- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊
一、准备工作
1.1导入数据
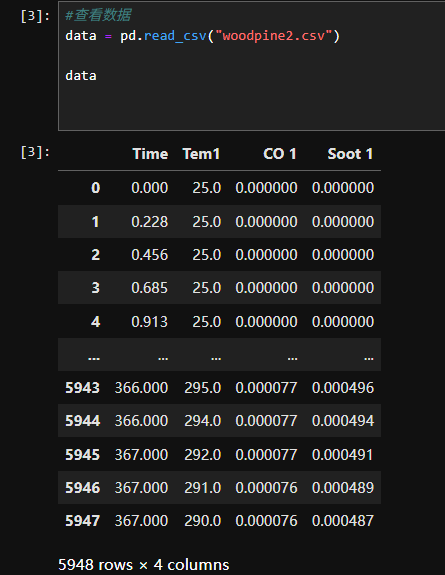
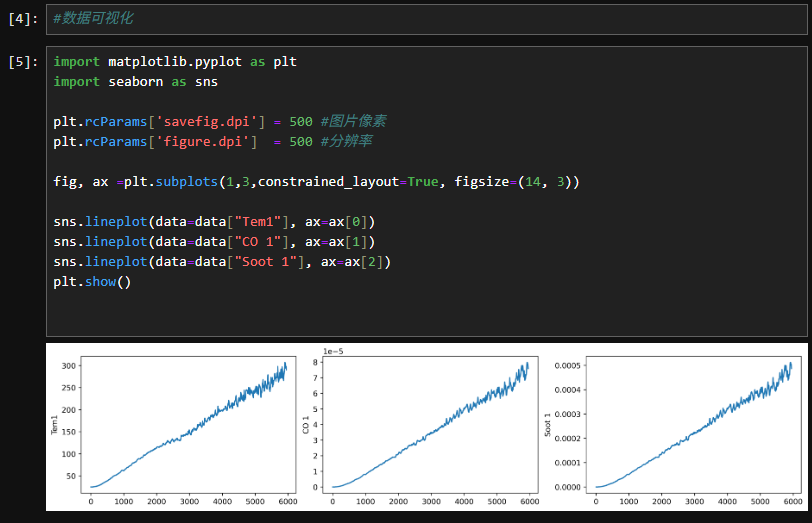
1.2数据集可视化
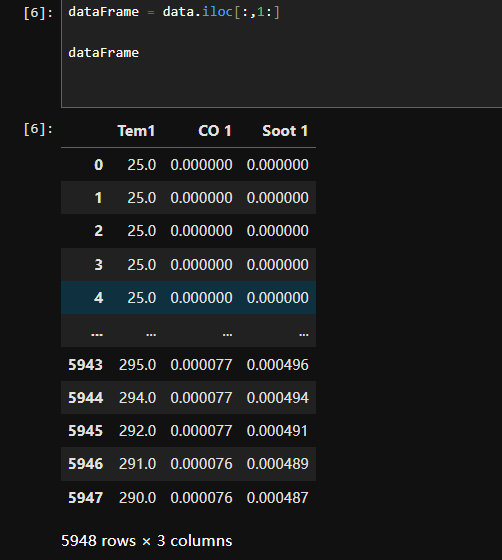
二、构建数据集
2.1数据集预处理
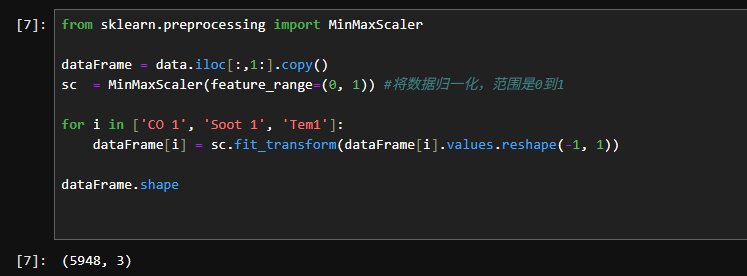
2.2设置X、Y
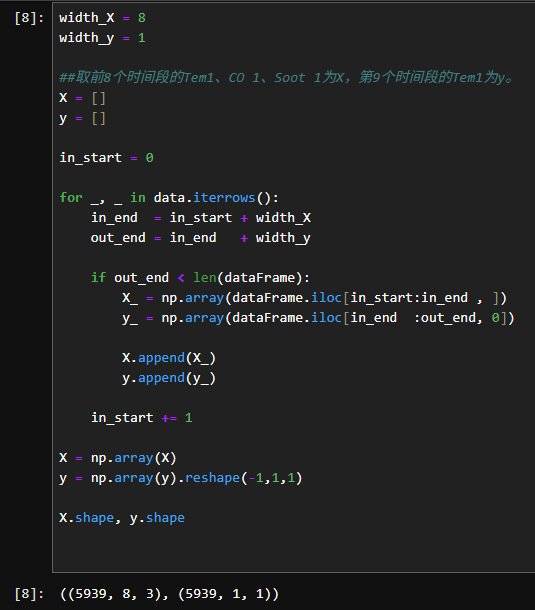
2.3检查数据集中有没有空值
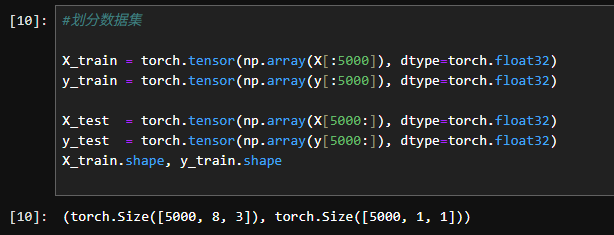
2.4划分数据集
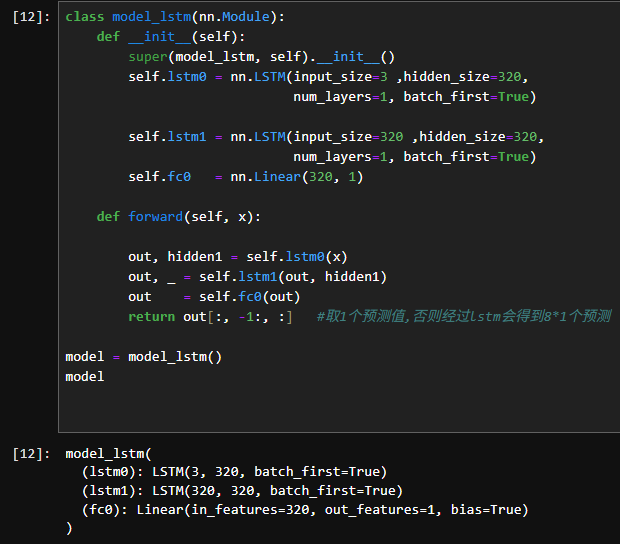
三、构建模型
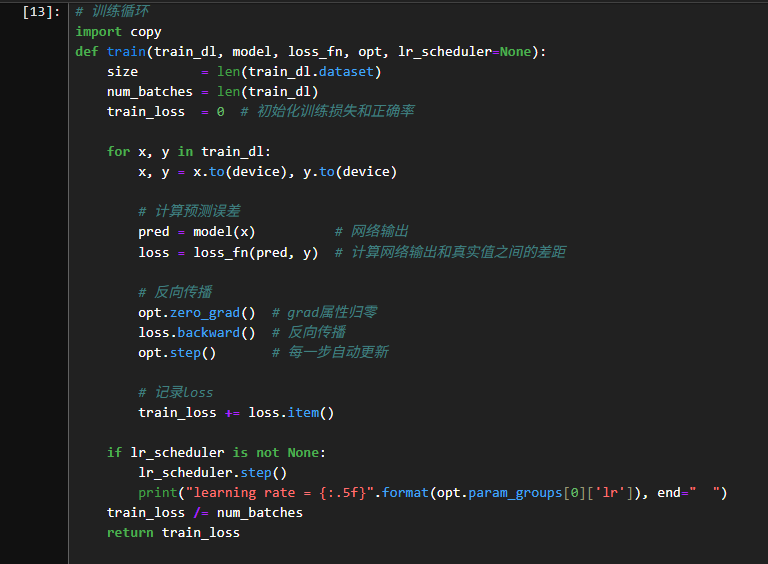
3.1定义训练函数
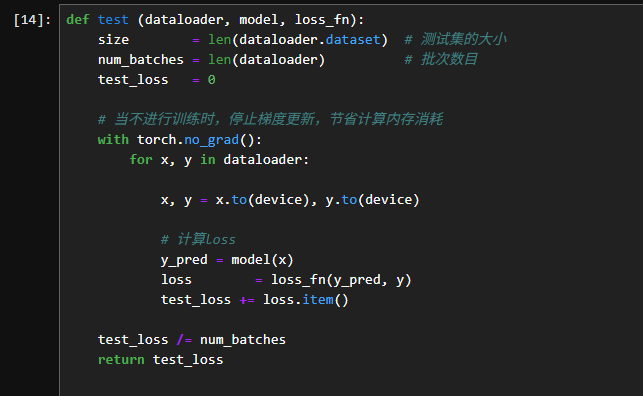
3.2定义测试函数
四、训练模型
#训练模型
model = model_lstm()
model = model.to(device)
loss_fn = nn.MSELoss() # 创建损失函数
learn_rate = 1e-1 # 学习率
opt = torch.optim.SGD(model.parameters(),lr=learn_rate,weight_decay=1e-4)
epochs = 50
train_loss = []
test_loss = []
lr_scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(opt,epochs, last_epoch=-1) for epoch in range(epochs):model.train()epoch_train_loss = train(train_dl, model, loss_fn, opt, lr_scheduler)model.eval()epoch_test_loss = test(test_dl, model, loss_fn)train_loss.append(epoch_train_loss)test_loss.append(epoch_test_loss)template = ('Epoch:{:2d}, Train_loss:{:.5f}, Test_loss:{:.5f}')print(template.format(epoch+1, epoch_train_loss, epoch_test_loss))print("="*20, 'Done', "="*20)
