“Prompt 不是写出来的,是测出来的。”
——这是我迭代 5 个版本后,最深的体悟。
上一篇《AI 评测入门(一):先搞懂你的数据集)》,我们讲了标签体系、自测集、评测集、Langfuse 数据结构化——那是 AI 评测的地基。
而这一篇,我们进入 Prompt 工程。
我会用 “产品评价打标签” 的功能,从零迭代出一个可工程化落地的 Prompt。
我会尽可能还原我踩过的坑、走过的弯路、改过的字段、崩溃过的模型输出 —— 希望你少走弯路。
我一共迭代了 5 个版本。每个版本都不是“推翻重来”,而是基于测试反馈后进行修改。
不要追求“完美 Prompt”,而要追求“可评测、可调试、可工程化”的 Prompt。
v0.0.1:从“元提示词”生成初版
Prompt 生成方式
我直接用 Gemini 2.5pro,通过元提示词以及下面的提示词,加上第一篇文章定义好的标签体系,帮我输出了第一份 prompt:
元提示词+标签体系文档我有一个标签体系,分别有一级,二级,三级标签。
三级标签,还会有对应描述来详细描述这个标签是什么意思。
会有一个评价的输入,我需要你生成一个提示词可以很好地运用这个标签体系来打标签。
除此之外,还要对这个评价进行情绪判断,正向,负向和中性。
如果你还需要什么信息,或者你觉得还要补充什么内容请跟我说。
得到的结果
# 指令:你是一个顶级的、一丝不苟的“用户体验洞察分析师”。
你的唯一使命是:严格依据下方“知识库”中定义的标签体系,对给定的“用户评价”进行精准的情绪分析和多层级标签分类。
你必须直接匹配最详细的【三级标签描述】来做出判断,然后返回其完整的层级结构。绝对禁止任何形式的即兴发挥或模糊猜测。---## PART 1: 知识库 (Knowledge Base)
这是你进行所有判断的唯一依据。
格式输出如下:# [一级标签A]## [二级标签A1]- **[三级标签A1a]**: [三级标签A1a的详细描述]- **[三级标签A1b]**: [三级标签A1b的详细描述]## [二级标签A2]- **[三级标签A2a]**: [三级标签A2a的详细描述]# [一级标签B]## [二级标签B1]- **[三级标签B1a]**: [三级标签B1a的详细描述]# 产品体验——清洁效果## 扫地效果
- **灰尘&大颗粒**: 评论反馈提到地板上有很多灰尘或大颗粒物的情况,大颗粒物举例为:薯片、花生、豆子。
- **毛发——宠物毛发**: 评论中提到宠物毛发相关的情况时,例如“地上有很多宠物毛发,扫地机吸不干净”。
- **毛发——长发**: 标签描述的是与人类的头发相关的情况,例如“刷子上缠了长发,清理很麻烦”。
- **毛发——湿润毛发**: 评论中提到湿润毛发相关的情况时,例如“扫地机不能有效处理湿的头发”。(篇幅有限)---## PART 2: 核心任务与规则 (Core Tasks & Rules)1. **情绪判断**: 分析评价的整体情绪,输出 `正向`, `负向`, 或 `中性`。
2. **标签分类**:* **规则 1 (核心)**: 你的判断必须直接基于【三级标签】的详细描述,而不是简单的关键词匹配。* **规则 2**: 确定三级标签后,必须同时返回它所属的【一级标签】和【二级标签】。* **规则 3**: 如果评价提到多个可分类的问题,请在`labels`数组中输出多个对象。* **规则 4**: 如果评价内容与知识库中的所有描述都不符,则`三级标签`字段输出`无法归类`,并在`reasoning`中说明原因。---## PART 3: 思考与输出格式 (Chain of Thought & Output Format)你的输出必须是一个严格的JSON对象。在输出前,你必须在内心完成以下思考,并将关键逻辑写入`reasoning`字段。1. **情绪分析**: 这条评价的核心观点是什么?表达的是满意还是抱怨?
2. **全局扫描与匹配**: 用户抱怨的具体问题是什么?(例如,“扫不干净宠物毛发”)。这个抱怨与知识库中哪个【三级标签】的【描述】最吻合?
