mysql是最常用的数据库之一,常见的函数用法大家应该都很熟悉,本文主要例举一些相对出现频率比较少的高级用法
(注:需注意mysql版本,大部分高级特性都是mysql8才有的)
多值索引与虚拟列
主要是解决字符串索引问题,光说概念会比较抽象 我们举两个例子来阐述
mysql文档地址:
https://dev.mysql.com/doc/refman/8.4/en/create-index.html#create-index-multi-valued:~:text=%E7%9A%84%E8%AF%A6%E7%BB%86%E4%BF%A1%E6%81%AF%E3%80%82-,%E5%A4%9A%E5%80%BC%E7%B4%A2%E5%BC%95,-InnoDB%E6%94%AF%E6%8C%81%E5%A4%9A
场景一: 我们日常开发中 经常会使用,分隔 (例如userIds), 但是随着数据量和需求的增加,会造成效率问题;终极解决方案是拆表 建立一个新的关系表,但如果涉及改动大,拆表是个大工程;有一个技巧就是将数据升级成json格式,为json字段建立索引;如果代码规范的话 我们只需要修改entity到DTO层的转换,外部都是调用DTO,改动量小很多;
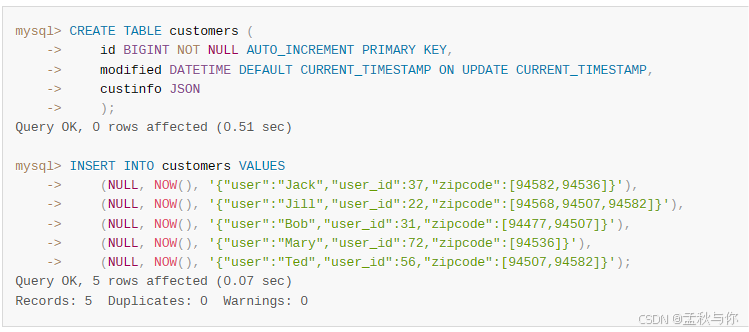
建立索引方式:
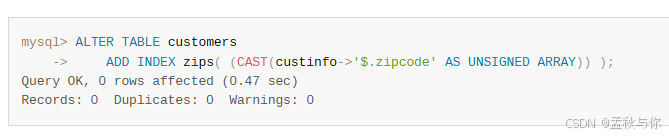
查询方式:
-- 索引方式 ref
SELECT * FROM customers WHERE 94507 MEMBER OF(custinfo->'$.zipcode');
-- 或 (索引方式range)
SELECT * FROM customersWHERE JSON_CONTAINS(custinfo->'$.zipcode', CAST('[94507,94582]' AS JSON));
json数据插入格式:
{"zipcode": [94536, 123]}
场景二: json字符串为普通的k-v 格式,但是我们需要通过对某个字段 例如姓名建立索引
可以建立虚拟列 对虚拟列建立索引
这样可以简化查询代码 (注意 如果是场景一 数组格式的数组要走索引 则不合适)
CREATE TABLE `file_test_phone` (`id` bigint NOT NULL,`name` varchar(255) COLLATE utf8mb4_unicode_ci DEFAULT NULL,`real_phone` json DEFAULT NULL,`phone` varchar(255) COLLATE utf8mb4_unicode_ci GENERATED ALWAYS AS (json_unquote(json_extract(`real_phone`,_utf8mb4'$.phone'))) VIRTUAL,PRIMARY KEY (`id`),UNIQUE KEY `uk_phone` (`phone`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci;
json字段插入数据格式:
{"phone": "123"}
将字符串拼接数据拆分
还是上面场景,如果不打算用这种方式,想要用传统的拆表来实现,拆表很容易,但是会涉及到历史数据迁移问题。
我们假设旧表 user表 有id 和 role_id字段,其中role_id是逗号分隔,

现在希望将role_id拆分出去
我们可以先将逗号拼接的字符串先转成数组字符串:
update user set role_id = concat ('[',role_id,']')