输出
learning rate = 0.09990 Epoch: 1, Train_loss:0.00120, Test_loss:0.01197
learning rate = 0.09961 Epoch: 2, Train_loss:0.01372, Test_loss:0.01150
learning rate = 0.09911 Epoch: 3, Train_loss:0.01330, Test_loss:0.01102
learning rate = 0.09843 Epoch: 4, Train_loss:0.01282, Test_loss:0.01050
learning rate = 0.09755 Epoch: 5, Train_loss:0.01228, Test_loss:0.00993
learning rate = 0.09649 Epoch: 6, Train_loss:0.01166, Test_loss:0.00931
learning rate = 0.09524 Epoch: 7, Train_loss:0.01094, Test_loss:0.00863
learning rate = 0.09382 Epoch: 8, Train_loss:0.01013, Test_loss:0.00790
learning rate = 0.09222 Epoch: 9, Train_loss:0.00922, Test_loss:0.00712
learning rate = 0.09045 Epoch:10, Train_loss:0.00823, Test_loss:0.00631
learning rate = 0.08853 Epoch:11, Train_loss:0.00718, Test_loss:0.00550
learning rate = 0.08645 Epoch:12, Train_loss:0.00611, Test_loss:0.00471
learning rate = 0.08423 Epoch:13, Train_loss:0.00507, Test_loss:0.00397
learning rate = 0.08187 Epoch:14, Train_loss:0.00409, Test_loss:0.00330
learning rate = 0.07939 Epoch:15, Train_loss:0.00322, Test_loss:0.00272
