4.5FAST Algorithm for Corner Detection
4.5.1FAST算法
我们已了解多种特征检测器,其中许多效果出色。但从实时应用的角度来看,它们的速度仍不够快。一个典型例子是计算资源有限的SLAM(同步定位与建图)移动机器人。
为解决此问题,Edward Rosten和Tom Drummond在2006年的论文《机器学习用于高速角点检测》中提出了FAST(加速分段测试特征)算法(2010年进行了修订)。以下是算法的基本概要,更多细节请参阅原始论文
- 选择图像中的一个像素点
p,判断其是否为关键点。设其强度值为Iₚ。 - 选择合适的阈值
t。 - 考虑以待测像素
p为中心的 16 个像素组成的圆形邻域(见下图)。

现在,如果在该圆形邻域(16 个像素)内,存在 n 个连续的像素,它们全都比 Iₚ + t 更亮,或者全都比 Iₚ - t 更暗(如上图中的白色虚线所示),则像素 p 被判定为一个角点。n 通常被选定为 12。
有人提出了一种高速测试方法来排除大量的非角点。该测试仅检查位于 1、9、5 和 13 位置的四个像素(首先测试 1 和 9 是否过亮或过暗。如果是,则再检查 5 和 13)。如果 p 是一个角点,那么这四个点中至少有三个必须全部比 Iₚ + t 更亮,或者全部比 Iₚ - t 更暗。如果这两种情况都不满足,那么 p 就不可能是一个角点。然后,可以对通过此测试的候选点应用完整的段测试标准,即检查圆周上的所有像素。该检测器本身表现出高性能,但也存在几个弱点:
- 当
n< 12 时,它无法拒绝那么多的候选点。 - 像素点的选择并非最优,因为其效率取决于问题的(检测)顺序和角点外观的分布。
- 高速测试的结果被丢弃了(未被充分利用)。
- 在相邻位置会检测到多个特征点。
前三个问题通过机器学习方法解决。最后一个问题使用非极大值抑制 (Non-maximal Suppression) 解决。
4.5.2机器学习角点检测器


FAST 算法比其他现有的角点检测器快好几倍。但它对高噪声水平不鲁棒,且依赖于阈值的选择。
cv.FastFeatureDetector_create()功能: 创建一个 FAST 检测器对象。参数: 此函数可以接受多个参数来配置检测器的行为,最常见的包括:threshold: 中心像素与周围圆形邻域像素的强度差阈值。用来判断一个像素是更亮、更暗还是相似。值越小,检测到的角点越多,但也可能包含更多噪声。
nonmaxSuppression: 是否启用非极大值抑制。
True (默认): 启用。对于相邻的多个角点,只保留响应最强的那个。这通常能获得更好的、分布更均匀的角点。
False: 禁用。可能会在一小片区域检测到多个密集的角点。
type: 指定高速测试的模式。通常是 cv.FAST_FEATURE_DETECTOR_TYPE_9_16(检查 9 个连续像素,使用 16 像素的圆)或其他变体。通常使用默认值即可。
返回值: 返回一个 FastFeatureDetector 对象,你可以用它来调用 .detect() 等方法。fast.detect()功能: 使用之前创建的 FAST 检测器在图像中查找关键点。参数:image: 输入的图像(必须是单通道灰度图)。
mask: 可选参数。指定搜索关键点的区域。只有在掩模非零的区域才会进行检测。
返回值: 返回一个关键点列表。每个关键点都是一个特殊的对象,包含以下重要属性:pt: 关键点的 (x, y) 坐标。例如 keypoint.pt 会返回 (123.0, 45.0)。
size: 关键点的有效邻域直径。
response: 关键点的响应强度(例如,FAST 的评分函数 V)。响应越强,该点越可能是“好”的角点。
angle: 关键点的方向(度),-1 表示未计算。
octave: 检测到该关键点的金字塔层级。cv.drawKeypoints(image, keypoints, outImage, color=None, flags=None)
image: 输入图像。通常是你想在上面绘制关键点的原始图像(彩色或灰度)。
keypoints: 关键点列表。这是由 fast.detect(), sift.detect(), orb.detect() 等特征检测器函数返回的结果。
outImage: 输出图像。绘制了关键点后的图像。可以是 None,也可以是一个已存在的图像数组。
color: 关键点的颜色。指定绘制关键点时使用的颜色。
格式通常为 (B, G, R) 元组,例如 (0, 255, 0) 表示绿色。
默认是随机颜色。
flags: 绘制标志。这是一个非常重要的参数,它控制着关键点的绘制方式。是 cv.DRAW_MATCHES_FLAGS_* 系列的常量。
cv.DRAW_MATCHES_FLAGS_DEFAULT (或 None): 默认方式。只绘制关键点的中心点(一个小圆点)。
cv.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS: 推荐使用。为每个关键点绘制一个带方向的圆,圆的尺寸表示关键点的大小,从圆心发出的射线表示关键点的方向。这种方式信息量更大。