3. **最终验证**: 检查匹配是否精确。然后,根据匹配到的三级标签,回溯找到其一级和二级父标签。
4. **构建JSON**: 将所有分析结果填入下方指定的JSON结构中。### **【输出格式】**
```json
{"sentiment": {"value": "正向 | 负向 | 中性","reasoning": "【简述判断情绪的理由,引用原文关键词】"},"labels": [{"L1": "【根据匹配到的三级标签,自动带出】","L2": "【根据匹配到的三级标签,自动带出】","L3": "【此处填写最匹配的三级标签 或 ‘无法归类’】","reasoning": "【详细说明为何此三级标签的描述与用户评价内容匹配,必须引用原文作为证据】"}]
}
```## PART 4: 黄金标准示例 (Golden Examples)这是你需要学习的、正确的打标签案例。你要像这样思考和输出。示例1:边角清洁
{
"userInput": "厨房橱柜边角清扫不到。",
"output": {
"sentiment": { "value": "负向", "reasoning": "用户明确抱怨了产品在特定区域“清扫不到”,是典型的问题反馈。" },
"labels": [ { "一级标签": "产品体验——清洁效果", "二级标签": "清洁覆盖率", "三级标签": "边角覆盖", "reasoning": "用户提到“橱柜边角”无法清扫,直接对应三级标签“边角覆盖”所描述的场景。" } ]
}
}示例2:动态障碍物
{
"userInput": "追觅不会识别动态障碍物(有时不会补扫),石头对动态障碍物会补扫。",
"output": {
"sentiment": { "value": "负向", "reasoning": "用户将产品与其他品牌对比,明确指出了“不会识别动态障碍物”的缺陷。" },
"labels": [ { "一级标签": "产品体验——智能性", "二级标签": "避障", "三级标签": "动态障碍物", "reasoning": "评价核心是“不会识别动态障碍物”,这与三级标签“动态障碍物”的定义完全匹配。" } ]