learning rate = 0.07679 Epoch:16, Train_loss:0.00247, Test_loss:0.00223
learning rate = 0.07409 Epoch:17, Train_loss:0.00185, Test_loss:0.00183
learning rate = 0.07129 Epoch:18, Train_loss:0.00137, Test_loss:0.00152
learning rate = 0.06841 Epoch:19, Train_loss:0.00100, Test_loss:0.00128
learning rate = 0.06545 Epoch:20, Train_loss:0.00073, Test_loss:0.00110
learning rate = 0.06243 Epoch:21, Train_loss:0.00054, Test_loss:0.00097
learning rate = 0.05937 Epoch:22, Train_loss:0.00040, Test_loss:0.00087
learning rate = 0.05627 Epoch:23, Train_loss:0.00031, Test_loss:0.00079
learning rate = 0.05314 Epoch:24, Train_loss:0.00024, Test_loss:0.00073
learning rate = 0.05000 Epoch:25, Train_loss:0.00020, Test_loss:0.00069
learning rate = 0.04686 Epoch:26, Train_loss:0.00017, Test_loss:0.00066
learning rate = 0.04373 Epoch:27, Train_loss:0.00015, Test_loss:0.00063
learning rate = 0.04063 Epoch:28, Train_loss:0.00013, Test_loss:0.00061
learning rate = 0.03757 Epoch:29, Train_loss:0.00012, Test_loss:0.00059
learning rate = 0.03455 Epoch:30, Train_loss:0.00012, Test_loss:0.00058
learning rate = 0.03159 Epoch:31, Train_loss:0.00011, Test_loss:0.00057
