1.c语言文件操作
fopen:打开文件,模式 "w"(写,覆盖)或 "r"(读)。
fwrite:fwrite(data, size, count, fp),按 size 字节写入 count 次数据。
fread:fread(buf, size, count, fp),返回实际读取字节数,需结合 feof 处理文件结束。
fclose:关闭文件,释放资源,必须调用以避免泄漏。
1.打开关闭文件:
#include <stdio.h>int main() {FILE *fp = fopen("myfile", "w");if (!fp) {printf("fopen error!\n");}while (1); // 死循环,fclose无法执行fclose(fp);return 0;
}2.写文件:
#include <stdio.h>
#include <string.h>int main() {FILE *fp = fopen("myfile", "w");if (!fp) {printf("fopen error!\n");return 1;}const char *msg = "hello bit!\n";for (int i = 0; i < 5; ++i) { // 更清晰的循环fwrite(msg, strlen(msg), 1, fp);}fclose(fp);return 0;
}3.读文件:
#include <stdio.h>
#include <string.h>int main() {FILE *fp = fopen("myfile", "r");if (!fp) {printf("fopen error!\n");return 1;}char buf[1024];const char *msg = "hello bit!\n"; // 正确定义指针(原代码可能笔误,此处修正)size_t read_len = strlen(msg); // 12字节while (1) {ssize_t s = fread(buf, 1, read_len, fp); // 每次读取12字节if (s > 0) {buf[s] = '\0'; // 终止字符串printf("%s", buf);}if (feof(fp)) { // 检查文件结束break;}}fclose(fp);return 0;
}更加细节的操作,可以再C语言文件操作-CSDN博客文章中查看
stdin &stdout& stderr