cv.DRAW_MATCHES_FLAGS_NOT_DRAW_SINGLE_POINTS: 不绘制单个的关键点(通常在与 DRAW_RICH_KEYPOINTS 结合使用时意义不大)。
cv.DRAW_MATCHES_FLAGS_DRAW_OVER_OUTIMG: 在输出的图像矩阵上直接绘制,而不是先创建一个副本。(通常不直接使用)
返回值: 返回绘制了关键点的输出图像。完整工作流程总结
-
导入 OpenCV:
import cv2 as cv -
读取图像并转为灰度图:
gray = cv.cvtColor(img, cv.COLOR_BGR2GRAY) -
创建检测器:
fast = cv.FastFeatureDetector_create(...) -
检测关键点:
kp = fast.detect(gray, None) -
(可选) 绘制/使用关键点:
cv.drawKeypoints(...)或直接访问kp列表中的属性进行计算。
demo:
import numpy as np
import cv2 as cv
from matplotlib import pyplot as pltimg = cv.imread('image4.png', cv.IMREAD_GRAYSCALE)fast = cv.FastFeatureDetector_create()kp = fast.detect(img,None)
img2 = cv.drawKeypoints(img,kp,None,(0,255,0))# Print all default params
print( "Threshold: {}".format(fast.getThreshold()) )
print( "nonmaxSuppression:{}".format(fast.getNonmaxSuppression()) )
print( "neighborhood: {}".format(fast.getType()) )
print( "Total Keypoints with nonmaxSuppression: {}".format(len(kp)) )cv.imwrite('fast_true1.png', img2)fast.setNonmaxSuppression(0)
kp = fast.detect(img,None)print( "Total Keypoints without nonmaxSuppression: {}".format(len(kp)) )img3 = cv.drawKeypoints(img,kp,None,color=(0,255,0))
cv.imwrite('fast_true2.png', img3)


4.6BRIEF (Binary Robust Independent Elementary Features)
我们知道 SIFT 使用 128 维向量作为描述符。由于使用浮点数,它基本上需要 512 字节。类似地,SURF 也至少需要 256 字节(对于 64 维)。为成千上万个特征创建这样的向量会占用大量内存,这对于资源受限的应用(尤其是嵌入式系统)是不可行的。内存越大,匹配所需的时间就越长。
但实际匹配可能并不需要所有这些维度。我们可以使用多种方法(如 PCA、LDA 等)来压缩它。甚至还有其他方法,如使用 LSH(局部敏感哈希)进行哈希处理,将 SIFT 的浮点描述符转换为二进制字符串。这些二进制字符串使用汉明距离进行特征匹配。这提供了更好的加速效果,因为计算汉明距离仅需进行异或运算和位计数,这在具有 SSE 指令的现代 CPU 中非常快。但这里,我们需要先找到描述符,然后才能应用哈希,这并没有解决我们最初的内存问题。
BRIEF 就在此时应运而生。它提供了一种捷径,无需先找到描述符就能直接获得二进制字符串。它取一个平滑后的图像块,并以一种独特的方式(论文中 explained)选择一组![]() 位置对。然后对这些位置对进行像素强度比较。例如,令第一个位置对为 p 和 q 。如果
位置对。然后对这些位置对进行像素强度比较。例如,令第一个位置对为 p 和 q 。如果 ![]() ,则结果为 1,否则为 0。这对所有
,则结果为 1,否则为 0。这对所有 ![]() 个位置对进行处理,得到一个
个位置对进行处理,得到一个 ![]() 维的比特串。
维的比特串。
这个 ![]() 可以是 128、256 或 512。OpenCV 支持所有这些尺寸,但默认情况下是 256(OpenCV 以字节表示。因此实际值为 16、32 和 64 字节)。一旦得到这个比特串,你就可以使用汉明距离来匹配这些描述符。
可以是 128、256 或 512。OpenCV 支持所有这些尺寸,但默认情况下是 256(OpenCV 以字节表示。因此实际值为 16、32 和 64 字节)。一旦得到这个比特串,你就可以使用汉明距离来匹配这些描述符。
重要的一点是,BRIEF 是一种特征描述符,它不提供任何查找特征点的方法。因此,你必须使用其他任何特征检测器,如 SIFT、SURF 等。该论文推荐使用 CenSurE(一种快速检测器),并且 BRIEF 对于 CenSurE 特征点的效果甚至比 SURF 点略好。
