一、Hash类型简介
Redis的Hash类型是 Redis 3.2 版本引入的一个数据结构,它允许你在一个键下面存储多个字段和值。在 Redis 内部,Hash 类型可以有多种底层数据结构来实现,这取决于存储的数据量和特定的使用模式。哈希类型适用于存储对象,例如用户信息、商品详情等。通过使用哈希,可以更方便地对数据进行操作和查询。
Hash的底层数据结构在早期版本使用ZipList(压缩列表)和HashTable,在某些版本中(尤其是较新版本),Redis 可能还会使用 Quicklist 作为 Hash 类型的底层数据结构。Quicklist 是 ziplist 和 linkedlist(链表)的混合体,它通过多个 ziplist 节点组成一个链表来提高大数据量下的性能。Quicklist 提供了更好的性能平衡,特别是在需要频繁插入和删除操作时。在 Redis 7.0 中,ZipList数据结构已经废弃了,交由 ListPack 数据结构来实现了。
二、Hash使用场景
- 存储用户信息:如果你需要存储用户信息,如用户名、邮箱、年龄等,可以使用 Redis Hash 存储。
- 缓存对象:如果你有一个对象需要频繁更新和访问,可以将这个对象的属性以 Hash 的形式存储到 Redis 中。
- 会话存储:可以使用 Redis Hash 存储用户会话信息,如用户的登录状态、购物车内容等。
- 频繁更新的统计数据,如用户积分、访问次数等。
- 程序中的频繁读取和偶尔更新的配置数据。
- 存储地理位置信息的应用(如地图服务),Redis Hash 可以用来存储地点ID、经纬度、地址等信息。
三、底层编码方式
编码方式主要分两部分讲,一个是Redis6中的编码方式,一个是Redis7的编码方式。
在Redis6中,Hash数据结构的底层实现有两种编码方式,分别是ziplist(压缩列表)和hashtable(哈希表),Quicklist 是 ziplist 和 linkedlist(链表)的混合体,它通过多个 ziplist 节点组成一个链表来提高大数据量下的性能。Quicklist 提供了更好的性能平衡,特别是在需要频繁插入和删除操作时。在 Redis 7.0 中,ZipList数据结构已经废弃了,交由 ListPack 数据结构来实现了。
四、Hash底层数据结构
Redis的Hash类型的储存结构,分别是ZipLIst、Quicklis、ListPack和HashTable ,下面对这些结构分别进行分析。
①ZIPLIST底层数据结构
ZipList是经过特殊编码的双向链接列表,对于上面提到的LinkedList链表结构,由于内存中不是连续的,LinkedList多使用指针导致浪费内存空间、内存使用率都较低。为了解决这个问题,引入了 ZipList这种数据结构。 ZipList是一种有顺序、内存连续的数据结构。具备节省内存空间、提升内存使用率,适用于元素数量少且长度比较小的场景。在Redis 7.0版本之前是List、Hash、ZSet底层实现之一,但是自身也存在其他问题,因此在 Redis 7.0后被ListPack完全替换。
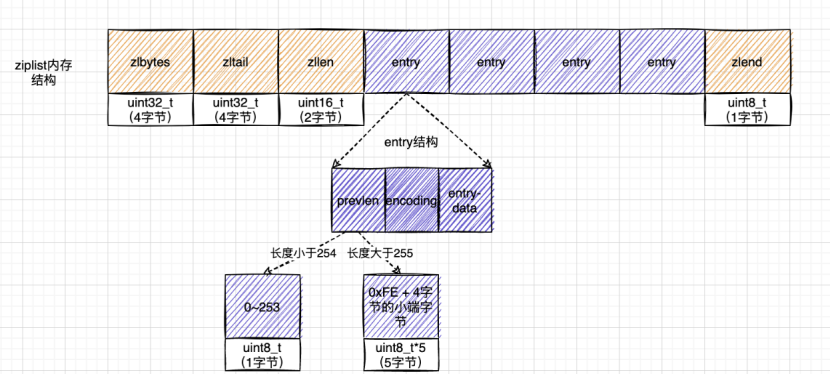
Ⅰ、ZIPLIST类对象
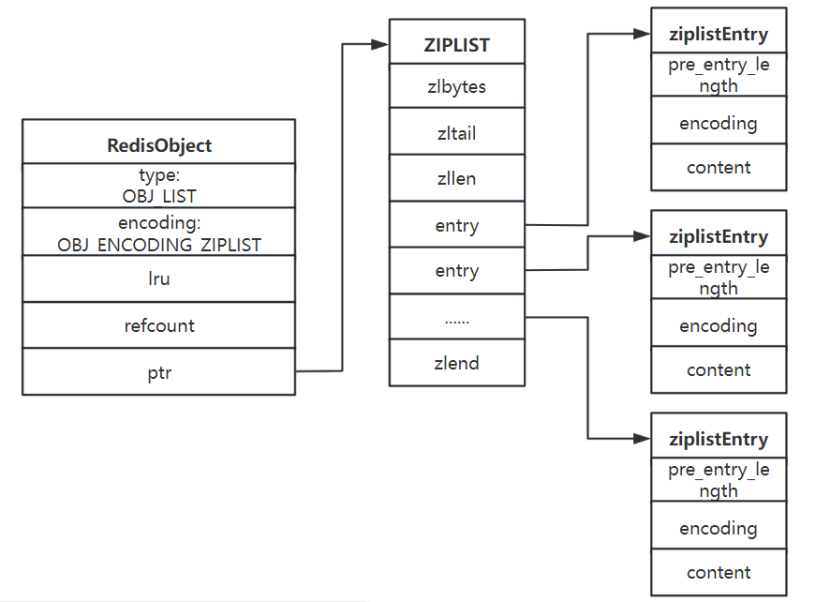