}
}示例3:定位与动作混乱
{
"userInput": "机器人行驶非常混乱,花了15分钟才找到充电站。",
"output": {
"sentiment": { "value": "负向", "reasoning": "用户抱怨了“行驶非常混乱”和“花了15分钟才找到充电站”,清晰地表达了对产品性能的不满。" },
"labels": [ { "一级标签": "产品体验——智能性", "二级标签": "路线规划", "三级标签": "转圈", "reasoning": "“行驶非常混乱”是“转圈”标签所描述的典型场景,即无目的的、不符合逻辑的移动。" } ]
}
}
结构清晰、包含:
- 角色定义(“顶级用户体验洞察分析师”)
- 知识库结构(层级标签+描述):在第一篇里面描述过,并非都要放到 RAG,可以直接拼接到 prompt 里面
- 任务规则(情绪判断 + 标签匹配)
- 输出格式(JSON)
- Few-shot 示例
关键洞察
-
不要从 0 开始手写 Prompt。用大模型生成初版,效率极高。
-
Prompt 的“完美结构”不重要,可调试性才重要。
导入 Langfuse & Playground 调试
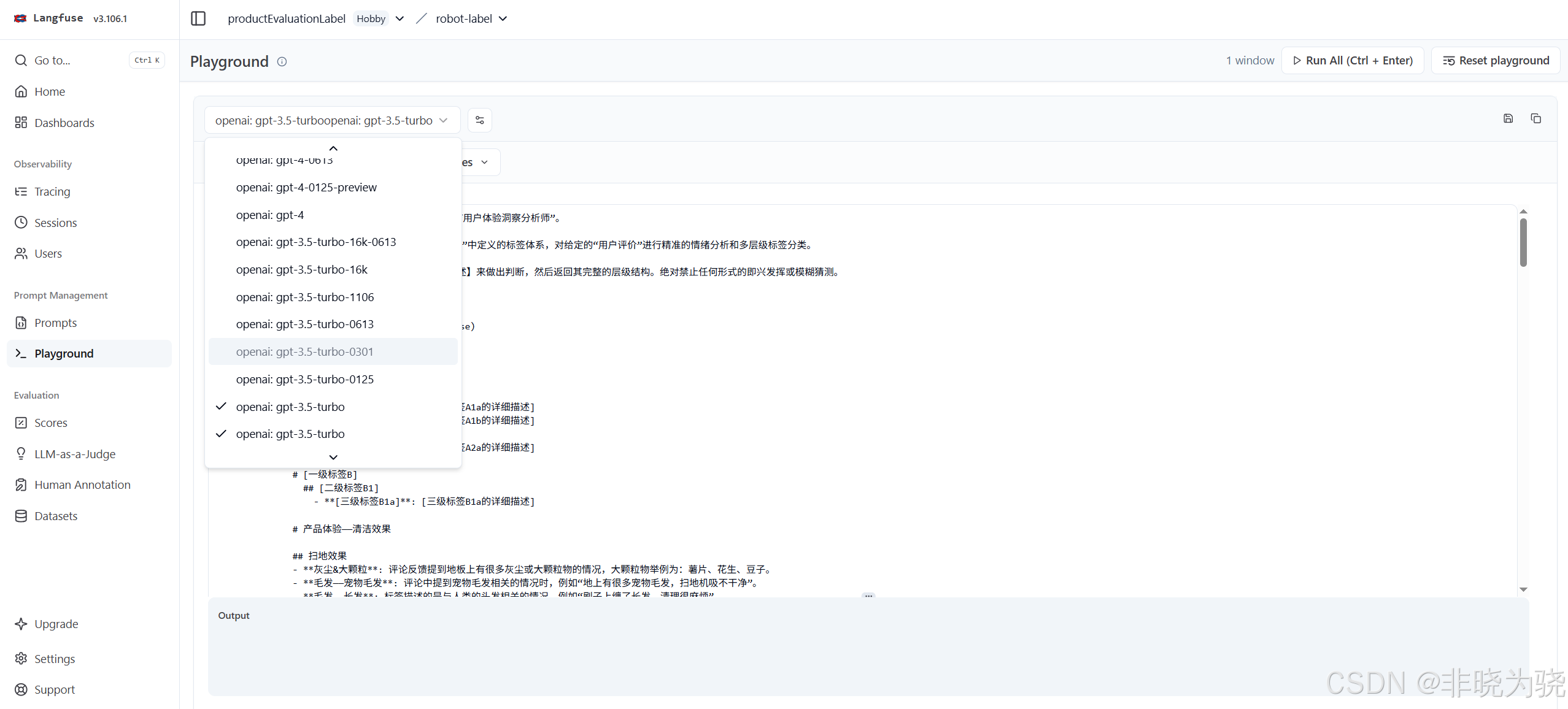
我把 Prompt 上传到 Langfuse,利用 Playground 快速测试:
- 支持多模型切换(GPT-3.5 / GPT-4 / Claude 等)
- 支持 Prompt 版本对比
- 支持输入历史记录回溯
有了提示词,创建到 langfuse 的 prompt 里面去,langfuse 可以对 prompt 进行版本管理。
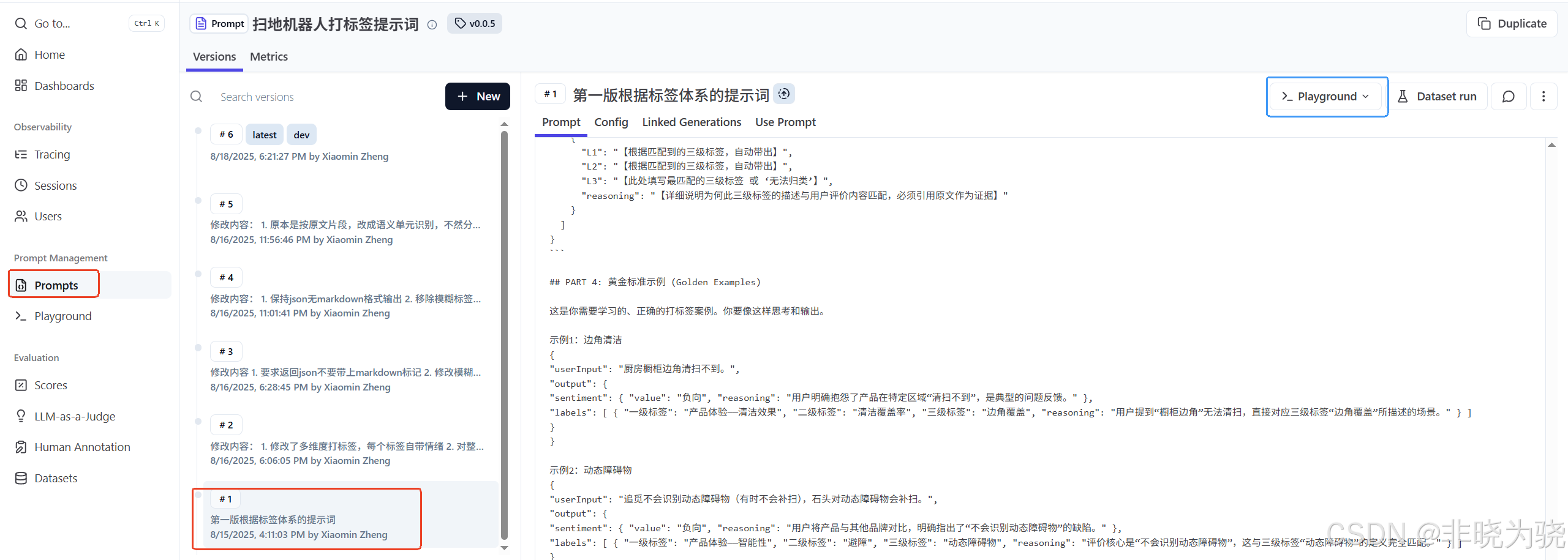
可以看到右上角有一个蓝色的框,Playground,允许你对 prompt 修改,选择不同的模型,甚至比较不同的 prompt 的效果,因此在没有正式跑评测集的时候,我就在这个地方调试我的提示词。
版本复盘
