开发者可以更高效地编写和运行CUDA程序。
CUDA工具链中的核心组件之一,专门用于编译含有CUDA C/C++扩展语法的源代码文件(通常以.cu为扩展名)。编译时需要使用nvcc hello_world.cu -o hello_world进行编译
- #include <cuda_runtime.h>:这是 CUDA 运行时 API 的头文件,包含了 CUDA 编程所需的各种函数声明和数据类型定义,是 CUDA 程序必不可少的头文件。
- 标准 C++ 头文件:stdio.h和iostream用于 CPU 端的输入输出操作,CUDA 程序可以无缝结合 C++ 标准库使用。
2. 核函数(Kernel Function)
核函数是 CUDA 编程中最核心的概念,是在 GPU 上执行的函数,代码中:
__global__ void hello_world(void)
- __global__:这是 CUDA 特有的函数修饰符,表明该函数是核函数。核函数有以下特点:
- 在 CPU 上调用,在 GPU 上执行
- 返回类型必须为 void
- 可以通过特殊的执行配置符指定启动的线程数量
3. 核函数的调用方式
核函数的调用方式与普通函数不同,需要使用特殊的执行配置符:
hello_world<<<1, 32>>>();<<<...>>>:这是 CUDA 特有的执行配置符,用于指定在 GPU 上启动的线程数量和组织方式
- 第一个参数1:表示启动 1 个线程块(block)
- 第二个参数32:表示每个线程块包含 32 个线程(thread)
- 因此,这个配置总共在 GPU 上启动了 1×32=32 个线程并行执行
4. 线程的标识与索引
在核函数中,我们可以通过threadIdx变量获取当前线程在其所属线程块中的索引:
printf("thread idx: %d\n", threadIdx.x);
- threadIdx:是一个uint3类型的结构体,包含三个成员:x、y、z,分别表示线程在三维线程块中的三个维度上的索引
- 为什么设计成三维?这是因为许多实际问题(如 3D 图形渲染、三维物理模拟等)具有天然的三维特性,三维索引可以更自然地映射这些问题
- 在这个例子中,我们只使用了一维索引threadIdx.x,表示线程在 x 维度上的索引(范围 0-31)
5. CPU 与 GPU 的同步机制
由于 CPU 和 GPU 是独立的处理器,它们的执行是异步的。为了确保 CPU 等待 GPU 完成计算后再继续执行,需要使用同步函数:
cudaDeviceSynchronize();
- 这个函数会阻塞 CPU 的执行,直到 GPU 完成所有之前提交的计算任务
- 同步操作对于确保数据一致性和正确的执行顺序非常重要
6. CUDA 错误处理机制
CUDA 操作可能会出现各种错误,良好的错误处理是编写健壮 CUDA 程序的关键:
cudaError_t err = cudaGetLastError();if (err != cudaSuccess) {cerr << "CUDA error: " << cudaGetErrorString(err) << endl;}- cudaGetLastError():获取最近一次 CUDA 操作产生的错误代码
- cudaError_t:CUDA 错误类型,cudaSuccess表示操作成功
- cudaGetErrorString():将错误代码转换为人类可读的错误信息
程序执行流程与结果分析
当我们编译并运行这个程序时,会得到类似以下的输出:
CPU: Hello world!
thread idx: 0
thread idx: 1
thread idx: 2
thread idx: 3
thread idx: 4
thread idx: 5
thread idx: 6
thread idx: 7
thread idx: 8
thread idx: 9
thread idx: 10
thread idx: 11
thread idx: 12
thread idx: 13
thread idx: 14
thread idx: 15
thread idx: 16
thread idx: 17
thread idx: 18
thread idx: 19
thread idx: 20
thread idx: 21
thread idx: 22
thread idx: 23
thread idx: 24
thread idx: 25
thread idx: 26
thread idx: 27
thread idx: 28
thread idx: 29
thread idx: 30
thread idx: 31
GPU: hello_world
GPU: Hello world finished!
CPU: Hello world finished!- 首先 CPU 输出 "CPU: Hello world!"