learning rate = 0.02871 Epoch:32, Train_loss:0.00011, Test_loss:0.00056
learning rate = 0.02591 Epoch:33, Train_loss:0.00011, Test_loss:0.00055
learning rate = 0.02321 Epoch:34, Train_loss:0.00011, Test_loss:0.00055
learning rate = 0.02061 Epoch:35, Train_loss:0.00011, Test_loss:0.00055
learning rate = 0.01813 Epoch:36, Train_loss:0.00011, Test_loss:0.00055
learning rate = 0.01577 Epoch:37, Train_loss:0.00011, Test_loss:0.00055
learning rate = 0.01355 Epoch:38, Train_loss:0.00012, Test_loss:0.00056
learning rate = 0.01147 Epoch:39, Train_loss:0.00012, Test_loss:0.00056
learning rate = 0.00955 Epoch:40, Train_loss:0.00012, Test_loss:0.00057
learning rate = 0.00778 Epoch:41, Train_loss:0.00013, Test_loss:0.00058
learning rate = 0.00618 Epoch:42, Train_loss:0.00013, Test_loss:0.00059
learning rate = 0.00476 Epoch:43, Train_loss:0.00013, Test_loss:0.00060
learning rate = 0.00351 Epoch:44, Train_loss:0.00014, Test_loss:0.00060
learning rate = 0.00245 Epoch:45, Train_loss:0.00014, Test_loss:0.00061
learning rate = 0.00157 Epoch:46, Train_loss:0.00014, Test_loss:0.00061
learning rate = 0.00089 Epoch:47, Train_loss:0.00014, Test_loss:0.00061