简而言之,BRIEF 是一种更快的特征描述符计算与匹配方法。除非存在大的面内旋转,否则它也能提供较高的识别率。
OpenCV 中的 STAR(CenSurE)
STAR 是一种源自 CenSurE 的特征检测器。然而,与使用正方形、六边形和八边形等多边形来逼近圆形的 CenSurE 不同,STAR 使用 2 个重叠的正方形来模拟圆形:1 个直立,1 个旋转 45 度。这些多边形是双层的。它们可以看作是具有粗边框的多边形。边框和内部封闭区域的权重符号相反。这比其他尺度空间检测器具有更好的计算特性,并且能够实时实现。与 SIFT 和 SURF 在子采样像素上寻找极值(这会在较大尺度上影响精度)不同,CenSurE 在金字塔的所有尺度上使用全空间分辨率来创建特征向量。
4.7ORB (Oriented FAST and Rotated BRIEF)
作为一名 OpenCV 爱好者,关于 ORB 最重要的一点是它出自“OpenCV Labs”。该算法由 Ethan Rublee, Vincent Rabaud, Kurt Konolige 和 Gary R. Bradski 在他们 2011 年的论文 《ORB: SIFT 或 SURF 的高效替代品》 中提出。正如标题所言,它在计算成本、匹配性能,尤其是专利方面,是 SIFT 和 SURF 的一个很好的替代品。是的,SIFT 和 SURF 是申请了专利的,使用它们需要付费。但 ORB 没有!
ORB 基本上是 FAST 关键点检测器和 BRIEF 描述符的融合,并进行了许多修改以增强性能。首先,它使用 FAST 寻找关键点,然后应用 Harris 角点测度从中找出前 N 个最好的点。它还使用图像金字塔来产生多尺度特征。但有一个问题是,FAST 不计算方向。那么旋转不变性如何实现呢?作者提出了以下修改。
它计算了以角点为中心的图像块的强度加权质心。从该角点指向质心的向量方向即为该点的方向。为了提高旋转不变性,使用 x 和 y 计算图像矩,计算应在半径为 r ( r 是图像块的大小)的圆形区域内进行。
对于描述符,ORB 使用 BRIEF 描述符。但我们已经知道 BRIEF 在旋转情况下表现很差。因此 ORB 所做的就是根据关键点的方向来“引导”(steer)BRIEF。对于在位置![]() 的任何包含 n 个二进制测试的特征集,定义一个
的任何包含 n 个二进制测试的特征集,定义一个 ![]() 的矩阵 S ,其中包含了这些像素的坐标。然后利用图像块的方向 theta,找到其旋转矩阵并旋转 S ,得到被引导(旋转)后的版本
的矩阵 S ,其中包含了这些像素的坐标。然后利用图像块的方向 theta,找到其旋转矩阵并旋转 S ,得到被引导(旋转)后的版本 ![]() 。
。
ORB 将角度离散化为 $ 2\pi/30 $(12 度)的增量,并构建了一个预计算 BRIEF 模式的查找表。只要关键点方向 $\theta$ 在不同视角下保持一致,就会使用正确的点集来计算其描述符。
BRIEF 有一个重要特性:每个位特征具有高方差且其均值接近 0.5。但一旦其沿关键点方向被引导后,就会失去这个属性而变得更加分散。高方差使得特征更具区分度,因为它对输入有不同的响应。另一个理想特性是测试之间不相关,这样每个测试都会对结果有贡献。为了解决所有这些问题,ORB 在所有可能的二进制测试中运行一种贪婪搜索,以找到那些同时具有高方差、均值接近 0.5 且不相关的测试。结果被称为 rBRIEF(Rotation-aware BRIEF)。
对于描述符匹配,它使用了在传统 LSH 基础上改进的多探针 LSH(multi-probe LSH)。论文指出,ORB 比 SURF 和 SIFT 快得多,并且 ORB 描述符的性能优于 SURF。ORB 是低功耗设备(如进行全景拼接等应用)的一个非常好的选择。
cv.ORB_create()功能: 创建一个 ORB 检测器对象。参数: 此函数可以接受多个参数来配置 ORB 检测器的行为。以下是一些最常用的参数:nfeatures: 保留的最佳特征点的最大数量。默认值为 500。
scaleFactor: 构建图像金字塔时的尺度因子。例如,scaleFactor=1.2 表示每层金字塔是下一层的 1.2 倍。值越大,金字塔层数越少,计算越快,但可能漏掉某些尺度的特征。 默认值为 1.2。
nlevels: 图像金字塔的层数。默认值为 8。
edgeThreshold: 图像边界的阈值,由于特征点需要完整的邻域,边界上的点会被忽略。默认值为 31。
firstLevel: 将原图像作为金字塔的第几层。默认值为 0。
WTA_K: 用于生成 rBRIEF 描述符的每个元素的点数。默认是 2(即一次比较两个点,产生 0 或 1)。如果为 3 或 4,则一次比较 3 或 4 个点,取亮度最高的那个点的索引(0,1,2 或 0,1,2,3),这会生成需要更多位来表示的描述符。
scoreType: 关键点评分类型。cv.ORB_HARRIS_SCORE(默认)使用 Harris 角点响应函数来排名特征点;cv.ORB_FAST_SCORE 使用 FAST 方法的一个稍低质量的替代方案,但速度更快。