- 然后启动 32 个 GPU 线程并行执行核函数
- 每个线程输出自己的索引值,其中索引为 0 的线程还会额外输出 "GPU: hello_world"
- 所有 GPU 线程执行完成后,CPU 输出执行完成的信息
需要注意的是,GPU 线程的执行顺序是不确定的,因此线程索引的输出顺序可能每次运行都不同,这体现了并行计算的特性。
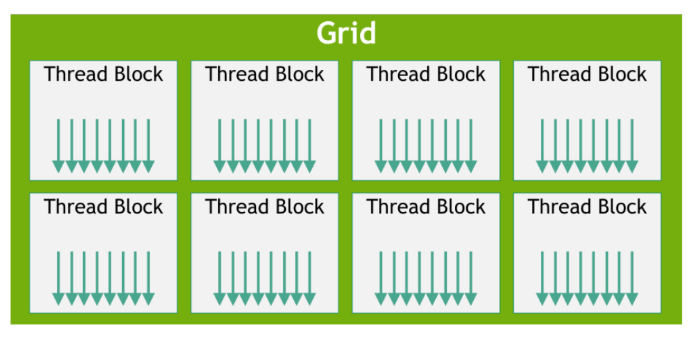
2. CUDA线程分层结构与执行模型
在CUDA的执行模型中,线程是CUDA中最小的执行单元。多个线程可以组织成一个线程块(Thread Block),而多个线程块又组成一个网格(Grid)。
线程块中的线程数量是有限制的,因为同一个线程块内的所有线程必须运行在同一个流多处理器(Streaming Multiprocessor, SM)上,并共享该SM的有限资源(如寄存器、共享内存等)。
线程块中的线程会以32个线程为一组进行调度(调度的时候受限于一个SM中的可用资源),这组线程被称为线程束(Warp)。
线程束(Warp)是SM中最基本的执行单元。当一个线程块被启动后,其中的所有线程会被划分成多个线程束,每个线程束包含32个线程。同一warp中的线程会同时执行相同的指令,但各自处理不同的数据,从而实现数据并行计算。
从执行模型中软硬件的对应关系来看,我们可以清晰地看到前面介绍的三级线程分层结构:线程(Thread)→线程块(Block)→网格(Grid)。
示例:
#include <cstdio>
#define BLOCK_SIZE 256__global__ void vecAdd(int *A, int *B, int *C, int n) {int i = blockIdx.x * blockDim.x + threadIdx.x;if (i < n) {C[i] = A[i] + B[i];}
}int main() {int N = 10000;size_t size = N * sizeof(int);// 主机内存分配与初始化int *A = (int*)malloc(size);int *B = (int*)malloc(size);int *C = (int*)malloc(size);for (int i = 0; i < N; i++) {A[i] = i;B[i] = i * i; // 修正幂运算错误}// 设备内存分配int *d_A, *d_B, *d_C;cudaMalloc((void**)&d_A, size);cudaMalloc((void**)&d_B, size);cudaMalloc((void**)&d_C, size);// 主机到设备的数据拷贝cudaMemcpy(d_A, A, size, cudaMemcpyHostToDevice);cudaMemcpy(d_B, B, size, cudaMemcpyHostToDevice);// 计算线程块数量并启动核函数int Num_Blocks = (N + BLOCK_SIZE - 1) / BLOCK_SIZE;vecAdd<<<Num_Blocks, BLOCK_SIZE>>>(d_A, d_B, d_C, N);cudaDeviceSynchronize(); // 等待GPU完成计算// 设备到主机的数据拷贝(修正方向错误)cudaMemcpy(C, d_C, size, cudaMemcpyDeviceToHost);// 结果验证for (int i = 0; i < N; i++) {if (C[i] != A[i] + B[i]) {printf("Error index: %d, Expected: %d, Got: %d.\n", i, A[i]+B[i], C[i]);}}printf("Vector addition completed successfully.\n");// 资源释放free(A);free(B);free(C);cudaFree(d_A);cudaFree(d_B);cudaFree(d_C);return 0;
}程序功能与整体架构
这段代码实现了两个向量的逐元素加法(C [i] = A [i] + B [i]),其中:
- 向量长度 N=10000
- 使用 CPU 初始化输入数据(A [i]=i,B [i]=i²)
- 通过 GPU 并行计算实现向量加法
- 最后在 CPU 端验证计算结果
程序采用了 CUDA 编程的标准流程:主机初始化→数据传输→GPU 计算→结果回传→验证释放,这一流程是所有 CUDA 应用的基础框架。
核心技术点详解
1. CUDA 内存模型与数据传输
CUDA 采用异构内存模型,CPU(主机)和 GPU(设备)拥有各自独立的内存空间,程序中清晰体现了这一特性:
// 主机内存分配(CPU可访问)