typedef struct ziplist{ /*ziplist分配的内存大小*/ uint32_t zlbytes; /*达到尾部的偏移量 */ uint32_t zltail; /*存储元素实体个数*/ uint16_t zllen; /*存储内容实体元素*/ unsigned char* content[]; /*尾部标识*/ unsigned char zlend;}ziplist;- zlbytes:压缩列表的字节长度。
- zltail:压缩列表尾元素相对于压缩列表起始地址的偏移量(目的是为了直接定位到尾节点,方便反向查询)。
- zllen:压缩列表的元素个数。
- entry:各个节点数据。
- zlend:压缩列表的结尾,占一个字节,一直是0xFF(255)。
Ⅱ、ZIPLIST中节点(entry)类对象
typedef struct ziplistEntry {
unsigned int pre_entry_len; // 前一个entry的长度编码大小
unsigned char encoding; // 节点编码方式
unsigned char *content; // 指向当前entry数据的指针(节点的起始指针)
} ziplistEntry;
- pre_entry_length: 记录了前一个节点的长度,通过这个值,可以进行指针计算,从而跳转到上一个节点。
- 根据编码方式的不同, pre_entry_length 域可能占用 1 字节或者 5 字节:1 字节,如果前一节点的长度小于 254 字节,便使用一个字节保存它的值。5 字节,如果前一节点的长度大于等于 254 字节,那么将第 1 个字节的值设为 254 ,然后用接下来的 4 个字节保存实际长度。
- encoding表示编码类型
字符串类型: 字符串类型有1、2、5三种编码长度,前两位表示编码类型,剩余位表示字符串长度。
00|aaaaaa:存储长度小于等于63byte的字符串。
01|aaaaaa bbbbbbbb:存储长度小于等于16383byte的字符串。
10|...... bbbbbbbb cccccccc dddddddd eeeeeeee:存储长度小于等于4294967295byte的字符串,'.'固定为0。
整数类型:整数类型的编码长度统一位1字节。
1100 0000:表示16位有符号整数,content占用2byte。
1101 0000:表示32位有符号整数,content占用4byte。
1110 0000:表示64位有符号整数,content占用8byte。
1111 0000:表示24位有符号整数,content占用3byte。
1111 1110:表示8位有符号整数,content占用1byte。
1111 0001 - 1111 1101:没有content部分,依次表示整数0-12。
- content: 保存当前entry节点数据,可以是字符串或整数。
Ⅲ、ZIPLIST底层数据结构
Ⅳ、ZIPLIST数据结构存在问题
- 查询效率
数据过多,导致链表过长,可能影响查询性能
- 内存重分配&&连锁更新
ZipList 在更新或者新增时候,如空间不够则需要对整个列表进行重新分配。当新插入的元素较大时,可能会导致后续元素的prevlen 占用空间都发生变化,从而引起「连锁更新」问题,导致每个元素的空间都









)






)