patchSize: 用于生成描述符的图像块大小。默认值为 31。
返回值: 返回一个 ORB 对象,你可以用它来调用 .detect(), .compute(), 或 .detectAndCompute() 等方法。orb.detect()功能: 使用之前创建的 ORB 检测器在图像中查找关键点。注意:此方法只检测关键点的位置、尺度和方向,不计算描述符。参数:image: 输入的图像(必须是单通道灰度图)。
mask: 可选参数。指定搜索关键点的区域。只有在掩模非零的区域才会进行检测。
返回值: 返回一个关键点列表。每个关键点都是一个特殊的对象,包含以下重要属性:pt: 关键点的 (x, y) 坐标。例如 keypoint.pt 会返回 (123.0, 45.0)。
size: 关键点的有效邻域直径。
angle: 关键点的方向(度),由 ORB 算法计算得出,提供了旋转不变性。
response: 关键点的响应强度(例如,Harris 角点响应或 FAST 得分)。响应越强,该点越可能是“好”的特征点。
octave: 检测到该关键点的金字塔层级。demo:
import numpy as np
import cv2 as cv
from matplotlib import pyplot as pltimg = cv.imread('image4.png')
img1 = cv.cvtColor(img,cv.COLOR_BGR2GRAY)orb = cv.ORB_create()kp = orb.detect(img1,None)kp,des = orb.compute(img1,kp)img2 = cv.drawKeypoints(img,kp,None,color=(255,0,0),flags=0)
cv.imwrite('orb.jpg',img2)
4.8Feature Matching
4.8.1Brute-Force 匹配器基础
Brute-Force 匹配器很简单。它获取第一组(查询图像)中一个特征的描述符,并使用某种距离计算方式与第二组(训练图像)中的所有其他特征进行匹配。然后返回最接近的一个。
对于 BF 匹配器,我们首先需要使用 cv.BFMatcher() 创建 BFMatcher 对象。它接受两个可选参数:
-
第一个是
normType(规范类型)。它指定要使用的距离测量方式。默认是cv.NORM_L2。这对于 SIFT、SURF 等描述符很好(cv.NORM_L1也可用)。对于基于二进制字符串的描述符,如 ORB、BRIEF、BRISK 等,应该使用cv.NORM_HAMMING,它使用汉明距离作为测量方式。如果 ORB 使用WTA_K == 3或4(即每个元素用多个比特表示),则应使用cv.NORM_HAMMING2。 -
第二个参数是一个布尔变量
crossCheck(交叉验证),默认为 false。如果为 true,匹配器只返回那些满足 (i,j) 条件的匹配项:集合 A 中的第 i 个描述符在集合 B 中的最佳匹配是第 j 个描述符,并且反过来,集合 B 中的第 j 个描述符在集合 A 中的最佳匹配也必须是第 i 个描述符。也就是说,两组中的两个特征应该互相匹配。它能提供一致的结果,并且是 SIFT 论文中 D.Lowe 提出的比率检验(ratio test)的一个很好的替代方案。
一旦创建完成,有两个重要的方法:BFMatcher.match() 和 BFMatcher.knnMatch()。第一个方法返回最佳匹配。第二个方法返回 k 个最佳匹配,其中 k 由用户指定。当我们需要对这些匹配进行额外处理时,这个方法会很有用。
就像我们使用 cv.drawKeypoints() 来绘制关键点一样,cv.drawMatches() 帮助我们绘制匹配项。它将两幅图像水平堆叠,并从第一幅图像到第二幅图像绘制线条来显示最佳匹配。还有一个 cv.drawMatchesKnn 可以绘制所有 k 个最佳匹配。如果 k=2,它将为每个关键点绘制两条匹配线。因此,如果我们想选择性地绘制,必须传递一个掩码(mask)。
4.8.2Brute-Force Matching with ORB Descriptors
demo:
import numpy as np
import cv2 as cv
import matplotlib.pyplot as pltimg1 = cv.imread('image4.png',cv.IMREAD_GRAYSCALE)
img2 = cv.imread('image4.png',cv.IMREAD_GRAYSCALE)# Initiate ORB detector
orb = cv.ORB_create()kp1,des1 = orb.detectAndCompute(img1,None)
kp2,des2 = orb.detectAndCompute(img2,None)# create BFMatcher object
bf = cv.BFMatcher(cv.NORM_HAMMING,crossCheck=True)# Match descriptors.