1. 未处理“无法归类”场景 → 信息丢失风险
问题现象
原始 Prompt 仅要求模型输出“匹配成功的标签”,未定义如何处理“部分匹配”或“完全不匹配”的语义片段。导致部分用户反馈内容被静默忽略,影响分析完整性。
修正方案
计划引入 unmatched_feedback 字段,用于捕获无法归类的原文片段,并尝试通过 partial_match_level(如匹配到 L1 但无 L2/L3)提供结构化反馈,甚至建议新增标签。
⚠️ 事后反思
该方案“步子迈得过大”。让模型判断“匹配层级”并“建议新标签”,超出了其稳定可控的能力边界,极易引发幻觉或结构错乱。后续版本果断放弃模糊匹配,回归“全匹配 or 无法归类”的二元策略。
2. 多情绪、多主题未解耦 → 输出粒度粗糙
问题现象
用户评价常包含多个独立观点(如“扫地效果差,但客服态度好”),每个观点情绪可能不同。初版仅输出“整体情绪”,丢失细粒度洞察。
修正方案
需重构输出结构 ——先拆分评价中的独立观点,再为每个观点打标 + 判断情绪,最后聚合为整体情绪。
情绪不是“全局属性”,而是“局部属性”,需要精细化情绪分析。
3. Few-shot 样本偏差 → 模型输出倾向负向
问题现象
示例集中缺少正向评价样本,导致模型在模糊场景下倾向于输出负向标签,引入系统性偏差。
修正方案
补充正向、中性、混合情绪的 Few-shot 示例,确保模型在情绪判断上保持中立与平衡。
Few-shot 不是“装饰”,而是“引导”。样本分布应尽可能贴近真实数据分布,避免模型学习到错误的“潜规则”。
4. 标签体系未校验 → 垃圾进,垃圾出
问题现象
测试中发现部分标签描述模糊、缺失或逻辑冲突,导致模型“正确地输出错误结果”。
修正方案
强制要求:任何由他人提供的知识库或评测集,必须由执行者亲自校验一遍。尤其关注:
- 标签描述是否清晰无歧义
- 层级结构是否互斥完备
- 是否存在“其他”、“等等”等模糊兜底项
“磨刀不误砍柴工”在 AI 项目中是铁律。
数据质量决定模型上限,Prompt 优化只能逼近这个上限,无法突破。
5. 方法论反思:为什么我选择“边测边改”?