接着用以下语句数据迁移:
INSERT INTO user_role (id,user_id, role_id)
SELECT UUID_SHORT(),u.id AS user_id,CAST(JSON_UNQUOTE(js.value) AS UNSIGNED) AS role_id
FROM user u
JOIN JSON_TABLE(u.role_id,'$[*]' COLUMNS (value VARCHAR(255) PATH '$')) AS js
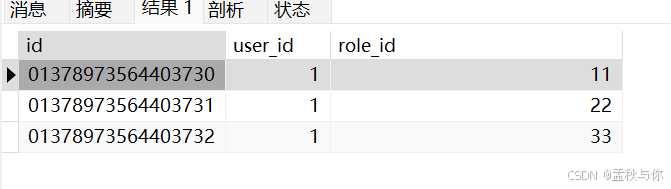
WHERE u.role_id IS NOT NULL AND JSON_VALID(u.role_id) AND JSON_LENGTH(u.role_id) > 0;JSON_TABLE 是作用于行数据的,所以我们看不到显式的join关联条件,执行后user_role数据示例:
分区
(仅讨论分区语法 博主个人感觉分区有点鸡肋 mysql的这个设计对数据来说或许合理 但对用户使用来说 并不友好;
当然这也是见仁见智 感兴趣可以自行造亿级以上数据测试 这是只是提供一种思路)
常用分区策略:
range分区: 比如按照年份分区
list分区:按照枚举值分区 比如根据省份
hash分区:按哈希值分区,适用于数据比较均匀的场景
key分区:类似HASH分区,但使用MySQL的内部哈希函数
mysql5.1之后就可以分区了 语法为
-- 移除分区
-- ALTER TABLE test_part REMOVE PARTITIONING;
-- 修改表分区 (如果是创建 则在建表语句后面跟上PARTITION )
ALTER TABLE test_part
PARTITION BY RANGE (code) (PARTITION p1 VALUES LESS THAN (100000000),PARTITION p2 VALUES LESS THAN (200000000),PARTITION p3 VALUES LESS THAN (300000000),PARTITION p4 VALUES LESS THAN MAXVALUE
);建表分区示例
-- 根据年份分区
CREATE TABLE orders (order_id INT NOT NULL,customer_id INT NOT NULL,order_date DATE NOT NULL,total DECIMAL(10, 2),PRIMARY KEY (order_id, order_date)