C默认会打开三个输入输出流,分别是stdin,stdout,stderr仔细观察发现,
这三个流的类型都是FILE*,fopen返回值类型,文件指针
2.系统文件I/O
认识一下两个概念:系统调用和库函数
上面的 fopen fclose freadfwrite 都是C标准库当中的函数,我们称之为库函数(libc)。
而 open close read write lseek 都属于系统提供的接口,称之为系统调用接口
不管是c c++ 还是java 所有的语言对文件的操作的库函数,其实都是系统IO套了一层语言的外壳
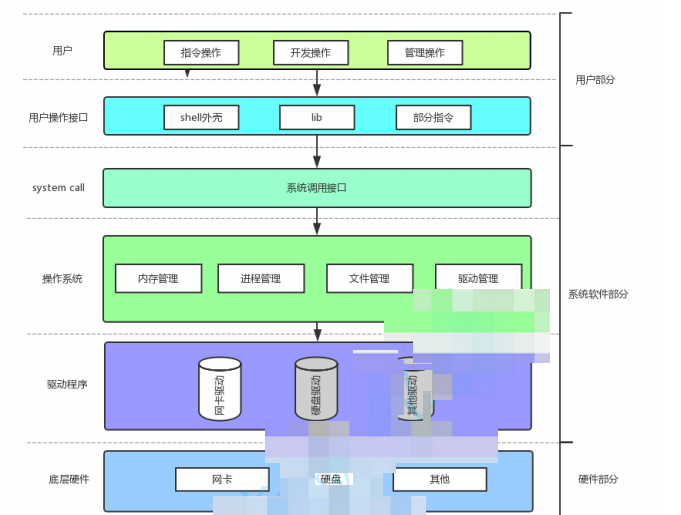
2.1.系统文件的接口
1.打开文件open:
打开或创建文件,返回文件描述符。
有两种创建方式:
第一种:就是文件已经存在的情况
第二种:就是文件如果不存在,那么就其文件进行创建,mode参数就是设置创建文件的权限
1 #include <sys/types.h>
2 #include <sys/stat.h>
3 #include <fcntl.h>4 int open(const char *pathname, int flags);
5 int open(const char *pathname, int flags, mode_t mode);6
7 pathname: 要打开或创建的目标文件
8 flags: 打开文件时,可通过“或”运算组合多个常量,规则如下:
9 参数:
10 基本模式(必选其一,互斥):
11 O_RDONLY:只读(0)
12 O_WRONLY:只写(1)
13 O_RDWR :读写(2)
14 三者必选且仅选其一
15 附加标志(可选,| 组合):
16 O_CREAT :创建文件(需配mode,不存在则建,存在则按基本模式打开)
17 O_APPEND:追加写(指针移到末尾,不覆盖原有内容)
18 O_TRUNC :写模式下截断文件(清空内容,覆盖写入,与O_APPEND互斥)
19 O_EXCL :与O_CREAT联用,确保文件不存在(存在则失败,errno=EEXIST,原子创建)
20 O_NONBLOCK:非阻塞IO(设备/套接字操作不阻塞,立即返回,需处理EAGAIN)
21 O_SYNC :同步写(数据+元数据立即刷盘,保证持久,性能开销大)
22 O_DIRECT :直接IO(绕过内核缓冲,需内存/偏移对齐,否则EINVAL)
23 mode: 仅O_CREAT时有效,指定新文件权限(如0644),实际权限为mode & ~umask24 返回值:
25 成功: 非负文件描述符(如3,4...,0/1/2为标准IO)
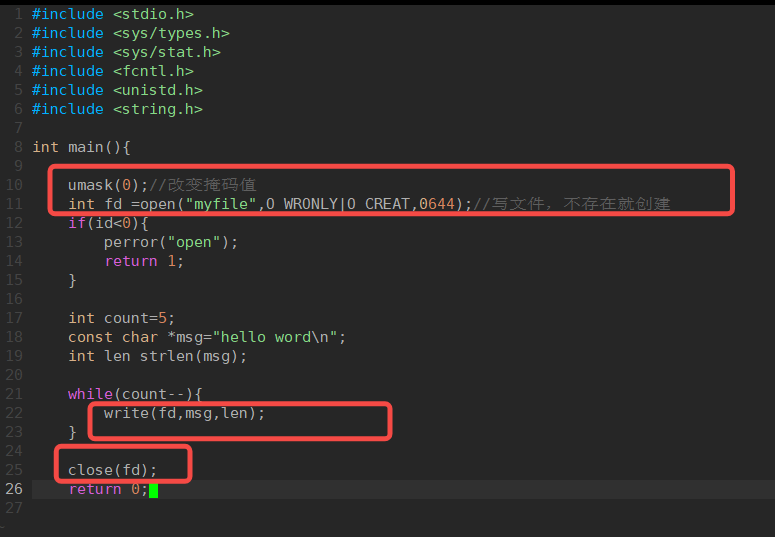
26 失败: -1(检查errno,用perror调试,如ENOENT(文件不存在)、EEXIST(O_CREAT+O_EXCL冲突)等)2.写文件write:
向文件写入缓冲区数据。
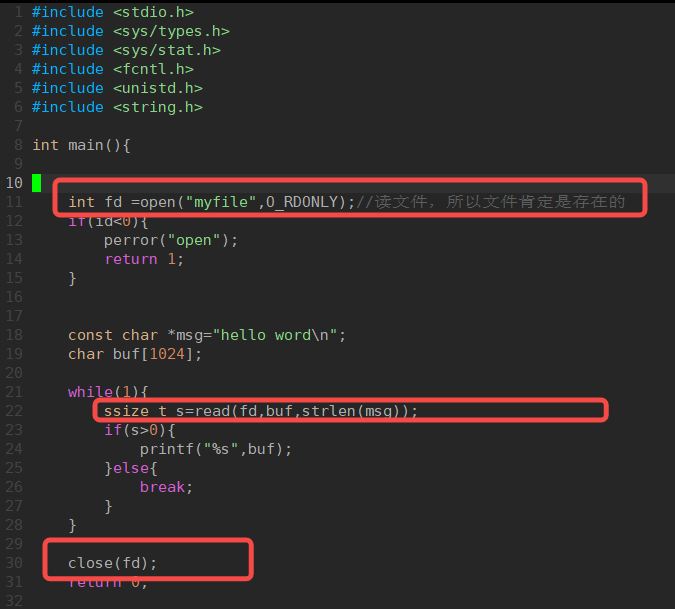
3.读文件read:
关闭文件描述符,释放资源。
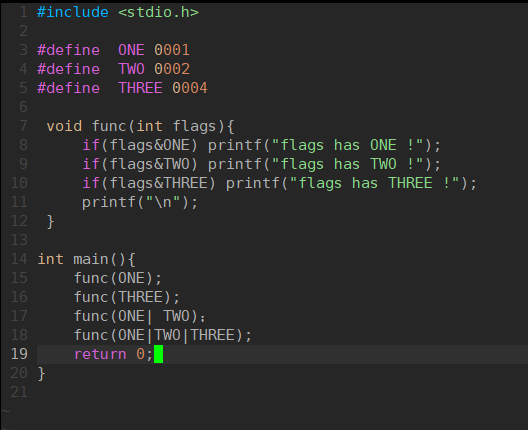
上面三种接口都使到标志位,那么下面就是识别标志位的一种方式:
上面参数flags传递标志位的方法:
采用的的位图的思想,只需要判断对应的二进制位上是否是1即可
2.1.文件描述符fd
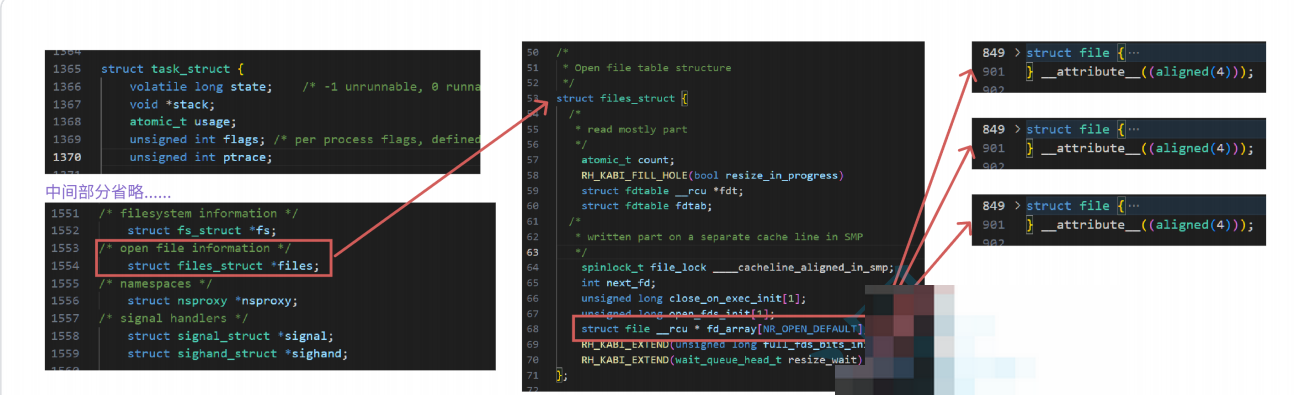
理解文件描述符之前先了解fd代表什么,又是存储在哪里?
一个进程都有PCB,在PCB中,有个指针数组*files 表示一个进程可以管理多个文件,而指针数组*files 的下标就是我们说的fd ,files[fd]:就是指向下标为fd的文件,系统会自动的的打开三个文件,分别是 标准输入,标准输出,标准错误,他们对应的下标是 0,1,2
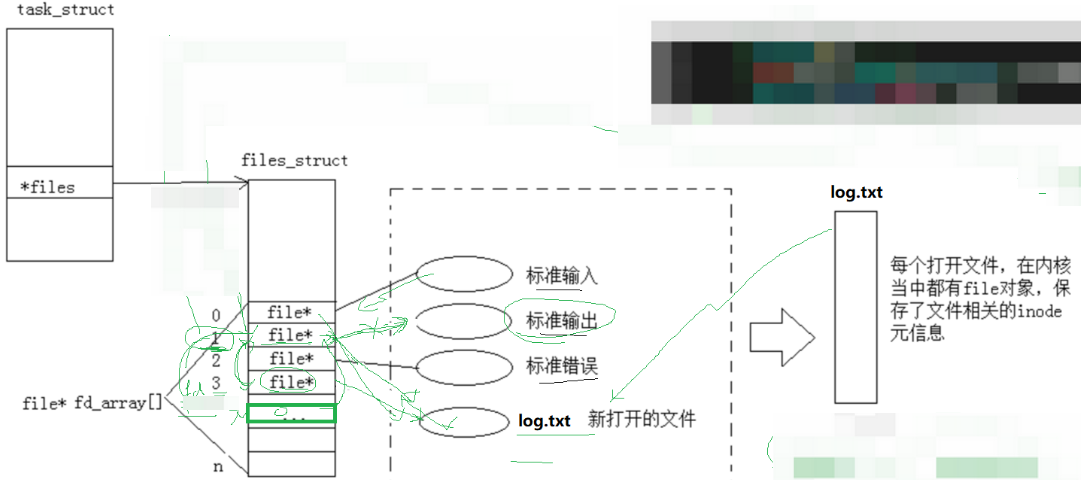
2.1.1.文件描述符的分配规则
2.此时将0和1下标的文件关闭,发现打印的0;
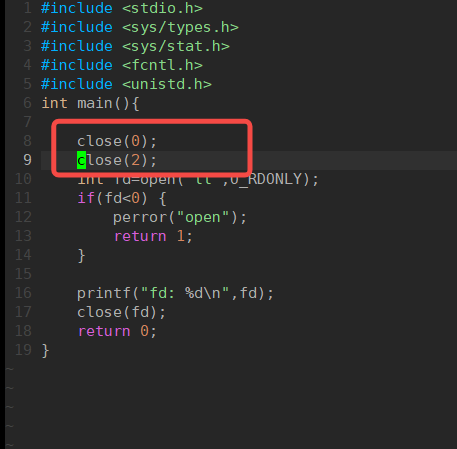