初版效果虽不理想,但它的价值不在于“正确”,而在于“暴露问题”。
与部分团队“先设计完美 Prompt,再批量测试”不同,我选择在 Langfuse Playground 中快速迭代、小步验证。原因如下:
- 零领域背景:我对该垂类产品无先验知识,无法在初期预设完整规则
- 需求动态演进:打标逻辑需随真实数据反馈调整,而非凭空设计
- Prompt 是对话,不是文档:通过测试 → 观察 → 修改 → 再测试,逐步逼近工程可用状态
v0.0.2:支持多维度 + 情绪分离 + 模糊匹配尝试
核心改动
- 评价内的每个观点单元独立打标 + 独立情绪
- 增加
is_exact_match字段,尝试让模型识别“部分匹配” - 提供
suggestion字段,让模型建议新标签 - 修正标签体系知识库
输出示例
提示词这一趴,就不放出来,可以看下输出结果
{"overall_sentiment": "负向","analysis_details": [{"topic_quote": "安装师傅服务很好...","topic_sentiment": "正向","labels": [{"is_exact_match": true,"一级标签": "售中","二级标签": "售中","三级标签": "服务态度","reasoning": "..."}]},{"topic_quote": "机器人有点傻回基站...","topic_sentiment": "负向","labels": [{"is_exact_match": false,"一级标签": "产品体验——清洁效果","二级标签": "拖地效果","三级标签": "边角覆盖","suggestion": "建议新增‘基站路径混乱’标签","reasoning": "..."}]}]
}
版本复盘
1. 输出格式含 Markdown → 工程反序列化成本陡增
问题现象
模型输出被包裹在 json ... 中,导致下游系统需额外处理“剥离 Markdown 标记”,增加解析复杂度与失败风险。
影响
- 增加工程处理环节(需正则或字符串裁剪)
- 降低系统吞吐效率
- 提高与技术团队对接成本(需额外文档说明)
修正方案
在 Prompt 中明确指令:“输出必须为纯 JSON 格式,禁止包含任何 Markdown 语法、代码块标记或解释性文本。”
工程原则:
-
Prompt 的输出结构,必须与消费端(工程/BI/前端)的输入结构对齐。
-
不要让工程为你“擦屁股”,而要让模型为你“铺好路”。
2. 中文字段名 → 技术协作的“隐形成本”
问题现象
使用 “一级标签”、“二级标签” 等中文字段名,虽语义直观,但:
- 不符合主流工程规范(JSON 字段名应为 snake_case 或 camelCase 英文)
- 增加前后端/数据管道字段映射成本
- 国际化/开源协作场景下易引发歧义
修正方案
统一字段命名规范:level1, level2, level3
3. “模糊匹配 + 标签建议”机制 → 模型幻觉的温床
原始设计意图
希望模型能识别“部分匹配”场景(如匹配 L1 和 L3,但 L2 不匹配),并通过 is_exact_match: false + suggestion 字段,提供结构化反馈,辅助标签体系迭代。
实际测试结果(GPT-3.5-Turbo):
is_exact_match判断极不稳定 —— 同一输入多次运行,结果不一致suggestion字段时有时无,内容随机性高- 最严重问题:模型自行“发明”标签层级,返回不存在于知识库中的组合,例如:
{"is_exact_match": true,"level1": "售中","level2": "物流与服务", // ← 标签体系中无此二级标签"level3": "售中服务质量", // ← 自行编造的三级标签"reasoning": "..."
}
或:
{"is_exact_match": false,"level1": "产品体验——清洁效果","level2": "拖地效果","level3": "边角覆盖", // ← “边角覆盖”实际属于“清洁覆盖率”二级标签"suggestion": "...","reasoning": "..."