int *A = (int*)malloc(size);
int *B = (int*)malloc(size);
int *C = (int*)malloc(size);// 设备内存分配(仅GPU可访问)
int *d_A, *d_B, *d_C;
cudaMalloc((void**)&d_A, size);
cudaMalloc((void**)&d_B, size);
cudaMalloc((void**)&d_C, size);- malloc:分配主机内存(Host Memory)
- cudaMalloc:分配设备内存(Device Memory),注意其特殊的指针地址传递方式(void**)&d_A
数据传输通过cudaMemcpy实现,需要明确指定传输方向:
// 主机到设备(Host → Device)
cudaMemcpy(d_A, A, size, cudaMemcpyHostToDevice);
cudaMemcpy(d_B, B, size, cudaMemcpyHostToDevice);// 设备到主机(Device → Host)
cudaMemcpy(C, d_C, size, cudaMemcpyDeviceToHost);cudaMemcpy的参数遵循目标地址→源地址的顺序,这是容易出错的关键点,必须与传输方向参数匹配。
2. 线程组织与索引计算
CUDA 通过网格(Grid)- 线程块(Block)- 线程(Thread) 的三级结构组织并行线程,这段代码展示了一维线程组织的典型方式:
// 定义每个线程块的线程数量#define BLOCK_SIZE 256// 计算所需线程块数量int Num_Blocks = (N + BLOCK_SIZE - 1) / BLOCK_SIZE;// 启动核函数时指定线程组织方式vecAdd<<<Num_Blocks, BLOCK_SIZE>>>(d_A, d_B, d_C, N);核函数内部通过以下公式计算全局线程索引:
int i = blockIdx.x * blockDim.x + threadIdx.x;- blockIdx.x:线程块在网格中的索引(0 到 Num_Blocks-1)
- blockDim.x:每个线程块的线程数(即 BLOCK_SIZE)
- threadIdx.x:线程在所属线程块中的索引(0 到 BLOCK_SIZE-1)
这种索引计算方式是 CUDA 一维问题的标准模式,通过组合块索引和线程索引,为每个线程分配唯一的全局索引。
3.显存分层结构和管理(存储模型)
在 CUDA 编程中,寄存器、共享显存和全局显存是我们最常关注的三种显存层级。它们构成了 GPU 内存层次结构的核心,在存储容量与访问速度方面呈现出典型的层级特性:
从容量来看:寄存器的容量最小,共享显存次之,全局显存拥有最大的存储空间。
从访问速度来看:寄存器访问速度最快,共享显存次之,全局显存相对较慢。
此外,这三种内存的可见范围(作用域)也逐级扩大:
寄存器是线程私有的内存空间,只能被当前线程访问,通常用于存储核函数中的临时变量;
共享显存由同一个线程块内的所有线程共享,是实现线程间协作的关键机制;
全局显存的作用范围覆盖整个设备,平时我们所说的显卡显存容量(如多少GB),指的就是全局显存,它可以被所有线程访问。
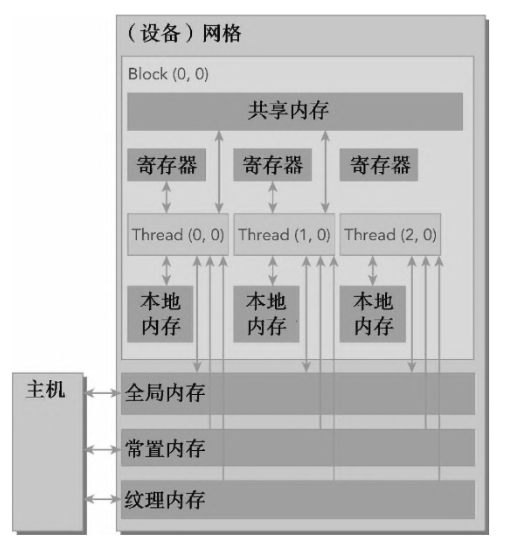

4.利用共享显存优化Cuda核函数
每个流式多处理器(SM)都包含一小块低延迟的内存池,称为共享显存(Shared Memory)。这块内存被当前在该 SM 上执行的线程块(block)中的所有线程所共享,是实现线程间高效通信与协作的关键资源。
与全局显存(Global Memory)相比,共享显存具有显著的优势(片上和片外的区别):其访问延迟大约低 20~30 倍,带宽则高出约 10 倍。因此,在并行计算中合理利用共享显存,可以大幅提高程序的性能和效率。
示例:
归约(Reduction)是并行计算中最基础也最核心的操作之一,它通过将大规模数据逐步聚合为单一结果(如求和、求最值),广泛应用于科学计算、数据分析等领域。本文将通过一段对比全局内存与共享内存归约的 CUDA 代码,深入解析 GPU 并行归约的实现原理、核心技术点及性能优化逻辑。
归约的本质是 “多对一” 的聚合操作。例如对数组[a0, a1, a2, ..., an-1]求和,串行逻辑是sum = a0 + a1 + ... + an-1,但在 GPU 上,我们可以让多个线程同时工作:每个线程处理部分元素,通过多轮合并最终得到总和。
这段代码实现了两种归约方案:
- 基于全局内存的归约(
reduceGmem):直接操作 GPU 全局内存进行数据合并; - 基于共享内存的归约(
reduceSmem):先将数据加载到 GPU 共享内存(更快的片上内存),再进行合并。