2.1.2.重定向
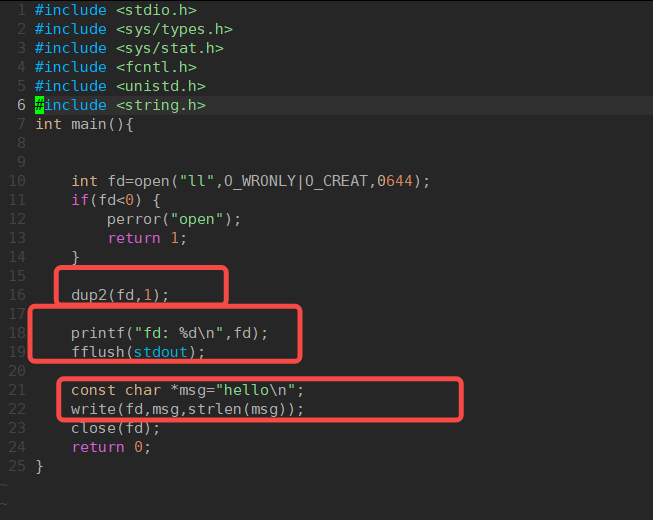
明白了上面的规则后,看一个现象:
当我们将标准输出给关闭,printf向输出文件写东西的时候,发现内容没有写到标准输出文件,而写到了新创建的文件
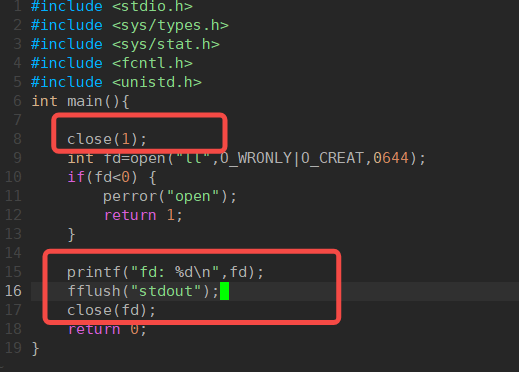
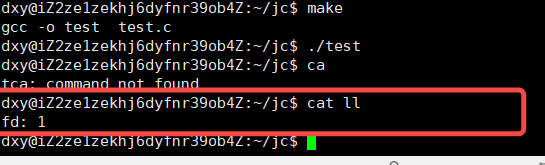
原理:
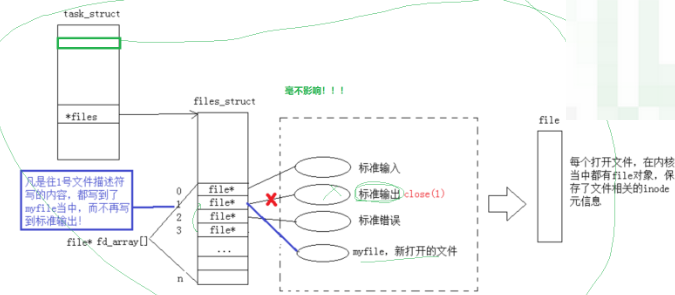
使用dup2 系统调用:
函数原型:

再看一个示例:发现此时的fd 和 1指向的都是新创建的ll 文件

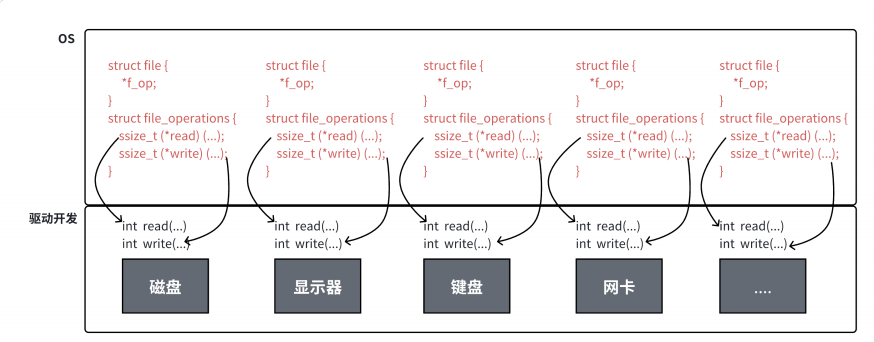
3.一切皆文件
首先,在windows中是文件的东西,它们在linux中也是文件;其次一些在windows中不是文件的东西,比如进程、磁盘、显示器、键盘这样硬件设备也被抽象成了文件,你可以使用访问文件的方法访问它们获得信息;甚至管道,也是文件;
这样做最明显的好处是,开发者仅需要使用一套 API和开发工具,即可调取 Linux 系统中绝大部分的资源。举个简单的例子,Linux中几乎所有读(读文件,读系统状态,读PIPE)的操作都可以用read 函数来进行;几乎所有更改(更改文件,更改系统参数,写PIPE)的操作都可以用 write 函数来进行。