matches = bf.match(des1,des2)# Sort them in the order of their distance.
matches = sorted(matches,key = lambda x:x.distance)# Draw first 30 matches.
img3 = cv.drawMatches(img1,kp1,img2,kp2,matches[:30],None,flags=cv.DrawMatchesFlags_NOT_DRAW_SINGLE_POINTS,matchColor=[0,0,255])plt.imshow(img3),plt.show()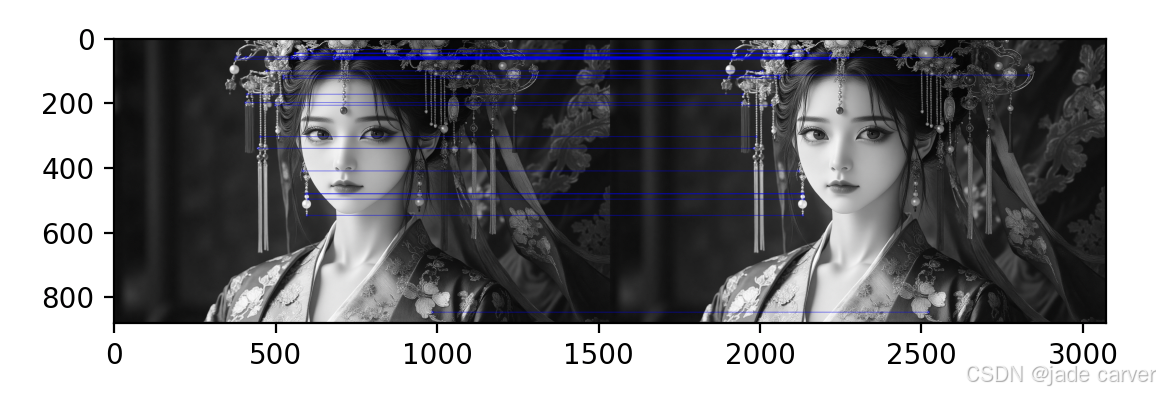
4.8.3What is this Matcher Object?
什么是这个匹配器对象(Matcher Object)?
matches = bf.match(des1, des2) 这行代码的结果是一个由 DMatch 对象 组成的列表。这个 DMatch 对象具有以下属性:
-
DMatch.distance - 描述符之间的距离。距离越小,匹配越好。
-
DMatch.trainIdx - 在训练描述符集(第二张图片
des2)中的描述符的索引。 -
DMatch.queryIdx - 在查询描述符集(第一张图片
des1)中的描述符的索引。 -
DMatch.imgIdx - 训练图像(第二张图片)的索引。
4.8.4Brute-Force Matching with SIFT Descriptors and Ratio Test
我们将使用BFMatcher.knnMatch()来获得k个最佳匹配。在这个例子中,我们将采取k=2
demo:
from turtle import distance
import numpy as np
import cv2 as cv
import matplotlib.pyplot as pltimg1 = cv.imread('image4.png',cv.IMREAD_GRAYSCALE)
img2 = cv.imread('image4.png',cv.IMREAD_GRAYSCALE)# Initiate SIFT detector
sift = cv.SIFT_create()kp1,des1 = sift.detectAndCompute(img1,None)
kp2,des2 = sift.detectAndCompute(img2,None)# BFMatcher with default params
bf = cv.BFMatcher()
matches = bf.knnMatch(des1,des2,k=2)
# print(matches)
# Apply ratio test
good = []
for m,n in matches:if m.distance < 0.75*n.distance:good.append([m])img3 = cv.drawMatchesKnn(img1,kp1,img2,kp2,good,None,flags=cv.DrawMatchesFlags_NOT_DRAW_SINGLE_POINTS)plt.imshow(img3),plt.show()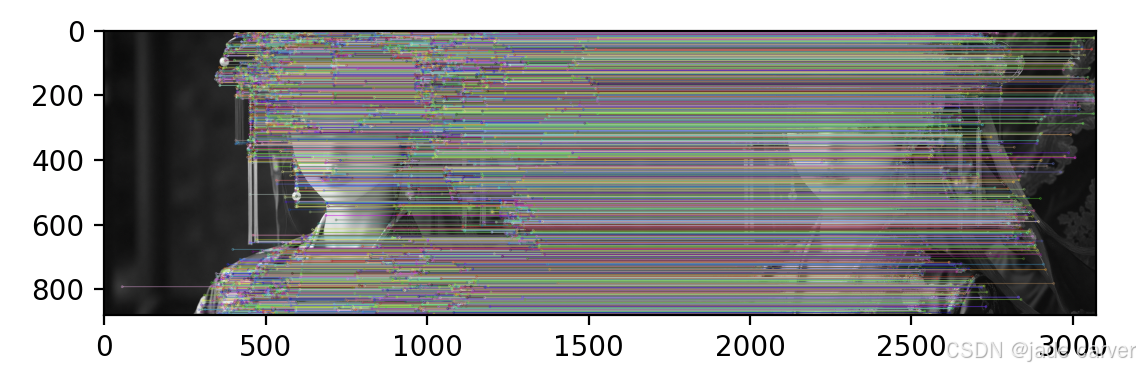
4.8.5基于 FLANN 的匹配器
FLANN 代表快速近似最近邻库(Fast Library for Approximate Nearest Neighbors)。它包含了一系列算法,这些算法针对在大数据集中进行快速最近邻搜索和高维特征进行了优化。对于大型数据集,它比 BFMatcher 工作得更快。我们将看到第二个基于 FLANN 匹配器的例子。
对于基于 FLANN 的匹配器,我们需要传递两个字典,这两个字典指定了要使用的算法及其相关参数等。
第一个是 IndexParams(索引参数)。对于各种算法,需要传递的信息在 FLANN 文档中有说明。总结如下:
对于 SIFT/SURF(浮点型描述符):使用 KDTree 算法,你可以传递以下参数:
FLANN_INDEX_KDTREE = 1
index_params = dict(algorithm = FLANN_INDEX_KDTREE, trees = 5)