learning rate = 0.00039 Epoch:48, Train_loss:0.00014, Test_loss:0.00061
learning rate = 0.00010 Epoch:49, Train_loss:0.00014, Test_loss:0.00061
learning rate = 0.00000 Epoch:50, Train_loss:0.00014, Test_loss:0.00061
==================== Done ====================
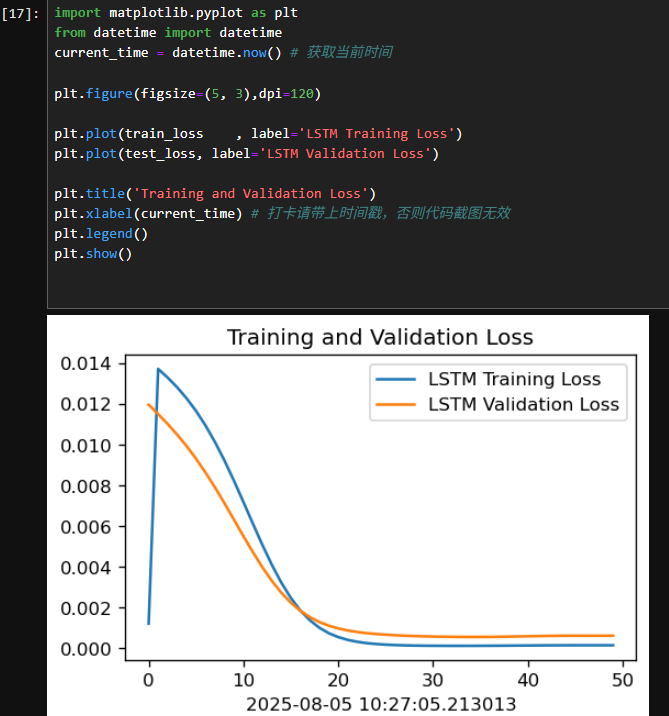
4.1Loss图
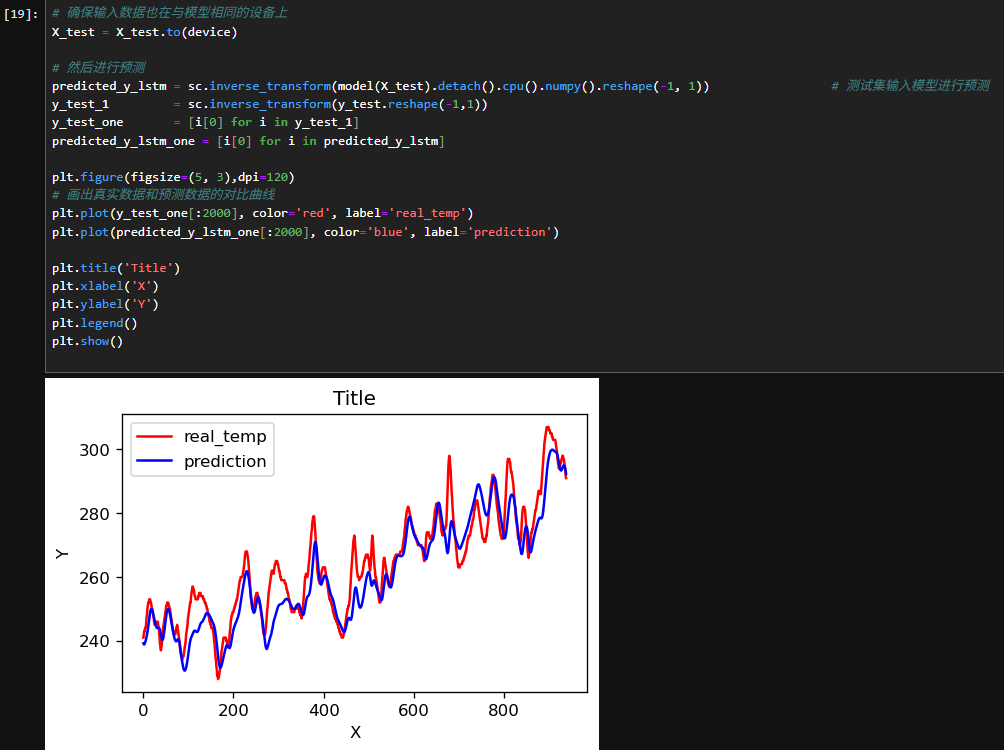
4.2调用模型进行预测
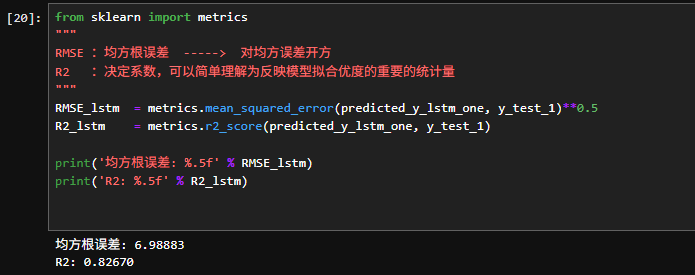
4.3R2值评估
五、总结
- LSTM模型的核心优势
时间序列数据的建模能力:LSTM(长短时记忆网络)专门设计来处理和预测序列数据中的长期依赖关系。在火灾温度预测这种时间序列问题中,LSTM能够有效捕捉过去温度数据与未来温度之间的关联,尤其在火灾数据中,温度往往有较强的时间依赖性。
解决梯度消失问题:传统的RNN在长时间序列中容易遇到梯度消失问题,而LSTM通过引入记忆单元(cell state)和门控机制有效地缓解了这一问题,能够记住远期的信息。
- PyTorch的使用
灵活性和易用性:PyTorch框架提供了非常简洁的API,并且在实现LSTM时具有高度的灵活性,能方便地调整网络结构、训练参数及优化方法。
调试和可视化:PyTorch的动态计算图使得调试过程更加直观,尤其是在处理复杂的深度学习模型时,可以逐步查看模型输出、梯度等中间结果。
- 模型训练与评估
数据预处理的重要性:时间序列数据的预处理,尤其是数据标准化或归一化,能够显著提高LSTM模型的训练效果。温度数据可能存在波动和不规律的变化,因此,去噪和处理缺失数据是模型成功的关键因素。
模型评估:对于回归任务,如火灾温度预测,常用的评估指标包括均方误差(MSE)、均方根误差(RMSE)和决定系数(R²)。这些指标可以帮助评估模型的预测精度,进一步调整模型超参数和结构。
- 模型的表现
训练和测试误差:通过模型训练过程中观察训练和测试误差,可能发现训练集误差较低但测试集误差较高,暗示过拟合的存在。通过交叉验证和正则化技术可以有效解决这一问题。
时间依赖性:LSTM能够捕捉到较长时间跨度的数据关系,但有时也会遇到短期依赖的情况,可能需要调整网络层数、隐藏层维度等参数



