4.缓冲区
缓冲区的定义:
缓冲区是内存空间的一部分。也就是说,在内存空间中预留了一定的存储空间,这些存储空间用来缓冲输入或输出的数据,这部分预留的空间就叫做缓冲区。缓冲区根据其对应的是输入设备还是输出设备,分为输入缓冲区和输出缓冲区。
在不同层面上也是分成 :
用户级:语言层缓冲区
语言层的缓冲区内容就缓冲到文件内核缓冲区
系统层: 文件内核缓冲区
文件内核缓冲区内容就缓冲到磁盘中
缓冲区的作用:
读写文件时,如果不会开辟对文件操作的缓冲区,直接通过系统调用对磁盘进行操作(读、写等),那么每次对文件进行一次读写操作时,都需要使用读写系统调用来处理此操作,即需要执行一次系统调用,执行一次系统调用将涉及到CPU状态的切换,即从用户空间切换到内核空间,实现进程上下文的切换,这将损耗一定的CPU时间,频繁的磁盘访问对程序的执行效率造成很大的影响。
为了减少使用系统调用的次数,提高效率,我们就可以采用缓冲机制。比如我们从磁盘里取信息,可以在磁盘文件进行操作时,可以一次从文件中读出大量的数据到缓冲区中,以后对这部分的访问就不需要再使用系统调用了,等缓冲区的数据取完后再去磁盘中读取,这样就可以减少磁盘的读写次数,再加上计算机对缓冲区的操作大大快于对磁盘的操作,故应用缓冲区可大大提高计算机的运行速度。
这时我们的CPU可以处理别的事情。可以看出,缓冲区就是块内存区,它用在输入输出设备和CPU之间,用来缓存数据。它使得低速的输入输出设备和高速的CPU能够协调工作,避免低速的输入输出设备占用CPU,解放出CPU,使其能够高效率工作。
4.1.缓冲类型
缓冲区类型分成下面三种:
全缓冲区:
这种缓冲方式要求填满整个缓冲区后才进行1/0系统调用操作。对于磁盘文件的操作通常使用全缓冲的方式访问。
原本标准输出是行缓冲区,但是已经重定向到了“log.txt”文件,所以变成了全缓冲区,所以要使用语言层的刷新函数fflush进行刷新

行缓冲区:
在行缓冲情况下,当在输入和输出中遇到换行符时,标准I/0库函数将会执行系统调用操作。当所操作的流涉及一个终端时(例如标准输入和标准输出),使用行缓冲方式。因为标准I/0库每行的缓冲区长度是固定的,所以只要填满了缓冲区,即使还没有遇到换行符,也会执行/O系统调用操作,默认行缓冲区的大小为1024。
原本标准输出是行缓冲区,但是已经重定向到了“log.txt”文件,所以变成了全缓冲区,所以没有数据刷新到文件缓冲区

无缓冲区:
无缓冲区是指标准I/0库不对字符进行缓存,直接调用系统调用。标准出错流stderr通常是不带缓冲区的,这使得出错信息能够尽快地显示出来。
标准错误就是无缓冲区:

4.2.FILE
观察此段代码:

运行结果1:
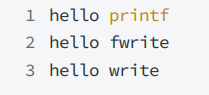
运行结果2(对进程实现输出重定向 ./hello > file):

重定向结果解析:
1.当重定向的时候,缓冲区的缓冲方式已经变成了从行缓冲变成了全缓冲。
2.所以msg0和msg1写在了用户级的缓冲区,msg3调用的是系统IO,所以直接写在,内核缓冲区中。
3.fork()创建子进程,所以父子进程都结束的时候,对进行二次对用户级的缓冲区的刷新
4.所以此时打印的是这种结果
 方法(1))


和OBB(定向包围盒)优化碰撞检测)