trees=5:构建 5 棵 KDTree,搜索时并行查询,提高召回率。对于 ORB/BRIEF(二进制描述符):使用 LSH(局部敏感哈希)算法:
FLANN_INDEX_LSH = 6
index_params = dict(algorithm = FLANN_INDEX_LSH,table_number = 6, # 推荐值:12key_size = 12, # 推荐值:20 multi_probe_level = 1) # 推荐值:2第二个字典是 SearchParams(搜索参数)。它指定了索引中的树应该被递归遍历的次数。值越高精度越好,但也需要更多时间。如果你想改变这个值,可以传递 search_params = dict(checks=100)。search_params(搜索参数)作用是控制搜索的精细程度。checks:指定递归遍历树的次数。值越高,搜索越彻底,找到最近邻的概率越大,但速度越慢。
search_params = dict(checks=50) # 默认值可能是32demo:
from turtle import distance
import numpy as np
import cv2 as cv
import matplotlib.pyplot as pltimg1 = cv.imread('image4.png',cv.IMREAD_GRAYSCALE)
img2 = cv.imread('image4.png',cv.IMREAD_GRAYSCALE)# Initiate SIFT detector
sift = cv.SIFT_create()kp1,des1 = sift.detectAndCompute(img1,None)
kp2,des2 = sift.detectAndCompute(img2,None)# FLANN parameters
FLANN_INDEX_KDTREE = 1
index_param = dict(algorithm =FLANN_INDEX_KDTREE,tree = 5)
search_param = dict(checks=50)flann = cv.FlannBasedMatcher(index_param,search_param)matches = flann.knnMatch(des1,des2,k=2)# Need to draw only good matches, so create a mask
matchesMask =[[0,0] for i in range(len(matches))]# ratio test as per Lowe's paper
for i,(m,n) in enumerate(matches):if m.distance < 0.9*n.distance:matchesMask[i]=[1,0]draw_params = dict(matchColor = (0,255,0),singlePointColor = (255,125,0),matchesMask = matchesMask,flags = cv.DrawMatchesFlags_DEFAULT)img3 = cv.drawMatchesKnn(img1,kp1,img2,kp2,matches,None,**draw_params)plt.imshow(img3,),plt.show()
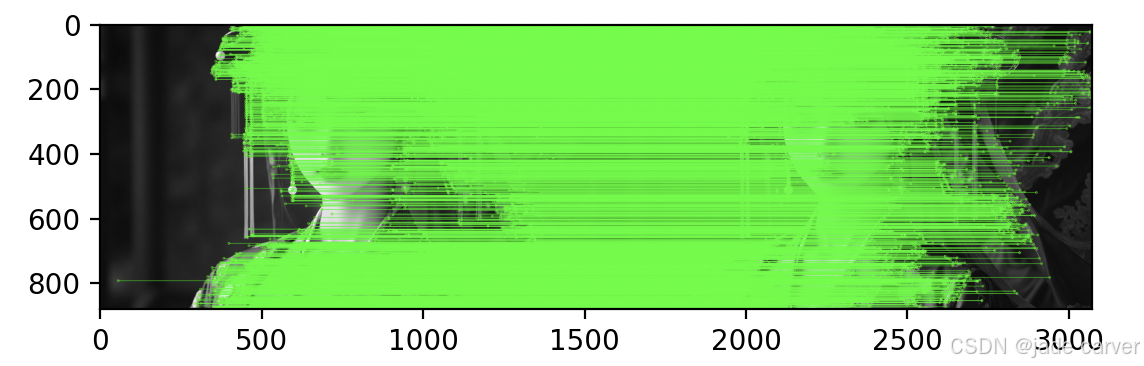
4.9Feature Matching + Homography to find Objects
给定两张有重叠区域的图像(比如从不同角度拍摄的同一本书、同一栋建筑),本节目标是通过特征匹配找到它们之间的对应点,并计算出一个变换矩阵(单应性矩阵),从而可以将一张图像“投影”或“对齐”到另一张图像的视角上。


cv.findHomography() - 计算变换矩阵
作用: 根据一系列对应的点对,计算出描述两个平面之间透视变换关系的 3x3 单应性矩阵 (H)。
H, mask = cv.findHomography(srcPoints, dstPoints, method=0, ransacReprojThreshold=3.0, maxIters=2000, confidence=0.995)
参数详解:srcPoints: 源平面中点的坐标。通常是第一张图像(查询图像)中的关键点坐标。形状为 (N, 1, 2) 的 NumPy 数组,其中 N 是点的数量。