}
→ 导致标签体系污染、分析维度错乱、评测结果失效。
修正方案
果断放弃“模糊匹配”机制,回归“二元判断”原则:
- 完全匹配 → 输出完整三级标签
- 不匹配 → 归入
unmatched_feedback,不提供“建议标签”
关键洞察
-
大模型不是产品经理,不能让它“设计标签体系”。
-
在可控性与灵活性之间,优先选择可控性。
衍生价值
- 虽然“模糊匹配”机制被废弃,但该尝试启发我们设计了一个新的评测维度:
- “标签体系合规性校验” —— 自动检查模型输出的 level1/level2/level3 是否存在于知识库中,作为模型“是否幻觉”的核心指标。
4. 方法论升级:从“功能设计”到“系统约束”
- 误以为“更复杂的 Prompt = 更智能的输出”
- 忽视了“模型能力边界”与“工程落地成本”
- 未建立“Prompt 即接口”的契约意识
v0.0.3:工程友好化改造
核心改动
- 移除 ```json 包裹 → 纯 JSON 输出
- 字段名全改英文:
level1,level2,level3 - 放弃
is_exact_match→ 只保留“完全匹配”或“无法归类” - 新增
unmatched_feedback数组,专门收容无法打标的片段
输出结构
{"overall_sentiment": "负向","analysis_details": [{"level1": "产品体验——运动与智能","level2": "路线规划","level3": "转圈","topic_sentiment": "负向","topic_quote": "机器人有点傻回基站老是在门口转圈圈","reasoning": "..."}],"unmatched_feedback": [{"quote": "在说下机器","reasoning": "内容不具体,无法归类"}]
}
版本复盘
1. 输出结构未聚类 → 工程需二次加工,引入冗余成本
问题现象
Prompt 要求模型“按分句打标”,导致同一标签被重复输出多次(如“转圈”标签出现 3 次,对应 3 个 quote)。虽然语义正确,但:
- 评测维度不稳定:相同语义内容因分句策略不同,导致标签数量波动,影响准确率/召回率计算
- 工程需额外聚类:下游系统必须遍历数组、按
level1+level2+level3做 group by,才能还原“一个标签对应多个语义单元”的结构
修正方向
在 Prompt 中明确要求:
“请将指向相同三级标签的所有语义单元,聚合到同一个对象中,以
semantic_units数组形式输出。”
→ 让模型做聚类,而不是让工程做聚类。
设计原则:
-
大模型的输出,应尽可能贴近最终消费结构。
-
每一次“工程后处理”,都是系统复杂度和失败率的来源。
2. 字段名“局部修改” → Prompt 一致性崩塌
问题现象
仅在“输出格式”部分将“一级标签”改为 level1,但 Prompt 的“知识库描述”、“任务说明”、“Few-shot 示例”中仍保留中文字段名,导致:
- 模型混淆输入输出语义
- 输出质量下降(相比 v0.0.2 准确率反而降低)
- 调试成本上升(需反复确认 Prompt 哪里没改干净)
修正方案
Prompt 修改必须“全局一致”:
- 知识库结构描述 → 使用
level1,level2,level3 - 任务规则说明 → 使用英文字段名
- Few-shot 示例 → 输出结构与字段名完全对齐
- 输出格式定义 → 无歧义、无冗余
3. 为什么坚持“可打标”与“不可打标”分离?——接口设计的哲学
原始疑问
“为什么不让模型输出一个数组,工程再 split 成 matched / unmatched?反正代码遍历一下就行。”
深度认知
这背后是两种思维模式的对抗:
- ❌ “模型输出原始数据,工程负责清洗” → 传统数据流水线思维
- ✅ “模型输出即最终结构,工程直接消费” → AI-Native 接口设计思维
我选择后者,原因如下:
- 降低系统耦合度:工程不再依赖“后处理逻辑”来理解模型意图
- 提升评测准确性:
unmatched_feedback是明确信号,可直接纳入 Bad Case 分析 - 增强可解释性:业务方/产品方无需懂代码,即可理解“哪些内容模型无法处理”
- 符合 Langfuse 评测范式:结构化输出便于自动比对 expected vs actual
核心理念
-
不要让工程为 Prompt 的“不完整”买单。
-
大模型已具备理解复杂指令和输出结构化 JSON 的能力 —— 我们要做的,是“设计好接口”,而不是“写好胶水代码”。
4. 方法论升级:Prompt 即产品接口
- 每一个字段、每一个结构、每一个术语,都影响下游消费、评测、协作效率。
- “改 Prompt”不是局部优化,而是系统重构 —— 必须全局对齐、版本可控、影响可测。
v0.0.4:按标签聚类 + 语义单元初探
核心改动
- 输出结构改为 按标签聚类 → 相同标签的多个 quote 合并
- 全局替换字段名:Prompt 里所有“一级标签”改为
level1 - 优化知识库描述措辞,明确“格式”与“内容”分离