)
PARTITION BY RANGE (YEAR(order_date)) (PARTITION p2019 VALUES LESS THAN (2020),PARTITION p2020 VALUES LESS THAN (2021),PARTITION p2021 VALUES LESS THAN (2022),PARTITION pmax VALUES LESS THAN MAXVALUE
);分区可以避免跨表分页的问题,虽然数据物理隔离了 但是终归是在同一张表;但是必须注意的一点:分区字段必须是主键字段之一;
因为一旦有主键,它就成为表的核心约束,MySQL 必须保证 主键在全表范围内唯一,但如果主键不包含分区字段,那主键值一样的数据有可能落入不同分区这样就出现了主键冲突,MySQL 没法检测这个冲突 —— 所以为了防止这种“隐形冲突”,它强制要求主键必须包含分区字段,否则干脆不让你建表。
这个设计不得不吐槽了,例如oracle就可以做到分区后也全局检测,所以不用限制主键分区
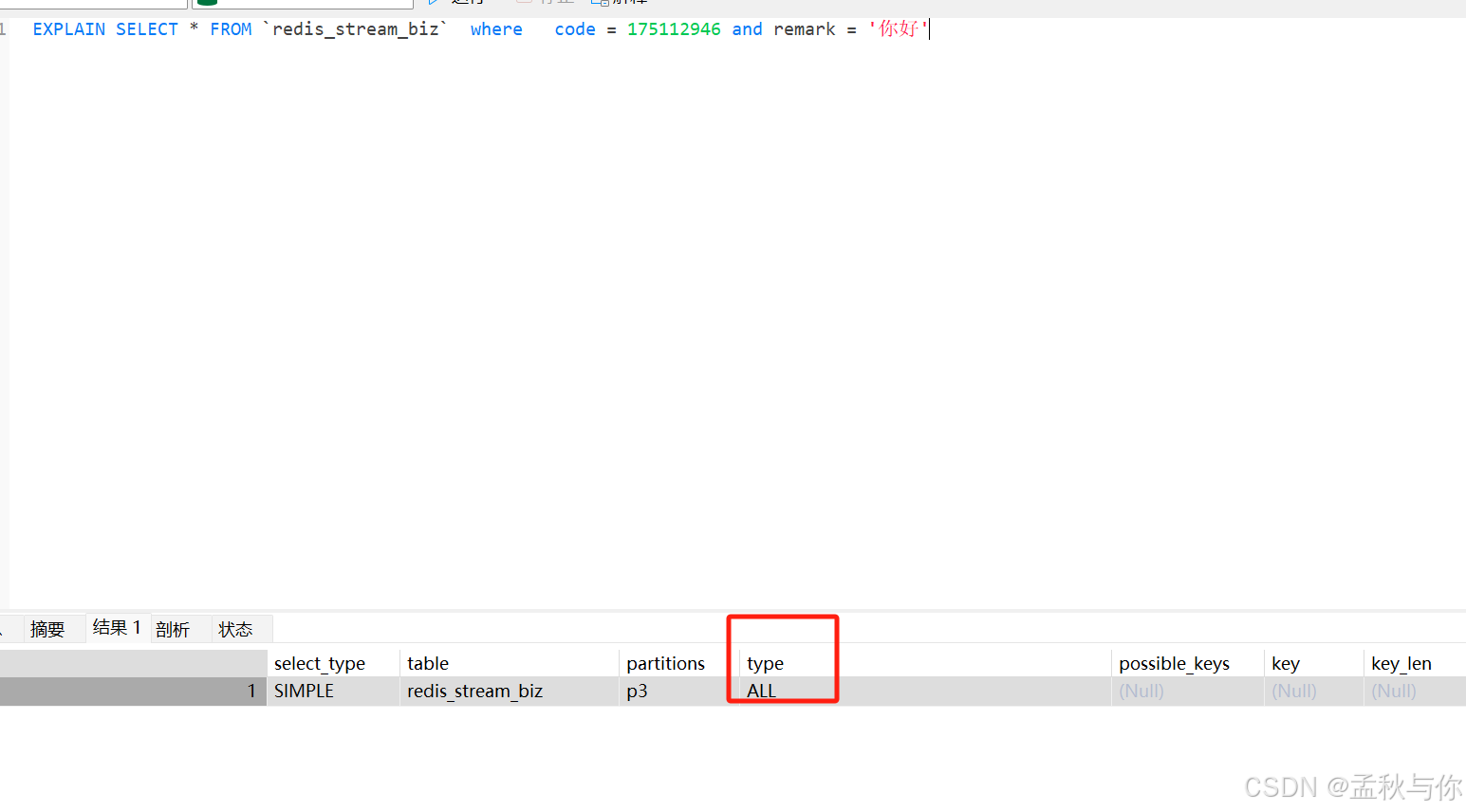
如下图 分区后反而降低了效率,主键本来就是聚促索引 弄成联合主键效率反而可能降低,在博主亲测的几千万级别数据 是完全没有必要分区(也没必要分表) , 不分区 建索引反而会快些
但是当表不存在主键的时候,最核心的性约束就不是主键了,而是唯一索引,这个时候 分区键是唯一索引字段就能分区成功了:
CREATE TABLE t1 (col1 INT NOT NULL,col2 DATE NOT NULL,col3 INT NOT NULL,col4 INT NOT NULL,UNIQUE KEY (col1, col2, col3)
)
PARTITION BY HASH(col3)
PARTITIONS 4;
-- 能执行成功
ALTER TABLE user_role_no_id PARTITION BY HASH(user_id) PARTITIONS 4;
那话又说回来,怎么会有大数据量的业务表不存在主键呢?
不存在主键的表(如配置表、字典表)又怎么会到分区的程度呢
这本身似乎是个悖论,所以我们平常见到的mysql分区应该也比较少;
[重申:本文仅介绍mysql有分区用法,实际使用可能需要斟酌再三]

Canvas基础(万字图文讲解))

)

)




的性能对比研究)


考前,面试前均可用!)




 : 阿里云百炼应用问答_回答图片问题_方案1_提问时上传图片文件)