dstPoints: 目标平面中点的坐标。与 srcPoints 一一对应。是第二张图像(训练图像)中的关键点坐标。形状必须与 srcPoints 相同。
method: 计算 H 矩阵的方法。
0: 常规方法,使用所有点。如果存在错误匹配(离群点),结果会非常差。
cv.RANSAC (推荐): 使用 RANSAC 算法。这是一种鲁棒的方法,即使输入的点对中存在大量错误匹配,它也能估算出正确的模型。它会找出一个最能符合内点 (inliers) 的模型。
cv.LMEDS: 最小中值方法。
ransacReprojThreshold: 仅当 method=cv.RANSAC 时有效。它是一个距离阈值(单位为像素),用来判断一个点是否是内点。这个参数很重要!
原理: 对于每一个点,算法使用计算出的 H 矩阵将 srcPoint 变换到目标平面,得到一个预测点。然后计算这个预测点与真实的 dstPoint 之间的欧氏距离。如果这个距离小于 ransacReprojThreshold,则该点被标记为内点。
如何设置: 值越大,能容忍的误差越大,被认为是内点的点就越多(可能包含一些错误点)。值越小,要求越严格,内点越少但更精确。通常设置在 1.0 到 10.0 之间,具体取决于你匹配的精度和图像分辨率。
maxIters: RANSAC 的最大迭代次数。
confidence: 置信度,表示算法期望找到的内点比例。
返回值:H: 计算得到的 3x3 单应性矩阵。如果没有找到解,则返回 None。
mask: 可选输出(尤其在使用 cv.RANSAC 或 cv.LMEDS 时非常有用)。它是一个形状为 (N, 1) 的数组,其中元素为 0 或 1。
mask[i] == 1: 表示第 i 对点被算法判定为内点,即它符合最终计算出的 H 模型。
mask[i] == 0: 表示第 i 对点是外点 (outlier),即错误匹配。cv.perspectiveTransform() - 应用变换矩阵
作用: 对一个或多个点执行透视变换。它使用一个已经计算好的变换矩阵(比如由 cv.findHomography() 得到的 H),将输入的点从源空间变换到目标空间。
dst = cv.perspectiveTransform(src, m)
参数详解:src: 输入的点集。可以是单个点 [x, y],但更常见的是多个点的集合。其形状必须是 (N, 1, 2),其中 N 是点的数量。注意: 这里的点坐标是 (x, y),而不是图像索引 (row, col)。
m: 变换矩阵。对于透视变换,这就是一个 3x3 的矩阵(例如单应性矩阵 H)。
返回值:dst: 变换后的点集。形状与 src 相同,为 (N, 1, 2)。核心区别与联系:厨师与食谱的比喻
| 特性 | cv.findHomography() | cv.perspectiveTransform() |
|---|---|---|
| 角色 | 厨师 (Chef) | 学徒 (Apprentice) |
| 任务 | 创造食谱 (H矩阵)。根据一些原材料(对应点对srcPoints, dstPoints),研究出烹饪的配方和步骤(计算变换矩阵 H)。 | 执行食谱。已经拿到了厨师写好的详细食谱(H 矩阵),只需要按照食谱把新的原材料(新的点集 src)做熟(变换)即可。 |
| 输入 | 两套对应的点集 | 一套点集 + 一个变换矩阵 |
| 输出 | 一个变换矩阵 (+ 内点掩码) | 变换后的点集 |
| 过程 | 复杂的数学计算和优化(如 RANSAC) | 直接的矩阵乘法运算 |
demo:输入两张图像,计算单应性矩阵:
我们设置一个条件,即至少有10个匹配(由MIN_MATCH_COUNT定义)在那里找到对象。否则,只需显示一条消息,说没有足够的匹配。
如果找到足够的匹配项,我们将提取两个图像中匹配的关键点的位置。他们通过寻找透视转换。一旦我们得到这个3x3变换矩阵,我们就用它来将queryImage的角转换为trainImage中的相应点。然后我们画它。
import numpy as np
import cv2 as cv
import matplotlib.pyplot as pltMIN_MATCH_COUNT = 10# 读取图像 - 注意:应该是两张不同的图像!
# 例如:img1 = 'object.png', img2 = 'scene_with_object.png'
img1 = cv.imread('image1.png', cv.IMREAD_GRAYSCALE) # 查询图像(小物体)