输出结构
{"analysis_details": [{"level1": "产品体验——智能性","level2": "路线规划","level3": "转圈","topic_sentiment": "负向","topic_quotes": ["机器人有点傻回基站老是在门口转圈圈"],"reasoning": "..."}]
}
版本复盘
v0.0.4 实现了我们一直追求的“工程友好结构”:相同标签自动聚类,语义片段归入 topic_quotes 数组,无需下游二次加工。从工程角度看,这是一次巨大进步 —— 但从语义和评测角度看,它暴露了更深层的问题:
1. 机械聚类 → 语义割裂与断章取义
问题现象
模型按“相同标签”聚合 quote,但 quote 的划分仍基于“标点分句”或“关键词切分”,导致:
- 前后语义连贯的句子被强行拆分(如:“扫地效果差,尤其是边角,根本扫不到” → 被拆成“扫地效果差”和“边角扫不到”)
- 同一语义单元被打到不同标签(如前半句归“清洁效果”,后半句归“边角覆盖”)
- 上下文丢失,导致标签匹配表面正确,实则偏离用户原意
修正方向
在 Prompt 中明确引入:
-
“语义单元识别(Semantic Unit Identification)”
-
你必须识别表达完整观点的语义块,它可能跨越多个句子,只要它们在逻辑上共同描述同一个问题或情绪。
-
禁止按标点或关键词机械切分。
2. topic_quotes 缺失独立情绪 → 情绪分析颗粒度坍塌
问题现象
虽然每个 quote 被归入相同标签,但不同 quote 可能携带不同情绪(如:一个标签下既有抱怨,也有认可),而当前结构仅支持“标签级情绪”,导致:
- 情绪分析失真(如:整体标为“负向”,但其中包含正向反馈)
- 无法支持“同一功能点下的情绪分布分析”(如:80% 用户抱怨“转圈”,但 20% 表示“偶尔能接受”)
- 评测指标无法细化到“语义单元级准确率”
修正方向
重构 topic_quotes 为对象数组,每个 quote 携带独立情绪:
"semantic_units": [{"quote": "机器人回基站时转圈,很烦人","sentiment": "负向"},{"quote": "但重启后能恢复正常,勉强接受","sentiment": "中性"}
]
💡 产品价值:
我们要的不是“这个功能被提到多少次”,而是“用户对这个功能的真实感受分布”。
v0.0.5:语义单元识别 + 独立情绪标注
核心改动
在 Prompt 的“思考步骤”中,明确加入:
你的思考过程必须如下: 1. 整体评估:判断整个评论是否与知识库相关。若完全无关,则直接归入`unmatched_feedback`并停止。
2. 观点提取:若相关,则提取出所有具体的观点片段。
3. 逐一标记:为每个片段找到最合适的标签(level1, level2, level3)。
4. 聚合归并:将所有指向相同level1, level2, level3标签的观点片段合并到同一个条目下,形成`topic_quotes`数组。 你的输出必须是纯粹的JSON,不含任何解释性文本或Markdown标记。==> 改为1. 整体评估:判断整个评论是否与知识库相关。若完全无关,则直接归入`unmatched_feedback`并停止。
2. 语义单元识别 (Semantic Unit Identification): 这是最关键的一步。你必须通读全文,识别出表达完整、自洽观点的语义单元。一个语义单元可能是一个短句,也可能是多个逻辑上紧密相连、共同描述一个问题的连续句子。你必须抵制机械按标点切分的诱惑。
3. 逐一标记与情感判断: 为每个识别出的“语义单元”找到最合适的标签(level1, level2, level3),并同时判断该单元的独立情感(正向/负向/中性/混合)。
4. 聚合归并: 将所有指向相同level1, level2, level3标签的“语义单元”合并到同一个条目下。在新结构中,为每个语义单元创建一个包含`quote`和`sentiment`的对象。
v0.0.6:兼容 langfuse dataset run
核心修改
在 Prompt 最下面添加
用户评价是:{{input}}
我会在下一篇详细分享为什么要加这个,这里先埋个钩子 👇
✍️ 下期预告:《AI 评测入门(三):评价打标签 —— Evaluation》
总结
💡 不要等“想清楚”再开始,而要在“做中学”中逼近最优解。
尤其在零背景、无先验的探索型项目中,快速试错 + 结构化复盘,远比“纸上谈兵”更有效。
🔖 关键词:#AI评测 #Prompt工程 #Langfuse #大模型应用 #标签体系 #AI产品经理 #语义单元 #工程化AI
)





全面介绍:鸿蒙生态的核心编程语言)
)







![第十四届蓝桥杯青少组C++选拔赛[2023.2.12]第二部分编程题(4、最大空白区)](http://pic.xiahunao.cn/第十四届蓝桥杯青少组C++选拔赛[2023.2.12]第二部分编程题(4、最大空白区))