通过对比两者的性能,我们能直观理解 GPU 内存层次对程序效率的影响。
#include <iostream>
#include <cstdlib> // 用于动态内存分配
#define BLOCK_SIZE 1024 // 线程块大小,需与归约逻辑匹配// 方法1:基于全局内存的归约
__global__ void reduceGmem(int *g_idata, int *g_odata, int n) {// 线程块内索引(关键修正:使用块内索引而非全局索引)unsigned int tid = threadIdx.x;// 定位当前线程块处理的数据段起始地址int *idata = g_idata + blockIdx.x * blockDim.x;// 边界检查:若当前线程处理的全局索引超出数据范围,直接返回if (blockIdx.x * blockDim.x + tid >= n)return;// 归约阶段1:1024→512(仅当块大小≥1024时执行)if (blockDim.x >= 1024 && tid < 512) {idata[tid] += idata[tid + 512];}__syncthreads(); // 块内同步,确保数据更新完成// 归约阶段2:512→256if (blockDim.x >= 512 && tid < 256) {idata[tid] += idata[tid + 256];}__syncthreads();// 归约阶段3:256→128if (blockDim.x >= 256 && tid < 128) {idata[tid] += idata[tid + 128];}__syncthreads();// 归约阶段4:128→64if (blockDim.x >= 128 && tid < 64) {idata[tid] += idata[tid + 64];}__syncthreads();// 最终阶段:64→1(利用warp内隐式同步)if (tid < 32) {volatile int *vmem = idata; // 修正:添加int类型vmem[tid] += vmem[tid + 32];vmem[tid] += vmem[tid + 16];vmem[tid] += vmem[tid + 8];vmem[tid] += vmem[tid + 4];vmem[tid] += vmem[tid + 2];vmem[tid] += vmem[tid + 1];}// 每个线程块的0号线程保存归约结果if (tid == 0) {g_odata[blockIdx.x] = idata[0];}
}// 方法2:基于共享内存的归约(补充完整逻辑)
__global__ void reduceSmem(int *g_idata, int *g_odata, int n) {__shared__ int smem[BLOCK_SIZE]; // 共享内存大小与线程块大小一致(关键修正)unsigned int tid = threadIdx.x;unsigned int global_tid = blockIdx.x * blockDim.x + tid;// 1. 加载数据到共享内存(带边界检查)smem[tid] = (global_tid < n) ? g_idata[global_tid] : 0;__syncthreads();// 2. 共享内存内归约(与全局内存归约逻辑类似,但访问更快)if (blockDim.x >= 1024 && tid < 512) {smem[tid] += smem[tid + 512];}__syncthreads();if (blockDim.x >= 512 && tid < 256) {smem[tid] += smem[tid + 256];}__syncthreads();if (blockDim.x >= 256 && tid < 128) {smem[tid] += smem[tid + 128];}__syncthreads();if (blockDim.x >= 128 && tid < 64) {smem[tid] += smem[tid + 64];}__syncthreads();// 最终阶段归约if (tid < 32) {volatile int *vmem = smem;vmem[tid] += vmem[tid + 32];vmem[tid] += vmem[tid + 16];vmem[tid] += vmem[tid + 8];vmem[tid] += vmem[tid + 4];vmem[tid] += vmem[tid + 2];vmem[tid] += vmem[tid + 1];}// 3. 