img2 = cv.imread('image2.png', cv.IMREAD_GRAYSCALE) # 训练图像(包含物体的场景)# 检查图像是否成功加载
if img1 is None or img2 is None:print("错误:无法加载图像!请检查文件路径。")exit()# Initiate SIFT detector
sift = cv.SIFT_create()# find the keypoints and descriptors with SIFT
kp1, des1 = sift.detectAndCompute(img1, None)
kp2, des2 = sift.detectAndCompute(img2, None)# 使用FLANN匹配器
FLANN_INDEX_KDTREE = 1
index_params = dict(algorithm=FLANN_INDEX_KDTREE, trees=5)
search_params = dict(checks=50)flann = cv.FlannBasedMatcher(index_params, search_params)# 进行KNN匹配
matches = flann.knnMatch(des1, des2, k=2)# store all the good matches as per Lowe's ratio test.
good = []
for m, n in matches:if m.distance < 0.7 * n.distance:good.append(m)if len(good) > MIN_MATCH_COUNT:src_pts = np.float32([kp1[m.queryIdx].pt for m in good]).reshape(-1, 1, 2)dst_pts = np.float32([kp2[m.trainIdx].pt for m in good]).reshape(-1, 1, 2)M, mask = cv.findHomography(src_pts, dst_pts, cv.RANSAC, 5.0)matchesMask = mask.ravel().tolist()h, w = img1.shape # 修正这里# 定义源图像的四个角点pts = np.float32([[0, 0], [0, h-1], [w-1, h-1], [w-1, 0]]).reshape(-1, 1, 2)dst = cv.perspectiveTransform(pts, M)# 在目标图像上绘制变换后的边界框img2_with_box = cv.polylines(img2, [np.int32(dst)], True, 255, 3, cv.LINE_AA)print(f"找到 {len(good)} 个良好匹配,其中 {sum(matchesMask)} 个是内点")else:print(f"未找到足够匹配 - {len(good)}/{MIN_MATCH_COUNT}")matchesMask = Noneimg2_with_box = img2 # 如果没有找到足够匹配,使用原始图像draw_params = dict(matchColor=(0, 255, 0), # draw matches in green colorsinglePointColor=None,matchesMask=matchesMask, # draw only inliersflags=cv.DrawMatchesFlags_NOT_DRAW_SINGLE_POINTS)# 绘制匹配结果
img3 = cv.drawMatches(img1, kp1, img2_with_box, kp2, good, None, **draw_params)# 显示结果
plt.figure(figsize=(15, 10))
plt.imshow(img3, cmap='gray')
plt.title('特征匹配与单应性变换结果')
plt.axis('off')
plt.show()
参考:OpenCV: Feature Detection and Description




)



:Tomcat 企业级监控)






)
)