保存每个线程块的归约结果if (tid == 0) {g_odata[blockIdx.x] = smem[0];}
}int main() {const int N = 102400; // 数据规模int *h_data = new int[N]; // 主机内存(动态分配,避免栈溢出)// 初始化主机数据(0到N-1的累加和,用于后续验证)for (int i = 0; i < N; i++) {h_data[i] = i;}// 设备内存分配int *d_idata, *d_odata1, *d_odata2;cudaMalloc((void**)&d_idata, sizeof(int) * N);cudaMalloc((void**)&d_odata1, sizeof(int) * ((N + BLOCK_SIZE - 1) / BLOCK_SIZE)); // 存储方法1的部分和cudaMalloc((void**)&d_odata2, sizeof(int) * ((N + BLOCK_SIZE - 1) / BLOCK_SIZE)); // 存储方法2的部分和// 主机→设备数据拷贝cudaMemcpy(d_idata, h_data, sizeof(int) * N, cudaMemcpyHostToDevice);// 计算线程块数量int num_blocks = (N + BLOCK_SIZE - 1) / BLOCK_SIZE;// 计时变量与事件cudaEvent_t start1, stop1, start2, stop2;cudaEventCreate(&start1);cudaEventCreate(&stop1);cudaEventCreate(&start2);cudaEventCreate(&stop2);// 测试基于全局内存的归约cudaEventRecord(start1);reduceGmem<<<num_blocks, BLOCK_SIZE>>>(d_idata, d_odata1, N); // 修正:使用<<<>>>cudaEventRecord(stop1);cudaEventSynchronize(stop1); // 等待计算完成// 测试基于共享内存的归约cudaEventRecord(start2);reduceSmem<<<num_blocks, BLOCK_SIZE>>>(d_idata, d_odata2, N); // 修正:核函数参数与名称匹配cudaEventRecord(stop2);cudaEventSynchronize(stop2);// 计算耗时float time1, time2;cudaEventElapsedTime(&time1, start1, stop1);cudaEventElapsedTime(&time2, start2, stop2);std::cout << "reduceGmem time: " << time1 << " ms" << std::endl;std::cout << "reduceSmem time: " << time2 << " ms" << std::endl;// 资源释放(关键修正:避免内存泄漏)delete[] h_data;cudaFree(d_idata);cudaFree(d_odata1);cudaFree(d_odata2);cudaEventDestroy(start1);cudaEventDestroy(stop1);cudaEventDestroy(start2);cudaEventDestroy(stop2);return 0;
}
1. 基于全局内存的归约(reduceGmem)
__global__ void reduceGmem(int *g_idata, int *g_odata, int n) {unsigned int tid = threadIdx.x; // 块内线程索引int *idata = g_idata + blockIdx.x * blockDim.x; // 当前块处理的数据段// 边界检查:避免访问超出数组范围的内存if (blockIdx.x * blockDim.x + tid >= n) return;// 多阶段归约:1024→512→256→...→1if (blockDim.x >= 1024 && tid < 512) idata[tid] += idata[tid + 512];__syncthreads();if (blockDim.x >= 512 && tid < 256) idata[tid] += idata[tid + 256];__syncthreads();if (blockDim.x >= 256 && tid < 128) idata[tid] += idata[tid + 128];__syncthreads();if (blockDim.x >= 128 && tid < 64) idata[tid] += idata[tid + 64];__syncthreads();// 最终阶段:利用warp内隐式同步if (tid < 32) {volatile int *vmem = idata; // 确保内存访问不被编译器优化vmem[tid] += vmem[tid + 32];vmem[tid] += vmem[tid + 16];vmem[tid] += vmem[tid + 8];vmem[tid] += vmem[tid + 4];vmem[tid] += vmem[tid + 2];vmem[tid] += vmem[tid + 1];}// 保存当前块的归约结果if (tid == 0) g_odata[blockIdx.x] = idata[0];
}关键设计思路:
- 数据划分:输入数组按线程块大小(
BLOCK_SIZE=1024)分成多个段,每个线程块处理一段数据,最终输出 “部分和”(每个块的结果)。 - 分阶段合并:通过 4 轮 “二分归约” 将 1024 个元素逐步缩减为 64 个,每轮只让前半线程参与(如
tid < 512处理tid与tid+512的合并),确保无重复计算。 - 线程同步:每轮合并后用
__syncthreads()阻塞块内所有线程,确保所有线程完成当前轮次后再进入下一轮(避免读取未更新的数据)。 - Warp 优化:最后 64→1 的合并仅用前 32 个线程(一个线程束,GPU 的基本执行单元),利用 warp 内线程的隐式同步(无需
__syncthreads()),同时用volatile防止编译器优化导致的内存访问错误。
注:
__syncthreads():线程块内的同步屏障,所有线程必须到达此函数后才能继续执行,用于避免 “先写后读” 的数据冲突(如线程 A 未写完数据,线程 B 就读取)。volatile关键字:在 warp 内操作时,强制编译器从内存而非寄存器读取数据,确保线程能获取到其他线程更新的最新值(warp 内线程无显式同步,依赖硬件执行一致性)。
2. 基于共享内存的归约(reduceSmem)
__global__ void reduceSmem(int *g_idata, int *g_odata, int n) {__shared__ int smem[BLOCK_SIZE]; // 共享内存:块内线程共享的片上内存unsigned int tid = threadIdx.x;unsigned int global_tid = blockIdx.x * blockDim.x + tid;// 步骤1:加载数据到共享内存(带边界检查)smem[tid] = (global_tid < n) ? g_idata[global_tid] : 0;__syncthreads();// 步骤2:共享内存内归约(逻辑与全局内存一致,但访问更快)if (blockDim.x >= 1024 && tid < 512) smem[tid] += smem[tid + 512];__syncthreads();if (blockDim.x >= 512 && tid < 256) smem[tid] += smem[tid + 256];__syncthreads();// ... 后续阶段与reduceGmem相同 ...// 步骤3:保存结果if (tid == 0) g_odata[blockIdx.x] = smem[0];
}与全局内存归约的核心差异:
- 引入共享内存:先将全局内存数据拷贝到
smem(共享内存),后续所有合并操作都在smem中进行。 - 性能优势:共享内存是 GPU 芯片上的高速缓存(访问延迟约为全局内存的 1/100),且支持线程块内的低延迟数据共享,大幅减少全局内存访问次数(全局内存是 GPU 性能瓶颈之一)。
运行程序后,通常会观察到reduceSmem的耗时显著低于reduceGmem,例如:
reduceGmem time: 30.91 ms
reduceSmem time: 0.018432 ms性能差异的核心原因:
- 全局内存的 “高延迟 + 低带宽利用率”:
reduceGmem每轮合并都需要访问全局内存,而全局内存的带宽利用率受访问模式限制(即使合并访问,效率仍低于共享内存)。 - 共享内存的 “低延迟 + 高复用”:
reduceSmem仅在加载阶段访问 1 次全局内存,后续合并全在共享内存中进行,且共享内存支持线程块内的高效数据复用。

)





)

:设计思路与实现原理(C/C++代码实现))
 條件指令、循環結構、定義函數)






:RecyclerView 多类型布局与数据刷新实战)
)
